


Highload++ మరియు DataFest Minsk 2019లో నా ప్రసంగాల ఆధారంగా.
నేడు చాలా మందికి, ఆన్లైన్ జీవితంలో మెయిల్ అంతర్భాగంగా ఉంది. దాని సహాయంతో, మేము వ్యాపార కరస్పాండెన్స్ నిర్వహిస్తాము, ఆర్థిక, హోటల్ బుకింగ్లు, ఆర్డర్లు చేయడం మరియు మరెన్నో సంబంధించిన అన్ని రకాల ముఖ్యమైన సమాచారాన్ని నిల్వ చేస్తాము. 2018 మధ్యలో, మేము మెయిల్ అభివృద్ధి కోసం ఒక ఉత్పత్తి వ్యూహాన్ని రూపొందించాము. ఆధునిక మెయిల్ ఎలా ఉండాలి?
మెయిల్ ఉండాలి తెలివైన, అంటే, పెరుగుతున్న సమాచారం యొక్క వాల్యూమ్ను నావిగేట్ చేయడంలో వినియోగదారులకు సహాయం చేయడం: ఫిల్టర్, నిర్మాణం మరియు దానిని అత్యంత అనుకూలమైన రీతిలో అందించడం. ఆమె ఉండాలి ఉపయోగకరమైన, మీ మెయిల్బాక్స్లోనే వివిధ పనులను పరిష్కరించడానికి మిమ్మల్ని అనుమతిస్తుంది, ఉదాహరణకు, జరిమానాలు చెల్లించండి (దురదృష్టవశాత్తూ, నేను ఉపయోగించే ఫంక్షన్). మరియు అదే సమయంలో, మెయిల్ తప్పనిసరిగా సమాచార రక్షణను అందించాలి, స్పామ్ను కత్తిరించడం మరియు హ్యాకింగ్ నుండి రక్షించడం, అంటే. సురక్షితంగా.
ఈ ప్రాంతాలు అనేక కీలక సమస్యలను నిర్వచించాయి, వీటిలో చాలా వరకు మెషిన్ లెర్నింగ్ ఉపయోగించి సమర్థవంతంగా పరిష్కరించబడతాయి. వ్యూహంలో భాగంగా అభివృద్ధి చేయబడిన ఇప్పటికే ఉన్న లక్షణాల ఉదాహరణలు ఇక్కడ ఉన్నాయి - ఒక్కో దిశకు ఒకటి.
- స్మార్ట్ ప్రత్యుత్తరం. మెయిల్కి స్మార్ట్ రిప్లై ఫీచర్ ఉంది. న్యూరల్ నెట్వర్క్ లేఖ యొక్క వచనాన్ని విశ్లేషిస్తుంది, దాని అర్థం మరియు ఉద్దేశ్యాన్ని అర్థం చేసుకుంటుంది మరియు ఫలితంగా మూడు అత్యంత సముచితమైన ప్రతిస్పందన ఎంపికలను అందిస్తుంది: సానుకూల, ప్రతికూల మరియు తటస్థ. ఇది అక్షరాలకు సమాధానమిచ్చేటప్పుడు సమయాన్ని గణనీయంగా ఆదా చేయడానికి సహాయపడుతుంది మరియు తరచుగా ప్రామాణికం కాని మరియు ఫన్నీ విధంగా ప్రతిస్పందిస్తుంది.
- ఇమెయిల్లను సమూహపరచడంఆన్లైన్ స్టోర్లలోని ఆర్డర్లకు సంబంధించినది. మేము తరచుగా ఆన్లైన్లో షాపింగ్ చేస్తాము మరియు, ఒక నియమం వలె, దుకాణాలు ప్రతి ఆర్డర్ కోసం అనేక ఇమెయిల్లను పంపగలవు. ఉదాహరణకు, అతిపెద్ద సేవ అయిన AliExpress నుండి, ఒక ఆర్డర్ కోసం చాలా అక్షరాలు వస్తాయి మరియు టెర్మినల్ సందర్భంలో వాటి సంఖ్య 29కి చేరుకోవచ్చని మేము లెక్కించాము. కాబట్టి, పేరున్న ఎంటిటీ రికగ్నిషన్ మోడల్ని ఉపయోగించి, మేము ఆర్డర్ నంబర్ను సంగ్రహిస్తాము మరియు టెక్స్ట్ నుండి ఇతర సమాచారం మరియు అన్ని అక్షరాలను ఒకే థ్రెడ్లో సమూహపరచండి. మేము ఆర్డర్ గురించిన ప్రాథమిక సమాచారాన్ని కూడా ప్రత్యేక పెట్టెలో ప్రదర్శిస్తాము, ఇది ఈ రకమైన ఇమెయిల్తో పని చేయడాన్ని సులభతరం చేస్తుంది.

- యాంటీ ఫిషింగ్. ఫిషింగ్ అనేది ముఖ్యంగా ప్రమాదకరమైన మోసపూరిత ఇమెయిల్ రకం, దీని సహాయంతో దాడి చేసేవారు ఆర్థిక సమాచారాన్ని (యూజర్ బ్యాంక్ కార్డ్లతో సహా) మరియు లాగిన్లను పొందడానికి ప్రయత్నిస్తారు. అలాంటి లేఖలు దృశ్యమానంగా సహా, సేవ ద్వారా పంపబడిన నిజమైన వాటిని అనుకరిస్తాయి. అందువల్ల, కంప్యూటర్ విజన్ సహాయంతో, మేము పెద్ద కంపెనీల (ఉదాహరణకు, Mail.ru, Sber, Alfa) నుండి లోగోలు మరియు అక్షరాల రూపకల్పన శైలిని గుర్తించాము మరియు మా స్పామ్ మరియు ఫిషింగ్ వర్గీకరణల్లోని టెక్స్ట్ మరియు ఇతర లక్షణాలతో పాటు దీన్ని పరిగణనలోకి తీసుకుంటాము. .
యంత్ర అభ్యాస
సాధారణంగా ఇమెయిల్లో మెషిన్ లెర్నింగ్ గురించి కొంచెం. మెయిల్ అత్యంత లోడ్ చేయబడిన సిస్టమ్: 1,5 మిలియన్ల DAU వినియోగదారుల కోసం మా సర్వర్ల ద్వారా రోజుకు సగటున 30 బిలియన్ అక్షరాలు పంపబడతాయి. దాదాపు 30 మెషిన్ లెర్నింగ్ సిస్టమ్లు అవసరమైన అన్ని ఫంక్షన్లు మరియు ఫీచర్లకు మద్దతిస్తాయి.
ప్రతి అక్షరం మొత్తం వర్గీకరణ పైప్లైన్ గుండా వెళుతుంది. మొదట మేము స్పామ్ను కత్తిరించాము మరియు మంచి ఇమెయిల్లను వదిలివేస్తాము. యాంటిస్పామ్ యొక్క పనిని వినియోగదారులు తరచుగా గమనించరు, ఎందుకంటే 95-99% స్పామ్ తగిన ఫోల్డర్లో కూడా ముగియదు. స్పామ్ గుర్తింపు అనేది మా సిస్టమ్లో చాలా ముఖ్యమైన భాగం మరియు అత్యంత కష్టతరమైనది, ఎందుకంటే స్పామ్ వ్యతిరేక రంగంలో డిఫెన్స్ మరియు అటాక్ సిస్టమ్ల మధ్య స్థిరమైన అనుసరణ ఉంటుంది, ఇది మా బృందానికి నిరంతర ఇంజనీరింగ్ సవాలును అందిస్తుంది.
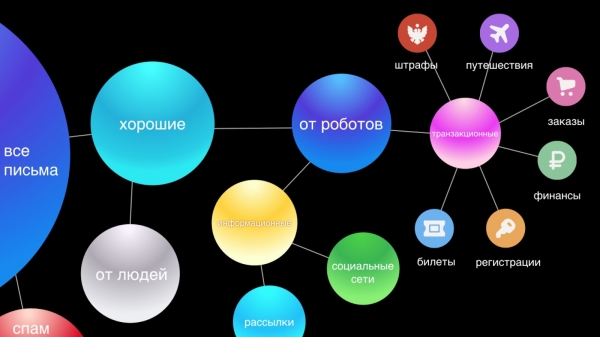
తరువాత, మేము వ్యక్తులు మరియు రోబోట్ల నుండి అక్షరాలను వేరు చేస్తాము. వ్యక్తుల నుండి వచ్చే ఇమెయిల్లు చాలా ముఖ్యమైనవి, కాబట్టి మేము వారి కోసం స్మార్ట్ ప్రత్యుత్తరం వంటి లక్షణాలను అందిస్తాము. రోబోల నుండి లేఖలు రెండు భాగాలుగా విభజించబడ్డాయి: లావాదేవీలు - ఇవి సేవల నుండి ముఖ్యమైన లేఖలు, ఉదాహరణకు, కొనుగోళ్లు లేదా హోటల్ రిజర్వేషన్లు, ఆర్థిక మరియు సమాచారం యొక్క నిర్ధారణలు - ఇవి వ్యాపార ప్రకటనలు, తగ్గింపులు.
లావాదేవీ ఇమెయిల్లు వ్యక్తిగత కరస్పాండెన్స్కు సమానమైన ప్రాముఖ్యతను కలిగి ఉంటాయని మేము విశ్వసిస్తున్నాము. వారు చేతిలో ఉండాలి, ఎందుకంటే మేము తరచుగా ఆర్డర్ లేదా ఎయిర్ టికెట్ రిజర్వేషన్ గురించి సమాచారాన్ని త్వరగా కనుగొనవలసి ఉంటుంది మరియు మేము ఈ అక్షరాల కోసం వెతకడానికి సమయాన్ని వెచ్చిస్తాము. అందువల్ల, సౌలభ్యం కోసం, మేము వాటిని స్వయంచాలకంగా ఆరు ప్రధాన వర్గాలుగా విభజిస్తాము: ప్రయాణం, ఆర్డర్లు, ఫైనాన్స్, టిక్కెట్లు, రిజిస్ట్రేషన్లు మరియు, చివరకు, జరిమానాలు.
సమాచార లేఖలు అతిపెద్ద మరియు బహుశా తక్కువ ముఖ్యమైన సమూహం, దీనికి తక్షణ ప్రతిస్పందన అవసరం లేదు, ఎందుకంటే అతను అలాంటి లేఖను చదవకపోతే వినియోగదారు జీవితంలో ముఖ్యమైనది ఏమీ మారదు. మా కొత్త ఇంటర్ఫేస్లో, మేము వాటిని రెండు థ్రెడ్లుగా కుదించాము: సోషల్ నెట్వర్క్లు మరియు వార్తాలేఖలు, తద్వారా ఇన్బాక్స్ను దృశ్యమానంగా క్లియర్ చేస్తుంది మరియు ముఖ్యమైన సందేశాలు మాత్రమే కనిపిస్తాయి.
దోపిడీ
పెద్ద సంఖ్యలో వ్యవస్థలు ఆపరేషన్లో చాలా ఇబ్బందులను కలిగిస్తాయి. అన్నింటికంటే, మోడల్లు కాలక్రమేణా క్షీణిస్తాయి, ఏదైనా సాఫ్ట్వేర్ లాగా: లక్షణాలు విచ్ఛిన్నమవుతాయి, యంత్రాలు విఫలమవుతాయి, కోడ్ వంకరగా మారుతుంది. అదనంగా, డేటా నిరంతరం మారుతూ ఉంటుంది: కొత్తవి జోడించబడతాయి, వినియోగదారు ప్రవర్తన నమూనాలు రూపాంతరం చెందుతాయి, మొదలైనవి, కాబట్టి సరైన మద్దతు లేని మోడల్ కాలక్రమేణా అధ్వాన్నంగా మరియు అధ్వాన్నంగా పని చేస్తుంది.
లోతైన యంత్ర అభ్యాసం వినియోగదారుల జీవితాల్లోకి చొచ్చుకుపోతుందని మనం మరచిపోకూడదు, పర్యావరణ వ్యవస్థపై వారు ఎక్కువ ప్రభావం చూపుతారు మరియు ఫలితంగా, మార్కెట్ ఆటగాళ్లు మరింత ఆర్థిక నష్టాలు లేదా లాభాలను పొందవచ్చు. అందువల్ల, పెరుగుతున్న ప్రాంతాలలో, ఆటగాళ్ళు ML అల్గారిథమ్ల పనికి అనుగుణంగా ఉన్నారు (క్లాసిక్ ఉదాహరణలు ప్రకటనలు, శోధన మరియు ఇప్పటికే పేర్కొన్న యాంటిస్పామ్).
అలాగే, మెషిన్ లెర్నింగ్ టాస్క్లకు ఒక ప్రత్యేకత ఉంది: సిస్టమ్లో ఏదైనా, చిన్నది కూడా, మోడల్తో చాలా పనిని సృష్టించగలదు: డేటాతో పని చేయడం, తిరిగి శిక్షణ ఇవ్వడం, విస్తరణ, వారాలు లేదా నెలలు పట్టవచ్చు. అందువల్ల, మీ నమూనాలు పనిచేసే వాతావరణం ఎంత వేగంగా మారుతుందో, వాటిని నిర్వహించడానికి ఎక్కువ కృషి అవసరం. ఒక బృందం చాలా వ్యవస్థలను సృష్టించగలదు మరియు దాని గురించి సంతోషంగా ఉంటుంది, కానీ కొత్తగా ఏమీ చేసే అవకాశం లేకుండా దాదాపు అన్ని వనరులను వాటిని నిర్వహించడానికి ఖర్చు చేస్తుంది. యాంటిస్పామ్ బృందంలో మేము ఒకసారి అలాంటి పరిస్థితిని ఎదుర్కొన్నాము. మరియు వారు మద్దతును స్వయంచాలకంగా చేయాల్సిన అవసరం ఉందని వారు స్పష్టమైన తీర్మానం చేసారు.
ఆటోమేషన్
ఏమి స్వయంచాలకంగా చేయవచ్చు? దాదాపు ప్రతిదీ, నిజానికి. మెషిన్ లెర్నింగ్ ఇన్ఫ్రాస్ట్రక్చర్ని నిర్వచించే నాలుగు ప్రాంతాలను నేను గుర్తించాను:
- వివరాల సేకరణ;
- అదనపు శిక్షణ;
- మోహరించేందుకు;
- పరీక్ష & పర్యవేక్షణ.
పర్యావరణం అస్థిరంగా మరియు నిరంతరం మారుతున్నట్లయితే, మోడల్ చుట్టూ ఉన్న మొత్తం మౌలిక సదుపాయాలు మోడల్ కంటే చాలా ముఖ్యమైనవిగా మారతాయి. ఇది మంచి పాత లీనియర్ క్లాసిఫైయర్ కావచ్చు, కానీ మీరు దీనికి సరైన ఫీచర్లను అందించి, వినియోగదారుల నుండి మంచి అభిప్రాయాన్ని పొందినట్లయితే, ఇది అన్ని గంటలు మరియు ఈలలతో కూడిన స్టేట్-ఆఫ్-ది-ఆర్ట్ మోడల్ల కంటే మెరుగ్గా పని చేస్తుంది.
ఫీడ్బ్యాక్ లూప్
ఈ చక్రం డేటా సేకరణ, అదనపు శిక్షణ మరియు విస్తరణను మిళితం చేస్తుంది - వాస్తవానికి, మొత్తం మోడల్ నవీకరణ చక్రం. ఇది ఎందుకు ముఖ్యమైనది? మెయిల్లో నమోదు షెడ్యూల్ను చూడండి:
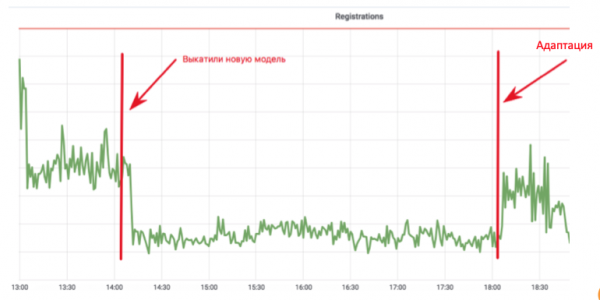
మెషీన్ లెర్నింగ్ డెవలపర్ బాట్లను ఇమెయిల్లో నమోదు చేయకుండా నిరోధించే యాంటీ-బాట్ మోడల్ను అమలు చేశారు. గ్రాఫ్ నిజమైన వినియోగదారులు మాత్రమే ఉండే విలువకు పడిపోతుంది. అంతా గొప్పదే! కానీ నాలుగు గంటలు గడిచాయి, బాట్లు వారి స్క్రిప్ట్లను సర్దుబాటు చేస్తాయి మరియు ప్రతిదీ సాధారణ స్థితికి వస్తుంది. ఈ అమలులో, డెవలపర్ ఫీచర్లను జోడించడం మరియు మోడల్కు మళ్లీ శిక్షణ ఇవ్వడం కోసం ఒక నెల గడిపారు, అయితే స్పామర్ నాలుగు గంటల్లో స్వీకరించగలిగారు.
చాలా బాధాకరంగా ఉండకూడదని మరియు తరువాత ప్రతిదీ పునరావృతం చేయనవసరం లేకుండా ఉండటానికి, ఫీడ్బ్యాక్ లూప్ ఎలా ఉంటుందో మరియు పర్యావరణం మారితే మనం ఏమి చేస్తాము అనే దాని గురించి మనం మొదట ఆలోచించాలి. డేటాను సేకరించడం ప్రారంభించండి - ఇది మా అల్గారిథమ్లకు ఇంధనం.
వివరాల సేకరణ
ఆధునిక న్యూరల్ నెట్వర్క్ల కోసం, ఎక్కువ డేటా, మెరుగైనది మరియు అవి వాస్తవానికి ఉత్పత్తి యొక్క వినియోగదారులచే ఉత్పత్తి చేయబడతాయని స్పష్టమవుతుంది. డేటాను గుర్తించడం ద్వారా వినియోగదారులు మాకు సహాయం చేయవచ్చు, కానీ మేము దీన్ని దుర్వినియోగం చేయలేము, ఎందుకంటే ఏదో ఒక సమయంలో వినియోగదారులు మీ మోడల్లను పూర్తి చేయడంలో అలసిపోతారు మరియు మరొక ఉత్పత్తికి మారతారు.
అత్యంత సాధారణ తప్పులలో ఒకటి (ఇక్కడ నేను ఆండ్రూ ఎన్జిని సూచిస్తున్నాను) పరీక్ష డేటాసెట్లోని కొలమానాలపై ఎక్కువ దృష్టి పెట్టడం, మరియు వినియోగదారు నుండి వచ్చే అభిప్రాయంపై కాదు, ఇది వాస్తవానికి పని నాణ్యతకు ప్రధాన కొలత, ఎందుకంటే మేము సృష్టించాము వినియోగదారు కోసం ఒక ఉత్పత్తి. వినియోగదారు అర్థం చేసుకోకపోతే లేదా మోడల్ యొక్క పనిని ఇష్టపడకపోతే, అప్పుడు ప్రతిదీ నాశనం అవుతుంది.
అందువల్ల, వినియోగదారు ఎల్లప్పుడూ ఓటు వేయగలగాలి మరియు అభిప్రాయానికి ఒక సాధనాన్ని అందించాలి. మెయిల్బాక్స్లో ఫైనాన్స్కు సంబంధించిన లేఖ వచ్చిందని మనం అనుకుంటే, దానిని “ఫైనాన్స్” అని గుర్తించి, వినియోగదారు క్లిక్ చేసి, ఇది ఫైనాన్స్ కాదని చెప్పగలిగే బటన్ను గీయాలి.
అభిప్రాయ నాణ్యత
యూజర్ ఫీడ్బ్యాక్ నాణ్యత గురించి మాట్లాడుకుందాం. ముందుగా, మీరు మరియు వినియోగదారు వేర్వేరు అర్థాలను ఒకే భావనలో ఉంచవచ్చు. ఉదాహరణకు, మీరు మరియు మీ ప్రోడక్ట్ మేనేజర్లు “ఫైనాన్స్” అంటే బ్యాంక్ నుండి వచ్చిన ఉత్తరాలు అని అనుకుంటారు మరియు వినియోగదారు తన పెన్షన్ గురించి అమ్మమ్మ నుండి వచ్చిన లేఖ కూడా ఫైనాన్స్ని సూచిస్తుందని భావిస్తారు. రెండవది, ఎటువంటి లాజిక్ లేకుండా బటన్లను నొక్కడానికి బుద్ధిహీనంగా ఇష్టపడే వినియోగదారులు ఉన్నారు. మూడవదిగా, వినియోగదారు తన ముగింపులలో లోతుగా పొరబడవచ్చు. మా అభ్యాసం నుండి ఒక అద్భుతమైన ఉదాహరణ వర్గీకరణను అమలు చేయడం , ఆఫ్రికాలో అకస్మాత్తుగా దొరికిన దూరపు బంధువు నుండి అనేక మిలియన్ డాలర్లు తీసుకోమని వినియోగదారుని అడిగే చాలా ఫన్నీ రకం స్పామ్. ఈ వర్గీకరణను అమలు చేసిన తర్వాత, మేము ఈ ఇమెయిల్లపై "స్పామ్ కాదు" క్లిక్లను తనిఖీ చేసాము మరియు వాటిలో 80% జ్యుసి నైజీరియన్ స్పామ్ అని తేలింది, ఇది వినియోగదారులు చాలా మోసపూరితంగా ఉంటారని సూచిస్తుంది.
మరియు బటన్లను వ్యక్తులు మాత్రమే కాకుండా, బ్రౌజర్గా నటించే అన్ని రకాల బాట్ల ద్వారా కూడా క్లిక్ చేయవచ్చని మర్చిపోకూడదు. కాబట్టి రా ఫీడ్బ్యాక్ నేర్చుకోవడం మంచిది కాదు. ఈ సమాచారంతో మీరు ఏమి చేయవచ్చు?
మేము రెండు విధానాలను ఉపయోగిస్తాము:
- లింక్ చేయబడిన ML నుండి అభిప్రాయం. ఉదాహరణకు, మేము ఆన్లైన్ యాంటీ-బాట్ సిస్టమ్ని కలిగి ఉన్నాము, ఇది నేను చెప్పినట్లుగా, పరిమిత సంఖ్యలో సంకేతాల ఆధారంగా త్వరిత నిర్ణయం తీసుకుంటుంది. మరియు వాస్తవం తర్వాత పని చేసే రెండవ, నెమ్మదిగా వ్యవస్థ ఉంది. ఇది వినియోగదారు, అతని ప్రవర్తన మొదలైన వాటి గురించి మరింత డేటాను కలిగి ఉంది. ఫలితంగా, అత్యంత సమాచారంతో కూడిన నిర్ణయం తీసుకోబడుతుంది; తదనుగుణంగా, ఇది అధిక ఖచ్చితత్వం మరియు పరిపూర్ణతను కలిగి ఉంటుంది. మీరు ఈ సిస్టమ్ల ఆపరేషన్లోని వ్యత్యాసాన్ని మొదటిదానికి శిక్షణ డేటాగా నిర్దేశించవచ్చు. అందువల్ల, సరళమైన వ్యవస్థ ఎల్లప్పుడూ మరింత సంక్లిష్టమైన పనితీరును చేరుకోవడానికి ప్రయత్నిస్తుంది.
- వర్గీకరణను క్లిక్ చేయండి. మీరు ప్రతి వినియోగదారు క్లిక్ని వర్గీకరించవచ్చు, దాని చెల్లుబాటు మరియు వినియోగాన్ని అంచనా వేయవచ్చు. మేము దీన్ని యాంటిస్పామ్ మెయిల్లో చేస్తాము, వినియోగదారు లక్షణాలు, అతని చరిత్ర, పంపినవారి లక్షణాలు, వచనం మరియు వర్గీకరణదారుల ఫలితాన్ని ఉపయోగిస్తాము. ఫలితంగా, మేము వినియోగదారు అభిప్రాయాన్ని ధృవీకరించే ఆటోమేటిక్ సిస్టమ్ను పొందుతాము. మరియు ఇది చాలా తక్కువ తరచుగా తిరిగి శిక్షణ పొందాల్సిన అవసరం ఉన్నందున, దాని పని అన్ని ఇతర వ్యవస్థలకు ఆధారం అవుతుంది. ఈ మోడల్లో ప్రధాన ప్రాధాన్యత ఖచ్చితత్వం, ఎందుకంటే సరికాని డేటాపై మోడల్కు శిక్షణ ఇవ్వడం పరిణామాలతో నిండి ఉంటుంది.
మేము డేటాను శుభ్రపరుస్తున్నప్పుడు మరియు మా ML సిస్టమ్లకు మరింత శిక్షణ ఇస్తున్నప్పుడు, వినియోగదారుల గురించి మనం మరచిపోకూడదు, ఎందుకంటే మాకు, గ్రాఫ్లో వేల, మిలియన్ల లోపాలు గణాంకాలు మరియు వినియోగదారుకు, ప్రతి బగ్ ఒక విషాదం. ఉత్పత్తిలో మీ లోపంతో వినియోగదారు ఏదో ఒకవిధంగా జీవించాలి అనే వాస్తవంతో పాటు, అభిప్రాయాన్ని స్వీకరించిన తర్వాత, భవిష్యత్తులో ఇదే విధమైన పరిస్థితి తొలగించబడుతుందని అతను ఆశిస్తున్నాడు. అందువల్ల, వినియోగదారులకు ఓటు వేయడానికి మాత్రమే కాకుండా, ML సిస్టమ్ల ప్రవర్తనను సరిదిద్దడానికి కూడా ఎల్లప్పుడూ విలువైనది, ఉదాహరణకు, ప్రతి అభిప్రాయ క్లిక్ కోసం వ్యక్తిగత హ్యూరిస్టిక్లను సృష్టించడం; మెయిల్ విషయంలో, ఇది ఫిల్టర్ చేయగల సామర్థ్యం కావచ్చు. ఈ వినియోగదారు కోసం పంపినవారు మరియు శీర్షిక ద్వారా అలాంటి అక్షరాలు.
మీరు సెమీ ఆటోమేటిక్ లేదా మాన్యువల్ మోడ్లో మద్దతు ఇవ్వడానికి కొన్ని నివేదికలు లేదా అభ్యర్థనల ఆధారంగా మోడల్ను రూపొందించాలి, తద్వారా ఇతర వినియోగదారులు ఇలాంటి సమస్యలతో బాధపడరు.
నేర్చుకోవడం కోసం హ్యూరిస్టిక్స్
ఈ హ్యూరిస్టిక్స్ మరియు క్రచెస్తో రెండు సమస్యలు ఉన్నాయి. మొదటిది ఏమిటంటే, ఎప్పటికప్పుడు పెరుగుతున్న క్రచెస్ను నిర్వహించడం కష్టం, సుదీర్ఘకాలం పాటు వాటి నాణ్యత మరియు పనితీరును విడదీయండి. రెండవ సమస్య ఏమిటంటే, లోపం తరచుగా ఉండకపోవచ్చు మరియు మోడల్కు మరింత శిక్షణ ఇవ్వడానికి కొన్ని క్లిక్లు సరిపోవు. కింది విధానాన్ని వర్తింపజేస్తే, ఈ రెండు సంబంధం లేని ప్రభావాలను గణనీయంగా తటస్థీకరించవచ్చు.
- మేము తాత్కాలిక ఊతకర్రను సృష్టిస్తాము.
- మేము దాని నుండి మోడల్కు డేటాను పంపుతాము, అందుకున్న డేటాతో సహా ఇది క్రమం తప్పకుండా నవీకరించబడుతుంది. ఇక్కడ, వాస్తవానికి, శిక్షణా సెట్లోని డేటా నాణ్యతను తగ్గించకుండా ఉండటానికి హ్యూరిస్టిక్స్ అధిక ఖచ్చితత్వాన్ని కలిగి ఉండటం ముఖ్యం.
- అప్పుడు మేము క్రచ్ను ట్రిగ్గర్ చేయడానికి మానిటరింగ్ను సెట్ చేసాము మరియు కొంత సమయం తర్వాత క్రచ్ ఇకపై పనిచేయదు మరియు పూర్తిగా మోడల్తో కప్పబడి ఉంటే, మీరు దాన్ని సురక్షితంగా తీసివేయవచ్చు. ఇప్పుడు ఈ సమస్య మళ్లీ వచ్చే అవకాశం లేదు.
కాబట్టి క్రచెస్ యొక్క సైన్యం చాలా ఉపయోగకరంగా ఉంటుంది. ప్రధాన విషయం ఏమిటంటే వారి సేవ అత్యవసరం మరియు శాశ్వతమైనది కాదు.
అదనపు శిక్షణ
రీట్రైనింగ్ అనేది వినియోగదారులు లేదా ఇతర సిస్టమ్ల నుండి ఫీడ్బ్యాక్ ఫలితంగా పొందిన కొత్త డేటాను జోడించడం మరియు దానిపై ఇప్పటికే ఉన్న మోడల్కు శిక్షణ ఇవ్వడం. అదనపు శిక్షణతో అనేక సమస్యలు ఉండవచ్చు:
- మోడల్ కేవలం అదనపు శిక్షణకు మద్దతు ఇవ్వకపోవచ్చు, కానీ మొదటి నుండి మాత్రమే నేర్చుకోండి.
- అదనపు శిక్షణ ఖచ్చితంగా ఉత్పత్తిలో పని నాణ్యతను మెరుగుపరుస్తుందని ప్రకృతి పుస్తకంలో ఎక్కడా వ్రాయబడలేదు. తరచుగా దీనికి విరుద్ధంగా జరుగుతుంది, అంటే, క్షీణత మాత్రమే సాధ్యమవుతుంది.
- మార్పులు ఊహించలేనివి కావచ్చు. ఇది మన కోసం మనం గుర్తించిన చాలా సూక్ష్మమైన అంశం. A/B పరీక్షలో కొత్త మోడల్ ప్రస్తుత దానితో పోల్చితే సారూప్య ఫలితాలను చూపినప్పటికీ, ఇది ఒకేలా పని చేస్తుందని దీని అర్థం కాదు. వారి పని కేవలం ఒక శాతంలో తేడా ఉండవచ్చు, ఇది కొత్త లోపాలను తీసుకురావచ్చు లేదా ఇప్పటికే సరిదిద్దబడిన పాత వాటిని తిరిగి ఇవ్వవచ్చు. ప్రస్తుత లోపాలతో ఎలా జీవించాలో మాకు మరియు వినియోగదారులు ఇద్దరికీ ఇప్పటికే తెలుసు మరియు పెద్ద సంఖ్యలో కొత్త లోపాలు తలెత్తినప్పుడు, వినియోగదారు ఏమి జరుగుతుందో కూడా అర్థం చేసుకోలేరు, ఎందుకంటే అతను ఊహించదగిన ప్రవర్తనను ఆశిస్తున్నాడు.
అందువల్ల, అదనపు శిక్షణలో అత్యంత ముఖ్యమైన విషయం ఏమిటంటే, మోడల్ మెరుగుపరచబడిందని లేదా కనీసం అధ్వాన్నంగా లేదని నిర్ధారించుకోవడం.
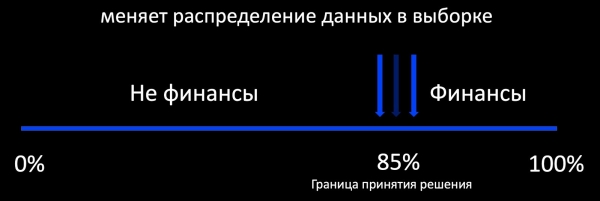
మేము అదనపు శిక్షణ గురించి మాట్లాడేటప్పుడు గుర్తుకు వచ్చే మొదటి విషయం యాక్టివ్ లెర్నింగ్ విధానం. దీని అర్థం ఏమిటి? ఉదాహరణకు, ఒక ఇమెయిల్ ఫైనాన్స్కి సంబంధించినదా కాదా అని వర్గీకరణ నిర్ణయిస్తుంది మరియు దాని నిర్ణయ సరిహద్దు చుట్టూ మేము లేబుల్ చేయబడిన ఉదాహరణల నమూనాను జోడిస్తాము. ఇది బాగా పని చేస్తుంది, ఉదాహరణకు, ప్రకటనలలో, చాలా అభిప్రాయం ఉంది మరియు మీరు ఆన్లైన్లో మోడల్కు శిక్షణ ఇవ్వవచ్చు. మరియు తక్కువ అభిప్రాయం ఉన్నట్లయితే, ఉత్పత్తి డేటా పంపిణీకి సంబంధించి మేము అత్యంత పక్షపాత నమూనాను పొందుతాము, దీని ఆధారంగా ఆపరేషన్ సమయంలో మోడల్ యొక్క ప్రవర్తనను అంచనా వేయడం అసాధ్యం.
నిజానికి, మా లక్ష్యం పాత నమూనాలను, ఇప్పటికే తెలిసిన నమూనాలను సంరక్షించడం మరియు కొత్త వాటిని పొందడం. ఇక్కడ కొనసాగింపు ముఖ్యం. మేము తరచుగా బయటకు రావడానికి చాలా కష్టపడే మోడల్, ఇప్పటికే పని చేస్తోంది, కాబట్టి మేము దాని పనితీరుపై దృష్టి పెట్టవచ్చు.
మెయిల్లో వేర్వేరు నమూనాలు ఉపయోగించబడతాయి: చెట్లు, లీనియర్, న్యూరల్ నెట్వర్క్లు. ప్రతిదానికి మేము మా స్వంత అదనపు శిక్షణ అల్గోరిథం చేస్తాము. అదనపు శిక్షణ ప్రక్రియలో, మేము క్రొత్త డేటాను మాత్రమే కాకుండా, తరచుగా కొత్త లక్షణాలను కూడా అందుకుంటాము, వీటిని మేము దిగువ అన్ని అల్గోరిథంలలో పరిగణనలోకి తీసుకుంటాము.
లీనియర్ మోడల్స్
మనకు లాజిస్టిక్ రిగ్రెషన్ ఉందని చెప్పండి. మేము ఈ క్రింది భాగాల నుండి నష్ట నమూనాను సృష్టిస్తాము:
- కొత్త డేటాపై లాగ్లాస్;
- మేము కొత్త ఫీచర్ల బరువులను క్రమబద్ధీకరిస్తాము (మేము పాత వాటిని తాకము);
- పాత నమూనాలను సంరక్షించడానికి మేము పాత డేటా నుండి కూడా నేర్చుకుంటాము;
- మరియు, బహుశా, అతి ముఖ్యమైన విషయం: మేము హార్మోనిక్ రెగ్యులరైజేషన్ను జోడిస్తాము, ఇది కట్టుబాటు ప్రకారం పాత మోడల్కు సంబంధించి బరువులు చాలా మారవని హామీ ఇస్తుంది.
ప్రతి లాస్ కాంపోనెంట్ కోఎఫీషియంట్లను కలిగి ఉన్నందున, క్రాస్ ధ్రువీకరణ ద్వారా లేదా ఉత్పత్తి అవసరాల ఆధారంగా మన పని కోసం సరైన విలువలను ఎంచుకోవచ్చు.
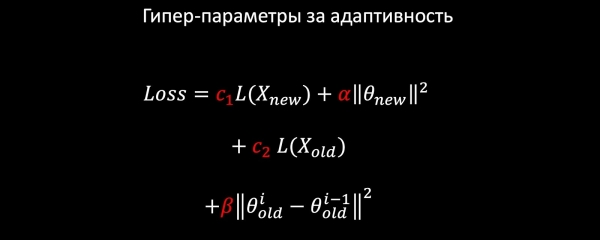
చెట్లు
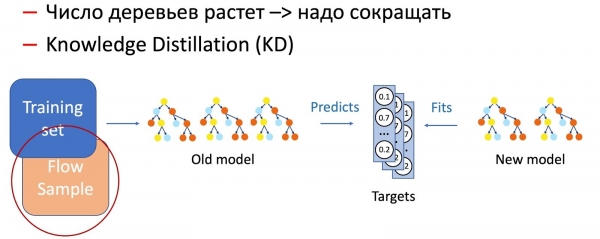
నిర్ణయ వృక్షాలకు వెళ్దాం. చెట్ల అదనపు శిక్షణ కోసం మేము క్రింది అల్గోరిథంను సంకలనం చేసాము:
- ఉత్పత్తి 100-300 చెట్ల అడవిని నడుపుతుంది, ఇది పాత డేటా సెట్పై శిక్షణ పొందింది.
- ముగింపులో మేము M = 5 ముక్కలను తీసివేసి, మొత్తం డేటా సెట్లో శిక్షణ పొందిన 2M = 10 కొత్త వాటిని జోడిస్తాము, కానీ కొత్త డేటా కోసం అధిక బరువుతో, ఇది సహజంగా మోడల్లో పెరుగుతున్న మార్పుకు హామీ ఇస్తుంది.
సహజంగానే, కాలక్రమేణా, చెట్ల సంఖ్య బాగా పెరుగుతుంది మరియు సమయాలకు అనుగుణంగా వాటిని క్రమానుగతంగా తగ్గించాలి. దీన్ని చేయడానికి, మేము ఇప్పుడు సర్వవ్యాప్త నాలెడ్జ్ డిస్టిలేషన్ (KD)ని ఉపయోగిస్తాము. దాని ఆపరేషన్ సూత్రం గురించి క్లుప్తంగా.
- మాకు ప్రస్తుత "సంక్లిష్ట" మోడల్ ఉంది. మేము శిక్షణ డేటా సెట్లో దీన్ని అమలు చేస్తాము మరియు అవుట్పుట్ వద్ద తరగతి సంభావ్యత పంపిణీని పొందుతాము.
- తర్వాత, తరగతి పంపిణీని టార్గెట్ వేరియబుల్గా ఉపయోగించి మోడల్ ఫలితాలను పునరావృతం చేయడానికి మేము విద్యార్థి మోడల్కు (ఈ సందర్భంలో తక్కువ చెట్లతో ఉన్న మోడల్) శిక్షణ ఇస్తాము.
- మేము డేటా సెట్ మార్కప్ను ఏ విధంగానూ ఉపయోగించము మరియు అందువల్ల మేము ఏకపక్ష డేటాను ఉపయోగించవచ్చు అని ఇక్కడ గమనించడం ముఖ్యం. వాస్తవానికి, మేము విద్యార్థి నమూనా కోసం శిక్షణ నమూనాగా పోరాట స్ట్రీమ్ నుండి డేటా నమూనాను ఉపయోగిస్తాము. ఈ విధంగా, శిక్షణా సమితి మోడల్ యొక్క ఖచ్చితత్వాన్ని నిర్ధారించడానికి అనుమతిస్తుంది మరియు స్ట్రీమ్ నమూనా ఉత్పత్తి పంపిణీపై సారూప్య పనితీరుకు హామీ ఇస్తుంది, శిక్షణా సమితి యొక్క పక్షపాతానికి పరిహారం ఇస్తుంది.
ఈ రెండు పద్ధతుల కలయిక (చెట్లను జోడించడం మరియు నాలెడ్జ్ డిస్టిలేషన్ని ఉపయోగించి వాటి సంఖ్యను కాలానుగుణంగా తగ్గించడం) కొత్త నమూనాల పరిచయం మరియు పూర్తి కొనసాగింపును నిర్ధారిస్తుంది.
KD సహాయంతో, మేము ఫీచర్లను తీసివేయడం మరియు ఖాళీలపై పని చేయడం వంటి మోడల్ ఫీచర్లపై విభిన్న కార్యకలాపాలను కూడా చేస్తాము. మా విషయంలో, డేటాబేస్లో నిల్వ చేయబడిన అనేక ముఖ్యమైన గణాంక లక్షణాలను (పంపేవారు, టెక్స్ట్ హ్యాష్లు, URLలు మొదలైనవి) కలిగి ఉన్నాము, అవి విఫలమవుతాయి. శిక్షణా సమితిలో వైఫల్యం పరిస్థితులు జరగనందున, మోడల్, వాస్తవానికి, సంఘటనల అటువంటి అభివృద్ధికి సిద్ధంగా లేదు. అటువంటి సందర్భాలలో, మేము KD మరియు ఆగ్మెంటేషన్ టెక్నిక్లను మిళితం చేస్తాము: డేటాలో కొంత భాగానికి శిక్షణ ఇచ్చేటప్పుడు, మేము అవసరమైన లక్షణాలను తీసివేస్తాము లేదా రీసెట్ చేస్తాము మరియు మేము అసలు లేబుల్లను (ప్రస్తుత మోడల్ యొక్క అవుట్పుట్లు) తీసుకుంటాము మరియు విద్యార్థి మోడల్ ఈ పంపిణీని పునరావృతం చేయడం నేర్చుకుంటుంది. .
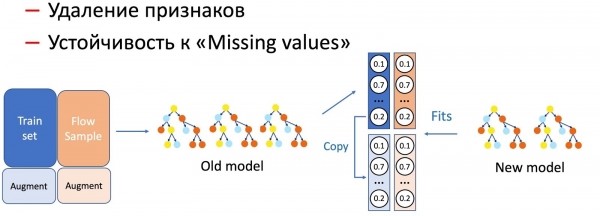
మరింత తీవ్రమైన మోడల్ మానిప్యులేషన్ సంభవిస్తుందని మేము గమనించాము, థ్రెడ్ నమూనా యొక్క ఎక్కువ శాతం అవసరం.
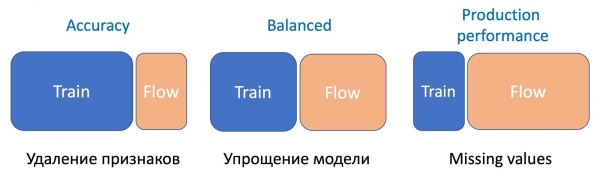
ఫీచర్ తొలగింపు, సరళమైన ఆపరేషన్, ప్రవాహంలో కొంత భాగం మాత్రమే అవసరం, ఎందుకంటే కొన్ని లక్షణాలు మాత్రమే మారతాయి మరియు ప్రస్తుత మోడల్ ఒకే సెట్లో శిక్షణ పొందింది - వ్యత్యాసం తక్కువగా ఉంటుంది. మోడల్ను సరళీకృతం చేయడానికి (చెట్ల సంఖ్యను చాలాసార్లు తగ్గించడం), ఇప్పటికే 50 నుండి 50 వరకు అవసరం. మరియు మోడల్ పనితీరును తీవ్రంగా ప్రభావితం చేసే ముఖ్యమైన గణాంక లక్షణాల లోపాల కోసం, పనిని సమం చేయడానికి మరింత ప్రవాహం అవసరం. అన్ని రకాల అక్షరాలపై కొత్త మినహాయింపు-నిరోధక మోడల్.
ఫాస్ట్టెక్స్ట్
ఫాస్ట్టెక్స్ట్కి వెళ్దాం. ఒక పదం యొక్క ప్రాతినిధ్యం (ఎంబెడ్డింగ్) అనేది పదం యొక్క ఎంబెడ్డింగ్ మొత్తం మరియు దానిలోని అన్ని అక్షరాలు N-గ్రాములు, సాధారణంగా ట్రిగ్రామ్లను కలిగి ఉంటుందని నేను మీకు గుర్తు చేస్తాను. చాలా ట్రిగ్రామ్లు ఉండవచ్చు కాబట్టి, బకెట్ హ్యాషింగ్ ఉపయోగించబడుతుంది, అంటే మొత్తం స్థలాన్ని నిర్దిష్ట స్థిర హ్యాష్మ్యాప్గా మారుస్తుంది. ఫలితంగా, బరువు మాతృక పదాలు + బకెట్ల సంఖ్యకు లోపలి పొర యొక్క పరిమాణంతో పొందబడుతుంది.
అదనపు శిక్షణతో, కొత్త సంకేతాలు కనిపిస్తాయి: పదాలు మరియు ట్రిగ్రామ్స్. Facebook నుండి ప్రామాణిక ఫాలో-అప్ శిక్షణలో ముఖ్యమైనది ఏమీ జరగదు. క్రాస్-ఎంట్రోపీతో పాత బరువులు మాత్రమే కొత్త డేటాపై మళ్లీ శిక్షణ పొందుతాయి. అందువల్ల, కొత్త ఫీచర్లు ఉపయోగించబడవు; వాస్తవానికి, ఈ విధానం ఉత్పత్తిలో మోడల్ యొక్క అనూహ్యతతో అనుబంధించబడిన పైన వివరించిన అన్ని ప్రతికూలతలను కలిగి ఉంది. అందుకే మేము ఫాస్ట్టెక్స్ట్ని కొద్దిగా సవరించాము. మేము అన్ని కొత్త బరువులను (పదాలు మరియు ట్రిగ్రామ్లు) జోడిస్తాము, క్రాస్-ఎంట్రోపీతో మొత్తం మ్యాట్రిక్స్ను విస్తరింపజేస్తాము మరియు లీనియర్ మోడల్తో సారూప్యత ద్వారా హార్మోనిక్ రెగ్యులరైజేషన్ని జోడిస్తాము, ఇది పాత బరువులలో ఒక చిన్న మార్పుకు హామీ ఇస్తుంది.

సిఎన్ఎన్
కన్వల్యూషనల్ నెట్వర్క్లు కొంచెం క్లిష్టంగా ఉంటాయి. CNNలో చివరి పొరలు పూర్తయితే, మీరు హార్మోనిక్ రెగ్యులరైజేషన్ను వర్తింపజేయవచ్చు మరియు కొనసాగింపుకు హామీ ఇవ్వవచ్చు. కానీ మొత్తం నెట్వర్క్ యొక్క అదనపు శిక్షణ అవసరమైతే, అటువంటి క్రమబద్ధీకరణ ఇకపై అన్ని పొరలకు వర్తించదు. అయితే, ట్రిపుల్ లాస్ (ట్రిపుల్ లాస్) ద్వారా కాంప్లిమెంటరీ ఎంబెడ్డింగ్లకు శిక్షణ ఇవ్వడానికి ఒక ఎంపిక ఉంది.).
ట్రిపుల్ నష్టం
యాంటీ-ఫిషింగ్ టాస్క్ని ఉదాహరణగా ఉపయోగించి, సాధారణ పరంగా ట్రిపుల్ లాస్ని చూద్దాం. మేము మా లోగోను అలాగే ఇతర కంపెనీల లోగోల యొక్క సానుకూల మరియు ప్రతికూల ఉదాహరణలను తీసుకుంటాము. మేము మొదటి వాటి మధ్య దూరాన్ని కనిష్టీకరించాము మరియు రెండవ దాని మధ్య దూరాన్ని పెంచుతాము, తరగతుల యొక్క ఎక్కువ కాంపాక్ట్నెస్ను నిర్ధారించడానికి మేము దీన్ని చిన్న గ్యాప్తో చేస్తాము.
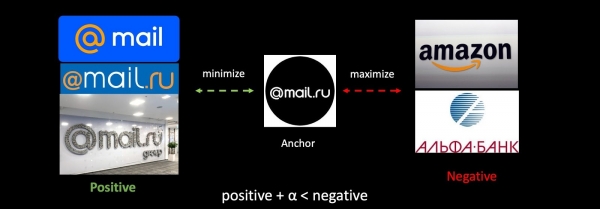
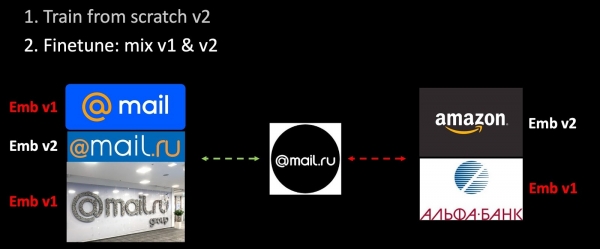
మేము నెట్వర్క్కు మరింత శిక్షణ ఇస్తే, మా మెట్రిక్ స్థలం పూర్తిగా మారుతుంది మరియు ఇది మునుపటి దానితో పూర్తిగా అననుకూలంగా మారుతుంది. వెక్టర్లను ఉపయోగించే సమస్యలలో ఇది తీవ్రమైన సమస్య. ఈ సమస్యను అధిగమించడానికి, మేము శిక్షణ సమయంలో పాత ఎంబెడ్డింగ్లను కలుపుతాము.
మేము శిక్షణా సెట్కు కొత్త డేటాను జోడించాము మరియు మొదటి నుండి మోడల్ యొక్క రెండవ వెర్షన్కు శిక్షణ ఇస్తున్నాము. రెండవ దశలో, మేము మా నెట్వర్క్కు (ఫైన్ట్యూనింగ్) మరింత శిక్షణ ఇస్తాము: మొదట చివరి పొర పూర్తయింది, ఆపై మొత్తం నెట్వర్క్ స్తంభింపజేయబడుతుంది. త్రిపాదిలను కంపోజ్ చేసే ప్రక్రియలో, మేము శిక్షణ పొందిన మోడల్ను ఉపయోగించి ఎంబెడ్డింగ్లలో కొంత భాగాన్ని మాత్రమే లెక్కిస్తాము, మిగిలినవి - పాతదాన్ని ఉపయోగిస్తాము. అందువలన, అదనపు శిక్షణ ప్రక్రియలో, మేము మెట్రిక్ ఖాళీలు v1 మరియు v2 అనుకూలతను నిర్ధారిస్తాము. హార్మోనిక్ రెగ్యులరైజేషన్ యొక్క ప్రత్యేక వెర్షన్.
మొత్తం ఆర్కిటెక్చర్
మేము యాంటిస్పామ్ని ఉపయోగించి మొత్తం సిస్టమ్ను ఉదాహరణగా పరిగణించినట్లయితే, అప్పుడు మోడల్లు వేరుచేయబడవు, కానీ ఒకదానికొకటి గూడులో ఉంటాయి. మేము చిత్రాలు, వచనం మరియు ఇతర లక్షణాలను తీసుకుంటాము, CNN మరియు ఫాస్ట్ టెక్స్ట్ ఉపయోగించి మేము పొందుపరచడం పొందుతాము. తరువాత, వర్గీకరణలు ఎంబెడ్డింగ్ల పైన వర్తించబడతాయి, ఇవి వివిధ తరగతులకు స్కోర్లను అందిస్తాయి (అక్షరాల రకాలు, స్పామ్, లోగో ఉనికి). తుది నిర్ణయం తీసుకోవడానికి ఇప్పటికే సంకేతాలు మరియు సంకేతాలు చెట్ల అడవిలోకి ప్రవేశిస్తున్నాయి. ఈ స్కీమ్లోని వ్యక్తిగత వర్గీకరణలు సిస్టమ్ యొక్క ఫలితాలను మరింత మెరుగ్గా అర్థం చేసుకోవడం మరియు సమస్యల విషయంలో మరింత నిర్దిష్టంగా భాగాలను తిరిగి శిక్షణ ఇవ్వడం సాధ్యపడుతుంది, మొత్తం డేటాను ముడి రూపంలో నిర్ణయ వృక్షాలకు అందించడం కంటే.
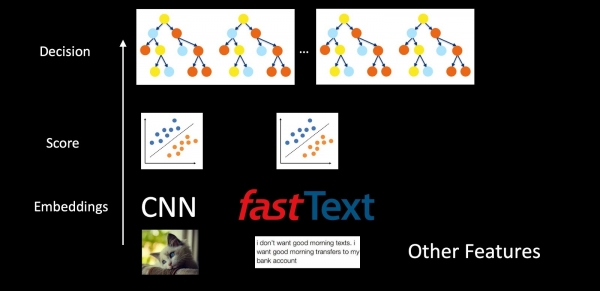
ఫలితంగా, మేము ప్రతి స్థాయిలో కొనసాగింపుకు హామీ ఇస్తున్నాము. CNN మరియు ఫాస్ట్ టెక్స్ట్లో దిగువ స్థాయిలో మేము హార్మోనిక్ రెగ్యులరైజేషన్ని ఉపయోగిస్తాము, మధ్యలో ఉన్న వర్గీకరణదారుల కోసం మేము సంభావ్యత పంపిణీ యొక్క స్థిరత్వం కోసం హార్మోనిక్ రెగ్యులరైజేషన్ మరియు రేట్ క్రమాంకనాన్ని కూడా ఉపయోగిస్తాము. బాగా, ట్రీ బూస్టింగ్ ఇంక్రిమెంటల్ గా లేదా నాలెడ్జ్ డిస్టిలేషన్ ఉపయోగించి శిక్షణ పొందుతుంది.
సాధారణంగా, అటువంటి నెస్టెడ్ మెషీన్ లెర్నింగ్ సిస్టమ్ను నిర్వహించడం సాధారణంగా నొప్పిగా ఉంటుంది, ఎందుకంటే దిగువ స్థాయిలో ఉన్న ఏదైనా భాగం పైన ఉన్న మొత్తం సిస్టమ్కి అప్డేట్కు దారి తీస్తుంది. కానీ మా సెటప్లో ప్రతి భాగం కొద్దిగా మారుతుంది మరియు మునుపటిదానికి అనుకూలంగా ఉంటుంది కాబట్టి, మొత్తం సిస్టమ్ను మొత్తం నిర్మాణాన్ని మళ్లీ శిక్షణ ఇవ్వాల్సిన అవసరం లేకుండా ముక్కలవారీగా నవీకరించబడుతుంది, ఇది తీవ్రమైన ఓవర్హెడ్ లేకుండా మద్దతు ఇవ్వడానికి అనుమతిస్తుంది.
మోహరించేందుకు
మేము డేటా సేకరణ మరియు వివిధ రకాల నమూనాల అదనపు శిక్షణ గురించి చర్చించాము, కాబట్టి మేము ఉత్పత్తి వాతావరణంలో వాటి విస్తరణకు వెళుతున్నాము.
A/B పరీక్ష
నేను ఇంతకు ముందే చెప్పినట్లుగా, డేటాను సేకరించే ప్రక్రియలో, మేము సాధారణంగా పక్షపాత నమూనాను పొందుతాము, దాని నుండి మోడల్ యొక్క ఉత్పత్తి పనితీరును అంచనా వేయడం అసాధ్యం. అందువల్ల, అమలు చేస్తున్నప్పుడు, వాస్తవానికి విషయాలు ఎలా జరుగుతున్నాయో అర్థం చేసుకోవడానికి మోడల్ను మునుపటి సంస్కరణతో పోల్చాలి, అంటే A/B పరీక్షలను నిర్వహించడం. వాస్తవానికి, చార్ట్లను రోలింగ్ అవుట్ చేయడం మరియు విశ్లేషించడం అనేది చాలా సాధారణమైనది మరియు సులభంగా ఆటోమేట్ చేయబడుతుంది. మోడల్ ప్రతిస్పందనలు మరియు వినియోగదారు ఫీడ్బ్యాక్పై అందుబాటులో ఉన్న అన్ని కొలమానాలను సేకరిస్తూ, మేము మా మోడల్లను క్రమంగా 5%, 30%, 50% మరియు 100% వినియోగదారులకు అందిస్తాము. కొన్ని తీవ్రమైన అవుట్లైయర్ల విషయంలో, మేము స్వయంచాలకంగా మోడల్ను వెనక్కి తీసుకుంటాము మరియు ఇతర సందర్భాల్లో, తగిన సంఖ్యలో వినియోగదారు క్లిక్లను సేకరించిన తర్వాత, మేము శాతాన్ని పెంచాలని నిర్ణయించుకుంటాము. ఫలితంగా, మేము కొత్త మోడల్ను 50% మంది వినియోగదారులకు పూర్తిగా స్వయంచాలకంగా తీసుకువస్తాము మరియు ఈ దశను ఆటోమేట్ చేయగలిగినప్పటికీ, మొత్తం ప్రేక్షకులకు రోల్ అవుట్ ఒక వ్యక్తిచే ఆమోదించబడుతుంది.
అయితే, A/B పరీక్ష ప్రక్రియ ఆప్టిమైజేషన్ కోసం స్థలాన్ని అందిస్తుంది. వాస్తవం ఏమిటంటే ఏదైనా A/B పరీక్ష చాలా పొడవుగా ఉంటుంది (మా విషయంలో ఇది ఫీడ్బ్యాక్ మొత్తాన్ని బట్టి 6 నుండి 24 గంటల వరకు పడుతుంది), ఇది చాలా ఖరీదైనది మరియు పరిమిత వనరులతో ఉంటుంది. అదనంగా, A/B పరీక్ష యొక్క మొత్తం సమయాన్ని తప్పనిసరిగా వేగవంతం చేయడానికి పరీక్ష కోసం తగినంత అధిక శాతం ప్రవాహం అవసరం (కొద్ది శాతంతో కొలమానాలను అంచనా వేయడానికి గణాంకపరంగా ముఖ్యమైన నమూనాను నియమించడం చాలా సమయం పడుతుంది), ఇది చేస్తుంది A/B స్లాట్ల సంఖ్య చాలా పరిమితం. సహజంగానే, మేము చాలా ఆశాజనకమైన మోడళ్లను మాత్రమే పరీక్షించాల్సిన అవసరం ఉంది, వీటిలో అదనపు శిక్షణ ప్రక్రియలో మేము చాలా ఎక్కువ పొందుతాము.
ఈ సమస్యను పరిష్కరించడానికి, మేము A/B పరీక్ష విజయాన్ని అంచనా వేసే ప్రత్యేక వర్గీకరణకు శిక్షణ ఇచ్చాము. దీన్ని చేయడానికి, మేము శిక్షణా సెట్లో, వాయిదా వేసిన వాటిపై మరియు స్ట్రీమ్లోని నమూనాపై నిర్ణయాత్మక గణాంకాలు, ఖచ్చితత్వం, రీకాల్ మరియు ఇతర కొలమానాలను ఫీచర్లుగా తీసుకుంటాము. మేము మోడల్ను ఉత్పత్తిలో ఉన్న ప్రస్తుత మోడల్తో, హ్యూరిస్టిక్లతో పోల్చి చూస్తాము మరియు మోడల్ యొక్క సంక్లిష్టతను పరిగణనలోకి తీసుకుంటాము. ఈ లక్షణాలన్నింటినీ ఉపయోగించి, పరీక్ష చరిత్రపై శిక్షణ పొందిన వర్గీకరణ అభ్యర్థి నమూనాలను మూల్యాంకనం చేస్తుంది, మా విషయంలో ఇవి చెట్ల అడవులు మరియు A/B పరీక్షలో ఏది ఉపయోగించాలో నిర్ణయిస్తుంది.
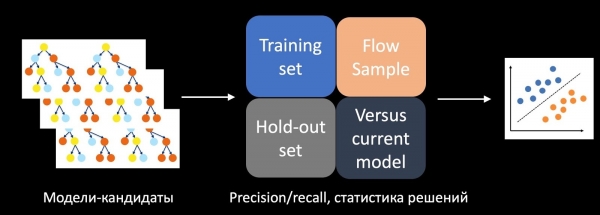
అమలు సమయంలో, ఈ విధానం మాకు విజయవంతమైన A/B పరీక్షల సంఖ్యను అనేక సార్లు పెంచడానికి అనుమతించింది.
టెస్టింగ్ & మానిటరింగ్
పరీక్షించడం మరియు పర్యవేక్షించడం, అసాధారణంగా, మన ఆరోగ్యానికి హాని కలిగించదు; బదులుగా, వారు దానిని మెరుగుపరుస్తారు మరియు అనవసరమైన ఒత్తిడి నుండి ఉపశమనం పొందుతారు. పరీక్ష వైఫల్యాన్ని నిరోధించడానికి మిమ్మల్ని అనుమతిస్తుంది మరియు వినియోగదారులపై ప్రభావాన్ని తగ్గించడానికి పర్యవేక్షణ మిమ్మల్ని సకాలంలో గుర్తించడానికి అనుమతిస్తుంది.
ముందుగానే లేదా తరువాత మీ సిస్టమ్ ఎల్లప్పుడూ తప్పులు చేస్తుందని ఇక్కడ అర్థం చేసుకోవడం ముఖ్యం - ఇది ఏదైనా సాఫ్ట్వేర్ అభివృద్ధి చక్రం కారణంగా ఉంటుంది. సిస్టమ్ డెవలప్మెంట్ ప్రారంభంలో ప్రతిదీ స్థిరపడే వరకు మరియు ఆవిష్కరణ యొక్క ప్రధాన దశ పూర్తయ్యే వరకు ఎల్లప్పుడూ చాలా బగ్లు ఉంటాయి. కానీ కాలక్రమేణా, ఎంట్రోపీ దాని టోల్ తీసుకుంటుంది మరియు లోపాలు మళ్లీ కనిపిస్తాయి - చుట్టూ ఉన్న భాగాల క్షీణత మరియు డేటాలో మార్పుల కారణంగా, నేను ప్రారంభంలో మాట్లాడాను.
ఏదైనా మెషిన్ లెర్నింగ్ సిస్టమ్ దాని మొత్తం జీవిత చక్రంలో దాని లాభం యొక్క కోణం నుండి పరిగణించబడాలని ఇక్కడ నేను గమనించాలనుకుంటున్నాను. దిగువ గ్రాఫ్ అరుదైన రకమైన స్పామ్ను క్యాచ్ చేయడానికి సిస్టమ్ ఎలా పని చేస్తుందో ఉదాహరణ చూపిస్తుంది (గ్రాఫ్లోని పంక్తి సున్నాకి సమీపంలో ఉంది). ఒక రోజు, తప్పుగా కాష్ చేయబడిన లక్షణం కారణంగా, ఆమె పిచ్చిగా మారింది. అదృష్టవశాత్తూ, అసాధారణ ట్రిగ్గరింగ్ కోసం పర్యవేక్షణ లేదు; ఫలితంగా, సిస్టమ్ నిర్ణయాత్మక సరిహద్దు వద్ద ఉన్న "స్పామ్" ఫోల్డర్కు పెద్ద పరిమాణంలో అక్షరాలను సేవ్ చేయడం ప్రారంభించింది. పరిణామాలను సరిదిద్దినప్పటికీ, వ్యవస్థ ఇప్పటికే చాలాసార్లు తప్పులు చేసింది, అది ఐదేళ్లలో కూడా చెల్లించదు. మరియు మోడల్ యొక్క జీవిత చక్రం యొక్క కోణం నుండి ఇది పూర్తి వైఫల్యం.
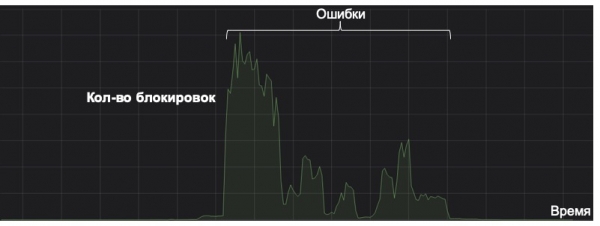
అందువల్ల, పర్యవేక్షణ వంటి సాధారణ విషయం మోడల్ జీవితంలో కీలకం అవుతుంది. ప్రామాణిక మరియు స్పష్టమైన కొలమానాలకు అదనంగా, మేము మోడల్ ప్రతిస్పందనలు మరియు స్కోర్ల పంపిణీని అలాగే కీలక ఫీచర్ విలువల పంపిణీని పరిశీలిస్తాము. KL డైవర్జెన్స్ని ఉపయోగించి, మేము ప్రస్తుత పంపిణీని చారిత్రాత్మకమైన వాటితో లేదా A/B పరీక్షలోని విలువలను మిగిలిన స్ట్రీమ్తో పోల్చవచ్చు, ఇది మోడల్లోని క్రమరాహిత్యాలను గమనించడానికి మరియు సకాలంలో మార్పులను వెనక్కి తీసుకోవడానికి అనుమతిస్తుంది.
చాలా సందర్భాలలో, మేము భవిష్యత్తులో మానిటరింగ్గా ఉపయోగించే సాధారణ హ్యూరిస్టిక్స్ లేదా మోడల్లను ఉపయోగించి మా మొదటి సిస్టమ్ వెర్షన్లను ప్రారంభిస్తాము. ఉదాహరణకు, మేము నిర్దిష్ట ఆన్లైన్ స్టోర్ల కోసం సాధారణ వాటితో పోల్చి NER మోడల్ను పర్యవేక్షిస్తాము మరియు వాటితో పోల్చితే వర్గీకరణ కవరేజ్ తగ్గితే, మేము కారణాలను అర్థం చేసుకుంటాము. హ్యూరిస్టిక్స్ యొక్క మరొక ఉపయోగకరమైన ఉపయోగం!
ఫలితాలు
వ్యాసం యొక్క ముఖ్య ఆలోచనలను మళ్ళీ చూద్దాం.
- ఫిబ్డెక్. మేము ఎల్లప్పుడూ వినియోగదారు గురించి ఆలోచిస్తాము: అతను మన తప్పులతో ఎలా జీవిస్తాడు, అతను వాటిని ఎలా నివేదించగలడు. శిక్షణ నమూనాల కోసం వినియోగదారులు స్వచ్ఛమైన అభిప్రాయానికి మూలం కాదని మర్చిపోవద్దు మరియు సహాయక ML వ్యవస్థల సహాయంతో ఇది క్లియర్ చేయబడాలి. వినియోగదారు నుండి సిగ్నల్ను సేకరించడం సాధ్యం కాకపోతే, మేము ఫీడ్బ్యాక్ యొక్క ప్రత్యామ్నాయ వనరుల కోసం చూస్తాము, ఉదాహరణకు, కనెక్ట్ చేయబడిన సిస్టమ్లు.
- అదనపు శిక్షణ. ఇక్కడ ప్రధాన విషయం కొనసాగింపు, కాబట్టి మేము ప్రస్తుత ఉత్పత్తి నమూనాపై ఆధారపడతాము. హార్మోనిక్ రెగ్యులరైజేషన్ మరియు సారూప్య ట్రిక్స్ కారణంగా మునుపటి వాటి నుండి చాలా తేడా ఉండకుండా ఉండటానికి మేము కొత్త మోడళ్లకు శిక్షణ ఇస్తాము.
- మోహరించేందుకు. కొలమానాల ఆధారంగా ఆటో-డిప్లాయ్మెంట్ మోడల్లను అమలు చేసే సమయాన్ని బాగా తగ్గిస్తుంది. మానిటరింగ్ గణాంకాలు మరియు నిర్ణయం తీసుకునే పంపిణీ, మీ ప్రశాంతమైన నిద్ర మరియు ఉత్పాదక వారాంతంలో వినియోగదారుల నుండి పడిపోయే సంఖ్య తప్పనిసరి.
సరే, ఇది మీ ML సిస్టమ్లను వేగంగా మెరుగుపరచడానికి, వాటిని వేగంగా మార్కెట్లోకి తీసుకురావడానికి మరియు వాటిని మరింత విశ్వసనీయంగా మరియు తక్కువ ఒత్తిడితో కూడినదిగా చేయడానికి మీకు సహాయపడుతుందని నేను ఆశిస్తున్నాను.
మూలం: www.habr.com
