


3. గ్లోబల్స్ ఉపయోగిస్తున్నప్పుడు నిర్మాణాల వైవిధ్యాలు
ఆర్డర్ చేసిన చెట్టు వంటి నిర్మాణం వివిధ ప్రత్యేక సందర్భాలను కలిగి ఉంటుంది. గ్లోబల్స్తో పనిచేసేటప్పుడు ఆచరణాత్మక విలువ కలిగిన వాటిని పరిశీలిద్దాం.
3.1 ప్రత్యేక సందర్భం 1. శాఖలు లేని ఒక నోడ్
 గ్లోబల్లను శ్రేణి లాగా మాత్రమే కాకుండా సాధారణ వేరియబుల్స్ లాగా కూడా ఉపయోగించవచ్చు. ఉదాహరణకు, కౌంటర్గా:
గ్లోబల్లను శ్రేణి లాగా మాత్రమే కాకుండా సాధారణ వేరియబుల్స్ లాగా కూడా ఉపయోగించవచ్చు. ఉదాహరణకు, కౌంటర్గా:
Set ^counter = 0 ; установка счётчика
Set id=$Increment(^counter) ; атомарное инкрементированиеఈ సందర్భంలో, గ్లోబల్, దాని అర్థంతో పాటు, శాఖలను కూడా కలిగి ఉంటుంది. ఒకటి మరొకటి మినహాయించదు.
3.2 ప్రత్యేక సందర్భం 2. ఒక శీర్షం మరియు అనేక శాఖలు
సాధారణంగా, ఇది క్లాసిక్ కీ-వాల్యూ బేస్. మరియు మేము ఒక టుపుల్ విలువలను విలువగా సేవ్ చేస్తే, మేము ప్రాథమిక కీతో చాలా సాధారణ పట్టికను పొందుతాము.
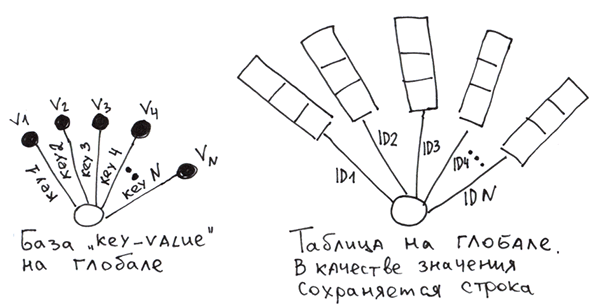
గ్లోబల్స్పై పట్టికను అమలు చేయడానికి, నిలువు వరుసల విలువల నుండి మనమే అడ్డు వరుసలను రూపొందించాలి, ఆపై వాటిని ప్రాథమిక కీని ఉపయోగించి గ్లోబల్కు సేవ్ చేయాలి. చదివేటప్పుడు స్ట్రింగ్ను మళ్లీ నిలువు వరుసలుగా విభజించడం సాధ్యం చేయడానికి, మీరు వీటిని ఉపయోగించవచ్చు:
- డీలిమిటర్ అక్షరాలు.
Set ^t(id1) = "col11/col21/col31" Set ^t(id2) = "col12/col22/col32" - ప్రతి ఫీల్డ్ ముందుగా నిర్ణయించిన బైట్ల సంఖ్యను ఆక్రమించే దృఢమైన పథకం. రిలేషనల్ డేటాబేస్లలో చేసినట్లుగా.
- ఒక ప్రత్యేక ఫంక్షన్ $LB (కాష్లో అందుబాటులో ఉంది), ఇది విలువల స్ట్రింగ్ను సృష్టిస్తుంది.
Set ^t(id1) = $LB("col11", "col21", "col31") Set ^t(id2) = $LB("col12", "col22", "col32")
ఆసక్తికరంగా, రిలేషనల్ డేటాబేస్లలో సెకండరీ ఇండెక్స్ల మాదిరిగా ఏదైనా చేయడానికి గ్లోబల్లను ఉపయోగించడం కష్టం కాదు. అలాంటి నిర్మాణాలను ఇండెక్స్ గ్లోబల్స్ అంటాం. ఇండెక్స్ గ్లోబల్ అనేది మెయిన్ గ్లోబల్ యొక్క ప్రాధమిక కీలో భాగం కాని ఫీల్డ్లను త్వరగా శోధించడానికి ఒక సహాయక చెట్టు. దాన్ని పూరించడానికి మరియు ఉపయోగించడానికి, మీరు అదనపు కోడ్ రాయాలి.
మొదటి కాలమ్లో గ్లోబల్ ఇండెక్స్ని క్రియేట్ చేద్దాం.
Set ^i("col11", id1) = 1
Set ^i("col12", id2) = 1ఇప్పుడు, మొదటి కాలమ్లో సమాచారాన్ని త్వరగా శోధించడానికి, మనం ప్రపంచాన్ని చూడాలి ^i మరియు మొదటి నిలువు వరుస యొక్క కావలసిన విలువకు సంబంధించిన ప్రాథమిక కీలను (id) కనుగొనండి.
విలువను చొప్పించినప్పుడు, అవసరమైన ఫీల్డ్ల కోసం మేము వెంటనే విలువ మరియు ఇండెక్స్ గ్లోబల్లు రెండింటినీ సృష్టించవచ్చు. మరియు విశ్వసనీయత కోసం, అన్నింటినీ లావాదేవీలో చుట్టుదాం.
TSTART
Set ^t(id1) = $LB("col11", "col21", "col31")
Set ^i("col11", id1) = 1
TCOMMITM లో ఎలా చేయాలో వివరాలు , .
వరుసలను చొప్పించడం/నవీకరించడం/తొలగించడం కోసం విధులు COS/Mలో వ్రాసి, కంపైల్ చేయబడితే, అటువంటి పట్టికలు సాంప్రదాయ డేటాబేస్ల వలె (లేదా మరింత వేగంగా) పని చేస్తాయి.నేను TSTART మరియు TCOMMIT ఆదేశాలను (లావాదేవీలు) ఉపయోగించడంతో సహా బల్క్ ఇన్సర్ట్ మరియు SELECT అనే పరీక్షలతో ఒక రెండు-నిలువు వరుసల పట్టికలో ఈ ప్రకటనను తనిఖీ చేసాను.
నేను ఏకకాల యాక్సెస్ మరియు సమాంతర లావాదేవీలతో మరింత క్లిష్టమైన దృశ్యాలను పరీక్షించలేదు.
లావాదేవీలను ఉపయోగించకుండా, చొప్పించే రేటు మిలియన్ విలువలకు 778 ఇన్సర్ట్లు/సెకండ్.
300 మిలియన్ విలువలతో - 422 ఇన్సర్ట్లు/సెకను.
లావాదేవీలను ఉపయోగిస్తున్నప్పుడు - 572M ఇన్సర్ట్లకు 082 ఇన్సర్ట్లు/సెకను. అన్ని కార్యకలాపాలు కంపైల్ చేసిన M కోడ్ నుండి జరిగాయి.
హార్డ్ డ్రైవ్లు సాధారణమైనవి, SSD కాదు. RAID5 రైట్-బ్యాక్తో. ఫెనోమ్ II 1100T ప్రాసెసర్.
ఇదే విధంగా SQL డేటాబేస్ను పరీక్షించడానికి, మీరు లూప్లో ఇన్సర్షన్లను నిర్వహించే నిల్వ చేసిన విధానాన్ని వ్రాయాలి. MySQL 5.5 (InnoDB నిల్వ)ని పరీక్షిస్తున్నప్పుడు, ఈ పద్ధతిని ఉపయోగించి నేను సెకనుకు 11K ఇన్సర్ట్ల కంటే ఎక్కువ సంఖ్యలను పొందలేదు.
అవును, గ్లోబల్స్లో టేబుల్ల అమలు రిలేషనల్ డేటాబేస్ల కంటే చాలా క్లిష్టంగా కనిపిస్తుంది. అందువల్ల, గ్లోబల్స్లోని పారిశ్రామిక డేటాబేస్లు పట్టిక డేటాతో పనిని సులభతరం చేయడానికి SQL యాక్సెస్ను కలిగి ఉంటాయి.
 సాధారణంగా, డేటా స్కీమా తరచుగా మారకపోతే, చొప్పించే వేగం క్లిష్టమైనది కాదు మరియు మొత్తం డేటాబేస్ సాధారణీకరించిన పట్టికల రూపంలో సులభంగా సూచించబడుతుంది, అప్పుడు SQLతో పని చేయడం సులభం, ఎందుకంటే ఇది అధిక స్థాయి సంగ్రహణను అందిస్తుంది. .
సాధారణంగా, డేటా స్కీమా తరచుగా మారకపోతే, చొప్పించే వేగం క్లిష్టమైనది కాదు మరియు మొత్తం డేటాబేస్ సాధారణీకరించిన పట్టికల రూపంలో సులభంగా సూచించబడుతుంది, అప్పుడు SQLతో పని చేయడం సులభం, ఎందుకంటే ఇది అధిక స్థాయి సంగ్రహణను అందిస్తుంది. .
 ఈ ప్రత్యేక సందర్భంలో నేను దానిని చూపించాలనుకున్నాను గ్లోబల్స్ ఇతర డేటాబేస్లను రూపొందించడానికి కన్స్ట్రక్టర్గా పని చేయవచ్చు. ఇతర భాషలను వ్రాయగలిగే అసెంబ్లర్ లాగా. మీరు గ్లోబల్స్లో అనలాగ్లను ఎలా సృష్టించవచ్చో ఇక్కడ ఉదాహరణలు ఉన్నాయి
ఈ ప్రత్యేక సందర్భంలో నేను దానిని చూపించాలనుకున్నాను గ్లోబల్స్ ఇతర డేటాబేస్లను రూపొందించడానికి కన్స్ట్రక్టర్గా పని చేయవచ్చు. ఇతర భాషలను వ్రాయగలిగే అసెంబ్లర్ లాగా. మీరు గ్లోబల్స్లో అనలాగ్లను ఎలా సృష్టించవచ్చో ఇక్కడ ఉదాహరణలు ఉన్నాయి
మీరు కనీస ప్రయత్నంతో ఒక రకమైన ప్రామాణికం కాని డేటాబేస్ను సృష్టించవలసి వస్తే, మీరు గ్లోబల్స్ వైపు చూడాలి.
3.3 ప్రత్యేక సందర్భం 3. రెండు-స్థాయి చెట్టు, రెండవ స్థాయి యొక్క ప్రతి నోడ్ స్థిర సంఖ్యలో శాఖలను కలిగి ఉంటుంది
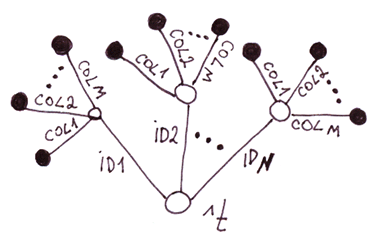 మీరు బహుశా ఊహించి ఉండవచ్చు: ఇది గ్లోబల్స్లో పట్టికల యొక్క ప్రత్యామ్నాయ అమలు. ఈ అమలును మునుపటి దానితో పోల్చి చూద్దాం.
మీరు బహుశా ఊహించి ఉండవచ్చు: ఇది గ్లోబల్స్లో పట్టికల యొక్క ప్రత్యామ్నాయ అమలు. ఈ అమలును మునుపటి దానితో పోల్చి చూద్దాం.
రెండు-స్థాయి చెట్టుపై పట్టికలు vs. ఒకే-స్థాయి చెట్టు మీద.
Минусы
Плюсы
- చొప్పించడం కోసం నెమ్మదిగా, మీరు నిలువు వరుసల సంఖ్యకు సమానమైన నోడ్ల సంఖ్యను సెట్ చేయాలి.
- మరింత డిస్క్ స్పేస్ వినియోగం. కాలమ్ పేర్లతో ఉన్న గ్లోబల్ ఇండెక్స్లు (అర్రే ఇండెక్స్లుగా అర్థం చేసుకోవడం) డిస్క్ స్థలాన్ని ఆక్రమిస్తాయి మరియు ప్రతి అడ్డు వరుసకు నకిలీ చేయబడతాయి.
- స్ట్రింగ్ను అన్వయించాల్సిన అవసరం లేనందున, వ్యక్తిగత నిలువు వరుసల విలువలకు వేగవంతమైన ప్రాప్యత. నా పరీక్షల ప్రకారం, ఇది 11,5 నిలువు వరుసలలో 2% వేగంగా ఉంటుంది మరియు పెద్ద సంఖ్యలో నిలువు వరుసలలో ఎక్కువ.
- డేటా స్కీమాను మార్చడం సులభం
- మరింత స్పష్టమైన కోడ్
తీర్మానం: అందరికీ కాదు. గ్లోబల్ల యొక్క అత్యంత కీలక ప్రయోజనాల్లో వేగం ఒకటి కాబట్టి, ఈ అమలును ఉపయోగించడంలో పెద్దగా ప్రయోజనం లేదు, ఎందుకంటే ఇది రిలేషనల్ డేటాబేస్లలోని పట్టికల కంటే వేగంగా పని చేయదు.
3.4 సాధారణ కేసు. చెట్లు మరియు ఆర్డర్ చెట్లు
చెట్టుగా సూచించబడే ఏదైనా డేటా నిర్మాణం గ్లోబల్లకు సరిగ్గా సరిపోతుంది.
3.4.1 సబ్జెక్ట్లతో కూడిన వస్తువులు
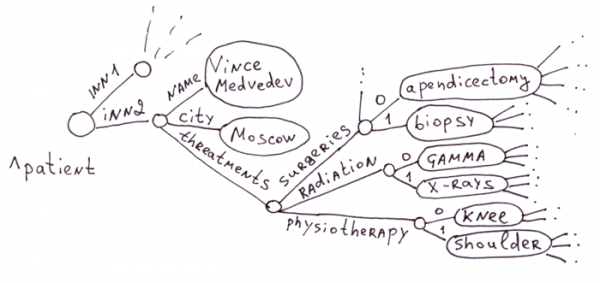
ఇది గ్లోబల్స్ యొక్క సాంప్రదాయ ఉపయోగం యొక్క ప్రాంతం. వైద్య రంగంలో వ్యాధులు, మందులు, లక్షణాలు మరియు చికిత్సా పద్ధతులు భారీ సంఖ్యలో ఉన్నాయి. ప్రతి రోగికి మిలియన్ ఫీల్డ్లతో పట్టికను రూపొందించడం అహేతుకం. అంతేకాకుండా, 99% ఫీల్డ్లు ఖాళీగా ఉంటాయి.
పట్టికల SQL డేటాబేస్ను ఊహించండి: “రోగి” ~ 100 ఫీల్డ్లు, “మెడిసిన్” - 000 ఫీల్డ్లు, “థెరపీ” - 100 ఫీల్డ్లు, “క్లిష్టాలు” - 000 ఫీల్డ్లు మొదలైనవి. మరియు అందువలన న. లేదా మీరు అనేక వేల పట్టికల డేటాబేస్ను సృష్టించవచ్చు, ఒక్కొక్కటి నిర్దిష్ట రకం రోగి కోసం (మరియు అవి అతివ్యాప్తి చెందుతాయి!), చికిత్సలు, మందులు మరియు ఈ టేబుల్ల మధ్య కనెక్షన్ల కోసం మరిన్ని వేల పట్టికలు.
గ్లోబల్స్ వైద్యానికి అనువైనవి, ఎందుకంటే అవి ప్రతి రోగికి అతని వైద్య చరిత్ర, వివిధ చికిత్సలు మరియు మందుల చర్యల గురించి ఖచ్చితమైన వివరణను, చెట్టు రూపంలో, ఖాళీ కాలమ్లపై అదనపు డిస్క్ స్థలాన్ని వృధా చేయకుండా, సృష్టించడానికి మిమ్మల్ని అనుమతిస్తాయి. రిలేషనల్ కేసులో అలానే ఉంటుంది.
 గ్లోబల్స్ ఉపయోగించి వ్యక్తుల గురించి డేటాతో డేటాబేస్ను సృష్టించడం సౌకర్యంగా ఉంటుంది, క్లయింట్ గురించి గరిష్టంగా వివిధ సమాచారాన్ని సేకరించడం మరియు క్రమబద్ధీకరించడం చాలా ముఖ్యమైనది. మెడిసిన్, బ్యాంకింగ్, మార్కెటింగ్, ఆర్కైవింగ్ మరియు ఇతర రంగాలలో దీనికి డిమాండ్ ఉంది
గ్లోబల్స్ ఉపయోగించి వ్యక్తుల గురించి డేటాతో డేటాబేస్ను సృష్టించడం సౌకర్యంగా ఉంటుంది, క్లయింట్ గురించి గరిష్టంగా వివిధ సమాచారాన్ని సేకరించడం మరియు క్రమబద్ధీకరించడం చాలా ముఖ్యమైనది. మెడిసిన్, బ్యాంకింగ్, మార్కెటింగ్, ఆర్కైవింగ్ మరియు ఇతర రంగాలలో దీనికి డిమాండ్ ఉంది
.
వాస్తవానికి, SQLలో మీరు కొన్ని పట్టికలతో చెట్టును కూడా అనుకరించవచ్చు (, ,,,,,,,,,), అయితే ఇది చాలా క్లిష్టంగా ఉంటుంది మరియు నెమ్మదిగా ఉంటుంది. ముఖ్యంగా, మీరు టేబుల్లపై పనిచేసే గ్లోబల్ను వ్రాయాలి మరియు అన్ని పనిని టేబుల్లతో అబ్స్ట్రాక్షన్ లేయర్ కింద దాచాలి. ఉన్నత స్థాయి సాంకేతికతను (SQL) ఉపయోగించి దిగువ స్థాయి సాంకేతికతను (గ్లోబల్స్) అనుకరించడం తప్పు. తగనిది.
జెయింట్ టేబుల్స్ (ALTER TABLE)లో డేటా స్కీమాను మార్చడానికి తగిన సమయం పట్టవచ్చు అనేది రహస్యం కాదు. ఉదాహరణకు, MySQL, పాత టేబుల్ నుండి సమాచారాన్ని పూర్తిగా కొత్త టేబుల్కి కాపీ చేయడం ద్వారా ALTER TABLE ADD|DROP COLUMN చేస్తుంది (పరీక్షించిన MyISAM, InnoDB ఇంజిన్లు). ఇది పని చేసే డేటాబేస్ను బిలియన్ల కొద్దీ రికార్డులతో రోజుల పాటు, వారాలు కాకపోయినా హ్యాంగ్ అప్ చేయగలదు.
 మనం గ్లోబల్స్ని ఉపయోగిస్తే డేటా స్ట్రక్చర్ని మార్చడం వల్ల మనకు ఏమీ ఖర్చు ఉండదు. ఏ సమయంలోనైనా మనకు అవసరమైన ఏదైనా కొత్త లక్షణాలను జోడించవచ్చు. బ్రాంచ్ల పేరు మార్చడంతో అనుబంధించబడిన మార్పులు నడుస్తున్న డేటాబేస్లో నేపథ్యంలో అమలు చేయబడతాయి.
మనం గ్లోబల్స్ని ఉపయోగిస్తే డేటా స్ట్రక్చర్ని మార్చడం వల్ల మనకు ఏమీ ఖర్చు ఉండదు. ఏ సమయంలోనైనా మనకు అవసరమైన ఏదైనా కొత్త లక్షణాలను జోడించవచ్చు. బ్రాంచ్ల పేరు మార్చడంతో అనుబంధించబడిన మార్పులు నడుస్తున్న డేటాబేస్లో నేపథ్యంలో అమలు చేయబడతాయి.
అందువల్ల, భారీ సంఖ్యలో ఐచ్ఛిక లక్షణాలతో వస్తువులను నిల్వ చేయడానికి వచ్చినప్పుడు, గ్లోబల్స్ గొప్ప ఎంపిక.
అంతేకాకుండా, గ్లోబల్లో అన్ని మార్గాలు B-ట్రీలు అయినందున, ఏదైనా ప్రాపర్టీలకు యాక్సెస్ తక్షణమే అని నేను మీకు గుర్తు చేస్తున్నాను.
గ్లోబల్ డేటాబేస్లు, సాధారణంగా, క్రమానుగత సమాచారాన్ని నిల్వ చేయగల సామర్థ్యంతో కూడిన ఒక రకమైన డాక్యుమెంట్-ఆధారిత డేటాబేస్. అందువల్ల, డాక్యుమెంట్-ఆధారిత డేటాబేస్లు వైద్య రికార్డులను నిల్వ చేసే రంగంలో గ్లోబల్లతో పోటీ పడగలవు. కానీ అది ఇప్పటికీ ఒకేలా లేదుపోలిక కోసం మొంగోడిబిని తీసుకుందాం. ఈ డొమైన్లో ఇది క్రింది కారణాల వల్ల గ్లోబల్స్కు కోల్పోతుంది:
- పత్రం పరిమాణం. నిల్వ యూనిట్ గరిష్టంగా 16MB వాల్యూమ్తో JSON ఆకృతిలో (మరింత ఖచ్చితంగా BSON) వచనం. JSON డేటాబేస్ ఒక భారీ JSON డాక్యుమెంట్లో నిల్వ చేయబడి, ఆపై ఫీల్డ్ల ద్వారా యాక్సెస్ చేయబడితే, పార్సింగ్ సమయంలో అది నెమ్మదించకుండా ఉండేలా పరిమితి ప్రత్యేకంగా రూపొందించబడింది. ఈ పత్రం రోగికి సంబంధించిన మొత్తం సమాచారాన్ని కలిగి ఉండాలి. రోగి రికార్డులు ఎంత మందంగా ఉంటాయో మనందరికీ తెలుసు. 16MB గరిష్ట కార్డ్ పరిమాణం MRI ఫైల్లు, X-రే స్కాన్లు మరియు ఇతర అధ్యయనాలను కలిగి ఉన్న రోగులకు తక్షణమే ముగింపునిస్తుంది. గ్లోబల్లోని ఒక శాఖలో మీరు గిగాబైట్లు మరియు టెరాబైట్ల సమాచారాన్ని కలిగి ఉండవచ్చు. సూత్రప్రాయంగా, మేము దీనిని అంతం చేయవచ్చు, కానీ నేను కొనసాగిస్తాను.
- రోగి యొక్క చార్ట్లో స్పృహ/మార్పు/కొత్త లక్షణాల తొలగింపు సమయం. అటువంటి డేటాబేస్ తప్పనిసరిగా మొత్తం మ్యాప్ను మెమరీలోకి చదవాలి (ఇది పెద్ద మొత్తం!), BSONని అన్వయించండి, కొత్త నోడ్ను జోడించడం/మార్చడం/తొలగించడం, సూచికలను నవీకరించడం, BSONలో ప్యాక్ చేయడం మరియు దానిని డిస్క్లో సేవ్ చేయడం. ఒక గ్లోబల్ నిర్దిష్ట ఆస్తిని మాత్రమే యాక్సెస్ చేయాలి మరియు దానిని మార్చవలసి ఉంటుంది.
- వ్యక్తిగత లక్షణాలకు త్వరిత ప్రాప్యత. డాక్యుమెంట్లోని అనేక లక్షణాలు మరియు దాని బహుళ-స్థాయి నిర్మాణంతో, గ్లోబల్లోని ప్రతి మార్గం B-ట్రీ అయినందున వ్యక్తిగత లక్షణాలకు ప్రాప్యత వేగంగా ఉంటుంది. BSONలో, మీరు కోరుకున్న ఆస్తిని కనుగొనడానికి పత్రాన్ని సరళంగా అన్వయించాలి.
3.3.2 అనుబంధ శ్రేణులు
అనుబంధ శ్రేణులు (నెస్టెడ్ శ్రేణులతో కూడా) గ్లోబల్లకు సరిగ్గా సరిపోతాయి. ఉదాహరణకు, PHP నుండి అటువంటి శ్రేణి మొదటి చిత్రం 3.3.1లో ప్రదర్శించబడుతుంది.
$a = array(
"name" => "Vince Medvedev",
"city" => "Moscow",
"threatments" => array(
"surgeries" => array("apedicectomy", "biopsy"),
"radiation" => array("gamma", "x-rays"),
"physiotherapy" => array("knee", "shoulder")
)
);3.3.3 క్రమానుగత పత్రాలు: XML, JSON
గ్లోబల్స్లో కూడా సులభంగా నిల్వ చేయబడుతుంది. నిల్వ కోసం వివిధ మార్గాల్లో వేయవచ్చు.
XML
XMLని గ్లోబల్లుగా విడదీయడానికి సులభమైన మార్గం నోడ్లలో ట్యాగ్ అట్రిబ్యూట్లను నిల్వ చేయడం. మరియు ట్యాగ్ అట్రిబ్యూట్లకు శీఘ్ర ప్రాప్యత అవసరమైతే, మేము వాటిని ప్రత్యేక బ్రాంచ్లలోకి తరలించవచ్చు.
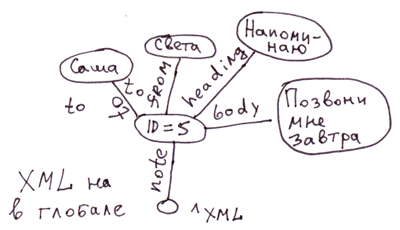
<note id=5>
<to>Вася</to>
<from>Света</from>
<heading>Напоминание</heading>
<body>Позвони мне завтра!</body>
</note>COSలో ఇది కోడ్కు అనుగుణంగా ఉంటుంది:
Set ^xml("note")="id=5"
Set ^xml("note","to")="Саша"
Set ^xml("note","from")="Света"
Set ^xml("note","heading")="Напоминание"
Set ^xml("note","body")="Позвони мне завтра!"వ్యాఖ్య: XML, JSON, అనుబంధ శ్రేణుల కోసం, మీరు గ్లోబల్స్లో ప్రదర్శించడానికి అనేక విభిన్న మార్గాలతో రావచ్చు. ఈ సందర్భంలో, మేము నోట్ ట్యాగ్లోని సబ్ట్యాగ్ల క్రమాన్ని ప్రతిబింబించలేదు. ప్రపంచవ్యాప్తంగా ^xml సబ్ట్యాగ్లు అక్షర క్రమంలో ప్రదర్శించబడతాయి. క్రమాన్ని ఖచ్చితంగా ప్రతిబింబించడానికి, మీరు క్రింది ప్రదర్శనను ఉపయోగించవచ్చు, ఉదాహరణకు:
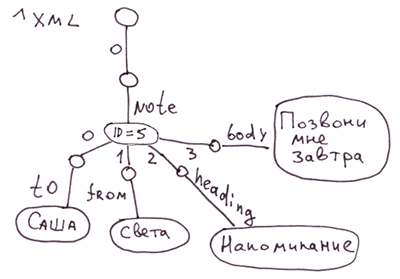
JSON.
విభాగం 3.3.1 నుండి మొదటి చిత్రం ఈ JSON పత్రం యొక్క ప్రతిబింబాన్ని చూపుతుంది:
var document = {
"name": "Vince Medvedev",
"city": "Moscow",
"threatments": {
"surgeries": ["apedicectomy", "biopsy"],
"radiation": ["gamma", "x-rays"],
"physiotherapy": ["knee", "shoulder"]
},
};3.3.4 క్రమానుగత సంబంధాల ద్వారా అనుసంధానించబడిన ఒకే విధమైన నిర్మాణాలు
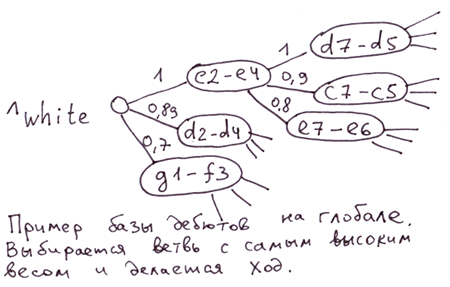
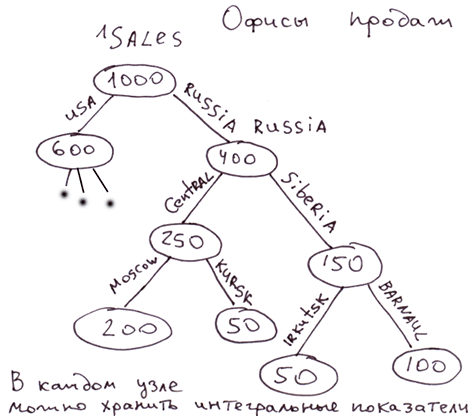
ఉదాహరణలు: విక్రయ కార్యాలయాల నిర్మాణం, MLM నిర్మాణంలో వ్యక్తుల స్థానం, చెస్లో ఓపెనింగ్ల డేటాబేస్.
డెబ్యూస్ డేటాబేస్. మీరు గ్లోబల్ నోడ్ యొక్క సూచిక విలువగా స్ట్రోక్ ఫోర్స్ అంచనాను ఉపయోగించవచ్చు. అప్పుడు, బలమైన కదలికను ఎంచుకోవడానికి, అత్యధిక బరువుతో శాఖను ఎంచుకోవడానికి సరిపోతుంది. గ్లోబల్లో, ప్రతి స్థాయిలోని అన్ని శాఖలు కదలిక బలం ద్వారా క్రమబద్ధీకరించబడతాయి.
విక్రయ కార్యాలయాల నిర్మాణం, MLM లో ప్రజల నిర్మాణం. నోడ్లు మొత్తం సబ్ట్రీ లక్షణాలను ప్రతిబింబించే నిర్దిష్ట కాషింగ్ విలువలను నిల్వ చేయగలవు. ఉదాహరణకు, ఇచ్చిన సబ్ట్రీ అమ్మకాల పరిమాణం. ఏ క్షణంలోనైనా మనం ఏదైనా శాఖ సాధించిన విజయాలను ప్రతిబింబించే బొమ్మను పొందవచ్చు.
4. ఏ సందర్భాలలో గ్లోబల్స్ ఉపయోగించడం చాలా ప్రయోజనకరంగా ఉంటుంది?
మొదటి కాలమ్ మీరు గ్లోబల్లను ఉపయోగించడం ద్వారా గణనీయమైన వేగాన్ని పొందగల సందర్భాలను ప్రదర్శిస్తుంది మరియు రెండవది డిజైన్ లేదా డేటా మోడల్ సరళీకృతం చేయబడినప్పుడు.
వేగం
డేటా ప్రాసెసింగ్/ప్రెజెంటేషన్ సౌలభ్యం
- చొప్పించడం [ప్రతి స్థాయిలో ఆటోమేటిక్ సార్టింగ్తో], [మాస్టర్ కీ ద్వారా ఇండెక్సింగ్]
- సబ్ట్రీలను తొలగిస్తోంది
- వ్యక్తిగత యాక్సెస్ అవసరమయ్యే అనేక సమూహ లక్షణాలతో ఉన్న వస్తువులు
- ఏ శాఖ నుండి అయినా, ఉనికిలో లేని పిల్లల శాఖలను దాటవేయగల సామర్థ్యంతో క్రమానుగత నిర్మాణం
- సబ్ట్రీల లోతు-మొదటి ప్రయాణం
- భారీ సంఖ్యలో ఐచ్ఛిక [మరియు/లేదా సమూహ] లక్షణాలు/ఎంటిటీలు కలిగిన వస్తువులు/ఎంటిటీలు
- స్కీమా-తక్కువ డేటా. కొత్త లక్షణాలు తరచుగా కనిపించినప్పుడు మరియు పాతవి అదృశ్యమైనప్పుడు.
- మీరు కస్టమ్ డేటాబేస్ సృష్టించాలి.
- మార్గం స్థావరాలు మరియు నిర్ణయం చెట్లు. మార్గాలను చెట్టుగా సూచించడం సౌకర్యంగా ఉన్నప్పుడు.
- పునరావృత్తిని ఉపయోగించకుండా క్రమానుగత నిర్మాణాలను తీసివేయడం
పొడిగింపు .
నిరాకరణ: ఈ కథనం మరియు దానికి నా వ్యాఖ్యలు నా అభిప్రాయం మరియు ఇంటర్సిస్టమ్స్ కార్పొరేషన్ యొక్క అధికారిక స్థానానికి ఎటువంటి సంబంధం లేదు.
మూలం: www.habr.com
