

పోస్ట్గ్రెస్ డేటాబేస్ను పూర్తి కార్యాచరణకు పునరుద్ధరించడంలో నా మొదటి విజయవంతమైన అనుభవాన్ని మీతో పంచుకోవాలనుకుంటున్నాను. పోస్ట్గ్రెస్ DBMSతో నాకు అర్ధ సంవత్సరం క్రితం పరిచయం ఏర్పడింది; అంతకు ముందు నాకు డేటాబేస్ పరిపాలనలో అనుభవం లేదు.

నేను ఒక పెద్ద IT కంపెనీలో సెమీ-DevOps ఇంజనీర్గా పని చేస్తున్నాను. మా కంపెనీ అధిక-లోడ్ సేవల కోసం సాఫ్ట్వేర్ను అభివృద్ధి చేస్తుంది మరియు పనితీరు, నిర్వహణ మరియు విస్తరణకు నేను బాధ్యత వహిస్తాను. నాకు ఒక ప్రామాణిక టాస్క్ ఇవ్వబడింది: ఒక సర్వర్లో అప్లికేషన్ను అప్డేట్ చేయడం. అప్లికేషన్ జంగోలో వ్రాయబడింది, నవీకరణ సమయంలో మైగ్రేషన్లు నిర్వహించబడతాయి (డేటాబేస్ నిర్మాణంలో మార్పులు), మరియు ఈ ప్రక్రియకు ముందు మేము ప్రామాణిక pg_dump ప్రోగ్రామ్ ద్వారా పూర్తి డేటాబేస్ డంప్ను తీసుకుంటాము.
డంప్ను తీసుకుంటున్నప్పుడు ఊహించని లోపం సంభవించింది (పోస్ట్గ్రెస్ వెర్షన్ 9.5):
pg_dump: Oumping the contents of table “ws_log_smevlog” failed: PQgetResult() failed.
pg_dump: Error message from server: ERROR: invalid page in block 4123007 of relatton base/16490/21396989
pg_dump: The command was: COPY public.ws_log_smevlog [...]
pg_dunp: [parallel archtver] a worker process dled unexpectedly లోపం "బ్లాక్లో చెల్లని పేజీ" ఫైల్ సిస్టమ్ స్థాయిలో సమస్యల గురించి మాట్లాడుతుంది, ఇది చాలా చెడ్డది. వివిధ వేదికలపై చేయాలని సూచించారు పూర్తి వాక్యూమ్ ఎంపికతో zero_damaged_pages ఈ సమస్యను పరిష్కరించడానికి. సరే, ప్రయత్నిద్దాం...
రికవరీ కోసం సిద్ధమవుతోంది
హెచ్చరిక! మీ డేటాబేస్ని పునరుద్ధరించడానికి ఏదైనా ప్రయత్నానికి ముందు పోస్ట్గ్రెస్ బ్యాకప్ తీసుకోవాలని నిర్ధారించుకోండి. మీకు వర్చువల్ మెషీన్ ఉంటే, డేటాబేస్ను ఆపి, స్నాప్షాట్ తీసుకోండి. స్నాప్షాట్ తీయడం సాధ్యం కాకపోతే, డేటాబేస్ను ఆపివేసి, పోస్ట్గ్రెస్ డైరెక్టరీలోని కంటెంట్లను (వాల్ ఫైల్లతో సహా) సురక్షిత ప్రదేశానికి కాపీ చేయండి. మా వ్యాపారంలో ప్రధాన విషయం విషయాలు మరింత దిగజారడం కాదు. చదవండి .
డేటాబేస్ సాధారణంగా నా కోసం పనిచేసినందున, నేను సాధారణ డేటాబేస్ డంప్కి పరిమితం చేసాను, కానీ దెబ్బతిన్న డేటాతో పట్టికను మినహాయించాను (ఎంపిక -T, --exclude-table=టేబుల్ pg_dumpలో).
సర్వర్ భౌతికమైనది, స్నాప్షాట్ తీయడం అసాధ్యం. బ్యాకప్ తీసివేయబడింది, ముందుకు వెళ్దాం.
ఫైల్ సిస్టమ్ తనిఖీ
డేటాబేస్ను పునరుద్ధరించడానికి ప్రయత్నించే ముందు, ఫైల్ సిస్టమ్తో ప్రతిదీ సరిగ్గా ఉందని మేము నిర్ధారించుకోవాలి. మరియు తప్పుల విషయంలో, వాటిని సరిదిద్దండి, లేకపోతే మీరు విషయాలను మరింత దిగజార్చవచ్చు.
నా విషయంలో, డేటాబేస్తో ఫైల్ సిస్టమ్ మౌంట్ చేయబడింది "/srv" మరియు రకం ext4.
డేటాబేస్ను ఆపడం: systemctl స్టాప్ postgresql@9.5-main.service మరియు ఫైల్ సిస్టమ్ ఎవరికీ ఉపయోగంలో లేదని మరియు ఆదేశాన్ని ఉపయోగించి అన్మౌంట్ చేయవచ్చని తనిఖీ చేయండి lsof:
lsof +D / srv
నేను కూడా redis డేటాబేస్ని ఆపివేయవలసి వచ్చింది, ఎందుకంటే అది కూడా ఉపయోగిస్తోంది "/srv". తర్వాత నేను అన్మౌంట్ చేసాను / srv (అమౌంట్).
ఫైల్ సిస్టమ్ యుటిలిటీని ఉపయోగించి తనిఖీ చేయబడింది e2fsck స్విచ్ -f తో (ఫైల్సిస్టమ్ క్లీన్గా మార్క్ చేయబడినప్పటికీ బలవంతంగా తనిఖీ చేస్తుంది):
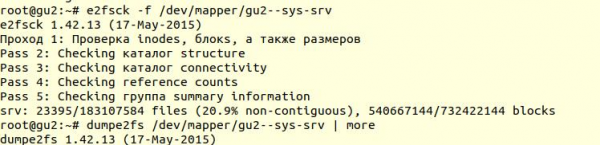
తరువాత, యుటిలిటీని ఉపయోగించడం dumpe2fs (sudo dumpe2fs /dev/mapper/gu2—sys-srv | grep తనిఖీ చేయబడింది) తనిఖీ నిజంగా జరిగిందని మీరు ధృవీకరించవచ్చు:

e2fsck ext4 ఫైల్ సిస్టమ్ స్థాయిలో సమస్యలు ఏవీ కనుగొనబడలేదు, అంటే మీరు డేటాబేస్ను పునరుద్ధరించడానికి ప్రయత్నించడం కొనసాగించవచ్చు లేదా దానికి తిరిగి వెళ్లవచ్చు వాక్యూమ్ పూర్తి (వాస్తవానికి, మీరు ఫైల్ సిస్టమ్ను తిరిగి మౌంట్ చేయాలి మరియు డేటాబేస్ను ప్రారంభించాలి).
మీకు భౌతిక సర్వర్ ఉంటే, డిస్క్ల స్థితిని తనిఖీ చేయండి (ద్వారా smartctl -a /dev/XXX) లేదా సమస్య హార్డ్వేర్ స్థాయిలో లేదని నిర్ధారించుకోవడానికి RAID కంట్రోలర్. నా విషయంలో, RAID "హార్డ్వేర్" అని తేలింది, కాబట్టి నేను RAID స్థితిని తనిఖీ చేయమని స్థానిక నిర్వాహకుడిని అడిగాను (సర్వర్ నా నుండి అనేక వందల కిలోమీటర్ల దూరంలో ఉంది). ఎటువంటి లోపాలు లేవని, అంటే మనం ఖచ్చితంగా పునరుద్ధరణ ప్రారంభించగలమని ఆయన అన్నారు.
ప్రయత్నం 1: zero_damaged_pages
సూపర్యూజర్ హక్కులను కలిగి ఉన్న ఖాతాతో మేము psql ద్వారా డేటాబేస్కు కనెక్ట్ చేస్తాము. మాకు సూపర్యూజర్ కావాలి, ఎందుకంటే... ఎంపిక zero_damaged_pages అతను మాత్రమే మార్చగలడు. నా విషయంలో ఇది postgres:
psql -h 127.0.0.1 -U postgres -s [డేటాబేస్_పేరు]
ఎంపిక zero_damaged_pages చదివిన లోపాలను విస్మరించడానికి అవసరం (postgrespro వెబ్సైట్ నుండి):
PostgreSQL పాడైన పేజీ హెడర్ను గుర్తించినప్పుడు, ఇది సాధారణంగా లోపాన్ని నివేదిస్తుంది మరియు ప్రస్తుత లావాదేవీని నిలిపివేస్తుంది. zero_damaged_pages ప్రారంభించబడితే, సిస్టమ్ బదులుగా హెచ్చరికను జారీ చేస్తుంది, మెమరీలో దెబ్బతిన్న పేజీని సున్నిస్తుంది మరియు ప్రాసెసింగ్ను కొనసాగిస్తుంది. ఈ ప్రవర్తన డేటాను నాశనం చేస్తుంది, అవి దెబ్బతిన్న పేజీలోని అన్ని అడ్డు వరుసలు.
మేము ఎంపికను ప్రారంభిస్తాము మరియు పట్టికల యొక్క పూర్తి వాక్యూమ్ చేయడానికి ప్రయత్నిస్తాము:
VACUUM FULL VERBOSE 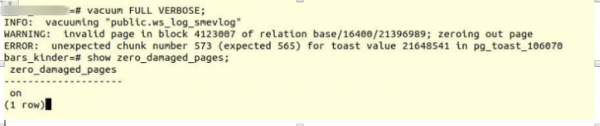
దురదృష్టవశాత్తు, దురదృష్టం.
మేము ఇలాంటి లోపాన్ని ఎదుర్కొన్నాము:
INFO: vacuuming "“public.ws_log_smevlog”
WARNING: invalid page in block 4123007 of relation base/16400/21396989; zeroing out page
ERROR: unexpected chunk number 573 (expected 565) for toast value 21648541 in pg_toast_106070– పొయెట్గ్రెస్లో “దీర్ఘ డేటా” ఒక పేజీలో సరిపోకపోతే (డిఫాల్ట్గా 8kb) నిల్వ చేసే విధానం.
ప్రయత్నం 2: రీఇండెక్స్
Google నుండి మొదటి సలహా సహాయం చేయలేదు. కొన్ని నిమిషాల శోధన తర్వాత, నేను రెండవ చిట్కాను కనుగొన్నాను - తయారు చేయడం రీఇండెక్స్ దెబ్బతిన్న పట్టిక. నేను ఈ సలహాను చాలా చోట్ల చూశాను, కానీ అది విశ్వాసాన్ని కలిగించలేదు. రీఇండెక్స్ చేద్దాం:
reindex table ws_log_smevlog 
రీఇండెక్స్ సమస్యలు లేకుండా పూర్తి.
అయితే, ఇది సహాయం చేయలేదు, వాక్యూమ్ ఫుల్ ఇదే లోపంతో క్రాష్ అయింది. నేను వైఫల్యాలకు అలవాటు పడ్డాను కాబట్టి, నేను ఇంటర్నెట్లో సలహా కోసం మరింత వెతకడం ప్రారంభించాను మరియు చాలా ఆసక్తికరంగా చూశాను .
ప్రయత్నం 3: ఎంపిక, పరిమితి, ఆఫ్సెట్
ఎగువ కథనం పట్టిక వరుసను వరుసల వారీగా చూడాలని మరియు సమస్యాత్మక డేటాను తీసివేయాలని సూచించింది. మొదట మనం అన్ని పంక్తులను చూడాలి:
for ((i=0; i<"Number_of_rows_in_nodes"; i++ )); do psql -U "Username" "Database Name" -c "SELECT * FROM nodes LIMIT 1 offset $i" >/dev/null || echo $i; doneనా విషయంలో, టేబుల్ కలిగి ఉంది 1 628 991 పంక్తులు! బాగా చూసుకోవాల్సిన అవసరం వచ్చింది , కానీ ఇది ప్రత్యేక చర్చకు సంబంధించిన అంశం. ఇది శనివారం, నేను ఈ ఆదేశాన్ని tmuxలో అమలు చేసి పడుకున్నాను:
for ((i=0; i<1628991; i++ )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog LIMIT 1 offset $i" >/dev/null || echo $i; doneఉదయం నాటికి నేను విషయాలు ఎలా జరుగుతున్నాయో తనిఖీ చేయాలని నిర్ణయించుకున్నాను. నా ఆశ్చర్యానికి, 20 గంటల తర్వాత, కేవలం 2% డేటా మాత్రమే స్కాన్ చేయబడిందని నేను కనుగొన్నాను! నేను 50 రోజులు వేచి ఉండాలనుకోలేదు. మరో పూర్తి వైఫల్యం.
కానీ నేను వదులుకోలేదు. స్కానింగ్కి ఇంత సమయం ఎందుకు పట్టిందని నేను ఆశ్చర్యపోయాను. డాక్యుమెంటేషన్ నుండి (మళ్ళీ పోస్ట్గ్రెస్ప్రోలో) నేను కనుగొన్నాను:
OFFSET అడ్డు వరుసలను అవుట్పుట్ చేయడం ప్రారంభించే ముందు పేర్కొన్న వరుసల సంఖ్యను దాటవేయాలని నిర్దేశిస్తుంది.
OFFSET మరియు LIMIT రెండూ పేర్కొనబడితే, సిస్టమ్ మొదట OFFSET అడ్డు వరుసలను దాటవేసి, ఆపై LIMIT పరిమితి కోసం అడ్డు వరుసలను లెక్కించడం ప్రారంభిస్తుంది.LIMITని ఉపయోగిస్తున్నప్పుడు, క్రమాన్ని అనుసరించి నిబంధనను ఉపయోగించడం కూడా ముఖ్యం, తద్వారా ఫలితం వరుసలు నిర్దిష్ట క్రమంలో అందించబడతాయి. లేకపోతే, అడ్డు వరుసల అనూహ్య ఉపసమితులు తిరిగి ఇవ్వబడతాయి.
సహజంగానే, పై ఆదేశం తప్పు: మొదటిది, లేదు ద్వారా ఆర్డర్, ఫలితం తప్పు కావచ్చు. రెండవది, Postgres మొదట OFFSET అడ్డు వరుసలను స్కాన్ చేసి దాటవేయవలసి ఉంటుంది మరియు పెరుగుతున్నప్పుడు OFFSET ఉత్పాదకత మరింత తగ్గుతుంది.
ప్రయత్నం 4: టెక్స్ట్ రూపంలో డంప్ తీసుకోండి
అప్పుడు ఒక అద్భుతమైన ఆలోచన నా మదిలోకి వచ్చింది: టెక్స్ట్ రూపంలో డంప్ తీసుకొని చివరిగా రికార్డ్ చేసిన పంక్తిని విశ్లేషించండి.
అయితే మొదట, పట్టిక యొక్క నిర్మాణాన్ని పరిశీలిద్దాం. ws_log_smevlog:
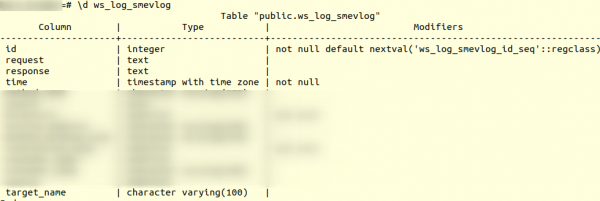
మా విషయంలో మనకు కాలమ్ ఉంది "ఐడి", ఇది అడ్డు వరుస యొక్క ప్రత్యేక ఐడెంటిఫైయర్ (కౌంటర్)ని కలిగి ఉంది. ప్రణాళిక ఇలా ఉంది:
- మేము టెక్స్ట్ రూపంలో డంప్ తీసుకోవడం ప్రారంభిస్తాము (sql ఆదేశాల రూపంలో)
- ఒక నిర్దిష్ట సమయంలో, డంప్ లోపం కారణంగా అంతరాయం ఏర్పడుతుంది, అయితే టెక్స్ట్ ఫైల్ ఇప్పటికీ డిస్క్లో సేవ్ చేయబడుతుంది
- మేము టెక్స్ట్ ఫైల్ చివరను చూస్తాము, తద్వారా విజయవంతంగా తొలగించబడిన చివరి పంక్తి యొక్క ఐడెంటిఫైయర్ (id)ని మేము కనుగొంటాము
నేను టెక్స్ట్ రూపంలో డంప్ తీసుకోవడం ప్రారంభించాను:
pg_dump -U my_user -d my_database -F p -t ws_log_smevlog -f ./my_dump.dumpడంప్, ఊహించిన విధంగా, అదే లోపంతో అంతరాయం కలిగింది:
pg_dump: Error message from server: ERROR: invalid page in block 4123007 of relatton base/16490/21396989 మరింత ద్వారా తోక నేను డంప్ చివర చూసాను (తోక -5 ./my_dump.dump) ఐడితో లైన్లో డంప్ అంతరాయం కలిగిందని కనుగొన్నారు 186 525. "కాబట్టి సమస్య ఐడి 186 526 లైన్లో ఉంది, అది విరిగిపోయింది మరియు తొలగించాల్సిన అవసరం ఉంది!" - నేను అనుకున్నాను. కానీ, డేటాబేస్కు ఒక ప్రశ్న వేయడం:
«id=186529 ఉన్న ws_log_smevlog నుండి * ఎంచుకోండి"ఈ లైన్తో అంతా బాగానే ఉందని తేలింది... 186 - 530 సూచికలతో ఉన్న వరుసలు కూడా సమస్యలు లేకుండా పనిచేశాయి. మరొక "అద్భుతమైన ఆలోచన" విఫలమైంది. ఇది ఎందుకు జరిగిందో తర్వాత నాకు అర్థమైంది: పట్టిక నుండి డేటాను తొలగించేటప్పుడు మరియు మార్చేటప్పుడు, అవి భౌతికంగా తొలగించబడవు, కానీ "డెడ్ టుపుల్స్"గా గుర్తించబడతాయి, ఆపై వస్తాయి ఆటోవాక్యూమ్ మరియు ఈ పంక్తులను తొలగించినట్లు గుర్తు చేస్తుంది మరియు ఈ పంక్తులను తిరిగి ఉపయోగించడానికి అనుమతిస్తుంది. అర్థం చేసుకోవడానికి, పట్టికలోని డేటా మారితే మరియు ఆటోవాక్యూమ్ ప్రారంభించబడితే, అది వరుసగా నిల్వ చేయబడదు.
ప్రయత్నం 5: SELECT, FROM, HHERE id=
వైఫల్యాలు మనల్ని మరింత బలపరుస్తాయి. మీరు ఎప్పటికీ వదులుకోకూడదు, మీరు చివరి వరకు వెళ్లి మిమ్మల్ని మరియు మీ సామర్థ్యాలను విశ్వసించాలి. కాబట్టి నేను మరొక ఎంపికను ప్రయత్నించాలని నిర్ణయించుకున్నాను: డేటాబేస్లోని అన్ని రికార్డులను ఒక్కొక్కటిగా చూడండి. నా పట్టిక యొక్క నిర్మాణాన్ని తెలుసుకోవడం (పైన చూడండి), మాకు ప్రత్యేకమైన ఐడి ఫీల్డ్ ఉంది (ప్రాధమిక కీ). మేము పట్టికలో 1 వరుసలను కలిగి ఉన్నాము మరియు id క్రమంలో ఉన్నాయి, అంటే మనం వాటిని ఒక్కొక్కటిగా చూడవచ్చు:
for ((i=1; i<1628991; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; doneఎవరికైనా అర్థం కాకపోతే, ఆదేశం క్రింది విధంగా పని చేస్తుంది: ఇది పట్టిక వరుసను వరుసగా స్కాన్ చేస్తుంది మరియు stdoutని పంపుతుంది / Dev / శూన్య, కానీ SELECT కమాండ్ విఫలమైతే, ఎర్రర్ టెక్స్ట్ ముద్రించబడుతుంది (stderr కన్సోల్కు పంపబడుతుంది) మరియు లోపం ఉన్న లైన్ ముద్రించబడుతుంది (ధన్యవాదాలు ||, అంటే ఎంపికకు సమస్యలు ఉన్నాయని అర్థం (కమాండ్ యొక్క రిటర్న్ కోడ్ 0 కాదు)).
నేను అదృష్టవంతుడిని, ఫీల్డ్లో నేను ఇండెక్స్లను సృష్టించాను id:

అంటే కావలసిన ఐడితో లైన్ని కనుగొనడానికి ఎక్కువ సమయం పట్టదు. సిద్ధాంతంలో ఇది పని చేయాలి. సరే, కమాండ్ని రన్ చేద్దాం tmux మరియు పడుకుందాం.
ఉదయం నాటికి దాదాపు 90 ఎంట్రీలు వీక్షించబడ్డాయని నేను కనుగొన్నాను, ఇది కేవలం 000% కంటే ఎక్కువ. మునుపటి పద్ధతి (5%)తో పోల్చినప్పుడు అద్భుతమైన ఫలితం! కానీ నేను 2 రోజులు వేచి ఉండదలచుకోలేదు ...
ప్రయత్నం 6: SELECT, FROM, ఎక్కడ id >= మరియు id
కస్టమర్ డేటాబేస్కు అంకితమైన అద్భుతమైన సర్వర్ను కలిగి ఉన్నారు: డ్యూయల్-ప్రాసెసర్ ఇంటెల్ జియాన్ E5-2697 v2, మా ప్రదేశంలో 48 థ్రెడ్లు ఉన్నాయి! సర్వర్లో లోడ్ సగటున ఉంది; మేము ఎటువంటి సమస్యలు లేకుండా దాదాపు 20 థ్రెడ్లను డౌన్లోడ్ చేసుకోవచ్చు. తగినంత ర్యామ్ కూడా ఉంది: 384 గిగాబైట్లు!
కాబట్టి, ఆదేశం సమాంతరంగా ఉండాలి:
for ((i=1; i<1628991; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; doneఇక్కడ అందమైన మరియు సొగసైన స్క్రిప్ట్ను వ్రాయడం సాధ్యమైంది, కానీ నేను వేగవంతమైన సమాంతరీకరణ పద్ధతిని ఎంచుకున్నాను: 0-1628991 పరిధిని 100 రికార్డ్ల విరామాలుగా మానవీయంగా విభజించి, ఫారమ్లోని 000 ఆదేశాలను విడిగా అమలు చేసాను:
for ((i=N; i<M; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; doneఅయితే అంతే కాదు. సిద్ధాంతపరంగా, డేటాబేస్కు కనెక్ట్ చేయడానికి కొంత సమయం మరియు సిస్టమ్ వనరులు కూడా పడుతుంది. 1ని కనెక్ట్ చేయడం చాలా తెలివైన పని కాదు, మీరు అంగీకరిస్తారు. కాబట్టి, ఒక కనెక్షన్లో ఒకటి కాకుండా 628 అడ్డు వరుసలను తిరిగి పొందండి. ఫలితంగా, జట్టు ఇలా రూపాంతరం చెందింది:
for ((i=N; i<M; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; donetmux సెషన్లో 16 విండోలను తెరిచి, ఆదేశాలను అమలు చేయండి:
1) for ((i=0; i<100000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done 2) for ((i=100000; i<200000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done … 15) for ((i=1400000; i<1500000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done 16) for ((i=1500000; i<1628991; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done
ఒక రోజు తర్వాత నేను మొదటి ఫలితాలను అందుకున్నాను! అవి (XXX మరియు ZZZ విలువలు ఇకపై భద్రపరచబడవు):
ERROR: missing chunk number 0 for toast value 37837571 in pg_toast_106070
829000
ERROR: missing chunk number 0 for toast value XXX in pg_toast_106070
829000
ERROR: missing chunk number 0 for toast value ZZZ in pg_toast_106070
146000మూడు పంక్తులు లోపాన్ని కలిగి ఉన్నాయని దీని అర్థం. మొదటి మరియు రెండవ సమస్య రికార్డుల ఐడిలు 829 మరియు 000 మధ్య ఉన్నాయి, మూడవది 830 మరియు 000 మధ్య ఉన్నాయి. తర్వాత, మేము సమస్య రికార్డుల యొక్క ఖచ్చితమైన ID విలువను కనుగొనవలసి ఉంటుంది. దీన్ని చేయడానికి, మేము 146 దశతో సమస్యాత్మక రికార్డులతో మా పరిధిని పరిశీలిస్తాము మరియు ఐడిని గుర్తిస్తాము:
for ((i=829000; i<830000; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done 829417 ERROR: unexpected chunk number 2 (expected 0) for toast value 37837843 in pg_toast_106070 829449 for ((i=146000; i<147000; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done 829417 ERROR: unexpected chunk number ZZZ (expected 0) for toast value XXX in pg_toast_106070 146911
సుఖాంతం
మేము సమస్యాత్మక పంక్తులను కనుగొన్నాము. మేము psql ద్వారా డేటాబేస్లోకి వెళ్లి వాటిని తొలగించడానికి ప్రయత్నిస్తాము:
my_database=# delete from ws_log_smevlog where id=829417;
DELETE 1
my_database=# delete from ws_log_smevlog where id=829449;
DELETE 1
my_database=# delete from ws_log_smevlog where id=146911;
DELETE 1నా ఆశ్చర్యానికి, ఎంపిక లేకుండా కూడా ఎటువంటి సమస్యలు లేకుండా ఎంట్రీలు తొలగించబడ్డాయి zero_damaged_pages.
అప్పుడు నేను డేటాబేస్కు కనెక్ట్ చేసాను వాక్యూమ్ ఫుల్ (దీన్ని చేయవలసిన అవసరం లేదని నేను భావిస్తున్నాను), చివరకు నేను బ్యాకప్ని ఉపయోగించి విజయవంతంగా తొలగించాను pg_dump. డంప్ ఎటువంటి లోపాలు లేకుండా తీయబడింది! సమస్య చాలా తెలివితక్కువ మార్గంలో పరిష్కరించబడింది. ఆనందానికి అవధులు లేవు, చాలా వైఫల్యాల తర్వాత మేము ఒక పరిష్కారాన్ని కనుగొనగలిగాము!
రసీదులు మరియు ముగింపు
నిజమైన పోస్ట్గ్రెస్ డేటాబేస్ను పునరుద్ధరించడంలో నా మొదటి అనుభవం ఇలా మారింది. ఈ అనుభవాన్ని నేను చాలా కాలం పాటు గుర్తుంచుకుంటాను.
చివరగా, డాక్యుమెంటేషన్ను రష్యన్లోకి అనువదించినందుకు పోస్ట్గ్రెస్ప్రోకి నేను ధన్యవాదాలు చెప్పాలనుకుంటున్నాను. , ఇది సమస్య యొక్క విశ్లేషణ సమయంలో చాలా సహాయపడింది.
మూలం: www.habr.com
