

అందరికి వందనాలు! నా పేరు గోలోవ్ నికోలాయ్. గతంలో, నేను Avitoలో పనిచేశాను మరియు డేటా ప్లాట్ఫారమ్ను ఆరు సంవత్సరాలు నిర్వహించాను, అంటే, నేను అన్ని డేటాబేస్లలో పనిచేశాను: విశ్లేషణాత్మక (వెర్టికా, క్లిక్హౌస్), స్ట్రీమింగ్ మరియు OLTP (Redis, Tarantool, VoltDB, MongoDB, PostgreSQL). ఈ సమయంలో, నేను పెద్ద సంఖ్యలో డేటాబేస్లతో వ్యవహరించాను - చాలా భిన్నమైన మరియు అసాధారణమైన మరియు వాటి ఉపయోగం యొక్క ప్రామాణికం కాని కేసులతో.
నేను ప్రస్తుతం ManyChatలో పని చేస్తున్నాను. సారాంశంలో, ఇది స్టార్టప్ - కొత్తది, ప్రతిష్టాత్మకమైనది మరియు వేగంగా అభివృద్ధి చెందుతోంది. మరియు నేను మొదట కంపెనీలో చేరినప్పుడు, ఒక క్లాసిక్ ప్రశ్న తలెత్తింది: "యువ స్టార్టప్ ఇప్పుడు DBMS మరియు డేటాబేస్ మార్కెట్ నుండి ఏమి తీసుకోవాలి?"
ఈ వ్యాసంలో, వద్ద నా నివేదిక ఆధారంగా , నేను ఈ ప్రశ్నకు సమాధానం ఇస్తాను. నివేదిక యొక్క వీడియో వెర్షన్ ఇక్కడ అందుబాటులో ఉంది .
సాధారణంగా తెలిసిన డేటాబేస్లు 2020
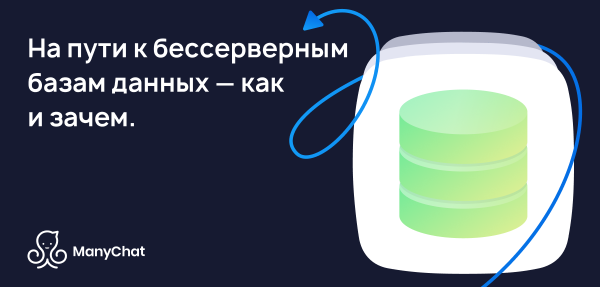
ఇది 2020, నేను చుట్టూ చూసాను మరియు మూడు రకాల డేటాబేస్లను చూశాను.
మొదటి రకం - క్లాసిక్ OLTP డేటాబేస్లు: PostgreSQL, SQL సర్వర్, ఒరాకిల్, MySQL. అవి చాలా కాలం క్రితం వ్రాయబడ్డాయి, కానీ అవి డెవలపర్ కమ్యూనిటీకి బాగా తెలిసినందున ఇప్పటికీ సంబంధితంగా ఉన్నాయి.
రెండవ రకం - "సున్నా" నుండి ఆధారాలు. వారు అంతర్నిర్మిత షార్డింగ్ మరియు ఇతర ఆకర్షణీయమైన లక్షణాలను జోడించడం ద్వారా SQL, సాంప్రదాయ నిర్మాణాలు మరియు ACIDని వదిలివేయడం ద్వారా క్లాసిక్ నమూనాల నుండి దూరంగా వెళ్లడానికి ప్రయత్నించారు. ఉదాహరణకు, ఇది కాసాండ్రా, మొంగోడిబి, రెడిస్ లేదా టరాన్టూల్. ఈ పరిష్కారాలన్నీ మార్కెట్కు ప్రాథమికంగా కొత్తదనాన్ని అందించాలని కోరుకున్నాయి మరియు నిర్దిష్ట పనులకు అత్యంత అనుకూలమైనవిగా మారినందున వాటి సముచిత స్థానాన్ని ఆక్రమించాయి. నేను ఈ డేటాబేస్లను NOSQL అనే గొడుగు పదంతో సూచిస్తాను.
“సున్నాలు” ముగిశాయి, మేము NOSQL డేటాబేస్లకు అలవాటు పడ్డాము మరియు ప్రపంచం, నా దృక్కోణం నుండి, తదుపరి దశను తీసుకుంది - నిర్వహించబడే డేటాబేస్. ఈ డేటాబేస్లు క్లాసిక్ OLTP డేటాబేస్లు లేదా కొత్త NoSQL వాటిని కలిగి ఉంటాయి. కానీ వారికి DBA మరియు DevOps అవసరం లేదు మరియు క్లౌడ్లలో నిర్వహించబడే హార్డ్వేర్పై నడుస్తుంది. డెవలపర్ కోసం, ఇది ఎక్కడో పని చేసే "కేవలం బేస్", కానీ ఇది సర్వర్లో ఎలా ఇన్స్టాల్ చేయబడిందో, సర్వర్ను ఎవరు కాన్ఫిగర్ చేసారు మరియు ఎవరు అప్డేట్ చేస్తారో ఎవరూ పట్టించుకోరు.
అటువంటి డేటాబేస్ల ఉదాహరణలు:
- AWS RDS అనేది PostgreSQL/MySQL కోసం నిర్వహించబడే రేపర్.
- DynamoDB అనేది Redis మరియు MongoDB మాదిరిగానే డాక్యుమెంట్ ఆధారిత డేటాబేస్ యొక్క AWS అనలాగ్.
- Amazon Redshift అనేది నిర్వహించబడే విశ్లేషణాత్మక డేటాబేస్.
ఇవి ప్రాథమికంగా పాత డేటాబేస్లు, కానీ హార్డ్వేర్తో పని చేయాల్సిన అవసరం లేకుండా నిర్వహించబడే వాతావరణంలో పెంచబడ్డాయి.
గమనిక. ఉదాహరణలు AWS పర్యావరణం కోసం తీసుకోబడ్డాయి, కానీ వాటి అనలాగ్లు Microsoft Azure, Google Cloud లేదా Yandex.Cloudలో కూడా ఉన్నాయి.
ఇందులో కొత్తగా ఏముంది? 2020లో, ఇవేవీ లేవు.
సర్వర్లెస్ కాన్సెప్ట్
2020లో మార్కెట్లో నిజంగా కొత్తది సర్వర్లెస్ లేదా సర్వర్లెస్ సొల్యూషన్స్.
సాధారణ సేవ లేదా బ్యాకెండ్ అప్లికేషన్ యొక్క ఉదాహరణను ఉపయోగించి దీని అర్థం ఏమిటో వివరించడానికి నేను ప్రయత్నిస్తాను.
సాధారణ బ్యాకెండ్ అప్లికేషన్ను అమలు చేయడానికి, మేము సర్వర్ను కొనుగోలు చేస్తాము లేదా అద్దెకు తీసుకుంటాము, దానిలో కోడ్ను కాపీ చేస్తాము, ఎండ్పాయింట్ను బయట ప్రచురిస్తాము మరియు అద్దె, విద్యుత్ మరియు డేటా సెంటర్ సేవలకు క్రమం తప్పకుండా చెల్లిస్తాము. ఇది ప్రామాణిక పథకం.
మరేదైనా మార్గం ఉందా? సర్వర్లెస్ సేవలతో మీరు చేయవచ్చు.
ఈ విధానం యొక్క దృష్టి ఏమిటి: సర్వర్ లేదు, క్లౌడ్లో వర్చువల్ ఉదాహరణను అద్దెకు తీసుకోవడం కూడా లేదు. సేవను అమలు చేయడానికి, కోడ్ను (ఫంక్షన్లు) రిపోజిటరీకి కాపీ చేసి, దానిని ఎండ్పాయింట్కు ప్రచురించండి. అప్పుడు మేము ఈ ఫంక్షన్కి ప్రతి కాల్కు చెల్లిస్తాము, అది అమలు చేయబడిన హార్డ్వేర్ను పూర్తిగా విస్మరిస్తాము.
నేను ఈ విధానాన్ని చిత్రాలతో వివరించడానికి ప్రయత్నిస్తాను.
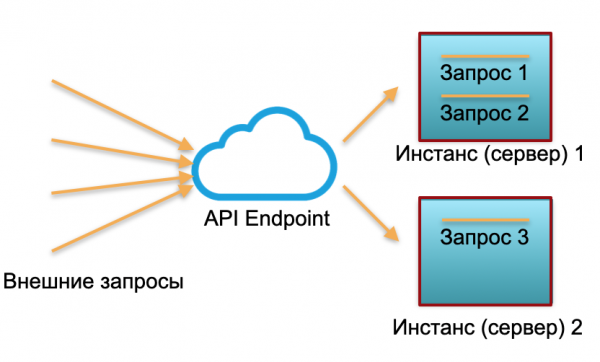
క్లాసిక్ విస్తరణ. మేము నిర్దిష్ట లోడ్తో సేవను కలిగి ఉన్నాము. మేము రెండు ఉదాహరణలను లేవనెత్తాము: భౌతిక సర్వర్లు లేదా AWSలో ఉదాహరణలు. బాహ్య అభ్యర్థనలు ఈ సందర్భాలలో పంపబడతాయి మరియు అక్కడ ప్రాసెస్ చేయబడతాయి.
మీరు చిత్రంలో చూడగలిగినట్లుగా, సర్వర్లు సమానంగా పారవేయబడవు. ఒకటి 100% ఉపయోగించబడింది, రెండు అభ్యర్థనలు ఉన్నాయి మరియు ఒకటి 50% మాత్రమే - పాక్షికంగా నిష్క్రియంగా ఉంది. మూడు అభ్యర్థనలు రాకపోతే, కానీ 30, అప్పుడు మొత్తం సిస్టమ్ లోడ్ను తట్టుకోలేకపోతుంది మరియు వేగాన్ని తగ్గించడం ప్రారంభమవుతుంది.
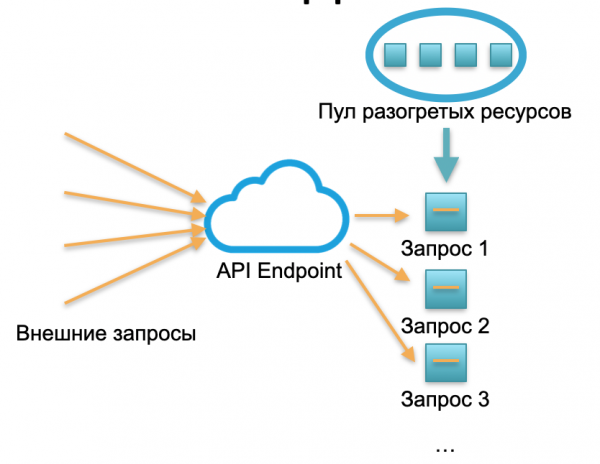
సర్వర్లెస్ విస్తరణ. సర్వర్ లేని వాతావరణంలో, అటువంటి సేవకు సందర్భాలు లేదా సర్వర్లు లేవు. వేడిచేసిన వనరుల యొక్క నిర్దిష్ట పూల్ ఉంది - అమలు చేయబడిన ఫంక్షన్ కోడ్తో తయారు చేయబడిన చిన్న డాకర్ కంటైనర్లు. సిస్టమ్ బాహ్య అభ్యర్థనలను అందుకుంటుంది మరియు వాటిలో ప్రతిదానికి సర్వర్లెస్ ఫ్రేమ్వర్క్ కోడ్తో ఒక చిన్న కంటైనర్ను పెంచుతుంది: ఇది ఈ నిర్దిష్ట అభ్యర్థనను ప్రాసెస్ చేస్తుంది మరియు కంటైనర్ను చంపుతుంది.
ఒక అభ్యర్థన - ఒక కంటైనర్ పెరిగింది, 1000 అభ్యర్థనలు - 1000 కంటైనర్లు. మరియు హార్డ్వేర్ సర్వర్లపై విస్తరణ ఇప్పటికే క్లౌడ్ ప్రొవైడర్ యొక్క పని. ఇది సర్వర్లెస్ ఫ్రేమ్వర్క్ ద్వారా పూర్తిగా దాచబడింది. ఈ కాన్సెప్ట్లో మేము ప్రతి కాల్కు చెల్లిస్తాము. ఉదాహరణకు, రోజుకు ఒక కాల్ వచ్చింది - మేము ఒక కాల్కి చెల్లించాము, నిమిషానికి ఒక మిలియన్ వచ్చింది - మేము ఒక మిలియన్ చెల్లించాము. లేదా ఒక సెకనులో, ఇది కూడా జరుగుతుంది.
సర్వర్లెస్ ఫంక్షన్ను ప్రచురించే భావన స్థితిలేని సేవకు అనుకూలంగా ఉంటుంది. మరియు మీకు (స్టేట్) స్టేట్ఫుల్ సేవ అవసరమైతే, మేము సేవకు డేటాబేస్ను జోడిస్తాము. ఈ సందర్భంలో, స్టేట్తో పని విషయానికి వస్తే, ప్రతి స్టేట్ఫుల్ ఫంక్షన్ డేటాబేస్ నుండి వ్రాస్తుంది మరియు చదవబడుతుంది. అంతేకాకుండా, వ్యాసం ప్రారంభంలో వివరించిన మూడు రకాల్లో ఏదైనా డేటాబేస్ నుండి.
ఈ డేటాబేస్లన్నింటికీ ఉమ్మడి పరిమితి ఏమిటి? ఇవి నిరంతరం ఉపయోగించే క్లౌడ్ లేదా హార్డ్వేర్ సర్వర్ (లేదా అనేక సర్వర్లు) ఖర్చులు. మేము క్లాసిక్ లేదా మేనేజ్డ్ డేటాబేస్ని ఉపయోగిస్తున్నామా, మాకు Devops మరియు అడ్మిన్ ఉన్నా లేదా లేకపోయినా, హార్డ్వేర్, విద్యుత్ మరియు డేటా సెంటర్ అద్దెకు 24/7 చెల్లిస్తాము. మేము ఒక క్లాసిక్ బేస్ కలిగి ఉంటే, మేము యజమాని మరియు బానిస కోసం చెల్లిస్తాము. ఇది ఎక్కువగా లోడ్ చేయబడిన షార్డ్ డేటాబేస్ అయితే, మేము 10, 20 లేదా 30 సర్వర్లకు చెల్లిస్తాము మరియు మేము నిరంతరం చెల్లిస్తాము.
వ్యయ నిర్మాణంలో శాశ్వతంగా రిజర్వు చేయబడిన సర్వర్ల ఉనికిని గతంలో అవసరమైన చెడుగా భావించారు. సాంప్రదాయిక డేటాబేస్లు కనెక్షన్ల సంఖ్యపై పరిమితులు, స్కేలింగ్ పరిమితులు, జియో-పంపిణీ చేసిన ఏకాభిప్రాయం వంటి ఇతర సమస్యలను కూడా కలిగి ఉంటాయి - అవి ఏదో ఒకవిధంగా నిర్దిష్ట డేటాబేస్లలో పరిష్కరించబడతాయి, కానీ అన్నీ ఒకేసారి కాదు మరియు ఆదర్శంగా కాదు.
సర్వర్లెస్ డేటాబేస్ - సిద్ధాంతం
2020 ప్రశ్న: డేటాబేస్ సర్వర్లెస్గా చేయడం కూడా సాధ్యమేనా? సర్వర్లెస్ బ్యాకెండ్ గురించి అందరూ విన్నారు... డేటాబేస్ సర్వర్లెస్గా మార్చడానికి ప్రయత్నిద్దాం?
ఇది వింతగా అనిపిస్తుంది, ఎందుకంటే డేటాబేస్ స్టేట్ఫుల్ సర్వీస్, సర్వర్లెస్ ఇన్ఫ్రాస్ట్రక్చర్కు చాలా సరిఅయినది కాదు. అదే సమయంలో, డేటాబేస్ యొక్క స్థితి చాలా పెద్దది: గిగాబైట్లు, టెరాబైట్లు మరియు విశ్లేషణాత్మక డేటాబేస్లలో పెటాబైట్లు కూడా. తేలికైన డాకర్ కంటైనర్లలో దీన్ని పెంచడం అంత సులభం కాదు.
మరోవైపు, దాదాపు అన్ని ఆధునిక డేటాబేస్లు భారీ మొత్తంలో లాజిక్ మరియు భాగాలను కలిగి ఉంటాయి: లావాదేవీలు, సమగ్రత సమన్వయం, విధానాలు, రిలేషనల్ డిపెండెన్సీలు మరియు చాలా లాజిక్. చాలా డేటాబేస్ లాజిక్ కోసం, ఒక చిన్న స్థితి సరిపోతుంది. గిగాబైట్లు మరియు టెరాబైట్లు నేరుగా ప్రశ్నలను అమలు చేయడంలో ప్రమేయం ఉన్న డేటాబేస్ లాజిక్లో కొద్ది భాగం మాత్రమే ఉపయోగించబడతాయి.
దీని ప్రకారం, ఆలోచన ఏమిటంటే: తర్కంలోని భాగం స్థితిలేని అమలును అనుమతించినట్లయితే, ఆధారాన్ని స్టేట్ఫుల్ మరియు స్టేట్లెస్ భాగాలుగా ఎందుకు విభజించకూడదు.
OLAP పరిష్కారాల కోసం సర్వర్లెస్
డేటాబేస్ను స్టేట్ఫుల్ మరియు స్టేట్లెస్ భాగాలుగా కత్తిరించడం ఆచరణాత్మక ఉదాహరణలను ఉపయోగించి ఎలా ఉంటుందో చూద్దాం.
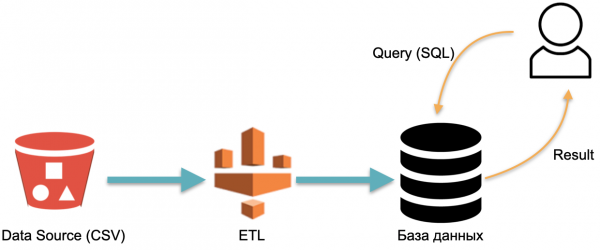
ఉదాహరణకు, మనకు విశ్లేషణాత్మక డేటాబేస్ ఉంది: బాహ్య డేటా (ఎడమవైపున ఎరుపు రంగు సిలిండర్), డేటాబేస్లోకి డేటాను లోడ్ చేసే ETL ప్రక్రియ మరియు డేటాబేస్కు SQL ప్రశ్నలను పంపే విశ్లేషకుడు. ఇది ఒక క్లాసిక్ డేటా వేర్హౌస్ ఆపరేషన్ స్కీమ్.
ఈ పథకంలో, ETL షరతులతో ఒకసారి నిర్వహించబడుతుంది. ఆపై మీరు ETLతో నిండిన డేటాతో డేటాబేస్ నడుస్తున్న సర్వర్ల కోసం నిరంతరం చెల్లించాలి, తద్వారా ప్రశ్నలను పంపడానికి ఏదైనా ఉంటుంది.
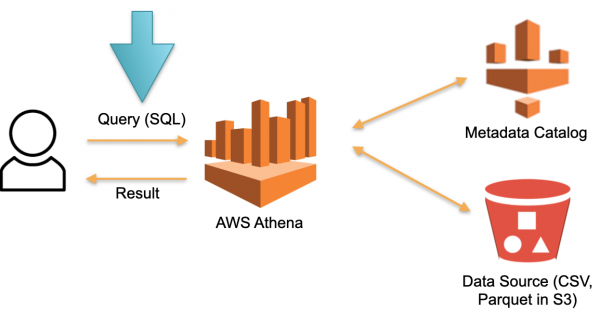
AWS ఎథీనా సర్వర్లెస్లో అమలు చేయబడిన ప్రత్యామ్నాయ విధానాన్ని చూద్దాం. డౌన్లోడ్ చేయబడిన డేటా నిల్వ చేయబడే శాశ్వతంగా అంకితమైన హార్డ్వేర్ లేదు. దీనికి బదులుగా:
- వినియోగదారు ఎథీనాకు SQL ప్రశ్నను సమర్పించారు. ఎథీనా ఆప్టిమైజర్ SQL ప్రశ్నను విశ్లేషిస్తుంది మరియు ప్రశ్నను అమలు చేయడానికి అవసరమైన నిర్దిష్ట డేటా కోసం మెటాడేటా స్టోర్ (మెటాడేటా)ను శోధిస్తుంది.
- ఆప్టిమైజర్, సేకరించిన డేటా ఆధారంగా, అవసరమైన డేటాను బాహ్య మూలాల నుండి తాత్కాలిక నిల్వ (తాత్కాలిక డేటాబేస్)లోకి డౌన్లోడ్ చేస్తుంది.
- వినియోగదారు నుండి ఒక SQL ప్రశ్న తాత్కాలిక నిల్వలో అమలు చేయబడుతుంది మరియు ఫలితం వినియోగదారుకు అందించబడుతుంది.
- తాత్కాలిక నిల్వ క్లియర్ చేయబడింది మరియు వనరులు విడుదల చేయబడ్డాయి.
ఈ ఆర్కిటెక్చర్లో, మేము అభ్యర్థనను అమలు చేసే ప్రక్రియకు మాత్రమే చెల్లిస్తాము. అభ్యర్థనలు లేవు - ఖర్చులు లేవు.
ఇది పని చేసే విధానం మరియు ఎథీనా సర్వర్లెస్లో మాత్రమే కాకుండా, రెడ్షిఫ్ట్ స్పెక్ట్రమ్లో (AWSలో) కూడా అమలు చేయబడుతుంది.
పదుల మరియు వందల టెరాబైట్ల డేటాతో సర్వర్లెస్ డేటాబేస్ నిజమైన ప్రశ్నలపై పనిచేస్తుందని ఎథీనా ఉదాహరణ చూపిస్తుంది. వందల టెరాబైట్లకు వందలకొద్దీ సర్వర్లు అవసరమవుతాయి, కానీ మేము వాటి కోసం చెల్లించాల్సిన అవసరం లేదు - మేము అభ్యర్థనల కోసం చెల్లిస్తాము. వెర్టికా వంటి ప్రత్యేక విశ్లేషణాత్మక డేటాబేస్లతో పోలిస్తే ప్రతి అభ్యర్థన వేగం (చాలా) తక్కువగా ఉంటుంది, కానీ మేము డౌన్టైమ్ పీరియడ్లకు చెల్లించము.
అటువంటి డేటాబేస్ అరుదైన విశ్లేషణాత్మక తాత్కాలిక ప్రశ్నలకు వర్తిస్తుంది. ఉదాహరణకు, మేము ఆకస్మికంగా కొంత పెద్ద మొత్తంలో డేటాపై పరికల్పనను పరీక్షించాలని నిర్ణయించుకున్నప్పుడు. ఈ సందర్భాలలో ఎథీనా సరైనది. సాధారణ అభ్యర్థనల కోసం, అటువంటి వ్యవస్థ ఖరీదైనది. ఈ సందర్భంలో, డేటాను కొన్ని ప్రత్యేక పరిష్కారంలో కాష్ చేయండి.
OLTP పరిష్కారాల కోసం సర్వర్లెస్
మునుపటి ఉదాహరణ OLAP (విశ్లేషణాత్మక) పనులను చూసింది. ఇప్పుడు OLTP టాస్క్లను చూద్దాం.
స్కేలబుల్ PostgreSQL లేదా MySQLని ఊహించుకుందాం. కనిష్ట వనరులతో రెగ్యులర్ మేనేజ్డ్ ఇన్స్టాన్స్ PostgreSQL లేదా MySQLని పెంచుదాం. ఉదాహరణకి ఎక్కువ లోడ్ వచ్చినప్పుడు, మేము రీడింగ్ లోడ్లో కొంత భాగాన్ని పంపిణీ చేసే అదనపు ప్రతిరూపాలను కనెక్ట్ చేస్తాము. అభ్యర్థనలు లేదా లోడ్ లేనట్లయితే, మేము ప్రతిరూపాలను ఆఫ్ చేస్తాము. మొదటి ఉదాహరణ మాస్టర్, మరియు మిగిలినవి ప్రతిరూపాలు.
ఈ ఆలోచన అరోరా సర్వర్లెస్ AWS అనే డేటాబేస్లో అమలు చేయబడింది. సూత్రం చాలా సులభం: బాహ్య అనువర్తనాల నుండి అభ్యర్థనలు ప్రాక్సీ ఫ్లీట్ ద్వారా ఆమోదించబడతాయి. లోడ్ పెరుగుదలను చూసినప్పుడు, ఇది ముందుగా వేడెక్కిన కొద్దిపాటి సందర్భాల నుండి కంప్యూటింగ్ వనరులను కేటాయిస్తుంది - కనెక్షన్ వీలైనంత త్వరగా చేయబడుతుంది. డిసేబుల్ సందర్భాలు అదే విధంగా జరుగుతాయి.
అరోరాలో అరోరా కెపాసిటీ యూనిట్, ACU అనే భావన ఉంది. ఇది (షరతులతో) ఒక ఉదాహరణ (సర్వర్). ప్రతి నిర్దిష్ట ACU మాస్టర్ లేదా బానిస కావచ్చు. ప్రతి కెపాసిటీ యూనిట్ దాని స్వంత RAM, ప్రాసెసర్ మరియు కనిష్ట డిస్క్లను కలిగి ఉంటుంది. దీని ప్రకారం, ఒకరు మాస్టర్, మిగిలినవి ప్రతిరూపాలు మాత్రమే చదవబడతాయి.
నడుస్తున్న ఈ అరోరా కెపాసిటీ యూనిట్ల సంఖ్య కాన్ఫిగర్ చేయదగిన పరామితి. కనీస పరిమాణం ఒకటి లేదా సున్నా కావచ్చు (ఈ సందర్భంలో, అభ్యర్థనలు లేనట్లయితే డేటాబేస్ పనిచేయదు).
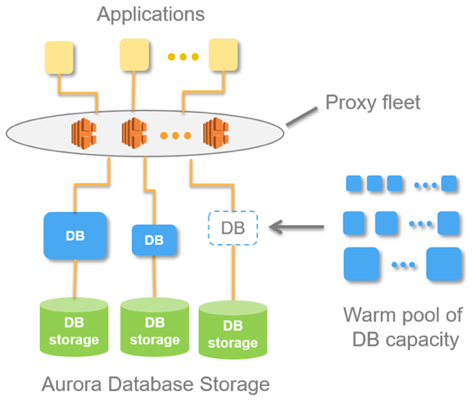
బేస్ అభ్యర్థనలను స్వీకరించినప్పుడు, ప్రాక్సీ ఫ్లీట్ అరోరా కెపాసిటీయూనిట్లను పెంచుతుంది, సిస్టమ్ పనితీరు వనరులను పెంచుతుంది. వనరులను పెంచే మరియు తగ్గించే సామర్థ్యం సిస్టమ్ను వనరులను "గారడీ" చేయడానికి అనుమతిస్తుంది: స్వయంచాలకంగా వ్యక్తిగత ACUలను ప్రదర్శిస్తుంది (వాటిని కొత్త వాటితో భర్తీ చేయడం) మరియు ఉపసంహరించబడిన వనరులకు అన్ని ప్రస్తుత నవీకరణలను రోల్ అవుట్ చేయండి.
అరోరా సర్వర్లెస్ బేస్ రీడింగ్ లోడ్ను స్కేల్ చేయగలదు. కానీ డాక్యుమెంటేషన్ ఈ విషయాన్ని నేరుగా చెప్పలేదు. వారు మల్టీ-మాస్టర్ను ఎత్తగలరని అనిపించవచ్చు. మంత్రము లేదు.
అనూహ్య యాక్సెస్తో సిస్టమ్లపై భారీ మొత్తంలో డబ్బు ఖర్చు చేయకుండా ఉండటానికి ఈ డేటాబేస్ బాగా సరిపోతుంది. ఉదాహరణకు, MVPని సృష్టించేటప్పుడు లేదా వ్యాపార కార్డ్ సైట్లను మార్కెటింగ్ చేస్తున్నప్పుడు, మేము సాధారణంగా స్థిరమైన లోడ్ను ఆశించము. దీని ప్రకారం, యాక్సెస్ లేనట్లయితే, మేము ఉదాహరణలకు చెల్లించము. ఊహించని లోడ్ సంభవించినప్పుడు, ఉదాహరణకు ఒక కాన్ఫరెన్స్ లేదా అడ్వర్టయిజింగ్ క్యాంపెయిన్ తర్వాత, వ్యక్తుల సమూహాలు సైట్ను సందర్శిస్తారు మరియు లోడ్ నాటకీయంగా పెరుగుతుంది, అరోరా సర్వర్లెస్ స్వయంచాలకంగా ఈ లోడ్ను తీసుకుంటుంది మరియు తప్పిపోయిన వనరులను (ACU) త్వరగా కనెక్ట్ చేస్తుంది. అప్పుడు సమావేశం గడిచిపోతుంది, ప్రతి ఒక్కరూ ప్రోటోటైప్ గురించి మరచిపోతారు, సర్వర్లు (ACU) చీకటిగా మారుతాయి మరియు ఖర్చులు సున్నాకి పడిపోతాయి - అనుకూలమైనది.
ఈ పరిష్కారం స్థిరమైన హైలోడ్కు తగినది కాదు ఎందుకంటే ఇది రైటింగ్ లోడ్ను స్కేల్ చేయదు. ఈ కనెక్షన్లు మరియు వనరుల డిస్కనెక్ట్లు అన్నీ "స్కేల్ పాయింట్" అని పిలవబడే సమయంలో జరుగుతాయి - డేటాబేస్ లావాదేవీ లేదా తాత్కాలిక పట్టికల ద్వారా మద్దతు ఇవ్వని సమయంలో. ఉదాహరణకు, ఒక వారంలోపు స్కేల్ పాయింట్ జరగకపోవచ్చు మరియు బేస్ అదే వనరులపై పనిచేస్తుంది మరియు కేవలం విస్తరించడం లేదా కుదించడం సాధ్యం కాదు.
మాయాజాలం లేదు - ఇది సాధారణ PostgreSQL. కానీ యంత్రాలను జోడించడం మరియు వాటిని డిస్కనెక్ట్ చేసే ప్రక్రియ పాక్షికంగా ఆటోమేటెడ్.
డిజైన్ ద్వారా సర్వర్లెస్
అరోరా సర్వర్లెస్ అనేది సర్వర్లెస్ యొక్క కొన్ని ప్రయోజనాలను ఉపయోగించుకోవడానికి క్లౌడ్ కోసం తిరిగి వ్రాయబడిన పాత డేటాబేస్. సర్వర్లెస్ విధానం - సర్వర్లెస్-బై-డిజైన్ కోసం మొదట క్లౌడ్ కోసం వ్రాయబడిన బేస్ గురించి ఇప్పుడు నేను మీకు చెప్తాను. ఇది ఫిజికల్ సర్వర్లపై నడుస్తుందనే ఊహ లేకుండా వెంటనే అభివృద్ధి చేయబడింది.
ఈ స్థావరాన్ని స్నోఫ్లేక్ అంటారు. ఇందులో మూడు కీ బ్లాక్లు ఉన్నాయి.
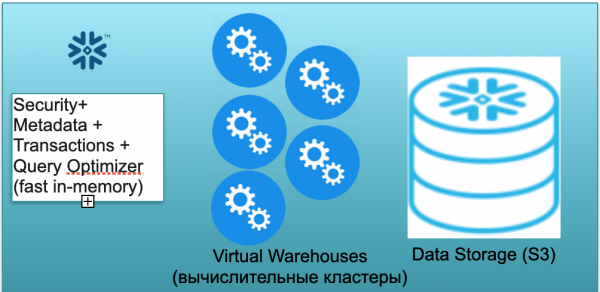
మొదటిది మెటాడేటా బ్లాక్. ఇది భద్రత, మెటాడేటా, లావాదేవీలు మరియు ప్రశ్న ఆప్టిమైజేషన్ (ఎడమవైపున ఉన్న ఇలస్ట్రేషన్లో చూపబడింది) వంటి సమస్యలను పరిష్కరించే వేగవంతమైన ఇన్-మెమరీ సేవ.
రెండవ బ్లాక్ అనేది గణనల కోసం వర్చువల్ కంప్యూటింగ్ క్లస్టర్ల సమితి (దృష్టాంతంలో నీలి సర్కిల్ల సమితి ఉంది).
మూడవ బ్లాక్ S3 ఆధారంగా డేటా నిల్వ వ్యవస్థ. S3 అనేది AWSలో డైమెన్షన్లెస్ ఆబ్జెక్ట్ స్టోరేజ్, వ్యాపారం కోసం డైమెన్షన్లెస్ డ్రాప్బాక్స్ లాంటిది.
స్నోఫ్లేక్ ఎలా పనిచేస్తుందో చూద్దాం, చల్లని ప్రారంభాన్ని ఊహిస్తూ. అంటే, ఒక డేటాబేస్ ఉంది, డేటా దానిలోకి లోడ్ చేయబడింది, రన్నింగ్ ప్రశ్నలు లేవు. దీని ప్రకారం, డేటాబేస్కు అభ్యర్థనలు లేకుంటే, మేము వేగవంతమైన ఇన్-మెమరీ మెటాడేటా సేవను (మొదటి బ్లాక్) పెంచాము. మరియు మేము S3 నిల్వను కలిగి ఉన్నాము, ఇక్కడ టేబుల్ డేటా నిల్వ చేయబడుతుంది, మైక్రోపార్టీషన్లు అని పిలవబడేవిగా విభజించబడింది. సరళత కోసం: పట్టిక లావాదేవీలను కలిగి ఉంటే, మైక్రోపార్టీషన్లు లావాదేవీల రోజులు. ప్రతి రోజు ప్రత్యేక మైక్రోపార్టీషన్, ప్రత్యేక ఫైల్. మరియు డేటాబేస్ ఈ మోడ్లో పనిచేస్తున్నప్పుడు, మీరు డేటా ఆక్రమించిన స్థలానికి మాత్రమే చెల్లిస్తారు. అంతేకాకుండా, ఒక్కో సీటుకు రేటు చాలా తక్కువగా ఉంటుంది (ముఖ్యంగా ముఖ్యమైన కుదింపును పరిగణనలోకి తీసుకుంటుంది). మెటాడేటా సేవ కూడా నిరంతరం పని చేస్తుంది, అయితే ప్రశ్నలను ఆప్టిమైజ్ చేయడానికి మీకు చాలా వనరులు అవసరం లేదు మరియు సేవను షేర్వేర్గా పరిగణించవచ్చు.
ఇప్పుడు ఒక వినియోగదారు మన డేటాబేస్కు వచ్చి SQL ప్రశ్నను పంపినట్లు ఊహించుకుందాం. SQL ప్రశ్న వెంటనే ప్రాసెసింగ్ కోసం మెటాడేటా సేవకు పంపబడుతుంది. దీని ప్రకారం, అభ్యర్థనను స్వీకరించిన తర్వాత, ఈ సేవ అభ్యర్థన, అందుబాటులో ఉన్న డేటా, వినియోగదారు అనుమతులను విశ్లేషిస్తుంది మరియు అన్నీ సరిగ్గా ఉంటే, అభ్యర్థనను ప్రాసెస్ చేయడానికి ఒక ప్రణాళికను రూపొందిస్తుంది.
తరువాత, సేవ కంప్యూటింగ్ క్లస్టర్ యొక్క ప్రారంభాన్ని ప్రారంభిస్తుంది. కంప్యూటింగ్ క్లస్టర్ అనేది గణనలను నిర్వహించే సర్వర్ల క్లస్టర్. అంటే, ఇది 1 సర్వర్, 2 సర్వర్లు, 4, 8, 16, 32 - మీకు కావలసినన్ని కలిగి ఉండే క్లస్టర్. మీరు ఒక అభ్యర్థనను విసిరారు మరియు ఈ క్లస్టర్ యొక్క ప్రారంభం వెంటనే ప్రారంభమవుతుంది. ఇది నిజంగా సెకన్లు పడుతుంది.
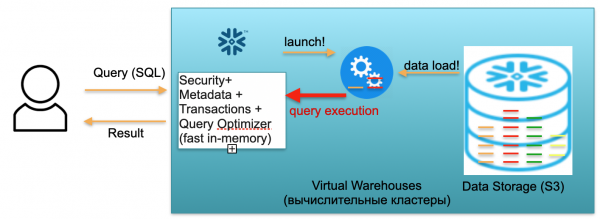
తరువాత, క్లస్టర్ ప్రారంభమైన తర్వాత, మీ అభ్యర్థనను ప్రాసెస్ చేయడానికి అవసరమైన మైక్రోపార్టీషన్లు S3 నుండి క్లస్టర్లోకి కాపీ చేయబడటం ప్రారంభమవుతుంది. అంటే, SQL ప్రశ్నను అమలు చేయడానికి మీకు ఒక టేబుల్ నుండి రెండు విభజనలు మరియు రెండవది నుండి ఒకటి అవసరమని ఊహించుకుందాం. ఈ సందర్భంలో, అవసరమైన మూడు విభజనలు మాత్రమే క్లస్టర్కు కాపీ చేయబడతాయి మరియు అన్ని పట్టికలు పూర్తిగా కావు. అందుకే, మరియు ఖచ్చితంగా ప్రతిదీ ఒక డేటా సెంటర్లో ఉన్నందున మరియు చాలా వేగవంతమైన ఛానెల్ల ద్వారా కనెక్ట్ చేయబడినందున, మొత్తం బదిలీ ప్రక్రియ చాలా త్వరగా జరుగుతుంది: సెకన్లలో, చాలా అరుదుగా నిమిషాల్లో, మేము కొన్ని భయంకరమైన అభ్యర్థనల గురించి మాట్లాడకపోతే . దీని ప్రకారం, మైక్రోపార్టీషన్లు కంప్యూటింగ్ క్లస్టర్కి కాపీ చేయబడతాయి మరియు పూర్తయిన తర్వాత, SQL ప్రశ్న ఈ కంప్యూటింగ్ క్లస్టర్పై అమలు చేయబడుతుంది. ఈ అభ్యర్థన యొక్క ఫలితం ఒక పంక్తి, అనేక పంక్తులు లేదా పట్టిక కావచ్చు - అవి వినియోగదారుకు బాహ్యంగా పంపబడతాయి, తద్వారా అతను దానిని డౌన్లోడ్ చేసుకోవచ్చు, అతని BI సాధనంలో ప్రదర్శించవచ్చు లేదా వేరే విధంగా ఉపయోగించవచ్చు.
ప్రతి SQL ప్రశ్న మునుపు లోడ్ చేయబడిన డేటా నుండి కంకరలను చదవడమే కాకుండా, డేటాబేస్లో కొత్త డేటాను లోడ్ చేస్తుంది/ఉత్పత్తి చేస్తుంది. అంటే, ఇది ఒక ప్రశ్న కావచ్చు, ఉదాహరణకు, మరొక పట్టికలో కొత్త రికార్డులను ఇన్సర్ట్ చేస్తుంది, ఇది కంప్యూటింగ్ క్లస్టర్లో కొత్త విభజన యొక్క రూపానికి దారి తీస్తుంది, ఇది స్వయంచాలకంగా ఒకే S3 నిల్వలో సేవ్ చేయబడుతుంది.
పైన వివరించిన దృశ్యం, వినియోగదారు రాక నుండి క్లస్టర్ను పెంచడం, డేటాను లోడ్ చేయడం, ప్రశ్నలను అమలు చేయడం, ఫలితాలను పొందడం వరకు, పెరిగిన వర్చువల్ కంప్యూటింగ్ క్లస్టర్, వర్చువల్ వేర్హౌస్ని ఉపయోగించి నిమిషాలకు రేటుతో చెల్లించబడుతుంది. AWS జోన్ మరియు క్లస్టర్ పరిమాణంపై ఆధారపడి రేటు మారుతూ ఉంటుంది, అయితే సగటున ఇది గంటకు కొన్ని డాలర్లు. నాలుగు యంత్రాల క్లస్టర్ రెండు యంత్రాల క్లస్టర్ కంటే రెండింతలు ఖరీదైనది మరియు ఎనిమిది యంత్రాల క్లస్టర్ ఇప్పటికీ రెండు రెట్లు ఖరీదైనది. అభ్యర్థనల సంక్లిష్టతను బట్టి 16, 32 యంత్రాల ఎంపికలు అందుబాటులో ఉన్నాయి. అయితే క్లస్టర్ వాస్తవానికి నడుస్తున్నప్పుడు మీరు ఆ నిమిషాలకు మాత్రమే చెల్లిస్తారు, ఎందుకంటే అభ్యర్థనలు లేనప్పుడు, మీరు మీ చేతులను తీసివేస్తారు మరియు 5-10 నిమిషాల నిరీక్షణ తర్వాత (కాన్ఫిగర్ చేయగల పరామితి) అది దానంతటదే వెళ్లిపోతుంది, వనరులను ఖాళీ చేయండి మరియు స్వేచ్ఛగా మారండి.
మీరు ఒక అభ్యర్థనను పంపినప్పుడు, క్లస్టర్ పాప్ అప్ అవుతుంది, ఒక నిమిషంలో, అది మరో నిమిషం, ఆపై షట్ డౌన్ చేయడానికి ఐదు నిమిషాలు లెక్కించబడుతుంది మరియు మీరు ఈ క్లస్టర్ యొక్క ఏడు నిమిషాల ఆపరేషన్ కోసం చెల్లించడం పూర్తి వాస్తవిక దృశ్యం, మరియు నెలలు మరియు సంవత్సరాలు కాదు.
సింగిల్-యూజర్ సెట్టింగ్లో స్నోఫ్లేక్ని ఉపయోగించి వివరించిన మొదటి దృశ్యం. ఇప్పుడు చాలా మంది వినియోగదారులు ఉన్నారని ఊహించుకుందాం, ఇది నిజమైన దృష్టాంతానికి దగ్గరగా ఉంటుంది.
పెద్ద సంఖ్యలో సాధారణ విశ్లేషణాత్మక SQL ప్రశ్నలతో మా డేటాబేస్ను నిరంతరం పేల్చే అనేక మంది విశ్లేషకులు మరియు పట్టిక నివేదికలు ఉన్నాయని చెప్పండి.
అదనంగా, మన దగ్గర ఇన్వెంటివ్ డేటా సైంటిస్ట్లు ఉన్నారని అనుకుందాం, వారు డేటాతో భయంకరమైన పనులను చేయడానికి ప్రయత్నిస్తున్నారు, పదుల టెరాబైట్లతో ఆపరేట్ చేస్తారు, బిలియన్ల మరియు ట్రిలియన్ల వరుసల డేటాను విశ్లేషించారు.
పైన వివరించిన రెండు రకాల పనిభారం కోసం, స్నోఫ్లేక్ వివిధ సామర్థ్యాల యొక్క అనేక స్వతంత్ర కంప్యూటింగ్ క్లస్టర్లను పెంచడానికి మిమ్మల్ని అనుమతిస్తుంది. అంతేకాకుండా, ఈ కంప్యూటింగ్ క్లస్టర్లు స్వతంత్రంగా పని చేస్తాయి, కానీ సాధారణ స్థిరమైన డేటాతో.
పెద్ద సంఖ్యలో లైట్ క్వెరీల కోసం, మీరు 2-3 చిన్న క్లస్టర్లను, ఒక్కొక్కటి దాదాపు 2 మెషీన్లను పెంచవచ్చు. ఈ ప్రవర్తనను ఇతర విషయాలతోపాటు, ఆటోమేటిక్ సెట్టింగ్లను ఉపయోగించి అమలు చేయవచ్చు. కాబట్టి మీరు, “స్నోఫ్లేక్, ఒక చిన్న క్లస్టర్ను పెంచండి. దానిపై లోడ్ ఒక నిర్దిష్ట పరామితి కంటే పెరిగితే, ఇదే రెండవ, మూడవదిగా పెంచండి. భారం తగ్గడం ప్రారంభించినప్పుడు, అదనపు మొత్తాన్ని చల్లార్చండి. తద్వారా ఎంత మంది విశ్లేషకులు వచ్చి నివేదికలు చూడటం ప్రారంభించినా, ప్రతి ఒక్కరికి తగినంత వనరులు ఉన్నాయి.
అదే సమయంలో, విశ్లేషకులు నిద్రలో ఉంటే మరియు నివేదికలను ఎవరూ చూడకపోతే, క్లస్టర్లు పూర్తిగా చీకటిగా మారవచ్చు మరియు మీరు వాటికి చెల్లించడం మానేస్తారు.
అదే సమయంలో, భారీ ప్రశ్నల కోసం (డేటా సైంటిస్ట్ల నుండి), మీరు 32 మెషీన్ల కోసం చాలా పెద్ద క్లస్టర్ను పెంచవచ్చు. ఈ క్లస్టర్ కూడా మీ భారీ అభ్యర్థన అమలులో ఉన్నప్పుడు ఆ నిమిషాలు మరియు గంటలకి మాత్రమే చెల్లించబడుతుంది.
పైన వివరించిన అవకాశం మిమ్మల్ని 2 మాత్రమే కాకుండా, మరిన్ని రకాల పనిభారాన్ని క్లస్టర్లుగా విభజించడానికి అనుమతిస్తుంది (ETL, పర్యవేక్షణ, రిపోర్ట్ మెటీరియలైజేషన్,...).
స్నోఫ్లేక్ని సంగ్రహిద్దాం. ఆధారం ఒక అందమైన ఆలోచన మరియు పని చేయదగిన అమలును మిళితం చేస్తుంది. ManyChatలో, మేము కలిగి ఉన్న మొత్తం డేటాను విశ్లేషించడానికి స్నోఫ్లేక్ని ఉపయోగిస్తాము. ఉదాహరణలో ఉన్నట్లుగా మనకు మూడు క్లస్టర్లు లేవు, కానీ 5 నుండి 9 వరకు, వివిధ పరిమాణాలు. కొన్ని టాస్క్ల కోసం మా వద్ద సంప్రదాయ 16-మెషిన్, 2-మెషిన్ మరియు సూపర్-స్మాల్ 1-మెషిన్ ఉన్నాయి. వారు విజయవంతంగా లోడ్ పంపిణీ మరియు మాకు చాలా సేవ్ అనుమతిస్తుంది.
డేటాబేస్ రీడింగ్ మరియు రైటింగ్ లోడ్ను విజయవంతంగా స్కేల్ చేస్తుంది. పఠన భారాన్ని మాత్రమే మోస్తున్న అదే "అరోరా"తో పోలిస్తే ఇది చాలా పెద్ద వ్యత్యాసం మరియు భారీ పురోగతి. స్నోఫ్లేక్ ఈ కంప్యూటింగ్ క్లస్టర్లతో మీ రచనా పనిభారాన్ని స్కేల్ చేయడానికి మిమ్మల్ని అనుమతిస్తుంది. అంటే, నేను చెప్పినట్లుగా, మేము ManyChatలో అనేక క్లస్టర్లను ఉపయోగిస్తాము, చిన్న మరియు అతి-చిన్న క్లస్టర్లు ప్రధానంగా ETL కోసం, డేటాను లోడ్ చేయడానికి ఉపయోగించబడతాయి. మరియు విశ్లేషకులు ఇప్పటికే మీడియం క్లస్టర్లలో నివసిస్తున్నారు, ఇవి ఖచ్చితంగా ETL లోడ్ ద్వారా ప్రభావితం కావు, కాబట్టి అవి చాలా త్వరగా పని చేస్తాయి.
దీని ప్రకారం, డేటాబేస్ OLAP పనులకు బాగా సరిపోతుంది. అయితే, దురదృష్టవశాత్తు, OLTP పనిభారానికి ఇది ఇంకా వర్తించదు. ముందుగా, ఈ డేటాబేస్ స్థూపాకారంగా ఉంటుంది, అన్ని తదుపరి పరిణామాలతో. రెండవది, ప్రతి అభ్యర్థన కోసం, అవసరమైతే, మీరు కంప్యూటింగ్ క్లస్టర్ను పెంచి, డేటాతో నింపే విధానం, దురదృష్టవశాత్తూ, OLTP లోడ్లకు ఇంకా తగినంత వేగంగా లేదు. OLAP టాస్క్ల కోసం సెకన్లు వేచి ఉండటం సాధారణం, కానీ OLTP టాస్క్లకు ఇది ఆమోదయోగ్యం కాదు; 100 ms మెరుగ్గా ఉంటుంది లేదా 10 ms మరింత మెరుగ్గా ఉంటుంది.
ఫలితం
డేటాబేస్ను స్టేట్లెస్ మరియు స్టేట్ఫుల్ భాగాలుగా విభజించడం ద్వారా సర్వర్లెస్ డేటాబేస్ సాధ్యమవుతుంది. పైన పేర్కొన్న అన్ని ఉదాహరణలలో, స్టేట్ఫుల్ భాగం, సాపేక్షంగా చెప్పాలంటే, S3లో మైక్రో-విభజనలను నిల్వ చేయడం మరియు స్టేట్లెస్ అనేది ఆప్టిమైజర్, మెటాడేటాతో పని చేయడం, స్వతంత్ర తేలికైన స్టేట్లెస్ సేవలుగా లేవనెత్తబడే భద్రతా సమస్యలను నిర్వహించడం వంటివి మీరు గమనించి ఉండవచ్చు.
SQL ప్రశ్నలను అమలు చేయడం అనేది స్నోఫ్లేక్ కంప్యూటింగ్ క్లస్టర్ల వంటి సర్వర్లెస్ మోడ్లో పాప్ అప్ చేయగల లైట్-స్టేట్ సేవలుగా కూడా గుర్తించబడుతుంది, అవసరమైన డేటాను మాత్రమే డౌన్లోడ్ చేస్తుంది, ప్రశ్నను అమలు చేయండి మరియు "బయటికి వెళ్లండి."
సర్వర్లెస్ ఉత్పత్తి స్థాయి డేటాబేస్లు ఇప్పటికే ఉపయోగం కోసం అందుబాటులో ఉన్నాయి, అవి పని చేస్తున్నాయి. ఈ సర్వర్లెస్ డేటాబేస్లు ఇప్పటికే OLAP టాస్క్లను నిర్వహించడానికి సిద్ధంగా ఉన్నాయి. దురదృష్టవశాత్తూ, పరిమితులు ఉన్నందున, OLTP పనుల కోసం అవి సూక్ష్మ నైపుణ్యాలతో ఉపయోగించబడతాయి. ఒకవైపు ఇది మైనస్. కానీ, మరోవైపు, ఇది ఒక అవకాశం. అరోరా పరిమితులు లేకుండా OLTP డేటాబేస్ను పూర్తిగా సర్వర్లెస్గా మార్చడానికి పాఠకులలో ఒకరు ఒక మార్గాన్ని కనుగొంటారు.
మీరు దీన్ని ఆసక్తికరంగా కనుగొన్నారని నేను ఆశిస్తున్నాను. సర్వర్లెస్ భవిష్యత్తు :)
మూలం: www.habr.com
