


สวัสดีฮับ! ในบทความนี้ ฉันต้องการพูดคุยเกี่ยวกับเครื่องมือที่ยอดเยี่ยมอย่างหนึ่งในการพัฒนากระบวนการประมวลผลข้อมูลแบบแบตช์ เช่น ในโครงสร้างพื้นฐานของ DWH ขององค์กรหรือ DataLake ของคุณ เราจะพูดถึง Apache Airflow (ต่อไปนี้จะเรียกว่า Airflow) Habré ถูกตัดความสนใจอย่างไม่ยุติธรรม และในส่วนหลัก ฉันจะพยายามโน้มน้าวคุณว่าอย่างน้อย Airflow ก็คุ้มค่าที่จะดูเมื่อเลือกตัวกำหนดเวลาสำหรับกระบวนการ ETL/ELT ของคุณ
ก่อนหน้านี้ ฉันเขียนบทความหลายชุดในหัวข้อ DWH ตอนที่ฉันทำงานที่ Tinkoff Bank ตอนนี้ฉันได้เป็นส่วนหนึ่งของทีม Mail.Ru Group และกำลังพัฒนาแพลตฟอร์มสำหรับการวิเคราะห์ข้อมูลในพื้นที่เล่นเกม จริงๆ แล้ว เมื่อมีข่าวสารและวิธีแก้ปัญหาที่น่าสนใจเกิดขึ้น ทีมของฉันและฉันจะพูดคุยที่นี่เกี่ยวกับแพลตฟอร์มของเราสำหรับการวิเคราะห์ข้อมูล
อารัมภบท
เอาล่ะ มาเริ่มกันเลย แอร์โฟลว์คืออะไร? นี่คือห้องสมุด (หรือ ) เพื่อพัฒนา วางแผน และติดตามกระบวนการทำงาน คุณสมบัติหลักของ Airflow: รหัส Python ใช้เพื่ออธิบาย (พัฒนา) กระบวนการ สิ่งนี้มีข้อดีมากมายสำหรับการจัดระเบียบโครงการและการพัฒนาของคุณ โดยพื้นฐานแล้ว โครงการ ETL ของคุณ (ตัวอย่าง) เป็นเพียงโครงการ Python และคุณสามารถจัดระเบียบได้ตามที่คุณต้องการ โดยคำนึงถึงลักษณะเฉพาะของโครงสร้างพื้นฐาน ขนาดทีม และ ข้อกำหนดอื่น ๆ ในทางดนตรีทุกอย่างก็เรียบง่าย ใช้สำหรับตัวอย่าง PyCharm + Git มันวิเศษมากและสะดวกสบายมาก!
ตอนนี้เรามาดูองค์ประกอบหลักของ Airflow กัน เมื่อเข้าใจแก่นแท้และวัตถุประสงค์แล้ว คุณสามารถจัดระเบียบสถาปัตยกรรมกระบวนการของคุณได้อย่างเหมาะสมที่สุด บางทีเอนทิตีหลักอาจเป็น Directed Acyclic Graph (ต่อไปนี้จะเรียกว่า DAG)
DAG
DAG คือการเชื่อมโยงงานของคุณอย่างมีความหมายซึ่งคุณต้องการทำให้เสร็จตามลำดับที่กำหนดไว้อย่างเคร่งครัดตามกำหนดการเฉพาะ Airflow มีเว็บอินเตอร์เฟสที่สะดวกสำหรับการทำงานกับ DAG และเอนทิตีอื่นๆ:
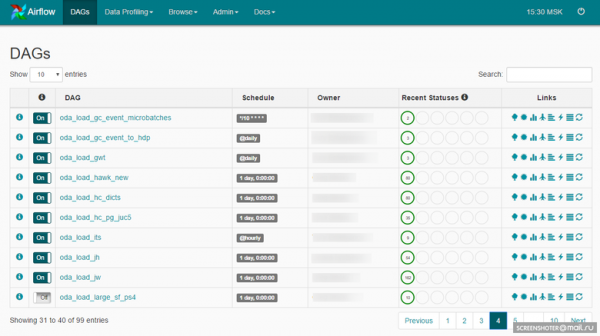
DAG อาจมีลักษณะเช่นนี้:
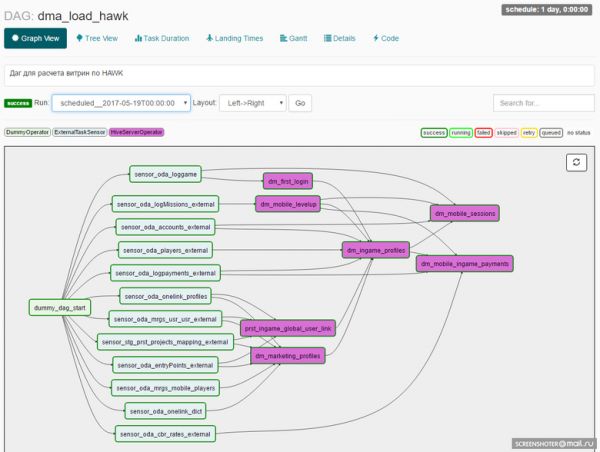
เมื่อออกแบบ DAG นักพัฒนาจะวางชุดของผู้ปฏิบัติงานที่จะสร้างงานภายใน DAG เรามาถึงหน่วยงานที่สำคัญอีกแห่งหนึ่ง: Airflow Operator
ผู้ประกอบการ
ตัวดำเนินการคือเอนทิตีตามอินสแตนซ์งานที่สร้างขึ้น ซึ่งอธิบายถึงสิ่งที่จะเกิดขึ้นระหว่างการดำเนินการอินสแตนซ์งาน มีชุดโอเปอเรเตอร์พร้อมใช้งานอยู่แล้ว ตัวอย่าง:
- BashOperator - ตัวดำเนินการสำหรับดำเนินการคำสั่งทุบตี
- PythonOperator - โอเปอเรเตอร์สำหรับการเรียกโค้ด Python
- EmailOperator — โอเปอเรเตอร์สำหรับการส่งอีเมล
- HTTPOperator - ตัวดำเนินการสำหรับการทำงานกับคำขอ http
- SqlOperator - ตัวดำเนินการสำหรับการรันโค้ด SQL
- เซ็นเซอร์เป็นตัวดำเนินการรอเหตุการณ์ (การมาถึงของเวลาที่กำหนด, ลักษณะของไฟล์ที่ต้องการ, บรรทัดในฐานข้อมูล, การตอบสนองจาก API ฯลฯ )
มีตัวดำเนินการเฉพาะเพิ่มเติม: DockerOperator, HiveOperator, S3FileTransferOperator, PrestoToMysqlOperator, SlackOperator
คุณยังสามารถพัฒนาตัวดำเนินการตามคุณลักษณะของคุณเองและใช้ในโครงการของคุณได้ ตัวอย่างเช่น เราสร้าง MongoDBToHiveViaHdfsTransfer ซึ่งเป็นตัวดำเนินการสำหรับส่งออกเอกสารจาก MongoDB ไปยัง Hive และตัวดำเนินการหลายตัวสำหรับการทำงานกับ : CHLoadFromHiveOperator และ CHTableLoaderOperator โดยพื้นฐานแล้ว ทันทีที่โปรเจ็กต์ใช้โค้ดที่สร้างจากคำสั่งพื้นฐานบ่อยครั้ง คุณสามารถคิดถึงการสร้างมันให้เป็นคำสั่งใหม่ได้ สิ่งนี้จะทำให้การพัฒนาเพิ่มเติมง่ายขึ้น และคุณจะขยายไลบรารีของผู้ปฏิบัติงานในโครงการ
ถัดไป อินสแตนซ์ของงานทั้งหมดเหล่านี้จำเป็นต้องได้รับการดำเนินการ และตอนนี้เราจะพูดถึงตัวกำหนดตารางเวลา
กำหนดการ
ตัวกำหนดเวลางานของ Airflow ถูกสร้างขึ้น . Celery เป็นไลบรารี Python ที่ให้คุณจัดระเบียบคิวรวมถึงการดำเนินการแบบอะซิงโครนัสและแบบกระจาย ในด้าน Airflow งานทั้งหมดจะแบ่งออกเป็นกลุ่ม พูลถูกสร้างขึ้นด้วยตนเอง โดยทั่วไป วัตถุประสงค์คือการจำกัดปริมาณงานในการทำงานกับแหล่งที่มาหรือเพื่อระบุงานภายใน DWH สามารถจัดการพูลได้ผ่านทางเว็บอินเตอร์เฟส:
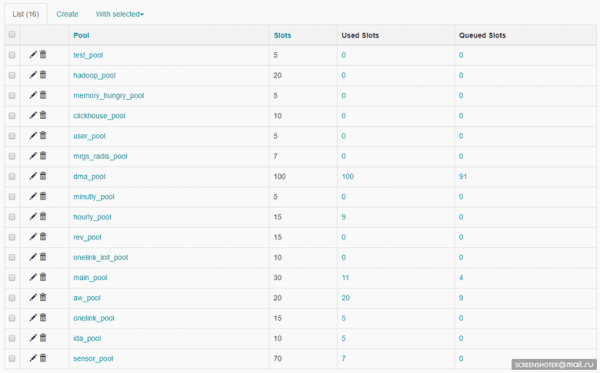
แต่ละพูลมีการจำกัดจำนวนสล็อต เมื่อสร้าง DAG มันจะได้รับพูล:
ALERT_MAILS = Variable.get("gv_mail_admin_dwh")
DAG_NAME = 'dma_load'
OWNER = 'Vasya Pupkin'
DEPENDS_ON_PAST = True
EMAIL_ON_FAILURE = True
EMAIL_ON_RETRY = True
RETRIES = int(Variable.get('gv_dag_retries'))
POOL = 'dma_pool'
PRIORITY_WEIGHT = 10
start_dt = datetime.today() - timedelta(1)
start_dt = datetime(start_dt.year, start_dt.month, start_dt.day)
default_args = {
'owner': OWNER,
'depends_on_past': DEPENDS_ON_PAST,
'start_date': start_dt,
'email': ALERT_MAILS,
'email_on_failure': EMAIL_ON_FAILURE,
'email_on_retry': EMAIL_ON_RETRY,
'retries': RETRIES,
'pool': POOL,
'priority_weight': PRIORITY_WEIGHT
}
dag = DAG(DAG_NAME, default_args=default_args)
dag.doc_md = __doc__พูลที่กำหนดในระดับ DAG สามารถแทนที่ได้ที่ระดับงาน
กระบวนการที่แยกจากกันคือ Scheduler มีหน้าที่รับผิดชอบในการกำหนดเวลางานทั้งหมดใน Airflow จริงๆ แล้ว Scheduler เกี่ยวข้องกับกลไกทั้งหมดในการตั้งค่างานเพื่อดำเนินการ งานต้องผ่านหลายขั้นตอนก่อนที่จะดำเนินการ:
- งานก่อนหน้านี้เสร็จสมบูรณ์ใน DAG แล้ว งานใหม่สามารถเข้าคิวได้
- คิวจะถูกจัดเรียงขึ้นอยู่กับลำดับความสำคัญของงาน (ลำดับความสำคัญสามารถควบคุมได้) และหากมีช่องว่างในพูล งานก็สามารถเริ่มดำเนินการได้
- หากมีคื่นฉ่ายคนงานอิสระงานจะถูกส่งไปยังงานนั้น งานที่คุณตั้งโปรแกรมไว้ในปัญหาจะเริ่มต้นขึ้นโดยใช้ตัวดำเนินการอย่างใดอย่างหนึ่ง
ง่ายพอ
ตัวกำหนดเวลาทำงานบนชุดของ DAG ทั้งหมดและงานทั้งหมดภายใน DAG
เพื่อให้ Scheduler เริ่มทำงานกับ DAG นั้น DAG จำเป็นต้องกำหนดเวลา:
dag = DAG(DAG_NAME, default_args=default_args, schedule_interval='@hourly')มีชุดค่าที่ตั้งล่วงหน้าสำเร็จรูป: @once, @hourly, @daily, @weekly, @monthly, @yearly.
คุณยังสามารถใช้นิพจน์ cron ได้:
dag = DAG(DAG_NAME, default_args=default_args, schedule_interval='*/10 * * * *')วันที่ดำเนินการ
เพื่อให้เข้าใจวิธีการทำงานของ Airflow สิ่งสำคัญคือต้องเข้าใจว่าวันที่ดำเนินการสำหรับ DAG คืออะไร ใน Airflow นั้น DAG มีมิติวันที่ดำเนินการ กล่าวคือ ขึ้นอยู่กับตารางการทำงานของ DAG อินสแตนซ์ของงานจะถูกสร้างขึ้นสำหรับวันที่ดำเนินการแต่ละวัน และสำหรับวันที่ดำเนินการแต่ละวัน สามารถดำเนินการงานซ้ำได้ - หรือ ตัวอย่างเช่น DAG สามารถทำงานพร้อมกันในวันที่ดำเนินการหลายๆ วัน นี่แสดงให้เห็นอย่างชัดเจนที่นี่:
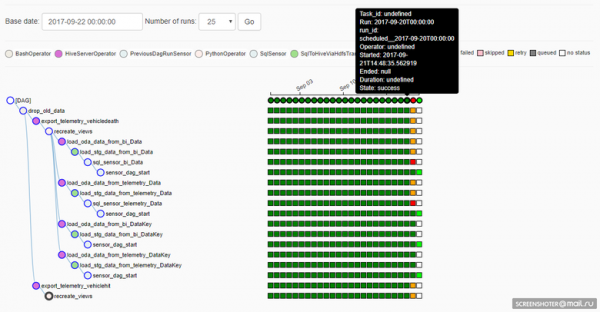
น่าเสียดาย (หรืออาจโชคดี: ขึ้นอยู่กับสถานการณ์) หากการดำเนินงานใน DAG ได้รับการแก้ไข การดำเนินการในวันดำเนินการครั้งก่อนจะดำเนินการโดยคำนึงถึงการปรับเปลี่ยน นี่เป็นสิ่งที่ดีถ้าคุณต้องการคำนวณข้อมูลใหม่ในช่วงที่ผ่านมาโดยใช้อัลกอริธึมใหม่ แต่มันไม่ดีเพราะความสามารถในการทำซ้ำของผลลัพธ์หายไป (แน่นอนว่าไม่มีใครรบกวนคุณในการส่งคืนซอร์สโค้ดเวอร์ชันที่ต้องการจาก Git และคำนวณว่าอะไร คุณต้องการครั้งเดียว ในแบบที่คุณต้องการ)
กำลังสร้างงาน
การใช้งาน DAG คือโค้ดใน Python ดังนั้นเราจึงมีวิธีที่สะดวกมากในการลดจำนวนโค้ดเมื่อทำงานกับซอร์สที่แบ่งส่วน สมมติว่าคุณมีชาร์ด MySQL สามชาร์ดเป็นแหล่งที่มา คุณต้องปีนเข้าไปในแต่ละชาร์ดและรับข้อมูลบางส่วน ยิ่งกว่านั้นอย่างเป็นอิสระและคู่ขนานกัน รหัส Python ใน DAG อาจมีลักษณะดังนี้:
connection_list = lv.get('connection_list')
export_profiles_sql = '''
SELECT
id,
user_id,
nickname,
gender,
{{params.shard_id}} as shard_id
FROM profiles
'''
for conn_id in connection_list:
export_profiles = SqlToHiveViaHdfsTransfer(
task_id='export_profiles_from_' + conn_id,
sql=export_profiles_sql,
hive_table='stg.profiles',
overwrite=False,
tmpdir='/data/tmp',
conn_id=conn_id,
params={'shard_id': conn_id[-1:], },
compress=None,
dag=dag
)
export_profiles.set_upstream(exec_truncate_stg)
export_profiles.set_downstream(load_profiles)DAG มีลักษณะดังนี้:
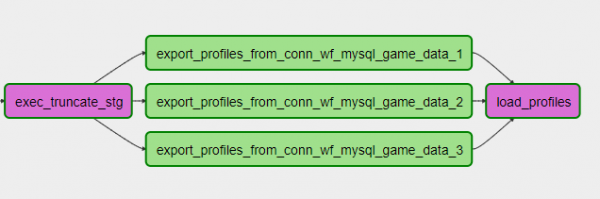
ในกรณีนี้ คุณสามารถเพิ่มหรือลบชาร์ดได้โดยเพียงแค่ปรับการตั้งค่าและอัปเดต DAG สะดวกสบาย!
คุณยังสามารถใช้การสร้างโค้ดที่ซับซ้อนมากขึ้นได้ เช่น ทำงานกับแหล่งที่มาในรูปแบบของฐานข้อมูลหรืออธิบายโครงสร้างตาราง อัลกอริทึมสำหรับการทำงานกับตาราง และเมื่อคำนึงถึงคุณสมบัติของโครงสร้างพื้นฐาน DWH จะสร้างกระบวนการ สำหรับการโหลด N ตารางลงในที่เก็บข้อมูลของคุณ หรือ ตัวอย่างเช่น การทำงานกับ API ที่ไม่รองรับการทำงานกับพารามิเตอร์ในรูปแบบของรายการ คุณสามารถสร้างงาน N งานใน DAG จากรายการนี้ จำกัดความขนานของคำขอใน API ไว้ที่พูล และขูด ข้อมูลที่จำเป็นจาก API ยืดหยุ่นได้!
ที่เก็บ
Airflow มีพื้นที่เก็บข้อมูลแบ็กเอนด์ของตัวเอง ฐานข้อมูล (อาจเป็น MySQL หรือ Postgres เรามี Postgres) ซึ่งจัดเก็บสถานะของงาน, DAG, การตั้งค่าการเชื่อมต่อ, ตัวแปรส่วนกลาง ฯลฯ ฯลฯ ในที่นี้ ฉันอยากจะบอกว่า พื้นที่เก็บข้อมูลใน Airflow นั้นง่ายมาก (ประมาณ 20 ตาราง) และสะดวกถ้าคุณต้องการสร้างกระบวนการของคุณเองนอกเหนือจากนั้น ฉันจำตาราง 100500 ตารางในที่เก็บ Informatica ได้ ซึ่งต้องศึกษาเป็นเวลานานก่อนที่จะเข้าใจวิธีสร้างแบบสอบถาม
การตรวจสอบ
เนื่องจากความเรียบง่ายของพื้นที่เก็บข้อมูล คุณสามารถสร้างกระบวนการตรวจสอบงานที่สะดวกสำหรับคุณได้ เราใช้แผ่นจดบันทึกใน Zeppelin โดยเราจะดูสถานะของงาน:
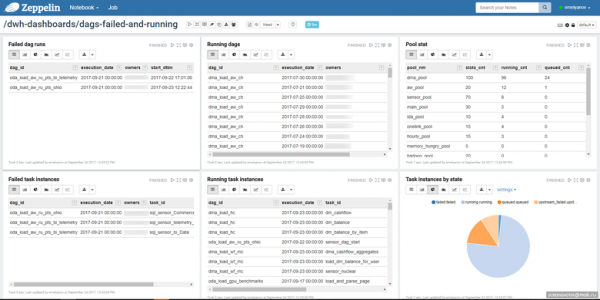
นี่อาจเป็นเว็บอินเตอร์เฟสของ Airflow เอง:
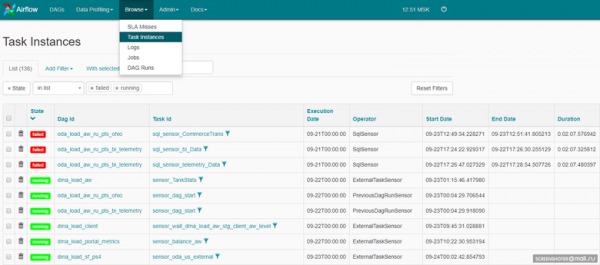
รหัส Airflow เป็นโอเพ่นซอร์ส ดังนั้นเราจึงเพิ่มการแจ้งเตือนไปยัง Telegram หากเกิดข้อผิดพลาด แต่ละอินสแตนซ์ที่กำลังทำงานอยู่จะสแปมกลุ่มใน Telegram ซึ่งทีมพัฒนาและสนับสนุนทั้งหมดประกอบด้วย
เราได้รับการตอบกลับทันทีผ่านทาง Telegram (หากจำเป็น) และผ่านทาง Zeppelin เราได้รับภาพรวมของงานใน Airflow
เบ็ดเสร็จ
Airflow ส่วนใหญ่เป็นโอเพ่นซอร์ส และคุณไม่ควรคาดหวังถึงปาฏิหาริย์จากสิ่งนี้ เตรียมพร้อมที่จะสละเวลาและความพยายามในการสร้างโซลูชันที่ได้ผล บรรลุเป้าหมายได้ เชื่อฉันสิ มันคุ้มค่า ความเร็วของการพัฒนา ความยืดหยุ่น ความง่ายในการเพิ่มกระบวนการใหม่ - คุณจะชอบมัน แน่นอนคุณต้องให้ความสนใจเป็นอย่างมากกับการจัดโครงการความมั่นคงของ Airflow เอง: ปาฏิหาริย์จะไม่เกิดขึ้น
ตอนนี้เรามี Airflow ทำงานทุกวัน ประมาณ 6,5 พันงาน. พวกเขาค่อนข้างแตกต่างกันในลักษณะตัวละคร มีงานในการโหลดข้อมูลลงใน DWH หลักจากแหล่งที่มาที่แตกต่างกันและเฉพาะเจาะจง มีงานคำนวณหน้าร้านภายใน DWH หลัก มีงานเผยแพร่ข้อมูลลงใน DWH ที่รวดเร็ว มีงานมากมาย - และ Airflow เคี้ยวมันจนหมดวันแล้ววันเล่า พูดเป็นตัวเลขนี่คือ 2,3 พัน งาน ELT ที่มีความซับซ้อนต่างกันภายใน DWH (Hadoop) ประมาณ 2,5 ร้อยฐานข้อมูล แหล่งที่มานี้เป็นทีมงานจาก นักพัฒนา ETL 4 คนซึ่งแบ่งออกเป็นการประมวลผลข้อมูล ETL ใน DWH และการประมวลผลข้อมูล ELT ภายใน DWH และแน่นอนมากกว่านั้น ผู้ดูแลระบบคนหนึ่งซึ่งเกี่ยวข้องกับโครงสร้างพื้นฐานของการบริการ
แผนสำหรับอนาคต
จำนวนกระบวนการเพิ่มขึ้นอย่างหลีกเลี่ยงไม่ได้ และสิ่งสำคัญที่เราจะทำในแง่ของโครงสร้างพื้นฐาน Airflow คือการปรับขนาด เราต้องการสร้างคลัสเตอร์ Airflow จัดสรรขาคู่หนึ่งให้กับพนักงาน Celery และสร้างส่วนหัวที่ทำซ้ำในตัวเองด้วยกระบวนการกำหนดเวลางานและพื้นที่เก็บข้อมูล
ถ้อยคำส
แน่นอนว่านี่ไม่ใช่ทุกอย่างที่ฉันอยากจะบอกเกี่ยวกับ Airflow แต่ฉันพยายามเน้นประเด็นหลัก ความอยากอาหารมาพร้อมกับการกิน ลองแล้วจะติดใจ :)
ที่มา: will.com
