

คุณจะแปลข้อกำหนดทางธุรกิจเป็นโครงสร้างข้อมูลเฉพาะได้อย่างไรโดยใช้ตัวอย่างการออกแบบฐานข้อมูล Messenger ตั้งแต่เริ่มต้น
- ส่วนที่ 1: การออกแบบโครงฐาน

ฐานของเราจะไม่ใหญ่และกระจัดกระจาย หรือ แต่ "เป็นเช่นนั้น" แต่ก็ดี - ใช้งานได้รวดเร็วและ พอดีกับเซิร์ฟเวอร์เดียว PostgreSQL - เพื่อให้คุณสามารถปรับใช้อินสแตนซ์แยกต่างหากของบริการที่ด้านข้างได้ เป็นต้น
ดังนั้น เราจะไม่พูดถึงปัญหาของการแบ่งส่วน การจำลองแบบ และการกระจายทางภูมิศาสตร์ แต่จะมุ่งเน้นไปที่โซลูชันวงจรภายในฐานข้อมูล
ขั้นตอนที่ 1: ข้อมูลเฉพาะทางธุรกิจบางอย่าง
เราจะไม่ออกแบบข้อความของเราแบบนามธรรม แต่จะรวมเข้ากับสภาพแวดล้อม . นั่นคือคนของเราไม่ "เพียงแค่โต้ตอบ" แต่สื่อสารกันในบริบทของการแก้ปัญหาทางธุรกิจบางอย่าง
แล้วธุรกิจมีงานอะไรบ้าง.. มาดูตัวอย่าง วาซิลี หัวหน้าแผนกพัฒนากันดีกว่า
- “นิโคไล สำหรับงานนี้ เราต้องการแผ่นแปะวันนี้!”
ซึ่งหมายความว่าการโต้ตอบสามารถดำเนินการได้ในบริบทของบางส่วน เอกสาร. - “Kolya คุณจะไป Dota เย็นนี้ไหม?”
นั่นคือแม้แต่คู่สนทนาเพียงคู่เดียวก็สามารถสื่อสารพร้อมกันได้ ในหัวข้อต่างๆ. - “ปีเตอร์ นิโคเลย์ ดูในไฟล์แนบเพื่อดูรายการราคาสำหรับเซิร์ฟเวอร์ใหม่”
ดังนั้นข้อความเดียวก็สามารถมีได้ ผู้รับหลายคน. ในกรณีนี้อาจมีข้อความประกอบด้วย ไฟล์ที่แนบมา. - “เซมยอนลองดูด้วย”
และควรมีโอกาสที่จะเข้าสู่การติดต่อโต้ตอบที่มีอยู่ เชิญสมาชิกใหม่.
มาดูรายการความต้องการที่ "ชัดเจน" กันในตอนนี้
โดยไม่เข้าใจถึงลักษณะเฉพาะของปัญหาที่ประยุกต์ใช้และข้อจำกัดที่ได้รับ การออกแบบ มีประสิทธิภาพ สคีมาฐานข้อมูลเพื่อแก้ไขมันแทบจะเป็นไปไม่ได้เลย
ขั้นตอนที่ 2: วงจรลอจิกน้อยที่สุด
จนถึงตอนนี้ ทุกอย่างทำงานคล้ายกับการติดต่อทางอีเมล ซึ่งเป็นเครื่องมือทางธุรกิจแบบดั้งเดิม ใช่ ปัญหาทางธุรกิจหลายอย่างแบบ "อัลกอริทึม" มีความคล้ายคลึงกัน ดังนั้นเครื่องมือในการแก้ปัญหาจึงมีโครงสร้างที่คล้ายคลึงกัน
มาแก้ไขไดอะแกรมเชิงตรรกะของความสัมพันธ์เอนทิตีที่ได้รับแล้ว เพื่อให้โมเดลของเราเข้าใจง่ายขึ้น เราจะใช้ตัวเลือกการแสดงผลแบบดั้งเดิมที่สุด โดยไม่มีภาวะแทรกซ้อนของสัญลักษณ์ UML หรือ IDEF:
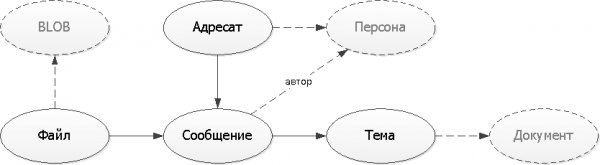
ในตัวอย่างของเรา บุคคล เอกสาร และ "เนื้อหา" ไบนารีของไฟล์เป็นเอนทิตี "ภายนอก" ที่มีอยู่อย่างอิสระโดยไม่มีบริการของเรา ดังนั้นในอนาคตเราจะมองว่าพวกเขาเป็นเพียงลิงก์ "ที่ไหนสักแห่ง" ของ UUID
วาด ไดอะแกรมง่ายที่สุด - ผู้คนส่วนใหญ่ที่คุณจะแสดงให้พวกเขาเห็นไม่ใช่ผู้เชี่ยวชาญในการอ่าน UML/IDEF แต่ต้องแน่ใจว่าได้วาด
ขั้นตอนที่ 3: ร่างโครงสร้างตาราง
เกี่ยวกับชื่อตารางและฟิลด์ชื่อเขตข้อมูลและตาราง "รัสเซีย" สามารถปฏิบัติได้แตกต่างกัน แต่นี่เป็นเรื่องของรสนิยม เพราะว่า ไม่มีนักพัฒนาต่างชาติและ PostgreSQL อนุญาตให้เราตั้งชื่อได้แม้จะเป็นอักษรอียิปต์โบราณก็ตาม อยู่ในเครื่องหมายคำพูดจากนั้น เราต้องการตั้งชื่อวัตถุให้ชัดเจนและชัดเจนเพื่อไม่ให้เกิดความคลาดเคลื่อน
เนื่องจากมีคนจำนวนมากเขียนข้อความถึงเราพร้อมกัน บางคนอาจทำเช่นนี้ด้วยซ้ำ ออฟไลน์ดังนั้นตัวเลือกที่ง่ายที่สุดคือ ใช้ UUID เป็นตัวระบุ ไม่เพียงแต่สำหรับหน่วยงานภายนอกเท่านั้น แต่ยังรวมถึงวัตถุทั้งหมดภายในบริการของเราด้วย ยิ่งไปกว่านั้น ยังสามารถสร้างขึ้นได้แม้กระทั่งในฝั่งไคลเอ็นต์ ซึ่งจะช่วยให้เรารองรับการส่งข้อความเมื่อฐานข้อมูลไม่พร้อมใช้งานชั่วคราว และโอกาสที่จะเกิดการชนกันก็ต่ำมาก
โครงสร้างตารางแบบร่างในฐานข้อมูลของเราจะมีลักษณะดังนี้:
ตาราง : RU
CREATE TABLE "Тема"(
"Тема"
uuid
PRIMARY KEY
, "Документ"
uuid
, "Название"
text
);
CREATE TABLE "Сообщение"(
"Сообщение"
uuid
PRIMARY KEY
, "Тема"
uuid
, "Автор"
uuid
, "ДатаВремя"
timestamp
, "Текст"
text
);
CREATE TABLE "Адресат"(
"Сообщение"
uuid
, "Персона"
uuid
, PRIMARY KEY("Сообщение", "Персона")
);
CREATE TABLE "Файл"(
"Файл"
uuid
PRIMARY KEY
, "Сообщение"
uuid
, "BLOB"
uuid
, "Имя"
text
);ตาราง: TH
CREATE TABLE theme(
theme
uuid
PRIMARY KEY
, document
uuid
, title
text
);
CREATE TABLE message(
message
uuid
PRIMARY KEY
, theme
uuid
, author
uuid
, dt
timestamp
, body
text
);
CREATE TABLE message_addressee(
message
uuid
, person
uuid
, PRIMARY KEY(message, person)
);
CREATE TABLE message_file(
file
uuid
PRIMARY KEY
, message
uuid
, content
uuid
, filename
text
);สิ่งที่ง่ายที่สุดในการอธิบายรูปแบบคือการเริ่ม "คลาย" กราฟการเชื่อมต่อ จากตารางที่ไม่ได้อ้างอิง ตัวเองไม่มีใคร
ขั้นตอนที่ 4: ค้นหาความต้องการที่ไม่ชัดเจน
เพียงเท่านี้เราได้ออกแบบฐานข้อมูลที่คุณสามารถเขียนได้อย่างสมบูรณ์แบบและ อย่างใด เพื่ออ่าน
เรามาสวมบทบาทเป็นผู้ใช้บริการของเรา - เราต้องการทำอะไรกับมัน?
- ข้อความล่าสุด
มัน เรียงตามลำดับเวลา การลงทะเบียนข้อความ "ของฉัน" ตามเกณฑ์ต่างๆ ที่ฉันเป็นหนึ่งในผู้รับ, ที่ฉันเป็นคนเขียน, ที่พวกเขาเขียนถึงฉันแล้วฉันไม่ตอบ, ที่พวกเขาไม่ตอบฉัน, ... - ผู้เข้าร่วมจดหมาย
ใครบ้างที่มีส่วนร่วมในการสนทนาที่ยาวนานนี้?
โครงสร้างของเราช่วยให้เราสามารถแก้ไขปัญหาทั้งสองนี้ "โดยทั่วไป" แต่ไม่รวดเร็ว ปัญหาคือว่าสำหรับการเรียงลำดับภายในงานแรก ไม่สามารถสร้างดัชนีได้เหมาะสำหรับผู้เข้าร่วมแต่ละคน (และคุณจะต้องแยกบันทึกทั้งหมด) และเพื่อแก้ไขรายการที่สองที่คุณต้องการ แยกข้อความทั้งหมด ในหัวข้อนี้
งานของผู้ใช้ที่ไม่ได้ตั้งใจอาจทำให้เป็นตัวหนา ข้ามผลผลิต.
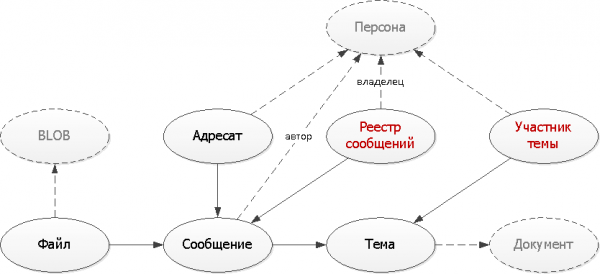
ขั้นตอนที่ 5: การทำให้เป็นปกติอย่างชาญฉลาด
ปัญหาของเราทั้งสองจะได้รับการแก้ไขด้วยตารางเพิ่มเติมที่เราจะแก้ไข ส่วนที่ซ้ำกันของข้อมูลจำเป็นต้องสร้างดัชนีที่เหมาะสมกับงานของเรา
ตาราง : RU
CREATE TABLE "РеестрСообщений"(
"Владелец"
uuid
, "ТипРеестра"
smallint
, "ДатаВремя"
timestamp
, "Сообщение"
uuid
, PRIMARY KEY("Владелец", "ТипРеестра", "Сообщение")
);
CREATE INDEX ON "РеестрСообщений"("Владелец", "ТипРеестра", "ДатаВремя" DESC);
CREATE TABLE "УчастникТемы"(
"Тема"
uuid
, "Персона"
uuid
, PRIMARY KEY("Тема", "Персона")
);ตาราง: TH
CREATE TABLE message_registry(
owner
uuid
, registry
smallint
, dt
timestamp
, message
uuid
, PRIMARY KEY(owner, registry, message)
);
CREATE INDEX ON message_registry(owner, registry, dt DESC);
CREATE TABLE theme_participant(
theme
uuid
, person
uuid
, PRIMARY KEY(theme, person)
);ที่นี่เราได้ใช้วิธีการทั่วไปสองวิธีที่ใช้ในการสร้างตารางเสริม:
- การคูณบันทึก
การใช้บันทึกข้อความเริ่มต้นหนึ่งบันทึก เราสร้างบันทึกการติดตามผลหลายรายการในการลงทะเบียนประเภทต่างๆ สำหรับเจ้าของที่แตกต่างกัน - ทั้งสำหรับผู้ส่งและผู้รับ แต่ตอนนี้การลงทะเบียนแต่ละรายการอยู่ในดัชนี - ในกรณีทั่วไปเราต้องการดูเฉพาะหน้าแรกเท่านั้น - บันทึกที่ไม่ซ้ำ
ทุกครั้งที่คุณส่งข้อความภายในหัวข้อใดหัวข้อหนึ่ง เพียงตรวจสอบว่ามีรายการดังกล่าวอยู่แล้วหรือไม่ ถ้าไม่เช่นนั้น ให้เพิ่มลงใน "พจนานุกรม" ของเรา
ในส่วนถัดไปของบทความเราจะพูดถึง เข้าสู่โครงสร้างของฐานข้อมูลของเรา
ที่มา: will.com
