

ปัจจุบัน บริการ Bitrix24 ไม่มีการรับส่งข้อมูลหลายร้อยกิกะบิต และก็ไม่มีเซิร์ฟเวอร์จำนวนมาก (แม้ว่าแน่นอนว่ามีอยู่ไม่กี่แห่งก็ตาม) แต่สำหรับลูกค้าหลายรายนี่เป็นเครื่องมือหลักในการทำงานในบริษัทและเป็นแอปพลิเคชันที่สำคัญต่อธุรกิจอย่างแท้จริง ดังนั้นจึงไม่มีทางที่จะล้มลงได้ จะเกิดอะไรขึ้นหากเกิดความผิดพลาด แต่บริการ "ฟื้นตัว" ได้อย่างรวดเร็วจนไม่มีใครสังเกตเห็นอะไรเลย และเป็นไปได้อย่างไรที่จะดำเนินการเฟลโอเวอร์โดยไม่สูญเสียคุณภาพของงานและจำนวนไคลเอนต์? Alexander Demidov ผู้อำนวยการฝ่ายบริการคลาวด์ที่ Bitrix24 พูดในบล็อกของเราเกี่ยวกับการพัฒนาระบบการจองตลอด 7 ปีของผลิตภัณฑ์

“เราเปิดตัว Bitrix24 ในรูปแบบ SaaS เมื่อ 7 ปีที่แล้ว ปัญหาหลักน่าจะเป็นดังต่อไปนี้: ก่อนที่จะเปิดตัวต่อสาธารณะในชื่อ SaaS ผลิตภัณฑ์นี้มีอยู่ในรูปแบบของโซลูชันชนิดบรรจุกล่อง ลูกค้าซื้อมันจากเรา โฮสต์มันไว้บนเซิร์ฟเวอร์ ตั้งค่าพอร์ทัลองค์กร ซึ่งเป็นโซลูชั่นทั่วไปสำหรับการสื่อสารของพนักงาน การจัดเก็บไฟล์ การจัดการงาน CRM แค่นั้นเอง และภายในปี 2012 เราตัดสินใจว่าต้องการเปิดตัวเป็น SaaS โดยบริหารจัดการด้วยตนเอง เพื่อให้มั่นใจถึงความทนทานต่อข้อผิดพลาดและความน่าเชื่อถือ เราได้รับประสบการณ์ตลอดเส้นทาง เพราะจนถึงตอนนั้นเรายังไม่มีเลย เราเป็นเพียงผู้ผลิตซอฟต์แวร์เท่านั้น ไม่ใช่ผู้ให้บริการ
เมื่อเปิดตัวบริการ เราเข้าใจดีว่าสิ่งที่สำคัญที่สุดคือการรับประกันความทนทานต่อข้อผิดพลาด ความน่าเชื่อถือ และความพร้อมใช้งานอย่างต่อเนื่องของบริการ เพราะหากคุณมีเว็บไซต์ธรรมดาๆ ทั่วไป ร้านค้า เป็นต้น และมันตกอยู่กับคุณและอยู่ที่นั่นเพื่อ หนึ่งชั่วโมง มีเพียงคุณเท่านั้นที่ต้องทนทุกข์ทรมาน คุณสูญเสียคำสั่งซื้อ คุณสูญเสียลูกค้า แต่สำหรับลูกค้าของคุณเอง นี่ไม่ใช่เรื่องสำคัญสำหรับเขามากนัก แน่นอนว่าเขาอารมณ์เสีย แต่เขาไปซื้อมันจากเว็บไซต์อื่น และหากนี่คือแอปพลิเคชันที่งานทั้งหมดภายในบริษัท การสื่อสาร การตัดสินใจเชื่อมโยงกัน สิ่งที่สำคัญที่สุดคือการได้รับความไว้วางใจจากผู้ใช้ นั่นคือ ไม่ทำให้พวกเขาผิดหวังและไม่ล้มลง เพราะงานทุกอย่างหยุดได้ถ้าบางอย่างข้างในไม่ทำงาน
Bitrix.24 เป็น SaaS
เราประกอบรถต้นแบบคันแรกหนึ่งปีก่อนที่จะเปิดตัวสู่สาธารณะในปี 2011 เราประกอบมันในเวลาประมาณหนึ่งสัปดาห์ ดูมัน หมุนมัน - มันใช้งานได้ด้วยซ้ำ นั่นคือ คุณสามารถเข้าไปในแบบฟอร์ม ป้อนชื่อของพอร์ทัลที่นั่น พอร์ทัลใหม่จะเปิดขึ้น และฐานผู้ใช้จะถูกสร้างขึ้น เราดูมัน ประเมินผลิตภัณฑ์ในหลักการ ทิ้งมัน และปรับแต่งมันอย่างต่อเนื่องตลอดทั้งปี เนื่องจากเรามีงานใหญ่: เราไม่ต้องการสร้างฐานโค้ดที่แตกต่างกันสองฐาน เราไม่ต้องการสนับสนุนผลิตภัณฑ์แพ็คเกจที่แยกจากกัน หรือโซลูชันคลาวด์ที่แยกจากกัน - เราต้องการทำทุกอย่างด้วยโค้ดเดียว
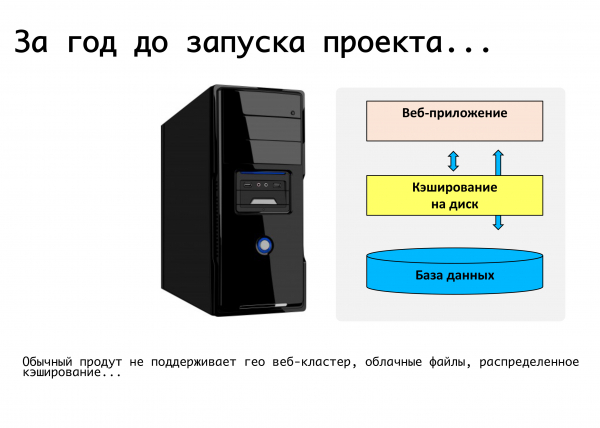
เว็บแอปพลิเคชันทั่วไปในขณะนั้นคือเซิร์ฟเวอร์ตัวหนึ่งที่รันโค้ด PHP ฐานข้อมูล mysql ไฟล์ถูกอัพโหลด เอกสาร รูปภาพถูกใส่ไว้ในโฟลเดอร์อัพโหลด ทั้งหมดนี้ใช้งานได้ อนิจจา เป็นไปไม่ได้ที่จะเปิดตัวบริการเว็บที่มีความเสถียรอย่างยิ่งยวดโดยใช้สิ่งนี้ ที่นั่น ไม่รองรับแคชแบบกระจาย ไม่รองรับการจำลองแบบฐานข้อมูล
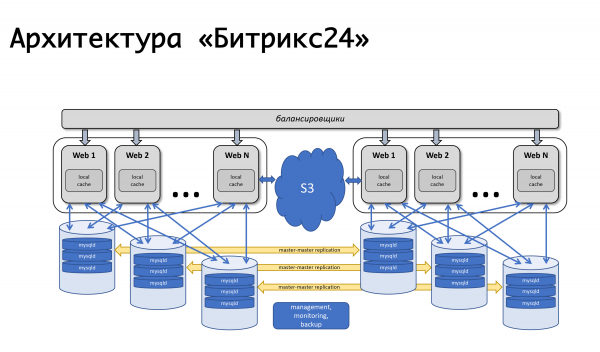
เรากำหนดข้อกำหนด: นี่คือความสามารถในการตั้งอยู่ในสถานที่ที่แตกต่างกัน รองรับการจำลอง และตั้งอยู่ในศูนย์ข้อมูลที่มีการกระจายทางภูมิศาสตร์ที่แตกต่างกัน แยกตรรกะของผลิตภัณฑ์และที่ที่จริงแล้วคือพื้นที่จัดเก็บข้อมูล สามารถปรับขนาดไดนามิกตามโหลด และทนต่อสถิตยศาสตร์โดยสิ้นเชิง จากการพิจารณาเหล่านี้ ในความเป็นจริงแล้ว ข้อกำหนดสำหรับผลิตภัณฑ์ก็เกิดขึ้น ซึ่งเราได้ปรับปรุงตลอดทั้งปี ในช่วงเวลานี้ ในแพลตฟอร์มซึ่งกลายเป็นหนึ่งเดียว - สำหรับโซลูชันแบบกล่องสำหรับบริการของเราเอง - เราได้ให้การสนับสนุนสำหรับสิ่งเหล่านั้นที่เราต้องการ รองรับการจำลองแบบ mysql ในระดับผลิตภัณฑ์นั่นคือนักพัฒนาที่เขียนโค้ดไม่คิดว่าคำขอของเขาจะถูกแจกจ่ายอย่างไร เขาใช้ API ของเรา และเรารู้วิธีกระจายคำขอเขียนและอ่านระหว่างผู้เชี่ยวชาญอย่างถูกต้อง และทาส
เราได้ให้การสนับสนุนในระดับผลิตภัณฑ์สำหรับพื้นที่จัดเก็บออบเจ็กต์บนคลาวด์ต่างๆ: พื้นที่เก็บข้อมูลของ Google, Amazon s3 รวมถึงการสนับสนุนสำหรับ open stack Swift ดังนั้น นี่จึงสะดวกทั้งสำหรับเราในฐานะบริการและสำหรับนักพัฒนาที่ทำงานกับโซลูชันแบบแพ็กเกจ หากพวกเขาใช้ API ของเราในการทำงาน พวกเขาจะไม่คิดว่าท้ายที่สุดแล้วไฟล์จะถูกบันทึกไว้ที่ใด ในเครื่องบนระบบไฟล์หรือ ในการจัดเก็บไฟล์อ็อบเจ็กต์
ด้วยเหตุนี้ เราจึงตัดสินใจทันทีว่าจะจองในระดับศูนย์ข้อมูลทั้งหมด ในปี 2012 เราเปิดตัวบน Amazon AWS ทั้งหมดเนื่องจากเรามีประสบการณ์กับแพลตฟอร์มนี้อยู่แล้ว - เว็บไซต์ของเราเองก็โฮสต์อยู่ที่นั่น เราสนใจความจริงที่ว่าในแต่ละภูมิภาค Amazon มีโซนความพร้อมใช้งานหลายแห่ง - อันที่จริง ศูนย์ข้อมูลหลายแห่ง (ตามคำศัพท์เฉพาะ) ที่มีความเป็นอิสระจากกันไม่มากก็น้อย และช่วยให้เราจองได้ที่ระดับของศูนย์ข้อมูลทั้งหมด: หากล้มเหลวกะทันหัน ฐานข้อมูลจะถูกจำลองแบบมาสเตอร์-มาสเตอร์ เว็บแอปพลิเคชันเซิร์ฟเวอร์จะถูกสำรองข้อมูล และข้อมูลคงที่จะถูกย้ายไปยังพื้นที่จัดเก็บอ็อบเจ็กต์ s3 โหลดมีความสมดุล - ในขณะนั้นโดย Amazon elb แต่หลังจากนั้นไม่นาน เราก็มาถึงโหลดบาลานเซอร์ของเราเอง เนื่องจากเราต้องการตรรกะที่ซับซ้อนมากขึ้น
สิ่งที่พวกเขาต้องการคือสิ่งที่พวกเขาได้รับ...
สิ่งพื้นฐานทั้งหมดที่เราต้องการให้แน่ใจว่า - ความทนทานต่อข้อผิดพลาดของเซิร์ฟเวอร์ เว็บแอปพลิเคชัน ฐานข้อมูล - ทุกอย่างทำงานได้ดี สถานการณ์ที่ง่ายที่สุด: หากหนึ่งในเว็บแอปพลิเคชันของเราล้มเหลว ทุกอย่างก็ง่ายดาย - แอปพลิเคชันเหล่านั้นจะถูกปิดจากการปรับสมดุล
เครื่องถ่วง (ในขณะนั้นคือขาออกของ Amazon) ทำเครื่องหมายว่าเครื่องไม่อยู่ในสภาพที่ไม่แข็งแรงและปิดการกระจายโหลดในเครื่องเหล่านั้น การปรับขนาดอัตโนมัติของ Amazon ทำงาน: เมื่อโหลดเพิ่มขึ้น เครื่องใหม่จะถูกเพิ่มในกลุ่มการปรับขนาดอัตโนมัติ โหลดจะถูกกระจายไปยังเครื่องใหม่ - ทุกอย่างเรียบร้อยดี ด้วยบาลานเซอร์ของเรา ตรรกะจะประมาณเดียวกัน: หากมีสิ่งใดเกิดขึ้นกับแอปพลิเคชันเซิร์ฟเวอร์ เราจะลบคำขอออกจากเครื่อง โยนเครื่องเหล่านี้ทิ้ง เริ่มเครื่องใหม่และทำงานต่อไป โครงการมีการเปลี่ยนแปลงเล็กน้อยในช่วงหลายปีที่ผ่านมา แต่ยังคงใช้งานได้: มันเรียบง่าย เข้าใจได้ และไม่มีปัญหากับมัน
เราทำงานทั่วโลก ปริมาณงานสูงสุดของลูกค้าแตกต่างไปจากเดิมอย่างสิ้นเชิง และในทางที่เป็นมิตร เราควรจะสามารถดำเนินงานบริการบางอย่างกับส่วนประกอบใดๆ ของระบบของเราได้ตลอดเวลา โดยที่ลูกค้าไม่มีใครสังเกตเห็น ดังนั้นเราจึงมีโอกาสที่จะปิดฐานข้อมูลจากการดำเนินงาน โดยกระจายโหลดไปยังศูนย์ข้อมูลแห่งที่สองอีกครั้ง
มันทำงานอย่างไร? — เราเปลี่ยนการรับส่งข้อมูลไปยังศูนย์ข้อมูลที่ใช้งานได้ - หากมีอุบัติเหตุที่ศูนย์ข้อมูล โดยสิ้นเชิง หากนี่คืองานที่เราวางแผนไว้กับฐานข้อมูลเดียว เราจะเปลี่ยนส่วนหนึ่งของการรับส่งข้อมูลที่ให้บริการไคลเอนต์เหล่านี้ไปยังศูนย์ข้อมูลที่สองโดยระงับ มันเป็นการจำลองแบบ หากจำเป็นต้องมีเครื่องใหม่สำหรับเว็บแอปพลิเคชันเนื่องจากมีภาระงานบนศูนย์ข้อมูลที่สองเพิ่มขึ้น เครื่องจะเริ่มทำงานโดยอัตโนมัติ เราทำงานเสร็จแล้ว การจำลองแบบได้รับการกู้คืน และเราคืนภาระงานทั้งหมดกลับคืน หากเราต้องการจำลองงานบางอย่างใน DC ที่สอง เช่น ติดตั้งการอัปเดตระบบหรือเปลี่ยนการตั้งค่าในฐานข้อมูลที่สอง โดยทั่วไปแล้ว เราจะทำซ้ำสิ่งเดียวกันในทิศทางอื่น และหากนี่คืออุบัติเหตุ เราจะทำทุกอย่างเพียงเล็กน้อย: เราใช้กลไกตัวจัดการเหตุการณ์ในระบบการตรวจสอบ หากมีการทริกเกอร์การตรวจสอบหลายครั้งและสถานะเปลี่ยนเป็นวิกฤต เราจะเรียกใช้ตัวจัดการนี้ ซึ่งเป็นตัวจัดการที่ดำเนินการตรรกะนี้หรือตรรกะนั้นได้ สำหรับแต่ละฐานข้อมูล เราจะระบุว่าเซิร์ฟเวอร์ใดเป็นเซิร์ฟเวอร์สำรอง และตำแหน่งที่ต้องเปลี่ยนการรับส่งข้อมูลหากไม่พร้อมใช้งาน ในอดีต เราใช้นาจิโอหรือทางแยกบางส่วนในรูปแบบใดรูปแบบหนึ่ง โดยหลักการแล้ว กลไกที่คล้ายกันนั้นมีอยู่ในเกือบทุกระบบการติดตาม เรายังไม่ได้ใช้อะไรที่ซับซ้อนไปกว่านี้ แต่บางทีสักวันหนึ่งเราจะใช้ ขณะนี้การตรวจสอบถูกกระตุ้นเนื่องจากไม่พร้อมใช้งานและมีความสามารถในการเปลี่ยนบางสิ่งบางอย่าง
เราจองทุกอย่างไว้หรือเปล่า?
เรามีลูกค้าจำนวนมากจากสหรัฐอเมริกา ลูกค้าจำนวนมากจากยุโรป ลูกค้าจำนวนมากที่อยู่ใกล้กับตะวันออก - ญี่ปุ่น สิงคโปร์ และอื่นๆ แน่นอนว่าลูกค้าส่วนใหญ่อยู่ในรัสเซีย นั่นคืองานไม่ได้อยู่ในภูมิภาคใดภูมิภาคหนึ่ง ผู้ใช้ต้องการการตอบสนองที่รวดเร็ว มีข้อกำหนดในการปฏิบัติตามกฎหมายท้องถิ่นต่างๆ และภายในแต่ละภูมิภาคเราจองศูนย์ข้อมูลไว้ 53 แห่ง พร้อมทั้งมีบริการเพิ่มเติมบางอย่างซึ่งสะดวกอีกครั้งที่จะจัดไว้ภายในภูมิภาคเดียว - สำหรับลูกค้าที่อยู่ใน ภูมิภาคนี้กำลังทำงานอยู่ ตัวจัดการ REST เซิร์ฟเวอร์การอนุญาต มีความสำคัญน้อยกว่าสำหรับการทำงานของไคลเอนต์โดยรวม คุณสามารถสลับผ่านพวกมันได้ด้วยความล่าช้าเล็กน้อยที่ยอมรับได้ แต่คุณไม่ต้องการคิดค้นวงล้อใหม่เกี่ยวกับวิธีการตรวจสอบและสิ่งที่ต้องทำ กับพวกเขา. ดังนั้นเราจึงพยายามใช้โซลูชันที่มีอยู่ให้เกิดประโยชน์สูงสุด แทนที่จะพัฒนาความสามารถบางอย่างในผลิตภัณฑ์เพิ่มเติม และบางแห่งเราใช้การสลับที่ระดับ DNS เล็กน้อย และเราจะพิจารณาความมีชีวิตชีวาของบริการด้วย DNS เดียวกัน Amazon มีบริการ Route 53 แต่ไม่ใช่แค่ DNS ที่คุณสามารถป้อนข้อมูลได้เพียงเท่านั้น มีความยืดหยุ่นและสะดวกกว่ามาก คุณสามารถสร้างบริการที่กระจายตามภูมิศาสตร์ด้วยการระบุตำแหน่งทางภูมิศาสตร์ เมื่อคุณใช้มันเพื่อระบุว่าลูกค้ามาจากไหนและมอบบันทึกบางอย่างให้เขา - ด้วยความช่วยเหลือนี้ คุณจะสามารถสร้างสถาปัตยกรรมเฟลโอเวอร์ได้ การตรวจสอบสภาพเดียวกันนั้นได้รับการกำหนดค่าใน Route 53 คุณตั้งค่าจุดสิ้นสุดที่ได้รับการตรวจสอบตั้งค่าเมตริกตั้งค่าโปรโตคอลเพื่อกำหนด "ความสด" ของบริการ - tcp, http, https; กำหนดความถี่ของการตรวจสอบเพื่อพิจารณาว่าบริการนั้นยังมีอยู่หรือไม่ และใน DNS เองนั้น คุณระบุสิ่งที่จะเป็นหลัก สิ่งที่จะเป็นรอง จะสลับได้ที่ไหนหากการตรวจสุขภาพถูกเรียกใช้ภายในเส้นทาง XNUMX ทั้งหมดนี้สามารถทำได้ด้วยเครื่องมืออื่น ๆ แต่ทำไมจึงสะดวก - เราตั้งค่าไว้ ขึ้นมาสักครั้งแล้วไม่ต้องคิดเลยว่าเราตรวจสอบอย่างไร สลับอย่างไร ทุกอย่างทำงานด้วยตัวมันเอง
ครั้งแรก "แต่": จะจองเส้นทาง 53 ได้อย่างไรและด้วยอะไร? ใครจะรู้จะเกิดอะไรขึ้นถ้ามีอะไรเกิดขึ้นกับเขา? โชคดีที่เราไม่เคยเหยียบคราดนี้ แต่ขอย้ำอีกครั้งว่าเหตุใดเราจึงคิดว่าเรายังจำเป็นต้องจอง ที่นี่เราวางหลอดไว้สำหรับตัวเราเองล่วงหน้า หลายครั้งต่อวันที่เราทำการขนถ่ายโซนทั้งหมดที่เรามีในเส้นทาง 53 โดยสมบูรณ์ API ของ Amazon ช่วยให้คุณสามารถส่งเป็น JSON ได้อย่างง่ายดาย และเรามีเซิร์ฟเวอร์สำรองข้อมูลหลายตัวที่เราแปลง อัปโหลดในรูปแบบของการกำหนดค่า และมีการกำหนดค่าการสำรองข้อมูลโดยประมาณ หากมีสิ่งใดเกิดขึ้น เราสามารถปรับใช้ด้วยตนเองได้อย่างรวดเร็วโดยไม่สูญเสียข้อมูลการตั้งค่า DNS
ประการที่สอง "แต่": อะไรในภาพนี้ยังไม่ได้จอง? บาลานเซอร์นั่นเอง! การกระจายลูกค้าของเราตามภูมิภาคนั้นง่ายมาก เรามีโดเมน bitrix24.ru, bitrix24.com, .de - ขณะนี้มี 13 โดเมนที่แตกต่างกัน ซึ่งทำงานในโซนต่างๆ เรามาถึงสิ่งต่อไปนี้: แต่ละภูมิภาคมีบาลานเซอร์ของตัวเอง ทำให้สะดวกยิ่งขึ้นในการกระจายข้ามภูมิภาค ขึ้นอยู่กับว่าโหลดสูงสุดบนเครือข่ายอยู่ที่ใด หากนี่เป็นความล้มเหลวในระดับบาลานเซอร์ตัวเดียว ก็เพียงแค่ถอดออกจากบริการและลบออกจาก DNS หากมีปัญหากับกลุ่มบาลานเซอร์ พวกเขาจะได้รับการสำรองข้อมูลบนไซต์อื่น และการสลับระหว่างไซต์เหล่านั้นทำได้โดยใช้เส้นทางเดียวกัน 53 เนื่องจากเนื่องจาก TTL สั้น การสลับจึงเกิดขึ้นภายในเวลาสูงสุด 2, 3, 5 นาที .
ประการที่สาม "แต่": อะไรที่ยังไม่ได้จอง? S3 ถูกต้อง เมื่อเราวางไฟล์ที่เราจัดเก็บไว้สำหรับผู้ใช้ใน s3 เราเชื่ออย่างจริงใจว่าเป็นไฟล์เจาะเกราะ และไม่จำเป็นต้องจองสิ่งใดไว้ที่นั่น แต่ประวัติศาสตร์แสดงให้เห็นว่าสิ่งต่าง ๆ เกิดขึ้นแตกต่างออกไป โดยทั่วไป Amazon อธิบายว่า S3 เป็นบริการพื้นฐาน เนื่องจาก Amazon เองก็ใช้ S3 เพื่อจัดเก็บอิมเมจของเครื่อง การกำหนดค่า อิมเมจ AMI สแน็ปช็อต... และหาก s3 ขัดข้อง เหมือนที่เกิดขึ้นครั้งเดียวในช่วง 7 ปีนี้ ตราบใดที่เราใช้มา bitrix24 มันติดตามเหมือนแฟนๆ มีหลายสิ่งหลายอย่างเกิดขึ้น – การไม่สามารถเริ่มเครื่องเสมือน, ความล้มเหลวของ API และอื่นๆ
และ S3 ก็ล้มได้ - มันเกิดขึ้นครั้งเดียว ดังนั้นเราจึงมาถึงโครงการต่อไปนี้: ไม่กี่ปีที่ผ่านมาไม่มีสถานที่จัดเก็บวัตถุสาธารณะที่ร้ายแรงในรัสเซียและเราพิจารณาทางเลือกในการทำบางสิ่งบางอย่างของเราเอง... โชคดีที่เราไม่ได้เริ่มทำเช่นนี้เพราะเราจะ ได้ขุดคุ้ยความเชี่ยวชาญที่เราไม่มีและอาจจะเลอะเทอะ ตอนนี้ Mail.ru มีพื้นที่จัดเก็บข้อมูลที่เข้ากันได้กับ s3, Yandex ก็มี และผู้ให้บริการรายอื่นหลายรายก็มี ในที่สุดเราก็มาถึงแนวคิดที่ว่าเราต้องการมี ประการแรก การสำรองข้อมูล และประการที่สอง คือความสามารถในการทำงานกับสำเนาในเครื่อง สำหรับภูมิภาครัสเซียโดยเฉพาะ เราใช้บริการ Mail.ru Hotbox ซึ่งเป็น API ที่เข้ากันได้กับ s3 เราไม่ต้องการการแก้ไขโค้ดภายในแอปพลิเคชันที่สำคัญใดๆ และเราได้สร้างกลไกต่อไปนี้: ใน s3 มีทริกเกอร์ที่ทริกเกอร์การสร้าง/การลบอ็อบเจ็กต์ Amazon มีบริการที่เรียกว่า Lambda ซึ่งเป็นการเปิดตัวโค้ดแบบไร้เซิร์ฟเวอร์ ที่จะดำเนินการเมื่อมีการทริกเกอร์บางอย่างเท่านั้น
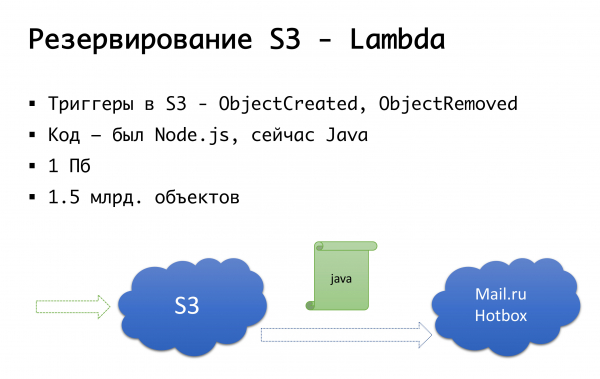
เราทำได้ง่ายๆ: หากทริกเกอร์ของเราเริ่มทำงาน เราจะรันโค้ดที่จะคัดลอกอ็อบเจ็กต์ไปยังที่เก็บข้อมูล Mail.ru หากต้องการเปิดตัวงานด้วยสำเนาข้อมูลในเครื่องอย่างสมบูรณ์ เรายังจำเป็นต้องมีการซิงโครไนซ์แบบย้อนกลับเพื่อให้ไคลเอนต์ที่อยู่ในเซ็กเมนต์รัสเซียสามารถทำงานกับพื้นที่เก็บข้อมูลที่อยู่ใกล้พวกเขามากขึ้น เมลกำลังจะเสร็จสิ้นทริกเกอร์ในที่เก็บข้อมูล - เป็นไปได้ที่จะทำการซิงโครไนซ์แบบย้อนกลับในระดับโครงสร้างพื้นฐาน แต่ตอนนี้เรากำลังทำสิ่งนี้ในระดับโค้ดของเราเอง หากเราเห็นว่าไคลเอนต์โพสต์ไฟล์แล้ว ในระดับโค้ดเราจะวางเหตุการณ์ไว้ในคิว ประมวลผลและทำการจำลองแบบย้อนกลับ เหตุใดจึงไม่ดี: หากเราทำงานบางประเภทกับวัตถุของเรานอกเหนือจากผลิตภัณฑ์ของเรา กล่าวคือ ด้วยวิธีการภายนอก เราจะไม่คำนึงถึงสิ่งนั้น ดังนั้นเราจึงรอจนถึงจุดสิ้นสุดเมื่อทริกเกอร์ปรากฏขึ้นที่ระดับการจัดเก็บข้อมูล ดังนั้นไม่ว่าเราจะรันโค้ดจากที่ใด วัตถุที่มาหาเราจะถูกคัดลอกไปในทิศทางอื่น
ในระดับโค้ด เราลงทะเบียนพื้นที่เก็บข้อมูลทั้งสองสำหรับไคลเอนต์แต่ละราย โดยอันหนึ่งถือเป็นอันหลัก และอีกอันถือเป็นอันสำรอง หากทุกอย่างเรียบร้อยดี เราจะทำงานกับพื้นที่จัดเก็บข้อมูลที่อยู่ใกล้เรามากขึ้น นั่นคือ ลูกค้าของเราที่อยู่ใน Amazon พวกเขาทำงานกับ S3 และผู้ที่ทำงานในรัสเซีย พวกเขาทำงานกับ Hotbox ถ้าแฟล็กถูกทริกเกอร์ ก็ควรจะเชื่อมต่อเฟลโอเวอร์ และเราจะสลับไคลเอนต์ไปยังที่เก็บข้อมูลอื่น เราสามารถเลือกช่องนี้ได้อย่างอิสระตามภูมิภาค และสามารถสลับไปมาได้ เรายังไม่ได้ใช้สิ่งนี้ในทางปฏิบัติ แต่เราได้จัดเตรียมกลไกนี้ไว้แล้ว และเราคิดว่าสักวันหนึ่งเราจะต้องมีสวิตช์นี้และมีประโยชน์ สิ่งนี้เคยเกิดขึ้นมาแล้วครั้งหนึ่ง
อ้าว แล้วอเมซอนก็หนีไป...
เดือนเมษายนนี้เป็นวันครบรอบการเริ่มต้นการบล็อก Telegram ในรัสเซีย ผู้ให้บริการที่ได้รับผลกระทบมากที่สุดที่ตกอยู่ภายใต้นี้คือ Amazon และน่าเสียดายที่บริษัทรัสเซียที่ทำงานให้กับคนทั้งโลกต้องทนทุกข์ทรมานมากกว่า
หากบริษัทเป็นบริษัทระดับโลกและรัสเซียมีส่วนน้อยมาก 3-5% ไม่ทางใดก็ทางหนึ่งคุณสามารถเสียสละพวกเขาได้
หากนี่คือ บริษัท รัสเซียล้วนๆ - ฉันแน่ใจว่าจะต้องตั้งอยู่ในพื้นที่ - มันจะสะดวกสำหรับผู้ใช้เอง สะดวกสบาย และจะมีความเสี่ยงน้อยลง
จะเป็นอย่างไรหากเป็นบริษัทที่ดำเนินงานทั่วโลกและมีลูกค้าจากรัสเซียและที่อื่น ๆ ทั่วโลกในจำนวนเท่ากันโดยประมาณ? การเชื่อมต่อของส่วนต่างๆ มีความสำคัญ และต้องทำงานร่วมกันไม่ทางใดก็ทางหนึ่ง
ย้อนกลับไปช่วงปลายเดือนมีนาคม 2018 Roskomnadzor ได้ส่งจดหมายไปยังผู้ให้บริการรายใหญ่ที่สุด แจ้งให้ทราบถึงแผนการที่จะบล็อกที่อยู่ IP ของ Amazon หลายล้านรายการ เพื่อบล็อก... แอปพลิเคชันส่งข้อความ Zello และด้วยความช่วยเหลือจากผู้ให้บริการเหล่านั้น พวกเขาได้ปล่อยจดหมายฉบับนี้ให้ทุกคนได้รู้ และทำให้เห็นได้ชัดว่าการเชื่อมต่อกับ Amazon อาจล่มสลาย วันนั้นเป็นวันศุกร์ และพวกเราก็รีบวิ่งไปหาเพื่อนร่วมงานที่ servers.ru ด้วยความตื่นตระหนก โดยบอกว่า "เพื่อนๆ เราต้องการเซิร์ฟเวอร์หลายเครื่องที่ไม่ใช่ในรัสเซีย ไม่ใช่ที่ Amazon แต่เป็นที่ไหนสักแห่งในอัมสเตอร์ดัม" เพื่อที่เราจะได้ตั้งเซิร์ฟเวอร์ของเราเองที่นั่นได้ VPN และพร็อกซีสำหรับปลายทางบางแห่งที่เราควบคุมไม่ได้ เช่น ปลายทาง S3—เราไม่สามารถลองตั้งค่าบริการใหม่และขอที่อยู่ IP อื่นได้ เรายังคงต้องสามารถเข้าถึงปลายทางเหล่านั้นได้ ภายในไม่กี่วัน เราได้ตั้งค่าเซิร์ฟเวอร์เหล่านี้เสร็จเรียบร้อย เปิดใช้งาน และเตรียมพร้อมสำหรับการบล็อกที่จะเริ่มต้นขึ้น ที่น่าสนใจคือ Roskomnadzor หลังจากเห็นความวุ่นวายและความตื่นตระหนก ก็กล่าวว่า "ไม่ เราไม่ได้บล็อกอะไรในตอนนี้" (แต่เป็นอย่างนั้นจนกระทั่งถึงตอนที่พวกเขาเริ่มบล็อก Telegram) หลังจากตั้งค่าตัวเลือกการหลีกเลี่ยงและตระหนักว่าการบล็อกยังไม่ได้ถูกนำมาใช้ เราจึงตัดสินใจที่จะไม่ตรวจสอบเรื่องทั้งหมด เผื่อไว้ก่อน

และในปี 2019 เรายังคงอยู่ในสภาพที่ถูกปิดกั้น เมื่อคืนฉันดู: IP ประมาณล้านรายการยังคงถูกบล็อกอยู่ จริงอยู่ Amazon ถูกปลดบล็อกเกือบทั้งหมด โดยถึงจุดสูงสุดแล้ว มีที่อยู่ถึง 20 ล้านที่อยู่... โดยทั่วไปแล้ว ความจริงก็คือความสอดคล้องกันอาจไม่สอดคล้องกันดีนัก กะทันหัน. มันอาจไม่เกิดขึ้นด้วยเหตุผลทางเทคนิค - ไฟไหม้, รถขุด, ทั้งหมดนี้ หรืออย่างที่เราได้เห็นแล้วว่าไม่ใช่ด้านเทคนิคทั้งหมด ดังนั้น คนทั้งใหญ่และใหญ่ที่มี AS ของตัวเอง อาจจะสามารถจัดการสิ่งนี้ด้วยวิธีอื่นได้ - การเชื่อมต่อโดยตรงและสิ่งอื่น ๆ อยู่ที่ระดับ l2 อยู่แล้ว แต่ในเวอร์ชันธรรมดา เช่น ของเราหรือเล็กกว่านั้น คุณสามารถมีความซ้ำซ้อนในระดับเซิร์ฟเวอร์ที่ยกมาจากที่อื่นได้ กำหนดค่า VPN พร็อกซีล่วงหน้าไว้ล่วงหน้า พร้อมความสามารถในการสลับการกำหนดค่าไปยังส่วนเหล่านั้นได้อย่างรวดเร็ว ที่มีความสำคัญต่อการเชื่อมต่อของคุณ สิ่งนี้มีประโยชน์สำหรับเรามากกว่าหนึ่งครั้งเมื่อการบล็อกของ Amazon เริ่มต้นขึ้น ในกรณีที่เลวร้ายที่สุด เราอนุญาตให้มีการรับส่งข้อมูล S3 ผ่านพวกเขาเท่านั้น แต่ทั้งหมดนี้ก็ค่อยๆ ได้รับการแก้ไข
จะจอง...ผู้ให้บริการทั้งหมดได้อย่างไร?
ขณะนี้เราไม่มีสถานการณ์ในกรณีที่อเมซอนทั้งหมดล่ม เรามีสถานการณ์ที่คล้ายกันสำหรับรัสเซีย ในรัสเซีย เราโฮสต์โดยผู้ให้บริการรายหนึ่ง ซึ่งเราเลือกให้มีเว็บไซต์หลายแห่ง และเมื่อปีที่แล้วเราประสบปัญหา แม้ว่าศูนย์ข้อมูลทั้งสองแห่งจะเป็นศูนย์ข้อมูล แต่อาจมีปัญหาอยู่ที่ระดับการกำหนดค่าเครือข่ายของผู้ให้บริการ ซึ่งจะยังคงส่งผลกระทบต่อศูนย์ข้อมูลทั้งสองแห่ง และเราอาจไม่สามารถใช้งานทั้งสองไซต์ได้ แน่นอนว่านั่นคือสิ่งที่เกิดขึ้น ในที่สุดเราก็พิจารณาสถาปัตยกรรมภายในอีกครั้ง มันไม่ได้เปลี่ยนแปลงมากนัก แต่สำหรับรัสเซีย ตอนนี้เรามีสองไซต์ ซึ่งไม่ได้มาจากผู้ให้บริการรายเดียวกัน แต่มาจากสองไซต์ที่ต่างกัน หากอันใดอันหนึ่งล้มเหลว เราก็สามารถเปลี่ยนไปใช้อันอื่นได้
ตามสมมุติฐาน สำหรับ Amazon เรากำลังพิจารณาความเป็นไปได้ในการจองในระดับของผู้ให้บริการรายอื่น อาจเป็น Google อาจเป็นคนอื่น... แต่จนถึงขณะนี้เราได้สังเกตในทางปฏิบัติแล้วว่าแม้ Amazon จะมีอุบัติเหตุในระดับหนึ่งของ Availability Zone หนึ่ง แต่อุบัติเหตุในระดับของทั้งภูมิภาคนั้นค่อนข้างหายาก ดังนั้น ตามทฤษฎีแล้ว เรามีความคิดที่ว่าเราอาจทำการจอง "Amazon ไม่ใช่ Amazon" แต่ในทางปฏิบัติยังไม่เป็นเช่นนั้น
คำไม่กี่คำเกี่ยวกับระบบอัตโนมัติ
ระบบอัตโนมัติจำเป็นเสมอไปหรือไม่? เป็นการเหมาะสมที่จะระลึกถึงเอฟเฟกต์ Dunning-Kruger บนแกน “x” คือความรู้และประสบการณ์ที่เราได้รับ และบนแกน “y” คือความมั่นใจในการกระทำของเรา ในตอนแรกเราไม่รู้อะไรเลยและไม่แน่ใจเลย ถ้าอย่างนั้นเราก็รู้เพียงเล็กน้อยและมีความมั่นใจอย่างมาก - นี่คือสิ่งที่เรียกว่า "จุดสูงสุดของความโง่เขลา" ซึ่งแสดงให้เห็นได้ดีจากภาพ "ภาวะสมองเสื่อมและความกล้าหาญ" จากนั้นเราได้เรียนรู้เพียงเล็กน้อยและพร้อมที่จะเข้าสู่การต่อสู้ จากนั้นเราก้าวไปสู่ข้อผิดพลาดร้ายแรงและพบว่าตัวเองตกอยู่ในหุบเขาแห่งความสิ้นหวัง เมื่อเราดูเหมือนจะรู้อะไรบางอย่าง แต่จริงๆ แล้วเราไม่รู้อะไรมากนัก เมื่อเราได้รับประสบการณ์ เราก็จะมีความมั่นใจมากขึ้น
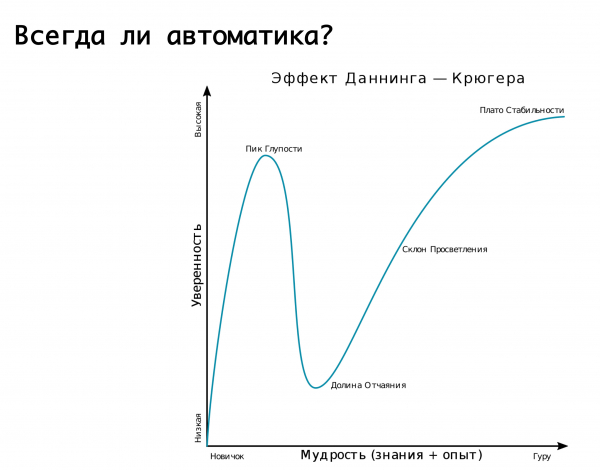
กราฟนี้อธิบายตรรกะของเราเกี่ยวกับสวิตช์อัตโนมัติต่างๆ สำหรับอุบัติเหตุบางอย่างได้ เราเริ่มต้น - เราไม่รู้วิธีทำอะไรเลย งานเกือบทั้งหมดทำด้วยมือ จากนั้นเราก็ตระหนักว่าเราสามารถแนบระบบอัตโนมัติเข้ากับทุกสิ่ง และนอนหลับอย่างสงบสุขได้ และทันใดนั้น เราก็ก้าวขึ้นไปบนคราดขนาดใหญ่: ผลบวกลวงเกิดขึ้น และเราสลับการรับส่งข้อมูลกลับไปกลับมา ในทางที่ดี ที่เราไม่ควรทำเช่นนี้ ผลที่ตามมาคือการจำลองพังทลายลงหรืออย่างอื่น นี่คือหุบเขาแห่งความสิ้นหวัง แล้วเราก็มาเข้าใจว่าเราต้องเข้าใกล้ทุกสิ่งอย่างชาญฉลาด นั่นคือมันสมเหตุสมผลที่จะพึ่งพาระบบอัตโนมัติโดยจัดให้มีสัญญาณเตือนที่ผิดพลาด แต่! หากผลที่ตามมาสามารถทำลายล้างได้ก็ควรปล่อยให้เป็นกะหน้าที่ให้กับวิศวกรที่ปฏิบัติหน้าที่ซึ่งจะตรวจสอบและติดตามว่าเกิดอุบัติเหตุจริงและจะดำเนินการตามที่จำเป็นด้วยตนเอง...
ข้อสรุป
ตลอดระยะเวลา 7 ปีที่ผ่านมา เราเปลี่ยนจากข้อเท็จจริงที่ว่าเมื่อมีบางอย่างล้มลง มีความตื่นตระหนก ไปสู่การเข้าใจว่าไม่มีปัญหา มีเพียงงานเท่านั้นที่ต้อง - และ - สามารถแก้ไขได้ เมื่อคุณสร้างบริการ ให้มองจากด้านบน ประเมินความเสี่ยงทั้งหมดที่อาจเกิดขึ้น หากคุณเห็นพวกเขาทันที ให้จัดเตรียมความซ้ำซ้อนล่วงหน้าและความเป็นไปได้ในการสร้างโครงสร้างพื้นฐานที่ทนทานต่อข้อผิดพลาด เนื่องจากจุดใดก็ตามที่สามารถล้มเหลวและนำไปสู่การใช้บริการไม่ได้จะต้องทำเช่นนั้นอย่างแน่นอน และแม้ว่าดูเหมือนว่าองค์ประกอบโครงสร้างพื้นฐานบางอย่างจะไม่ล้มเหลวอย่างแน่นอน - เช่น s3 โปรดจำไว้ว่าสามารถทำได้ และอย่างน้อยก็ในทางทฤษฎี คุณต้องมีความคิดว่าคุณจะทำอย่างไรกับพวกเขาหากมีอะไรเกิดขึ้น มีแผนบริหารความเสี่ยง เมื่อคุณคิดที่จะทำทุกอย่างโดยอัตโนมัติหรือด้วยตนเอง ให้ประเมินความเสี่ยง: จะเกิดอะไรขึ้นหากระบบอัตโนมัติเริ่มเปลี่ยนทุกอย่าง สิ่งนี้จะไม่นำไปสู่สถานการณ์ที่เลวร้ายยิ่งกว่าเมื่อเทียบกับอุบัติเหตุหรือไม่? บางทีอาจจำเป็นต้องใช้การประนีประนอมที่สมเหตุสมผลระหว่างการใช้ระบบอัตโนมัติและปฏิกิริยาของวิศวกรที่ปฏิบัติหน้าที่ซึ่งจะประเมินภาพจริงและเข้าใจว่าจำเป็นต้องเปลี่ยนบางสิ่งทันทีหรือ "ใช่ แต่ไม่ใช่ตอนนี้"
การประนีประนอมที่สมเหตุสมผลระหว่างลัทธิพอใจ แต่สิ่งดีเลิศกับความพยายาม เวลา และเงินที่แท้จริง ซึ่งคุณสามารถใช้จ่ายในโครงการที่คุณจะได้ในที่สุด
ข้อความนี้เป็นรายงานของ Alexander Demidov ที่ได้รับการปรับปรุงและขยายในที่ประชุม .
ที่มา: will.com
