


สวัสดีทุกคน! ผมชื่อดมิทรี ซัมโซนอฟ ทำงานเป็นหัวหน้าผู้ดูแลระบบที่ Odnoklassniki เรามีเซิร์ฟเวอร์จริงกว่า 7 เครื่อง คอนเทนเนอร์ในคลาวด์ 11 ตัว และแอปพลิเคชัน 200 ตัว ซึ่งในรูปแบบต่างๆ กันนั้นก่อให้เกิดคลัสเตอร์ที่แตกต่างกันถึง 700 คลัสเตอร์ เซิร์ฟเวอร์ส่วนใหญ่กำลังทำงานอยู่ CentOS 7.
เมื่อวันที่ 14 สิงหาคม 2018 ข้อมูลเกี่ยวกับช่องโหว่ FragmentSmack ได้รับการเผยแพร่
() และ SegmentSmack (). สิ่งเหล่านี้เป็นช่องโหว่ที่มีเวกเตอร์การโจมตีเครือข่ายและคะแนนค่อนข้างสูง (7.5) ซึ่งคุกคามการปฏิเสธการให้บริการ (DoS) เนื่องจากทรัพยากรหมด (CPU) ในเวลานั้นยังไม่มีการเสนอการแก้ไขเคอร์เนลสำหรับ FragmentSmack ยิ่งไปกว่านั้นยังออกมาช้ากว่าการเผยแพร่ข้อมูลเกี่ยวกับช่องโหว่อีกด้วย เพื่อกำจัด SegmentSmack แนะนำให้อัปเดตเคอร์เนล แพ็คเกจอัพเดตนั้นเปิดตัวในวันเดียวกัน สิ่งเดียวที่เหลือคือการติดตั้ง
ไม่ เราไม่ต่อต้านการอัปเดตเคอร์เนลเลย! อย่างไรก็ตามมีความแตกต่าง...
วิธีที่เราอัปเดตเคอร์เนลในการใช้งานจริง
โดยทั่วไปไม่มีอะไรซับซ้อน:
- ดาวน์โหลดแพ็คเกจ;
- ติดตั้งบนเซิร์ฟเวอร์จำนวนหนึ่ง (รวมถึงเซิร์ฟเวอร์ที่โฮสต์คลาวด์ของเรา)
- ตรวจสอบให้แน่ใจว่าไม่มีอะไรเสียหาย
- ตรวจสอบให้แน่ใจว่าใช้การตั้งค่าเคอร์เนลมาตรฐานทั้งหมดโดยไม่มีข้อผิดพลาด
- รอสักสองสามวัน
- ตรวจสอบประสิทธิภาพของเซิร์ฟเวอร์
- สลับการปรับใช้เซิร์ฟเวอร์ใหม่เป็นเคอร์เนลใหม่
- อัปเดตเซิร์ฟเวอร์ทั้งหมดตามศูนย์ข้อมูล (ศูนย์ข้อมูลครั้งละหนึ่งศูนย์เพื่อลดผลกระทบต่อผู้ใช้ในกรณีที่เกิดปัญหา)
- รีบูทเซิร์ฟเวอร์ทั้งหมด
ทำซ้ำกับเมล็ดทุกกิ่งที่เรามี ในขณะนี้คือ:
- คลังสินค้า CentOS 7 3.10 - สำหรับเซิร์ฟเวอร์ทั่วไปส่วนใหญ่;
- วานิลลา 4.19 - สำหรับเรา เพราะเราต้องการ BFQ, BBR ฯลฯ
- Elrepo kernel-ml 5.2 - สำหรับ เนื่องจาก 4.19 เคยทำงานไม่เสถียร แต่จำเป็นต้องมีฟีเจอร์เดียวกัน
ดังที่คุณอาจเดาได้ การรีบูตเซิร์ฟเวอร์หลายพันเครื่องใช้เวลานานที่สุด เนื่องจากช่องโหว่บางรายการไม่ได้มีความสำคัญสำหรับเซิร์ฟเวอร์ทั้งหมด เราจึงรีบูตเฉพาะเซิร์ฟเวอร์ที่สามารถเข้าถึงได้โดยตรงจากอินเทอร์เน็ตเท่านั้น ในระบบคลาวด์ เพื่อไม่ให้จำกัดความยืดหยุ่น เราจะไม่ผูกคอนเทนเนอร์ที่สามารถเข้าถึงได้จากภายนอกกับเซิร์ฟเวอร์แต่ละเครื่องด้วยเคอร์เนลใหม่ แต่จะรีบูตโฮสต์ทั้งหมดโดยไม่มีข้อยกเว้น โชคดีที่ขั้นตอนนั้นง่ายกว่าเซิร์ฟเวอร์ทั่วไป ตัวอย่างเช่น คอนเทนเนอร์ไร้สัญชาติสามารถย้ายไปยังเซิร์ฟเวอร์อื่นระหว่างการรีบูตได้
อย่างไรก็ตาม ยังมีงานอีกมากและอาจใช้เวลาหลายสัปดาห์ และหากมีปัญหากับเวอร์ชันใหม่อาจใช้เวลานานหลายเดือน ผู้โจมตีเข้าใจเรื่องนี้ดี ดังนั้นพวกเขาจึงต้องมีแผนบี
FragmentSmack/SegmentSmack. วิธีแก้ปัญหา
โชคดีที่มีช่องโหว่บางอย่างเช่นแผน B อยู่ และเรียกว่าวิธีแก้ปัญหา โดยส่วนใหญ่ นี่คือการเปลี่ยนแปลงในการตั้งค่าเคอร์เนล/แอปพลิเคชันที่สามารถลดผลกระทบที่อาจเกิดขึ้นให้เหลือน้อยที่สุดหรือกำจัดการหาประโยชน์จากช่องโหว่โดยสิ้นเชิง
ในกรณีของ FragmentSmack/SegmentSmack วิธีแก้ปัญหานี้:
«คุณสามารถเปลี่ยนค่าเริ่มต้นของ 4MB และ 3MB ใน net.ipv4.ipfrag_high_thresh และ net.ipv4.ipfrag_low_thresh (และค่าที่เหมือนกันสำหรับ ipv6 net.ipv6.ipfrag_high_thresh และ net.ipv6.ipfrag_low_thresh) เป็น 256 kB และ 192 kB ตามลำดับหรือ ต่ำกว่า. การทดสอบพบว่าการใช้งาน CPU ลดลงเล็กน้อยถึงมากในระหว่างการโจมตี ขึ้นอยู่กับฮาร์ดแวร์ การตั้งค่า และเงื่อนไข อย่างไรก็ตาม อาจมีผลกระทบต่อประสิทธิภาพการทำงานบางส่วนเนื่องจาก ipfrag_high_thresh=262144 ไบต์ เนื่องจากมีเพียงแฟรกเมนต์ 64K เพียงสองแฟรกเมนต์เท่านั้นที่สามารถใส่ลงในคิวการประกอบซ้ำได้ในแต่ละครั้ง ตัวอย่างเช่น มีความเสี่ยงที่แอปพลิเคชันที่ทำงานกับแพ็กเก็ต UDP ขนาดใหญ่จะใช้งานไม่ได้'
พารามิเตอร์นั้นเอง อธิบายไว้ดังนี้:
ipfrag_high_thresh - LONG INTEGER
Maximum memory used to reassemble IP fragments.
ipfrag_low_thresh - LONG INTEGER
Maximum memory used to reassemble IP fragments before the kernel
begins to remove incomplete fragment queues to free up resources.
The kernel still accepts new fragments for defragmentation.
เราไม่มี UDP ขนาดใหญ่ในบริการการผลิต ไม่มีการรับส่งข้อมูลแบบกระจัดกระจายบน LAN มีการรับส่งข้อมูลแบบกระจัดกระจายบน WAN แต่ไม่มีนัยสำคัญ ไม่มีสัญญาณ - คุณสามารถเปิดตัววิธีแก้ปัญหาได้!
FragmentSmack/SegmentSmack. เลือดแรก
ปัญหาแรกที่เราพบคือบางครั้งคอนเทนเนอร์ระบบคลาวด์จะใช้การตั้งค่าใหม่เพียงบางส่วนเท่านั้น (เฉพาะ ipfrag_low_thresh) และบางครั้งก็ไม่ได้ใช้เลย - การตั้งค่าใหม่ล้มเหลวตั้งแต่เริ่มต้น ไม่สามารถจำลองปัญหาได้อย่างเสถียร (การตั้งค่าทั้งหมดใช้ด้วยตนเองโดยไม่มีปัญหาใดๆ) การทำความเข้าใจว่าเหตุใดคอนเทนเนอร์จึงล่มตั้งแต่เริ่มต้นนั้นไม่ใช่เรื่องง่ายเช่นกัน: ไม่พบข้อผิดพลาด สิ่งหนึ่งที่แน่นอนก็คือ การย้อนกลับการตั้งค่าจะช่วยแก้ปัญหาการล่มของคอนเทนเนอร์ได้
เหตุใดการใช้ Sysctl บนโฮสต์จึงไม่เพียงพอที่จะใช้งาน คอนเทนเนอร์อาศัยอยู่ในเนมสเปซเครือข่ายเฉพาะของตัวเอง อย่างน้อยที่สุด ในคอนเทนเนอร์อาจแตกต่างจากโฮสต์
การตั้งค่า Sysctl ถูกนำไปใช้ในคอนเทนเนอร์อย่างไร เนื่องจากคอนเทนเนอร์ของเราไม่มีสิทธิพิเศษ คุณจะไม่สามารถเปลี่ยนการตั้งค่า Sysctl ใด ๆ โดยการเข้าไปในตัวคอนเทนเนอร์เองได้ - คุณเพียงแค่มีสิทธิ์ไม่เพียงพอ ในการรันคอนเทนเนอร์ คลาวด์ของเราในขณะนั้นใช้ Docker (ตอนนี้ ). พารามิเตอร์ของคอนเทนเนอร์ใหม่ถูกส่งไปยัง Docker ผ่าน API รวมถึงการตั้งค่า Sysctl ที่จำเป็น
ขณะค้นหาเวอร์ชันต่างๆ ปรากฎว่า Docker API ไม่ได้ส่งคืนข้อผิดพลาดทั้งหมด (อย่างน้อยในเวอร์ชัน 1.10) เมื่อเราพยายามเริ่มคอนเทนเนอร์ด้วย "docker run" ในที่สุดเราก็เห็นบางอย่าง:
write /proc/sys/net/ipv4/ipfrag_high_thresh: invalid argument docker: Error response from daemon: Cannot start container <...>: [9] System error: could not synchronise with container process.
ค่าพารามิเตอร์ไม่ถูกต้อง แต่ทำไม? และเหตุใดจึงไม่ถูกต้องเพียงบางครั้งเท่านั้น? ปรากฎว่า Docker ไม่รับประกันลำดับที่ใช้พารามิเตอร์ Sysctl (เวอร์ชันทดสอบล่าสุดคือ 1.13.1) ดังนั้นบางครั้ง ipfrag_high_thresh พยายามตั้งค่าเป็น 256K เมื่อ ipfrag_low_thresh ยังคงเป็น 3M นั่นคือขีด จำกัด บนต่ำกว่า เกินขีดจำกัดล่างซึ่งนำไปสู่ข้อผิดพลาด
ในเวลานั้น เราใช้กลไกของเราเองในการกำหนดค่าคอนเทนเนอร์ใหม่หลังจากเริ่มต้นแล้ว (แช่แข็งคอนเทนเนอร์หลังจากนั้น และดำเนินการคำสั่งในเนมสเปซของคอนเทนเนอร์ผ่าน ) และเรายังเพิ่มการเขียนพารามิเตอร์ Sysctl ในส่วนนี้ด้วย ปัญหาได้รับการแก้ไขแล้ว
FragmentSmack/SegmentSmack. เลือดหยดแรก 2
ก่อนที่เราจะมีเวลาทำความเข้าใจการใช้วิธีแก้ปัญหาในระบบคลาวด์ ข้อร้องเรียนแรกๆ ที่ไม่ค่อยพบบ่อยจากผู้ใช้ก็เริ่มมาถึง ในเวลานั้น เวลาผ่านไปหลายสัปดาห์นับตั้งแต่เริ่มใช้วิธีแก้ปัญหาบนเซิร์ฟเวอร์เครื่องแรก การสอบสวนเบื้องต้นแสดงให้เห็นว่าได้รับการร้องเรียนเกี่ยวกับบริการแต่ละอย่าง ไม่ใช่ทุกเซิร์ฟเวอร์ของบริการเหล่านี้ ปัญหากลับกลายเป็นความไม่แน่นอนอย่างมากอีกครั้ง
อันดับแรก เราลองย้อนกลับการตั้งค่า Sysctl แล้ว แต่ก็ไม่มีผลอะไร การปรับแต่งการตั้งค่าเซิร์ฟเวอร์และแอปพลิเคชันต่างๆ ก็ไม่ได้ช่วยเช่นกัน การรีบูตช่วยได้ รีบูตเพื่อแก้ไขปัญหา Linux แม้จะไม่เป็นธรรมชาติ แต่ก็เป็นสภาวะปกติในการทำงานกับ Windows ในสมัยก่อนนั้นมันก็ใช้ได้นะ และเราก็คิดว่ามันเป็น "ความผิดพลาดของเคอร์เนล" ตอนที่ใช้การตั้งค่า Sysctl ใหม่ ช่างโง่เขลาเหลือเกิน...
สามสัปดาห์ต่อมาปัญหาก็เกิดขึ้นอีก การกำหนดค่าเซิร์ฟเวอร์เหล่านี้ค่อนข้างง่าย: Nginx ในโหมดพร็อกซี/บาลานเซอร์ การจราจรไม่มาก หมายเหตุเบื้องต้นใหม่: จำนวนข้อผิดพลาด 504 บนไคลเอนต์เพิ่มขึ้นทุกวัน (). กราฟแสดงจำนวนข้อผิดพลาด 504 ครั้งต่อวันสำหรับบริการนี้:
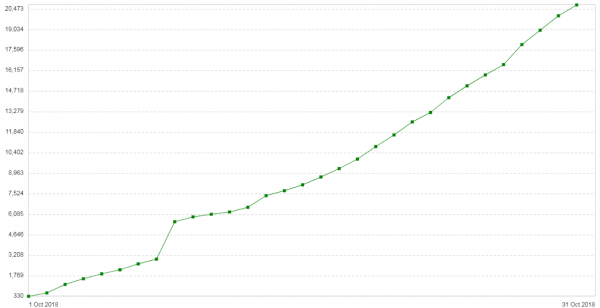
ข้อผิดพลาดทั้งหมดเกี่ยวข้องกับแบ็กเอนด์เดียวกัน - เกี่ยวกับข้อผิดพลาดที่อยู่ในคลาวด์ กราฟการใช้หน่วยความจำสำหรับชิ้นส่วนของแพ็คเกจบนแบ็กเอนด์นี้มีลักษณะดังนี้:
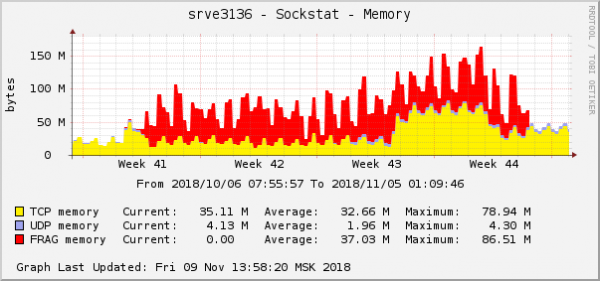
นี่เป็นหนึ่งในอาการที่ชัดเจนที่สุดของปัญหาในกราฟของระบบปฏิบัติการ ในระบบคลาวด์ ในเวลาเดียวกัน ปัญหาเครือข่ายอื่นเกี่ยวกับการตั้งค่า QoS (การควบคุมการจราจร) ได้รับการแก้ไขแล้ว บนกราฟปริมาณการใช้หน่วยความจำสำหรับส่วนของแพ็กเก็ต มีลักษณะเหมือนกันทุกประการ:
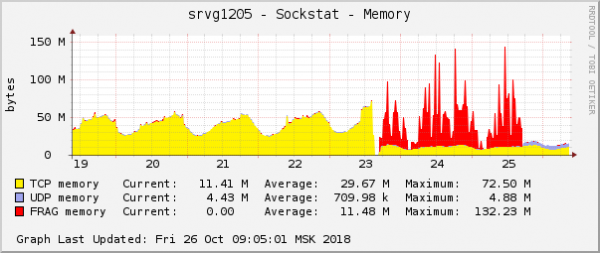
สมมติฐานนั้นง่ายมาก: หากกราฟดูเหมือนกัน แสดงว่ามีเหตุผลเดียวกัน นอกจากนี้ปัญหาใดๆ เกี่ยวกับหน่วยความจำประเภทนี้ยังพบได้น้อยมาก
สาระสำคัญของปัญหาที่แก้ไขคือเราใช้ตัวกำหนดเวลาแพ็กเก็ต fq พร้อมการตั้งค่าเริ่มต้นใน QoS ตามค่าเริ่มต้น สำหรับการเชื่อมต่อหนึ่งครั้ง อนุญาตให้คุณเพิ่ม 100 แพ็กเก็ตลงในคิว และการเชื่อมต่อบางส่วน ในสถานการณ์ที่ช่องสัญญาณขาดแคลน ก็เริ่มอุดตันคิวต่อความจุ ในกรณีนี้แพ็กเก็ตจะถูกทิ้ง ในสถิติ tc (tc -s qdisc) จะเห็นได้ดังนี้:
qdisc fq 2c6c: parent 1:2c6c limit 10000p flow_limit 100p buckets 1024 orphan_mask 1023 quantum 3028 initial_quantum 15140 refill_delay 40.0ms
Sent 454701676345 bytes 491683359 pkt (dropped 464545, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
1024 flows (1021 inactive, 0 throttled)
0 gc, 0 highprio, 0 throttled, 464545 flows_plimit
“464545 flows_plimit” คือแพ็กเก็ตที่ถูกดร็อปเนื่องจากเกินขีดจำกัดคิวของการเชื่อมต่อหนึ่งครั้ง และ “ดรอป 464545” คือผลรวมของแพ็กเก็ตที่ถูกดร็อปทั้งหมดของตัวกำหนดตารางเวลานี้ หลังจากเพิ่มความยาวของคิวเป็น 1 และรีสตาร์ทคอนเทนเนอร์แล้ว ปัญหาก็หยุดเกิดขึ้น คุณสามารถนั่งดื่มสมูทตี้ได้
FragmentSmack/SegmentSmack. เลือดสุดท้าย
ประการแรก หลายเดือนหลังจากที่มีการประกาศช่องโหว่ของเคอร์เนล ในที่สุดก็มีการปล่อยแพทช์แก้ไข FragmentSmack ออกมา (จำไว้ว่า การประกาศในเดือนสิงหาคมเป็นการแก้ไขเฉพาะ SegmentSmack เท่านั้น) ซึ่งทำให้เรามีโอกาสที่จะเลิกใช้ Workaround ซึ่งสร้างปัญหาให้เรามากพอสมควร ในช่วงเวลานั้น เราได้ย้ายเซิร์ฟเวอร์บางส่วนไปยังเคอร์เนลใหม่แล้ว และตอนนี้เราต้องเริ่มต้นใหม่ทั้งหมด ทำไมเราถึงอัปเดตเคอร์เนลโดยไม่รอการแก้ไข FragmentSmack? ความจริงก็คือ กระบวนการป้องกันช่องโหว่เหล่านี้เกิดขึ้นพร้อมกัน (และรวมเข้าด้วยกัน) กับกระบวนการอัปเดต Workaround นั่นเอง CentOS (ซึ่งใช้เวลานานกว่าการอัปเดตเคอร์เนลเพียงอย่างเดียว) นอกจากนี้ SegmentSmack เป็นช่องโหว่ที่อันตรายกว่า และมีการแก้ไขทันที ดังนั้นจึงสมเหตุสมผลอยู่แล้ว อย่างไรก็ตาม การอัปเดตเคอร์เนลเพียงอย่างเดียวก็อาจใช้เวลานานกว่า CentOS เราทำไม่ได้เนื่องจากช่องโหว่ FragmentSmack ที่ปรากฏขึ้นระหว่างนั้น CentOS ปัญหาข้อ 7.5 ได้รับการแก้ไขในเวอร์ชัน 7.6 เท่านั้น ดังนั้นเราจึงต้องหยุดการอัปเดตเป็นเวอร์ชัน 7.5 และเริ่มต้นการอัปเดตเป็นเวอร์ชัน 7.6 ใหม่ทั้งหมด ปัญหานี้ก็เกิดขึ้นเช่นกัน
ประการที่สอง มีการร้องเรียนจากผู้ใช้เกี่ยวกับปัญหาที่เกิดขึ้นไม่บ่อยนัก ตอนนี้เรารู้แล้วว่าทั้งหมดเกี่ยวข้องกับการอัปโหลดไฟล์จากไคลเอนต์ไปยังเซิร์ฟเวอร์บางส่วนของเรา ยิ่งไปกว่านั้น มีการอัปโหลดจำนวนน้อยมากจากมวลรวมทั้งหมดผ่านเซิร์ฟเวอร์เหล่านี้
ดังที่เราจำได้จากเรื่องราวข้างต้น การย้อนกลับ Sysctl ไม่ได้ช่วยอะไร การรีบูตช่วยได้ แต่เป็นการชั่วคราว
ความสงสัยเกี่ยวกับ Sysctl ไม่ได้ถูกลบออก แต่คราวนี้จำเป็นต้องรวบรวมข้อมูลให้ได้มากที่สุด นอกจากนี้ยังขาดความสามารถอย่างมากในการสร้างปัญหาการอัปโหลดบนไคลเอนต์เพื่อศึกษาสิ่งที่เกิดขึ้นอย่างแม่นยำมากขึ้น
การวิเคราะห์สถิติและบันทึกที่มีอยู่ทั้งหมดไม่ได้ช่วยให้เราเข้าใจสิ่งที่เกิดขึ้นมากขึ้น มีการขาดความสามารถอย่างเฉียบพลันในการสร้างปัญหาขึ้นมาใหม่เพื่อ "สัมผัส" ความเชื่อมโยงที่เฉพาะเจาะจง ในที่สุด นักพัฒนาที่ใช้แอปพลิเคชันเวอร์ชันพิเศษสามารถจัดการปัญหาที่เกิดขึ้นบนอุปกรณ์ทดสอบเมื่อเชื่อมต่อผ่าน Wi-Fi อย่างเสถียร นี่เป็นความก้าวหน้าในการสืบสวน ไคลเอนต์เชื่อมต่อกับ Nginx ซึ่งพร็อกซีไปที่แบ็กเอนด์ซึ่งเป็นแอปพลิเคชัน Java ของเรา
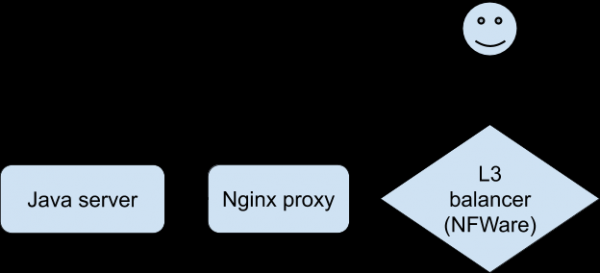
บทสนทนาสำหรับปัญหาเป็นเช่นนี้ (แก้ไขที่ด้านพร็อกซี Nginx):
- ลูกค้า: ขอข้อมูลการดาวน์โหลดไฟล์
- เซิร์ฟเวอร์ Java: การตอบสนอง
- ลูกค้า: POST พร้อมไฟล์
- เซิร์ฟเวอร์ Java: ข้อผิดพลาด
ในเวลาเดียวกัน เซิร์ฟเวอร์ Java เขียนลงในบันทึกที่ได้รับข้อมูล 0 ไบต์จากไคลเอนต์ และพร็อกซี Nginx เขียนว่าคำขอใช้เวลามากกว่า 30 วินาที (30 วินาทีคือการหมดเวลาของแอปพลิเคชันไคลเอนต์) เหตุใดจึงหมดเวลาและทำไมถึง 0 ไบต์ จากมุมมองของ HTTP ทุกอย่างทำงานได้ตามปกติ แต่ POST พร้อมไฟล์ดูเหมือนจะหายไปจากเครือข่าย ยิ่งไปกว่านั้น มันหายไประหว่างไคลเอนต์กับ Nginx ถึงเวลาที่จะติดอาวุธให้ตัวเองด้วย Tcpdump! แต่ก่อนอื่นคุณต้องเข้าใจการกำหนดค่าเครือข่ายก่อน พร็อกซี Nginx อยู่ด้านหลังบาลานเซอร์ L3 . Tunneling ใช้ในการส่งแพ็กเก็ตจาก L3 balancer ไปยังเซิร์ฟเวอร์ ซึ่งจะเพิ่มส่วนหัวลงในแพ็กเก็ต:
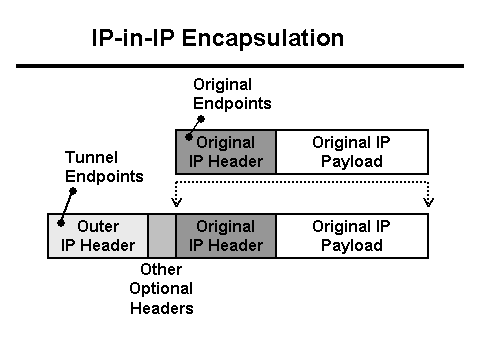
ในกรณีนี้ เครือข่ายมาที่เซิร์ฟเวอร์นี้ในรูปแบบของการรับส่งข้อมูลที่ติดแท็ก Vlan ซึ่งจะเพิ่มฟิลด์ของตัวเองลงในแพ็กเก็ตด้วย:
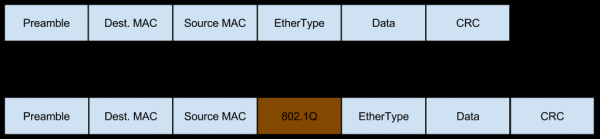
และการรับส่งข้อมูลนี้ยังสามารถแยกส่วนได้ (เปอร์เซ็นต์เล็กน้อยของการรับส่งข้อมูลที่กระจัดกระจายขาเข้าที่เราพูดถึงเมื่อประเมินความเสี่ยงจากวิธีแก้ปัญหา) ซึ่งเปลี่ยนเนื้อหาของส่วนหัวด้วย:
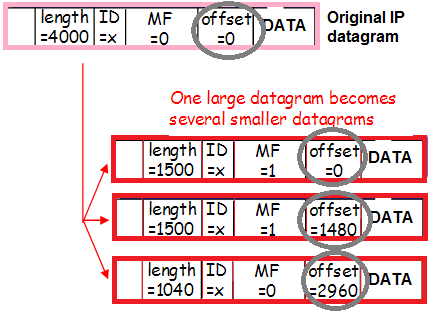
อีกครั้งหนึ่ง: แพ็กเก็ตถูกห่อหุ้มด้วยแท็ก Vlan ห่อหุ้มด้วยอุโมงค์ซึ่งมีการแยกส่วน เพื่อให้เข้าใจได้ดีขึ้นว่าสิ่งนี้เกิดขึ้นได้อย่างไร เรามาติดตามเส้นทางแพ็กเก็ตจากไคลเอนต์ไปยังพร็อกซี Nginx กัน
- แพ็กเก็ตไปถึงบาลานเซอร์ L3 สำหรับการกำหนดเส้นทางที่ถูกต้องภายในศูนย์ข้อมูล แพ็กเก็ตจะถูกห่อหุ้มไว้ในอุโมงค์และส่งไปยังการ์ดเครือข่าย
- เนื่องจากส่วนหัวของแพ็กเก็ต + ช่องสัญญาณไม่พอดีกับ MTU แพ็กเก็ตจึงถูกตัดออกเป็นแฟรกเมนต์และส่งไปยังเครือข่าย
- เมื่อได้รับแพ็กเก็ต สวิตช์ที่อยู่หลังบาลานเซอร์ L3 จะเพิ่มแท็ก Vlan เข้าไปและส่งต่อไป
- สวิตช์ที่อยู่ด้านหน้าพร็อกซี Nginx จะเห็น (ขึ้นอยู่กับการตั้งค่าพอร์ต) ว่าเซิร์ฟเวอร์ต้องการแพ็กเก็ตที่ห่อหุ้ม Vlan ดังนั้นจึงส่งตามที่เป็นอยู่โดยไม่ต้องลบแท็ก Vlan
- Linux รับชิ้นส่วนจากบรรจุภัณฑ์แต่ละชิ้นแล้วนำมาติดกาวเข้าด้วยกันเป็นบรรจุภัณฑ์ขนาดใหญ่ชิ้นเดียว
- จากนั้นแพ็กเก็ตจะไปถึงอินเทอร์เฟซ Vlan โดยที่เลเยอร์แรกจะถูกลบออก - การห่อหุ้ม Vlan
- แล้วก็ Linux จากนั้นส่งข้อมูลไปยังอินเทอร์เฟซ Tunnel ซึ่งจะมีการลบเลเยอร์เพิ่มเติมออกไปอีกชั้นหนึ่ง นั่นคือ การห่อหุ้มแบบ Tunnel (Tunnel encapsulation)
ความยากคือการส่งทั้งหมดนี้เป็นพารามิเตอร์ไปยัง tcpdump
เริ่มจากจุดสิ้นสุด: มีแพ็กเก็ต IP ที่สะอาด (โดยไม่มีส่วนหัวที่ไม่จำเป็น) จากไคลเอนต์โดยลบการห่อหุ้ม vlan และทันเนลหรือไม่
tcpdump host <ip клиента>
ไม่ ไม่มีแพ็คเกจดังกล่าวบนเซิร์ฟเวอร์ ดังนั้นปัญหาจะต้องอยู่ที่นั่นก่อนหน้านี้ มีแพ็กเก็ตใดบ้างที่ลบเฉพาะการห่อหุ้ม Vlan เท่านั้น
tcpdump ip[32:4]=0xx390x2xx
0xx390x2xx คือที่อยู่ IP ไคลเอ็นต์ในรูปแบบเลขฐานสิบหก
32:4 — ที่อยู่และความยาวของฟิลด์ที่ SCR IP ถูกเขียนลงในแพ็กเก็ต Tunnel
ต้องเลือกที่อยู่ฟิลด์โดยใช้กำลังดุร้ายเนื่องจากบนอินเทอร์เน็ตพวกเขาเขียนประมาณ 40, 44, 50, 54 แต่ไม่มีที่อยู่ IP ที่นั่น คุณยังสามารถดูแพ็กเก็ตรายการใดรายการหนึ่งในรูปแบบฐานสิบหก (พารามิเตอร์ -xx หรือ -XX ใน tcpdump) และคำนวณที่อยู่ IP ที่คุณทราบ
มีส่วนของแพ็กเก็ตที่ไม่มีการลบ Vlan และ Tunnel encapsulation หรือไม่
tcpdump ((ip[6:2] > 0) and (not ip[6] = 64))
เวทมนตร์นี้จะแสดงให้เราเห็นชิ้นส่วนทั้งหมด รวมถึงชิ้นสุดท้ายด้วย อาจเป็นไปได้ว่า IP สามารถกรองสิ่งเดียวกันได้ แต่ฉันไม่ได้ลองเนื่องจากมีแพ็กเก็ตดังกล่าวไม่มากนักและแพ็กเก็ตที่ฉันต้องการนั้นพบได้ง่ายในโฟลว์ทั่วไป พวกเขาอยู่ที่นี่:
14:02:58.471063 In 00:de:ff:1a:94:11 ethertype IPv4 (0x0800), length 1516: (tos 0x0, ttl 63, id 53652, offset 0, flags [+], proto IPIP (4), length 1500)
11.11.11.11 > 22.22.22.22: truncated-ip - 20 bytes missing! (tos 0x0, ttl 50, id 57750, offset 0, flags [DF], proto TCP (6), length 1500)
33.33.33.33.33333 > 44.44.44.44.80: Flags [.], seq 0:1448, ack 1, win 343, options [nop,nop,TS val 11660691 ecr 2998165860], length 1448
0x0000: 0000 0001 0006 00de fb1a 9441 0000 0800 ...........A....
0x0010: 4500 05dc d194 2000 3f09 d5fb 0a66 387d E.......?....f8}
0x0020: 1x67 7899 4500 06xx e198 4000 3206 6xx4 .faEE.....@.2.m.
0x0030: b291 x9xx x345 2541 83b9 0050 9740 0x04 .......A...P.@..
0x0040: 6444 4939 8010 0257 8c3c 0000 0101 080x dDI9...W.......
0x0050: 00b1 ed93 b2b4 6964 xxd8 ffe1 006a 4578 ......ad.....jEx
0x0060: 6966 0000 4x4d 002a 0500 0008 0004 0100 if..MM.*........
14:02:58.471103 ใน 00:de:ff:1a:94:11 ethertype IPv4 (0x0800) ความยาว 62: (tos 0x0, ttl 63, รหัส 53652 ออฟเซ็ต 1480, แฟล็ก [ไม่มี], โปรโต IPIP (4), ความยาว 40)
11.11.11.11 > 22.22.22.22: โปรโตคอล IP-4
0x0000: 0000 0001 0006 00de fb1a 9441 0000 0800 ..........อา....
0x0010: 4500 0028 d194 00b9 3f04 faf6 2x76 385x จ.(....?....f8}
0x0020: 1x76 6545 xxxx 1x11 2d2c 0c21 8016 8e43 .faE...D-,.!...C
0x0030: x978 e91d x9b0 d608 0000 0000 0000 7c31 .x............|Q
0x0040: 881d c4b6 0000 0000 0000 0000 0000 .............
นี่คือสองส่วนของแพ็คเกจเดียว (รหัสเดียวกัน 53652) พร้อมรูปถ่าย (คำว่า Exif มองเห็นได้ในแพ็คเกจแรก) เนื่องจากมีแพ็คเกจในระดับนี้ แต่ไม่ได้อยู่ในรูปแบบที่รวมไว้ในดัมพ์ ปัญหาจึงชัดเจนกับแอสเซมบลี ในที่สุดก็มีหลักฐานเชิงสารคดีเรื่องนี้แล้ว!
ตัวถอดรหัสแพ็กเก็ตไม่ได้เปิดเผยปัญหาใดๆ ที่จะขัดขวางการสร้าง ลองที่นี่: . ในตอนแรก เมื่อคุณพยายามยัดเยียดบางอย่างที่นั่น ตัวถอดรหัสจะไม่ชอบรูปแบบแพ็กเก็ต ปรากฎว่ามีออคเต็ตพิเศษอีกสองออคเต็ตระหว่าง Srcmac และ Ethertype (ไม่เกี่ยวข้องกับข้อมูลแฟรกเมนต์) หลังจากถอดออกแล้ว ตัวถอดรหัสก็เริ่มทำงาน อย่างไรก็ตาม มันก็ไม่มีปัญหาอะไร
ไม่ว่าใครจะพูดอะไร ก็ไม่พบสิ่งอื่นใดนอกจาก Sysctl เหล่านั้น สิ่งที่เหลืออยู่คือการหาวิธีระบุเซิร์ฟเวอร์ที่มีปัญหาเพื่อทำความเข้าใจขนาดและตัดสินใจดำเนินการต่อไป พบตัวนับที่ต้องการได้เร็วพอ:
netstat -s | grep "packet reassembles failed”
นอกจากนี้ยังอยู่ใน snmpd ภายใต้ OID=1.3.6.1.2.1.4.31.1.1.16.1 ().
“จำนวนความล้มเหลวที่ตรวจพบโดยอัลกอริธึมการประกอบ IP อีกครั้ง (ไม่ว่าด้วยเหตุผลใดก็ตาม: หมดเวลา ข้อผิดพลาด ฯลฯ )”
ในบรรดากลุ่มเซิร์ฟเวอร์ที่ศึกษาปัญหานั้น ตัวนับสองตัวนี้เพิ่มขึ้นเร็วขึ้น สองตัวช้ากว่า และอีกสองตัวไม่เพิ่มขึ้นเลย การเปรียบเทียบไดนามิกของตัวนับนี้กับไดนามิกของข้อผิดพลาด HTTP บนเซิร์ฟเวอร์ Java เปิดเผยความสัมพันธ์ นั่นคือสามารถตรวจสอบมิเตอร์ได้
การมีตัวบ่งชี้ปัญหาที่เชื่อถือได้เป็นสิ่งสำคัญมาก เพื่อให้คุณสามารถระบุได้อย่างแม่นยำว่าการย้อนกลับ Sysctl ช่วยได้หรือไม่ เนื่องจากจากเรื่องที่แล้ว เรารู้ว่าสิ่งนี้ไม่สามารถเข้าใจได้ทันทีจากแอปพลิเคชัน ตัวบ่งชี้นี้จะช่วยให้เราระบุปัญหาทั้งหมดในการผลิตก่อนที่ผู้ใช้จะค้นพบ
หลังจากย้อนกลับ Sysctl ข้อผิดพลาดในการตรวจสอบก็หยุดลง ดังนั้นสาเหตุของปัญหาจึงได้รับการพิสูจน์แล้ว เช่นเดียวกับความจริงที่ว่าการย้อนกลับช่วยได้
เราย้อนกลับการตั้งค่าการกระจายตัวบนเซิร์ฟเวอร์อื่น ซึ่งมีการตรวจสอบแบบใหม่เข้ามา และบางแห่งที่เราจัดสรรหน่วยความจำสำหรับแฟรกเมนต์มากกว่าค่าเริ่มต้นก่อนหน้านี้ (นี่คือสถิติ UDP ซึ่งการสูญเสียบางส่วนซึ่งไม่สังเกตเห็นได้ชัดเจนเมื่อเทียบกับพื้นหลังทั่วไป) .
คำถามที่สำคัญที่สุด
เหตุใดแพ็กเก็ตจึงกระจัดกระจายบน L3 balancer ของเรา แพ็กเก็ตส่วนใหญ่ที่มาจากผู้ใช้ไปยังบาลานเซอร์คือ SYN และ ACK ขนาดของบรรจุภัณฑ์เหล่านี้มีขนาดเล็ก แต่เนื่องจากส่วนแบ่งของแพ็กเก็ตดังกล่าวมีขนาดใหญ่มาก เมื่อเทียบกับพื้นหลังแล้ว เราจึงไม่สังเกตเห็นว่ามีแพ็กเก็ตขนาดใหญ่ที่เริ่มแยกส่วน
เหตุผลก็คือสคริปต์การกำหนดค่าที่ใช้งานไม่ได้ บนเซิร์ฟเวอร์ที่มีอินเทอร์เฟซ Vlan (มีเซิร์ฟเวอร์เพียงไม่กี่เครื่องที่มีการแท็กการรับส่งข้อมูลในการใช้งานจริงในขณะนั้น) Advmss ช่วยให้เราสามารถถ่ายทอดให้กับลูกค้าว่าข้อมูลที่แพ็กเก็ตในทิศทางของเราควรมีขนาดเล็กลง เพื่อที่ว่าหลังจากแนบส่วนหัวของทันเนลแล้ว พวกเขาก็ไม่จำเป็นต้องแยกส่วน
เหตุใดการย้อนกลับ Sysctl จึงไม่ช่วย แต่การรีบูตทำได้ การย้อนกลับ Sysctl เปลี่ยนจำนวนหน่วยความจำที่พร้อมใช้งานสำหรับการรวมแพ็คเกจ ในเวลาเดียวกันเห็นได้ชัดว่าข้อเท็จจริงที่ว่าหน่วยความจำล้นสำหรับแฟรกเมนต์ทำให้การเชื่อมต่อช้าลงซึ่งทำให้แฟรกเมนต์ล่าช้าเป็นเวลานานในคิว นั่นคือกระบวนการดำเนินไปเป็นรอบ
การรีบูตจะล้างหน่วยความจำและทุกอย่างกลับคืนสู่การสั่งซื้อ
เป็นไปได้ไหมที่จะทำโดยไม่มีวิธีแก้ปัญหา? ใช่ แต่มีความเสี่ยงสูงที่ผู้ใช้จะขาดบริการในกรณีที่มีการโจมตี แน่นอนว่าการใช้วิธีแก้ปัญหาทำให้เกิดปัญหาต่างๆ มากมาย รวมถึงการชะลอตัวของหนึ่งในบริการสำหรับผู้ใช้ แต่อย่างไรก็ตาม เราเชื่อว่าการกระทำดังกล่าวมีความสมเหตุสมผล
ขอบคุณมากสำหรับ Andrey Timofeev () เพื่อขอความช่วยเหลือในการสอบสวนเช่นเดียวกับ Alexey Krenev () - สำหรับงานอันยิ่งใหญ่ในการปรับปรุงให้ทันสมัย Centos และแกนประมวลผลของเซิร์ฟเวอร์ ในกรณีนี้ กระบวนการต้องเริ่มต้นใหม่หลายครั้ง ส่งผลให้ใช้เวลานานหลายเดือน
ที่มา: will.com
