

ในตอนแรกมีเทคโนโลยีหนึ่งเรียกว่า BPF เรามองเธอ บทความเกี่ยวกับพันธสัญญาเดิมในชุดนี้ ได้รับการพัฒนาและรวมเข้าไว้ในเนื้อหาหลักในปี 2013 โดยความพยายามของอเล็กเซย์ สตาโรโวอิตอฟและแดเนียล บอร์กแมน Linux เป็นเวอร์ชันปรับปรุงที่ออกแบบมาเพื่อใช้งานกับเครื่อง 64 บิตสมัยใหม่ เทคโนโลยีใหม่นี้เคยถูกเรียกว่า Internal BPF ในช่วงสั้นๆ จากนั้นเปลี่ยนชื่อเป็น Extended BPF และในปัจจุบัน หลังจากผ่านไปหลายปี ทุกคนก็เรียกมันว่า BPF เฉยๆ
โดยพื้นฐานแล้ว BPF อนุญาตให้โค้ดที่ผู้ใช้เขียนขึ้นเองสามารถทำงานในพื้นที่เคอร์เนลได้ Linux และสถาปัตยกรรมใหม่นี้ประสบความสำเร็จอย่างมาก จนเราต้องเขียนบทความอีกนับสิบฉบับเพื่ออธิบายการใช้งานทั้งหมด (สิ่งเดียวที่นักพัฒนาทำไม่สำเร็จ ดังที่คุณเห็นได้จากแผนภูมิประสิทธิภาพด้านล่าง คือการสร้างโลโก้ที่ดี)
บทความนี้อธิบายถึงโครงสร้างของเครื่องเสมือน BPF, อินเทอร์เฟซเคอร์เนลสำหรับการทำงานกับ BPF, เครื่องมือในการพัฒนา ตลอดจนภาพรวมของคุณลักษณะที่มีอยู่โดยย่อ สั้นมาก เช่น ทุกสิ่งที่เราต้องการในอนาคตสำหรับการศึกษาเชิงลึกเกี่ยวกับการใช้งานจริงของ BPF
สรุปบทความ
ขั้นแรก เราจะดูสถาปัตยกรรม BPF จากมุมสูงและร่างองค์ประกอบหลัก
เมื่อเข้าใจสถาปัตยกรรมโดยรวมแล้ว เราจะอธิบายโครงสร้างของเครื่องเสมือน BPF
ในส่วนนี้ เราจะพิจารณาวงจรชีวิตของวัตถุ BPF - โปรแกรมและแผนที่อย่างละเอียดยิ่งขึ้น
ด้วยความเข้าใจในระบบอยู่แล้ว ในที่สุดเราจะดูวิธีสร้างและจัดการวัตถุจากพื้นที่ผู้ใช้โดยใช้การเรียกระบบพิเศษ: bpf(2).
แน่นอนคุณสามารถเขียนโปรแกรมโดยใช้การเรียกระบบ แต่มันยาก สำหรับสถานการณ์ที่สมจริงยิ่งขึ้น โปรแกรมเมอร์นิวเคลียร์ได้พัฒนาห้องสมุด libbpf. เราจะสร้างโครงกระดูกแอปพลิเคชัน BPF พื้นฐานที่เราจะใช้ในตัวอย่างต่อๆ ไป
ที่นี่เราจะเรียนรู้ว่าโปรแกรม BPF สามารถเข้าถึงฟังก์ชันตัวช่วยเคอร์เนลได้อย่างไร ซึ่งเป็นเครื่องมือที่ขยายขีดความสามารถของ BPF ใหม่โดยพื้นฐานแล้วเมื่อเทียบกับแผนที่แบบคลาสสิก
เมื่อถึงจุดนี้ เราก็จะรู้เพียงพอที่จะเข้าใจได้อย่างชัดเจนว่าเราจะสร้างโปรแกรมที่ใช้แผนที่ได้อย่างไร และมาดูกันสั้น ๆ เกี่ยวกับเครื่องมือตรวจสอบที่ยอดเยี่ยมและทรงพลัง
ส่วนช่วยเหลือเกี่ยวกับวิธีการประกอบยูทิลิตี้และเคอร์เนลที่จำเป็นสำหรับการทดลอง
ในตอนท้ายของบทความ ผู้ที่อ่านมาถึงตอนนี้จะพบคำที่สร้างแรงบันดาลใจและคำอธิบายสั้น ๆ เกี่ยวกับสิ่งที่จะเกิดขึ้นในบทความต่อไปนี้ นอกจากนี้ เราจะแสดงรายการลิงก์จำนวนหนึ่งสำหรับการศึกษาด้วยตนเองสำหรับผู้ที่ไม่มีความปรารถนาหรือไม่สามารถรอการศึกษาต่อได้
รู้เบื้องต้นเกี่ยวกับสถาปัตยกรรม BPF
ก่อนจะเริ่มดูสถาปัตยกรรม BPF ขอกล่าวถึงเป็นครั้งสุดท้าย (อ๊ะ) ซึ่งพัฒนาขึ้นเพื่อตอบสนองต่อการเกิดขึ้นของเครื่อง RISC และแก้ปัญหาการกรองแพ็กเก็ตอย่างมีประสิทธิภาพ สถาปัตยกรรมประสบความสำเร็จอย่างมากที่ถือกำเนิดขึ้นในยุค XNUMX ใน Berkeley UNIX มันถูกพอร์ตไปยังระบบปฏิบัติการที่มีอยู่ส่วนใหญ่ มีชีวิตรอดมาจนถึงวัย XNUMX ที่คลั่งไคล้และยังคงพบแอปพลิเคชันใหม่ๆ
BPF ใหม่ได้รับการพัฒนาเพื่อตอบสนองต่อความแพร่หลายของเครื่อง 64 บิต บริการคลาวด์ และความต้องการที่เพิ่มขึ้นสำหรับเครื่องมือสร้าง SDN (Sซอฟต์แวร์-dละเอียด n(เครือข่าย) พัฒนาขึ้นโดยวิศวกรเครือข่ายหลักเพื่อทดแทน BPF แบบดั้งเดิมอย่างมีประสิทธิภาพยิ่งขึ้น BPF รุ่นใหม่นี้ถูกนำไปใช้ในงานติดตามเส้นทางที่ซับซ้อนเพียงแค่หกเดือนต่อมา Linux ระบบต่างๆ และตอนนี้ หกปีหลังจากที่ระบบเหล่านี้ปรากฏตัว เราคงต้องเขียนบทความใหม่ทั้งหมดเพื่อที่จะระบุประเภทต่างๆ ของโปรแกรมเหล่านั้น
ภาพตลก
โดยแก่นแท้แล้ว BPF คือเครื่องเสมือนแบบแซนด์บ็อกซ์ที่ช่วยให้คุณสามารถเรียกใช้โค้ด “ตามอำเภอใจ” ในพื้นที่เคอร์เนลได้โดยไม่กระทบต่อความปลอดภัย โปรแกรม BPF ถูกสร้างขึ้นในพื้นที่ผู้ใช้ โหลดลงในเคอร์เนล และเชื่อมต่อกับแหล่งเหตุการณ์บางแห่ง เหตุการณ์อาจเป็นได้ เช่น การส่งแพ็กเก็ตไปยังอินเทอร์เฟซเครือข่าย การเปิดตัวฟังก์ชันเคอร์เนลบางอย่าง เป็นต้น ในกรณีของแพ็คเกจ โปรแกรม BPF จะสามารถเข้าถึงข้อมูลและข้อมูลเมตาของแพ็คเกจได้ (สำหรับการอ่านและการเขียน ขึ้นอยู่กับประเภทของโปรแกรม) ในกรณีของการรันฟังก์ชันเคอร์เนล อาร์กิวเมนต์ของ ฟังก์ชั่นรวมทั้งพอยน์เตอร์ไปยังหน่วยความจำเคอร์เนล ฯลฯ
มาดูกระบวนการนี้กันดีกว่า ขั้นแรก เรามาพูดถึงความแตกต่างประการแรกจาก BPF แบบคลาสสิก ซึ่งเป็นโปรแกรมที่เขียนด้วยแอสเซมเบลอร์ ในเวอร์ชันใหม่ สถาปัตยกรรมได้รับการขยายเพื่อให้สามารถเขียนโปรแกรมในภาษาระดับสูงได้ ซึ่งแน่นอนว่าเป็นภาษา C เป็นหลัก ด้วยเหตุนี้ จึงได้มีการพัฒนาแบ็กเอนด์สำหรับ llvm ซึ่งช่วยให้สามารถสร้างโค้ดไบต์สำหรับสถาปัตยกรรม BPF ได้

สถาปัตยกรรม BPF ส่วนหนึ่งได้รับการออกแบบเพื่อให้ทำงานอย่างมีประสิทธิภาพบนเครื่องจักรที่ทันสมัย เพื่อให้ใช้งานได้ในทางปฏิบัติ เมื่อโหลดโค้ดไบต์ BPF ลงในเคอร์เนลแล้ว จะถูกแปลเป็นโค้ดเนทีฟโดยใช้ส่วนประกอบที่เรียกว่าคอมไพเลอร์ JIT (Jอุสต์ In Tฉัน) ถัดไป หากคุณจำได้ว่าใน BPF แบบคลาสสิก โปรแกรมจะถูกโหลดลงในเคอร์เนลและแนบกับแหล่งเหตุการณ์แบบอะตอมมิก - ในบริบทของการเรียกระบบครั้งเดียว ในสถาปัตยกรรมใหม่ สิ่งนี้เกิดขึ้นในสองขั้นตอน ขั้นแรก โค้ดจะถูกโหลดลงในเคอร์เนลโดยใช้การเรียกของระบบ bpf(2)จากนั้น ต่อมาด้วยกลไกอื่นๆ ที่แตกต่างกันไปขึ้นอยู่กับประเภทของโปรแกรม โปรแกรมจะเชื่อมต่อกับแหล่งเหตุการณ์
ที่นี่ผู้อ่านอาจมีคำถาม: เป็นไปได้อย่างไร รับประกันความปลอดภัยในการรันโค้ดดังกล่าวอย่างไร? เรารับประกันความปลอดภัยของการดำเนินการโดยขั้นตอนการโหลดโปรแกรม BPF ที่เรียกว่า verifier (ในภาษาอังกฤษ ขั้นตอนนี้เรียกว่า verifier และฉันจะใช้คำภาษาอังกฤษต่อไป):

Verifier เป็นเครื่องวิเคราะห์แบบสแตติกที่รับรองว่าโปรแกรมจะไม่ทำลายเคอร์เนลตามปกติ โดยวิธีการนี้ไม่ได้หมายความว่าโปรแกรมไม่สามารถรบกวนการทำงานของระบบ - โปรแกรม BPF สามารถอ่านและเขียนพื้นที่หน่วยความจำเคอร์เนลคืนค่าของฟังก์ชันตัดทอนส่วนเสริมเขียนใหม่ และแม้แต่การส่งต่อแพ็กเก็ตเครือข่าย ตัวตรวจสอบรับประกันว่าเคอร์เนลจะไม่ขัดข้องจากการรันโปรแกรม BPF และโปรแกรมที่สามารถเขียนได้ตามกฎ เช่น ข้อมูลของแพ็กเก็ตขาออก จะไม่สามารถเขียนทับหน่วยความจำเคอร์เนลนอกแพ็กเก็ตได้ . เราจะดูรายละเอียดเพิ่มเติมเล็กน้อยเกี่ยวกับตัวตรวจสอบความถูกต้องในส่วนที่เกี่ยวข้อง หลังจากที่เราได้ทำความคุ้นเคยกับส่วนประกอบอื่นๆ ของ BPF แล้ว
แล้วเราได้เรียนรู้อะไรบ้างจนถึงตอนนี้? ผู้ใช้เขียนโปรแกรมในภาษา C โหลดลงในเคอร์เนลโดยใช้การเรียกของระบบ bpf(2)ซึ่งจะถูกตรวจสอบโดยผู้ตรวจสอบและแปลเป็นโค้ดไบต์ดั้งเดิม จากนั้นผู้ใช้รายเดียวกันหรือรายอื่นจะเชื่อมต่อโปรแกรมกับแหล่งเหตุการณ์และเริ่มดำเนินการ การแยกการบูตและการเชื่อมต่อเป็นสิ่งจำเป็นด้วยเหตุผลหลายประการ ประการแรก การเรียกใช้ตัวตรวจสอบมีราคาค่อนข้างแพง และการดาวน์โหลดโปรแกรมเดียวกันหลายครั้งทำให้เราเสียเวลากับคอมพิวเตอร์ ประการที่สอง วิธีการเชื่อมต่อโปรแกรมนั้นขึ้นอยู่กับประเภทของโปรแกรม และอินเทอร์เฟซ "สากล" หนึ่งอินเทอร์เฟซที่พัฒนาขึ้นเมื่อปีที่แล้วอาจไม่เหมาะกับโปรแกรมประเภทใหม่ (แม้ว่าตอนนี้สถาปัตยกรรมจะมีความเป็นผู้ใหญ่มากขึ้นแล้ว แต่ก็มีแนวคิดที่จะรวมอินเทอร์เฟซนี้ไว้ในระดับหนึ่ง libbpf.)
ผู้อ่านที่สนใจอาจสังเกตเห็นว่าเรายังเขียนภาพไม่เสร็จ ที่จริงแล้วทั้งหมดข้างต้นไม่ได้อธิบายว่า BPF เปลี่ยนภาพโดยพื้นฐานอย่างไรเมื่อเทียบกับ BPF แบบคลาสสิก นวัตกรรมสองอย่างที่ขยายขอบเขตของการบังคับใช้อย่างมีนัยสำคัญคือความสามารถในการใช้หน่วยความจำที่ใช้ร่วมกันและฟังก์ชันตัวช่วยเคอร์เนล (ตัวช่วยเคอร์เนล) ใน BPF มีการใช้หน่วยความจำที่ใช้ร่วมกันโดยใช้แผนที่ที่เรียกว่า - โครงสร้างข้อมูลที่ใช้ร่วมกันกับ API เฉพาะ พวกเขาได้ชื่อนี้อาจเป็นเพราะแผนที่ประเภทแรกที่ปรากฏขึ้นคือตารางแฮช จากนั้น อาร์เรย์, ตารางแฮชในเครื่อง (ต่อ CPU) และอาร์เรย์ในเครื่อง, แผนผังการค้นหา, แผนที่ที่มีตัวชี้ไปยังโปรแกรม BPF และอื่นๆ อีกมากมาย ตอนนี้เราสนใจในความจริงที่ว่าโปรแกรม BPF มีความสามารถในการบันทึกสถานะระหว่างการโทรและแชร์กับโปรแกรมอื่นและพื้นที่ผู้ใช้
แผนที่สามารถเข้าถึงได้จากกระบวนการของผู้ใช้โดยใช้การเรียกระบบ bpf(2)และจากโปรแกรม BPF ที่ทำงานอยู่ในเคอร์เนลโดยใช้ฟังก์ชันตัวช่วย นอกจากนี้ ยังมีผู้ช่วยเหลือไม่เพียงแต่เพื่อทำงานกับแผนที่เท่านั้น แต่ยังรวมถึงการเข้าถึงความสามารถเคอร์เนลอื่นๆ ด้วย ตัวอย่างเช่น โปรแกรม BPF สามารถใช้ฟังก์ชันตัวช่วยเพื่อส่งต่อแพ็กเก็ตไปยังอินเทอร์เฟซอื่น สร้างเหตุการณ์ perf เข้าถึงโครงสร้างเคอร์เนล และอื่นๆ

โดยรวมแล้ว BPF ให้ความสามารถในการโหลดโดยพลการ เช่น ตรวจสอบโดยผู้ตรวจสอบ รหัสผู้ใช้ลงในพื้นที่เคอร์เนล รหัสนี้สามารถบันทึกสถานะระหว่างการโทรและสื่อสารกับพื้นที่ผู้ใช้ และมีสิทธิ์เข้าถึงระบบย่อยเคอร์เนลที่อนุญาตสำหรับโปรแกรมประเภทนี้
สิ่งนี้คล้ายกับความสามารถที่มีให้โดยโมดูลเคอร์เนลอยู่แล้ว เมื่อเปรียบเทียบกับสิ่งที่ BPF มีข้อดีบางประการ (แน่นอน คุณสามารถเปรียบเทียบได้เฉพาะแอปพลิเคชันที่คล้ายกัน เช่น การติดตามระบบ - คุณไม่สามารถเขียนไดรเวอร์โดยพลการบน BPF) เราสามารถสังเกตเกณฑ์รายการที่ต่ำกว่า (ยูทิลิตี้บางตัวที่ใช้ BPF ไม่จำเป็นต้องให้ผู้ใช้มีทักษะการเขียนโปรแกรมเคอร์เนลหรือทักษะการเขียนโปรแกรมโดยทั่วไป) ความปลอดภัยรันไทม์ (ยกมือขึ้นในความคิดเห็น ผู้ที่ไม่ได้ทำลายระบบเมื่อเขียน หรือโมดูลการทดสอบ) atomicity - มีเวลาหยุดทำงานเมื่อโหลดโมดูลซ้ำ และระบบย่อย BPF รับประกันว่าจะไม่พลาดเหตุการณ์ใดๆ (พูดตามตรง ไม่จริงสำหรับโปรแกรม BPF ทุกประเภท)
การมีอยู่ของความสามารถดังกล่าวทำให้ BPF เป็นเครื่องมือสากลสำหรับการขยายแกนหลักซึ่งได้รับการยืนยันในทางปฏิบัติ: มีการเพิ่มโปรแกรมประเภทใหม่มากขึ้นใน BPF บริษัทขนาดใหญ่จำนวนมากขึ้นใช้ BPF บนเซิร์ฟเวอร์ต่อสู้ 24x7 การเริ่มต้นสร้างมากขึ้นเรื่อย ๆ ธุรกิจของพวกเขาเกี่ยวกับโซลูชั่น โดยอ้างอิงจาก BPF BPF ถูกใช้ทุกที่: เพื่อป้องกันการโจมตี DDoS, การสร้าง SDN (เช่น การติดตั้งเครือข่ายสำหรับ kubernetes) เป็นเครื่องมือหลักสำหรับระบบติดตามและรวบรวมสถิติ ในระบบตรวจจับการบุกรุกและระบบแซนด์บ็อกซ์ เป็นต้น
มาจบบทวิจารณ์ของบทความที่นี่ และดูรายละเอียดเพิ่มเติมเกี่ยวกับเครื่องเสมือนและระบบนิเวศของ BPF
การพูดนอกเรื่อง: สาธารณูปโภค
เพื่อให้สามารถรันตัวอย่างในส่วนต่อไปนี้ได้ คุณอาจต้องการโปรแกรมอรรถประโยชน์จำนวนหนึ่ง อย่างน้อยที่สุด llvm/clang ด้วยการสนับสนุน bpf และ bpftool. ในส่วน คุณสามารถอ่านคำแนะนำในการสร้างยูทิลิตี้รวมถึงเคอร์เนลของคุณเอง ส่วนนี้อยู่ด้านล่างเพื่อไม่ให้รบกวนความกลมกลืนของงานนำเสนอของเรา
การลงทะเบียนและชุดคำสั่งของเครื่องเสมือน BPF
สถาปัตยกรรมและระบบคำสั่งของ BPF ได้รับการพัฒนาโดยคำนึงถึงความจริงที่ว่าโปรแกรมจะเขียนด้วยภาษา C และหลังจากโหลดลงในเคอร์เนลแล้วจะแปลเป็นโค้ดเนทีฟ ดังนั้นจำนวนการลงทะเบียนและชุดคำสั่งจึงถูกเลือกโดยคำนึงถึงจุดตัดในความหมายทางคณิตศาสตร์ของความสามารถของเครื่องจักรสมัยใหม่ นอกจากนี้ โปรแกรมยังมีข้อจำกัดหลายประการ เช่น จนกระทั่งเมื่อไม่นานมานี้ ไม่สามารถเขียนลูปและรูทีนย่อยได้ และจำนวนคำสั่งถูกจำกัดอยู่ที่ 4096 (ขณะนี้โปรแกรมพิเศษสามารถโหลดได้มากถึงหนึ่งล้านคำสั่ง)
BPF มีรีจิสเตอร์ 64 บิตที่ผู้ใช้เข้าถึงได้สิบเอ็ดรายการ r0-r10 และตัวนับโปรแกรม ลงทะเบียน r10 มีตัวชี้เฟรมและเป็นแบบอ่านอย่างเดียว โปรแกรมสามารถเข้าถึงสแต็กขนาด 512 ไบต์ ณ รันไทม์และหน่วยความจำที่ใช้ร่วมกันได้ไม่จำกัดจำนวนในรูปแบบของแผนที่
โปรแกรม BPF ได้รับอนุญาตให้เรียกใช้ชุดตัวช่วยเคอร์เนลเฉพาะได้ ขึ้นอยู่กับประเภทของโปรแกรม และล่าสุดคือฟังก์ชันปกติ ฟังก์ชันที่เรียกใช้แต่ละฟังก์ชันสามารถรับอาร์กิวเมนต์ที่ส่งในรีจิสเตอร์ได้สูงสุด XNUMX อาร์กิวเมนต์ r1-r5และค่าที่ส่งคืนจะถูกส่งไปที่ r0. รับประกันว่าหลังจากกลับจากฟังก์ชันเนื้อหาของรีจิสเตอร์ r6-r9 จะไม่เปลี่ยนแปลง
เพื่อการแปลโปรแกรมที่มีประสิทธิภาพ ให้ลงทะเบียน r0-r11 สำหรับสถาปัตยกรรมที่รองรับทั้งหมดจะถูกแมปกับรีจิสเตอร์จริงโดยเฉพาะ โดยคำนึงถึงฟีเจอร์ ABI ของสถาปัตยกรรมปัจจุบัน ตัวอย่างเช่นสำหรับ x86_64 ลงทะเบียน r1-r5ใช้ในการส่งพารามิเตอร์ฟังก์ชัน จะแสดงบน rdi, rsi, rdx, rcx, r8ซึ่งใช้ในการส่งพารามิเตอร์ไปยังฟังก์ชันต่างๆ x86_64. ตัวอย่างเช่น รหัสทางด้านซ้ายจะแปลเป็นรหัสทางด้านขวาดังนี้:
1: (b7) r1 = 1 mov $0x1,%rdi
2: (b7) r2 = 2 mov $0x2,%rsi
3: (b7) r3 = 3 mov $0x3,%rdx
4: (b7) r4 = 4 mov $0x4,%rcx
5: (b7) r5 = 5 mov $0x5,%r8
6: (85) call pc+1 callq 0x0000000000001ee8ลงทะเบียน r0 ยังใช้เพื่อส่งคืนผลลัพธ์ของการดำเนินการโปรแกรมและในการลงทะเบียน r1 โปรแกรมจะถูกส่งผ่านตัวชี้ไปยังบริบท - ขึ้นอยู่กับประเภทของโปรแกรม ตัวอย่างเช่น โครงสร้าง (สำหรับ XDP) หรือโครงสร้าง (สำหรับโปรแกรมเครือข่ายต่างๆ) หรือโครงสร้าง (สำหรับโปรแกรมติดตามประเภทต่างๆ) เป็นต้น
ดังนั้นเราจึงมีชุดของการลงทะเบียน ตัวช่วยเคอร์เนล สแต็ค ตัวชี้ไปยังบริบท และหน่วยความจำที่ใช้ร่วมกันในรูปแบบของแผนที่ ไม่ใช่ว่าทั้งหมดนี้มีความจำเป็นอย่างเด็ดขาดในการเดินทาง แต่ ...
เรามาอธิบายต่อและพูดคุยเกี่ยวกับระบบคำสั่งสำหรับการทำงานกับวัตถุเหล่านี้ ทั้งหมด () คำสั่ง BPF มีขนาด 64 บิตคงที่ หากคุณดูคำสั่งเดียวบนเครื่อง Big Endian 64 บิต คุณจะเห็น
![]()
ที่นี่ Code - นี่คือการเข้ารหัสคำสั่ง Dst/Src เป็นการเข้ารหัสต้นทางและปลายทางตามลำดับ Off - การเยื้องแบบ 16 บิตและ Imm เป็นจำนวนเต็ม 32 บิตแบบมีเครื่องหมายที่ใช้ในบางคำสั่ง (คล้ายกับค่าคงที่ K จาก cBPF) การเข้ารหัส Code มีหนึ่งในสองประเภท:
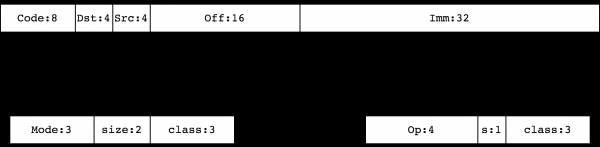
คลาสคำสั่ง 0, 1, 2, 3 กำหนดคำสั่งสำหรับการทำงานกับหน่วยความจำ พวกเขา , BPF_LD, BPF_LDX, BPF_ST, BPF_STXตามลำดับ รุ่นที่ 4, 7 (BPF_ALU, BPF_ALU64) เป็นชุดคำสั่ง ALU รุ่นที่ 5, 6 (BPF_JMP, BPF_JMP32) สรุปคำแนะนำการกระโดด
แผนเพิ่มเติมสำหรับการศึกษาระบบคำสั่ง BPF คือ: แทนที่จะแสดงรายการคำแนะนำและพารามิเตอร์ทั้งหมดอย่างพิถีพิถัน เราจะวิเคราะห์ตัวอย่างสองสามตัวอย่างในส่วนนี้ และจากนั้นจะเห็นได้ชัดว่าคำแนะนำใช้งานได้จริงอย่างไรและจะแยกชิ้นส่วนด้วยตนเองอย่างไร ไฟล์ไบนารีใด ๆ สำหรับ BPF ในการรวมเนื้อหาเพิ่มเติมในบทความ เราจะพบกับคำแนะนำส่วนบุคคลในส่วนเกี่ยวกับ Verifier, คอมไพเลอร์ JIT, การแปล BPF แบบคลาสสิก ตลอดจนเมื่อศึกษาแผนที่ ฟังก์ชันการโทร ฯลฯ
เมื่อเราพูดถึงคำสั่งแต่ละคำสั่ง เราจะอ้างถึงไฟล์เคอร์เนล и ซึ่งกำหนดรหัสตัวเลขของคำสั่ง BPF เมื่อศึกษาสถาปัตยกรรมด้วยตนเองและ/หรือแยกวิเคราะห์ไบนารี คุณสามารถค้นหาความหมายได้จากแหล่งข้อมูลต่อไปนี้ โดยจัดเรียงตามความซับซ้อน: , , และแน่นอน ในซอร์สโค้ดด้วย Linux — ตัวตรวจสอบ, JIT, ตัวแปล BPF
ตัวอย่าง: การแยกส่วน BPF ในหัวของคุณ
มาดูตัวอย่างที่เราจะคอมไพล์โปรแกรมกัน readelf-example.c และดูผลลัพธ์ไบนารี่ เราจะเปิดเผยเนื้อหาต้นฉบับ readelf-example.c ด้านล่างหลังจากกู้คืนลอจิกจากรหัสไบนารี:
$ clang -target bpf -c readelf-example.c -o readelf-example.o -O2
$ llvm-readelf -x .text readelf-example.o
Hex dump of section '.text':
0x00000000 b7000000 01000000 15010100 00000000 ................
0x00000010 b7000000 02000000 95000000 00000000 ................คอลัมน์แรกในเอาต์พุต readelf คือการเยื้องและโปรแกรมของเราจึงประกอบด้วยสี่คำสั่ง:
Code Dst Src Off Imm
b7 0 0 0000 01000000
15 0 1 0100 00000000
b7 0 0 0000 02000000
95 0 0 0000 00000000รหัสคำสั่งมีค่าเท่ากัน b7, 15, b7 и 95. จำได้ว่าบิตที่มีนัยสำคัญน้อยที่สุดสามบิตคือคลาสของคำสั่ง ในกรณีของเรา บิตที่สี่ของคำสั่งทั้งหมดว่างเปล่า ดังนั้น คลาสคำสั่งจึงเป็น 7, 5, 7, 5 ตามลำดับ คลาส 7 คือ BPF_ALU64และ 5 คือ BPF_JMP. สำหรับทั้งสองคลาส รูปแบบคำสั่งจะเหมือนกัน (ดูด้านบน) และเราสามารถเขียนโปรแกรมของเราใหม่ได้ในลักษณะนี้ (ในขณะเดียวกัน เราจะเขียนคอลัมน์ที่เหลือใหม่ในรูปแบบของมนุษย์):
Op S Class Dst Src Off Imm
b 0 ALU64 0 0 0 1
1 0 JMP 0 1 1 0
b 0 ALU64 0 0 0 2
9 0 JMP 0 0 0 0การทำงาน b ชั้น ALU64 - เป็น . มันกำหนดค่าให้กับการลงทะเบียนปลายทาง ถ้าบิตถูกตั้งค่าไว้ s (แหล่งที่มา) จากนั้นค่าจะถูกนำมาจากรีจิสเตอร์ต้นทางและหากไม่ได้ตั้งค่าในกรณีของเราค่านั้นจะถูกนำมาจากฟิลด์ Imm. ดังนั้นในคำแนะนำที่หนึ่งและสามเราจึงดำเนินการ r0 = Imm. นอกจากนี้ การดำเนินการของ JMP คลาส 1 ก็คือ (กระโดดถ้าเท่ากัน). ในกรณีของเราตั้งแต่บิต S เป็นศูนย์ โดยจะเปรียบเทียบค่าของรีจิสเตอร์ต้นทางกับฟิลด์ Imm. หากค่าตรงกันการเปลี่ยนแปลงจะเกิดขึ้น PC + Offที่ไหน PCตามปกติจะมีที่อยู่ของคำสั่งถัดไป สุดท้ายปฏิบัติการ JMP Class 9 ก็คือ . คำสั่งนี้จะยุติโปรแกรมโดยกลับไปที่เคอร์เนล r0. เพิ่มคอลัมน์ใหม่ในตารางของเรา:
Op S Class Dst Src Off Imm Disassm
MOV 0 ALU64 0 0 0 1 r0 = 1
JEQ 0 JMP 0 1 1 0 if (r1 == 0) goto pc+1
MOV 0 ALU64 0 0 0 2 r0 = 2
EXIT 0 JMP 0 0 0 0 exitเราสามารถเขียนใหม่ด้วยวิธีที่สะดวกกว่า:
r0 = 1
if (r1 == 0) goto END
r0 = 2
END:
exitหากเราจำสิ่งที่อยู่ในทะเบียนได้ r1 โปรแกรมจะถูกส่งผ่านตัวชี้ไปยังบริบทจากเคอร์เนลและในรีจิสเตอร์ r0 ค่าจะถูกส่งกลับไปยังเคอร์เนล จากนั้นเราจะเห็นว่าหากตัวชี้ไปยังบริบทเป็นศูนย์ เราจะส่งคืน 1 หรือไม่เช่นนั้น - 2 ลองตรวจสอบว่าเราพูดถูกโดยดูที่แหล่งที่มา:
$ cat readelf-example.c
int foo(void *ctx)
{
return ctx ? 2 : 1;
}ใช่ มันเป็นโปรแกรมที่ไม่มีความหมาย แต่แปลเป็นคำสั่งง่ายๆ เพียงสี่คำสั่งเท่านั้น
ตัวอย่างข้อยกเว้น: คำสั่ง 16 ไบต์
เราได้กล่าวไว้ก่อนหน้านี้ว่าบางคำสั่งใช้มากกว่า 64 บิต สิ่งนี้ใช้กับคำแนะนำ lddw (รหัส = 0x18 = | | ) - โหลดคำสองคำจากฟิลด์ลงในทะเบียน Imm. ความจริงก็คือ Imm มีขนาด 32 และ double word คือ 64 บิต ดังนั้นการโหลดค่าทันที 64 บิตลงในรีจิสเตอร์ในคำสั่ง 64 บิตเดียวจะไม่ทำงาน เมื่อต้องการทำเช่นนี้ จะใช้คำสั่งสองคำสั่งที่อยู่ติดกันเพื่อจัดเก็บส่วนที่สองของค่า 64 บิตลงในฟิลด์ Imm. ตัวอย่างเช่น:
$ cat x64.c
long foo(void *ctx)
{
return 0x11223344aabbccdd;
}
$ clang -target bpf -c x64.c -o x64.o -O2
$ llvm-readelf -x .text x64.o
Hex dump of section '.text':
0x00000000 18000000 ddccbbaa 00000000 44332211 ............D3".
0x00000010 95000000 00000000 ........มีเพียงสองคำสั่งในโปรแกรมไบนารี:
Binary Disassm
18000000 ddccbbaa 00000000 44332211 r0 = Imm[0]|Imm[1]
95000000 00000000 exitเราจะพบกันใหม่กับคำแนะนำ lddwเมื่อเราพูดถึงการย้ายที่ตั้งและการทำงานกับแผนที่
ตัวอย่าง: การแยกชิ้นส่วน BPF โดยใช้เครื่องมือมาตรฐาน
ดังนั้นเราจึงได้เรียนรู้วิธีการอ่านรหัสไบนารีของ BPF และพร้อมที่จะแยกวิเคราะห์คำสั่งใดๆ หากจำเป็น อย่างไรก็ตามควรกล่าวว่าในทางปฏิบัติจะสะดวกและรวดเร็วกว่าในการแยกโปรแกรมโดยใช้เครื่องมือมาตรฐานเช่น:
$ llvm-objdump -d x64.o
Disassembly of section .text:
0000000000000000 <foo>:
0: 18 00 00 00 dd cc bb aa 00 00 00 00 44 33 22 11 r0 = 1234605617868164317 ll
2: 95 00 00 00 00 00 00 00 exitวงจรชีวิตของอ็อบเจ็กต์ BPF ระบบไฟล์ bpffs
(รายละเอียดบางส่วนที่อธิบายไว้ในส่วนย่อยนี้ฉันได้เรียนรู้จาก อเล็กซี่ สตาร์โวอิตอฟ .)
วัตถุ BPF - โปรแกรมและแผนที่ - ถูกสร้างขึ้นจากพื้นที่ผู้ใช้โดยใช้คำสั่ง BPF_PROG_LOAD и BPF_MAP_CREATE การโทรของระบบ bpf(2)เราจะพูดถึงสิ่งที่เกิดขึ้นในหัวข้อถัดไป ในเวลาเดียวกัน โครงสร้างข้อมูลเคอร์เนลจะถูกสร้างขึ้นและสำหรับแต่ละโครงสร้าง refcount (จำนวนการอ้างอิง) ถูกตั้งค่าเป็นหนึ่ง และตัวอธิบายไฟล์ที่ชี้ไปยังวัตถุจะถูกส่งกลับไปยังผู้ใช้ หลังจากปิดที่จับ refcount วัตถุจะลดลงหนึ่ง และเมื่อถึงศูนย์ วัตถุจะถูกทำลาย
หากโปรแกรมใช้แผนที่แล้ว refcount ของแผนที่เหล่านี้จะเพิ่มขึ้นหนึ่งแผนที่หลังจากโหลดโปรแกรม เช่น ตัวอธิบายไฟล์สามารถปิดได้จากกระบวนการของผู้ใช้และยังคง refcount จะไม่กลายเป็นโมฆะ:
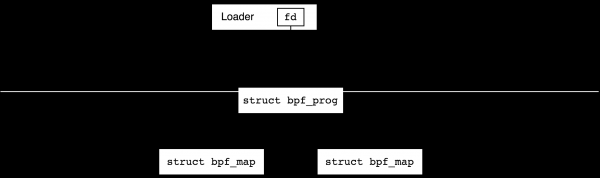
หลังจากโหลดโปรแกรมสำเร็จแล้ว เรามักจะแนบโปรแกรมนั้นกับตัวสร้างเหตุการณ์บางประเภท ตัวอย่างเช่น เราสามารถวางไว้บนอินเทอร์เฟซเครือข่ายเพื่อประมวลผลแพ็กเก็ตขาเข้าหรือเชื่อมต่อกับบางส่วน tracepoint ในแกนกลาง ณ จุดนี้ จำนวนลิงก์จะเพิ่มขึ้นทีละหนึ่ง และเราสามารถปิดตัวอธิบายไฟล์ในตัวโหลดได้
จะเกิดอะไรขึ้นถ้าเราปิดโปรแกรมโหลดบูตตอนนี้? ขึ้นอยู่กับประเภทของตัวสร้างเหตุการณ์ (ฮุค) hooks เครือข่ายทั้งหมดจะยังคงอยู่หลังจากที่ตัวโหลดเสร็จสิ้น ซึ่งเรียกว่า hooks ทั่วโลก และ ตัวอย่างเช่น โปรแกรมการติดตามจะถูกปล่อยออกมาหลังจากกระบวนการที่สร้างโปรแกรมเหล่านั้นยุติลง (และด้วยเหตุนี้จึงเรียกว่าโลคัล จาก "โลคัลถึงโปรเซส") ในทางเทคนิคแล้ว hooks ในเครื่องจะมีตัวอธิบายไฟล์ที่เกี่ยวข้องในพื้นที่ผู้ใช้เสมอ ดังนั้นจะปิดเมื่อกระบวนการถูกปิด แต่ hooks ทั่วโลกไม่มี ในรูปต่อไปนี้ โดยใช้กากบาทสีแดง ฉันพยายามแสดงให้เห็นว่าการยุติโปรแกรมตัวโหลดส่งผลต่ออายุการใช้งานของอ็อบเจ็กต์ในกรณีของ hook ภายในและส่วนกลางอย่างไร
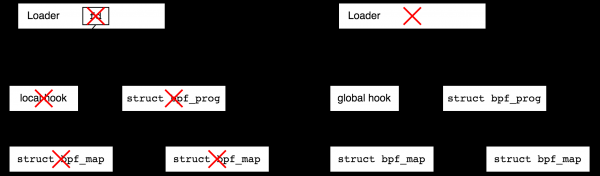
เหตุใดจึงมีความแตกต่างระหว่าง hooks ระดับท้องถิ่นและระดับโลก การเรียกใช้โปรแกรมเครือข่ายบางประเภทนั้นสมเหตุสมผลหากไม่มีพื้นที่ผู้ใช้ ตัวอย่างเช่น ลองนึกภาพการป้องกัน DDoS - bootloader จะเขียนกฎและเชื่อมต่อโปรแกรม BPF เข้ากับอินเทอร์เฟซเครือข่าย หลังจากนั้น bootloader สามารถไปและฆ่าตัวเองได้ ในทางกลับกัน ลองจินตนาการถึงโปรแกรมการติดตามการดีบักที่คุณเขียนไว้ภายในสิบนาที เมื่อเสร็จสิ้น คุณคงไม่อยากให้มีขยะเหลืออยู่ในระบบ และ hooks ในเครื่องจะรับประกันสิ่งนั้น
ในทางกลับกัน ลองจินตนาการว่าคุณต้องการเชื่อมต่อกับจุดติดตามในเคอร์เนลและรวบรวมสถิติเป็นเวลาหลายปี ในกรณีนี้ คุณต้องการทำส่วนผู้ใช้ให้เสร็จและกลับไปที่สถิติเป็นครั้งคราว คุณลักษณะนี้มีให้โดยระบบไฟล์ bpf นี่คือระบบไฟล์หลอกที่ใช้หน่วยความจำเท่านั้นที่อนุญาตให้คุณสร้างไฟล์ที่อ้างถึงอ็อบเจ็กต์ BPF และด้วยเหตุนี้จึงเพิ่ม refcount วัตถุ หลังจากนี้ ตัวโหลดสามารถออกได้ และวัตถุที่สร้างขึ้นจะยังคงอยู่
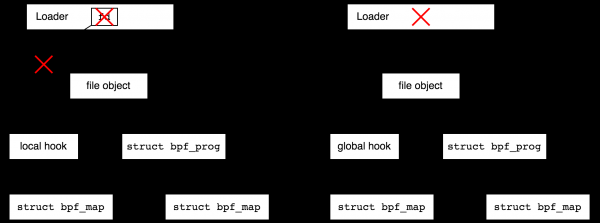
การสร้างไฟล์ใน bpffs ที่อ้างถึงออบเจกต์ BPF เรียกว่า "การปักหมุด" ("การปักหมุด" ดังเช่นในวลีต่อไปนี้: "กระบวนการสามารถปักหมุดโปรแกรมหรือแผนที่ BPF") การสร้างออบเจกต์ไฟล์สำหรับออบเจ็กต์ BPF นั้นเหมาะสมไม่เพียงแต่เพื่อยืดอายุของออบเจ็กต์ในเครื่องเท่านั้น แต่ยังเพื่อความสะดวกในการใช้ออบเจกต์ส่วนกลางอีกด้วย ย้อนกลับไปที่ตัวอย่างด้วยโปรแกรมป้องกัน DDoS ส่วนกลาง เราต้องการให้มาดูที่ สถิติครั้งแล้วครั้งเล่า
ระบบไฟล์ BPF มักจะติดตั้งบน /sys/fs/bpfแต่ยังสามารถติดตั้งในเครื่องได้ เช่น:
$ mkdir bpf-mountpoint
$ sudo mount -t bpf none bpf-mountpointชื่อในระบบไฟล์ถูกสร้างขึ้นโดยใช้คำสั่ง BPF_OBJ_PIN การเรียกระบบ BPF เพื่อให้เห็นภาพ ลองใช้โปรแกรม คอมไพล์ อัพโหลด และปักหมุดมันลงไป bpffs. โปรแกรมของเราไม่ได้มีประโยชน์อะไร เราเพียงแต่นำเสนอโค้ดเพื่อให้คุณสามารถทำซ้ำตัวอย่างได้:
$ cat test.c
__attribute__((section("xdp"), used))
int test(void *ctx)
{
return 0;
}
char _license[] __attribute__((section("license"), used)) = "GPL";มาคอมไพล์โปรแกรมนี้และสร้างสำเนาของระบบไฟล์ในเครื่อง bpffs:
$ clang -target bpf -c test.c -o test.o
$ mkdir bpf-mountpoint
$ sudo mount -t bpf none bpf-mountpointตอนนี้เรามาดาวน์โหลดโปรแกรมของเราโดยใช้ยูทิลิตี้นี้ bpftool และดูที่การเรียกระบบประกอบ bpf(2) (บางบรรทัดที่ไม่เกี่ยวข้องถูกลบออกจากเอาต์พุต strace):
$ sudo strace -e bpf bpftool prog load ./test.o bpf-mountpoint/test
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_XDP, prog_name="test", ...}, 120) = 3
bpf(BPF_OBJ_PIN, {pathname="bpf-mountpoint/test", bpf_fd=3}, 120) = 0ที่นี่เราได้โหลดโปรแกรมด้วย BPF_PROG_LOADได้รับตัวอธิบายไฟล์จากเคอร์เนล 3 และด้วยคำสั่ง BPF_OBJ_PIN ปักหมุดตัวอธิบายไฟล์นี้เป็นไฟล์ "bpf-mountpoint/test". จากนั้นตัวดาวน์โหลด bpftool ทำงานเสร็จแล้ว แต่โปรแกรมของเรายังคงอยู่ในเคอร์เนลแม้ว่าเราจะไม่ได้แนบมันเข้ากับอินเทอร์เฟซเครือข่ายก็ตาม:
$ sudo bpftool prog | tail -3
783: xdp name test tag 5c8ba0cf164cb46c gpl
loaded_at 2020-05-05T13:27:08+0000 uid 0
xlated 24B jited 41B memlock 4096Bเราสามารถลบวัตถุไฟล์ได้ตามปกติ unlink(2) และหลังจากนั้นโปรแกรมที่เกี่ยวข้องจะถูกลบออก:
$ sudo rm ./bpf-mountpoint/test
$ sudo bpftool prog show id 783
Error: get by id (783): No such file or directoryการลบวัตถุ
เมื่อพูดถึงการลบอ็อบเจ็กต์ จำเป็นต้องชี้แจงว่าหลังจากที่เรายกเลิกการเชื่อมต่อโปรแกรมจากฮุค (ตัวสร้างเหตุการณ์) แล้ว ไม่มีเหตุการณ์ใหม่สักเหตุการณ์เดียวที่จะทริกเกอร์การเปิดตัว อย่างไรก็ตาม อินสแตนซ์ปัจจุบันทั้งหมดของโปรแกรมจะเสร็จสมบูรณ์ในลำดับปกติ .
โปรแกรม BPF บางประเภทอนุญาตให้คุณเปลี่ยนโปรแกรมได้ทันที เช่น ให้ลำดับอะตอมมิกซิตี replace = detach old program, attach new program. ในกรณีนี้ อินสแตนซ์ที่ใช้งานอยู่ทั้งหมดของโปรแกรมเวอร์ชันเก่าจะทำงานให้เสร็จ และเครื่องจัดการเหตุการณ์ใหม่จะถูกสร้างขึ้นจากโปรแกรมใหม่ และ "อะตอมมิกซิตี" ในที่นี้หมายความว่าจะไม่มีเหตุการณ์ใดพลาดไป
การแนบโปรแกรมกับแหล่งเหตุการณ์
ในบทความนี้ เราจะไม่อธิบายความเชื่อมโยงของโปรแกรมกับแหล่งเหตุการณ์แยกกัน เนื่องจากเป็นการเหมาะสมที่จะศึกษาสิ่งนี้ในบริบทของโปรแกรมประเภทใดประเภทหนึ่งโดยเฉพาะ ซม. ด้านล่าง ซึ่งเราจะแสดงวิธีการเชื่อมต่อโปรแกรมเช่น XDP
การจัดการวัตถุโดยใช้การเรียกระบบ bpf
โปรแกรมบีพีเอฟ
อ็อบเจ็กต์ BPF ทั้งหมดถูกสร้างและจัดการจากพื้นที่ผู้ใช้โดยใช้การเรียกระบบ bpfโดยมีต้นแบบดังนี้
#include <linux/bpf.h>
int bpf(int cmd, union bpf_attr *attr, unsigned int size);นี่คือทีม cmd เป็นหนึ่งในค่าประเภท , attr - ตัวชี้ไปยังพารามิเตอร์สำหรับโปรแกรมเฉพาะและ size — ขนาดของวัตถุตามตัวชี้ เช่น โดยปกตินี้ sizeof(*attr). ในการเรียกระบบเคอร์เนล 5.8 bpf รองรับคำสั่งที่แตกต่างกัน 34 คำสั่ง และ union bpf_attr ครอบคลุม 200 เส้น แต่เราไม่ควรกังวลกับสิ่งนี้ เนื่องจากเราจะทำความคุ้นเคยกับคำสั่งและพารามิเตอร์ต่างๆ ในหลายบทความ
เริ่มจากทีมกันก่อน BPF_PROG_LOADซึ่งสร้างโปรแกรม BPF - รับชุดคำสั่ง BPF และโหลดลงในเคอร์เนล ในขณะที่ทำการโหลด ตัวตรวจสอบจะเปิดใช้งาน จากนั้นคอมไพเลอร์ JIT และหลังจากดำเนินการสำเร็จ ไฟล์ตัวอธิบายของโปรแกรมจะถูกส่งคืนให้กับผู้ใช้ เราเห็นว่าจะเกิดอะไรขึ้นกับเขาต่อไปในส่วนที่แล้ว .
ตอนนี้เราจะเขียนโปรแกรมแบบกำหนดเองที่จะโหลดโปรแกรม BPF อย่างง่าย แต่ก่อนอื่นเราต้องตัดสินใจว่าเราต้องการโหลดโปรแกรมประเภทใด - เราจะต้องเลือก และภายใต้กรอบประเภทนี้ให้เขียนโปรแกรมที่จะผ่านการทดสอบบนตัวตรวจสอบ อย่างไรก็ตามเพื่อไม่ให้กระบวนการซับซ้อนนี่คือวิธีแก้ปัญหาสำเร็จรูป: เราจะใช้โปรแกรมเช่น BPF_PROG_TYPE_XDPซึ่งจะคืนค่ากลับมา XDP_PASS (ข้ามแพ็คเกจทั้งหมด) ในแอสเซมเบลอร์ BPF มันดูง่ายมาก:
r0 = 2
exitหลังจากที่เราได้ตัดสินใจแล้ว ที่ เราจะอัปโหลด เราสามารถบอกได้ว่าเราจะดำเนินการอย่างไร:
#define _GNU_SOURCE
#include <string.h>
#include <unistd.h>
#include <sys/syscall.h>
#include <linux/bpf.h>
static inline __u64 ptr_to_u64(const void *ptr)
{
return (__u64) (unsigned long) ptr;
}
int main(void)
{
struct bpf_insn insns[] = {
{
.code = BPF_ALU64 | BPF_MOV | BPF_K,
.dst_reg = BPF_REG_0,
.imm = XDP_PASS
},
{
.code = BPF_JMP | BPF_EXIT
},
};
union bpf_attr attr = {
.prog_type = BPF_PROG_TYPE_XDP,
.insns = ptr_to_u64(insns),
.insn_cnt = sizeof(insns)/sizeof(insns[0]),
.license = ptr_to_u64("GPL"),
};
strncpy(attr.prog_name, "woo", sizeof(attr.prog_name));
syscall(__NR_bpf, BPF_PROG_LOAD, &attr, sizeof(attr));
for ( ;; )
pause();
}เหตุการณ์ที่น่าสนใจในโปรแกรมเริ่มต้นด้วยการกำหนดอาร์เรย์ insns - โปรแกรม BPF ของเราในรหัสเนทีฟ ในกรณีนี้ แต่ละคำสั่งของโปรแกรม BPF จะถูกรวมไว้ในโครงสร้าง . องค์ประกอบแรก insns สอดคล้องกับคำแนะนำ r0 = 2, ที่สอง - exit.
ล่าถอย. เคอร์เนลกำหนดมาโครที่สะดวกยิ่งขึ้นสำหรับการเขียนรหัสเครื่อง และการใช้ไฟล์ส่วนหัวของเคอร์เนล tools/include/linux/filter.h เราสามารถเขียน
struct bpf_insn insns[] = {
BPF_MOV64_IMM(BPF_REG_0, XDP_PASS),
BPF_EXIT_INSN()
};แต่เนื่องจากการเขียนโปรแกรม BPF ในโค้ดแบบเนทีฟนั้นจำเป็นสำหรับการเขียนการทดสอบในคอร์และบทความเกี่ยวกับ BPF เท่านั้น การไม่มีมาโครเหล่านี้ไม่ได้ทำให้ชีวิตของนักพัฒนาซับซ้อนขึ้น
หลังจากกำหนดโปรแกรม BPF แล้ว เราก็ไปยังการโหลดมันลงในเคอร์เนล ชุดพารามิเตอร์ที่เรียบง่ายของเรา attr ประกอบด้วยประเภทของโปรแกรม ชุดและจำนวนชุดคำสั่ง ใบอนุญาตที่จำเป็น และชื่อ "woo"ซึ่งเราใช้เพื่อค้นหาโปรแกรมของเราในระบบหลังจากโหลดเสร็จแล้ว โปรแกรมถูกโหลดเข้าสู่ระบบโดยใช้การเรียกระบบตามที่สัญญาไว้ bpf.
ในตอนท้ายของโปรแกรม เราจะจบลงด้วยการวนซ้ำไม่สิ้นสุดซึ่งจำลองเพย์โหลด หากไม่มีเคอร์เนลโปรแกรมจะถูกฆ่าโดยเคอร์เนลเมื่อปิดตัวอธิบายไฟล์ที่การเรียกของระบบส่งคืนถึงเรา bpfและเราจะไม่เห็นในระบบ
เอาล่ะ เราพร้อมสำหรับการทดสอบแล้ว มาประกอบและรันโปรแกรมด้านล่างกัน straceเพื่อตรวจสอบว่าทุกอย่างทำงานได้ตามปกติ:
$ clang -g -O2 simple-prog.c -o simple-prog
$ sudo strace ./simple-prog
execve("./simple-prog", ["./simple-prog"], 0x7ffc7b553480 /* 13 vars */) = 0
...
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_XDP, insn_cnt=2, insns=0x7ffe03c4ed50, license="GPL", log_level=0, log_size=0, log_buf=NULL, kern_version=KERNEL_V
ERSION(0, 0, 0), prog_flags=0, prog_name="woo", prog_ifindex=0, expected_attach_type=BPF_CGROUP_INET_INGRESS}, 72) = 3
pause(ทุกอย่างปกติดี, bpf(2) คืนค่า descriptor 3 ให้เรา และเราก็วนลูปไม่สิ้นสุดด้วย pause(). ลองหาโปรแกรมของเราในระบบดูครับ ในการทำเช่นนี้เราจะไปที่เทอร์มินัลอื่นและใช้ยูทิลิตี้นี้ bpftool:
# bpftool prog | grep -A3 woo
390: xdp name woo tag 3b185187f1855c4c gpl
loaded_at 2020-08-31T24:66:44+0000 uid 0
xlated 16B jited 40B memlock 4096B
pids simple-prog(10381)เราเห็นว่าระบบมีโปรแกรมโหลดอยู่ woo ซึ่งรหัสสากลคือ 390 และสิ่งที่กำลังดำเนินการอยู่ simple-prog มีตัวอธิบายไฟล์เปิดชี้ไปที่โปรแกรม (และถ้า simple-prog เสร็จงานแล้ว woo จะหายไป). ตามที่คาดไว้โปรแกรม woo ใช้เวลา 16 ไบต์ - สองคำสั่ง - ของรหัสไบนารี่ในสถาปัตยกรรม BPF แต่ในรูปแบบดั้งเดิม (x86_64) จะมีขนาด 40 ไบต์แล้ว มาดูโปรแกรมของเราในรูปแบบดั้งเดิม:
# bpftool prog dump xlated id 390
0: (b7) r0 = 2
1: (95) exitไม่แปลกใจ. ทีนี้มาดูรหัสที่สร้างโดยคอมไพเลอร์ JIT:
# bpftool prog dump jited id 390
bpf_prog_3b185187f1855c4c_woo:
0: nopl 0x0(%rax,%rax,1)
5: push %rbp
6: mov %rsp,%rbp
9: sub $0x0,%rsp
10: push %rbx
11: push %r13
13: push %r14
15: push %r15
17: pushq $0x0
19: mov $0x2,%eax
1e: pop %rbx
1f: pop %r15
21: pop %r14
23: pop %r13
25: pop %rbx
26: leaveq
27: retqไม่ค่อยมีประสิทธิภาพสำหรับ exit(2)แต่ตามความเป็นจริงแล้ว โปรแกรมของเราเรียบง่ายเกินไป และสำหรับโปรแกรมที่ไม่ซับซ้อน แน่นอนว่าจำเป็นต้องมีบทนำและบทส่งท้ายที่เพิ่มโดยคอมไพเลอร์ JIT
แผนที่
โปรแกรม BPF สามารถใช้พื้นที่หน่วยความจำที่มีโครงสร้างซึ่งมีให้ทั้งโปรแกรม BPF อื่นๆ และโปรแกรมพื้นที่ผู้ใช้ ออบเจ็กต์เหล่านี้เรียกว่าแผนที่ และในส่วนนี้เราจะแสดงวิธีจัดการโดยใช้การเรียกระบบ bpf.
สมมติว่าความเป็นไปได้ของแผนที่ไม่ได้จำกัดอยู่เพียงการเข้าถึงหน่วยความจำที่ใช้ร่วมกันเท่านั้น มีแผนที่สำหรับวัตถุประสงค์พิเศษ เช่น ตัวชี้ไปยังโปรแกรม BPF หรือตัวชี้ไปยังอินเทอร์เฟซเครือข่าย แผนที่สำหรับการทำงานกับเหตุการณ์ที่สมบูรณ์แบบ เป็นต้น ที่นี่เราจะไม่พูดถึงพวกเขาเพื่อไม่ให้ผู้อ่านสับสน นอกเหนือจากนั้น เรากำลังเพิกเฉยต่อปัญหาเรื่องเวลา เนื่องจากสิ่งเหล่านี้ไม่สำคัญสำหรับตัวอย่างของเรา สามารถดูรายการประเภทแผนที่ที่มีอยู่ทั้งหมดได้ใน และในส่วนนี้เราจะยกตัวอย่างประเภทแรกในอดีตคือตารางแฮช BPF_MAP_TYPE_HASH.
หากคุณกำลังสร้างตารางแฮชใน C++ คุณจะพูดว่า unordered_map<int,long> wooซึ่งในภาษารัสเซียแปลว่า “ฉันต้องการโต๊ะ” woo ไม่จำกัดขนาด โดยมีประเภทกุญแจ intและค่าเป็นประเภท long". ในการสร้างตารางแฮช BPF เราต้องทำสิ่งเดียวกันโดยประมาณ ยกเว้นว่าเราจะต้องระบุขนาดสูงสุดของตาราง และแทนที่จะระบุประเภทของคีย์และค่า เราต้องระบุขนาดเป็นไบต์ . สร้างแผนที่โดยใช้คำสั่ง BPF_MAP_CREATE การโทรของระบบ bpf. มาดูโปรแกรมขั้นต่ำที่สร้างแผนที่กัน หลังจากโปรแกรมก่อนหน้านี้ที่โหลดโปรแกรม BPF โปรแกรมนี้ควรมีลักษณะเรียบง่าย:
$ cat simple-map.c
#define _GNU_SOURCE
#include <string.h>
#include <unistd.h>
#include <sys/syscall.h>
#include <linux/bpf.h>
int main(void)
{
union bpf_attr attr = {
.map_type = BPF_MAP_TYPE_HASH,
.key_size = sizeof(int),
.value_size = sizeof(int),
.max_entries = 4,
};
strncpy(attr.map_name, "woo", sizeof(attr.map_name));
syscall(__NR_bpf, BPF_MAP_CREATE, &attr, sizeof(attr));
for ( ;; )
pause();
}ที่นี่เรากำหนดชุดของพารามิเตอร์ attrซึ่งเราพูดว่า "ฉันต้องการตารางแฮชที่มีคีย์และค่าขนาด sizeof(int)ซึ่งฉันสามารถใส่ได้สูงสุดสี่องค์ประกอบ เมื่อสร้างแผนที่ BPF คุณสามารถระบุพารามิเตอร์อื่นๆ ได้ เช่น ในตัวอย่างกับโปรแกรม เราระบุชื่อของวัตถุเป็น "woo".
มาคอมไพล์และรันโปรแกรม:
$ clang -g -O2 simple-map.c -o simple-map
$ sudo strace ./simple-map
execve("./simple-map", ["./simple-map"], 0x7ffd40a27070 /* 14 vars */) = 0
...
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_HASH, key_size=4, value_size=4, max_entries=4, map_name="woo", ...}, 72) = 3
pause(นี่คือการเรียกของระบบ bpf(2) ส่งหมายเลขอธิบายแผนที่มาให้เรา 3 จากนั้นโปรแกรมจะรอคำแนะนำเพิ่มเติมในการเรียกของระบบตามที่คาดไว้ pause(2).
ตอนนี้ให้ส่งโปรแกรมของเราไปที่พื้นหลังหรือเปิดเทอร์มินัลอื่นแล้วดูวัตถุของเราโดยใช้ยูทิลิตี้ bpftool (เราสามารถแยกแยะแผนที่ของเราจากแผนที่อื่นได้ด้วยชื่อของมัน):
$ sudo bpftool map
...
114: hash name woo flags 0x0
key 4B value 4B max_entries 4 memlock 4096B
...หมายเลข 114 คือรหัสสากลของวัตถุของเรา โปรแกรมใดๆ ในระบบสามารถใช้ ID นี้เพื่อเปิดแผนที่ที่มีอยู่โดยใช้คำสั่ง BPF_MAP_GET_FD_BY_ID การโทรของระบบ bpf.
ตอนนี้เราสามารถเล่นกับตารางแฮชของเรา มาดูเนื้อหากัน:
$ sudo bpftool map dump id 114
Found 0 elementsว่างเปล่า. ลองใส่ค่าลงไป hash[1] = 1:
$ sudo bpftool map update id 114 key 1 0 0 0 value 1 0 0 0ลองดูที่ตารางอีกครั้ง:
$ sudo bpftool map dump id 114
key: 01 00 00 00 value: 01 00 00 00
Found 1 elementไชโย! เราจัดการเพื่อเพิ่มหนึ่งองค์ประกอบ โปรดทราบว่าเราต้องทำงานในระดับไบต์ตั้งแต่นั้นเป็นต้นมา bptftool ไม่รู้ว่าค่าในตารางแฮชเป็นประเภทไหน (ความรู้นี้สามารถถ่ายทอดให้เธอได้โดยใช้ BTF แต่ตอนนี้มีมากกว่านั้น)
bpftool อ่านและเพิ่มองค์ประกอบอย่างไร มาดูใต้ฝากระโปรง:
$ sudo strace -e bpf bpftool map dump id 114
bpf(BPF_MAP_GET_FD_BY_ID, {map_id=114, next_id=0, open_flags=0}, 120) = 3
bpf(BPF_MAP_GET_NEXT_KEY, {map_fd=3, key=NULL, next_key=0x55856ab65280}, 120) = 0
bpf(BPF_MAP_LOOKUP_ELEM, {map_fd=3, key=0x55856ab65280, value=0x55856ab652a0}, 120) = 0
key: 01 00 00 00 value: 01 00 00 00
bpf(BPF_MAP_GET_NEXT_KEY, {map_fd=3, key=0x55856ab65280, next_key=0x55856ab65280}, 120) = -1 ENOENTก่อนอื่นเราเปิดแผนที่ด้วยรหัสสากลโดยใช้คำสั่ง BPF_MAP_GET_FD_BY_ID и bpf(2) ส่งคำอธิบาย 3 ให้เรา ถัดไปโดยใช้คำสั่ง BPF_MAP_GET_NEXT_KEY เราพบคีย์แรกในตารางโดยผ่าน NULL เป็นตัวชี้ไปยังคีย์ "ก่อนหน้า" ถ้าเรามีกุญแจเราก็ทำได้ BPF_MAP_LOOKUP_ELEMซึ่งส่งคืนค่าในตัวชี้ value. ขั้นตอนต่อไปคือเราพยายามค้นหาองค์ประกอบถัดไปโดยส่งพอยน์เตอร์ไปยังคีย์ปัจจุบัน แต่ตารางของเรามีเพียงองค์ประกอบเดียวและคำสั่ง BPF_MAP_GET_NEXT_KEY ผลตอบแทน ENOENT.
เอาล่ะ มาเปลี่ยนค่าด้วยคีย์ 1 สมมติว่าตรรกะทางธุรกิจของเราต้องการการลงทะเบียน hash[1] = 2:
$ sudo strace -e bpf bpftool map update id 114 key 1 0 0 0 value 2 0 0 0
bpf(BPF_MAP_GET_FD_BY_ID, {map_id=114, next_id=0, open_flags=0}, 120) = 3
bpf(BPF_MAP_UPDATE_ELEM, {map_fd=3, key=0x55dcd72be260, value=0x55dcd72be280, flags=BPF_ANY}, 120) = 0ตามที่คาดไว้ มันง่ายมาก: คำสั่ง BPF_MAP_GET_FD_BY_ID เปิดแผนที่ของเราด้วย ID และคำสั่ง BPF_MAP_UPDATE_ELEM เขียนทับองค์ประกอบ
ดังนั้น หลังจากสร้างตารางแฮชจากโปรแกรมหนึ่งแล้ว เราสามารถอ่านและเขียนเนื้อหาจากโปรแกรมอื่นได้ โปรดทราบว่าหากเราสามารถทำได้จากบรรทัดคำสั่ง ก็อาจเป็นโปรแกรมอื่นในระบบก็ได้ นอกเหนือจากคำสั่งที่อธิบายไว้ข้างต้นแล้ว ยังมีคำสั่งอื่นๆ ในการทำงานกับแผนที่จากพื้นที่ผู้ใช้อีกด้วย :
BPF_MAP_LOOKUP_ELEM: ค้นหาค่าด้วยคีย์BPF_MAP_UPDATE_ELEM: อัพเดต/สร้างมูลค่าBPF_MAP_DELETE_ELEM: ปุ่มลบBPF_MAP_GET_NEXT_KEY: ค้นหาคีย์ถัดไป (หรือคีย์แรก)BPF_MAP_GET_NEXT_ID: ให้คุณผ่านแผนที่ที่มีอยู่ทั้งหมด นี่คือวิธีการทำงานbpftool mapBPF_MAP_GET_FD_BY_ID: เปิดแผนที่ที่มีอยู่โดย ID สากลBPF_MAP_LOOKUP_AND_DELETE_ELEM: อัปเดตค่าของวัตถุแบบอะตอมมิกและส่งคืนค่าเก่าBPF_MAP_FREEZE: ทำให้แผนที่ไม่เปลี่ยนรูปจาก userspace (การดำเนินการนี้ไม่สามารถยกเลิกได้)BPF_MAP_LOOKUP_BATCH,BPF_MAP_LOOKUP_AND_DELETE_BATCH,BPF_MAP_UPDATE_BATCH,BPF_MAP_DELETE_BATCH: การดำเนินการจำนวนมาก ตัวอย่างเช่น,BPF_MAP_LOOKUP_AND_DELETE_BATCH- นี่เป็นวิธีเดียวที่เชื่อถือได้ในการอ่านและรีเซ็ตค่าทั้งหมดจากแผนที่
คำสั่งเหล่านี้อาจใช้ไม่ได้กับแผนที่ทุกประเภท แต่โดยทั่วไปแล้ว การทำงานกับแผนที่ประเภทอื่นๆ จากพื้นที่ผู้ใช้จะมีลักษณะเหมือนกับการทำงานกับตารางแฮชทุกประการ
สำหรับการสั่งซื้อ มาทำการทดสอบตารางแฮชของเราให้สมบูรณ์กันเถอะ โปรดจำไว้ว่าเราสร้างตารางที่สามารถมีได้ถึงสี่คีย์? มาเพิ่มองค์ประกอบอีกเล็กน้อย:
$ sudo bpftool map update id 114 key 2 0 0 0 value 1 0 0 0
$ sudo bpftool map update id 114 key 3 0 0 0 value 1 0 0 0
$ sudo bpftool map update id 114 key 4 0 0 0 value 1 0 0 0จนถึงตอนนี้ดีมาก:
$ sudo bpftool map dump id 114
key: 01 00 00 00 value: 01 00 00 00
key: 02 00 00 00 value: 01 00 00 00
key: 04 00 00 00 value: 01 00 00 00
key: 03 00 00 00 value: 01 00 00 00
Found 4 elementsลองเพิ่มอีกอัน:
$ sudo bpftool map update id 114 key 5 0 0 0 value 1 0 0 0
Error: update failed: Argument list too longอย่างที่คาดไว้ เราล้มเหลว ลองดูข้อผิดพลาดโดยละเอียดเพิ่มเติม:
$ sudo strace -e bpf bpftool map update id 114 key 5 0 0 0 value 1 0 0 0
bpf(BPF_MAP_GET_FD_BY_ID, {map_id=114, next_id=0, open_flags=0}, 120) = 3
bpf(BPF_OBJ_GET_INFO_BY_FD, {info={bpf_fd=3, info_len=80, info=0x7ffe6c626da0}}, 120) = 0
bpf(BPF_MAP_UPDATE_ELEM, {map_fd=3, key=0x56049ded5260, value=0x56049ded5280, flags=BPF_ANY}, 120) = -1 E2BIG (Argument list too long)
Error: update failed: Argument list too long
+++ exited with 255 +++ทุกอย่างเป็นไปตามที่คาดไว้ คำสั่ง BPF_MAP_UPDATE_ELEM พยายามสร้างคีย์ใหม่ที่ห้า แต่ขัดข้อง E2BIG.
ดังนั้นเราจึงสามารถสร้างและโหลดโปรแกรม BPF ตลอดจนสร้างและจัดการแผนที่จากพื้นที่ผู้ใช้ ตอนนี้มันเป็นเรื่องสมเหตุสมผลที่จะดูว่าเราจะใช้แผนที่จากโปรแกรม BPF ได้อย่างไร เราสามารถพูดคุยเกี่ยวกับเรื่องนี้ในภาษาของโปรแกรมที่อ่านยากในรหัสแมโครของเครื่อง แต่ในความเป็นจริง ถึงเวลาแล้วที่จะแสดงวิธีการเขียนและบำรุงรักษาโปรแกรม BPF จริง ๆ - โดยใช้ libbpf.
(สำหรับผู้อ่านที่ไม่พอใจกับการขาดตัวอย่างระดับต่ำ: เราจะวิเคราะห์ในรายละเอียดโปรแกรมที่ใช้แผนที่และฟังก์ชันตัวช่วยที่สร้างขึ้นโดยใช้ libbpf และบอกคุณว่าเกิดอะไรขึ้นในระดับการสอน สำหรับผู้อ่านที่ไม่พอใจ เป็นอย่างมากเราเพิ่ม ในที่ที่เหมาะสมในบทความ)
การเขียนโปรแกรม BPF โดยใช้ libbpf
การเขียนโปรแกรม BPF โดยใช้รหัสเครื่องนั้นน่าสนใจในตอนแรกเท่านั้น จากนั้นความเต็มอิ่มก็เข้ามา ณ จุดนี้คุณต้องหันมาสนใจ llvmซึ่งมีแบ็กเอนด์สำหรับสร้างโค้ดสำหรับสถาปัตยกรรม BPF รวมถึงไลบรารี libbpfซึ่งช่วยให้คุณสามารถเขียนฝั่งผู้ใช้ของแอปพลิเคชัน BPF และโหลดโค้ดของโปรแกรม BPF ที่สร้างขึ้นโดยใช้ llvm/clang.
ดังที่เราจะเห็นในบทความนี้และบทความต่อๆ ไป libbpf ทำงานได้ค่อนข้างมากหากไม่มีมัน (หรือเครื่องมือที่คล้ายกัน - iproute2, libbcc, libbpf-goฯลฯ) เป็นไปไม่ได้ที่จะมีชีวิตอยู่ หนึ่งในคุณสมบัตินักฆ่าของโครงการ libbpf คือ BPF CO-RE (คอมไพล์ครั้งเดียว รันทุกที่) - โปรเจ็กต์ที่ให้คุณเขียนโปรแกรม BPF ที่พกพาจากเคอร์เนลหนึ่งไปยังอีกเคอร์เนลได้ ด้วยความสามารถในการรันบน API ต่างๆ (เช่น เมื่อโครงสร้างเคอร์เนลเปลี่ยนจากเวอร์ชัน เป็นเวอร์ชั่น) เพื่อให้สามารถทำงานกับ CO-RE ได้ เคอร์เนลของคุณจะต้องได้รับการคอมไพล์ด้วยการสนับสนุน BTF (เราจะอธิบายวิธีการดำเนินการในส่วนนี้ . มันง่ายมากที่จะตรวจสอบว่าเคอร์เนลของคุณสร้างด้วย BTF หรือไม่ - โดยไฟล์ต่อไปนี้:
$ ls -lh /sys/kernel/btf/vmlinux
-r--r--r-- 1 root root 2.6M Jul 29 15:30 /sys/kernel/btf/vmlinuxไฟล์นี้มีข้อมูลเกี่ยวกับประเภทข้อมูลทั้งหมดที่ใช้ในเคอร์เนลและใช้ในตัวอย่างทั้งหมดของเราโดยใช้ libbpf. เราจะพูดถึงรายละเอียดเกี่ยวกับ CO-RE ในบทความหน้า แต่ในบทความนี้ เพียงแค่สร้างเคอร์เนลด้วยตัวคุณเอง CONFIG_DEBUG_INFO_BTF.
ห้องสมุด libbpf อยู่ในไดเรกทอรีโดยตรง tools/lib/bpf เคอร์เนลและการพัฒนาจะดำเนินการผ่านรายชื่อผู้รับจดหมาย bpf@vger.kernel.org. อย่างไรก็ตาม สำหรับความต้องการของแอปพลิเคชันที่อยู่นอกเคอร์เนล ที่เก็บแยกต่างหากจะได้รับการดูแล ซึ่งไลบรารีหลักถูกมิเรอร์สำหรับการเข้าถึงการอ่านมากหรือน้อยตามที่เป็นอยู่
ในส่วนนี้ เราจะดูว่าคุณสามารถสร้างโครงการโดยใช้ libbpf, เขียนโปรแกรมทดสอบบางส่วน (ไม่มากก็น้อย) และวิเคราะห์โดยละเอียดว่ามันทำงานอย่างไร สิ่งนี้จะทำให้เราอธิบายได้ง่ายขึ้นในส่วนต่อไปนี้ว่าโปรแกรม BPF โต้ตอบกับแผนที่ โปรแกรมช่วยเคอร์เนล BTF และอื่นๆ อย่างไร
โดยทั่วไปแล้วโครงการจะใช้ libbpf เพิ่มที่เก็บ github เป็นโมดูลย่อย git เราจะทำเช่นกัน:
$ mkdir /tmp/libbpf-example
$ cd /tmp/libbpf-example/
$ git init-db
Initialized empty Git repository in /tmp/libbpf-example/.git/
$ git submodule add https://github.com/libbpf/libbpf.git
Cloning into '/tmp/libbpf-example/libbpf'...
remote: Enumerating objects: 200, done.
remote: Counting objects: 100% (200/200), done.
remote: Compressing objects: 100% (103/103), done.
remote: Total 3354 (delta 101), reused 118 (delta 79), pack-reused 3154
Receiving objects: 100% (3354/3354), 2.05 MiB | 10.22 MiB/s, done.
Resolving deltas: 100% (2176/2176), done.กำลังจะ libbpf ง่ายมาก:
$ cd libbpf/src
$ mkdir build
$ OBJDIR=build DESTDIR=root make -s install
$ find root
root
root/usr
root/usr/include
root/usr/include/bpf
root/usr/include/bpf/bpf_tracing.h
root/usr/include/bpf/xsk.h
root/usr/include/bpf/libbpf_common.h
root/usr/include/bpf/bpf_endian.h
root/usr/include/bpf/bpf_helpers.h
root/usr/include/bpf/btf.h
root/usr/include/bpf/bpf_helper_defs.h
root/usr/include/bpf/bpf.h
root/usr/include/bpf/libbpf_util.h
root/usr/include/bpf/libbpf.h
root/usr/include/bpf/bpf_core_read.h
root/usr/lib64
root/usr/lib64/libbpf.so.0.1.0
root/usr/lib64/libbpf.so.0
root/usr/lib64/libbpf.a
root/usr/lib64/libbpf.so
root/usr/lib64/pkgconfig
root/usr/lib64/pkgconfig/libbpf.pcแผนต่อไปของเราในส่วนนี้มีดังนี้: เราจะเขียนโปรแกรม BPF เช่น BPF_PROG_TYPE_XDPเหมือนกับในตัวอย่างที่แล้ว แต่ใน C ให้คอมไพล์ด้วย clangและเขียนโปรแกรมตัวช่วยที่จะโหลดลงในเคอร์เนล ในส่วนต่อไปนี้ เราจะขยายขีดความสามารถของทั้งโปรแกรม BPF และโปรแกรมผู้ช่วย
ตัวอย่าง: สร้างแอปพลิเคชันที่สมบูรณ์ด้วย libbpf
ก่อนอื่นเราใช้ไฟล์ /sys/kernel/btf/vmlinuxที่กล่าวถึงข้างต้น และสร้างสิ่งที่เทียบเท่าในรูปแบบของไฟล์ส่วนหัว:
$ bpftool btf dump file /sys/kernel/btf/vmlinux format c > vmlinux.hไฟล์นี้จะจัดเก็บโครงสร้างข้อมูลทั้งหมดที่มีอยู่ในเคอร์เนลของเรา ตัวอย่างเช่น นี่คือวิธีการกำหนดส่วนหัว IPv4 ในเคอร์เนล:
$ grep -A 12 'struct iphdr {' vmlinux.h
struct iphdr {
__u8 ihl: 4;
__u8 version: 4;
__u8 tos;
__be16 tot_len;
__be16 id;
__be16 frag_off;
__u8 ttl;
__u8 protocol;
__sum16 check;
__be32 saddr;
__be32 daddr;
};ตอนนี้เราจะเขียนโปรแกรม BPF ของเราในภาษา C:
$ cat xdp-simple.bpf.c
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
SEC("xdp/simple")
int simple(void *ctx)
{
return XDP_PASS;
}
char LICENSE[] SEC("license") = "GPL";แม้ว่าโปรแกรมของเราจะเรียบง่ายมาก แต่เราก็ยังต้องใส่ใจในรายละเอียดมากมาย อันดับแรก ไฟล์ส่วนหัวแรกที่เรารวมไว้คือ vmlinux.hซึ่งเราเพิ่งสร้างขึ้นโดยใช้ bpftool btf dump - ตอนนี้เราไม่จำเป็นต้องติดตั้งแพ็คเกจส่วนหัวของเคอร์เนลเพื่อค้นหาว่าโครงสร้างเคอร์เนลเป็นอย่างไร ไฟล์ส่วนหัวต่อไปนี้มาหาเราจากห้องสมุด libbpf. ตอนนี้เราต้องการเพียงเพื่อกำหนดมาโคร SECซึ่งส่งอักขระไปยังส่วนที่เหมาะสมของไฟล์อ็อบเจ็กต์ ELF โปรแกรมของเรามีอยู่ในส่วน xdp/simpleโดยที่ก่อนเครื่องหมายทับ เรากำหนดประเภทโปรแกรม BPF ซึ่งเป็นแบบแผนที่ใช้ใน libbpfตามชื่อส่วนจะแทนที่ประเภทที่ถูกต้องเมื่อเริ่มต้น bpf(2). โปรแกรม BPF เปิดอยู่ C - ง่ายมากและประกอบด้วยหนึ่งบรรทัด return XDP_PASS. ในที่สุดก็มีภาคแยก "license" มีชื่อของใบอนุญาต
เราสามารถคอมไพล์โปรแกรมของเราด้วย llvm/clang เวอร์ชัน >= 10.0.0 หรือดีกว่า (ดูหัวข้อ ):
$ clang --version
clang version 11.0.0 (https://github.com/llvm/llvm-project.git afc287e0abec710398465ee1f86237513f2b5091)
...
$ clang -O2 -g -c -target bpf -I libbpf/src/root/usr/include xdp-simple.bpf.c -o xdp-simple.bpf.oท่ามกลางคุณสมบัติที่น่าสนใจ: เราระบุสถาปัตยกรรมเป้าหมาย -target bpf และเส้นทางไปยังส่วนหัว libbpfที่เราเพิ่งติดตั้งไป นอกจากนี้อย่าลืมเกี่ยวกับ -O2หากไม่มีตัวเลือกนี้ คุณอาจต้องพบกับความประหลาดใจในภายหลัง ลองดูโค้ดของเรา เราเขียนโปรแกรมตามที่เราต้องการได้หรือไม่
$ llvm-objdump --section=xdp/simple --no-show-raw-insn -D xdp-simple.bpf.o
xdp-simple.bpf.o: file format elf64-bpf
Disassembly of section xdp/simple:
0000000000000000 <simple>:
0: r0 = 2
1: exitใช่ มันได้ผล! ตอนนี้เรามีไฟล์ไบนารี่พร้อมโปรแกรม และเราต้องการสร้างแอปพลิเคชันที่จะโหลดลงในเคอร์เนล เพื่อจุดประสงค์นี้ห้องสมุด libbpf เสนอทางเลือกสองทางแก่เรา - ใช้ API ระดับล่างหรือ API ระดับสูงกว่า เราจะไปทางที่สอง เพราะเราต้องการเรียนรู้วิธีเขียน ดาวน์โหลด และเชื่อมต่อโปรแกรม BPF โดยใช้ความพยายามน้อยที่สุดในการศึกษาครั้งต่อไป
ขั้นแรก เราต้องสร้าง "โครงร่าง" ของโปรแกรมของเราจากไบนารีโดยใช้ยูทิลิตี้เดียวกัน bpftool - มีดสวิสแห่งโลก BPF (ซึ่งสามารถนำมาใช้ตามตัวอักษรได้เนื่องจาก Daniel Borkman - หนึ่งในผู้สร้างและผู้ดูแล BPF - เป็นชาวสวิส):
$ bpftool gen skeleton xdp-simple.bpf.o > xdp-simple.skel.hในไฟล์ xdp-simple.skel.h มีรหัสไบนารี่ของโปรแกรมและฟังก์ชั่นสำหรับจัดการ - โหลด, แนบ, ลบอ็อบเจ็กต์ของเรา ในกรณีง่าย ๆ ของเรา สิ่งนี้ดูเหมือนเกินกำลัง แต่ก็ใช้งานได้ในกรณีที่ไฟล์อ็อบเจ็กต์มีโปรแกรมและแผนที่ BPF จำนวนมาก และในการโหลด ELF ยักษ์นี้ เราเพียงแค่ต้องสร้างโครงกระดูกและเรียกใช้ฟังก์ชันหนึ่งหรือสองฟังก์ชันจากแอปพลิเคชันแบบกำหนดเองที่เรา กำลังเขียน เรามาต่อกันดีกว่า
ตามความเป็นจริงแล้ว โปรแกรมตัวโหลดของเรานั้นไม่สำคัญเลย:
#include <err.h>
#include <unistd.h>
#include "xdp-simple.skel.h"
int main(int argc, char **argv)
{
struct xdp_simple_bpf *obj;
obj = xdp_simple_bpf__open_and_load();
if (!obj)
err(1, "failed to open and/or load BPF objectn");
pause();
xdp_simple_bpf__destroy(obj);
}ที่นี่ struct xdp_simple_bpf กำหนดไว้ในไฟล์ xdp-simple.skel.h และอธิบายไฟล์วัตถุของเรา:
struct xdp_simple_bpf {
struct bpf_object_skeleton *skeleton;
struct bpf_object *obj;
struct {
struct bpf_program *simple;
} progs;
struct {
struct bpf_link *simple;
} links;
};เราสามารถเห็นร่องรอยของ API ระดับต่ำได้ที่นี่: โครงสร้าง struct bpf_program *simple и struct bpf_link *simple. โครงสร้างแรกอธิบายโปรแกรมของเราโดยเฉพาะ ซึ่งเขียนไว้ในส่วนนี้ xdp/simpleและส่วนที่สองอธิบายวิธีที่โปรแกรมเชื่อมต่อกับแหล่งเหตุการณ์
ฟังก์ชัน xdp_simple_bpf__open_and_loadเปิดวัตถุ ELF แยกวิเคราะห์ สร้างโครงสร้างและโครงสร้างย่อยทั้งหมด (นอกเหนือจากโปรแกรมแล้ว ELF ยังมีส่วนอื่นๆ เช่น ข้อมูล ข้อมูลแบบอ่านอย่างเดียว ข้อมูลการดีบัก ใบอนุญาต ฯลฯ) จากนั้นโหลดลงในเคอร์เนลผ่านการเรียกระบบ bpfซึ่งเราสามารถตรวจสอบได้ด้วยการคอมไพล์และรันโปรแกรม:
$ clang -O2 -I ./libbpf/src/root/usr/include/ xdp-simple.c -o xdp-simple ./libbpf/src/root/usr/lib64/libbpf.a -lelf -lz
$ sudo strace -e bpf ./xdp-simple
...
bpf(BPF_BTF_LOAD, 0x7ffdb8fd9670, 120) = 3
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_XDP, insn_cnt=2, insns=0xdfd580, license="GPL", log_level=0, log_size=0, log_buf=NULL, kern_version=KERNEL_VERSION(5, 8, 0), prog_flags=0, prog_name="simple", prog_ifindex=0, expected_attach_type=0x25 /* BPF_??? */, ...}, 120) = 4มาดูโปรแกรมของเรากับ bpftool. มาหารหัสของมัน:
# bpftool p | grep -A4 simple
463: xdp name simple tag 3b185187f1855c4c gpl
loaded_at 2020-08-01T01:59:49+0000 uid 0
xlated 16B jited 40B memlock 4096B
btf_id 185
pids xdp-simple(16498)และ dump (เราใช้รูปแบบคำสั่งที่สั้นลง bpftool prog dump xlated):
# bpftool p d x id 463
int simple(void *ctx):
; return XDP_PASS;
0: (b7) r0 = 2
1: (95) exitสิ่งใหม่ ๆ! โปรแกรมจะพิมพ์ชิ้นส่วนของไฟล์ต้นฉบับ C ของเรา ซึ่งจัดทำโดยห้องสมุด libbpfซึ่งพบส่วนการดีบักในไบนารี รวบรวมเป็นวัตถุ BTF โหลดลงในเคอร์เนลโดยใช้ BPF_BTF_LOADจากนั้นระบุตัวอธิบายไฟล์ที่เป็นผลลัพธ์เมื่อโหลดโปรแกรมด้วยคำสั่ง BPG_PROG_LOAD.
ตัวช่วยเคอร์เนล
โปรแกรม BPF สามารถเรียกใช้ฟังก์ชัน "ภายนอก" - ตัวช่วยเคอร์เนล ฟังก์ชันตัวช่วยเหล่านี้ช่วยให้โปรแกรม BPF เข้าถึงโครงสร้างเคอร์เนล จัดการแผนที่ และยังสื่อสารกับ "โลกแห่งความเป็นจริง" - สร้างเหตุการณ์ที่สมบูรณ์แบบ ควบคุมฮาร์ดแวร์ (เช่น แพ็กเก็ตเปลี่ยนเส้นทาง) ฯลฯ
ตัวอย่าง: bpf_get_smp_processor_id
ภายในกรอบของกระบวนทัศน์ “การเรียนรู้ตามตัวอย่าง” ลองพิจารณาฟังก์ชันตัวช่วยอย่างหนึ่ง bpf_get_smp_processor_id(), ในไฟล์ kernel/bpf/helpers.c. โดยจะส่งคืนหมายเลขโปรเซสเซอร์ที่โปรแกรม BPF ที่เรียกว่ากำลังทำงานอยู่ แต่เราไม่สนใจความหมายของมันเท่ากับความจริงที่ว่าการใช้งานนั้นใช้เวลาเพียงบรรทัดเดียว:
BPF_CALL_0(bpf_get_smp_processor_id)
{
return smp_processor_id();
}คำจำกัดความของฟังก์ชันตัวช่วย BPF มีลักษณะคล้ายกับคำจำกัดความของการเรียกใช้ระบบ Linuxตัวอย่างเช่น ในที่นี้เราได้กำหนดฟังก์ชันที่ไม่มีอาร์กิวเมนต์ (ฟังก์ชันที่รับอาร์กิวเมนต์สามตัวจะถูกกำหนดโดยใช้มาโคร) BPF_CALL_3. จำนวนอาร์กิวเมนต์สูงสุดคือห้า) อย่างไรก็ตาม นี่เป็นเพียงส่วนแรกของคำจำกัดความ ส่วนที่สองคือการกำหนดโครงสร้างประเภท struct bpf_func_protoซึ่งมีคำอธิบายของฟังก์ชันตัวช่วย ซึ่งผู้ตรวจสอบสามารถเข้าใจได้:
const struct bpf_func_proto bpf_get_smp_processor_id_proto = {
.func = bpf_get_smp_processor_id,
.gpl_only = false,
.ret_type = RET_INTEGER,
};การลงทะเบียนฟังก์ชั่นตัวช่วย
เพื่อให้โปรแกรม BPF บางประเภทใช้ฟังก์ชันนี้ได้ จะต้องลงทะเบียนโปรแกรมนั้น เช่น สำหรับประเภท BPF_PROG_TYPE_XDP ฟังก์ชั่นถูกกำหนดไว้ในเคอร์เนล xdp_func_protoซึ่งกำหนด ID ฟังก์ชันตัวช่วยกำหนดว่า XDP รองรับฟังก์ชันนี้หรือไม่ หน้าที่ของเราคือ :
static const struct bpf_func_proto *
xdp_func_proto(enum bpf_func_id func_id, const struct bpf_prog *prog)
{
switch (func_id) {
...
case BPF_FUNC_get_smp_processor_id:
return &bpf_get_smp_processor_id_proto;
...
}
}ประเภทโปรแกรม BPF ใหม่จะถูก "กำหนด" ในไฟล์ ด้วยมาโคร BPF_PROG_TYPE. กำหนดในเครื่องหมายคำพูดเนื่องจากเป็นคำจำกัดความเชิงตรรกะ และในภาษา C คำจำกัดความของโครงสร้างคอนกรีตทั้งชุดเกิดขึ้นในที่อื่น โดยเฉพาะในไฟล์ kernel/bpf/verifier.c คำจำกัดความทั้งหมดจากไฟล์ bpf_types.h ใช้เพื่อสร้างอาร์เรย์ของโครงสร้าง bpf_verifier_ops[]:
static const struct bpf_verifier_ops *const bpf_verifier_ops[] = {
#define BPF_PROG_TYPE(_id, _name, prog_ctx_type, kern_ctx_type)
[_id] = & _name ## _verifier_ops,
#include <linux/bpf_types.h>
#undef BPF_PROG_TYPE
};นั่นคือสำหรับโปรแกรม BPF แต่ละประเภท จะมีการกำหนดตัวชี้ไปยังโครงสร้างข้อมูลของประเภทนั้น struct bpf_verifier_opsซึ่งเริ่มต้นด้วยค่า _name ## _verifier_ops, เช่น., xdp_verifier_ops สำหรับ xdp. โครงสร้าง xdp_verifier_ops ในไฟล์ net/core/filter.c ดังต่อไปนี้:
const struct bpf_verifier_ops xdp_verifier_ops = {
.get_func_proto = xdp_func_proto,
.is_valid_access = xdp_is_valid_access,
.convert_ctx_access = xdp_convert_ctx_access,
.gen_prologue = bpf_noop_prologue,
};ที่นี่เราเห็นฟังก์ชันที่เราคุ้นเคย xdp_func_protoซึ่งจะเรียกใช้ตัวตรวจสอบทุกครั้งที่เผชิญกับความท้าทาย บางส่วน ฟังก์ชั่นภายในโปรแกรม BPF โปรดดู .
มาดูกันว่าโปรแกรม BPF เชิงสมมุติใช้ฟังก์ชันนี้อย่างไร bpf_get_smp_processor_id. ในการทำเช่นนี้ เราเขียนโปรแกรมใหม่จากส่วนก่อนหน้าดังนี้:
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
SEC("xdp/simple")
int simple(void *ctx)
{
if (bpf_get_smp_processor_id() != 0)
return XDP_DROP;
return XDP_PASS;
}
char LICENSE[] SEC("license") = "GPL";สัญญลักษณ์ bpf_get_smp_processor_id в <bpf/bpf_helper_defs.h> ห้องสมุด libbpf ในขณะที่
static u32 (*bpf_get_smp_processor_id)(void) = (void *) 8;นั่นคือ bpf_get_smp_processor_id เป็นตัวชี้ฟังก์ชันที่มีค่าเป็น 8 โดยที่ 8 คือค่า BPF_FUNC_get_smp_processor_id ชนิด enum bpf_fun_idซึ่งกำหนดไว้สำหรับเราในไฟล์ vmlinux.h (ไฟล์ bpf_helper_defs.h สร้างโดยสคริปต์ในเคอร์เนล ดังนั้นตัวเลข "วิเศษ" จึงใช้ได้) ฟังก์ชันนี้ไม่ใช้อาร์กิวเมนต์และส่งคืนค่าประเภท __u32. เมื่อเราเรียกใช้ในโปรแกรมของเรา clang สร้างคำสั่ง BPF_CALL "ชนิดที่ถูกต้อง". ลองรวบรวมโปรแกรมและดูที่ส่วน xdp/simple:
$ clang -O2 -g -c -target bpf -I libbpf/src/root/usr/include xdp-simple.bpf.c -o xdp-simple.bpf.o
$ llvm-objdump -D --section=xdp/simple xdp-simple.bpf.o
xdp-simple.bpf.o: file format elf64-bpf
Disassembly of section xdp/simple:
0000000000000000 <simple>:
0: 85 00 00 00 08 00 00 00 call 8
1: bf 01 00 00 00 00 00 00 r1 = r0
2: 67 01 00 00 20 00 00 00 r1 <<= 32
3: 77 01 00 00 20 00 00 00 r1 >>= 32
4: b7 00 00 00 02 00 00 00 r0 = 2
5: 15 01 01 00 00 00 00 00 if r1 == 0 goto +1 <LBB0_2>
6: b7 00 00 00 01 00 00 00 r0 = 1
0000000000000038 <LBB0_2>:
7: 95 00 00 00 00 00 00 00 exitในบรรทัดแรกเราจะเห็นคำแนะนำ call, พารามิเตอร์ IMM ซึ่งเท่ากับ 8 และ SRC_REG - ศูนย์ ตามแบบแผน ABI ที่ใช้โดยผู้ตรวจสอบ นี่คือการเรียกใช้ฟังก์ชันตัวช่วยหมายเลขแปด หลังจากเปิดตัว ตรรกะก็ง่ายๆ คืนค่าจากรีจิสเตอร์ r0 คัดลอกไปที่ r1 และในบรรทัด 2,3 จะถูกแปลงเป็นประเภท u32 — 32 บิตบนจะถูกล้าง ในบรรทัด 4,5,6,7 เราส่งคืน 2 (XDP_PASS) หรือ 1 (XDP_DROP) ขึ้นอยู่กับว่าฟังก์ชันตัวช่วยจากบรรทัด 0 ส่งคืนค่าเป็นศูนย์หรือไม่เป็นศูนย์
มาทดสอบกัน: โหลดโปรแกรมและดูผลลัพธ์ bpftool prog dump xlated:
$ bpftool gen skeleton xdp-simple.bpf.o > xdp-simple.skel.h
$ clang -O2 -g -I ./libbpf/src/root/usr/include/ -o xdp-simple xdp-simple.c ./libbpf/src/root/usr/lib64/libbpf.a -lelf -lz
$ sudo ./xdp-simple &
[2] 10914
$ sudo bpftool p | grep simple
523: xdp name simple tag 44c38a10c657e1b0 gpl
pids xdp-simple(10915)
$ sudo bpftool p d x id 523
int simple(void *ctx):
; if (bpf_get_smp_processor_id() != 0)
0: (85) call bpf_get_smp_processor_id#114128
1: (bf) r1 = r0
2: (67) r1 <<= 32
3: (77) r1 >>= 32
4: (b7) r0 = 2
; }
5: (15) if r1 == 0x0 goto pc+1
6: (b7) r0 = 1
7: (95) exitตกลง ผู้ตรวจสอบพบตัวช่วยเคอร์เนลที่ถูกต้อง
ตัวอย่าง: ผ่านการโต้แย้งและในที่สุดก็รันโปรแกรม!
ฟังก์ชันตัวช่วยระดับรันทั้งหมดมีต้นแบบ
u64 fn(u64 r1, u64 r2, u64 r3, u64 r4, u64 r5)พารามิเตอร์ของฟังก์ชันตัวช่วยจะถูกส่งผ่านในรีจิสเตอร์ r1-r5และค่าจะถูกส่งกลับในทะเบียน r0. ไม่มีฟังก์ชันที่รับอาร์กิวเมนต์มากกว่าห้าข้อ และไม่คาดว่าจะเพิ่มการรองรับสำหรับอาร์กิวเมนต์เหล่านี้ในอนาคต
มาดูตัวช่วยเคอร์เนลใหม่และวิธีที่ BPF ส่งผ่านพารามิเตอร์ มาเขียนใหม่กัน xdp-simple.bpf.c ดังนี้ (บรรทัดที่เหลือไม่มีการเปลี่ยนแปลง):
SEC("xdp/simple")
int simple(void *ctx)
{
bpf_printk("running on CPU%un", bpf_get_smp_processor_id());
return XDP_PASS;
}โปรแกรมของเราพิมพ์หมายเลขของ CPU ที่กำลังทำงานอยู่ ลองรวบรวมและดูรหัส:
$ llvm-objdump -D --section=xdp/simple --no-show-raw-insn xdp-simple.bpf.o
0000000000000000 <simple>:
0: r1 = 10
1: *(u16 *)(r10 - 8) = r1
2: r1 = 8441246879787806319 ll
4: *(u64 *)(r10 - 16) = r1
5: r1 = 2334956330918245746 ll
7: *(u64 *)(r10 - 24) = r1
8: call 8
9: r1 = r10
10: r1 += -24
11: r2 = 18
12: r3 = r0
13: call 6
14: r0 = 2
15: exitในบรรทัด 0-7 เราเขียนสตริง running on CPU%unและจากนั้นในบรรทัดที่ 8 เราเรียกใช้สิ่งที่คุ้นเคย bpf_get_smp_processor_id. ในบรรทัดที่ 9-12 เราเตรียมข้อโต้แย้งของผู้ช่วย bpf_printk - ลงทะเบียน r1, r2, r3. ทำไมถึงมีสามคนไม่ใช่สองคน? เพราะ bpf_printk - รอบตัวผู้ช่วยที่แท้จริง bpf_trace_printkซึ่งต้องผ่านขนาดของสตริงรูปแบบ
ตอนนี้เรามาเพิ่มสองสามบรรทัดกัน xdp-simple.cเพื่อให้โปรแกรมของเราเชื่อมต่อกับอินเทอร์เฟซ lo และมันก็เริ่มต้นขึ้นจริงๆ!
$ cat xdp-simple.c
#include <linux/if_link.h>
#include <err.h>
#include <unistd.h>
#include "xdp-simple.skel.h"
int main(int argc, char **argv)
{
__u32 flags = XDP_FLAGS_SKB_MODE;
struct xdp_simple_bpf *obj;
obj = xdp_simple_bpf__open_and_load();
if (!obj)
err(1, "failed to open and/or load BPF objectn");
bpf_set_link_xdp_fd(1, -1, flags);
bpf_set_link_xdp_fd(1, bpf_program__fd(obj->progs.simple), flags);
cleanup:
xdp_simple_bpf__destroy(obj);
}ที่นี่เราใช้ฟังก์ชัน bpf_set_link_xdp_fdซึ่งเชื่อมต่อโปรแกรม BPF ประเภท XDP กับอินเทอร์เฟซเครือข่าย เราได้ฮาร์ดโค้ดหมายเลขอินเทอร์เฟซแล้ว loซึ่งก็คือ 1 เสมอ เราเรียกใช้ฟังก์ชันสองครั้งเพื่อแยกโปรแกรมเก่าออกก่อนหากมีการแนบ โปรดทราบว่าตอนนี้เราไม่จำเป็นต้องโทร pause หรือการวนซ้ำไม่สิ้นสุด: โปรแกรมตัวโหลดของเราจะออก แต่โปรแกรม BPF จะไม่ถูกทำลาย เนื่องจากมีการเชื่อมต่อกับแหล่งเหตุการณ์ หลังจากดาวน์โหลดและเชื่อมต่อสำเร็จ โปรแกรมจะเปิดตัวสำหรับแต่ละแพ็กเก็ตเครือข่ายที่มา lo.
มาดาวน์โหลดโปรแกรมและดูอินเทอร์เฟซกัน lo:
$ sudo ./xdp-simple
$ sudo bpftool p | grep simple
669: xdp name simple tag 4fca62e77ccb43d6 gpl
$ ip l show dev lo
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 xdpgeneric qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
prog/xdp id 669โปรแกรมที่เราดาวน์โหลดมี ID 669 และเราเห็น ID เดียวกันบนอินเทอร์เฟซ lo. เราจะส่งพัสดุสองสามชิ้นไปที่ 127.0.0.1 (ขอ+ตอบกลับ):
$ ping -c1 localhostและตอนนี้ดูที่เนื้อหาของไฟล์เสมือนการดีบัก /sys/kernel/debug/tracing/trace_pipe, ซึ่งใน bpf_printk เขียนข้อความของเขา:
# cat /sys/kernel/debug/tracing/trace_pipe
ping-13937 [000] d.s1 442015.377014: bpf_trace_printk: running on CPU0
ping-13937 [000] d.s1 442015.377027: bpf_trace_printk: running on CPU0พบเห็นพัสดุสองชิ้น lo และประมวลผลบน CPU0 - โปรแกรม BPF ที่ไม่มีความหมายเต็มรูปแบบโปรแกรมแรกของเราใช้งานได้!
เป็นที่น่าสังเกตว่า bpf_printk เขียนไปยังไฟล์ดีบั๊กด้วยเหตุผล: นี่ไม่ใช่ตัวช่วยที่ดีที่สุดสำหรับใช้ในการผลิต แต่เป้าหมายของเราคือการแสดงบางสิ่งที่เรียบง่าย
การเข้าถึงแผนที่จากโปรแกรม BPF
ตัวอย่าง: การใช้แผนที่จากโปรแกรม BPF
ในส่วนก่อนหน้านี้ เราได้เรียนรู้วิธีสร้างและใช้แผนที่จากพื้นที่ผู้ใช้ และตอนนี้เรามาดูส่วนเคอร์เนลกัน มาเริ่มกันตามปกติด้วยตัวอย่าง มาเขียนโปรแกรมของเราใหม่กัน xdp-simple.bpf.c ดังต่อไปนี้:
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
struct {
__uint(type, BPF_MAP_TYPE_ARRAY);
__uint(max_entries, 8);
__type(key, u32);
__type(value, u64);
} woo SEC(".maps");
SEC("xdp/simple")
int simple(void *ctx)
{
u32 key = bpf_get_smp_processor_id();
u32 *val;
val = bpf_map_lookup_elem(&woo, &key);
if (!val)
return XDP_ABORTED;
*val += 1;
return XDP_PASS;
}
char LICENSE[] SEC("license") = "GPL";ในตอนต้นของโปรแกรมเราได้เพิ่มคำจำกัดความของแผนที่ woo: นี่คืออาร์เรย์ 8 องค์ประกอบที่เก็บค่าเช่น u64 (ใน C เราจะกำหนดอาร์เรย์เช่น u64 woo[8]). ในโปรแกรม "xdp/simple" เราได้จำนวนโปรเซสเซอร์ปัจจุบันเป็นตัวแปร key แล้วใช้ฟังก์ชันตัวช่วย bpf_map_lookup_element เราได้รับพอยน์เตอร์ไปยังรายการที่เกี่ยวข้องในอาเรย์ ซึ่งเราเพิ่มขึ้นทีละรายการ แปลเป็นภาษารัสเซีย: เราคำนวณสถิติที่ CPU ประมวลผลแพ็กเก็ตขาเข้า มาลองรันโปรแกรมกัน:
$ clang -O2 -g -c -target bpf -I libbpf/src/root/usr/include xdp-simple.bpf.c -o xdp-simple.bpf.o
$ bpftool gen skeleton xdp-simple.bpf.o > xdp-simple.skel.h
$ clang -O2 -g -I ./libbpf/src/root/usr/include/ -o xdp-simple xdp-simple.c ./libbpf/src/root/usr/lib64/libbpf.a -lelf -lz
$ sudo ./xdp-simpleมาเช็คกันว่าเธอติด lo และส่งแพ็กเก็ตบางส่วน:
$ ip l show dev lo
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 xdpgeneric qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
prog/xdp id 108
$ for s in `seq 234`; do sudo ping -f -c 100 127.0.0.1 >/dev/null 2>&1; doneทีนี้มาดูเนื้อหาของอาร์เรย์:
$ sudo bpftool map dump name woo
[
{ "key": 0, "value": 0 },
{ "key": 1, "value": 400 },
{ "key": 2, "value": 0 },
{ "key": 3, "value": 0 },
{ "key": 4, "value": 0 },
{ "key": 5, "value": 0 },
{ "key": 6, "value": 0 },
{ "key": 7, "value": 46400 }
]กระบวนการเกือบทั้งหมดได้รับการประมวลผลบน CPU7 สิ่งนี้ไม่สำคัญสำหรับเรา สิ่งสำคัญคือโปรแกรมใช้งานได้และเราเข้าใจวิธีเข้าถึงแผนที่จากโปรแกรม BPF โดยใช้ .
ดัชนีลึกลับ
ดังนั้นเราจึงสามารถเข้าถึงแผนที่จากโปรแกรม BPF โดยใช้การโทรเช่น
val = bpf_map_lookup_elem(&woo, &key);ฟังก์ชันตัวช่วยมีลักษณะอย่างไร
void *bpf_map_lookup_elem(struct bpf_map *map, const void *key)แต่เรากำลังผ่านตัวชี้ &woo ไปยังโครงสร้างที่ไม่มีชื่อ struct { ... }...
หากเราดูที่แอสเซมเบลอร์ของโปรแกรมเราจะเห็นว่าค่า &woo ไม่ได้กำหนดไว้จริง (บรรทัดที่ 4):
llvm-objdump -D --section xdp/simple xdp-simple.bpf.o
xdp-simple.bpf.o: file format elf64-bpf
Disassembly of section xdp/simple:
0000000000000000 <simple>:
0: 85 00 00 00 08 00 00 00 call 8
1: 63 0a fc ff 00 00 00 00 *(u32 *)(r10 - 4) = r0
2: bf a2 00 00 00 00 00 00 r2 = r10
3: 07 02 00 00 fc ff ff ff r2 += -4
4: 18 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r1 = 0 ll
6: 85 00 00 00 01 00 00 00 call 1
...และมีอยู่ในการย้าย:
$ llvm-readelf -r xdp-simple.bpf.o | head -4
Relocation section '.relxdp/simple' at offset 0xe18 contains 1 entries:
Offset Info Type Symbol's Value Symbol's Name
0000000000000020 0000002700000001 R_BPF_64_64 0000000000000000 wooแต่ถ้าเราดูโปรแกรมที่โหลดมาแล้ว เราจะเห็นตัวชี้ไปยังแผนที่ที่ถูกต้อง (บรรทัดที่ 4):
$ sudo bpftool prog dump x name simple
int simple(void *ctx):
0: (85) call bpf_get_smp_processor_id#114128
1: (63) *(u32 *)(r10 -4) = r0
2: (bf) r2 = r10
3: (07) r2 += -4
4: (18) r1 = map[id:64]
...ดังนั้นเราจึงสรุปได้ว่าในขณะที่เปิดตัวโปรแกรมโหลดเดอร์ของเรา ลิงก์ไปยัง &woo ถูกแทนที่ด้วยบางสิ่งบางอย่างด้วยห้องสมุด libbpf. ก่อนอื่นเราจะดูที่ผลลัพธ์ strace:
$ sudo strace -e bpf ./xdp-simple
...
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_ARRAY, key_size=4, value_size=8, max_entries=8, map_name="woo", ...}, 120) = 4
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_XDP, prog_name="simple", ...}, 120) = 5เราเห็นว่า libbpf สร้างแผนที่ woo แล้วโหลดโปรแกรมของเรา simple. มาดูวิธีการโหลดโปรแกรมกันดีกว่า:
- เรียก
xdp_simple_bpf__open_and_loadจากไฟล์xdp-simple.skel.h - ซึ่งก่อให้เกิด
xdp_simple_bpf__loadจากไฟล์xdp-simple.skel.h - ซึ่งก่อให้เกิด
bpf_object__load_skeletonจากไฟล์libbpf/src/libbpf.c - ซึ่งก่อให้เกิด
bpf_object__load_xattrของlibbpf/src/libbpf.c
ฟังก์ชั่นสุดท้ายจะโทร bpf_object__create_mapsซึ่งสร้างหรือเปิดแผนที่ที่มีอยู่ เปลี่ยนเป็นไฟล์อธิบาย (นี่คือที่ที่เราเห็น BPF_MAP_CREATE ในเอาต์พุต strace.) ถัดไปเรียกว่าฟังก์ชัน bpf_object__relocate และเธอเป็นคนที่สนใจเราเนื่องจากเราจำสิ่งที่เราเห็นได้ woo ในตารางการย้ายที่อยู่ สำรวจมันในที่สุดเราก็เข้าสู่ฟังก์ชั่น bpf_program__relocateซึ่งและ :
case RELO_LD64:
insn[0].src_reg = BPF_PSEUDO_MAP_FD;
insn[0].imm = obj->maps[relo->map_idx].fd;
break;ดังนั้นเราจึงปฏิบัติตามคำแนะนำของเรา
18 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r1 = 0 llและแทนที่รีจิสเตอร์ต้นทางด้วย BPF_PSEUDO_MAP_FDและ IMM แรกไปยังตัวอธิบายไฟล์ของแผนที่ของเรา และถ้ามีค่าเท่ากัน ตัวอย่างเช่น 0xdeadbeefดังนั้นเราจึงได้รับคำสั่ง
18 11 00 00 ef eb ad de 00 00 00 00 00 00 00 00 r1 = 0 llนี่คือวิธีการส่งข้อมูลแผนที่ไปยังโปรแกรม BPF ที่โหลดโดยเฉพาะ ในกรณีนี้ สามารถสร้างแผนที่โดยใช้ BPF_MAP_CREATE, และเปิดโดย ID โดยใช้ BPF_MAP_GET_FD_BY_ID.
รวมเมื่อใช้ libbpf อัลกอริธึมมีดังนี้:
- ในเวลารวบรวม สำหรับการอ้างอิงถึงแผนที่ รายการจะถูกสร้างขึ้นในตารางการย้ายตำแหน่ง
libbpfเปิดวัตถุ ELF ค้นหาแผนที่ที่ใช้ทั้งหมด และสร้างตัวอธิบายไฟล์สำหรับพวกเขา- ตัวอธิบายไฟล์ถูกโหลดลงในเคอร์เนลโดยเป็นส่วนหนึ่งของคำสั่ง
LD64
อย่างที่คุณสามารถจินตนาการได้ ยังมีอะไรอีกมากมายที่จะเกิดขึ้นและเราจะต้องพิจารณาถึงแก่นแท้ โชคดีที่เรามีเบาะแส - เราได้เขียนความหมายลงไปแล้ว BPF_PSEUDO_MAP_FD ในการลงทะเบียนแหล่งที่มาและเราสามารถฝังมันได้ซึ่งจะนำเราไปสู่ความศักดิ์สิทธิ์ของนักบุญทั้งหมด - kernel/bpf/verifier.cโดยที่ฟังก์ชันที่มีชื่อคุณลักษณะจะแทนที่ตัวอธิบายไฟล์ด้วยแอดเดรสของโครงสร้างประเภท struct bpf_map:
static int replace_map_fd_with_map_ptr(struct bpf_verifier_env *env) {
...
f = fdget(insn[0].imm);
map = __bpf_map_get(f);
if (insn->src_reg == BPF_PSEUDO_MAP_FD) {
addr = (unsigned long)map;
}
insn[0].imm = (u32)addr;
insn[1].imm = addr >> 32;(สามารถดูรหัสเต็มได้ ). เพื่อให้อัลกอริทึมของเราสมบูรณ์:
- ในระหว่างการโหลดโปรแกรม ผู้ตรวจสอบจะตรวจสอบการใช้แผนที่ที่ถูกต้องและกำหนดที่อยู่ของโครงสร้างที่เกี่ยวข้อง
struct bpf_map
เมื่อโหลดไบนารี ELF ด้วย libbpf มีอีกมากที่เกิดขึ้น แต่เราจะพูดถึงในบทความอื่น ๆ
กำลังโหลดโปรแกรมและแผนที่โดยไม่ใช้ libbpf
ตามที่สัญญาไว้ นี่คือตัวอย่างสำหรับผู้อ่านที่ต้องการทราบวิธีสร้างและโหลดโปรแกรมที่ใช้แผนที่โดยไม่มีความช่วยเหลือ libbpf. สิ่งนี้มีประโยชน์เมื่อคุณทำงานในสภาพแวดล้อมที่คุณไม่สามารถสร้างการพึ่งพา หรือบันทึกทุกบิต หรือเขียนโปรแกรมเช่น ซึ่งสร้างรหัสไบนารี BPF ได้ทันที
เพื่อให้ง่ายต่อการปฏิบัติตามตรรกะ เราจะเขียนตัวอย่างของเราใหม่เพื่อจุดประสงค์เหล่านี้ xdp-simple. คุณสามารถค้นหาโค้ดที่สมบูรณ์และเพิ่มเติมเล็กน้อยของโปรแกรมที่พิจารณาในตัวอย่างนี้ได้ .
ตรรกะของแอปพลิเคชันของเรามีดังนี้:
- สร้างแผนที่ประเภท
BPF_MAP_TYPE_ARRAYโดยใช้คำสั่งBPF_MAP_CREATE, - สร้างโปรแกรมที่ใช้แผนที่นี้
- เชื่อมต่อโปรแกรมเข้ากับอินเทอร์เฟซ
lo,
ซึ่งแปลว่ามนุษย์
int main(void)
{
int map_fd, prog_fd;
map_fd = map_create();
if (map_fd < 0)
err(1, "bpf: BPF_MAP_CREATE");
prog_fd = prog_load(map_fd);
if (prog_fd < 0)
err(1, "bpf: BPF_PROG_LOAD");
xdp_attach(1, prog_fd);
}ที่นี่ map_create สร้างแผนที่ในลักษณะเดียวกับที่เราทำในตัวอย่างแรกเกี่ยวกับการเรียกของระบบ bpf - “เคอร์เนล โปรดสร้างแผนที่ใหม่ให้ฉันในรูปแบบของอาร์เรย์ 8 องค์ประกอบเช่น __u64 และคืน file descriptor ให้ฉัน":
static int map_create()
{
union bpf_attr attr;
memset(&attr, 0, sizeof(attr));
attr.map_type = BPF_MAP_TYPE_ARRAY,
attr.key_size = sizeof(__u32),
attr.value_size = sizeof(__u64),
attr.max_entries = 8,
strncpy(attr.map_name, "woo", sizeof(attr.map_name));
return syscall(__NR_bpf, BPF_MAP_CREATE, &attr, sizeof(attr));
}โปรแกรมยังโหลดง่าย:
static int prog_load(int map_fd)
{
union bpf_attr attr;
struct bpf_insn insns[] = {
...
};
memset(&attr, 0, sizeof(attr));
attr.prog_type = BPF_PROG_TYPE_XDP;
attr.insns = ptr_to_u64(insns);
attr.insn_cnt = sizeof(insns)/sizeof(insns[0]);
attr.license = ptr_to_u64("GPL");
strncpy(attr.prog_name, "woo", sizeof(attr.prog_name));
return syscall(__NR_bpf, BPF_PROG_LOAD, &attr, sizeof(attr));
}ส่วนที่ยุ่งยาก prog_load คือคำจำกัดความของโปรแกรม BPF ของเราในฐานะอาร์เรย์ของโครงสร้าง struct bpf_insn insns[]. แต่เนื่องจากเราใช้โปรแกรมที่เรามีในภาษาซี เราจึงสามารถโกงได้เล็กน้อย:
$ llvm-objdump -D --section xdp/simple xdp-simple.bpf.o
0000000000000000 <simple>:
0: 85 00 00 00 08 00 00 00 call 8
1: 63 0a fc ff 00 00 00 00 *(u32 *)(r10 - 4) = r0
2: bf a2 00 00 00 00 00 00 r2 = r10
3: 07 02 00 00 fc ff ff ff r2 += -4
4: 18 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r1 = 0 ll
6: 85 00 00 00 01 00 00 00 call 1
7: b7 01 00 00 00 00 00 00 r1 = 0
8: 15 00 04 00 00 00 00 00 if r0 == 0 goto +4 <LBB0_2>
9: 61 01 00 00 00 00 00 00 r1 = *(u32 *)(r0 + 0)
10: 07 01 00 00 01 00 00 00 r1 += 1
11: 63 10 00 00 00 00 00 00 *(u32 *)(r0 + 0) = r1
12: b7 01 00 00 02 00 00 00 r1 = 2
0000000000000068 <LBB0_2>:
13: bf 10 00 00 00 00 00 00 r0 = r1
14: 95 00 00 00 00 00 00 00 exitโดยรวมแล้วเราต้องเขียนคำสั่งทั้งหมด 14 คำสั่งในรูปแบบของโครงสร้างเช่น struct bpf_insn (สภา: นำการถ่ายโอนข้อมูลจากด้านบน อ่านส่วนคำแนะนำอีกครั้ง เปิด и และพยายามกำหนด struct bpf_insn insns[] ด้วยตัวเอง):
struct bpf_insn insns[] = {
/* 85 00 00 00 08 00 00 00 call 8 */
{
.code = BPF_JMP | BPF_CALL,
.imm = 8,
},
/* 63 0a fc ff 00 00 00 00 *(u32 *)(r10 - 4) = r0 */
{
.code = BPF_MEM | BPF_STX,
.off = -4,
.src_reg = BPF_REG_0,
.dst_reg = BPF_REG_10,
},
/* bf a2 00 00 00 00 00 00 r2 = r10 */
{
.code = BPF_ALU64 | BPF_MOV | BPF_X,
.src_reg = BPF_REG_10,
.dst_reg = BPF_REG_2,
},
/* 07 02 00 00 fc ff ff ff r2 += -4 */
{
.code = BPF_ALU64 | BPF_ADD | BPF_K,
.dst_reg = BPF_REG_2,
.imm = -4,
},
/* 18 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r1 = 0 ll */
{
.code = BPF_LD | BPF_DW | BPF_IMM,
.src_reg = BPF_PSEUDO_MAP_FD,
.dst_reg = BPF_REG_1,
.imm = map_fd,
},
{ }, /* placeholder */
/* 85 00 00 00 01 00 00 00 call 1 */
{
.code = BPF_JMP | BPF_CALL,
.imm = 1,
},
/* b7 01 00 00 00 00 00 00 r1 = 0 */
{
.code = BPF_ALU64 | BPF_MOV | BPF_K,
.dst_reg = BPF_REG_1,
.imm = 0,
},
/* 15 00 04 00 00 00 00 00 if r0 == 0 goto +4 <LBB0_2> */
{
.code = BPF_JMP | BPF_JEQ | BPF_K,
.off = 4,
.src_reg = BPF_REG_0,
.imm = 0,
},
/* 61 01 00 00 00 00 00 00 r1 = *(u32 *)(r0 + 0) */
{
.code = BPF_MEM | BPF_LDX,
.off = 0,
.src_reg = BPF_REG_0,
.dst_reg = BPF_REG_1,
},
/* 07 01 00 00 01 00 00 00 r1 += 1 */
{
.code = BPF_ALU64 | BPF_ADD | BPF_K,
.dst_reg = BPF_REG_1,
.imm = 1,
},
/* 63 10 00 00 00 00 00 00 *(u32 *)(r0 + 0) = r1 */
{
.code = BPF_MEM | BPF_STX,
.src_reg = BPF_REG_1,
.dst_reg = BPF_REG_0,
},
/* b7 01 00 00 02 00 00 00 r1 = 2 */
{
.code = BPF_ALU64 | BPF_MOV | BPF_K,
.dst_reg = BPF_REG_1,
.imm = 2,
},
/* <LBB0_2>: bf 10 00 00 00 00 00 00 r0 = r1 */
{
.code = BPF_ALU64 | BPF_MOV | BPF_X,
.src_reg = BPF_REG_1,
.dst_reg = BPF_REG_0,
},
/* 95 00 00 00 00 00 00 00 exit */
{
.code = BPF_JMP | BPF_EXIT
},
};แบบฝึกหัดสำหรับผู้ที่ไม่ได้เขียนเอง - ค้นหา map_fd.
มีอีกหนึ่งส่วนที่ไม่เปิดเผยในโปรแกรมของเรา - xdp_attach. ขออภัย โปรแกรมเช่น XDP ไม่สามารถเชื่อมต่อโดยใช้การเรียกของระบบได้ bpfผู้ที่สร้าง BPF และ XDP มาจากชุมชนออนไลน์ Linuxซึ่งหมายความว่าพวกเขาใช้สิ่งที่คุ้นเคยที่สุด (แต่ไม่ใช่สำหรับ ปกติ people) อินเทอร์เฟซสำหรับการโต้ตอบกับเคอร์เนล: , ดูสิ่งนี้ด้วย . วิธีที่ง่ายที่สุดในการดำเนินการ xdp_attach กำลังคัดลอกโค้ดจาก libbpfกล่าวคือจากไฟล์ ซึ่งเราทำแล้ว ย่อให้สั้นลงเล็กน้อย:
ยินดีต้อนรับสู่โลกของซ็อกเก็ต netlink
เปิดซ็อกเก็ต netlink เช่น NETLINK_ROUTE:
int netlink_open(__u32 *nl_pid)
{
struct sockaddr_nl sa;
socklen_t addrlen;
int one = 1, ret;
int sock;
memset(&sa, 0, sizeof(sa));
sa.nl_family = AF_NETLINK;
sock = socket(AF_NETLINK, SOCK_RAW, NETLINK_ROUTE);
if (sock < 0)
err(1, "socket");
if (setsockopt(sock, SOL_NETLINK, NETLINK_EXT_ACK, &one, sizeof(one)) < 0)
warnx("netlink error reporting not supported");
if (bind(sock, (struct sockaddr *)&sa, sizeof(sa)) < 0)
err(1, "bind");
addrlen = sizeof(sa);
if (getsockname(sock, (struct sockaddr *)&sa, &addrlen) < 0)
err(1, "getsockname");
*nl_pid = sa.nl_pid;
return sock;
}เราอ่านจากซ็อกเก็ตดังกล่าว:
static int bpf_netlink_recv(int sock, __u32 nl_pid, int seq)
{
bool multipart = true;
struct nlmsgerr *errm;
struct nlmsghdr *nh;
char buf[4096];
int len, ret;
while (multipart) {
multipart = false;
len = recv(sock, buf, sizeof(buf), 0);
if (len < 0)
err(1, "recv");
if (len == 0)
break;
for (nh = (struct nlmsghdr *)buf; NLMSG_OK(nh, len);
nh = NLMSG_NEXT(nh, len)) {
if (nh->nlmsg_pid != nl_pid)
errx(1, "wrong pid");
if (nh->nlmsg_seq != seq)
errx(1, "INVSEQ");
if (nh->nlmsg_flags & NLM_F_MULTI)
multipart = true;
switch (nh->nlmsg_type) {
case NLMSG_ERROR:
errm = (struct nlmsgerr *)NLMSG_DATA(nh);
if (!errm->error)
continue;
ret = errm->error;
// libbpf_nla_dump_errormsg(nh); too many code to copy...
goto done;
case NLMSG_DONE:
return 0;
default:
break;
}
}
}
ret = 0;
done:
return ret;
}สุดท้าย นี่คือฟังก์ชันของเราที่เปิดซ็อกเก็ตและส่งข้อความพิเศษที่มีตัวอธิบายไฟล์:
static int xdp_attach(int ifindex, int prog_fd)
{
int sock, seq = 0, ret;
struct nlattr *nla, *nla_xdp;
struct {
struct nlmsghdr nh;
struct ifinfomsg ifinfo;
char attrbuf[64];
} req;
__u32 nl_pid = 0;
sock = netlink_open(&nl_pid);
if (sock < 0)
return sock;
memset(&req, 0, sizeof(req));
req.nh.nlmsg_len = NLMSG_LENGTH(sizeof(struct ifinfomsg));
req.nh.nlmsg_flags = NLM_F_REQUEST | NLM_F_ACK;
req.nh.nlmsg_type = RTM_SETLINK;
req.nh.nlmsg_pid = 0;
req.nh.nlmsg_seq = ++seq;
req.ifinfo.ifi_family = AF_UNSPEC;
req.ifinfo.ifi_index = ifindex;
/* started nested attribute for XDP */
nla = (struct nlattr *)(((char *)&req)
+ NLMSG_ALIGN(req.nh.nlmsg_len));
nla->nla_type = NLA_F_NESTED | IFLA_XDP;
nla->nla_len = NLA_HDRLEN;
/* add XDP fd */
nla_xdp = (struct nlattr *)((char *)nla + nla->nla_len);
nla_xdp->nla_type = IFLA_XDP_FD;
nla_xdp->nla_len = NLA_HDRLEN + sizeof(int);
memcpy((char *)nla_xdp + NLA_HDRLEN, &prog_fd, sizeof(prog_fd));
nla->nla_len += nla_xdp->nla_len;
/* if user passed in any flags, add those too */
__u32 flags = XDP_FLAGS_SKB_MODE;
nla_xdp = (struct nlattr *)((char *)nla + nla->nla_len);
nla_xdp->nla_type = IFLA_XDP_FLAGS;
nla_xdp->nla_len = NLA_HDRLEN + sizeof(flags);
memcpy((char *)nla_xdp + NLA_HDRLEN, &flags, sizeof(flags));
nla->nla_len += nla_xdp->nla_len;
req.nh.nlmsg_len += NLA_ALIGN(nla->nla_len);
if (send(sock, &req, req.nh.nlmsg_len, 0) < 0)
err(1, "send");
ret = bpf_netlink_recv(sock, nl_pid, seq);
cleanup:
close(sock);
return ret;
}ทุกอย่างพร้อมสำหรับการทดสอบ:
$ cc nolibbpf.c -o nolibbpf
$ sudo strace -e bpf ./nolibbpf
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_ARRAY, map_name="woo", ...}, 72) = 3
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_XDP, insn_cnt=15, prog_name="woo", ...}, 72) = 4
+++ exited with 0 +++มาดูกันว่าโปรแกรมของเราเชื่อมต่อกับ lo:
$ ip l show dev lo
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 xdpgeneric qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
prog/xdp id 160ลองส่ง Ping และดูที่แผนที่:
$ for s in `seq 234`; do sudo ping -f -c 100 127.0.0.1 >/dev/null 2>&1; done
$ sudo bpftool m dump name woo
key: 00 00 00 00 value: 90 01 00 00 00 00 00 00
key: 01 00 00 00 value: 00 00 00 00 00 00 00 00
key: 02 00 00 00 value: 00 00 00 00 00 00 00 00
key: 03 00 00 00 value: 00 00 00 00 00 00 00 00
key: 04 00 00 00 value: 00 00 00 00 00 00 00 00
key: 05 00 00 00 value: 00 00 00 00 00 00 00 00
key: 06 00 00 00 value: 40 b5 00 00 00 00 00 00
key: 07 00 00 00 value: 00 00 00 00 00 00 00 00
Found 8 elementsไชโย ทุกอย่างทำงานได้ โปรดทราบว่าแผนที่ของเราจะแสดงเป็นไบต์อีกครั้ง นี่เป็นเพราะความจริงที่ว่าตรงกันข้ามกับ libbpf เราไม่ได้โหลดข้อมูลประเภท (BTF) แต่เราจะพูดถึงเรื่องนี้เพิ่มเติมในครั้งต่อไป
เครื่องมือพัฒนา
ในส่วนนี้ เราจะดูชุดเครื่องมือนักพัฒนา BPF ขั้นต่ำ
โดยทั่วไปแล้ว คุณไม่จำเป็นต้องมีอะไรพิเศษในการพัฒนาโปรแกรม BPF - BPF ทำงานบนเคอร์เนลการกระจายที่เหมาะสม และโปรแกรมถูกสร้างขึ้นโดยใช้ clangซึ่งสามารถจัดหาได้จากบรรจุภัณฑ์ อย่างไรก็ตาม เนื่องจาก BPF อยู่ระหว่างการพัฒนา แกนหลักและเครื่องมือจึงมีการเปลี่ยนแปลงตลอดเวลา หากคุณไม่ต้องการเขียนโปรแกรม BPF ในรูปแบบเก่าตั้งแต่ปี 2019 คุณจะต้องสร้าง
llvm/clangpahole- แกนของมัน
bpftool
(หมายเหตุ: ส่วนนี้และตัวอย่างทั้งหมดในบทความนี้ถูกทดสอบบน...) Debian 10.)
llvm/กราว
BPF เป็นมิตรกับ LLVM และแม้ว่าเมื่อเร็วๆ นี้โปรแกรม BPF สามารถคอมไพล์ด้วย gcc ได้ แต่การพัฒนาปัจจุบันทั้งหมดเสร็จสิ้นแล้วสำหรับ LLVM ดังนั้นสิ่งแรกที่เราจะทำคือสร้างเวอร์ชันปัจจุบัน clang จากคอมไพล์:
$ sudo apt install ninja-build
$ git clone --depth 1 https://github.com/llvm/llvm-project.git
$ mkdir -p llvm-project/llvm/build/install
$ cd llvm-project/llvm/build
$ cmake .. -G "Ninja" -DLLVM_TARGETS_TO_BUILD="BPF;X86"
-DLLVM_ENABLE_PROJECTS="clang"
-DBUILD_SHARED_LIBS=OFF
-DCMAKE_BUILD_TYPE=Release
-DLLVM_BUILD_RUNTIME=OFF
$ time ninja
... много времени спустя
$ตอนนี้เราสามารถตรวจสอบได้ว่าประกอบอย่างถูกต้องหรือไม่:
$ ./bin/llc --version
LLVM (http://llvm.org/):
LLVM version 11.0.0git
Optimized build.
Default target: x86_64-unknown-linux-gnu
Host CPU: znver1
Registered Targets:
bpf - BPF (host endian)
bpfeb - BPF (big endian)
bpfel - BPF (little endian)
x86 - 32-bit X86: Pentium-Pro and above
x86-64 - 64-bit X86: EM64T and AMD64(คำแนะนำการชุมนุม clang ฉันนำมาจาก .)
เราจะไม่ติดตั้งโปรแกรมที่สร้างขึ้นใหม่ แต่จะเพิ่มโปรแกรมเหล่านี้เข้าไปแทน PATHตัวอย่างเช่น:
export PATH="`pwd`/bin:$PATH"(สามารถเพิ่มเป็น .bashrc หรือไปยังไฟล์แยกต่างหาก โดยส่วนตัวแล้วฉันเพิ่มสิ่งนี้ลงไป ~/bin/activate-llvm.sh และเมื่อจำเป็นฉันก็ทำ . activate-llvm.sh.)
ปาโฮล และ BTF
คุณประโยชน์ pahole ใช้เมื่อสร้างเคอร์เนลเพื่อสร้างข้อมูลการดีบักในรูปแบบ BTF เราจะไม่ลงรายละเอียดในบทความนี้เกี่ยวกับรายละเอียดของเทคโนโลยี BTF เว้นแต่ว่าสะดวกและเราต้องการใช้ ดังนั้นหากคุณจะสร้างเคอร์เนล ให้สร้างก่อน pahole (โดยไม่ต้อง pahole คุณจะไม่สามารถสร้างเคอร์เนลด้วยตัวเลือกนี้ได้ CONFIG_DEBUG_INFO_BTF:
$ git clone https://git.kernel.org/pub/scm/devel/pahole/pahole.git
$ cd pahole/
$ sudo apt install cmake
$ mkdir build
$ cd build/
$ cmake -D__LIB=lib ..
$ make
$ sudo make install
$ which pahole
/usr/local/bin/paholeเมล็ดสำหรับทดลองกับ BPF
เมื่อสำรวจความเป็นไปได้ของ BPF ฉันต้องการประกอบแกนของตัวเอง โดยทั่วไปสิ่งนี้ไม่จำเป็น เนื่องจากคุณจะสามารถคอมไพล์และโหลดโปรแกรม BPF บนเคอร์เนลการแจกจ่ายได้ อย่างไรก็ตาม การมีเคอร์เนลของคุณเองทำให้คุณสามารถใช้คุณสมบัติ BPF ล่าสุดได้ ซึ่งจะปรากฏในการแจกจ่ายของคุณในไม่กี่เดือนอย่างดีที่สุด หรือในกรณีของเครื่องมือแก้ไขข้อบกพร่องบางอย่างจะไม่ได้รับการจัดทำแพ็คเกจเลยในอนาคตอันใกล้ นอกจากนี้แกนหลักของตัวเองยังทำให้การทดลองใช้โค้ดเป็นเรื่องสำคัญ
ในการสร้างเคอร์เนล คุณต้องมีเคอร์เนลอย่างแรก และประการที่สองคือไฟล์คอนฟิกูเรชันเคอร์เนล หากต้องการทดลองกับ BPF เราสามารถใช้แบบปกติได้ แกนหลักหรือหนึ่งในแกนหลักของนักพัฒนา ในอดีต การพัฒนา BPF เกิดขึ้นภายในชุมชนเครือข่าย Linux ดังนั้น การเปลี่ยนแปลงทั้งหมดจึงต้องผ่านเดวิด มิลเลอร์ ผู้ดูแลระบบเครือข่าย ไม่ช้าก็เร็ว Linuxการเปลี่ยนแปลงเครือข่ายนั้นขึ้นอยู่กับลักษณะของมัน—การแก้ไขข้อผิดพลาดหรือการเพิ่มคุณสมบัติใหม่—ซึ่งจะส่งผลให้เกิดการเปลี่ยนแปลงหลักสองประการ ได้แก่: หรือ . การเปลี่ยนแปลงสำหรับ BPF จะกระจายในลักษณะเดียวกันระหว่าง и ซึ่งจะถูกรวมเข้าด้วยกันเป็น net และ net-next ตามลำดับ สำหรับรายละเอียดเพิ่มเติม โปรดดู и . ดังนั้น เลือกเคอร์เนลตามรสนิยมของคุณและความต้องการความเสถียรของระบบที่คุณกำลังทดสอบ (*-next คอร์นั้นไม่เสถียรที่สุดในบรรดารายการเหล่านั้น)
บทความนี้ไม่ได้อยู่ในขอบเขตที่จะพูดคุยเกี่ยวกับวิธีจัดการไฟล์การกำหนดค่าเคอร์เนล - สันนิษฐานว่าคุณรู้วิธีการทำเช่นนี้แล้ว หรือ ด้วยตัวเอง อย่างไรก็ตาม คำแนะนำต่อไปนี้ควรมากหรือน้อยเพียงพอที่จะทำให้ระบบที่เปิดใช้งาน BPF ใช้งานได้
ดาวน์โหลดหนึ่งในเคอร์เนลด้านบน:
$ git clone git://git.kernel.org/pub/scm/linux/kernel/git/bpf/bpf-next.git
$ cd bpf-nextสร้างการกำหนดค่าเคอร์เนลที่ใช้งานได้น้อยที่สุด:
$ cp /boot/config-`uname -r` .config
$ make localmodconfigเปิดใช้งานตัวเลือก BPF ในไฟล์ .config ที่คุณเลือกเอง (เป็นไปได้มากที่สุด CONFIG_BPF จะเปิดใช้งานอยู่แล้วเนื่องจาก systemd ใช้) นี่คือรายการตัวเลือกจากเคอร์เนลที่ใช้สำหรับบทความนี้:
CONFIG_CGROUP_BPF=y
CONFIG_BPF=y
CONFIG_BPF_LSM=y
CONFIG_BPF_SYSCALL=y
CONFIG_ARCH_WANT_DEFAULT_BPF_JIT=y
CONFIG_BPF_JIT_ALWAYS_ON=y
CONFIG_BPF_JIT_DEFAULT_ON=y
CONFIG_IPV6_SEG6_BPF=y
# CONFIG_NETFILTER_XT_MATCH_BPF is not set
# CONFIG_BPFILTER is not set
CONFIG_NET_CLS_BPF=y
CONFIG_NET_ACT_BPF=y
CONFIG_BPF_JIT=y
CONFIG_BPF_STREAM_PARSER=y
CONFIG_LWTUNNEL_BPF=y
CONFIG_HAVE_EBPF_JIT=y
CONFIG_BPF_EVENTS=y
CONFIG_BPF_KPROBE_OVERRIDE=y
CONFIG_DEBUG_INFO_BTF=yต่อไป เราสามารถสร้างและติดตั้งโมดูลและเคอร์เนลได้อย่างง่ายดาย (อย่างไรก็ตาม คุณสามารถสร้างเคอร์เนลโดยใช้โมดูลที่เพิ่งสร้าง clangโดยการเพิ่ม CC=clang):
$ make -s -j $(getconf _NPROCESSORS_ONLN)
$ sudo make modules_install
$ sudo make installและรีบูตด้วยเคอร์เนลใหม่ (ฉันใช้ kexec จากแพคเกจ kexec-tools):
v=5.8.0-rc6+ # если вы пересобираете текущее ядро, то можно делать v=`uname -r`
sudo kexec -l -t bzImage /boot/vmlinuz-$v --initrd=/boot/initrd.img-$v --reuse-cmdline &&
sudo kexec -ebpftool
ยูทิลิตีที่ใช้บ่อยที่สุดในบทความจะเป็นยูทิลิตี bpftoolซึ่งจัดเตรียมไว้เป็นส่วนหนึ่งของเคอร์เนล Linuxโปรแกรมนี้เขียนและดูแลโดยนักพัฒนา BPF สำหรับนักพัฒนา BPF และสามารถใช้จัดการวัตถุ BPF ทุกประเภทได้ เช่น การโหลดโปรแกรม การสร้างและแก้ไขแผนที่ การสำรวจระบบนิเวศ BPF และอื่นๆ เอกสารประกอบในรูปแบบของซอร์สโค้ดสำหรับหน้าคู่มือสามารถดูได้ที่นี่ หรือเรียบเรียงแล้ว .
ในขณะที่เขียนนี้ bpftool พร้อมใช้งานได้ทันทีสำหรับ RHEL, Fedora และ Ubuntu (ดูตัวอย่างเช่น) ซึ่งบอกเล่าเรื่องราวของการห่อที่ยังไม่เสร็จ bpftool в Debianแต่ถ้าคุณประกอบเคอร์เนลเสร็จแล้ว ก็ให้ประกอบต่อไป bpftool ง่ายเหมือนพาย:
$ cd ${linux}/tools/bpf/bpftool
# ... пропишите пути к последнему clang, как рассказано выше
$ make -s
Auto-detecting system features:
... libbfd: [ on ]
... disassembler-four-args: [ on ]
... zlib: [ on ]
... libcap: [ on ]
... clang-bpf-co-re: [ on ]
Auto-detecting system features:
... libelf: [ on ]
... zlib: [ on ]
... bpf: [ on ]
$(ที่นี่ ${linux} - นี่คือไดเรกทอรีเคอร์เนลของคุณ) หลังจากดำเนินการคำสั่งเหล่านี้ bpftool จะถูกรวบรวมไว้ในไดเร็กทอรี ${linux}/tools/bpf/bpftool และสามารถเขียนบนเส้นทางได้ (ก่อนอื่นผู้ใช้ root) หรือเพียงคัดลอกไปที่ /usr/local/sbin.
เก็บรวบรวม bpftool ดีที่สุดกับหลัง clangประกอบตามที่อธิบายไว้ข้างต้น และตรวจสอบว่าประกอบถูกต้องโดยใช้คำสั่ง ตัวอย่างเช่น
$ sudo bpftool feature probe kernel
Scanning system configuration...
bpf() syscall for unprivileged users is enabled
JIT compiler is enabled
JIT compiler hardening is disabled
JIT compiler kallsyms exports are enabled for root
...ซึ่งจะแสดงว่าฟีเจอร์ BPF ใดที่เปิดใช้งานในเคอร์เนลของคุณ
โดยวิธีการก่อนหน้านี้สามารถเรียกใช้คำสั่งก่อนหน้านี้ได้
# bpftool f p kสิ่งนี้ทำได้โดยการเปรียบเทียบกับยูทิลิตี้จากแพ็คเกจ iproute2ที่ซึ่งเราสามารถพูดได้ เช่น ip a s eth0 แทน ip addr show dev eth0.
ข้อสรุป
BPF อนุญาตให้ใส่หมัดเพื่อวัดและเปลี่ยนการทำงานของเคอร์เนลได้อย่างมีประสิทธิภาพในทันที ระบบประสบความสำเร็จอย่างมากตามประเพณีที่ดีที่สุดของ UNIX: กลไกง่ายๆ ที่ช่วยให้สามารถ (re) ตั้งโปรแกรมเคอร์เนลได้ ทำให้ผู้คนและองค์กรจำนวนมากสามารถทดลองได้ และแม้ว่าการทดลองตลอดจนการพัฒนาโครงสร้างพื้นฐานของ BPF จะยังไม่สิ้นสุด แต่ระบบก็มี ABI ที่เสถียรอยู่แล้ว ซึ่งช่วยให้คุณสร้างตรรกะทางธุรกิจที่เชื่อถือได้และที่สำคัญที่สุดคือมีประสิทธิภาพ
ฉันต้องการทราบว่าในความคิดของฉันเทคโนโลยีกลายเป็นที่นิยมมากเพราะในแง่หนึ่งมันสามารถ เพื่อเล่น (สถาปัตยกรรมของเครื่องสามารถเข้าใจได้มากหรือน้อยในเย็นวันหนึ่ง) และในทางกลับกันเพื่อแก้ปัญหาที่ไม่สามารถแก้ไขได้ (อย่างสวยงาม) ก่อนที่จะปรากฏตัว องค์ประกอบทั้งสองนี้รวมกันทำให้ผู้คนทดลองและฝัน ซึ่งนำไปสู่การเกิดขึ้นของโซลูชันที่เป็นนวัตกรรมมากขึ้นเรื่อยๆ
บทความนี้แม้จะไม่สั้นนัก แต่เป็นเพียงบทนำสู่โลกของ BPF และไม่ได้อธิบายคุณลักษณะ "ขั้นสูง" และส่วนสำคัญของสถาปัตยกรรม แนวทางต่อไปเป็นดังนี้: บทความถัดไปจะเป็นภาพรวมของประเภทโปรแกรม BPF (เคอร์เนล 5.8 รองรับ 30 ประเภทโปรแกรม) จากนั้นเราจะมาดูวิธีเขียนแอปพลิเคชัน BPF จริงโดยใช้โปรแกรมตัวอย่างสำหรับการติดตามเคอร์เนล จากนั้นจะถึงเวลาสำหรับหลักสูตรเชิงลึกเพิ่มเติมเกี่ยวกับสถาปัตยกรรม BPF และจากนั้นสำหรับตัวอย่างแอปพลิเคชันระบบเครือข่ายและความปลอดภัย BPF
บทความก่อนหน้านี้ในชุดนี้
ลิงค์
— เอกสารเกี่ยวกับ BPF จาก cilium หรือถ้าเจาะจงกว่านี้จาก Daniel Borkman หนึ่งในผู้สร้างและผู้ดูแล BPF นี่เป็นคำอธิบายที่จริงจังประการแรกๆ ซึ่งแตกต่างจากคำอธิบายอื่นๆ ตรงที่แดเนียลรู้แน่ชัดว่าเขาเขียนถึงอะไรและไม่มีข้อผิดพลาดใดๆ โดยเฉพาะอย่างยิ่ง เอกสารนี้จะอธิบายวิธีการทำงานกับโปรแกรม BPF ประเภท XDP และ TC โดยใช้ยูทิลิตี้ที่รู้จักกันดี
ipจากแพคเกจiproute2.- ไฟล์ต้นฉบับพร้อมเอกสารประกอบสำหรับคลาสสิก และสำหรับ BPF แบบขยาย การอ่านที่ดีถ้าคุณต้องการเจาะลึกภาษาแอสเซมบลีและรายละเอียดทางเทคนิคของสถาปัตยกรรม
. ไม่ค่อยมีการอัปเดต แต่เหมาะเจาะตามที่ Alexei Starovoitov (ผู้เขียน eBPF) และ Andrii Nakryiko - (ผู้ดูแล) เขียนไว้ที่นั่น
libbpf).. กระทู้ทวิตเตอร์น่าสนใจโดย Quentin Monnet พร้อมตัวอย่างและเคล็ดลับการใช้ bpftool
. รายการลิงก์ขนาดมหึมา (และยังคงอยู่) ไปยังเอกสารประกอบ BPF โดย Quentin Monnet
ที่มา: will.com
