

ในบทความนี้เราจะพูดถึงวิธีการและเหตุผลที่เราพัฒนา – กลไกที่ถ่ายโอนข้อมูลระหว่างแอปพลิเคชันไคลเอนต์และเซิร์ฟเวอร์ 1C: Enterprise - ตั้งแต่การตั้งค่างานไปจนถึงการคิดผ่านสถาปัตยกรรมและรายละเอียดการใช้งาน
ระบบโต้ตอบ (ต่อไปนี้จะเรียกว่า SV) เป็นระบบส่งข้อความแบบกระจายและทนทานต่อข้อผิดพลาดพร้อมการรับประกันการจัดส่ง SV ได้รับการออกแบบให้เป็นบริการที่มีภาระงานสูงและมีความสามารถในการปรับขนาดสูง มีทั้งแบบบริการออนไลน์ (จัดทำโดย 1C) และผลิตภัณฑ์ที่ผลิตจำนวนมากซึ่งสามารถปรับใช้บนเซิร์ฟเวอร์ของคุณเองได้
SV ใช้พื้นที่จัดเก็บแบบกระจาย และเครื่องมือค้นหา . นอกจากนี้เรายังจะพูดถึง Java และวิธีที่เราปรับขนาด PostgreSQL ในแนวนอน
คำแถลงปัญหา
เพื่อให้ชัดเจนว่าทำไมเราถึงสร้างระบบโต้ตอบ ฉันจะบอกคุณเล็กน้อยเกี่ยวกับวิธีการทำงานของการพัฒนาแอปพลิเคชันทางธุรกิจใน 1C
เริ่มต้นด้วยข้อมูลเล็กน้อยเกี่ยวกับเราสำหรับผู้ที่ยังไม่รู้ว่าเราทำอะไร :) เรากำลังสร้างแพลตฟอร์มเทคโนโลยี 1C:Enterprise แพลตฟอร์มดังกล่าวประกอบด้วยเครื่องมือพัฒนาแอปพลิเคชันทางธุรกิจ รวมถึงรันไทม์ที่ช่วยให้แอปพลิเคชันทางธุรกิจทำงานในสภาพแวดล้อมข้ามแพลตฟอร์มได้
กระบวนทัศน์การพัฒนาไคลเอ็นต์-เซิร์ฟเวอร์
แอปพลิเคชันทางธุรกิจที่สร้างขึ้นบน 1C:Enterprise ทำงานในสามระดับ สถาปัตยกรรม “DBMS – แอปพลิเคชันเซิร์ฟเวอร์ – ไคลเอนต์” รหัสแอปพลิเคชันเขียนอยู่ใน สามารถดำเนินการได้บนแอปพลิเคชันเซิร์ฟเวอร์หรือบนไคลเอนต์ การทำงานกับออบเจ็กต์แอปพลิเคชันทั้งหมด (ไดเร็กทอรี เอกสาร ฯลฯ) เช่นเดียวกับการอ่านและเขียนฐานข้อมูล จะดำเนินการบนเซิร์ฟเวอร์เท่านั้น ฟังก์ชันการทำงานของแบบฟอร์มและส่วนต่อประสานคำสั่งยังถูกนำไปใช้บนเซิร์ฟเวอร์ด้วย ลูกค้าดำเนินการรับ เปิด และแสดงแบบฟอร์ม "สื่อสาร" กับผู้ใช้ (คำเตือน คำถาม...) การคำนวณเล็กน้อยในรูปแบบที่ต้องการการตอบสนองอย่างรวดเร็ว (เช่น การคูณราคาตามปริมาณ) การทำงานกับไฟล์ในเครื่อง ทำงานกับอุปกรณ์
ในโค้ดแอปพลิเคชัน ส่วนหัวของขั้นตอนและฟังก์ชันจะต้องระบุอย่างชัดเจนว่าโค้ดจะถูกดำเนินการที่ไหน - โดยใช้คำสั่ง &AtClient / &AtServer (&AtClient / &AtServer ในภาษาเวอร์ชันภาษาอังกฤษ) นักพัฒนา 1C จะแก้ไขฉันโดยบอกว่าคำสั่งนั้นเป็นจริง แต่สำหรับเราเรื่องนี้ไม่สำคัญแล้ว
คุณสามารถเรียกรหัสเซิร์ฟเวอร์จากรหัสไคลเอนต์ได้ แต่คุณไม่สามารถเรียกรหัสไคลเอนต์จากรหัสเซิร์ฟเวอร์ได้ นี่เป็นข้อจำกัดพื้นฐานที่เราสร้างขึ้นด้วยเหตุผลหลายประการ โดยเฉพาะอย่างยิ่ง เนื่องจากรหัสเซิร์ฟเวอร์จะต้องเขียนในลักษณะที่ดำเนินการในลักษณะเดียวกันไม่ว่าจะเรียกจากที่ใด - จากไคลเอนต์หรือจากเซิร์ฟเวอร์ และในกรณีของการเรียกรหัสเซิร์ฟเวอร์จากรหัสเซิร์ฟเวอร์อื่น จะไม่มีไคลเอ็นต์ดังกล่าว และเนื่องจากในระหว่างการดำเนินการโค้ดเซิร์ฟเวอร์ ไคลเอนต์ที่เรียกโค้ดดังกล่าวสามารถปิด ออกจากแอปพลิเคชันได้ และเซิร์ฟเวอร์จะไม่มีใครโทรอีกต่อไป

รหัสที่จัดการการคลิกปุ่ม: การเรียกขั้นตอนเซิร์ฟเวอร์จากไคลเอนต์จะทำงาน แต่การเรียกขั้นตอนไคลเอนต์จากเซิร์ฟเวอร์จะไม่ทำงาน
ซึ่งหมายความว่าหากเราต้องการส่งข้อความจากเซิร์ฟเวอร์ไปยังแอปพลิเคชันไคลเอนต์ เช่น การสร้างรายงาน "ระยะยาว" เสร็จสิ้นแล้วและสามารถดูรายงานได้ เราก็ไม่มีวิธีการดังกล่าว คุณต้องใช้ลูกเล่น เช่น สำรวจเซิร์ฟเวอร์จากรหัสไคลเอ็นต์เป็นระยะ แต่วิธีนี้ทำให้ระบบโหลดด้วยการโทรที่ไม่จำเป็นและโดยทั่วไปแล้วดูไม่สวยงามมากนัก
และยังมีความจำเป็นด้วย เช่น เมื่อมีสายโทรศัพท์เข้ามา - เมื่อโทรออกให้แจ้งแอปพลิเคชันไคลเอนต์เกี่ยวกับเรื่องนี้เพื่อให้สามารถใช้หมายเลขผู้โทรค้นหาในฐานข้อมูลคู่สัญญาและแสดงข้อมูลผู้ใช้เกี่ยวกับคู่สัญญาที่โทร หรือตัวอย่างเช่น เมื่อมีคำสั่งซื้อมาถึงคลังสินค้า ให้แจ้งใบสมัครลูกค้าของลูกค้าเกี่ยวกับเรื่องนี้ โดยทั่วไปมีหลายกรณีที่กลไกดังกล่าวจะเป็นประโยชน์
การผลิตนั่นเอง
สร้างกลไกการส่งข้อความ รวดเร็ว เชื่อถือได้ รับประกันการจัดส่ง พร้อมความสามารถในการค้นหาข้อความอย่างยืดหยุ่น ตามกลไกนี้ ใช้งาน Messenger (ข้อความ แฮงเอาท์วิดีโอ) ที่ทำงานภายในแอปพลิเคชัน 1C
ออกแบบระบบให้ปรับขนาดได้ในแนวนอน โหลดที่เพิ่มขึ้นจะต้องครอบคลุมโดยการเพิ่มจำนวนโหนด
การดำเนินงาน
เราตัดสินใจที่จะไม่รวมส่วนเซิร์ฟเวอร์ของ SV เข้ากับแพลตฟอร์ม 1C:Enterprise โดยตรง แต่จะนำไปใช้เป็นผลิตภัณฑ์แยกต่างหาก ซึ่ง API นี้สามารถเรียกได้จากโค้ดของโซลูชันแอปพลิเคชัน 1C สิ่งนี้เกิดขึ้นด้วยเหตุผลหลายประการ เหตุผลหลักคือฉันต้องการให้สามารถแลกเปลี่ยนข้อความระหว่างแอปพลิเคชัน 1C ที่แตกต่างกันได้ (เช่น ระหว่างการจัดการการค้าและการบัญชี) แอปพลิเคชัน 1C ที่แตกต่างกันสามารถทำงานบนแพลตฟอร์ม 1C:Enterprise เวอร์ชันที่แตกต่างกัน ซึ่งอยู่บนเซิร์ฟเวอร์ที่แตกต่างกัน เป็นต้น ในสภาวะดังกล่าว การใช้ SV เป็นผลิตภัณฑ์แยกต่างหากซึ่งติดตั้ง "ด้านข้าง" ของการติดตั้ง 1C ถือเป็นทางออกที่ดีที่สุด
ดังนั้นเราจึงตัดสินใจสร้าง SV เป็นผลิตภัณฑ์แยกต่างหาก เราขอแนะนำให้บริษัทขนาดเล็กใช้เซิร์ฟเวอร์ CB ที่เราติดตั้งในระบบคลาวด์ของเรา (wss://1cdialog.com) เพื่อหลีกเลี่ยงต้นทุนค่าโสหุ้ยที่เกี่ยวข้องกับการติดตั้งและการกำหนดค่าภายในเครื่องของเซิร์ฟเวอร์ ลูกค้ารายใหญ่อาจพบว่าแนะนำให้ติดตั้งเซิร์ฟเวอร์ CB ของตนเองที่สถานที่ของตน เราใช้วิธีการที่คล้ายกันในผลิตภัณฑ์ SaaS บนคลาวด์ของเรา – ผลิตเป็นผลิตภัณฑ์ที่ผลิตจำนวนมากสำหรับการติดตั้งที่ไซต์งานของลูกค้า และยังปรับใช้ในระบบคลาวด์ของเราด้วย .
ใบสมัคร
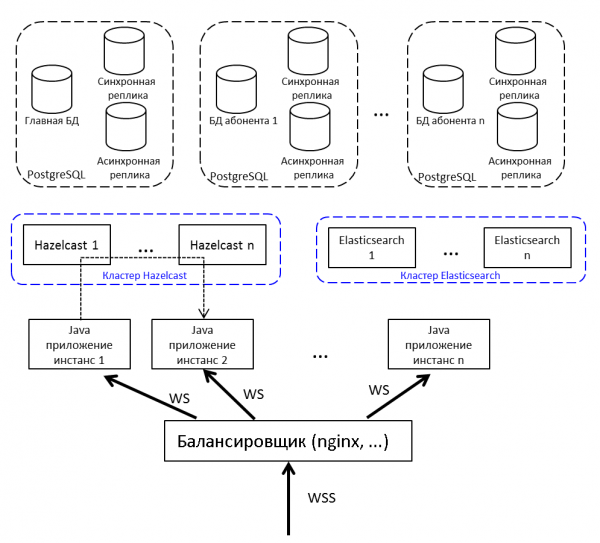
ในการกระจายความทนทานต่อโหลดและข้อผิดพลาด เราจะไม่ปรับใช้แอปพลิเคชัน Java เพียงแอปพลิเคชันเดียว แต่ปรับใช้หลายแอปพลิเคชัน โดยมีโหลดบาลานเซอร์อยู่ด้านหน้า หากคุณต้องการถ่ายโอนข้อความจากโหนดหนึ่งไปอีกโหนดหนึ่ง ให้ใช้เผยแพร่/สมัครสมาชิกใน Hazelcast
การสื่อสารระหว่างไคลเอนต์และเซิร์ฟเวอร์ทำผ่าน websocket เหมาะอย่างยิ่งสำหรับระบบเรียลไทม์
แคชแบบกระจาย
เราเลือกระหว่าง Redis, Hazelcast และ Ehcache มันคือปี 2015 Redis เพิ่งเปิดตัวคลัสเตอร์ใหม่ (ใหม่เกินไป น่ากลัว) มี Sentinel ที่มีข้อจำกัดมากมาย Ehcache ไม่รู้วิธีประกอบเป็นคลัสเตอร์ (ฟังก์ชันนี้ปรากฏในภายหลัง) เราตัดสินใจลองใช้ Hazelcast 3.4
Hazelcast ถูกประกอบเป็นคลัสเตอร์นอกกล่อง ในโหมดโหนดเดียวมันไม่มีประโยชน์มากและสามารถใช้เป็นแคชได้เท่านั้น - ไม่ทราบวิธีถ่ายโอนข้อมูลลงดิสก์หากคุณสูญเสียโหนดเดียวข้อมูลก็จะสูญหาย เราปรับใช้ Hazelcast หลายตัว โดยระหว่างนั้นเราจะสำรองข้อมูลสำคัญไว้ เราไม่สำรองแคช – เราไม่รังเกียจมัน
สำหรับเรา Hazelcast คือ:
- การจัดเก็บเซสชันผู้ใช้ การไปที่ฐานข้อมูลสำหรับเซสชันแต่ละครั้งใช้เวลานาน ดังนั้นเราจึงใส่เซสชันทั้งหมดไว้ใน Hazelcast
- แคช หากคุณกำลังมองหาโปรไฟล์ผู้ใช้ ให้ตรวจสอบแคช เขียนข้อความใหม่ - วางไว้ในแคช
- หัวข้อสำหรับการสื่อสารระหว่างอินสแตนซ์ของแอปพลิเคชัน โหนดสร้างเหตุการณ์และวางไว้ในหัวข้อ Hazelcast โหนดแอปพลิเคชันอื่นที่สมัครรับหัวข้อนี้จะได้รับและประมวลผลเหตุการณ์
- ล็อคคลัสเตอร์ ตัวอย่างเช่น เราสร้างการสนทนาโดยใช้คีย์เฉพาะ (การสนทนาแบบซิงเกิลตันภายในฐานข้อมูล 1C):
conversationKeyChecker.check("БЕНЗОКОЛОНКА");
doInClusterLock("БЕНЗОКОЛОНКА", () -> {
conversationKeyChecker.check("БЕНЗОКОЛОНКА");
createChannel("БЕНЗОКОЛОНКА");
});เราตรวจสอบว่าไม่มีช่อง เราเอาล็อคไป ตรวจสอบอีกครั้ง และสร้างมันขึ้นมา หากคุณไม่ตรวจสอบการล็อคหลังจากทำการล็อค ก็มีโอกาสที่เธรดอื่นจะตรวจสอบในขณะนั้นด้วย และตอนนี้จะพยายามสร้างการสนทนาเดียวกัน - แต่มันมีอยู่แล้ว คุณไม่สามารถล็อคโดยใช้การล็อคจาวาแบบซิงโครไนซ์หรือปกติ ผ่านฐานข้อมูล - มันช้าและน่าเสียดายสำหรับฐานข้อมูล ผ่าน Hazelcast - นั่นคือสิ่งที่คุณต้องการ
การเลือก DBMS
เรามีประสบการณ์มากมายและประสบความสำเร็จในการทำงานกับ PostgreSQL และทำงานร่วมกับนักพัฒนาของ DBMS นี้
ไม่ใช่เรื่องง่ายสำหรับคลัสเตอร์ PostgreSQL - มีอยู่จริง , , แต่โดยทั่วไปแล้วสิ่งเหล่านี้ไม่ใช่ NoSQL ที่ขยายขนาดออกจากกล่อง เราไม่ได้ถือว่า NoSQL เป็นที่เก็บข้อมูลหลัก แค่เราใช้ Hazelcast ซึ่งเราไม่เคยใช้งานมาก่อนก็เพียงพอแล้ว
หากคุณต้องการปรับขนาดฐานข้อมูลเชิงสัมพันธ์นั่นหมายถึง . ดังที่คุณทราบ เมื่อใช้การแบ่งส่วน เราจะแบ่งฐานข้อมูลออกเป็นส่วนๆ เพื่อให้สามารถวางแต่ละส่วนไว้บนเซิร์ฟเวอร์ที่แยกจากกัน
เวอร์ชันแรกของการแบ่งส่วนของเราถือว่ามีความสามารถในการกระจายแต่ละตารางของแอปพลิเคชันของเราไปยังเซิร์ฟเวอร์ที่แตกต่างกันในสัดส่วนที่ต่างกัน มีข้อความมากมายบนเซิร์ฟเวอร์ A - โปรดย้ายส่วนหนึ่งของตารางนี้ไปยังเซิร์ฟเวอร์ B การตัดสินใจครั้งนี้เป็นการพูดถึงการปรับให้เหมาะสมก่อนเวลาอันควร ดังนั้นเราจึงตัดสินใจจำกัดตัวเองให้อยู่ในแนวทางที่มีผู้เช่าหลายราย
คุณสามารถอ่านเกี่ยวกับผู้เช่าหลายรายได้บนเว็บไซต์ .
SV มีแนวคิดในการสมัครและผู้สมัครสมาชิก แอปพลิเคชันคือการติดตั้งแอปพลิเคชันทางธุรกิจโดยเฉพาะ เช่น ERP หรือการบัญชี พร้อมด้วยผู้ใช้และข้อมูลธุรกิจ ผู้สมัครสมาชิกคือองค์กรหรือบุคคลที่ลงทะเบียนแอปพลิเคชันในเซิร์ฟเวอร์ SV ในนามของ ผู้สมัครสมาชิกสามารถลงทะเบียนแอปพลิเคชันได้หลายรายการ และแอปพลิเคชันเหล่านี้สามารถแลกเปลี่ยนข้อความระหว่างกันได้ สมาชิกกลายเป็นผู้เช่าในระบบของเรา ข้อความจากสมาชิกหลายรายสามารถอยู่ในฐานข้อมูลทางกายภาพเดียว หากเราเห็นว่าสมาชิกเริ่มสร้างการรับส่งข้อมูลจำนวนมาก เราจะย้ายไปยังฐานข้อมูลทางกายภาพที่แยกจากกัน (หรือแม้แต่เซิร์ฟเวอร์ฐานข้อมูลที่แยกจากกัน)
เรามีฐานข้อมูลหลักที่จัดเก็บตารางเส้นทางพร้อมข้อมูลเกี่ยวกับตำแหน่งของฐานข้อมูลสมาชิกทั้งหมด
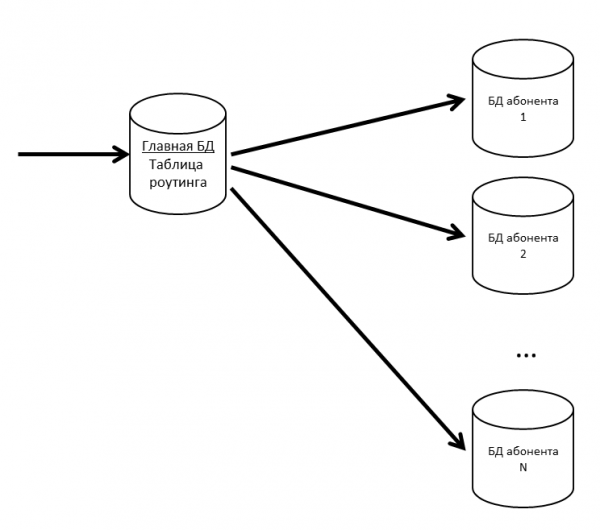
เพื่อป้องกันไม่ให้ฐานข้อมูลหลักเป็นคอขวด เราจะเก็บตารางเส้นทาง (และข้อมูลอื่น ๆ ที่จำเป็นบ่อย) ไว้ในแคช
หากฐานข้อมูลของผู้สมัครสมาชิกเริ่มช้าลง เราจะตัดออกเป็นพาร์ติชันภายใน ในโครงการอื่นที่เราใช้ .
เนื่องจากการสูญเสียข้อความของผู้ใช้ถือเป็นเรื่องไม่ดี เราจึงรักษาฐานข้อมูลของเราด้วยแบบจำลอง การรวมกันของแบบจำลองซิงโครนัสและอะซิงโครนัสช่วยให้คุณประกันตัวเองในกรณีที่ฐานข้อมูลหลักสูญหาย การสูญเสียข้อความจะเกิดขึ้นหากฐานข้อมูลหลักและแบบจำลองแบบซิงโครนัสล้มเหลวพร้อมกันเท่านั้น
หากแบบจำลองแบบซิงโครนัสสูญหาย แบบจำลองแบบอะซิงโครนัสจะกลายเป็นแบบซิงโครนัส
หากฐานข้อมูลหลักสูญหาย แบบจำลองแบบซิงโครนัสจะกลายเป็นฐานข้อมูลหลัก และแบบจำลองแบบอะซิงโครนัสจะกลายเป็นแบบจำลองแบบซิงโครนัส
Elasticsearch สำหรับการค้นหา
เนื่องจากเหนือสิ่งอื่นใด SV ยังเป็นผู้ส่งสารด้วย จึงต้องการค้นหาที่รวดเร็ว สะดวก และยืดหยุ่น โดยคำนึงถึงสัณฐานวิทยาด้วยการใช้การจับคู่ที่ไม่แม่นยำ เราตัดสินใจที่จะไม่สร้างวงล้อขึ้นมาใหม่และใช้เครื่องมือค้นหาฟรี Elasticsearch ที่สร้างขึ้นจากห้องสมุด . นอกจากนี้เรายังปรับใช้ Elasticsearch ในคลัสเตอร์ (ข้อมูลหลัก – ข้อมูล – ข้อมูล) เพื่อขจัดปัญหาในกรณีที่โหนดแอปพลิเคชันล้มเหลว
เราพบบน GitHub สำหรับ Elasticsearch และใช้งาน ในดัชนี Elasticsearch เราจัดเก็บรากคำ (ซึ่งปลั๊กอินกำหนด) และ N-grams เมื่อผู้ใช้ป้อนข้อความเพื่อค้นหา เราจะค้นหาข้อความที่พิมพ์ในกลุ่ม N-gram เมื่อบันทึกลงในดัชนี คำว่า "ข้อความ" จะถูกแบ่งออกเป็น N-grams ต่อไปนี้:
[เหล่านั้น, tek, tex, ข้อความ, ข้อความ, ek, อดีต, ต่อ, ข้อความ, ks, kst, ksty, st, sty, คุณ]
และรากของคำว่า “ข้อความ” ก็จะยังคงอยู่เช่นกัน วิธีนี้ทำให้คุณสามารถค้นหาที่จุดเริ่มต้น ตรงกลาง และท้ายคำได้
ภาพรวม
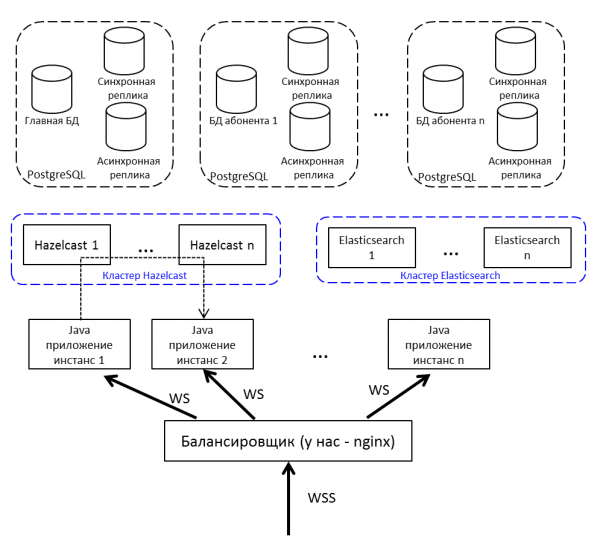
ทำซ้ำรูปภาพตั้งแต่ต้นบทความ แต่มีคำอธิบาย:
- Balancer เปิดเผยบนอินเทอร์เน็ต เรามี nginx มันสามารถเป็นอะไรก็ได้
- อินสแตนซ์แอปพลิเคชัน Java สื่อสารกันผ่าน Hazelcast
- เพื่อทำงานกับเว็บซ็อกเก็ตที่เราใช้ .
- แอปพลิเคชัน Java เขียนด้วย Java 8 และประกอบด้วยบันเดิล . แผนดังกล่าวรวมถึงการโยกย้ายไปยัง Java 10 และการเปลี่ยนไปใช้โมดูล
การพัฒนาและการทดสอบ
ในกระบวนการพัฒนาและทดสอบ SV เราพบคุณสมบัติที่น่าสนใจหลายประการของผลิตภัณฑ์ที่เราใช้
การทดสอบโหลดและหน่วยความจำรั่ว
การเปิดตัว SV แต่ละรายการเกี่ยวข้องกับการทดสอบโหลด จะประสบความสำเร็จเมื่อ:
- การทดสอบใช้งานได้หลายวันและไม่มีบริการล้มเหลว
- เวลาตอบสนองสำหรับการดำเนินการหลักไม่เกินเกณฑ์ที่สะดวกสบาย
- ประสิทธิภาพลดลงเมื่อเทียบกับรุ่นก่อนไม่เกิน 10%
เรากรอกฐานข้อมูลทดสอบด้วยข้อมูล - ในการทำเช่นนี้ เราได้รับข้อมูลเกี่ยวกับสมาชิกที่ใช้งานมากที่สุดจากเซิร์ฟเวอร์ที่ใช้งานจริง คูณตัวเลขด้วย 5 (จำนวนข้อความ การสนทนา ผู้ใช้) และทดสอบด้วยวิธีนั้น
เราทำการทดสอบโหลดของระบบโต้ตอบในการกำหนดค่าสามแบบ:
- การทดสอบความเครียด
- การเชื่อมต่อเท่านั้น
- การลงทะเบียนสมาชิก
ในระหว่างการทดสอบภาวะวิกฤต เราเปิดตัวเธรดหลายร้อยเธรด และโหลดระบบโดยไม่หยุด: การเขียนข้อความ การสร้างการสนทนา การรับรายการข้อความ เราจำลองการกระทำของผู้ใช้ทั่วไป (รับรายการข้อความที่ยังไม่ได้อ่าน เขียนถึงใครบางคน) และโซลูชันซอฟต์แวร์ (ส่งแพ็คเกจที่มีการกำหนดค่าอื่น ประมวลผลการแจ้งเตือน)
ตัวอย่างเช่น นี่คือลักษณะของการทดสอบความเครียด:
- ผู้ใช้เข้าสู่ระบบ
- ขอการสนทนาที่ยังไม่ได้อ่านของคุณ
- 50% มีแนวโน้มที่จะอ่านข้อความ
- 50% มีแนวโน้มที่จะส่งข้อความ
- ผู้ใช้รายถัดไป:
- มีโอกาส 20% ที่จะสร้างการสนทนาใหม่
- สุ่มเลือกการสนทนาใดก็ได้
- เข้าไปข้างใน
- ขอข้อความ โปรไฟล์ผู้ใช้
- สร้างข้อความห้าข้อความที่ส่งถึงผู้ใช้แบบสุ่มจากการสนทนานี้
- ออกจากการสนทนา
- ทำซ้ำ 20 ครั้ง
- ออกจากระบบ กลับไปที่จุดเริ่มต้นของสคริปต์
- แชทบอทเข้าสู่ระบบ (จำลองข้อความจากรหัสแอปพลิเคชัน)
- มีโอกาส 50% ที่จะสร้างช่องทางใหม่ในการแลกเปลี่ยนข้อมูล (เสวนาพิเศษ)
- 50% มีแนวโน้มที่จะเขียนข้อความถึงช่องทางที่มีอยู่
สถานการณ์ "การเชื่อมต่อเท่านั้น" ปรากฏขึ้นด้วยเหตุผล มีสถานการณ์เกิดขึ้น: ผู้ใช้ได้เชื่อมต่อระบบแล้ว แต่ยังไม่ได้มีส่วนร่วม ผู้ใช้แต่ละคนเปิดคอมพิวเตอร์เวลา 09 น. ทำการเชื่อมต่อกับเซิร์ฟเวอร์และยังคงเงียบอยู่ พวกเหล่านี้อันตราย มีหลายอย่าง - แพ็คเกจเดียวที่พวกเขามีคือ PING/PONG แต่พวกเขายังคงเชื่อมต่อกับเซิร์ฟเวอร์ (พวกเขาตามไม่ทัน - จะเกิดอะไรขึ้นถ้ามีข้อความใหม่) การทดสอบจำลองสถานการณ์ที่ผู้ใช้จำนวนมากพยายามเข้าสู่ระบบภายในครึ่งชั่วโมง คล้ายกับการทดสอบความเครียด แต่มุ่งเน้นไปที่อินพุตแรกนี้อย่างแม่นยำเพื่อไม่ให้เกิดความล้มเหลว (บุคคลไม่ได้ใช้ระบบและหลุดออกไปแล้ว - เป็นการยากที่จะคิดถึงสิ่งที่แย่กว่านั้น)
สคริปต์การลงทะเบียนสมาชิกเริ่มต้นตั้งแต่การเปิดตัวครั้งแรก เราทำการทดสอบภาวะวิกฤตและมั่นใจว่าระบบไม่ช้าลงในระหว่างการโต้ตอบ แต่ผู้ใช้เข้ามาและการลงทะเบียนเริ่มล้มเหลวเนื่องจากการหมดเวลา เมื่อลงทะเบียนเราใช้ ซึ่งเกี่ยวข้องกับเอนโทรปีของระบบ เซิร์ฟเวอร์ไม่มีเวลาสะสมเอนโทรปีเพียงพอ และเมื่อมีการร้องขอ SecureRandom ใหม่ เซิร์ฟเวอร์จะค้างเป็นเวลาสิบวินาที มีหลายวิธีในสถานการณ์นี้ เช่น เปลี่ยนไปใช้ /dev/urandom ที่มีความปลอดภัยน้อยกว่า ติดตั้งบอร์ดพิเศษที่สร้างเอนโทรปี สร้างตัวเลขสุ่มล่วงหน้า และเก็บไว้ในพูล เราปิดปัญหาเกี่ยวกับพูลชั่วคราว แต่ตั้งแต่นั้นมา เราได้ทำการทดสอบแยกต่างหากสำหรับการลงทะเบียนสมาชิกใหม่
เราใช้เป็นตัวสร้างโหลด . มันไม่รู้วิธีทำงานกับ websocket มันต้องมีปลั๊กอิน อันดับแรกในผลการค้นหาสำหรับคำค้นหา "jmeter websocket" คือ: ซึ่งแนะนำ .
นั่นคือจุดที่เราตัดสินใจที่จะเริ่มต้น
เกือบจะในทันทีหลังจากเริ่มการทดสอบอย่างจริงจัง เราพบว่า JMeter เริ่มมีหน่วยความจำรั่ว
ปลั๊กอินเป็นเรื่องใหญ่ที่แยกจากกัน ด้วยดาว 176 ดวง มี 132 ส้อมบน GitHub ผู้เขียนเองไม่ได้ให้คำมั่นสัญญากับมันมาตั้งแต่ปี 2015 (เราใช้มันในปี 2015 จากนั้นก็ไม่ได้ทำให้เกิดความสงสัย) ปัญหา GitHub หลายประการเกี่ยวกับหน่วยความจำรั่ว คำขอดึงข้อมูล 7 รายการที่ไม่ได้ปิด
หากคุณตัดสินใจที่จะดำเนินการทดสอบโหลดโดยใช้ปลั๊กอินนี้ โปรดใส่ใจกับการสนทนาต่อไปนี้:
- ในสภาพแวดล้อมแบบมัลติเธรด LinkedList ปกติจะถูกนำมาใช้ และผลลัพธ์ก็คือ ในรันไทม์ ซึ่งสามารถแก้ไขได้โดยการสลับไปที่ ConcurrentLinkedDeque หรือโดยการซิงโครไนซ์บล็อก เราเลือกตัวเลือกแรกสำหรับตัวเราเอง ().
- หน่วยความจำรั่ว เมื่อตัดการเชื่อมต่อ ข้อมูลการเชื่อมต่อจะไม่ถูกลบ ().
- ในโหมดสตรีมมิ่ง (เมื่อ websocket ไม่ได้ปิดในตอนท้ายของตัวอย่าง แต่ใช้ในภายหลังในแผน) รูปแบบการตอบสนองจะไม่ทำงาน ().
นี่เป็นหนึ่งในนั้นบน GitHub สิ่งที่เราทำ:
- ได้เอา (@elyrank) – แก้ไขปัญหาที่ 1 และ 3
- แก้ไขปัญหาที่ 2
- อัปเดตท่าเทียบเรือจาก 9.2.14 เป็น 9.3.12
- ห่อ SimpleDateFormat ใน ThreadLocal; SimpleDateFormat ไม่ปลอดภัยต่อเธรด ซึ่งนำไปสู่ NPE ณ รันไทม์
- แก้ไขหน่วยความจำรั่วอีกครั้ง (การเชื่อมต่อถูกปิดอย่างไม่ถูกต้องเมื่อตัดการเชื่อมต่อ)
แต่ก็ยังไหล!
ความทรงจำเริ่มหมดไม่ใช่ในหนึ่งวัน แต่ในสองวัน ไม่มีเวลาเหลือแล้วจริงๆ ดังนั้นเราจึงตัดสินใจเปิดตัวเธรดน้อยลง แต่ใช้ตัวแทนสี่คน ควรจะเพียงพอเป็นเวลาอย่างน้อยหนึ่งสัปดาห์
ผ่านไปสองวันแล้ว...
ตอนนี้ Hazelcast หน่วยความจำไม่เพียงพอ บันทึกแสดงให้เห็นว่าหลังจากการทดสอบสองสามวัน Hazelcast ก็เริ่มบ่นเกี่ยวกับการขาดหน่วยความจำ และหลังจากนั้นไม่นานคลัสเตอร์ก็แตกสลาย และโหนดต่างๆ ก็ยังคงตายไปทีละโหนด เราเชื่อมต่อ JVisualVM กับ Hazelcast และเห็น "เลื่อยที่เพิ่มขึ้น" ซึ่งเรียกกันทั่วไปว่า GC แต่ไม่สามารถล้างหน่วยความจำได้
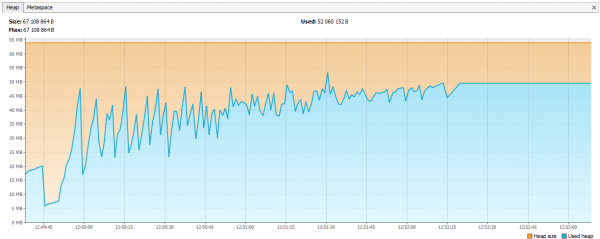
ปรากฎว่าใน Hazelcast 3.4 เมื่อลบแผนที่ / multiMap (map.destroy()) หน่วยความจำจะไม่ถูกปล่อยออกโดยสมบูรณ์:
ขณะนี้ข้อบกพร่องได้รับการแก้ไขแล้วในเวอร์ชัน 3.5 แต่ในตอนนั้นยังเป็นปัญหาอยู่ เราสร้าง multiMaps ใหม่พร้อมชื่อไดนามิกและลบออกตามตรรกะของเรา รหัสมีลักษณะดังนี้:
public void join(Authentication auth, String sub) {
MultiMap<UUID, Authentication> sessions = instance.getMultiMap(sub);
sessions.put(auth.getUserId(), auth);
}
public void leave(Authentication auth, String sub) {
MultiMap<UUID, Authentication> sessions = instance.getMultiMap(sub);
sessions.remove(auth.getUserId(), auth);
if (sessions.size() == 0) {
sessions.destroy();
}
}ชื่อเรื่อง:
service.join(auth1, "НОВЫЕ_СООБЩЕНИЯ_В_ОБСУЖДЕНИИ_UUID1");
service.join(auth2, "НОВЫЕ_СООБЩЕНИЯ_В_ОБСУЖДЕНИИ_UUID1");multiMap ถูกสร้างขึ้นสำหรับการสมัครสมาชิกแต่ละครั้งและถูกลบเมื่อไม่จำเป็น เราตัดสินใจว่าจะเริ่ม Map คีย์จะเป็นชื่อของการสมัครสมาชิกและค่าจะเป็นตัวระบุเซสชัน (ซึ่งคุณจะได้รับตัวระบุผู้ใช้หากจำเป็น)
public void join(Authentication auth, String sub) {
addValueToMap(sub, auth.getSessionId());
}
public void leave(Authentication auth, String sub) {
removeValueFromMap(sub, auth.getSessionId());
}แผนภูมิได้รับการปรับปรุง
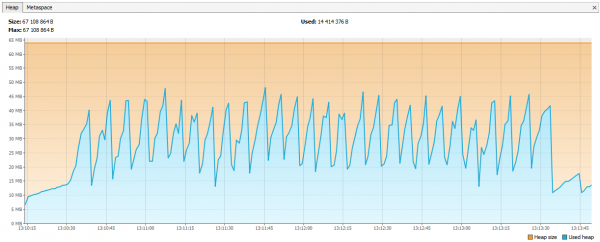
เราได้เรียนรู้อะไรอีกบ้างเกี่ยวกับการทดสอบโหลด
- JSR223 จำเป็นต้องเขียนด้วย Groovy และรวมแคชการคอมไพล์ด้วย ซึ่งเร็วกว่ามาก .
- กราฟ Jmeter-Plugins เข้าใจได้ง่ายกว่ากราฟมาตรฐาน .
เกี่ยวกับประสบการณ์ของเรากับ Hazelcast
Hazelcast เป็นผลิตภัณฑ์ใหม่สำหรับเรา เราเริ่มทำงานกับมันตั้งแต่เวอร์ชัน 3.4.1 ขณะนี้เซิร์ฟเวอร์ที่ใช้งานจริงของเราใช้เวอร์ชัน 3.9.2 (ในขณะที่เขียน Hazelcast เวอร์ชันล่าสุดคือ 3.10)
การสร้างรหัส
เราเริ่มต้นด้วยตัวระบุจำนวนเต็ม ลองจินตนาการว่าเราต้องการ Long อีกอันสำหรับเอนทิตีใหม่ ลำดับในฐานข้อมูลไม่เหมาะสม ตารางเกี่ยวข้องกับการแบ่งส่วน - ปรากฎว่ามีข้อความ ID=1 ใน DB1 และ ID ข้อความ=1 ใน DB2 คุณไม่สามารถใส่ ID นี้ใน Elasticsearch หรือใน Hazelcast แต่สิ่งที่แย่ที่สุดคือถ้าคุณต้องการรวมข้อมูลจากสองฐานข้อมูลให้เป็นหนึ่งเดียว (เช่น ตัดสินใจว่าฐานข้อมูลเดียวเพียงพอสำหรับสมาชิกเหล่านี้) คุณสามารถเพิ่ม AtomicLong หลายรายการลงใน Hazelcast และเก็บตัวนับไว้ที่นั่น จากนั้นประสิทธิภาพของการรับ ID ใหม่จะเพิ่มขึ้นและรับบวกกับเวลาสำหรับการร้องขอไปยัง Hazelcast แต่ Hazelcast มีบางสิ่งที่เหมาะสมกว่า - FlakeIdGenerator เมื่อติดต่อลูกค้าแต่ละราย พวกเขาจะได้รับช่วงรหัส เช่น รหัสแรกตั้งแต่ 1 ถึง 10 รหัสที่สองตั้งแต่ 000 ถึง 10 เป็นต้น ขณะนี้ลูกค้าสามารถออกตัวระบุใหม่ได้ด้วยตัวเองจนกว่าช่วงที่ออกจะสิ้นสุดลง มันทำงานได้อย่างรวดเร็ว แต่เมื่อคุณรีสตาร์ทแอปพลิเคชัน (และไคลเอนต์ Hazelcast) ลำดับใหม่จะเริ่มต้นขึ้น - ดังนั้นการข้าม ฯลฯ นอกจากนี้ นักพัฒนาไม่เข้าใจจริงๆ ว่าทำไม ID จึงเป็นจำนวนเต็ม แต่ไม่สอดคล้องกันมาก เราชั่งน้ำหนักทุกอย่างและเปลี่ยนมาใช้ UUID
อย่างไรก็ตามสำหรับผู้ที่ต้องการเป็นเหมือน Twitter มีห้องสมุด Snowcast เช่นนี้ - นี่คือการใช้งาน Snowflake บน Hazelcast คุณสามารถดูได้ที่นี่:
แต่เรากลับไม่ได้รับมันอีกต่อไป
TransactionalMap.แทนที่
ความประหลาดใจอีกอย่าง: TransactionalMap.replace ไม่ทำงาน นี่คือการทดสอบ:
@Test
public void replaceInMap_putsAndGetsInsideTransaction() {
hazelcastInstance.executeTransaction(context -> {
HazelcastTransactionContextHolder.setContext(context);
try {
context.getMap("map").put("key", "oldValue");
context.getMap("map").replace("key", "oldValue", "newValue");
String value = (String) context.getMap("map").get("key");
assertEquals("newValue", value);
return null;
} finally {
HazelcastTransactionContextHolder.clearContext();
}
});
}
Expected : newValue
Actual : oldValueฉันต้องเขียนการแทนที่ของตัวเองโดยใช้ getForUpdate:
protected <K,V> boolean replaceInMap(String mapName, K key, V oldValue, V newValue) {
TransactionalTaskContext context = HazelcastTransactionContextHolder.getContext();
if (context != null) {
log.trace("[CACHE] Replacing value in a transactional map");
TransactionalMap<K, V> map = context.getMap(mapName);
V value = map.getForUpdate(key);
if (oldValue.equals(value)) {
map.put(key, newValue);
return true;
}
return false;
}
log.trace("[CACHE] Replacing value in a not transactional map");
IMap<K, V> map = hazelcastInstance.getMap(mapName);
return map.replace(key, oldValue, newValue);
}ทดสอบไม่เพียงแต่โครงสร้างข้อมูลปกติเท่านั้น แต่ยังทดสอบเวอร์ชันของธุรกรรมด้วย มันเกิดขึ้นที่ IMap ใช้งานได้ แต่ไม่มี TransactionalMap อีกต่อไป
ใส่ JAR ใหม่โดยไม่ต้องหยุดทำงาน
อันดับแรก เราตัดสินใจบันทึกออบเจ็กต์ของคลาสของเราใน Hazelcast ตัวอย่างเช่น เรามีคลาส Application เราต้องการบันทึกและอ่านมัน บันทึก:
IMap<UUID, Application> map = hazelcastInstance.getMap("application");
map.set(id, application);เราอ่าน:
IMap<UUID, Application> map = hazelcastInstance.getMap("application");
return map.get(id);ทุกอย่างทำงานได้ จากนั้นเราตัดสินใจสร้างดัชนีใน Hazelcast เพื่อค้นหาโดย:
map.addIndex("subscriberId", false);และเมื่อเขียนเอนทิตีใหม่ พวกเขาเริ่มได้รับ ClassNotFoundException Hazelcast พยายามเพิ่มลงในดัชนี แต่ไม่รู้อะไรเลยเกี่ยวกับคลาสของเรา และต้องการให้ส่ง JAR ที่มีคลาสนี้มาให้ เราทำอย่างนั้นทุกอย่างทำงานได้ แต่มีปัญหาใหม่ปรากฏขึ้น: จะอัปเดต JAR โดยไม่ต้องหยุดคลัสเตอร์โดยสมบูรณ์ได้อย่างไร Hazelcast ไม่รับ JAR ใหม่ในระหว่างการอัพเดตแบบโหนดต่อโหนด เมื่อมาถึงจุดนี้ เราตัดสินใจว่าเราจะอยู่ได้โดยไม่ต้องค้นหาดัชนี ท้ายที่สุดแล้ว หากคุณใช้ Hazelcast เป็นที่เก็บคีย์-ค่า ทุกอย่างจะได้ผลใช่ไหม ไม่เชิง. พฤติกรรมของ IMap และ TransactionalMap แตกต่างกันอีกครั้งที่นี่ โดยที่ Imap ไม่สนใจ TransactionalMap จะแสดงข้อผิดพลาด
ไอแมป. เราเขียนวัตถุ 5000 ชิ้นอ่านมัน ทุกอย่างเป็นไปตามที่คาดหวัง
@Test
void get5000() {
IMap<UUID, Application> map = hazelcastInstance.getMap("application");
UUID subscriberId = UUID.randomUUID();
for (int i = 0; i < 5000; i++) {
UUID id = UUID.randomUUID();
String title = RandomStringUtils.random(5);
Application application = new Application(id, title, subscriberId);
map.set(id, application);
Application retrieved = map.get(id);
assertEquals(id, retrieved.getId());
}
}แต่มันใช้งานไม่ได้กับธุรกรรม เราได้รับ ClassNotFoundException:
@Test
void get_transaction() {
IMap<UUID, Application> map = hazelcastInstance.getMap("application_t");
UUID subscriberId = UUID.randomUUID();
UUID id = UUID.randomUUID();
Application application = new Application(id, "qwer", subscriberId);
map.set(id, application);
Application retrievedOutside = map.get(id);
assertEquals(id, retrievedOutside.getId());
hazelcastInstance.executeTransaction(context -> {
HazelcastTransactionContextHolder.setContext(context);
try {
TransactionalMap<UUID, Application> transactionalMap = context.getMap("application_t");
Application retrievedInside = transactionalMap.get(id);
assertEquals(id, retrievedInside.getId());
return null;
} finally {
HazelcastTransactionContextHolder.clearContext();
}
});
}ใน 3.8 กลไกการปรับใช้คลาสผู้ใช้ปรากฏขึ้น คุณสามารถกำหนดหนึ่งโหนดหลักและอัพเดตไฟล์ JAR บนโหนดนั้นได้
ตอนนี้เราได้เปลี่ยนแนวทางของเราไปอย่างสิ้นเชิง: เราทำให้อนุกรมเป็น JSON และบันทึกไว้ใน Hazelcast Hazelcast ไม่จำเป็นต้องทราบโครงสร้างของคลาสของเรา และเราสามารถอัปเดตได้โดยไม่ต้องหยุดทำงาน การกำหนดเวอร์ชันของวัตถุโดเมนถูกควบคุมโดยแอปพลิเคชัน แอปพลิเคชันเวอร์ชันต่างๆ สามารถทำงานพร้อมกันได้ และสถานการณ์อาจเกิดขึ้นได้เมื่อแอปพลิเคชันใหม่เขียนออบเจ็กต์ด้วยฟิลด์ใหม่ แต่แอปพลิเคชันเก่ายังไม่ทราบเกี่ยวกับฟิลด์เหล่านี้ และในเวลาเดียวกัน แอปพลิเคชันใหม่จะอ่านออบเจ็กต์ที่เขียนโดยแอปพลิเคชันเก่าที่ไม่มีฟิลด์ใหม่ เราจัดการกับสถานการณ์ดังกล่าวภายในแอปพลิเคชัน แต่เพื่อความง่าย เราจะไม่เปลี่ยนแปลงหรือลบฟิลด์ เราจะขยายคลาสโดยการเพิ่มฟิลด์ใหม่เท่านั้น
เรารับประกันประสิทธิภาพสูงได้อย่างไร
เดินทางไปเฮเซลแคสต์สี่ครั้ง - ดี สองไปที่ฐานข้อมูล - แย่
การไปที่แคชเพื่อดูข้อมูลย่อมดีกว่าการไปที่ฐานข้อมูลเสมอ แต่คุณไม่ต้องการเก็บบันทึกที่ไม่ได้ใช้เช่นกัน เราปล่อยให้การตัดสินใจเกี่ยวกับสิ่งที่จะแคชไว้จนกว่าจะถึงขั้นตอนสุดท้ายของการพัฒนา เราจะเปิดการบันทึกการสืบค้นทั้งหมดใน PostgreSQL (log_min_duration_statement ถึง 0) และทำการทดสอบโหลดเป็นเวลา 20 นาที ยูทิลิตี้อย่าง pgFouine และ pgBadger สามารถสร้างรายงานการวิเคราะห์ได้โดยใช้บันทึกที่รวบรวมไว้ ในรายงาน เราจะมองหาข้อความค้นหาที่ช้าและบ่อยครั้งเป็นหลัก สำหรับการสืบค้นที่ช้า เราจะสร้างแผนการดำเนินการ (อธิบาย) และประเมินว่าการสืบค้นดังกล่าวสามารถเร่งให้เร็วขึ้นได้หรือไม่ คำขอข้อมูลอินพุตเดียวกันบ่อยครั้งจะพอดีกับแคช เราพยายามให้ข้อความค้นหาเป็นแบบ "คงที่" หนึ่งตารางต่อข้อความค้นหา
การแสวงหาผลประโยชน์
SV ซึ่งเป็นบริการออนไลน์ได้เริ่มดำเนินการในฤดูใบไม้ผลิปี 2017 และเป็นผลิตภัณฑ์แยกต่างหาก SV ได้รับการเผยแพร่ในเดือนพฤศจิกายน 2017 (ในขณะนั้นอยู่ในสถานะเวอร์ชันเบต้า)
ตลอดระยะเวลากว่าหนึ่งปีของการดำเนินงาน ไม่มีปัญหาร้ายแรงในการดำเนินงานบริการออนไลน์ของ CB เราติดตามบริการออนไลน์ผ่านทาง รวบรวมและปรับใช้จาก .
การแจกจ่ายเซิร์ฟเวอร์ SV มีให้เลือกในรูปแบบแพ็กเกจดั้งเดิม ได้แก่ RPM, DEB และ MSI นอกจากนี้ยังมี... Windows เรามีตัวติดตั้งแบบไฟล์ EXE ไฟล์เดียวที่ติดตั้งเซิร์ฟเวอร์ Hazelcast และ Elasticsearch บนเครื่องเดียว ในตอนแรกเราเรียกการติดตั้งนี้ว่าเวอร์ชัน "สาธิต" แต่ตอนนี้เห็นได้ชัดแล้วว่านี่เป็นตัวเลือกการใช้งานที่ได้รับความนิยมมากที่สุด
ที่มา: will.com
