

ฉันชื่อแอนตัน บาเดริน ฉันทำงานที่ศูนย์เทคโนโลยีขั้นสูงและดูแลระบบ หนึ่งเดือนที่ผ่านมา การประชุมองค์กรของเราสิ้นสุดลง โดยเราได้แบ่งปันประสบการณ์ที่สั่งสมมากับชุมชนไอทีในเมืองของเรา ฉันพูดคุยเกี่ยวกับการตรวจสอบแอปพลิเคชันเว็บ เนื้อหานี้มีไว้สำหรับผู้เยาว์หรือระดับกลางที่ไม่ได้สร้างกระบวนการนี้ตั้งแต่เริ่มต้น

รากฐานที่สำคัญของระบบการตรวจสอบคือการแก้ปัญหาทางธุรกิจ การติดตามเพื่อประโยชน์ในการติดตามนั้นไม่เป็นประโยชน์กับใครเลย ธุรกิจต้องการอะไร? เพื่อให้ทุกอย่างทำงานได้อย่างรวดเร็วและไม่มีข้อผิดพลาด ธุรกิจต้องการที่จะดำเนินการเชิงรุกเพื่อที่เราจะได้ระบุปัญหาในบริการและแก้ไขปัญหาโดยเร็วที่สุด อันที่จริงสิ่งเหล่านี้คือปัญหาที่ฉันแก้ไขตลอดปีที่แล้วในโครงการสำหรับลูกค้ารายหนึ่งของเรา
เกี่ยวกับโครงการ
โครงการนี้เป็นหนึ่งในโปรแกรมความภักดีที่ใหญ่ที่สุดในประเทศ เราช่วยให้เครือข่ายร้านค้าปลีกเพิ่มความถี่ในการขายผ่านเครื่องมือทางการตลาดต่างๆ เช่น บัตรโบนัส โดยรวมแล้วโปรเจ็กต์ประกอบด้วย 14 แอปพลิเคชันที่ทำงานบนเซิร์ฟเวอร์ XNUMX เครื่อง
ในระหว่างขั้นตอนการสัมภาษณ์ ฉันสังเกตเห็นซ้ำแล้วซ้ำอีกว่าผู้ดูแลระบบไม่ได้ติดตามตรวจสอบแอปพลิเคชันเว็บอย่างถูกต้องเสมอไป หลายคนยังคงมุ่งเน้นไปที่ตัวชี้วัดระบบปฏิบัติการและติดตามบริการในบางครั้ง
ในกรณีของฉัน ระบบการตรวจสอบของลูกค้าก่อนหน้านี้ใช้ Icinga มันไม่ได้แก้ปัญหาข้างต้นแต่อย่างใด บ่อยครั้งที่ลูกค้าแจ้งให้เราทราบเกี่ยวกับปัญหา และบ่อยครั้งที่เรามีข้อมูลไม่เพียงพอในการหาสาเหตุที่แท้จริง
นอกจากนี้ยังมีความเข้าใจที่ชัดเจนถึงความไร้ประโยชน์ของการพัฒนาต่อไป ฉันคิดว่าคนที่คุ้นเคยกับไอซิ่งก้าจะเข้าใจฉัน ดังนั้นเราจึงตัดสินใจออกแบบระบบตรวจสอบเว็บแอปพลิเคชันใหม่สำหรับโปรเจ็กต์นี้ใหม่ทั้งหมด
โพร
เราเลือก Prometheus ตามตัวชี้วัดหลักสามประการ:
- ตัวชี้วัดที่มีอยู่จำนวนมาก ในกรณีของเรามี 60 คน แน่นอนว่าเป็นที่น่าสังเกตว่าเราไม่ได้ใช้ส่วนใหญ่ (อาจประมาณ 95%) ในทางกลับกันทั้งหมดมีราคาค่อนข้างถูก สำหรับเรา นี่คือความสุดขั้วอีกประการหนึ่งเมื่อเทียบกับ Icinga ที่ใช้ก่อนหน้านี้ ในนั้น การเพิ่มตัวชี้วัดเป็นเรื่องที่ยุ่งยากเป็นพิเศษ: สิ่งที่มีอยู่มีราคาแพง (เพียงดูซอร์สโค้ดของปลั๊กอินใดก็ได้) ปลั๊กอินใด ๆ เป็นสคริปต์ใน Bash หรือ Python ซึ่งการเปิดตัวซึ่งมีราคาแพงในแง่ของทรัพยากรที่ใช้
- ระบบนี้ใช้ทรัพยากรจำนวนค่อนข้างน้อย RAM 600 MB, 15% ของหนึ่งคอร์และ IOPS สองสามโหลนั้นเพียงพอสำหรับการวัดทั้งหมดของเรา แน่นอนว่าคุณต้องเรียกใช้ตัวส่งออกตัวชี้วัด แต่พวกมันทั้งหมดเขียนด้วยภาษา Go และยังไม่หิวโหยมากนัก ฉันไม่คิดว่าในความเป็นจริงสมัยใหม่นี่เป็นปัญหา
- ให้ความสามารถในการโยกย้ายไปยัง Kubernetes เมื่อพิจารณาถึงแผนของลูกค้า ทางเลือกก็ชัดเจน
ELK
ก่อนหน้านี้ เราไม่ได้รวบรวมหรือประมวลผลบันทึก ข้อบกพร่องนั้นชัดเจนสำหรับทุกคน เราเลือก ELK เพราะเรามีประสบการณ์กับระบบนี้มาแล้ว เราจัดเก็บบันทึกแอปพลิเคชันไว้ที่นั่นเท่านั้น เกณฑ์การคัดเลือกหลักคือการค้นหาข้อความแบบเต็มและความเร็ว
คลิกเฮาส์
เริ่มแรกตัวเลือกตกอยู่ที่ InfluxDB เราตระหนักถึงความจำเป็นในการรวบรวมบันทึก Nginx สถิติจาก pg_stat_statements และจัดเก็บข้อมูลประวัติของ Prometheus เราไม่ชอบ Influx เพราะมันเริ่มใช้หน่วยความจำจำนวนมากเป็นระยะๆ และขัดข้อง นอกจากนี้ ฉันต้องการจัดกลุ่มการสืบค้นด้วย remote_addr แต่การจัดกลุ่มใน DBMS นี้ทำได้โดยใช้แท็กเท่านั้น แท็กมีราคาแพง (หน่วยความจำ) จำนวนแท็กถูกจำกัดตามเงื่อนไข
เราเริ่มการค้นหาของเราอีกครั้ง สิ่งที่จำเป็นคือฐานข้อมูลเชิงวิเคราะห์ที่ใช้ทรัพยากรน้อยที่สุด โดยควรมีการบีบอัดข้อมูลบนดิสก์
Clickhouse ตรงตามเกณฑ์เหล่านี้ทั้งหมด และเราไม่เคยเสียใจกับการเลือกของเรา เราไม่ได้เขียนข้อมูลจำนวนพิเศษลงไป (จำนวนการแทรกเพียงประมาณห้าพันต่อนาทีเท่านั้น)
NewRelic
NewRelic อยู่กับเราในอดีตเพราะเป็นทางเลือกของลูกค้า เราใช้เป็น APM
Zabbix
เราใช้ Zabbix เพื่อตรวจสอบ Black Box ของ API ต่างๆ โดยเฉพาะ
การกำหนดแนวทางการติดตามผล
เราต้องการแยกย่อยงานและด้วยเหตุนี้จึงจัดระบบแนวทางการติดตาม
เพื่อทำเช่นนี้ ฉันแบ่งระบบของเราออกเป็นระดับต่อไปนี้:
- ฮาร์ดแวร์และ VMS;
- ระบบปฏิบัติการ;
- บริการระบบ ซอฟต์แวร์สแต็ก
- แอปพลิเคชัน;
- ตรรกะทางธุรกิจ
เหตุใดวิธีนี้จึงสะดวก:
- เรารู้ว่าใครเป็นผู้รับผิดชอบงานแต่ละระดับ และด้วยเหตุนี้ เราสามารถส่งการแจ้งเตือนได้
- เราสามารถใช้โครงสร้างนี้เมื่อระงับการแจ้งเตือน - การส่งการแจ้งเตือนเกี่ยวกับความไม่พร้อมใช้งานของฐานข้อมูลจะแปลกเมื่อเครื่องเสมือนโดยรวมไม่พร้อมใช้งาน
เนื่องจากงานของเราคือการระบุการละเมิดในการทำงานของระบบ เราจึงต้องเน้นชุดตัวชี้วัดที่ควรค่าแก่การใส่ใจในแต่ละระดับเมื่อเขียนกฎการแจ้งเตือนในแต่ละระดับ ต่อไป มาดูระดับ “VMS”, “ระบบปฏิบัติการ” และ “บริการระบบ, ซอฟต์แวร์สแต็ก”
เครื่องเสมือน
โฮสติ้ง ระบบจะจัดสรรทรัพยากร CPU, ดิสก์, หน่วยความจำ และเครือข่ายให้กับเรา เรามีปัญหาเกี่ยวกับสองอย่างแรก ดังนั้นนี่คือตัวชี้วัดต่างๆ:
เวลาที่ถูกขโมย CPU - เมื่อคุณซื้อเครื่องเสมือนบน Amazon (เช่น t2.micro) คุณควรเข้าใจว่าคุณไม่ได้จัดสรรแกนประมวลผลทั้งหมด แต่เป็นเพียงโควต้าของเวลาเท่านั้น และเมื่อคุณหมดพลังงาน โปรเซสเซอร์จะถูกพรากไปจากคุณ
ตัวชี้วัดนี้ช่วยให้คุณติดตามปัญหาดังกล่าวและตัดสินใจได้ ตัวอย่างเช่น คุณควรอัปเกรดเป็นแพ็กเกจที่สูงกว่า หรือควรแยกการประมวลผลงานเบื้องหลังและการร้องขอ API ออกเป็นส่วนๆ ที่แตกต่างกันหรือไม่ เซิร์ฟเวอร์.
IOPS + CPU iowait time - ด้วยเหตุผลบางประการ คลาวด์โฮสติ้งจำนวนมากทำบาปโดยไม่ได้ให้ IOPS เพียงพอ ยิ่งไปกว่านั้น กำหนดการที่มี IOPS ต่ำก็ไม่ใช่ข้อโต้แย้งสำหรับพวกเขา ดังนั้นจึงคุ้มค่าที่จะสะสม CPU iowait ด้วยกราฟคู่นี้ - ด้วย IOPS ต่ำและการรอ I/O สูง - คุณสามารถพูดคุยกับโฮสติ้งและแก้ไขปัญหาได้แล้ว
ระบบปฏิบัติการ
ตัวชี้วัดระบบปฏิบัติการ:
- จำนวนหน่วยความจำที่มีหน่วยเป็น %;
- กิจกรรมการใช้งานสลับ: vmstat swapin, swapout;
- จำนวนไอโหนดที่มีอยู่และพื้นที่ว่างบนระบบไฟล์เป็น %
- โหลดเฉลี่ย
- จำนวนการเชื่อมต่อในสถานะ tw;
- Conntrack ความแน่นของตาราง;
- สามารถตรวจสอบคุณภาพของเครือข่ายได้โดยใช้ยูทิลิตี้ ss ซึ่งเป็นแพ็คเกจ iproute2 - รับตัวบ่งชี้การเชื่อมต่อ RTT จากเอาต์พุตและจัดกลุ่มตามพอร์ตปลายทาง
นอกจากนี้ในระดับระบบปฏิบัติการ เราก็มีเอนทิตีเช่นกระบวนการด้วย สิ่งสำคัญคือต้องระบุชุดของกระบวนการที่มีบทบาทสำคัญในการดำเนินงานในระบบ ตัวอย่างเช่น หากคุณมี pgpool หลายตัว คุณจะต้องรวบรวมข้อมูลสำหรับแต่ละ pgpool
ชุดเมตริกมีดังนี้:
- ซีพียู;
- หน่วยความจำมีถิ่นที่อยู่เป็นหลัก
- IO - โดยเฉพาะอย่างยิ่งใน IOPS;
- FileFd - เปิดและ จำกัด ;
- ความล้มเหลวของหน้าที่สำคัญ - ด้วยวิธีนี้คุณสามารถเข้าใจว่ากระบวนการใดกำลังถูกสลับ
เราปรับใช้การตรวจสอบทั้งหมดใน Docker และเราใช้ Advisor เพื่อรวบรวมข้อมูลตัวชี้วัด บนเครื่องอื่นๆ เราใช้ process-exporter
บริการระบบซอฟต์แวร์สแต็ค
แต่ละแอปพลิเคชันมีลักษณะเฉพาะของตัวเอง และเป็นการยากที่จะแยกแยะชุดเมตริกที่เฉพาะเจาะจงออก
ชุดสากลคือ:
- อัตราคำขอ;
- จำนวนข้อผิดพลาด
- เวลาแฝง;
- ความอิ่มตัว
ตัวอย่างที่โดดเด่นที่สุดของการตรวจสอบในระดับนี้คือ Nginx และ PostgreSQL
บริการที่มีการโหลดมากที่สุดในระบบของเราคือฐานข้อมูล ในอดีต เรามักประสบปัญหาในการพิจารณาว่าฐานข้อมูลกำลังทำอะไรอยู่
เราเห็นว่ามีการโหลดบนดิสก์เป็นจำนวนมาก แต่บันทึกที่ช้าไม่ได้แสดงอะไรเลยจริงๆ เราแก้ไขปัญหานี้โดยใช้ pg_stat_statements ซึ่งเป็นมุมมองที่รวบรวมสถิติการสืบค้น
นั่นคือทั้งหมดที่ผู้ดูแลระบบต้องการ
เราสร้างกราฟของกิจกรรมคำขออ่านและเขียน:
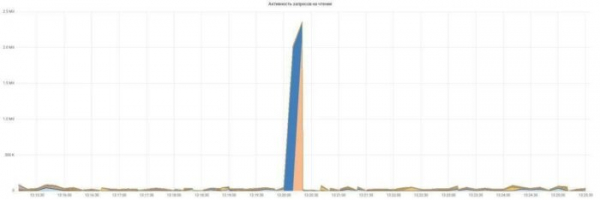
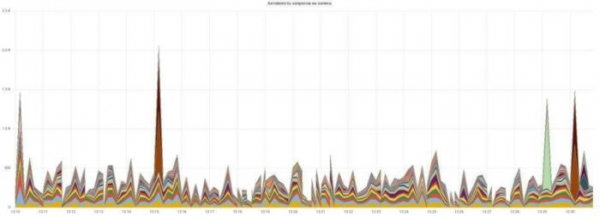
ทุกอย่างเรียบง่ายและชัดเจน แต่ละคำขอมีสีของตัวเอง
ตัวอย่างที่ชัดเจนไม่แพ้กันคือบันทึกของ Nginx ไม่น่าแปลกใจเลยที่มีเพียงไม่กี่คนที่แยกวิเคราะห์หรือพูดถึงพวกเขาในรายการสิ่งที่ต้องมี รูปแบบมาตรฐานไม่มีข้อมูลมากนักและจำเป็นต้องขยาย
โดยส่วนตัวแล้วฉันได้เพิ่ม request_time, upstream_response_time, body_bytes_sent, request_length, request_id เราวางแผนเวลาตอบสนองและจำนวนข้อผิดพลาด:
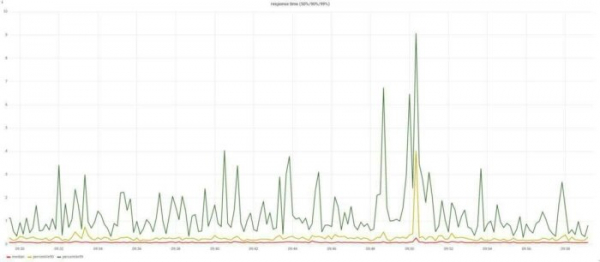
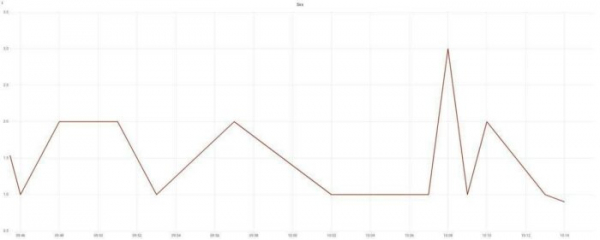
เราสร้างกราฟเวลาตอบสนองและจำนวนข้อผิดพลาด จดจำ? ฉันพูดคุยเกี่ยวกับวัตถุประสงค์ทางธุรกิจหรือไม่? ได้อย่างรวดเร็วและไม่มีข้อผิดพลาด? เราได้กล่าวถึงปัญหาเหล่านี้ด้วยแผนภูมิสองแผนภูมิแล้ว และคุณสามารถเรียกผู้ดูแลระบบที่ปฏิบัติหน้าที่มาใช้ได้แล้ว
แต่ปัญหาอีกประการหนึ่งยังคงอยู่ - เพื่อให้แน่ใจว่าสามารถขจัดสาเหตุของเหตุการณ์ได้อย่างรวดเร็ว
การแก้ไขเหตุการณ์
กระบวนการทั้งหมดตั้งแต่การระบุจนถึงการแก้ปัญหาสามารถแบ่งออกเป็นหลายขั้นตอน:
- การระบุปัญหา
- แจ้งให้ผู้บริหารปฏิบัติหน้าที่ทราบ
- การตอบสนองต่อเหตุการณ์
- การกำจัดสาเหตุ
เป็นสิ่งสำคัญที่เราต้องทำสิ่งนี้ให้เร็วที่สุด และหากเราไม่สามารถมีเวลาได้มากนักในขั้นตอนของการระบุปัญหาและส่งการแจ้งเตือน - ไม่ว่าในกรณีใดจะใช้เวลาสองนาทีกับพวกเขาจากนั้นอันที่ตามมานั้นเป็นเพียงการไม่ได้ไถพรวนเพื่อการปรับปรุง
ลองจินตนาการว่าโทรศัพท์ของเจ้าหน้าที่ปฏิบัติหน้าที่ดังขึ้น เขาจะทำอย่างไร? มองหาคำตอบสำหรับคำถาม - อะไรแตก แตกตรงไหน มีปฏิกิริยาอย่างไร? ต่อไปนี้คือวิธีที่เราตอบคำถามเหล่านี้:
เราเพียงแต่รวมข้อมูลทั้งหมดนี้ไว้ในข้อความแจ้งเตือน โดยให้ลิงก์ไปยังหน้าวิกิที่อธิบายวิธีตอบสนองต่อปัญหานี้ วิธีแก้ไข และยกระดับปัญหา
ฉันยังไม่ได้พูดอะไรเกี่ยวกับเลเยอร์แอปพลิเคชันและตรรกะทางธุรกิจ ขออภัย แอปพลิเคชันของเรายังไม่ได้ใช้การรวบรวมเมตริก แหล่งข้อมูลจากระดับเหล่านี้แหล่งเดียวคือบันทึก
สองสามจุด
ขั้นแรก ให้เขียนบันทึกที่มีโครงสร้าง ไม่จำเป็นต้องใส่บริบทในข้อความ ทำให้ยากต่อการจัดกลุ่มและวิเคราะห์ Logstash ใช้เวลานานในการทำให้ทั้งหมดนี้เป็นมาตรฐาน
ประการที่สอง ใช้ระดับความรุนแรงอย่างถูกต้อง แต่ละภาษามีมาตรฐานของตัวเอง ส่วนตัวผมแบ่งได้ XNUMX ระดับ คือ
- ไม่มีข้อผิดพลาด
- ข้อผิดพลาดฝั่งไคลเอ็นต์
- ความผิดพลาดอยู่ฝั่งเรา เราไม่เสียเงิน เราไม่แบกรับความเสี่ยง
- ความผิดพลาดอยู่ฝั่งเรา เราเสียเงิน
ผมขอสรุป. คุณต้องพยายามสร้างการตรวจสอบตามตรรกะทางธุรกิจ พยายามตรวจสอบแอปพลิเคชันและดำเนินการโดยใช้หน่วยวัด เช่น จำนวนยอดขาย จำนวนการลงทะเบียนผู้ใช้ใหม่ จำนวนผู้ใช้ที่ใช้งานอยู่ในปัจจุบัน และอื่นๆ
หากธุรกิจทั้งหมดของคุณเป็นเพียงปุ่มเดียวในเบราว์เซอร์ คุณจะต้องตรวจสอบว่ามีการคลิกและทำงานอย่างถูกต้องหรือไม่ ที่เหลือทั้งหมดไม่สำคัญ
หากคุณไม่มีสิ่งนี้ คุณสามารถลองติดตามได้ในบันทึกของแอปพลิเคชัน บันทึก Nginx และอื่นๆ เหมือนที่เราทำ คุณควรอยู่ใกล้กับใบสมัครให้มากที่สุด
แน่นอนว่าตัวชี้วัดระบบปฏิบัติการมีความสำคัญ แต่ธุรกิจไม่สนใจตัวชี้วัดเหล่านี้ เราจะไม่จ่ายเงินสำหรับตัวชี้วัดเหล่านั้น
ที่มา: will.com
