


สวัสดีฮับ! ฉันชื่อ Artem Karamyshev หัวหน้าทีมบริหารระบบ - เรามีการเปิดตัวผลิตภัณฑ์ใหม่มากมายในปีที่ผ่านมา เราต้องการให้แน่ใจว่าบริการ API สามารถปรับขนาดได้ง่าย ทนทานต่อข้อผิดพลาด และพร้อมสำหรับการเติบโตอย่างรวดเร็วของปริมาณผู้ใช้ แพลตฟอร์มของเราใช้งานบน OpenStack และฉันต้องการแจ้งให้คุณทราบว่าปัญหาความทนทานต่อข้อผิดพลาดของส่วนประกอบใดบ้างที่เราต้องแก้ไขเพื่อให้ได้ระบบที่ทนทานต่อข้อผิดพลาด ฉันคิดว่านี่จะน่าสนใจสำหรับผู้ที่พัฒนาผลิตภัณฑ์บน OpenStack ด้วย
ความทนทานต่อข้อผิดพลาดโดยรวมของแพลตฟอร์มประกอบด้วยความยืดหยุ่นของส่วนประกอบต่างๆ ดังนั้นเราจะค่อยๆ ผ่านทุกระดับที่เราระบุความเสี่ยงและปิดมัน
เวอร์ชันวิดีโอของเรื่องราวนี้ แหล่งที่มาหลักคือรายงานในการประชุม Uptime วันที่ 4 ซึ่งจัดโดย คุณสามารถดูได้ .
ความยืดหยุ่นของสถาปัตยกรรมทางกายภาพ
ขณะนี้ส่วนสาธารณะของระบบคลาวด์ MCS ตั้งอยู่ในศูนย์ข้อมูลระดับ Tier III สองแห่ง โดยระหว่างศูนย์เหล่านั้นจะมีไฟเบอร์สีเข้มของตัวเอง ซึ่งสงวนไว้ในระดับกายภาพตามเส้นทางที่ต่างกัน โดยมีปริมาณงานอยู่ที่ 200 Gbit/s ระดับ III มอบระดับความทนทานต่อข้อผิดพลาดที่จำเป็นสำหรับโครงสร้างพื้นฐานทางกายภาพ
เส้นใยสีเข้มถูกสงวนไว้ทั้งในระดับกายภาพและระดับตรรกะ กระบวนการจองช่องทางเป็นแบบวนซ้ำ ปัญหาเกิดขึ้น และเรากำลังปรับปรุงการสื่อสารระหว่างศูนย์ข้อมูลอย่างต่อเนื่อง
ตัวอย่างเช่น ไม่นานมานี้ ขณะทำงานในบ่อน้ำใกล้กับศูนย์ข้อมูลแห่งหนึ่ง เครื่องขุดเจาะท่อหนึ่งพัง และภายในท่อนี้มีทั้งสายเคเบิลออปติคัลหลักและสายเคเบิลสำรอง ช่องทางการสื่อสารที่ทนต่อข้อผิดพลาดของเรากับศูนย์ข้อมูลกลายเป็นจุดอ่อนในจุดหนึ่งเช่นกัน ดังนั้นเราจึงสูญเสียโครงสร้างพื้นฐานบางส่วนไป เราได้ข้อสรุปและดำเนินการหลายประการ รวมถึงการติดตั้งเลนส์เพิ่มเติมในบ่อน้ำที่อยู่ติดกัน
ในศูนย์ข้อมูล มีผู้ให้บริการด้านการสื่อสารอยู่หลายจุดซึ่งเราถ่ายทอดคำนำหน้าผ่าน BGP สำหรับแต่ละทิศทางของเครือข่าย จะมีการเลือกตัววัดที่ดีที่สุด ซึ่งช่วยให้ไคลเอนต์ที่แตกต่างกันได้รับคุณภาพการเชื่อมต่อที่ดีที่สุด หากการสื่อสารผ่านผู้ให้บริการรายหนึ่งล่ม เราจะสร้างเส้นทางของเราใหม่ผ่านผู้ให้บริการที่มีอยู่
หากผู้ให้บริการล้มเหลว เราจะสลับไปยังผู้ให้บริการรายถัดไปโดยอัตโนมัติ ในกรณีที่ศูนย์ข้อมูลแห่งใดแห่งหนึ่งขัดข้อง เรามีสำเนาบริการของเราในศูนย์ข้อมูลแห่งที่สองซึ่งจะรับภาระงานทั้งหมด
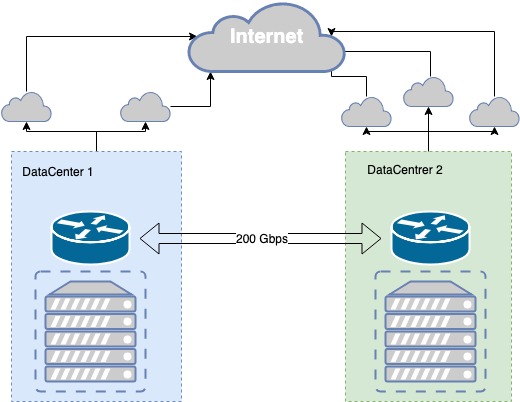
ความยืดหยุ่นของโครงสร้างพื้นฐานทางกายภาพ
สิ่งที่เราใช้สำหรับความทนทานต่อข้อผิดพลาดระดับแอปพลิเคชัน
บริการของเราสร้างขึ้นจากส่วนประกอบโอเพ่นซอร์สจำนวนหนึ่ง
ExaBGP เป็นบริการที่ใช้ฟังก์ชันจำนวนหนึ่งโดยใช้โปรโตคอลการกำหนดเส้นทางแบบไดนามิกที่ใช้ BGP เราใช้ข้อมูลนี้อย่างจริงจังเพื่อโฆษณาที่อยู่ IP ที่อนุญาตพิเศษของเราซึ่งผู้ใช้เข้าถึง API
HAProxy เป็นตัวจัดสรรภาระงานสูงที่ช่วยให้คุณสามารถกำหนดค่ากฎการปรับสมดุลการรับส่งข้อมูลที่ยืดหยุ่นมากในระดับต่างๆ ของโมเดล OSI เราใช้มันเพื่อสร้างสมดุลต่อหน้าบริการทั้งหมด: ฐานข้อมูล นายหน้าข้อความ บริการ API บริการบนเว็บ โครงการภายในของเรา - ทุกอย่างอยู่เบื้องหลัง HAProxy
แอปพลิเคชันเอพีไอ — เว็บแอปพลิเคชันที่เขียนด้วยภาษาไพธอน ซึ่งผู้ใช้จัดการโครงสร้างพื้นฐานและบริการของเขา
ใบสมัครคนงาน (ต่อไปนี้จะเรียกว่าผู้ปฏิบัติงาน) - ในบริการ OpenStack นี่คือเดมอนโครงสร้างพื้นฐานที่ช่วยให้คุณสามารถถ่ายทอดคำสั่ง API ไปยังโครงสร้างพื้นฐานได้ ตัวอย่างเช่น การสร้างดิสก์เกิดขึ้นในผู้ปฏิบัติงาน และคำขอการสร้างเกิดขึ้นใน API ของแอปพลิเคชัน
สถาปัตยกรรมแอปพลิเคชัน OpenStack มาตรฐาน
บริการส่วนใหญ่ที่พัฒนาขึ้นสำหรับ OpenStack พยายามใช้กระบวนทัศน์เดียว โดยทั่วไปบริการจะประกอบด้วย 2 ส่วน ได้แก่ API และผู้ปฏิบัติงาน (ตัวดำเนินการแบ็กเอนด์) ตามกฎแล้ว API คือแอปพลิเคชัน WSGI ใน python ซึ่งเปิดตัวเป็นกระบวนการอิสระ (daemon) หรือใช้เว็บเซิร์ฟเวอร์ Nginx หรือ Apache สำเร็จรูป API ประมวลผลคำขอของผู้ใช้และส่งคำแนะนำเพิ่มเติมไปยังแอปพลิเคชันของผู้ปฏิบัติงานเพื่อดำเนินการ การถ่ายโอนเกิดขึ้นโดยใช้นายหน้าข้อความ ซึ่งโดยทั่วไปคือ RabbitMQ ส่วนตัวอื่น ๆ ได้รับการสนับสนุนไม่ดี เมื่อข้อความส่งถึงนายหน้า พนักงานจะประมวลผลข้อความเหล่านั้น และจะตอบกลับหากจำเป็น
กระบวนทัศน์นี้เกี่ยวข้องกับจุดความล้มเหลวทั่วไปที่แยกได้: RabbitMQ และฐานข้อมูล แต่ RabbitMQ ถูกแยกออกมาภายในบริการเดียว และตามทฤษฎีแล้ว สามารถแยกเป็นรายบุคคลสำหรับแต่ละบริการได้ ดังนั้นที่ MCS เราจึงแยกบริการเหล่านี้ให้มากที่สุดเท่าที่จะเป็นไปได้ เราจึงสร้างฐานข้อมูล RabbitMQ แยกต่างหากสำหรับแต่ละโครงการ แนวทางนี้เป็นสิ่งที่ดีเพราะในกรณีที่เกิดอุบัติเหตุ ณ จุดเสี่ยงบางจุด บริการไม่ได้พังทั้งหมดแต่เพียงบางส่วนเท่านั้น
จำนวนแอปพลิเคชันของผู้ปฏิบัติงานนั้นไม่จำกัด ดังนั้น API จึงสามารถปรับขนาดตามแนวนอนด้านหลังบาลานเซอร์ได้อย่างง่ายดาย เพื่อเพิ่มประสิทธิภาพและความทนทานต่อข้อผิดพลาด
บริการบางอย่างจำเป็นต้องมีการประสานงานภายในบริการเมื่อมีการดำเนินการตามลำดับที่ซับซ้อนเกิดขึ้นระหว่าง API และผู้ปฏิบัติงาน ในกรณีนี้ มีการใช้ศูนย์ประสานงานแห่งเดียว ซึ่งเป็นระบบคลัสเตอร์ เช่น Redis, Memcache ฯลฯ ซึ่งช่วยให้พนักงานคนหนึ่งสามารถบอกอีกคนหนึ่งได้ว่างานนี้ได้รับมอบหมายให้เขา (“โปรดอย่ารับไป”) เราใช้ ฯลฯ ตามกฎแล้ว พนักงานจะสื่อสารกับฐานข้อมูล เขียนและอ่านข้อมูลจากที่นั่น เราใช้ mariadb เป็นฐานข้อมูลซึ่งอยู่ในคลัสเตอร์มัลติมาสเตอร์
บริการเดี่ยวแบบคลาสสิกนี้ได้รับการจัดระเบียบในลักษณะที่เป็นที่ยอมรับโดยทั่วไปสำหรับ OpenStack ถือได้ว่าเป็นระบบปิดซึ่งวิธีการปรับขนาดและความทนทานต่อข้อผิดพลาดค่อนข้างชัดเจน ตัวอย่างเช่น สำหรับความทนทานต่อข้อบกพร่องของ API การวางบาลานเซอร์ไว้ข้างหน้าก็เพียงพอแล้ว การปรับขนาดพนักงานทำได้โดยการเพิ่มจำนวน
จุดอ่อนในโครงการทั้งหมดคือ RabbitMQ และ MariaDB สถาปัตยกรรมของพวกเขาสมควรได้รับบทความแยกต่างหาก ในบทความนี้ ฉันต้องการเน้นที่ความทนทานต่อข้อบกพร่องของ API
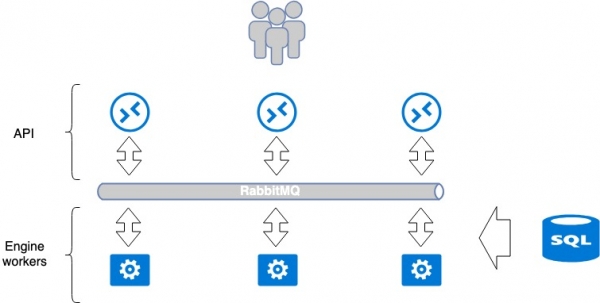
สถาปัตยกรรมแอปพลิเคชัน OpenStack การปรับสมดุลและความทนทานต่อข้อผิดพลาดของแพลตฟอร์มคลาวด์
การทำให้ HAProxy balancer ทนทานต่อข้อผิดพลาดโดยใช้ ExaBGP
เพื่อให้ API ของเราสามารถปรับขนาดได้ รวดเร็ว และทนทานต่อข้อผิดพลาด เราได้วางโหลดบาลานเซอร์ไว้ข้างหน้า เราเลือก HAProxy ในความคิดของฉัน มันมีคุณสมบัติที่จำเป็นทั้งหมดสำหรับงานของเรา: การปรับสมดุลในระดับ OSI หลายระดับ, อินเทอร์เฟซการจัดการ, ความยืดหยุ่นและความสามารถในการปรับขนาด, วิธีการปรับสมดุลจำนวนมาก, การรองรับตารางเซสชัน
ปัญหาแรกที่จำเป็นต้องแก้ไขคือความทนทานต่อความเสียหายของตัวปรับสมดุลเอง เพียงแค่ติดตั้งบาลานเซอร์ก็ทำให้เกิดจุดล้มเหลวเช่นกัน: บาลานเซอร์หยุดทำงานและบริการหยุดทำงาน เพื่อป้องกันไม่ให้สิ่งนี้เกิดขึ้น เราใช้ HAProxy ร่วมกับ ExaBGP
ExaBGP ช่วยให้คุณใช้กลไกในการตรวจสอบสถานะของบริการได้ เราใช้กลไกนี้เพื่อตรวจสอบการทำงานของ HAProxy และในกรณีที่เกิดปัญหา ให้ปิดใช้งานบริการ HAProxy จาก BGP
รูปแบบ ExaBGP+HAProxy
- เราติดตั้งซอฟต์แวร์ที่จำเป็น ExaBGP และ HAProxy บนเซิร์ฟเวอร์สามเครื่อง
- เราสร้างอินเทอร์เฟซแบบย้อนกลับบนแต่ละเซิร์ฟเวอร์
- บนเซิร์ฟเวอร์ทั้งสามเครื่อง เราได้กำหนดที่อยู่ IP สีขาวเดียวกันให้กับอินเทอร์เฟซนี้
- ที่อยู่ IP สีขาวถูกโฆษณาบนอินเทอร์เน็ตผ่าน ExaBGP
การยอมรับข้อผิดพลาดทำได้โดยการโฆษณาที่อยู่ IP เดียวกันจากเซิร์ฟเวอร์ทั้งสามเครื่อง จากมุมมองของเครือข่าย ที่อยู่เดียวกันสามารถเข้าถึงได้จากฮ็อปถัดไปที่แตกต่างกันสามแห่ง เราเตอร์มองเห็นเส้นทางที่เหมือนกันสามเส้นทาง เลือกลำดับความสำคัญสูงสุดตามตัวชี้วัดของตัวเอง (โดยปกติจะเป็นตัวเลือกเดียวกัน) และการรับส่งข้อมูลจะถูกส่งไปยังเซิร์ฟเวอร์ตัวใดตัวหนึ่งเท่านั้น
ในกรณีที่เกิดปัญหากับการทำงานของ HAProxy หรือเซิร์ฟเวอร์ล้มเหลว ExaBGP จะหยุดประกาศเส้นทาง และการรับส่งข้อมูลจะสลับไปยังเซิร์ฟเวอร์อื่นได้อย่างราบรื่น
ดังนั้นเราจึงสามารถทนต่อความผิดพลาดของบาลานเซอร์ได้
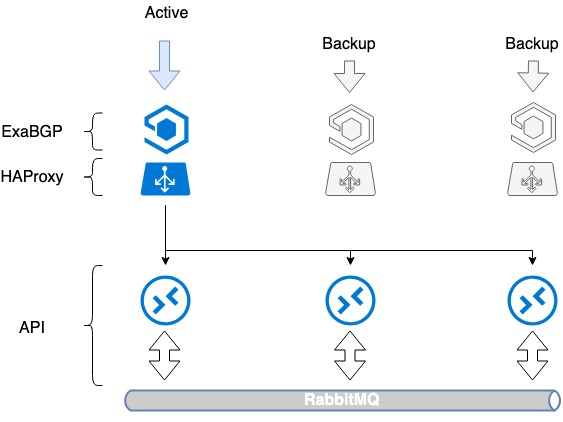
ความทนทานต่อข้อผิดพลาดของบาลานเซอร์ HAProxy
รูปแบบกลายเป็นความไม่สมบูรณ์แบบ: เราเรียนรู้วิธีจอง HAProxy แต่ไม่ได้เรียนรู้วิธีกระจายโหลดภายในบริการ ดังนั้นเราจึงขยายแผนนี้เล็กน้อย: เราก้าวไปสู่การสร้างสมดุลระหว่างที่อยู่ IP สีขาวหลายรายการ
การปรับสมดุลตาม DNS บวก BGP
ปัญหาของการทำโหลดบาลานซ์สำหรับ HAProxy ของเรายังคงไม่ได้รับการแก้ไข อย่างไรก็ตาม มันสามารถแก้ไขได้ค่อนข้างง่ายเหมือนที่เราทำที่นี่
เพื่อสร้างสมดุลให้กับเซิร์ฟเวอร์ 3 เครื่อง คุณจะต้องมีที่อยู่ IP สีขาว XNUMX รายการและ DNS เก่าที่ดี ที่อยู่แต่ละรายการเหล่านี้ถูกกำหนดบนอินเทอร์เฟซแบบวนกลับของ HAProxy แต่ละรายการและโฆษณาทางอินเทอร์เน็ต
ใน OpenStack ในการจัดการทรัพยากร จะใช้ไดเร็กทอรีบริการซึ่งระบุ API จุดสิ้นสุดของบริการเฉพาะ ในไดเร็กทอรีนี้ เราจดทะเบียนชื่อโดเมน - public.infra.mail.ru ซึ่งแก้ไขผ่าน DNS ด้วยที่อยู่ IP ที่แตกต่างกันสามแห่ง เป็นผลให้เราได้รับการกระจายโหลดระหว่างสามที่อยู่ผ่านทาง DNS
แต่เนื่องจากเมื่อประกาศที่อยู่ IP สีขาว เราไม่ได้ควบคุมลำดับความสำคัญในการเลือกเซิร์ฟเวอร์ นี่จึงยังไม่สมดุล โดยทั่วไปแล้ว จะมีการเลือกเซิร์ฟเวอร์เพียงเซิร์ฟเวอร์เดียวโดยพิจารณาจากความอาวุโสของที่อยู่ IP และอีกสองเซิร์ฟเวอร์จะไม่ทำงานเนื่องจากไม่มีการระบุตัววัดใน BGP
เราเริ่มส่งเส้นทางผ่าน ExaBGP ด้วยตัวชี้วัดที่แตกต่างกัน ตัวปรับสมดุลแต่ละตัวโฆษณาที่อยู่ IP สีขาวทั้งสามรายการ แต่หนึ่งในนั้นซึ่งเป็นที่อยู่หลักสำหรับตัวปรับสมดุลนี้ ได้รับการโฆษณาโดยใช้ตัวชี้วัดขั้นต่ำ ดังนั้นในขณะที่บาลานเซอร์ทั้งสามกำลังทำงานอยู่ การเรียกไปยังที่อยู่ IP แรกจะไปที่บาลานเซอร์ตัวแรก การเรียกไปยังตัวที่สองถึงตัวที่สอง และการโทรไปยังตัวที่สามถึงตัวที่สาม
จะเกิดอะไรขึ้นเมื่อบาลานเซอร์ตัวใดตัวหนึ่งล้มลง? หากบาลานเซอร์ตัวใดล้มเหลว ที่อยู่หลักจะยังคงโฆษณาจากอีกสองตัวที่เหลือ และการรับส่งข้อมูลจะถูกกระจายระหว่างกัน ดังนั้นเราจึงให้ที่อยู่ IP แก่ผู้ใช้หลายรายการพร้อมกันผ่าน DNS ด้วยการปรับสมดุลด้วย DNS และตัววัดที่แตกต่างกัน เราจึงได้รับการกระจายโหลดที่สม่ำเสมอทั่วทั้งบาลานเซอร์ทั้งสามตัว และในขณะเดียวกัน เราก็ไม่สูญเสียความอดทนต่อความผิดพลาด
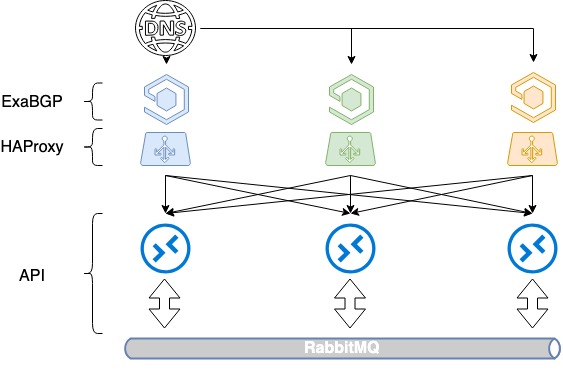
ปรับสมดุล HAProxy ตาม DNS + BGP
ปฏิสัมพันธ์ระหว่าง ExaBGP และ HAProxy
ดังนั้นเราจึงใช้การทนทานต่อข้อผิดพลาดในกรณีที่เซิร์ฟเวอร์ออก โดยอิงจากการหยุดการประกาศเส้นทาง แต่ HAProxy ยังสามารถปิดระบบได้ด้วยเหตุผลอื่นนอกเหนือจากความล้มเหลวของเซิร์ฟเวอร์: ข้อผิดพลาดในการดูแลระบบ ความล้มเหลวภายในบริการ เราต้องการเอาบาลานเซอร์ที่เสียหายออกจากใต้โหลดในกรณีเหล่านี้ และเราต้องการกลไกอื่น
ดังนั้น เพื่อขยายแผนก่อนหน้านี้ เราจึงนำฮาร์ทบีทระหว่าง ExaBGP และ HAProxy มาใช้ นี่คือการใช้งานซอฟต์แวร์ของการโต้ตอบระหว่าง ExaBGP และ HAProxy เมื่อ ExaBGP ใช้สคริปต์ที่กำหนดเองเพื่อตรวจสอบสถานะของแอปพลิเคชัน
ในการดำเนินการนี้ คุณต้องกำหนดค่าตัวตรวจสอบความสมบูรณ์ในการกำหนดค่า ExaBGP ซึ่งสามารถตรวจสอบสถานะของ HAProxy ได้ ในกรณีของเรา เราได้กำหนดค่าแบ็กเอนด์สถานภาพใน HAProxy และจากฝั่ง ExaBGP เราจะตรวจสอบด้วยคำขอ GET แบบง่ายๆ หากการประกาศหยุดเกิดขึ้น แสดงว่า HAProxy น่าจะใช้งานไม่ได้และไม่จำเป็นต้องโฆษณา
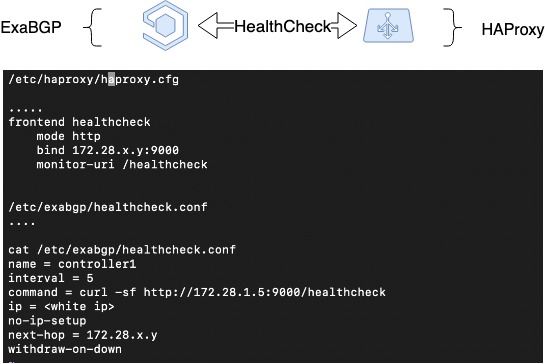
ตรวจสุขภาพ HAProxy
HAProxy Peers: การซิงโครไนซ์เซสชัน
สิ่งต่อไปที่ต้องทำคือการซิงโครไนซ์เซสชัน เมื่อทำงานผ่านบาลานเซอร์แบบกระจาย เป็นการยากที่จะจัดระเบียบการจัดเก็บข้อมูลเกี่ยวกับเซสชันของลูกค้า แต่ HAProxy เป็นหนึ่งในบาลานเซอร์ไม่กี่ตัวที่สามารถทำได้เนื่องจากฟังก์ชันการทำงานของเพียร์ส - ความสามารถในการถ่ายโอนตารางเซสชันระหว่างกระบวนการ HAProxy ที่แตกต่างกัน
มีวิธีการปรับสมดุลที่แตกต่างกัน: วิธีง่ายๆ เช่น และขยายออกไปเมื่อจำเซสชันของลูกค้าได้ และทุกครั้งที่เขาลงเอยที่เซิร์ฟเวอร์เดิมเหมือนเมื่อก่อน เราต้องการใช้ตัวเลือกที่สอง
HAProxy ใช้ Stick-Table เพื่อบันทึกเซสชันไคลเอ็นต์ของกลไกนี้ โดยจะบันทึกที่อยู่ IP ดั้งเดิมของลูกค้า ที่อยู่เป้าหมายที่เลือก (แบ็กเอนด์) และข้อมูลบริการบางอย่าง โดยทั่วไป ตารางสติ๊กใช้เพื่อจัดเก็บคู่ต้นทาง-IP + ปลายทาง-IP ซึ่งมีประโยชน์อย่างยิ่งสำหรับแอปพลิเคชันที่ไม่สามารถถ่ายโอนบริบทเซสชันผู้ใช้เมื่อสลับไปยังบาลานเซอร์อื่น ตัวอย่างเช่น ในโหมดการปรับสมดุล RoundRobin
หากมีการสอนโต๊ะแบบแท่งให้เคลื่อนที่ระหว่างกระบวนการ HAProxy ที่แตกต่างกัน (ระหว่างกระบวนการสมดุลที่เกิดขึ้น) เครื่องถ่วงของเราจะสามารถทำงานกับโต๊ะแบบแท่งกลุ่มเดียวได้ สิ่งนี้จะทำให้สามารถสลับเครือข่ายของลูกค้าได้อย่างราบรื่นหากหนึ่งในบาลานเซอร์ล้มเหลว การทำงานกับเซสชันไคลเอนต์จะดำเนินต่อไปบนแบ็กเอนด์เดิมที่เลือกไว้ก่อนหน้านี้
เพื่อการทำงานที่เหมาะสม จะต้องแก้ไขปัญหาที่อยู่ IP ต้นทางของบาลานเซอร์ที่ใช้สร้างเซสชัน ในกรณีของเรา นี่คือที่อยู่แบบไดนามิกบนอินเทอร์เฟซแบบย้อนกลับ
การทำงานที่ถูกต้องของเพื่อนร่วมงานทำได้ภายใต้เงื่อนไขบางประการเท่านั้น นั่นคือ การหมดเวลาของ TCP ต้องมีขนาดใหญ่เพียงพอ หรือการสลับต้องเร็วเพียงพอเพื่อให้เซสชัน TCP ไม่มีเวลายุติ อย่างไรก็ตาม ช่วยให้สามารถสลับได้อย่างราบรื่น
ใน IaaS เรามีบริการที่สร้างขึ้นโดยใช้เทคโนโลยีเดียวกัน นี้ ซึ่งเรียกว่าออคตาเวีย ขึ้นอยู่กับกระบวนการ HAProxy สองกระบวนการ และในขั้นต้นจะมีการสนับสนุนสำหรับเพียร์ด้วย พวกเขาได้พิสูจน์ตัวเองว่ายอดเยี่ยมในบริการนี้
รูปภาพแสดงการเคลื่อนไหวของตารางเพียร์ระหว่างอินสแตนซ์ HAProxy สามอินสแตนซ์ตามแผนผัง โดยจะเสนอการกำหนดค่าเกี่ยวกับวิธีการกำหนดค่า:
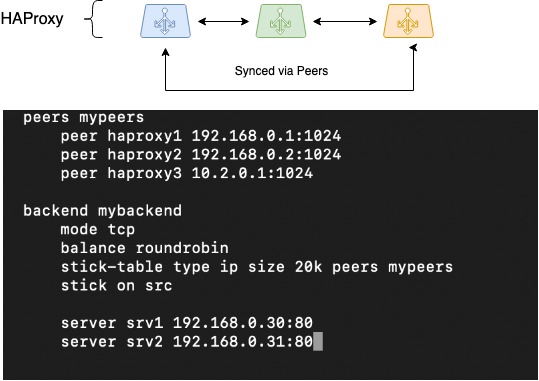
HAProxy Peers (การซิงโครไนซ์เซสชัน)
หากคุณใช้รูปแบบเดียวกัน จะต้องทดสอบการทำงานของมันอย่างระมัดระวัง ไม่ใช่ความจริงที่ว่ามันจะทำงานในลักษณะเดียวกัน 100% ของเวลาทั้งหมด แต่อย่างน้อยคุณจะไม่สูญเสีย Stick Table เมื่อคุณต้องการจดจำ IP ต้นทางของไคลเอ็นต์
การจำกัดจำนวนคำขอพร้อมกันจากไคลเอนต์เดียวกัน
บริการใดๆ ที่เปิดเผยต่อสาธารณะ รวมถึง API ของเรา อาจขึ้นอยู่กับคำขอที่ล้นหลาม เหตุผลอาจแตกต่างกันอย่างสิ้นเชิง ตั้งแต่ข้อผิดพลาดของผู้ใช้ไปจนถึงการโจมตีแบบกำหนดเป้าหมาย เรามี DDoSed ตามที่อยู่ IP เป็นระยะๆ ลูกค้ามักจะทำผิดพลาดในสคริปต์และมอบ mini-DDoS ให้กับเรา
ไม่ทางใดก็ทางหนึ่ง ต้องมีการป้องกันเพิ่มเติม วิธีแก้ปัญหาที่ชัดเจนคือการจำกัดจำนวนคำขอ API และไม่เสียเวลาของ CPU ในการประมวลผลคำขอที่เป็นอันตราย
เพื่อดำเนินการตามข้อจำกัดดังกล่าว เราใช้ขีดจำกัดอัตรา ซึ่งจัดระเบียบบนพื้นฐานของ HAProxy โดยใช้ตารางแท่งเดียวกัน การตั้งค่าขีดจำกัดนั้นค่อนข้างง่ายและช่วยให้คุณจำกัดผู้ใช้ตามจำนวนคำขอที่ส่งไปยัง API อัลกอริทึมจะจดจำ IP ต้นทางที่ใช้สร้างคำขอ และจำกัดจำนวนคำขอพร้อมกันจากผู้ใช้หนึ่งราย แน่นอนว่าเราคำนวณโปรไฟล์โหลด API โดยเฉลี่ยสำหรับแต่ละบริการและตั้งขีดจำกัดไว้ที่ 10 เท่าของค่านี้ เรายังคงติดตามสถานการณ์อย่างใกล้ชิดและจับตาดูชีพจร
สิ่งนี้มีลักษณะอย่างไรในทางปฏิบัติ? เรามีลูกค้าที่ใช้ API การปรับขนาดอัตโนมัติของเราตลอดเวลา พวกเขาสร้างเครื่องเสมือนประมาณสองถึงสามร้อยเครื่องในตอนเช้าและลบออกในตอนเย็น สำหรับ OpenStack การสร้างเครื่องเสมือนพร้อมบริการ PaaS นั้นจำเป็นต้องมีคำขอ API อย่างน้อย 1000 รายการ เนื่องจากการโต้ตอบระหว่างบริการก็เกิดขึ้นผ่าน API เช่นกัน
การโอนงานดังกล่าวทำให้เกิดภาระค่อนข้างมาก เราประเมินภาระนี้ รวบรวมยอดรายวัน เพิ่มขึ้นเป็นสิบเท่า และนี่กลายเป็นขีดจำกัดอัตราของเรา เราจับชีพจรของเรา เรามักจะเห็นบอทและสแกนเนอร์ที่พยายามมองมาที่เราเพื่อดูว่าเรามีสคริปต์ CGA ใด ๆ ที่สามารถเรียกใช้ได้หรือไม่ เรากำลังดำเนินการตัดพวกมันอย่างจริงจัง
วิธีอัปเดต Codebase ของคุณโดยที่ผู้ใช้ไม่สังเกตเห็น
นอกจากนี้เรายังใช้ความทนทานต่อข้อผิดพลาดในระดับกระบวนการปรับใช้โค้ดอีกด้วย อาจมีข้อบกพร่องในระหว่างการเปิดตัว แต่ผลกระทบต่อความพร้อมใช้งานของบริการสามารถลดลงได้
เราอัปเดตบริการของเราอย่างต่อเนื่องและต้องแน่ใจว่าโค้ดเบสได้รับการอัปเดตโดยไม่ส่งผลกระทบต่อผู้ใช้ เราจัดการเพื่อแก้ไขปัญหานี้โดยใช้ความสามารถในการจัดการของ HAProxy และการใช้งาน Graceful Shutdown ในบริการของเรา
เพื่อแก้ไขปัญหานี้ จำเป็นต้องตรวจสอบให้แน่ใจว่ามีการควบคุมบาลานเซอร์และการปิดบริการ "ถูกต้อง":
- ในกรณีของ HAProxy การควบคุมจะดำเนินการผ่านไฟล์สถิติ ซึ่งโดยพื้นฐานแล้วคือซ็อกเก็ตและถูกกำหนดไว้ในการกำหนดค่า HAProxy คุณสามารถส่งคำสั่งผ่าน stdio ได้ แต่เครื่องมือควบคุมการกำหนดค่าหลักของเรานั้นสามารถใช้งานได้ ดังนั้นจึงมีโมดูลในตัวสำหรับจัดการ HAProxy ซึ่งเราใช้อย่างแข็งขัน
- บริการ API และ Engine ส่วนใหญ่ของเรารองรับเทคโนโลยีการปิดระบบที่สวยงาม: เมื่อปิดระบบ จะรอให้งานปัจจุบันเสร็จสิ้น ไม่ว่าจะเป็นคำขอ http หรืองานบริการบางอย่าง สิ่งเดียวกันนี้เกิดขึ้นกับคนงาน มันรู้งานทั้งหมดที่ทำอยู่และสิ้นสุดเมื่อทำทุกอย่างสำเร็จแล้ว
ด้วยสองประเด็นนี้ อัลกอริธึมที่ปลอดภัยสำหรับการปรับใช้ของเราจึงมีลักษณะเช่นนี้
- นักพัฒนารวบรวมแพ็คเกจโค้ดใหม่ (สำหรับเรานี่คือ RPM) ทดสอบในสภาพแวดล้อม dev ทดสอบในสเตจ และปล่อยไว้ในที่เก็บสเตจ
- นักพัฒนากำหนดงานสำหรับการปรับใช้พร้อมคำอธิบายโดยละเอียดที่สุดของ "สิ่งประดิษฐ์": เวอร์ชันของแพ็คเกจใหม่ คำอธิบายฟังก์ชันใหม่และรายละเอียดอื่น ๆ เกี่ยวกับการปรับใช้หากจำเป็น
- ผู้ดูแลระบบเริ่มการอัพเดต เปิดตัว Playbook Ansible ซึ่งจะทำสิ่งต่อไปนี้:
- รับแพ็กเกจจากที่เก็บสเตจและใช้เพื่ออัปเดตเวอร์ชันของแพ็กเกจในที่เก็บผลิตภัณฑ์
- รวบรวมรายการแบ็กเอนด์ของบริการที่อัปเดต
- ปิดบริการแรกที่จะได้รับการอัปเดตใน HAProxy และรอให้กระบวนการทำงานเสร็จสิ้น ต้องขอบคุณการปิดระบบอย่างค่อยเป็นค่อยไป เรามั่นใจว่าคำขอของลูกค้าปัจจุบันทั้งหมดจะเสร็จสมบูรณ์ได้สำเร็จ
- หลังจากที่ API และผู้ปฏิบัติงานหยุดทำงานโดยสมบูรณ์ และปิด HAProxy แล้ว โค้ดก็จะได้รับการอัปเดต
- บริการเรียกใช้ Ansible
- สำหรับแต่ละบริการ ระบบจะดึง "แฮนเดิล" บางส่วนออก ซึ่งทำการทดสอบหน่วยกับการทดสอบคีย์ที่กำหนดไว้ล่วงหน้าจำนวนหนึ่ง มีการตรวจสอบรหัสใหม่ขั้นพื้นฐาน
- หากไม่พบข้อผิดพลาดในขั้นตอนก่อนหน้า ระบบจะเปิดใช้งานแบ็กเอนด์
- มาดูแบ็กเอนด์ถัดไปกันดีกว่า
- หลังจากอัปเดตแบ็กเอนด์ทั้งหมดแล้ว การทดสอบการทำงานจะเริ่มขึ้น หากไม่มีหายไป นักพัฒนาจะพิจารณาฟังก์ชันใหม่ที่เขาสร้างขึ้น
การดำเนินการนี้ทำให้การติดตั้งใช้งานเสร็จสมบูรณ์
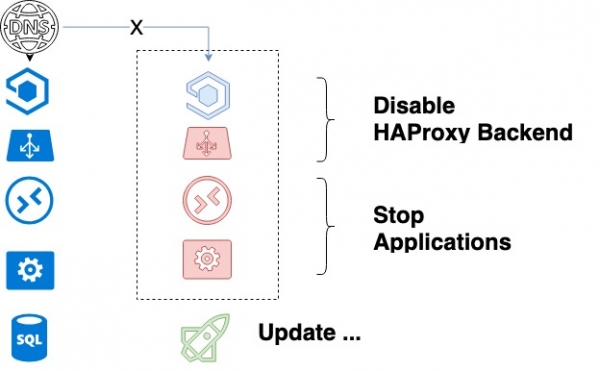
รอบการอัพเดตบริการ
โครงการนี้จะไม่ทำงานถ้าเราไม่มีกฎข้อเดียว เรารองรับทั้งเวอร์ชันเก่าและใหม่ในการต่อสู้ ล่วงหน้าในขั้นตอนของการพัฒนาซอฟต์แวร์มีการกำหนดไว้ว่าแม้ว่าจะมีการเปลี่ยนแปลงในฐานข้อมูลบริการ แต่ก็จะไม่ทำลายโค้ดก่อนหน้า ส่งผลให้ฐานโค้ดค่อยๆ อัปเดต
ข้อสรุป
การแบ่งปันความคิดของตัวเองเกี่ยวกับสถาปัตยกรรมเว็บที่ทนทานต่อข้อผิดพลาด ฉันอยากจะทราบประเด็นสำคัญอีกครั้ง:
- ความอดทนต่อความผิดพลาดทางกายภาพ
- ความทนทานต่อข้อผิดพลาดของเครือข่าย (บาลานเซอร์, BGP);
- ความทนทานต่อข้อผิดพลาดของซอฟต์แวร์ที่ใช้และพัฒนา
ทุกคนมีสถานะการออนไลน์ที่มั่นคง!
ที่มา: will.com
