

Docker Swarm, Kubernetes และ Mesos เป็นเฟรมเวิร์กการประสานคอนเทนเนอร์ที่ได้รับความนิยมมากที่สุด ในการบรรยายของเขา Arun Gupta เปรียบเทียบแง่มุมต่อไปนี้ของ Docker, Swarm และ Kubernetes:
- การพัฒนาท้องถิ่น
- ฟังก์ชันการปรับใช้
- แอปพลิเคชันหลายคอนเทนเนอร์
- การค้นพบบริการ
- ปรับขนาดบริการ
- งานที่รันครั้งเดียว
- บูรณาการกับมาเวน
- การอัปเดต "กลิ้ง"
- การสร้างคลัสเตอร์ฐานข้อมูล Couchbase
ด้วยเหตุนี้ คุณจะได้รับความเข้าใจที่ชัดเจนเกี่ยวกับสิ่งที่เครื่องมือการจัดการแต่ละอย่างนำเสนอ และเรียนรู้วิธีใช้แพลตฟอร์มเหล่านี้อย่างมีประสิทธิภาพ
Arun Gupta เป็นหัวหน้านักเทคโนโลยีสำหรับผลิตภัณฑ์โอเพ่นซอร์สที่ Amazon Web Services ซึ่งพัฒนาชุมชนนักพัฒนา Sun, Oracle, Red Hat และ Couchbase มานานกว่า 10 ปี มีประสบการณ์มากมายในการทำงานในทีมงานข้ามสายงานชั้นนำในการพัฒนาและดำเนินกลยุทธ์สำหรับแคมเปญและโปรแกรมการตลาด เขาเป็นผู้นำทีมวิศวกรของ Sun และเป็นหนึ่งในผู้ก่อตั้งทีม Java EE และเป็นผู้สร้าง Devoxx4Kids สาขาสหรัฐอเมริกา Arun Gupta เป็นผู้เขียนโพสต์มากกว่า 2 โพสต์ในบล็อกด้านไอที และได้เสวนาในกว่า 40 ประเทศ
บรรทัด 55 มี COUCHBASE_URI ที่ชี้ไปยังบริการฐานข้อมูลนี้ ซึ่งสร้างขึ้นโดยใช้ไฟล์การกำหนดค่า Kubernetes เช่นกัน หากคุณดูที่บรรทัดที่ 2 คุณจะเห็นประเภท: Service คือบริการที่ฉันกำลังสร้างเรียกว่า couchbase-service และมีชื่อเดียวกันอยู่ในบรรทัดที่ 4 ด้านล่างนี้คือพอร์ตบางส่วน

บรรทัดหลักคือ 6 และ 7 ในการให้บริการ ฉันพูดว่า "เฮ้ นี่คือป้ายกำกับที่ฉันกำลังมองหา!" และป้ายกำกับเหล่านี้ไม่มีอะไรมากไปกว่าชื่อคู่ที่แปรผันได้ และบรรทัดที่ 7 ชี้ไปที่ couchbase-rs-pod ของฉัน แอปพลิเคชัน. ต่อไปนี้คือพอร์ตที่ให้การเข้าถึงเลเบลเดียวกันเหล่านี้
ในบรรทัดที่ 19 ฉันสร้าง ReplicaSet ประเภทใหม่ บรรทัดที่ 31 มีชื่อของรูปภาพ และบรรทัดที่ 24-27 ชี้ไปที่ข้อมูลเมตาที่เกี่ยวข้องกับพ็อดของฉัน นี่คือสิ่งที่บริการกำลังมองหาและสิ่งที่ควรทำในการเชื่อมต่อ ในตอนท้ายของไฟล์มีการเชื่อมต่อระหว่างบรรทัด 55-56 และ 4 โดยพูดว่า: "ใช้บริการนี้!"
ดังนั้นฉันจึงเริ่มบริการเมื่อมีชุดแบบจำลอง และเนื่องจากชุดแบบจำลองแต่ละชุดมีพอร์ตของตัวเองพร้อมป้ายกำกับที่เกี่ยวข้อง จึงรวมอยู่ในบริการด้วย จากมุมมองของนักพัฒนา คุณเพียงแค่เรียกใช้บริการ ซึ่งจากนั้นจะใช้ชุดแบบจำลองที่คุณต้องการ
ด้วยเหตุนี้ ฉันมีพ็อด WildFly ที่สื่อสารกับแบ็กเอนด์ฐานข้อมูลผ่าน Couchbase Service ฉันสามารถใช้ส่วนหน้ากับพ็อด WildFly หลายตัวได้ ซึ่งยังสื่อสารกับแบ็คเอนด์ couchbase ผ่านบริการ couchbase อีกด้วย
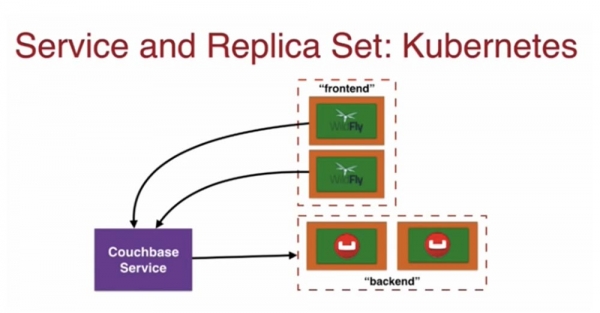
ต่อมาเราจะดูว่าบริการที่อยู่นอกคลัสเตอร์สื่อสารผ่านที่อยู่ IP กับองค์ประกอบที่อยู่ภายในคลัสเตอร์และมีที่อยู่ IP ภายในอย่างไร
ดังนั้น คอนเทนเนอร์ไร้สัญชาตินั้นดี แต่การใช้คอนเทนเนอร์แบบ stateful นั้นดีแค่ไหน? มาดูการตั้งค่าระบบสำหรับคอนเทนเนอร์แบบมีสถานะหรือแบบถาวร ใน Docker มี 4 แนวทางที่แตกต่างกันสำหรับเค้าโครงการจัดเก็บข้อมูลที่คุณควรใส่ใจ อย่างแรกคือ Implicit Per-Container ซึ่งหมายความว่าเมื่อใช้ couchbase, MySQL หรือ MyDB satateful container คอนเทนเนอร์ทั้งหมดจะเริ่มต้นด้วย Sandbox เริ่มต้น นั่นคือทุกสิ่งที่เก็บไว้ในฐานข้อมูลจะถูกเก็บไว้ในคอนเทนเนอร์นั้นเอง หากคอนเทนเนอร์หายไป ข้อมูลก็จะหายไปตามไปด้วย
อย่างที่สองคือ Explicit Per-Container เมื่อคุณสร้างที่เก็บข้อมูลเฉพาะด้วยคำสั่งสร้างวอลุ่มนักเทียบท่าและจัดเก็บข้อมูลในนั้น แนวทางต่อโฮสต์ที่สามเกี่ยวข้องกับการแมปพื้นที่เก็บข้อมูล เมื่อทุกสิ่งที่จัดเก็บไว้ในคอนเทนเนอร์จะถูกทำซ้ำพร้อมกันบนโฮสต์ หากคอนเทนเนอร์ล้มเหลว ข้อมูลจะยังคงอยู่ในโฮสต์ อย่างหลังคือการใช้โฮสต์ Multi-Host หลายตัวซึ่งแนะนำให้ใช้ในขั้นตอนการผลิตของโซลูชันต่างๆ สมมติว่าคอนเทนเนอร์ของคุณพร้อมกับแอปพลิเคชันของคุณทำงานบนโฮสต์ แต่คุณต้องการจัดเก็บข้อมูลของคุณไว้ที่ใดที่หนึ่งบนอินเทอร์เน็ต และด้วยเหตุนี้ คุณจึงใช้การแมปอัตโนมัติสำหรับระบบแบบกระจาย

แต่ละวิธีเหล่านี้ใช้สถานที่จัดเก็บเฉพาะ ข้อมูลโดยนัยและชัดเจนต่อคอนเทนเนอร์เก็บข้อมูลบนโฮสต์ที่ /var/lib/docker/volumes เมื่อใช้วิธี Per-Host ที่เก็บข้อมูลจะถูกติดตั้งภายในคอนเทนเนอร์ และตัวคอนเทนเนอร์จะถูกติดตั้งบนโฮสต์ สำหรับมัลติโฮสต์ สามารถใช้โซลูชัน เช่น Ceph, ClusterFS, NFS ฯลฯ ได้
หากคอนเทนเนอร์ถาวรล้มเหลว ไดเร็กทอรีหน่วยเก็บข้อมูลจะไม่สามารถเข้าถึงได้ในสองกรณีแรก แต่ในสองกรณีสุดท้ายจะคงการเข้าถึงไว้ อย่างไรก็ตาม ในกรณีแรก คุณสามารถเข้าถึงพื้นที่เก็บข้อมูลผ่านโฮสต์ Docker ที่ทำงานบนเครื่องเสมือนได้ ในกรณีที่สอง ข้อมูลจะไม่สูญหายเช่นกัน เนื่องจากคุณได้สร้างที่เก็บข้อมูลที่ชัดเจน
หากโฮสต์ล้มเหลว ไดเร็กทอรีหน่วยเก็บข้อมูลจะไม่พร้อมใช้งานในสามกรณีแรก ในกรณีสุดท้าย การเชื่อมต่อกับที่เก็บข้อมูลจะไม่ถูกขัดจังหวะ สุดท้ายนี้ ฟังก์ชั่นที่ใช้ร่วมกันจะถูกแยกออกจากการจัดเก็บอย่างสมบูรณ์ในกรณีแรก และเป็นไปได้ในส่วนที่เหลือ ในกรณีที่สอง คุณสามารถแชร์พื้นที่จัดเก็บข้อมูลได้ ขึ้นอยู่กับว่าฐานข้อมูลของคุณรองรับพื้นที่จัดเก็บข้อมูลแบบกระจายหรือไม่ ในกรณีของ Per-Host การกระจายข้อมูลจะทำได้บนโฮสต์ที่กำหนดเท่านั้น และสำหรับหลายโฮสต์ การกระจายข้อมูลจะทำได้โดยการขยายคลัสเตอร์
สิ่งนี้ควรนำมาพิจารณาเมื่อสร้างคอนเทนเนอร์แบบเก็บสถานะ เครื่องมือ Docker ที่มีประโยชน์อีกตัวหนึ่งคือปลั๊กอิน Volume ซึ่งทำงานบนหลักการของ "มีแบตเตอรี่อยู่ แต่ต้องเปลี่ยนใหม่" เมื่อคุณเริ่มคอนเทนเนอร์ Docker จะมีข้อความว่า “เฮ้ เมื่อคุณเริ่มคอนเทนเนอร์ด้วยฐานข้อมูลแล้ว คุณสามารถจัดเก็บข้อมูลของคุณในคอนเทนเนอร์นี้ได้!” นี่คือคุณลักษณะเริ่มต้น แต่คุณสามารถเปลี่ยนได้ ปลั๊กอินนี้อนุญาตให้คุณใช้ไดรฟ์เครือข่ายหรือสิ่งที่คล้ายกันแทนฐานข้อมูลคอนเทนเนอร์ ประกอบด้วยไดรเวอร์เริ่มต้นสำหรับพื้นที่จัดเก็บข้อมูลบนโฮสต์ และอนุญาตให้รวมคอนเทนเนอร์เข้ากับระบบจัดเก็บข้อมูลภายนอก เช่น Amazon EBS, Azure Storage และ GCE Persistent disk
สไลด์ถัดไปแสดงสถาปัตยกรรมของปลั๊กอิน Docker Volume
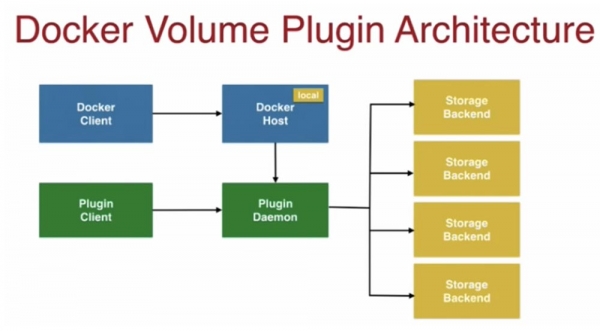
สีฟ้าแสดงถึงไคลเอ็นต์ Docker ที่เชื่อมโยงกับโฮสต์ Docker สีน้ำเงิน ซึ่งมีกลไกการจัดเก็บข้อมูลในตัวเครื่องที่ให้คอนเทนเนอร์สำหรับจัดเก็บข้อมูลแก่คุณ สีเขียวหมายถึง Plugin Client และ Plugin Daemon ซึ่งเชื่อมต่อกับโฮสต์ด้วย พวกเขาให้โอกาสในการจัดเก็บข้อมูลในที่จัดเก็บข้อมูลเครือข่ายประเภท Storage Backend ที่คุณต้องการ
ปลั๊กอิน Docker Volume สามารถใช้กับที่เก็บข้อมูล Portworx จริงๆ แล้วโมดูล PX-Dev เป็นคอนเทนเนอร์ที่คุณเรียกใช้ซึ่งเชื่อมต่อกับโฮสต์ Docker ของคุณและช่วยให้คุณจัดเก็บข้อมูลบน Amazon EBS ได้อย่างง่ายดาย
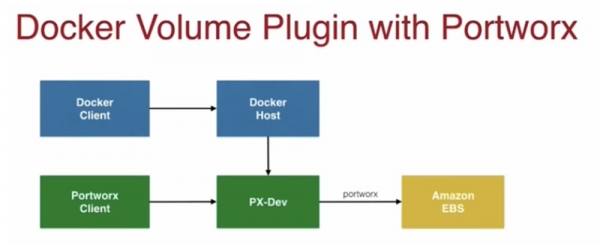
ไคลเอ็นต์ Portworx ช่วยให้คุณสามารถตรวจสอบสถานะของคอนเทนเนอร์การจัดเก็บข้อมูลต่างๆ ที่เชื่อมต่อกับโฮสต์ของคุณ หากคุณเยี่ยมชมบล็อกของฉัน คุณสามารถอ่านวิธีใช้ Portworx ด้วย Docker ให้เกิดประโยชน์สูงสุดได้
แนวคิดของพื้นที่จัดเก็บใน Kubernetes นั้นคล้ายคลึงกับ Docker และแสดงด้วยไดเร็กทอรีที่คอนเทนเนอร์ของคุณสามารถเข้าถึงได้ในพ็อด โดยไม่ขึ้นกับอายุการใช้งานของคอนเทนเนอร์ใดๆ ประเภทพื้นที่จัดเก็บข้อมูลที่พบบ่อยที่สุด ได้แก่ hostPath, nfs, awsElasticBlockStore และ gsePersistentDisk มาดูกันว่าร้านค้าเหล่านี้ทำงานอย่างไรใน Kubernetes โดยทั่วไปขั้นตอนการเชื่อมต่อจะมี 3 ขั้นตอน
ประการแรกคือบุคคลที่อยู่ฝั่งเครือข่าย ซึ่งโดยปกติจะเป็นผู้ดูแลระบบ จะให้พื้นที่จัดเก็บข้อมูลถาวรแก่คุณ มีไฟล์การกำหนดค่า PersistentVolume ที่สอดคล้องกันสำหรับสิ่งนี้ จากนั้น นักพัฒนาแอปพลิเคชันจะเขียนไฟล์การกำหนดค่าที่เรียกว่า PersistentVolumeClaim หรือคำขอพื้นที่เก็บข้อมูล PVC ซึ่งระบุว่า: “ฉันมีพื้นที่จัดเก็บแบบกระจายขนาด 50GB ที่จัดสรรไว้ แต่เพื่อให้บุคคลอื่นใช้ความจุของพื้นที่นั้นด้วย ฉันกำลังบอก PVC นี้ว่าขณะนี้ฉัน ต้องการเพียง 10 GB" สุดท้าย ขั้นตอนที่สามคือคำขอของคุณถูกเมาท์เป็นที่จัดเก็บข้อมูล และแอปพลิเคชันที่มีพ็อด หรือชุดแบบจำลอง หรือสิ่งที่คล้ายกัน จะเริ่มใช้งาน สิ่งสำคัญคือต้องจำไว้ว่ากระบวนการนี้ประกอบด้วย 3 ขั้นตอนที่กล่าวถึงและสามารถปรับขนาดได้
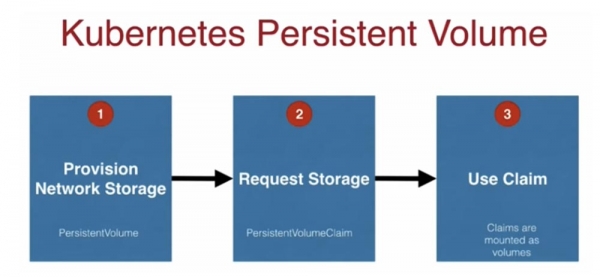
สไลด์ถัดไปแสดง Kubernetes Persistence Container ของสถาปัตยกรรม AWS
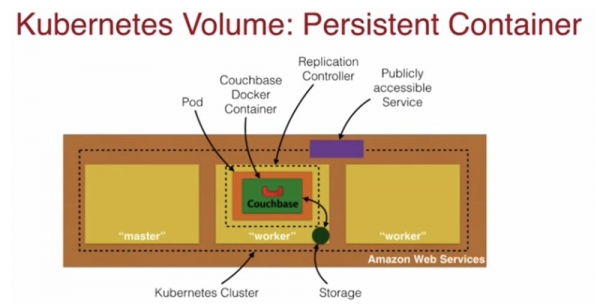
ภายในสี่เหลี่ยมสีน้ำตาลที่แสดงถึงคลัสเตอร์ Kubernetes จะมีโหนดหลักหนึ่งโหนดและโหนดผู้ปฏิบัติงานสองโหนด ซึ่งระบุด้วยสีเหลือง หนึ่งในโหนดของผู้ปฏิบัติงานประกอบด้วยพ็อดสีส้ม พื้นที่เก็บข้อมูล ตัวควบคุมแบบจำลอง และคอนเทนเนอร์ Docker Couchbase สีเขียว ภายในคลัสเตอร์ เหนือโหนด สี่เหลี่ยมสีม่วงบ่งบอกถึงบริการที่สามารถเข้าถึงได้จากภายนอก แนะนำให้ใช้สถาปัตยกรรมนี้สำหรับการจัดเก็บข้อมูลบนอุปกรณ์ หากจำเป็น ฉันสามารถจัดเก็บข้อมูลของฉันไว้ใน EBS นอกคลัสเตอร์ได้ ดังที่แสดงในสไลด์ถัดไป นี่เป็นโมเดลทั่วไปสำหรับการปรับขนาด แต่มีแง่มุมทางการเงินที่ต้องพิจารณาเมื่อใช้งาน การจัดเก็บข้อมูลไว้ที่ใดที่หนึ่งบนเครือข่ายอาจมีราคาแพงกว่าบนโฮสต์ เมื่อเลือกโซลูชันการจัดวางคอนเทนเนอร์ นี่เป็นหนึ่งในข้อโต้แย้งที่มีน้ำหนักมาก
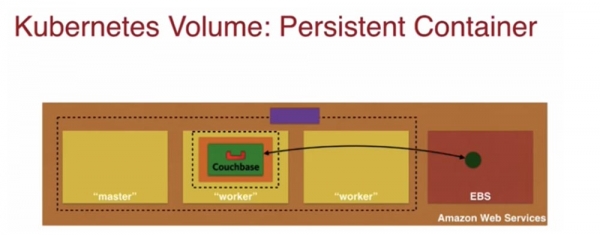
เช่นเดียวกับ Docker คุณสามารถใช้คอนเทนเนอร์ Kubernetes แบบถาวรกับ Portworx ได้
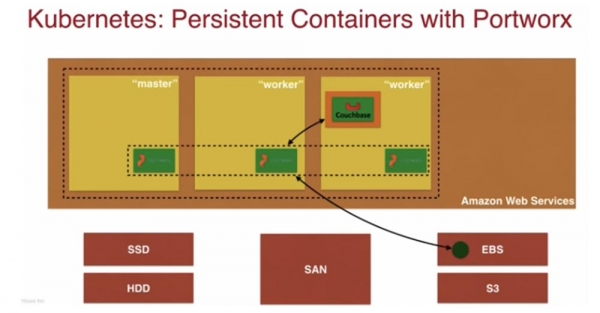
นี่คือสิ่งที่ในคำศัพท์เฉพาะของ Kubernetes 1.6 ในปัจจุบันเรียกว่า “StatefulSet” ซึ่งเป็นวิธีการทำงานกับแอปพลิเคชัน Stateful ที่ประมวลผลเหตุการณ์เกี่ยวกับการหยุด Pod และการดำเนินการปิดเครื่องอย่างสง่างาม ในกรณีของเรา แอปพลิเคชันดังกล่าวเป็นฐานข้อมูล ในบล็อกของฉัน คุณสามารถอ่านวิธีสร้าง StatefulSet ใน Kubernetes โดยใช้ Portworx
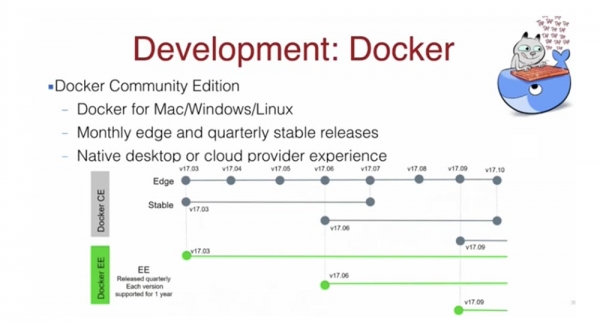
มาพูดถึงด้านการพัฒนาบ้าง อย่างที่ผมบอกไป Docker มีสองเวอร์ชัน คือ CE และ EE เวอร์ชัน CE คือ Community Edition ที่เสถียร ซึ่งจะได้รับการอัปเดตทุกสามเดือน ต่างจากเวอร์ชัน EE ที่อัปเดตทุกเดือน คุณสามารถดาวน์โหลด Docker สำหรับ Mac ได้ Linux หรือ Windowsเมื่อติดตั้งเสร็จแล้ว Docker จะอัปเดตตัวเองโดยอัตโนมัติ ทำให้เริ่มต้นใช้งานได้ง่ายมาก
สำหรับ Kubernetes ฉันชอบเวอร์ชัน Minikube ซึ่งเป็นวิธีที่ดีในการเริ่มต้นใช้งานแพลตฟอร์มโดยการสร้างคลัสเตอร์บนโหนดเดียว หากต้องการสร้างคลัสเตอร์ของหลายโหนด ตัวเลือกเวอร์ชันจะกว้างกว่า: เหล่านี้คือ kops, kube-aws (CoreOS+AWS), kube-up (ล้าสมัย) หากคุณต้องการใช้ Kubernetes ที่ใช้ AWS ฉันขอแนะนำให้เข้าร่วม AWS SIG ซึ่งจะประชุมออนไลน์ทุกวันศุกร์และเผยแพร่เอกสารที่น่าสนใจมากมายเกี่ยวกับการทำงานร่วมกับ AWS Kubernetes
มาดูกันว่า Rolling Update ทำงานอย่างไรบนแพลตฟอร์มเหล่านี้ หากมีคลัสเตอร์หลายโหนด ระบบจะใช้อิมเมจเวอร์ชันเฉพาะ เช่น WildFly:1 การอัปเดตทีละส่วนหมายความว่าเวอร์ชันอิมเมจจะถูกแทนที่ด้วยเวอร์ชันใหม่ตามลำดับในแต่ละโหนด ทีละรายการ
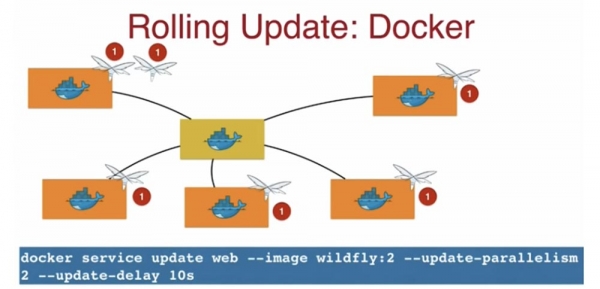
ในการดำเนินการนี้ฉันใช้คำสั่งการอัปเดตบริการนักเทียบท่า (ชื่อบริการ) ซึ่งฉันระบุเวอร์ชันใหม่ของอิมเมจ WildFly:2 และวิธีการอัปเดต update-parallelism 2 หมายเลข 2 หมายความว่าระบบจะอัปเดตอิมเมจแอปพลิเคชัน 2 ตัว พร้อมกันนั้นก็จะมีการดีเลย์การอัพเดต 10 วินาที 10 วินาที หลังจากนั้น 2 รูปภาพถัดไปจะถูกอัพเดตอีก 2 โหนด เป็นต้น กลไกการอัปเดตแบบกลิ้งอย่างง่ายนี้จัดเตรียมไว้ให้คุณโดยเป็นส่วนหนึ่งของ Docker
ใน Kubernetes การอัปเดตแบบกลิ้งจะทำงานในลักษณะนี้ ตัวควบคุมการจำลอง rc จะสร้างชุดของแบบจำลองที่เป็นเวอร์ชันเดียวกัน และแต่ละพ็อดใน webapp-rc นี้จะมีป้ายกำกับอยู่ใน etcd เมื่อฉันต้องการพ็อด ฉันจะใช้บริการแอปพลิเคชันเพื่อเข้าถึงพื้นที่เก็บข้อมูล ฯลฯ ซึ่งให้พ็อดแก่ฉันโดยใช้ป้ายกำกับที่ระบุ
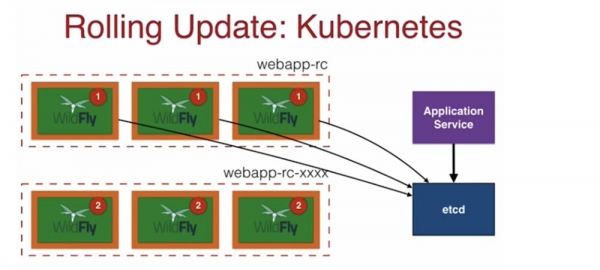
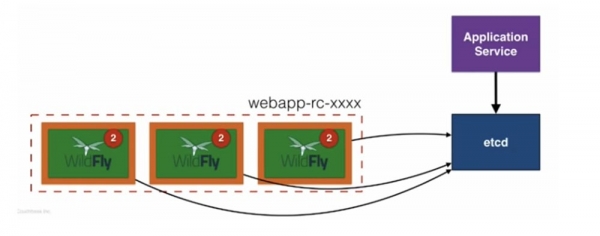
ในกรณีนี้ เรามี 3 พ็อดในตัวควบคุมการจำลองที่รันแอปพลิเคชัน WildFly เวอร์ชัน 1 เมื่ออัปเดตในเบื้องหลัง ตัวควบคุมการจำลองอีกตัวจะถูกสร้างขึ้นด้วยชื่อและดัชนีเดียวกันที่ส่วนท้าย - - xxxxx โดยที่ x เป็นตัวเลขสุ่ม และ ด้วยป้ายกำกับเดียวกัน ขณะนี้ Application Service มีพ็อดสามอันที่มีแอปพลิเคชันเวอร์ชันเก่า และพ็อดสามอันที่มีเวอร์ชันใหม่ในตัวควบคุมการจำลองใหม่ หลังจากนี้ พ็อดเก่าจะถูกลบออก และตัวควบคุมการจำลองที่มีพ็อดใหม่จะถูกเปลี่ยนชื่อและนำไปใช้งาน
มาพูดถึงการตรวจสอบกันบ้าง Docker มีคำสั่งตรวจสอบในตัวมากมาย ตัวอย่างเช่น คำสั่ง `docker container stats` ช่วยให้คุณสามารถแสดงข้อมูลเกี่ยวกับสถานะของคอนเทนเนอร์ทุกวินาทีบนคอนโซล รวมถึงการใช้งาน CPU และดิสก์ และโหลดเครือข่าย เครื่องมือ Docker Remote API ให้ข้อมูลเกี่ยวกับวิธีที่ไคลเอ็นต์สื่อสารกับเซิร์ฟเวอร์ มันใช้คำสั่งง่ายๆ แต่มีพื้นฐานมาจาก Docker REST API ในกรณีนี้ คำว่า REST, Flash และ Remote มีความหมายเหมือนกัน เมื่อคุณสื่อสารกับโฮสต์ มันคือ REST API Docker Remote API ช่วยให้คุณได้รับข้อมูลเพิ่มเติมเกี่ยวกับคอนเทนเนอร์ที่กำลังทำงานอยู่ บทความในบล็อกของฉันจะอธิบายวิธีการใช้เครื่องมือตรวจสอบนี้กับ... Windows Server.
การตรวจสอบเหตุการณ์ของระบบนักเทียบท่าเมื่อเรียกใช้คลัสเตอร์หลายโฮสต์ทำให้สามารถรับข้อมูลเกี่ยวกับความล้มเหลวของโฮสต์หรือคอนเทนเนอร์เสียหายบนโฮสต์เฉพาะ บริการปรับขนาด และอื่นๆ ที่คล้ายคลึงกัน ตั้งแต่ Docker 1.20 เป็นต้นไป จะมี Prometheus ซึ่งฝังอุปกรณ์ปลายทางไว้ในแอปพลิเคชันที่มีอยู่ สิ่งนี้ช่วยให้คุณรับการวัดผ่าน HTTP และแสดงบนแดชบอร์ด
คุณสมบัติการตรวจสอบอีกอย่างคือ cAdvisor (ย่อมาจาก Container Advisor) โดยจะวิเคราะห์และให้ข้อมูลการใช้ทรัพยากรและประสิทธิภาพจากการรันคอนเทนเนอร์ โดยให้ตัววัด Prometheus ทันทีที่แกะกล่อง สิ่งพิเศษเกี่ยวกับเครื่องมือนี้คือให้ข้อมูลในช่วง 60 วินาทีที่ผ่านมาเท่านั้น ดังนั้นคุณจะต้องสามารถรวบรวมข้อมูลนี้และนำไปไว้ในฐานข้อมูลเพื่อให้คุณสามารถตรวจสอบกระบวนการในระยะยาวได้ นอกจากนี้ยังสามารถใช้เพื่อแสดงการวัดแดชบอร์ดแบบกราฟิกโดยใช้ Grafana หรือ Kibana บล็อกของฉันมีคำอธิบายโดยละเอียดเกี่ยวกับวิธีใช้ cAdvisor เพื่อตรวจสอบคอนเทนเนอร์โดยใช้แดชบอร์ด Kibana
สไลด์ถัดไปแสดงให้เห็นว่าเอาต์พุตจุดสิ้นสุด Prometheus มีลักษณะอย่างไรและหน่วยวัดที่พร้อมให้แสดง
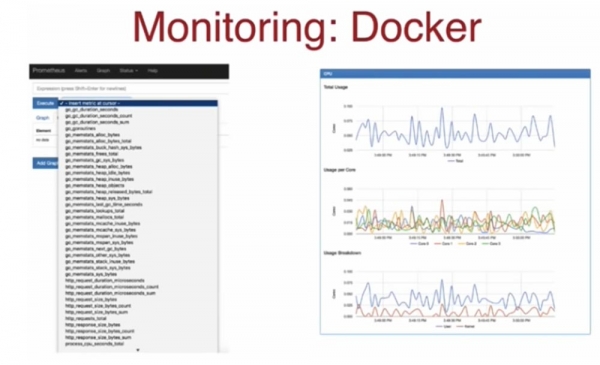
ที่ด้านล่างซ้าย คุณจะเห็นตัวชี้วัดสำหรับคำขอ HTTP การตอบกลับ ฯลฯ ทางด้านขวาคือการแสดงผลแบบกราฟิก
Kubernetes ยังมีเครื่องมือตรวจสอบในตัวอีกด้วย สไลด์นี้แสดงคลัสเตอร์ทั่วไปที่มีหนึ่งโหนดหลักและโหนดผู้ปฏิบัติงานสามโหนด
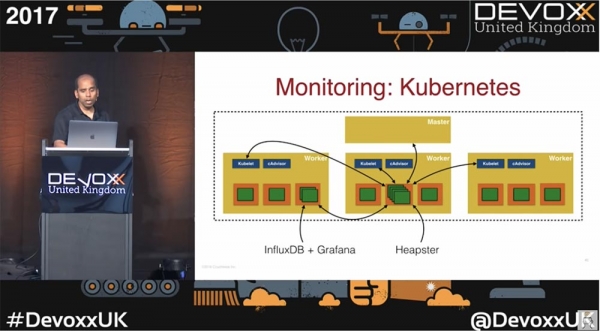
แต่ละโหนดการทำงานจะมี cAdvisor ที่เปิดใช้งานโดยอัตโนมัติ นอกจากนี้ยังมี Heapster ซึ่งเป็นระบบตรวจสอบประสิทธิภาพและรวบรวมตัวชี้วัดที่เข้ากันได้กับ Kubernetes เวอร์ชัน 1.0.6 และสูงกว่า Heapster ช่วยให้คุณไม่เพียงแต่รวบรวมตัววัดประสิทธิภาพของปริมาณงาน พ็อด และคอนเทนเนอร์เท่านั้น แต่ยังรวมถึงเหตุการณ์และสัญญาณอื่นๆ ที่สร้างโดยทั้งคลัสเตอร์อีกด้วย ในการรวบรวมข้อมูล ระบบจะพูดคุยกับ Kubelet ของแต่ละพ็อด จัดเก็บข้อมูลในฐานข้อมูล InfluxDB โดยอัตโนมัติ และส่งเอาต์พุตเป็นหน่วยเมตริกไปยังแดชบอร์ด Grafana อย่างไรก็ตาม โปรดทราบว่าหากคุณใช้ miniKube คุณลักษณะนี้จะไม่สามารถใช้งานได้ตามค่าเริ่มต้น ดังนั้น คุณจะต้องใช้ส่วนเสริมในการตรวจสอบ ดังนั้นทุกอย่างขึ้นอยู่กับตำแหน่งที่คุณรันคอนเทนเนอร์ และเครื่องมือตรวจสอบใดที่คุณสามารถใช้ได้เป็นค่าเริ่มต้น และเครื่องมือใดที่คุณต้องติดตั้งเป็นส่วนเสริมแยกต่างหาก
สไลด์ถัดไปแสดงแดชบอร์ด Grafana ที่แสดงสถานะการทำงานของคอนเทนเนอร์ของฉัน มีข้อมูลที่น่าสนใจค่อนข้างมากที่นี่ แน่นอนว่ามีเครื่องมือตรวจสอบกระบวนการ Docker และ Kubernetes เชิงพาณิชย์มากมาย เช่น SysDig, DataDog, NewRelic บางส่วนมีช่วงทดลองใช้งานฟรี 30 ปี ดังนั้นคุณจึงสามารถลองค้นหาโปรแกรมที่เหมาะกับคุณที่สุดได้ โดยส่วนตัวแล้ว ฉันชอบใช้ SysDig และ NewRelic ซึ่งทำงานร่วมกับ Kubernetes ได้ดี มีเครื่องมือต่างๆ ที่ผสานรวมเข้ากับแพลตฟอร์ม Docker และ Kubernetes ได้เป็นอย่างดี

โฆษณาบางส่วน🙂
ขอบคุณที่อยู่กับเรา คุณชอบบทความของเราหรือไม่? ต้องการดูเนื้อหาที่น่าสนใจเพิ่มเติมหรือไม่ สนับสนุนเราโดยการสั่งซื้อหรือแนะนำให้เพื่อน , อะนาล็อกที่ไม่เหมือนใครของเซิร์ฟเวอร์ระดับเริ่มต้นซึ่งเราคิดค้นขึ้นเพื่อคุณ: (ใช้ได้กับ RAID1 และ RAID10 สูงสุด 24 คอร์ และสูงสุด 40GB DDR4)
Dell R730xd ถูกกว่า 2 เท่าในศูนย์ข้อมูล Equinix Tier IV ในอัมสเตอร์ดัม? ที่นี่ที่เดียวเท่านั้น ในเนเธอร์แลนด์! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - จาก $99! อ่านเกี่ยวกับ
ที่มา: will.com
