

ฉันชื่อ Viktor Yagofarov และฉันกำลังพัฒนาแพลตฟอร์ม Kubernetes ที่ DomClick ในตำแหน่งผู้จัดการฝ่ายพัฒนาด้านเทคนิคในทีม Ops (ปฏิบัติการ) ฉันต้องการพูดคุยเกี่ยวกับโครงสร้างของกระบวนการ Dev <-> Ops ของเรา เกี่ยวกับคุณลักษณะของการดำเนินงานหนึ่งในคลัสเตอร์ k8s ที่ใหญ่ที่สุดในรัสเซีย ตลอดจนแนวทางปฏิบัติ DevOps / SRE ที่ทีมของเราใช้

ทีมปฏิบัติการ
ขณะนี้ทีม Ops มี 15 คน สามคนรับผิดชอบสำนักงาน สองคนทำงานในเขตเวลาที่แตกต่างกันและว่าง รวมถึงตอนกลางคืนด้วย ดังนั้น เจ้าหน้าที่จาก Ops จะคอยเฝ้าดูตลอดเวลาและพร้อมที่จะตอบสนองต่อเหตุการณ์ที่มีความซับซ้อน เราไม่มีกะกลางคืนซึ่งช่วยรักษาความคิดของเราและให้ทุกคนมีโอกาสนอนหลับพักผ่อนให้เพียงพอและใช้เวลาว่างไม่เฉพาะกับคอมพิวเตอร์เท่านั้น
ทุกคนมีความสามารถที่แตกต่างกัน: นักเครือข่าย, DBA, ผู้เชี่ยวชาญสแต็ก ELK, ผู้ดูแลระบบ / นักพัฒนา Kubernetes, การตรวจสอบ, การจำลองเสมือน, ผู้เชี่ยวชาญด้านฮาร์ดแวร์ ฯลฯ สิ่งหนึ่งที่ทำให้ทุกคนเป็นหนึ่งเดียวกัน - ทุกคนสามารถแทนที่พวกเราคนใดก็ได้ในระดับหนึ่ง: ตัวอย่างเช่น แนะนำโหนดใหม่ในคลัสเตอร์ k8s, อัปเดต PostgreSQL, เขียนไปป์ไลน์ CI / CD + Ansible, ทำให้บางอย่างเป็นอัตโนมัติใน Python / Bash / Go, เชื่อมต่อชิ้นส่วน ของฮาร์ดแวร์ไปยัง DPC ความสามารถที่แข็งแกร่งในด้านใดๆ จะไม่รบกวนการเปลี่ยนทิศทางของกิจกรรมและเริ่มสูบฉีดในด้านอื่นๆ ตัวอย่างเช่น ฉันได้งานในบริษัทแห่งหนึ่งในตำแหน่งผู้เชี่ยวชาญ PostgreSQL และตอนนี้ความรับผิดชอบหลักของฉันคือคลัสเตอร์ Kubernetes ในทีมยินดีต้อนรับการเติบโตใด ๆ และความรู้สึกไหล่ได้รับการพัฒนาอย่างมาก
อย่างไรก็ตาม เรากำลังมองหาผู้สมัครอยู่ คุณสมบัติของผู้สมัครค่อนข้างเป็นมาตรฐาน สำหรับผมแล้ว สิ่งสำคัญคือผู้สมัครต้องเข้ากับทีมได้ดี ไม่ชอบการเผชิญหน้า แต่ก็ต้องสามารถปกป้องมุมมองของตนเองได้ เต็มใจที่จะพัฒนาตนเอง และไม่กลัวที่จะลองสิ่งใหม่ๆ รวมถึงเต็มใจที่จะเสนอไอเดีย นอกจากนี้ ทักษะการเขียนโปรแกรมในภาษาสคริปต์และความรู้พื้นฐานก็เป็นสิ่งจำเป็นเช่นกัน Linux และภาษาอังกฤษ ภาษาอังกฤษมีความจำเป็นอย่างยิ่ง เพราะหากใครทำผิดพลาด พวกเขาสามารถค้นหาคำตอบจาก Google ได้ภายใน 10 วินาที ไม่ใช่ 10 นาที พร้อมด้วยผู้เชี่ยวชาญที่มีความรู้ลึกซึ้ง Linux ตอนนี้มันยากมากเลยครับ ตลกดี แต่ผู้สมัครสองในสามคนตอบคำถามไม่ได้ว่า "Load Average คืออะไร? มันประกอบด้วยอะไรบ้าง?" และคำถาม "จะสร้าง core dump จากโปรแกรม C ได้อย่างไร" ถูกมองว่าเป็นเรื่องของมนุษย์เหนือมนุษย์... หรือไดโนเสาร์ เราต้องทนกับเรื่องนี้ เพราะคนส่วนใหญ่มักมีความสามารถด้านอื่น ๆ ที่พัฒนามาสูง และเราจะสอน Linux ให้พวกเขา คำตอบของคำถามที่ว่า "ทำไมวิศวกร DevOps ถึงต้องรู้เรื่องพวกนี้ในโลกคลาวด์ยุคใหม่" คงต้องขอละไว้ก่อนในบทความนี้ แต่โดยสรุปแล้ว: ทั้งหมดนี้จำเป็นครับ
คำสั่งเครื่องมือ
ทีมเครื่องมือมีบทบาทสำคัญในระบบอัตโนมัติ งานหลักของพวกเขาคือการสร้างเครื่องมือกราฟิกและ CLI ที่สะดวกสำหรับนักพัฒนา ตัวอย่างเช่น การพัฒนา Confer ภายในของเราทำให้คุณสามารถเปิดตัวแอปพลิเคชันไปยัง Kubernetes ได้ด้วยการคลิกเมาส์เพียงไม่กี่ครั้ง กำหนดค่าทรัพยากร คีย์จากห้องนิรภัย เป็นต้น เคยมี Jenkins + Helm 2 แต่ฉันต้องพัฒนาเครื่องมือของตัวเองเพื่อกำจัดการคัดลอกและวางความสม่ำเสมอให้กับวงจรชีวิตของซอฟต์แวร์
ทีม Ops ไม่ได้เขียนไปป์ไลน์สำหรับนักพัฒนา แต่สามารถให้คำแนะนำเกี่ยวกับปัญหาใด ๆ เป็นลายลักษณ์อักษร (บางทีมยังมี Helm 3)
DevOps
สำหรับ DevOps เราเห็นดังนี้:
ทีม Dev เขียนโค้ด เผยแพร่ผ่าน Confer to dev -> qa/stage -> prod เป็นความรับผิดชอบของทีม Dev และ Ops เพื่อให้แน่ใจว่าโค้ดจะไม่ทำงานช้าลงและไม่เกิดข้อผิดพลาด ในเวลากลางวัน เจ้าหน้าที่ปฏิบัติหน้าที่จากทีมปฏิบัติการควรตอบสนองต่อเหตุการณ์ด้วยใบสมัครของเขา และในตอนเย็นและกลางคืน ผู้ดูแลหน้าที่ (Ops) ควรปลุกนักพัฒนาที่ปฏิบัติหน้าที่ หากเขาทราบแน่นอนว่าปัญหาไม่ได้เกิดขึ้น ในโครงสร้างพื้นฐาน เมตริกและการแจ้งเตือนทั้งหมดในการเฝ้าติดตามจะปรากฏโดยอัตโนมัติหรือกึ่งอัตโนมัติ
พื้นที่รับผิดชอบของ Ops เริ่มตั้งแต่ช่วงเวลาที่แอปพลิเคชันเปิดตัวไปจนถึงการผลิต แต่ความรับผิดชอบของ Dev ไม่ได้จบเพียงแค่นั้น - เราทำสิ่งหนึ่งและอยู่ในเรือลำเดียวกัน
นักพัฒนาจะแนะนำผู้ดูแลระบบหากพวกเขาต้องการความช่วยเหลือในการเขียน microservice ของผู้ดูแลระบบ (เช่น Go backend + HTML5) และผู้ดูแลระบบจะแนะนำนักพัฒนาเกี่ยวกับโครงสร้างพื้นฐานหรือปัญหาที่เกี่ยวข้องกับ k8s
อย่างไรก็ตาม เราไม่มีเสาหินเลย มีแต่ไมโครเซอร์วิสเท่านั้น จนถึงขณะนี้จำนวนมีความผันผวนระหว่าง 900 ถึง 1000 ในคลัสเตอร์ prod k8s หากวัดด้วยจำนวน การใช้งาน. จำนวนพ็อดผันผวนระหว่าง 1700 ถึง 2000 พ็อดในกลุ่มผลิตภัณฑ์ตอนนี้อยู่ที่ประมาณ 2000
ฉันไม่สามารถให้ตัวเลขที่แน่นอนได้ เนื่องจากเราตรวจสอบไมโครเซอร์วิสที่ไม่จำเป็นและตัดออกในโหมดกึ่งอัตโนมัติ การติดตามเอนทิตีที่ไม่จำเป็นใน k8s ช่วยเราได้ ซึ่งช่วยประหยัดทรัพยากรและเงิน
การจัดการทรัพยากร
การตรวจสอบ
การตรวจสอบข้อมูลที่สร้างขึ้นอย่างมีประสิทธิภาพกลายเป็นรากฐานที่สำคัญในการทำงานของคลัสเตอร์ขนาดใหญ่ เรายังไม่พบโซลูชันสากลที่ครอบคลุมความต้องการการตรวจสอบทั้งหมด 100% ดังนั้นเราจึงตรึงโซลูชันแบบกำหนดเองที่แตกต่างกันเป็นระยะๆ ในสภาพแวดล้อมนี้
- Zabbix. การตรวจสอบแบบเก่าที่ดี ซึ่งออกแบบมาเพื่อตรวจสอบสถานะโดยรวมของโครงสร้างพื้นฐานเป็นหลัก มันบอกเราเมื่อโหนดตายเพราะโปรเซสเซอร์ หน่วยความจำ ดิสก์ เครือข่าย และอื่นๆ ไม่มีอะไรเหนือธรรมชาติ แต่เรายังมี DaemonSet ของเอเจนต์แยกต่างหากด้วยความช่วยเหลือ เช่น เราตรวจสอบสถานะ DNS ในคลัสเตอร์ เรามองหาคอร์คอร์เด็นพ็อดโง่ๆ เราตรวจสอบความพร้อมใช้งานของโฮสต์ภายนอก ดูเหมือนว่าทำไมต้องกังวลกับมัน แต่สำหรับทราฟฟิกปริมาณมากองค์ประกอบนี้เป็นจุดล้มเหลวที่ร้ายแรง ก่อนหน้านี้ฉันมี การต่อสู้กับประสิทธิภาพ DNS ในคลัสเตอร์เป็นอย่างไร
- ผู้ดำเนินการ Prometheus. ชุดของผู้ส่งออกต่างๆ ให้ภาพรวมที่ดีของส่วนประกอบคลัสเตอร์ทั้งหมด ต่อไป เราจะแสดงภาพทั้งหมดนี้บนแดชบอร์ดขนาดใหญ่ใน Grafana และใช้ตัวจัดการการแจ้งเตือนสำหรับการแจ้งเตือน
อีกเครื่องมือที่มีประโยชน์สำหรับเราคือ . เราเขียนสิ่งนี้หลังจากหลายครั้งที่เราพบสถานการณ์ที่ทีมหนึ่งใช้เส้นทางทับซ้อนกับทางเข้าของทีมอื่น ซึ่งทำให้เกิดข้อผิดพลาด 50x ตอนนี้ ก่อนที่จะนำไปใช้งานจริง นักพัฒนาตรวจสอบว่าพวกเขาจะไม่ทำร้ายใคร และสำหรับทีมของฉัน เครื่องมือนี้เป็นเครื่องมือที่ดีสำหรับการวินิจฉัยเบื้องต้นเกี่ยวกับปัญหาเกี่ยวกับ Ingresses เป็นเรื่องตลกที่ในตอนแรกมันถูกเขียนขึ้นสำหรับผู้ดูแลระบบและดูค่อนข้าง "เงอะงะ" แต่หลังจากที่ทีมพัฒนาตกหลุมรักเครื่องมือนี้ มันก็เปลี่ยนไปมากและเริ่มดูไม่เหมือน "ผู้ดูแลระบบสร้างหน้าเว็บสำหรับผู้ดูแลระบบ" . ในไม่ช้า เราจะละทิ้งเครื่องมือนี้ และสถานการณ์ดังกล่าวจะได้รับการตรวจสอบแม้กระทั่งก่อนที่ไปป์ไลน์จะเปิดตัว
ทรัพยากรของทีมใน "Cube"
ก่อนที่จะดำเนินการตามตัวอย่าง ควรอธิบายว่าเรามีการจัดสรรทรัพยากรอย่างไร ไมโครเซอร์วิส.
เพื่อทำความเข้าใจว่าทีมใดใช้ในปริมาณเท่าใด ทรัพยากร (โปรเซสเซอร์, หน่วยความจำ, SSD ในเครื่อง) เราจัดสรรของเราเอง namespace ใน "Cube" และจำกัดความสามารถสูงสุดในแง่ของโปรเซสเซอร์ หน่วยความจำ และดิสก์ โดยก่อนหน้านี้ได้หารือถึงความต้องการของทีม ดังนั้น ในกรณีทั่วไป คำสั่งหนึ่งคำสั่งจะไม่บล็อกคลัสเตอร์ทั้งหมดสำหรับการปรับใช้ โดยจัดสรรหน่วยความจำหลายพันคอร์และเทราไบต์ให้กับตัวมันเอง การเข้าถึงเนมสเปซนั้นออกผ่าน AD (เราใช้ RBAC) เนมสเปซและขีดจำกัดจะถูกเพิ่มผ่านคำขอดึงไปยังที่เก็บ GIT จากนั้นทุกอย่างจะถูกนำออกใช้โดยอัตโนมัติผ่านไปป์ไลน์ Ansible
ตัวอย่างการจัดสรรทรัพยากรต่อทีม:
namespaces:
chat-team:
pods: 23
limits:
cpu: 11
memory: 20Gi
requests:
cpu: 11
memory: 20Gi
คำขอและขีดจำกัด
คิวบ์" ขอร้อง คือจำนวนของทรัพยากรสำรองที่รับประกันภายใต้ รุน (คอนเทนเนอร์นักเทียบท่าอย่างน้อยหนึ่งรายการ) ในคลัสเตอร์ ขีดจำกัดคือค่าสูงสุดที่ไม่รับประกัน คุณมักจะเห็นในแผนภูมิว่าทีมใดตั้งค่าคำขอมากเกินไปสำหรับแอปพลิเคชันทั้งหมดของตน และไม่สามารถนำแอปพลิเคชันไปใช้กับ "Cube" ได้ เนื่องจากภายใต้เนมสเปซของพวกเขาได้ "ใช้" คำขอทั้งหมดไปแล้ว
วิธีที่ถูกต้องในสถานการณ์นี้คือการดูการใช้ทรัพยากรจริงและเปรียบเทียบกับจำนวนที่ร้องขอ (คำขอ)
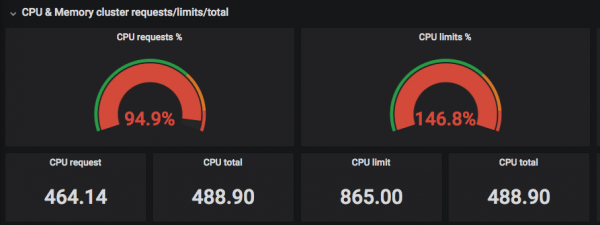
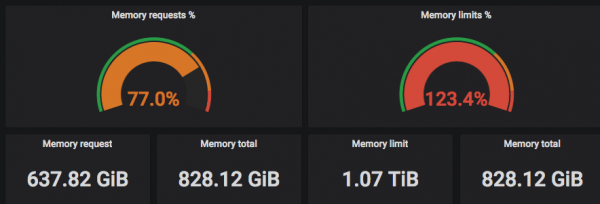
ภาพหน้าจอด้านบนแสดงให้เห็นว่า CPU ที่ "ร้องขอ" (ร้องขอ) ถูกเลือกตามจำนวนเธรดจริง และขีดจำกัดอาจเกินจำนวนเธรด CPU จริง =)
ทีนี้มาดูเนมสเปซบางส่วนให้ละเอียดยิ่งขึ้น (ฉันเลือกเนมสเปซ kube-system - เนมสเปซระบบสำหรับส่วนประกอบของ "Cube" เอง) และดูอัตราส่วนของเวลาตัวประมวลผลและหน่วยความจำที่ใช้จริงกับตัวที่ร้องขอ:
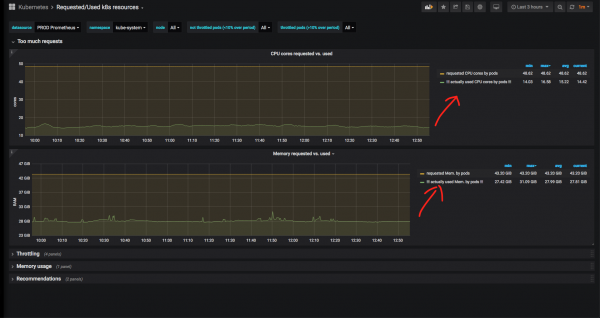
เห็นได้ชัดว่ามีหน่วยความจำและ CPU ที่สงวนไว้สำหรับบริการระบบมากกว่าที่ใช้จริง ในกรณีของระบบ kube สิ่งนี้เป็นสิ่งที่ถูกต้อง: มันเกิดขึ้นที่ตัวควบคุม nginx ingress หรือ nodelocaldns ที่จุดสูงสุดวางอยู่บน CPU และกิน RAM จำนวนมาก ดังนั้นระยะขอบดังกล่าวจึงสมเหตุสมผล นอกจากนี้ เราไม่สามารถพึ่งพาแผนภูมิในช่วง 3 ชั่วโมงที่ผ่านมาได้ จึงควรดูเมตริกที่ผ่านมาในช่วงเวลาใหญ่ๆ
ระบบ "คำแนะนำ" ได้รับการพัฒนา ตัวอย่างเช่น คุณสามารถดูได้ว่าทรัพยากรใดจะดีกว่าในการเพิ่ม "ขีดจำกัด" (แถบด้านบนที่อนุญาต) เพื่อไม่ให้ "การควบคุมปริมาณ" เกิดขึ้น: ช่วงเวลาที่พ็อดใช้ CPU หรือหน่วยความจำสำหรับควอนตัมเวลาที่กำหนดแล้ว และกำลังรอจนกว่าจะ "ละลาย":
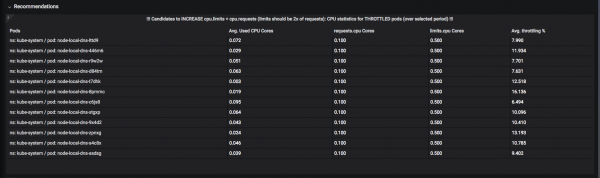
และนี่คือฝักที่ควรควบคุมความอยากอาหาร:
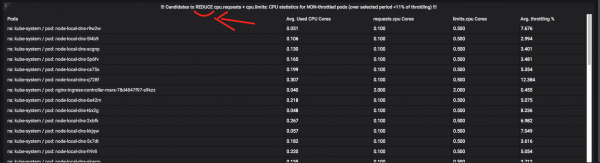
เกี่ยวกับ การควบคุมปริมาณ + การตรวจสอบทรัพยากร คุณสามารถเขียนได้มากกว่าหนึ่งบทความ ดังนั้นถามคำถามในความคิดเห็น ฉันสามารถพูดได้สองสามคำว่างานในการทำให้เมตริกดังกล่าวเป็นแบบอัตโนมัตินั้นยากมากและต้องใช้เวลามาก และการดำเนินการที่สมดุลกับฟังก์ชัน "หน้าต่าง" และ "CTE" Prometheus / VictoriaMetrics (คำศัพท์เหล่านี้อยู่ในเครื่องหมายคำพูด เนื่องจากมี แทบจะไม่มีอะไรแบบนี้ใน PromQL และคุณต้องฟันดาบข้อความค้นหาที่น่ากลัวบนหน้าจอข้อความต่างๆ และปรับแต่งให้เหมาะสม)
เป็นผลให้นักพัฒนามีเครื่องมือในการตรวจสอบเนมสเปซของตนใน "Cube" และสามารถเลือกได้ว่าจะให้แอปพลิเคชันใด "ตัด" ทรัพยากรที่ไหนและเวลาใด และพ็อดใดที่สามารถให้ CPU ทั้งหมดตลอดทั้งคืน
วิธีการ
ในบริษัทเช่นตอนนี้ ทันสมัยเรายึดมั่นใน DevOps- และ SRE-นักปฏิบัติ เมื่อบริษัทมีไมโครเซอร์วิส 1000 รายการ นักพัฒนาประมาณ 350 คน และผู้ดูแลระบบ 15 คนสำหรับโครงสร้างพื้นฐานทั้งหมด คุณต้อง “นำสมัย”: เบื้องหลัง “คำศัพท์” เหล่านี้มีความจำเป็นเร่งด่วนที่จะต้องทำให้ทุกอย่างเป็นอัตโนมัติ และผู้ดูแลระบบไม่ควรเป็นคอขวด ในกระบวนการ
ในฐานะ Ops เรามีเมตริกและแดชบอร์ดต่างๆ สำหรับนักพัฒนาที่เกี่ยวข้องกับความเร็วในการตอบสนองของบริการและข้อผิดพลาดของบริการ
เราใช้วิธีการเช่น: , и โดยนำมารวมกัน เราพยายามลดจำนวนแดชบอร์ดให้เหลือน้อยที่สุดเพื่อให้เห็นได้ชัดเจนว่าบริการใดกำลังลดระดับลง (เช่น โค้ดตอบกลับต่อวินาที เวลาตอบสนองที่เปอร์เซ็นไทล์ที่ 99) เป็นต้น ทันทีที่จำเป็นต้องมีเมตริกใหม่สำหรับแดชบอร์ดทั่วไป เราจะวาดและเพิ่มทันที
ฉันไม่ได้วาดกราฟิกเป็นเวลาหนึ่งเดือนแล้ว นี่อาจเป็นสัญญาณที่ดี หมายความว่า "ความต้องการ" ส่วนใหญ่ได้ถูกนำไปใช้แล้ว มันเกิดขึ้นเป็นเวลาหนึ่งสัปดาห์ที่ฉันวาดแผนภูมิใหม่อย่างน้อยวันละครั้ง
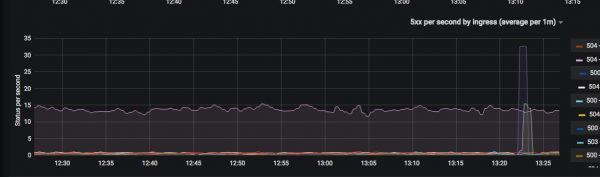
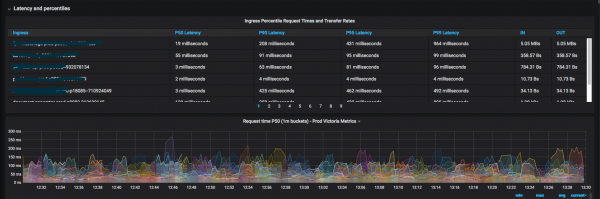
ผลลัพธ์ที่ได้มีค่าเพราะตอนนี้นักพัฒนาไม่ค่อยไปหาผู้ดูแลระบบพร้อมกับคำถามว่า "จะดูเมตริกบางประเภทได้ที่ไหน"
การแนะนำของ บริการตาข่าย อยู่ใกล้แค่เอื้อมและน่าจะทำให้ชีวิตง่ายขึ้นมากสำหรับทุกคน เพื่อนร่วมงานจาก Tools ใกล้จะนำนามธรรม "Istio of a healthy people" ไปใช้แล้ว: วงจรชีวิตของคำขอ HTTP แต่ละรายการจะปรากฏในการเฝ้าติดตาม และ จะสามารถเข้าใจได้เสมอว่า "ทุกอย่างพังทลายในขั้นตอนใด" ที่การโต้ตอบระหว่างบริการ (และไม่เพียงเท่านั้น) สมัครรับข่าวสารจากฮับ DomClick =)
รองรับโครงสร้างพื้นฐาน Kubernetes
ในอดีตเราใช้เวอร์ชันแพตช์ คูบีสเปรย์ - บทบาทที่พร้อมสำหรับการปรับใช้ ขยาย และอัปเดต Kubernetes เมื่อถึงจุดหนึ่ง การสนับสนุนสำหรับการติดตั้งที่ไม่ใช่ kubeadm ถูกตัดออกจากสาขาหลัก และไม่มีการเสนอกระบวนการเปลี่ยนไปใช้ kubeadm เป็นผลให้ Southbridge สร้างทางแยกของตัวเอง (ด้วยการสนับสนุน kubeadm และการแก้ไขปัญหาที่สำคัญอย่างรวดเร็ว)
กระบวนการอัปเกรดสำหรับคลัสเตอร์ k8s ทั้งหมดมีลักษณะดังนี้:
- เอา คูบีสเปรย์ จาก Southbridge ตรวจสอบกับสาขาของเรา merjim
- ออกอัพเดทเป็น ความตึงเครียด- "คิวบ์"
- เราเปิดตัวการอัปเดตทีละโหนด (ใน Ansible นี่คือ "serial: 1") ใน dev- "คิวบ์"
- กำลังปรับปรุง แยง ในเย็นวันเสาร์ ทีละโหนด
ในอนาคตมีแผนที่จะแทนที่ คูบีสเปรย์ ไปสู่สิ่งที่เร็วกว่าและไปที่ คูบีด.
โดยรวมแล้ว เรามี "Cubes" อยู่ XNUMX แบบ ได้แก่ Stress, Dev และ Prod เราวางแผนที่จะเปิดตัวอีกสแตนด์บายร้อน) Prod- "Cube" ในศูนย์ข้อมูลที่สอง ความตึงเครียด и dev อยู่ในเครื่องเสมือน (oVirt for Stress และ VMWare cloud for Dev) แยง- "Cube" อยู่บน "โลหะเปลือย" (โลหะเปลือย): เป็นโหนดเดียวกันกับ 32 เธรด CPU, หน่วยความจำ 64-128 GB และ SSD RAID 300 10 GB - มีทั้งหมด 50 รายการ โหนด "บาง" สามโหนดมีไว้สำหรับ "ผู้เชี่ยวชาญ" แยง- "คิวบา": หน่วยความจำ 16 GB, 12 เธรด CPU
สำหรับการขาย เราเลือกใช้ “โลหะเปลือย” และหลีกเลี่ยงเลเยอร์ที่ไม่จำเป็น เช่น OpenStack: เราไม่ต้องการ "เพื่อนบ้านที่มีเสียงดัง" และ CPU ขโมยเวลา. และความซับซ้อนของการดูแลระบบเพิ่มขึ้นประมาณครึ่งหนึ่งในกรณีของ OpenStack ภายในบริษัท
สำหรับ CI/CD Cubic และส่วนประกอบโครงสร้างพื้นฐานอื่นๆ เราใช้เซิร์ฟเวอร์ GIT แยกต่างหาก ซึ่งก็คือ Helm 3 อะตอม), Jenkins, Ansible และ Docker เราชอบสาขาคุณลักษณะและปรับใช้กับสภาพแวดล้อมที่แตกต่างกันจากพื้นที่เก็บข้อมูลเดียวกัน
ข้อสรุป

โดยทั่วไปแล้ว กระบวนการ DevOps ที่ DomClick จะมีลักษณะเช่นนี้จากมุมมองของวิศวกรฝ่ายปฏิบัติการ บทความนี้กลายเป็นบทความทางเทคนิคน้อยกว่าที่ฉันคาดไว้ ดังนั้นติดตามข่าว DomClick บน Habré: จะมีบทความ "ฮาร์ดคอร์" เกี่ยวกับ Kubernetes และอีกมากมาย
ที่มา: will.com
