

สวัสดีทุกคน! ฉันชื่อโกลอฟนิโคไล ก่อนหน้านี้ ฉันทำงานที่ Avito และจัดการแพลตฟอร์มข้อมูลเป็นเวลาหกปี นั่นคือ ฉันทำงานกับฐานข้อมูลทั้งหมด: การวิเคราะห์ (Vertica, ClickHouse), สตรีมมิ่งและ OLTP (Redis, Tarantool, VoltDB, MongoDB, PostgreSQL) ในช่วงเวลานี้ ฉันจัดการกับฐานข้อมูลจำนวนมาก - แตกต่างและผิดปกติอย่างมาก และในกรณีการใช้งานที่ไม่ได้มาตรฐาน
ปัจจุบันฉันทำงานที่ ManyChat โดยพื้นฐานแล้ว นี่คือการเริ่มต้นใหม่ ทะเยอทะยาน และเติบโตอย่างรวดเร็ว และเมื่อฉันเข้าร่วมบริษัทครั้งแรก คำถามคลาสสิกก็เกิดขึ้น: “ตอนนี้สตาร์ทอัพรุ่นใหม่ควรได้อะไรจาก DBMS และตลาดฐานข้อมูล”
ในบทความนี้ตามรายงานของฉันที่ ฉันจะตอบคำถามนี้ สามารถดูรายงานเวอร์ชันวิดีโอได้ที่ .
ฐานข้อมูลที่รู้จักกันทั่วไปในปี 2020
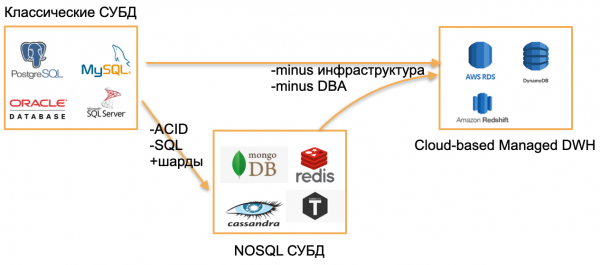
มันคือปี 2020 ฉันมองไปรอบ ๆ และเห็นฐานข้อมูลสามประเภท
ประเภทแรก - ฐานข้อมูล OLTP แบบคลาสสิก: PostgreSQL, เซิร์ฟเวอร์ SQL, Oracle, MySQL เขียนไว้เมื่อนานมาแล้ว แต่ยังคงมีความเกี่ยวข้องเนื่องจากมีความคุ้นเคยกับชุมชนนักพัฒนามาก
ประเภทที่สองคือ ฐานจาก "ศูนย์". พวกเขาพยายามที่จะย้ายออกจากรูปแบบคลาสสิกโดยละทิ้ง SQL โครงสร้างแบบดั้งเดิมและ ACID โดยการเพิ่มการแบ่งส่วนและคุณสมบัติที่น่าสนใจอื่น ๆ ในตัว ตัวอย่างเช่น นี่คือ Cassandra, MongoDB, Redis หรือ Tarantool โซลูชันทั้งหมดนี้ต้องการนำเสนอสิ่งใหม่ที่เป็นพื้นฐานให้กับตลาดและเข้าครอบครองเฉพาะกลุ่ม เนื่องจากกลายเป็นว่าสะดวกอย่างยิ่งสำหรับงานบางอย่าง ฉันจะแสดงฐานข้อมูลเหล่านี้ด้วยคำว่า NOSQL
"ศูนย์" จบลงแล้ว เราคุ้นเคยกับฐานข้อมูล NOSQL และจากมุมมองของฉัน โลกได้ก้าวไปอีกขั้น - ฐานข้อมูลที่ได้รับการจัดการ. ฐานข้อมูลเหล่านี้มีแกนหลักเดียวกันกับฐานข้อมูล OLTP แบบคลาสสิกหรือฐานข้อมูล NoSQL ใหม่ แต่พวกเขาไม่จำเป็นต้องใช้ DBA และ DevOps และทำงานบนฮาร์ดแวร์ที่ได้รับการจัดการในระบบคลาวด์ สำหรับนักพัฒนา นี่เป็น "เพียงฐาน" ที่ทำงานที่ไหนสักแห่ง แต่ไม่มีใครสนใจว่าจะมีการติดตั้งบนเซิร์ฟเวอร์อย่างไร ใครเป็นผู้กำหนดค่าเซิร์ฟเวอร์ และใครเป็นผู้อัปเดต
ตัวอย่างของฐานข้อมูลดังกล่าว:
- AWS RDS เป็น Wrapper ที่มีการจัดการสำหรับ PostgreSQL/MySQL
- DynamoDB เป็นอะนาล็อก AWS ของฐานข้อมูลตามเอกสาร คล้ายกับ Redis และ MongoDB
- Amazon RedShift เป็นฐานข้อมูลการวิเคราะห์ที่ได้รับการจัดการ
โดยพื้นฐานแล้วเหล่านี้เป็นฐานข้อมูลเก่า แต่ได้รับการเลี้ยงดูในสภาพแวดล้อมที่มีการจัดการโดยไม่จำเป็นต้องทำงานกับฮาร์ดแวร์
บันทึก. ตัวอย่างนี้จัดทำขึ้นสำหรับสภาพแวดล้อม AWS แต่อะนาล็อกยังมีอยู่ใน Microsoft Azure, Google Cloud หรือ Yandex.Cloud
มีอะไรใหม่เกี่ยวกับเรื่องนี้? ในปี 2020 ไม่มีสิ่งนี้
แนวคิดแบบไร้เซิร์ฟเวอร์
มีอะไรใหม่ในตลาดในปี 2020 คือโซลูชันแบบไร้เซิร์ฟเวอร์หรือแบบไร้เซิร์ฟเวอร์
ฉันจะพยายามอธิบายว่าสิ่งนี้หมายความว่าอย่างไรโดยใช้ตัวอย่างของบริการปกติหรือแอปพลิเคชันแบ็กเอนด์
ในการปรับใช้แอปพลิเคชันแบ็กเอนด์ปกติ เราซื้อหรือเช่าเซิร์ฟเวอร์ คัดลอกโค้ดลงบนเซิร์ฟเวอร์ เผยแพร่อุปกรณ์ปลายทางภายนอก และชำระค่าบริการค่าเช่า ค่าไฟฟ้า และศูนย์ข้อมูลเป็นประจำ นี่คือโครงการมาตรฐาน
มีวิธีอื่น ๆ ? ด้วยบริการไร้เซิร์ฟเวอร์ที่คุณสามารถทำได้
จุดเน้นของแนวทางนี้คืออะไร: ไม่มีเซิร์ฟเวอร์ ไม่มีการเช่าอินสแตนซ์เสมือนในระบบคลาวด์ด้วยซ้ำ หากต้องการใช้บริการ ให้คัดลอกโค้ด (ฟังก์ชัน) ไปยังพื้นที่เก็บข้อมูลและเผยแพร่ไปยังตำแหน่งข้อมูล จากนั้นเราก็จ่ายสำหรับการเรียกใช้ฟังก์ชันนี้แต่ละครั้ง โดยไม่สนใจฮาร์ดแวร์ที่เรียกใช้ฟังก์ชันนี้โดยสิ้นเชิง
ฉันจะพยายามอธิบายวิธีการนี้ด้วยรูปภาพ
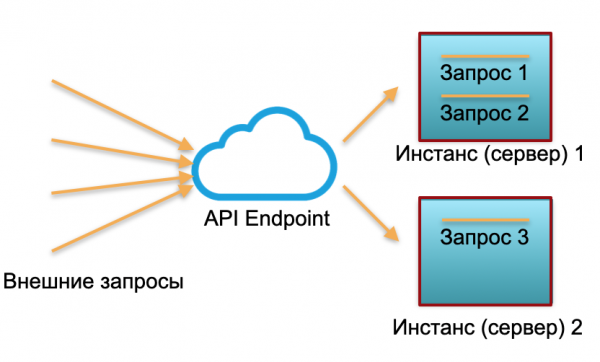
การปรับใช้แบบคลาสสิก. เรามีบริการที่มีภาระแน่นอน เราสร้างสองอินสแตนซ์: เซิร์ฟเวอร์จริงหรืออินสแตนซ์ใน AWS คำขอภายนอกจะถูกส่งไปยังอินสแตนซ์เหล่านี้และประมวลผลที่นั่น
ดังที่คุณเห็นในภาพ เซิร์ฟเวอร์ไม่ได้ถูกกำจัดอย่างเท่าเทียมกัน คำขอหนึ่งใช้งาน 100% มีสองคำขอ และคำขอหนึ่งมีเพียง 50% - ไม่ได้ใช้งานบางส่วน หากคำขอไม่ถึงสามคำขอ แต่ถึง 30 รายการ ระบบทั้งหมดจะไม่สามารถรับมือกับโหลดได้และจะเริ่มช้าลง
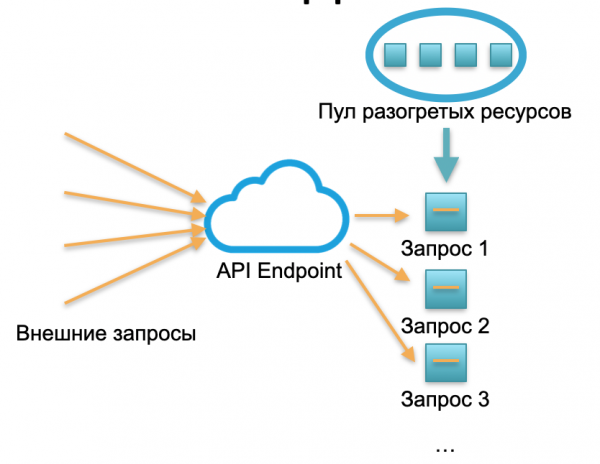
การปรับใช้แบบไร้เซิร์ฟเวอร์. ในสภาพแวดล้อมแบบไร้เซิร์ฟเวอร์ บริการดังกล่าวจะไม่มีอินสแตนซ์หรือเซิร์ฟเวอร์ มีแหล่งทรัพยากรที่ให้ความร้อนจำนวนหนึ่ง - คอนเทนเนอร์ Docker ขนาดเล็กที่เตรียมไว้พร้อมโค้ดฟังก์ชันที่ปรับใช้ ระบบได้รับการร้องขอจากภายนอก และสำหรับแต่ละคำขอ กรอบงานแบบไร้เซิร์ฟเวอร์จะยกคอนเทนเนอร์ขนาดเล็กพร้อมโค้ด: โดยจะประมวลผลคำขอเฉพาะนี้และปิดคอนเทนเนอร์
หนึ่งคำขอ - ยกคอนเทนเนอร์หนึ่งรายการ คำขอ 1000 รายการ - คอนเทนเนอร์ 1000 รายการ และการปรับใช้บนเซิร์ฟเวอร์ฮาร์ดแวร์นั้นเป็นงานของผู้ให้บริการคลาวด์อยู่แล้ว มันถูกซ่อนไว้อย่างสมบูรณ์โดยเฟรมเวิร์กไร้เซิร์ฟเวอร์ ในแนวคิดนี้เราจ่ายค่าโทรทุกครั้ง ตัวอย่างเช่น มีสายเข้ามาหนึ่งสายในหนึ่งวัน - เราจ่ายค่าโทรหนึ่งครั้ง นาทีละล้านสาย - เราจ่ายเป็นล้าน หรือในไม่กี่วินาที สิ่งนี้ก็เกิดขึ้นเช่นกัน
แนวคิดของการเผยแพร่ฟังก์ชันไร้เซิร์ฟเวอร์เหมาะสำหรับบริการไร้สัญชาติ และหากคุณต้องการบริการสถานะ (สถานะ) เราจะเพิ่มฐานข้อมูลให้กับบริการ ในกรณีนี้ เมื่อพูดถึงการทำงานกับสถานะ แต่ละฟังก์ชัน statefull ก็แค่เขียนและอ่านจากฐานข้อมูล นอกจากนี้จากฐานข้อมูลทั้ง XNUMX ประเภทที่อธิบายไว้ตอนต้นบทความ
ข้อจำกัดทั่วไปของฐานข้อมูลเหล่านี้คืออะไร? นี่คือต้นทุนของเซิร์ฟเวอร์คลาวด์หรือฮาร์ดแวร์ที่ใช้งานอยู่ตลอดเวลา (หรือเซิร์ฟเวอร์หลายเครื่อง) ไม่ว่าเราจะใช้ฐานข้อมูลแบบคลาสสิกหรือแบบจัดการ ไม่ว่าเราจะมี Devops และผู้ดูแลระบบหรือไม่ก็ตาม เรายังคงจ่ายค่าฮาร์ดแวร์ ไฟฟ้า และค่าเช่าศูนย์ข้อมูลทุกวันตลอด 24 ชั่วโมง หากเรามีฐานแบบคลาสสิก เราจะจ่ายสำหรับนายและทาส หากเป็นฐานข้อมูลชาร์ดที่มีการโหลดสูง เราจะจ่ายค่าเซิร์ฟเวอร์ 7, 10 หรือ 20 เครื่อง และเราจะจ่ายอย่างต่อเนื่อง
ก่อนหน้านี้การมีอยู่ของเซิร์ฟเวอร์ที่สงวนไว้อย่างถาวรในโครงสร้างต้นทุนถูกมองว่าเป็นสิ่งชั่วร้ายที่จำเป็น ฐานข้อมูลทั่วไปยังมีปัญหาอื่นๆ อีกด้วย เช่น การจำกัดจำนวนการเชื่อมต่อ ข้อจำกัดในการขยายขนาด ฉันทามติเกี่ยวกับการกระจายทางภูมิศาสตร์ ซึ่งสามารถแก้ไขได้ในฐานข้อมูลบางประเภท แต่ไม่ใช่ทั้งหมดพร้อมกันและไม่ใช่ในอุดมคติ
ฐานข้อมูลแบบไร้เซิร์ฟเวอร์-ทฤษฎี
คำถามปี 2020: เป็นไปได้ไหมที่จะสร้างฐานข้อมูลแบบไร้เซิร์ฟเวอร์ด้วย ทุกคนคงเคยได้ยินเกี่ยวกับแบ็กเอนด์แบบไร้เซิร์ฟเวอร์... มาลองทำฐานข้อมูลแบบไร้เซิร์ฟเวอร์กันดูไหม
ฟังดูแปลกเพราะฐานข้อมูลเป็นบริการแบบ statefull ไม่เหมาะมากสำหรับโครงสร้างพื้นฐานแบบไร้เซิร์ฟเวอร์ ในเวลาเดียวกัน สถานะของฐานข้อมูลมีขนาดใหญ่มาก: กิกะไบต์ เทราไบต์ และในฐานข้อมูลเชิงวิเคราะห์แม้แต่เพตาไบต์ มันไม่ง่ายเลยที่จะเลี้ยงมันในคอนเทนเนอร์ Docker ที่มีน้ำหนักเบา
ในทางกลับกัน ฐานข้อมูลสมัยใหม่เกือบทั้งหมดมีตรรกะและส่วนประกอบจำนวนมาก: ธุรกรรม การประสานงานด้านความสมบูรณ์ ขั้นตอน การพึ่งพาเชิงสัมพันธ์ และตรรกะจำนวนมาก สำหรับลอจิกฐานข้อมูลจำนวนมาก สถานะขนาดเล็กก็เพียงพอแล้ว กิกะไบต์และเทราไบต์ถูกใช้โดยตรงโดยส่วนเล็กๆ ของตรรกะฐานข้อมูลที่เกี่ยวข้องกับการดำเนินการค้นหาโดยตรง
ดังนั้น แนวคิดก็คือ: หากส่วนหนึ่งของตรรกะอนุญาตให้มีการดำเนินการแบบไร้สัญชาติ ทำไมไม่แบ่งฐานออกเป็นส่วนที่มีสถานะและไม่มีสถานะ
ไร้เซิร์ฟเวอร์สำหรับโซลูชัน OLAP
มาดูกันว่าการตัดฐานข้อมูลออกเป็นส่วน Stateful และ Stateless จะเป็นอย่างไรโดยใช้ตัวอย่างที่ใช้งานได้จริง
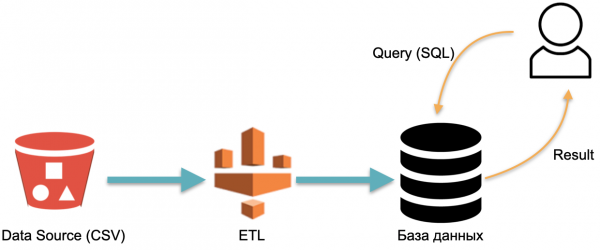
เช่น เรามีฐานข้อมูลเชิงวิเคราะห์: ข้อมูลภายนอก (รูปทรงกระบอกสีแดงด้านซ้าย) กระบวนการ ETL ที่โหลดข้อมูลลงในฐานข้อมูล และนักวิเคราะห์ที่ส่งคำสั่ง SQL ไปยังฐานข้อมูล นี่คือแผนการดำเนินงานคลังข้อมูลแบบคลาสสิก
ในรูปแบบนี้ ETL จะดำเนินการตามเงื่อนไขหนึ่งครั้ง จากนั้นคุณจะต้องจ่ายเงินอย่างต่อเนื่องสำหรับเซิร์ฟเวอร์ที่ฐานข้อมูลทำงานด้วยข้อมูลที่เต็มไปด้วย ETL เพื่อที่จะมีบางสิ่งที่จะส่งแบบสอบถามไป
มาดูแนวทางอื่นที่นำมาใช้ใน AWS Athena Serverless ไม่มีฮาร์ดแวร์เฉพาะถาวรสำหรับจัดเก็บข้อมูลที่ดาวน์โหลด แทนสิ่งนี้:
- ผู้ใช้ส่งแบบสอบถาม SQL ไปยัง Athena เครื่องมือเพิ่มประสิทธิภาพ Athena จะวิเคราะห์การสืบค้น SQL และค้นหาที่เก็บข้อมูลเมตา (ข้อมูลเมตา) เพื่อหาข้อมูลเฉพาะที่จำเป็นในการดำเนินการสืบค้น
- เครื่องมือเพิ่มประสิทธิภาพตามข้อมูลที่รวบรวมจะดาวน์โหลดข้อมูลที่จำเป็นจากแหล่งภายนอกไปยังที่เก็บข้อมูลชั่วคราว (ฐานข้อมูลชั่วคราว)
- การสืบค้น SQL จากผู้ใช้จะดำเนินการในพื้นที่เก็บข้อมูลชั่วคราว และผลลัพธ์จะถูกส่งกลับไปยังผู้ใช้
- พื้นที่เก็บข้อมูลชั่วคราวถูกล้างและปล่อยทรัพยากรแล้ว
ในสถาปัตยกรรมนี้ เราจ่ายเฉพาะกระบวนการดำเนินการตามคำขอเท่านั้น ไม่มีการร้องขอ - ไม่มีค่าใช้จ่าย
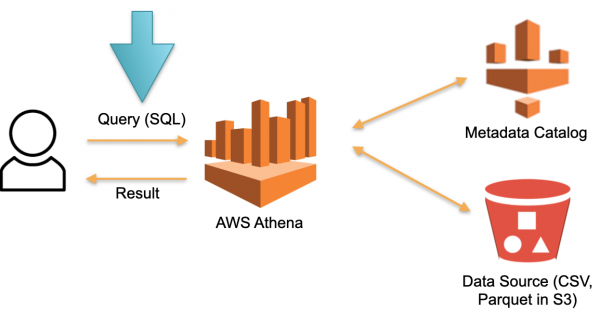
นี่เป็นแนวทางการทำงานและนำไปใช้ไม่เพียงแต่ใน Athena Serverless เท่านั้น แต่ยังนำไปใช้ใน Redshift Spectrum (ใน AWS) ด้วย
ตัวอย่าง Athena แสดงให้เห็นว่าฐานข้อมูล Serverless ทำงานกับการสืบค้นจริงที่มีข้อมูลหลายสิบและหลายร้อยเทราไบต์ หลายร้อยเทราไบต์จะต้องใช้เซิร์ฟเวอร์หลายร้อยเครื่อง แต่เราไม่ต้องเสียค่าใช้จ่าย - เราจ่ายสำหรับคำขอ ความเร็วของแต่ละคำขอนั้นต่ำ (มาก) เมื่อเทียบกับฐานข้อมูลการวิเคราะห์เฉพาะทางเช่น Vertica แต่เราไม่จ่ายเงินสำหรับช่วงหยุดทำงาน
ฐานข้อมูลดังกล่าวใช้ได้กับการสืบค้นเฉพาะกิจเชิงวิเคราะห์ซึ่งพบไม่บ่อยนัก ตัวอย่างเช่น เมื่อเราตัดสินใจทดสอบสมมติฐานกับข้อมูลจำนวนมหาศาลโดยธรรมชาติ Athena เหมาะสำหรับกรณีเหล่านี้ สำหรับการร้องขอเป็นประจำ ระบบดังกล่าวมีราคาแพง ในกรณีนี้ ให้แคชข้อมูลในโซลูชันพิเศษบางอย่าง
ไร้เซิร์ฟเวอร์สำหรับโซลูชัน OLTP
ตัวอย่างก่อนหน้านี้ดูที่งาน OLAP (เชิงวิเคราะห์) ตอนนี้เรามาดูงาน OLTP กัน
ลองจินตนาการถึง PostgreSQL หรือ MySQL ที่ปรับขนาดได้ มาสร้าง PostgreSQL หรือ MySQL อินสแตนซ์ที่มีการจัดการเป็นประจำด้วยทรัพยากรน้อยที่สุดกันดีกว่า เมื่ออินสแตนซ์ได้รับโหลดมากขึ้น เราจะเชื่อมต่อแบบจำลองเพิ่มเติมซึ่งเราจะกระจายส่วนหนึ่งของโหลดการอ่านให้ หากไม่มีคำขอหรือโหลด เราจะปิดการจำลอง อินสแตนซ์แรกคือต้นแบบ และส่วนที่เหลือเป็นแบบจำลอง
แนวคิดนี้ถูกนำไปใช้ในฐานข้อมูลที่เรียกว่า Aurora Serverless AWS หลักการนั้นง่ายมาก: คำขอจากแอปพลิเคชันภายนอกจะได้รับการยอมรับโดยฟลีตพร็อกซี เมื่อเห็นโหลดเพิ่มขึ้น ระบบจะจัดสรรทรัพยากรการประมวลผลจากอินสแตนซ์ขั้นต่ำที่วอร์มไว้ล่วงหน้า - การเชื่อมต่อจะทำได้โดยเร็วที่สุด การปิดใช้งานอินสแตนซ์เกิดขึ้นในลักษณะเดียวกัน
ภายในออโรร่ามีแนวคิดเรื่อง Aurora Capacity Unit, ACU นี่คือ (ตามเงื่อนไข) อินสแตนซ์ (เซิร์ฟเวอร์) ACU แต่ละตัวสามารถเป็นแบบหลักหรือแบบรองได้ หน่วยความจุแต่ละหน่วยมี RAM, โปรเซสเซอร์ และดิสก์ขั้นต่ำของตัวเอง ดังนั้น คนหนึ่งคือผู้เชี่ยวชาญ ส่วนที่เหลือเป็นแบบจำลองแบบอ่านอย่างเดียว
จำนวนหน่วยความจุ Aurora ที่ทำงานอยู่นี้เป็นพารามิเตอร์ที่กำหนดค่าได้ ปริมาณขั้นต่ำอาจเป็นหนึ่งหรือศูนย์ (ในกรณีนี้ ฐานข้อมูลจะไม่ทำงานหากไม่มีคำขอ)
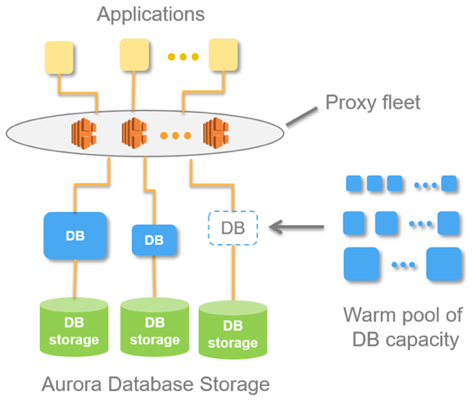
เมื่อฐานได้รับคำขอ ฟลีตพร็อกซีจะเพิ่ม Aurora CapacityUnits ซึ่งเป็นการเพิ่มทรัพยากรประสิทธิภาพของระบบ ความสามารถในการเพิ่มและลดทรัพยากรทำให้ระบบสามารถ "จัดการ" ทรัพยากรได้: แสดง ACU แต่ละตัวโดยอัตโนมัติ (แทนที่ด้วยอันใหม่) และเผยแพร่การอัปเดตปัจจุบันทั้งหมดไปยังทรัพยากรที่ถูกถอนออก
ฐาน Aurora Serverless สามารถปรับขนาดโหลดการอ่านได้ แต่เอกสารไม่ได้บอกสิ่งนี้โดยตรง อาจรู้สึกเหมือนว่าพวกเขาสามารถยกระดับปรมาจารย์หลายคนได้ ไม่มีเวทย์มนตร์
ฐานข้อมูลนี้เหมาะอย่างยิ่งที่จะหลีกเลี่ยงการใช้จ่ายเงินจำนวนมากกับระบบที่มีการเข้าถึงที่คาดเดาไม่ได้ ตัวอย่างเช่น เมื่อสร้างเว็บไซต์ MVP หรือการตลาดนามบัตร เรามักจะไม่คาดหวังว่าจะมีภาระงานที่มั่นคง ดังนั้น หากไม่มีการเข้าถึง เราก็ไม่ต้องจ่ายค่าอินสแตนซ์ เมื่อโหลดที่ไม่คาดคิดเกิดขึ้น เช่น หลังการประชุมหรือแคมเปญโฆษณา ผู้คนจำนวนมากเยี่ยมชมไซต์และโหลดเพิ่มขึ้นอย่างมาก Aurora Serverless จะใช้โหลดนี้โดยอัตโนมัติและเชื่อมต่อทรัพยากรที่ขาดหายไป (ACU) อย่างรวดเร็ว จากนั้นการประชุมก็ผ่านไป ทุกคนลืมเกี่ยวกับต้นแบบ เซิร์ฟเวอร์ (ACU) หยุดทำงาน และค่าใช้จ่ายลดลงเหลือศูนย์อย่างสะดวกสบาย
โซลูชันนี้ไม่เหมาะสำหรับการโหลดสูงที่เสถียร เนื่องจากไม่ได้ปรับขนาดภาระการเขียน การเชื่อมต่อและการตัดการเชื่อมต่อของทรัพยากรทั้งหมดนี้เกิดขึ้นที่สิ่งที่เรียกว่า “มาตราส่วน” ซึ่งเป็นจุดที่ธุรกรรมหรือตารางชั่วคราวไม่รองรับฐานข้อมูล ตัวอย่างเช่น ภายในหนึ่งสัปดาห์ จุดปรับขนาดอาจไม่เกิดขึ้น และฐานทำงานบนทรัพยากรเดียวกัน และไม่สามารถขยายหรือหดตัวได้
ไม่มีเวทย์มนตร์ - เป็น PostgreSQL ปกติ แต่กระบวนการเพิ่มเครื่องจักรและยกเลิกการเชื่อมต่อนั้นเป็นไปโดยอัตโนมัติบางส่วน
ไร้เซิร์ฟเวอร์ด้วยการออกแบบ
Aurora Serverless เป็นฐานข้อมูลเก่าที่เขียนใหม่สำหรับระบบคลาวด์เพื่อใช้ประโยชน์จากข้อดีบางประการของ Serverless และตอนนี้ ผมจะบอกคุณเกี่ยวกับฐานซึ่งเดิมเขียนขึ้นสำหรับระบบคลาวด์ สำหรับแนวทางแบบไร้เซิร์ฟเวอร์ - แบบไร้เซิร์ฟเวอร์โดยการออกแบบ ได้รับการพัฒนาทันทีโดยไม่ต้องสันนิษฐานว่าจะทำงานบนเซิร์ฟเวอร์จริง
ฐานนี้เรียกว่าสโนว์เฟลก มันมีสามช่วงตึกที่สำคัญ
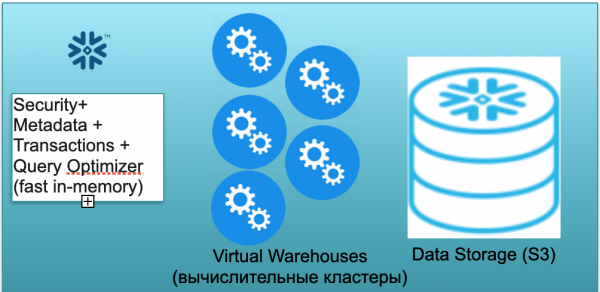
ประการแรกคือบล็อกข้อมูลเมตา นี่คือบริการในหน่วยความจำที่รวดเร็วซึ่งแก้ไขปัญหาด้านความปลอดภัย ข้อมูลเมตา ธุรกรรม และการเพิ่มประสิทธิภาพคิวรี (แสดงในภาพประกอบด้านซ้าย)
บล็อกที่สองคือชุดของกลุ่มการคำนวณเสมือนสำหรับการคำนวณ (ในภาพประกอบมีชุดวงกลมสีน้ำเงิน)
บล็อกที่สามคือระบบจัดเก็บข้อมูลที่ใช้ S3 S3 คือพื้นที่จัดเก็บอ็อบเจ็กต์ไร้มิติใน AWS เหมือนกับ Dropbox สำหรับธุรกิจไร้มิติ
มาดูกันว่าสโนว์เฟลกทำงานอย่างไรโดยถือว่าสตาร์ทเย็น นั่นคือมีฐานข้อมูลข้อมูลถูกโหลดเข้าไปไม่มีการสืบค้นที่รันอยู่ ดังนั้น หากไม่มีคำขอไปยังฐานข้อมูล เราก็ได้ยกระดับบริการข้อมูลเมตาในหน่วยความจำที่รวดเร็ว (บล็อกแรก) และเรามีพื้นที่จัดเก็บข้อมูล S3 ซึ่งจัดเก็บข้อมูลตาราง โดยแบ่งออกเป็นส่วนที่เรียกว่าไมโครพาร์ติชั่น เพื่อความง่าย: หากตารางมีธุรกรรม ไมโครพาร์ติชั่นคือวันของการทำธุรกรรม ทุกวันจะมีพาร์ติชั่นแยกกัน เป็นไฟล์แยกกัน และเมื่อฐานข้อมูลทำงานในโหมดนี้ คุณจะต้องจ่ายเฉพาะพื้นที่ที่ข้อมูลครอบครองเท่านั้น นอกจากนี้ อัตราต่อที่นั่งยังต่ำมาก (โดยเฉพาะอย่างยิ่งเมื่อคำนึงถึงการบีบอัดที่มีนัยสำคัญ) บริการข้อมูลเมตายังทำงานอย่างต่อเนื่อง แต่คุณไม่จำเป็นต้องใช้ทรัพยากรจำนวนมากเพื่อเพิ่มประสิทธิภาพการสืบค้น และบริการนี้ถือได้ว่าเป็นแชร์แวร์
ตอนนี้ ลองจินตนาการว่ามีผู้ใช้มาที่ฐานข้อมูลของเราและส่งข้อความค้นหา SQL การสืบค้น SQL จะถูกส่งไปยังบริการ Metadata เพื่อการประมวลผลทันที ดังนั้น เมื่อได้รับคำขอ บริการนี้จะวิเคราะห์คำขอ ข้อมูลที่มีอยู่ การอนุญาตของผู้ใช้ และหากทุกอย่างเรียบร้อยดี ก็จะจัดทำแผนสำหรับการประมวลผลคำขอ
ถัดไป บริการจะเริ่มต้นการเปิดตัวคลัสเตอร์คอมพิวเตอร์ คลัสเตอร์การประมวลผลคือคลัสเตอร์ของเซิร์ฟเวอร์ที่ทำการคำนวณ นั่นคือนี่คือคลัสเตอร์ที่สามารถประกอบด้วย 1 เซิร์ฟเวอร์ 2 เซิร์ฟเวอร์ 4, 8, 16, 32 - มากเท่าที่คุณต้องการ คุณส่งคำขอและการเปิดตัวคลัสเตอร์นี้จะเริ่มต้นทันที ใช้เวลาไม่กี่วินาทีจริงๆ
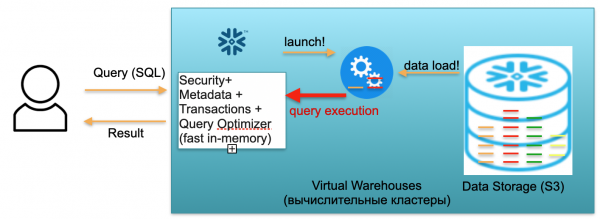
ถัดไป หลังจากที่คลัสเตอร์เริ่มต้นแล้ว ไมโครพาร์ติชันที่จำเป็นในการประมวลผลคำขอของคุณจะเริ่มคัดลอกไปยังคลัสเตอร์จาก S3 นั่นคือ ลองจินตนาการว่าในการรันคิวรี SQL คุณต้องมีพาร์ติชั่นสองพาร์ติชั่นจากตารางหนึ่งและอีกพาร์ติชั่นจากตารางที่สอง ในกรณีนี้ เฉพาะพาร์ติชันที่จำเป็นสามพาร์ติชันเท่านั้นที่จะถูกคัดลอกไปยังคลัสเตอร์ และไม่ใช่ทุกตารางทั้งหมด นั่นคือเหตุผล และแน่นอน เนื่องจากทุกอย่างตั้งอยู่ภายในศูนย์ข้อมูลเดียวและเชื่อมต่อกันด้วยช่องทางที่รวดเร็วมาก กระบวนการถ่ายโอนทั้งหมดจึงเกิดขึ้นอย่างรวดเร็ว: ในไม่กี่วินาที น้อยมากในไม่กี่นาที เว้นแต่ว่าเรากำลังพูดถึงคำขอที่ร้ายแรงบางอย่าง ดังนั้น ไมโครพาร์ติชันจะถูกคัดลอกไปยังคลัสเตอร์การประมวลผล และเมื่อเสร็จสิ้น การสืบค้น SQL จะถูกดำเนินการบนคลัสเตอร์การประมวลผลนี้ ผลลัพธ์ของคำขอนี้อาจเป็นหนึ่งบรรทัด หลายบรรทัด หรือหนึ่งตารางก็ได้ โดยจะส่งไปยังผู้ใช้ภายนอกเพื่อให้เขาสามารถดาวน์โหลด แสดงไว้ในเครื่องมือ BI หรือใช้ในลักษณะอื่นได้
แบบสอบถาม SQL แต่ละรายการไม่เพียงแต่สามารถอ่านการรวมจากข้อมูลที่โหลดก่อนหน้านี้ แต่ยังโหลด/สร้างข้อมูลใหม่ในฐานข้อมูลอีกด้วย นั่นคืออาจเป็นแบบสอบถามที่แทรกบันทึกใหม่ลงในตารางอื่นซึ่งนำไปสู่การปรากฏตัวของพาร์ติชันใหม่บนคลัสเตอร์คอมพิวเตอร์ซึ่งในทางกลับกันจะถูกบันทึกโดยอัตโนมัติในที่เก็บข้อมูล S3 เดียว
สถานการณ์ที่อธิบายไว้ข้างต้น ตั้งแต่การมาถึงของผู้ใช้ไปจนถึงการเพิ่มคลัสเตอร์ การโหลดข้อมูล การดำเนินการค้นหา การรับผลลัพธ์ จะได้รับค่าตอบแทนในอัตรานาทีในการใช้คลัสเตอร์คอมพิวเตอร์เสมือนที่เพิ่มขึ้น และคลังสินค้าเสมือน อัตราจะแตกต่างกันไปขึ้นอยู่กับโซน AWS และขนาดคลัสเตอร์ แต่โดยเฉลี่ยจะอยู่ที่ไม่กี่ดอลลาร์ต่อชั่วโมง คลัสเตอร์ที่มีสี่เครื่องมีราคาแพงเป็นสองเท่าของคลัสเตอร์ที่มีสองเครื่อง และคลัสเตอร์ที่มีแปดเครื่องยังคงมีราคาแพงกว่าสองเท่า มีตัวเลือกเครื่องจักรให้เลือก 16, 32 เครื่อง ขึ้นอยู่กับความซับซ้อนของคำขอ แต่คุณจ่ายเฉพาะนาทีเหล่านั้นเมื่อคลัสเตอร์กำลังทำงานจริง เพราะเมื่อไม่มีการร้องขอ คุณจะละมือออก และหลังจากรอประมาณ 5-10 นาที (พารามิเตอร์ที่กำหนดค่าได้) คลัสเตอร์จะหายไปเอง เพิ่มทรัพยากรและเป็นอิสระ
สถานการณ์ที่สมจริงโดยสิ้นเชิงคือเมื่อคุณส่งคำขอ คลัสเตอร์จะปรากฏขึ้น พูดง่ายๆ ก็คือในหนึ่งนาที นับอีกนาที จากนั้นอีกห้านาทีในการปิดระบบ และสุดท้ายคุณจะต้องจ่ายเงินสำหรับการดำเนินการเจ็ดนาทีของคลัสเตอร์นี้ และ ไม่ใช่เป็นเดือนหรือเป็นปี
สถานการณ์แรกที่อธิบายโดยใช้ Snowflake ในการตั้งค่าผู้ใช้คนเดียว ตอนนี้ลองจินตนาการว่ามีผู้ใช้จำนวนมากซึ่งใกล้เคียงกับสถานการณ์จริงมากขึ้น
สมมติว่าเรามีนักวิเคราะห์และรายงาน Tableau จำนวนมากที่โจมตีฐานข้อมูลของเราอย่างต่อเนื่องด้วยการสืบค้น SQL แบบง่ายเชิงวิเคราะห์จำนวนมาก
นอกจากนี้ สมมติว่าเรามี Data Scientist ที่มีความคิดสร้างสรรค์ซึ่งพยายามทำสิ่งมหัศจรรย์ด้วยข้อมูล ทำงานด้วยข้อมูลหลายสิบเทราไบต์ วิเคราะห์ข้อมูลนับพันล้านล้านล้านแถว
สำหรับปริมาณงานสองประเภทที่อธิบายไว้ข้างต้น Snowflake ช่วยให้คุณสามารถเพิ่มคลัสเตอร์การประมวลผลอิสระหลายกลุ่มที่มีความจุต่างกันได้ นอกจากนี้ คลัสเตอร์การประมวลผลเหล่านี้ยังทำงานแยกจากกัน แต่มีข้อมูลทั่วไปที่สอดคล้องกัน
สำหรับการสืบค้นแบบ light จำนวนมาก คุณสามารถเพิ่มคลัสเตอร์ขนาดเล็กได้ 2-3 คลัสเตอร์ โดยแต่ละคลัสเตอร์จะมีประมาณ 2 เครื่อง ลักษณะการทำงานนี้สามารถนำไปใช้ได้ เหนือสิ่งอื่นใด โดยใช้การตั้งค่าอัตโนมัติ ดังนั้นคุณจึงพูดว่า “เกล็ดหิมะ ยกกระจุกเล็กๆ ขึ้น หากโหลดเพิ่มขึ้นเหนือพารามิเตอร์บางตัว ให้เพิ่มวินาทีที่สามที่คล้ายกัน เมื่อภาระเริ่มลดลง ให้ดับส่วนเกิน” ดังนั้นไม่ว่านักวิเคราะห์จะมาเริ่มดูรายงานสักกี่คน ทุกคนก็มีทรัพยากรเพียงพอ
ในเวลาเดียวกัน หากนักวิเคราะห์หลับและไม่มีใครดูรายงาน คลัสเตอร์ก็อาจจะมืดมิดและคุณหยุดจ่ายเงินสำหรับรายงานเหล่านั้น
ในเวลาเดียวกัน สำหรับการสืบค้นจำนวนมาก (จาก Data Scientists) คุณสามารถเพิ่มคลัสเตอร์ขนาดใหญ่มากได้หนึ่งคลัสเตอร์สำหรับ 32 เครื่อง คลัสเตอร์นี้จะได้รับการชำระเงินเฉพาะนาทีและชั่วโมงเหล่านั้นเมื่อคำขอขนาดใหญ่ของคุณทำงานอยู่ที่นั่น
โอกาสที่อธิบายไว้ข้างต้นช่วยให้คุณสามารถแบ่งไม่เพียงแต่ 2 เท่านั้น แต่ยังแบ่งประเภทงานออกเป็นคลัสเตอร์ได้มากขึ้น (ETL, การตรวจสอบ, รายงานการทำให้เป็นรูปธรรม,...)
มาสรุปสโนว์เฟลกกันดีกว่า ฐานเป็นการผสมผสานแนวคิดที่สวยงามและการนำไปปฏิบัติที่ใช้การได้ ที่ ManyChat เราใช้ Snowflake เพื่อวิเคราะห์ข้อมูลทั้งหมดที่เรามี เราไม่มีสามคลัสเตอร์ตามตัวอย่าง แต่มีตั้งแต่ 5 ถึง 9 คลัสเตอร์ที่มีขนาดแตกต่างกัน เรามีเครื่องจักรทั่วไป 16 เครื่อง 2 เครื่อง และ 1 เครื่องขนาดเล็กพิเศษสำหรับงานบางอย่าง กระจายโหลดได้สำเร็จและช่วยให้เราประหยัดได้มาก
ฐานข้อมูลปรับขนาดโหลดการอ่านและการเขียนได้สำเร็จ นี่เป็นความแตกต่างอย่างมากและเป็นความก้าวหน้าครั้งใหญ่เมื่อเทียบกับ "ออโรร่า" แบบเดียวกันซึ่งรับภาระการอ่านเท่านั้น Snowflake ช่วยให้คุณสามารถปรับขนาดปริมาณงานเขียนของคุณด้วยคลัสเตอร์การประมวลผลเหล่านี้ ตามที่ฉันได้กล่าวไปแล้ว เราใช้หลายคลัสเตอร์ใน ManyChat คลัสเตอร์ขนาดเล็กและขนาดเล็กมากส่วนใหญ่จะใช้สำหรับ ETL สำหรับการโหลดข้อมูล และนักวิเคราะห์ก็อาศัยอยู่ในคลัสเตอร์ขนาดกลางอยู่แล้ว ซึ่งไม่ได้รับผลกระทบจากโหลด ETL เลย ดังนั้นจึงทำงานได้อย่างรวดเร็วมาก
ดังนั้นฐานข้อมูลจึงเหมาะสมอย่างยิ่งสำหรับงาน OLAP อย่างไรก็ตาม น่าเสียดายที่ยังไม่สามารถใช้ได้กับปริมาณงาน OLTP ประการแรก ฐานข้อมูลนี้เป็นแบบเรียงเป็นแนว โดยมีผลที่ตามมาทั้งหมด ประการที่สอง วิธีการนั้นเอง เมื่อคุณเพิ่มคลัสเตอร์คอมพิวเตอร์และเพิ่มข้อมูลจำนวนมากสำหรับแต่ละคำขอ (หากจำเป็น) น่าเสียดายที่ยังไม่เร็วพอสำหรับการโหลด OLTP การรอวินาทีสำหรับงาน OLAP เป็นเรื่องปกติ แต่สำหรับงาน OLTP จะยอมรับไม่ได้ 100 ms จะดีกว่า หรือ 10 ms จะดีกว่า
ทั้งหมด
ฐานข้อมูลแบบไร้เซิร์ฟเวอร์สามารถทำได้โดยการแบ่งฐานข้อมูลออกเป็นส่วนไร้สถานะและแบบเก็บสถานะ คุณอาจสังเกตเห็นว่าในตัวอย่างข้างต้นทั้งหมด ส่วน Stateful นั้นค่อนข้างจะพูดคือจัดเก็บพาร์ติชั่นขนาดเล็กใน S3 และ Stateless เป็นตัวเพิ่มประสิทธิภาพ โดยทำงานร่วมกับเมทาดาทา จัดการปัญหาด้านความปลอดภัยที่สามารถหยิบยกขึ้นมาเป็นบริการไร้สัญชาติแบบน้ำหนักเบาอิสระ
การดำเนินการสืบค้น SQL ยังถือเป็นบริการสถานะแสงที่สามารถปรากฏขึ้นในโหมดไร้เซิร์ฟเวอร์ เช่น คลัสเตอร์คอมพิวเตอร์ Snowflake ดาวน์โหลดเฉพาะข้อมูลที่จำเป็น ดำเนินการสืบค้น และ "ดับลง"
ฐานข้อมูลระดับการผลิตแบบไร้เซิร์ฟเวอร์พร้อมให้ใช้งานแล้ว และกำลังทำงานอยู่ ฐานข้อมูลแบบไร้เซิร์ฟเวอร์เหล่านี้พร้อมที่จะจัดการงาน OLAP แล้ว น่าเสียดาย สำหรับงาน OLTP พวกมันถูกใช้... โดยมีความแตกต่าง เนื่องจากมีข้อจำกัด ในด้านหนึ่งนี่คือลบ แต่ในทางกลับกัน นี่คือโอกาส บางทีผู้อ่านคนใดคนหนึ่งอาจพบวิธีสร้างฐานข้อมูล OLTP โดยไม่ต้องใช้เซิร์ฟเวอร์โดยสมบูรณ์ โดยไม่มีข้อจำกัดของ Aurora
ฉันหวังว่าคุณจะพบว่ามันน่าสนใจ Serverless คืออนาคต :)
ที่มา: will.com
