

ผู้ใช้ของเราเขียนข้อความถึงกันโดยไม่รู้สึกเหนื่อยล้า

นั่นค่อนข้างมาก หากคุณตั้งใจที่จะอ่านข้อความทั้งหมดของผู้ใช้ทั้งหมด อาจต้องใช้เวลามากกว่า 150 ปี โดยมีเงื่อนไขว่าคุณเป็นผู้อ่านที่ค่อนข้างเชี่ยวชาญและใช้เวลาไม่เกินหนึ่งวินาทีในแต่ละข้อความ
ด้วยปริมาณข้อมูลดังกล่าว จึงจำเป็นอย่างยิ่งที่จะต้องสร้างตรรกะสำหรับการจัดเก็บและการเข้าถึงข้อมูลอย่างเหมาะสมที่สุด มิฉะนั้นในช่วงเวลาที่ไม่วิเศษเพียงชั่วครู่อาจชัดเจนว่าในไม่ช้าทุกอย่างจะผิดพลาด
สำหรับเรา ช่วงเวลานี้เกิดขึ้นเมื่อหนึ่งปีครึ่งที่แล้ว เรามาถึงสิ่งนี้ได้อย่างไรและเกิดอะไรขึ้นในท้ายที่สุด - เราบอกคุณตามลำดับ
พื้นหลัง
ในการใช้งานครั้งแรก ข้อความ VKontakte ทำงานร่วมกับแบ็กเอนด์ PHP และ MySQL ร่วมกัน นี่เป็นวิธีแก้ปัญหาตามปกติสำหรับเว็บไซต์นักเรียนขนาดเล็ก อย่างไรก็ตาม ไซต์นี้เติบโตอย่างควบคุมไม่ได้และเริ่มต้องการการเพิ่มประสิทธิภาพโครงสร้างข้อมูลด้วยตัวมันเอง
ในตอนท้ายของปี 2009 มีการเขียนที่เก็บ text-engine แห่งแรกและในปี 2010 ข้อความก็ถูกถ่ายโอนไปยังที่เก็บดังกล่าว
ในโปรแกรมส่งข้อความ ข้อความจะถูกจัดเก็บไว้ในรายการ ซึ่งเป็น "กล่องจดหมาย" ชนิดหนึ่ง แต่ละรายการดังกล่าวถูกกำหนดโดย uid - ผู้ใช้ที่เป็นเจ้าของข้อความเหล่านี้ทั้งหมด ข้อความมีชุดคุณลักษณะ: ตัวระบุคู่สนทนา ข้อความ ไฟล์แนบ และอื่นๆ ตัวระบุข้อความภายใน “กล่อง” คือ local_id ซึ่งไม่เคยเปลี่ยนแปลงและถูกกำหนดตามลำดับสำหรับข้อความใหม่ “กล่อง” มีความเป็นอิสระและไม่มีการซิงโครไนซ์ระหว่างกันภายในเอ็นจิ้น การสื่อสารระหว่างกล่องเหล่านั้นเกิดขึ้นที่ระดับ PHP คุณสามารถดูโครงสร้างข้อมูลและความสามารถของ text-engine ได้จากภายใน .
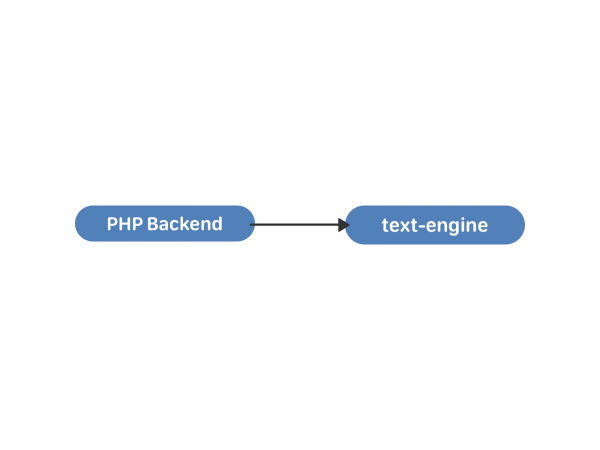
ซึ่งก็เพียงพอแล้วสำหรับการโต้ตอบระหว่างผู้ใช้สองคน คาดเดาสิ่งที่เกิดขึ้นต่อไป?
ในเดือนพฤษภาคม 2011 VKontakte ได้แนะนำการสนทนากับผู้เข้าร่วมหลายคน - การแชทหลายทาง เพื่อทำงานร่วมกับพวกเขา เราได้สร้างคลัสเตอร์ใหม่ขึ้นมาสองกลุ่ม ได้แก่ แชทสำหรับสมาชิกและสมาชิกแชท อันแรกเก็บข้อมูลเกี่ยวกับการแชทตามผู้ใช้ ส่วนอันที่สองเก็บข้อมูลเกี่ยวกับผู้ใช้โดยการแชท นอกเหนือจากรายชื่อแล้ว ยังรวมถึง ตัวอย่างเช่น ผู้ใช้ที่เชิญ และเวลาที่เพิ่มพวกเขาในการแชท
“PHP มาส่งข้อความไปที่แชทกันเถอะ” ผู้ใช้กล่าว
“เอาน่า {username}” PHP กล่าว
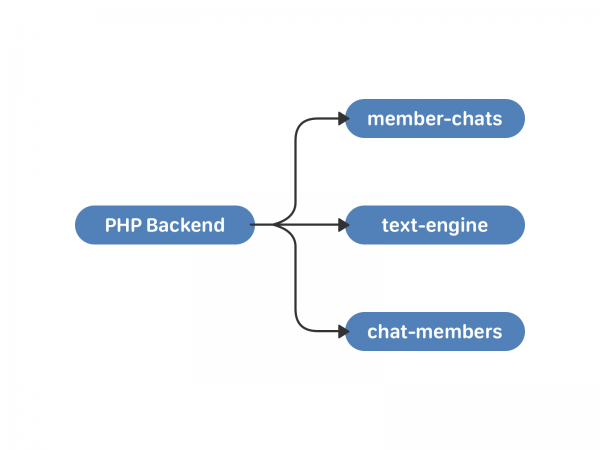
โครงการนี้มีข้อเสียอยู่ การซิงโครไนซ์ยังคงเป็นความรับผิดชอบของ PHP การแชทจำนวนมากและผู้ใช้ที่ส่งข้อความถึงพวกเขาพร้อมกันถือเป็นเรื่องราวที่อันตราย เนื่องจากอินสแตนซ์ของโปรแกรมส่งข้อความขึ้นอยู่กับ uid ผู้เข้าร่วมการแชทจึงอาจได้รับข้อความเดียวกันในเวลาที่ต่างกัน ใครๆ ก็สามารถอยู่กับสิ่งนี้ได้หากความก้าวหน้ายังคงอยู่ แต่นั่นจะไม่เกิดขึ้น
เมื่อปลายปี 2015 เราได้เปิดตัวข้อความชุมชน และเมื่อต้นปี 2016 เราได้เปิดตัว API สำหรับพวกเขา ด้วยการถือกำเนิดของแชทบอทขนาดใหญ่ในชุมชน จึงเป็นไปได้ที่จะลืมแม้กระทั่งการกระจายโหลด
บอทที่ดีจะสร้างข้อความหลายล้านข้อความต่อวัน แม้แต่ผู้ใช้ที่พูดเก่งที่สุดก็ไม่สามารถอวดสิ่งนี้ได้ ซึ่งหมายความว่าบางกรณีของ text-engine ที่บอทดังกล่าวอาศัยอยู่เริ่มประสบปัญหาอย่างเต็มที่
เอ็นจิ้นข้อความในปี 2016 คือ 100 อินสแตนซ์ของสมาชิกแชทและการแชทของสมาชิก และเอ็นจิ้นข้อความ 8000 ตัว พวกเขาโฮสต์บนเซิร์ฟเวอร์นับพันเครื่อง โดยแต่ละเซิร์ฟเวอร์มีหน่วยความจำ 64 GB เพื่อเป็นมาตรการฉุกเฉินครั้งแรก เราได้เพิ่มหน่วยความจำอีก 32 GB เราประมาณการการคาดการณ์ หากไม่มีการเปลี่ยนแปลงครั้งใหญ่ ก็เพียงพอแล้วสำหรับอีกปีหนึ่ง คุณต้องมีฮาร์ดแวร์หรือปรับฐานข้อมูลให้เหมาะสมด้วยตนเอง
เนื่องจากธรรมชาติของสถาปัตยกรรม การเพิ่มฮาร์ดแวร์เป็นทวีคูณจึงสมเหตุสมผลเท่านั้น นั่นคืออย่างน้อยก็เพิ่มจำนวนรถยนต์เป็นสองเท่า - แน่นอนว่านี่เป็นเส้นทางที่ค่อนข้างแพง เราจะเพิ่มประสิทธิภาพ
แนวคิดใหม่
สาระสำคัญของแนวทางใหม่คือการแชท แชทมีรายการข้อความที่เกี่ยวข้อง ผู้ใช้มีรายการแชท
ขั้นต่ำที่ต้องการคือฐานข้อมูลใหม่สองฐานข้อมูล:
- โปรแกรมแชท นี่คือที่เก็บเวกเตอร์การแชท การแชทแต่ละครั้งจะมีเวกเตอร์ข้อความที่เกี่ยวข้องกัน แต่ละข้อความมีข้อความและตัวระบุข้อความที่ไม่ซ้ำกันภายในแชท - chat_local_id
- ผู้ใช้เครื่องยนต์ นี่คือที่เก็บข้อมูลเวกเตอร์ของผู้ใช้ - ลิงก์ไปยังผู้ใช้ ผู้ใช้แต่ละคนมีเวกเตอร์ของ peer_id (คู่สนทนา - ผู้ใช้อื่น การสนทนาหลายรายการ หรือชุมชน) และเวกเตอร์ของข้อความ แต่ละ peer_id มีเวกเตอร์ของข้อความที่เกี่ยวข้องกัน แต่ละข้อความมี chat_local_id และ ID ข้อความเฉพาะสำหรับผู้ใช้นั้น - user_local_id
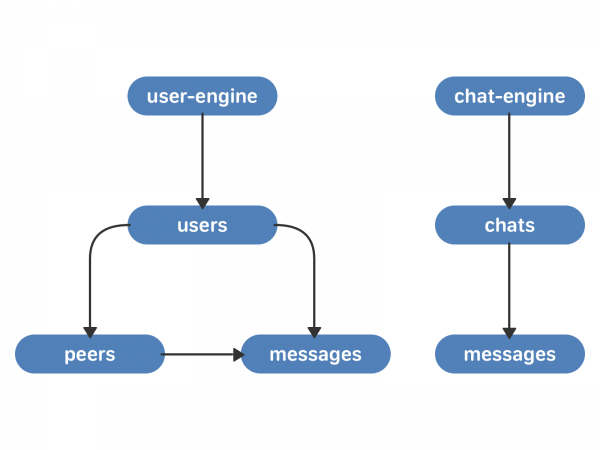
คลัสเตอร์ใหม่สื่อสารกันโดยใช้ TCP - สิ่งนี้ทำให้แน่ใจได้ว่าลำดับคำขอจะไม่เปลี่ยนแปลง คำขอและการยืนยันจะถูกบันทึกไว้ในฮาร์ดไดรฟ์ - เพื่อให้เราสามารถกู้คืนสถานะของคิวได้ตลอดเวลาหลังจากเกิดความล้มเหลวหรือรีสตาร์ทเครื่องยนต์ เนื่องจากกลไกผู้ใช้และเครื่องมือแชทมีขนาด 4 ส่วนแต่ละส่วน คิวคำขอระหว่างคลัสเตอร์จึงจะถูกกระจายเท่า ๆ กัน (แต่ในความเป็นจริงไม่มีเลย - และทำงานเร็วมาก)
การทำงานกับดิสก์ในฐานข้อมูลของเราในกรณีส่วนใหญ่จะขึ้นอยู่กับการรวมกันของบันทึกการเปลี่ยนแปลงแบบไบนารี (binlog) สแน็ปช็อตแบบคงที่ และรูปภาพบางส่วนในหน่วยความจำ การเปลี่ยนแปลงในระหว่างวันจะถูกเขียนลงใน binlog และสแน็ปช็อตของสถานะปัจจุบันจะถูกสร้างขึ้นเป็นระยะ สแน็ปช็อตคือชุดของโครงสร้างข้อมูลที่ปรับให้เหมาะกับวัตถุประสงค์ของเรา ประกอบด้วยส่วนหัว (metaindex ของรูปภาพ) และชุดของ metafiles ส่วนหัวจะถูกจัดเก็บอย่างถาวรใน RAM และระบุตำแหน่งที่จะค้นหาข้อมูลจากสแน็ปช็อต ไฟล์เมตาแต่ละไฟล์มีข้อมูลที่น่าจะจำเป็นในเวลาที่ใกล้เคียงกัน เช่น เกี่ยวข้องกับผู้ใช้รายเดียว เมื่อคุณสอบถามฐานข้อมูลโดยใช้ส่วนหัวของสแน็ปช็อต ระบบจะอ่านเมตาไฟล์ที่จำเป็น จากนั้นจะพิจารณาการเปลี่ยนแปลงใน binlog ที่เกิดขึ้นหลังจากสร้างสแน็ปช็อต คุณสามารถอ่านเพิ่มเติมเกี่ยวกับประโยชน์ของแนวทางนี้ได้ .
ในเวลาเดียวกันข้อมูลในฮาร์ดไดรฟ์จะเปลี่ยนแปลงเพียงวันละครั้งเท่านั้น - ตอนดึกในมอสโกซึ่งมีภาระน้อยที่สุด ด้วยเหตุนี้ (เมื่อรู้ว่าโครงสร้างบนดิสก์คงที่ตลอดทั้งวัน) เราจึงสามารถแทนที่เวกเตอร์ด้วยอาร์เรย์ที่มีขนาดคงที่ได้ - และด้วยเหตุนี้จึงได้รับหน่วยความจำ
การส่งข้อความในรูปแบบใหม่มีลักษณะดังนี้:
- แบ็กเอนด์ PHP จะติดต่อกับเอ็นจิ้นผู้ใช้พร้อมคำขอให้ส่งข้อความ
- พร็อกซีของกลไกผู้ใช้ส่งคำขอไปยังอินสแตนซ์ของโปรแกรมแชทที่ต้องการ ซึ่งส่งกลับไปยังโปรแกรมผู้ใช้ chat_local_id - ตัวระบุเฉพาะของข้อความใหม่ภายในแชทนี้ จากนั้น chat_engine จะเผยแพร่ข้อความไปยังผู้รับทุกคนในการแชท
- user-engine ได้รับ chat_local_id จาก chat-engine และส่งคืน user_local_id เป็น PHP ซึ่งเป็นตัวระบุข้อความเฉพาะสำหรับผู้ใช้รายนี้ ตัวระบุนี้จะถูกใช้เพื่อทำงานกับข้อความผ่าน API เป็นต้น
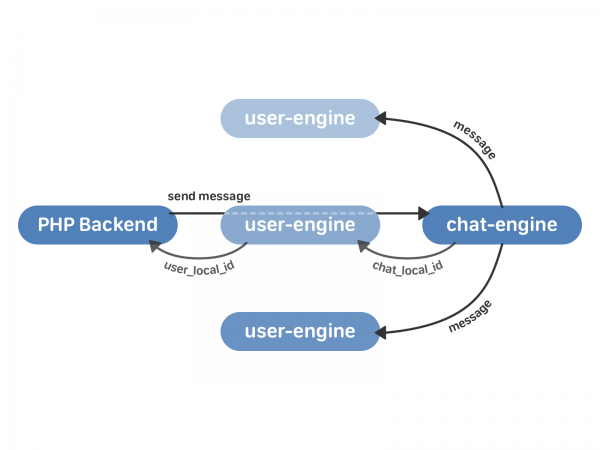
แต่นอกเหนือจากการส่งข้อความจริงๆ แล้ว คุณต้องดำเนินการสิ่งสำคัญอีกสองสามประการ:
- ตัวอย่างเช่น รายการย่อยคือข้อความล่าสุดที่คุณเห็นเมื่อเปิดรายการการสนทนา ข้อความที่ยังไม่ได้อ่าน ข้อความที่มีแท็ก (“สำคัญ”, “สแปม” ฯลฯ )
- การบีบอัดข้อความในโปรแกรมแชท
- การแคชข้อความในเอ็นจิ้นผู้ใช้
- ค้นหา (ผ่านกล่องโต้ตอบทั้งหมดและภายในกล่องโต้ตอบที่ระบุ)
- การอัปเดตแบบเรียลไทม์ (Longpolling)
- บันทึกประวัติเพื่อใช้แคชบนไคลเอนต์มือถือ
รายการย่อยทั้งหมดมีโครงสร้างที่เปลี่ยนแปลงอย่างรวดเร็ว เพื่อทำงานร่วมกับพวกเขาเราใช้ . ตัวเลือกนี้อธิบายได้จากข้อเท็จจริงที่ว่าบางครั้งที่ด้านบนสุดของแผนผัง บางครั้งเราจัดเก็บข้อความทั้งหมดจากสแน็ปช็อต - ตัวอย่างเช่น หลังจากการจัดทำดัชนีใหม่ทุกคืน แผนผังจะประกอบด้วยหนึ่งด้านบนสุดซึ่งประกอบด้วยข้อความทั้งหมดของรายการย่อย Splay tree ทำให้ง่ายต่อการแทรกลงตรงกลางของจุดยอดดังกล่าวโดยไม่ต้องคำนึงถึงการทรงตัว นอกจากนี้ Splay จะไม่จัดเก็บข้อมูลที่ไม่จำเป็น ซึ่งช่วยให้เราประหยัดความจำ
ข้อความเกี่ยวข้องกับข้อมูลจำนวนมาก ซึ่งส่วนใหญ่เป็นข้อความ ซึ่งมีประโยชน์ในการบีบอัด สิ่งสำคัญคือเราสามารถยกเลิกการเก็บถาวรข้อความใดข้อความหนึ่งได้อย่างแม่นยำ ใช้ในการบีบอัดข้อความ ด้วยพฤติกรรมของเราเอง - ตัวอย่างเช่น เรารู้ว่าในข้อความคำที่สลับกับ "ที่ไม่ใช่คำ" - การเว้นวรรค เครื่องหมายวรรคตอน - และเรายังจำคุณสมบัติบางอย่างของการใช้สัญลักษณ์สำหรับภาษารัสเซียด้วย
เนื่องจากมีผู้ใช้น้อยกว่าแชทมาก เพื่อบันทึกคำขอดิสก์การเข้าถึงโดยสุ่มในโปรแกรมแชท เราจึงแคชข้อความในโปรแกรมผู้ใช้
การค้นหาข้อความถูกนำมาใช้เป็นการสืบค้นในแนวทแยงจากกลไกผู้ใช้ไปยังอินสแตนซ์ของกลไกแชททั้งหมดที่มีการแชทของผู้ใช้รายนี้ ผลลัพธ์จะรวมกันอยู่ในเอ็นจิ้นผู้ใช้เอง
รายละเอียดทั้งหมดได้ถูกนำมาพิจารณาแล้ว สิ่งที่เหลืออยู่คือการเปลี่ยนไปใช้รูปแบบใหม่ - และโดยเฉพาะอย่างยิ่งโดยที่ผู้ใช้ไม่สังเกตเห็น
การโยกย้ายข้อมูล
ดังนั้นเราจึงมีเอ็นจิ้นข้อความที่เก็บข้อความตามผู้ใช้ และสมาชิกแชทสองกลุ่มและแชทสมาชิกที่เก็บข้อมูลเกี่ยวกับห้องแชทหลายห้องและผู้ใช้ในห้องเหล่านั้น จะเปลี่ยนจากสิ่งนี้ไปยังเอ็นจิ้นผู้ใช้และแชทเอ็นจิ้นใหม่ได้อย่างไร
การแชทของสมาชิกในรูปแบบเก่าใช้เพื่อการปรับให้เหมาะสมเป็นหลัก เราถ่ายโอนข้อมูลที่จำเป็นไปยังสมาชิกแชทอย่างรวดเร็ว จากนั้นข้อมูลดังกล่าวจะไม่เข้าร่วมในกระบวนการย้ายอีกต่อไป
คิวสำหรับสมาชิกแชท มันมี 100 อินสแตนซ์ ในขณะที่เครื่องมือแชทมี 4 พัน ในการถ่ายโอนข้อมูล คุณต้องปฏิบัติตามข้อกำหนด - ด้วยเหตุนี้ สมาชิกแชทจึงถูกแบ่งออกเป็น 4 ชุดเดียวกัน จากนั้นจึงเปิดใช้งานการอ่าน binlog ของสมาชิกแชทในเครื่องมือแชท
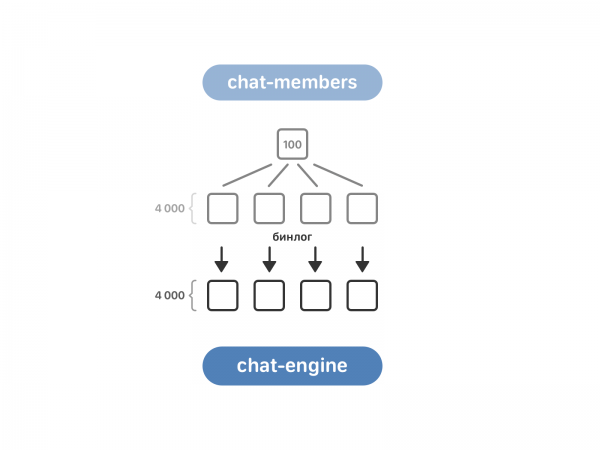
ตอนนี้เครื่องมือแชทรู้เกี่ยวกับการแชทหลายแชทจากสมาชิกแชท แต่ยังไม่รู้อะไรเกี่ยวกับบทสนทนากับคู่สนทนาสองคน บทสนทนาดังกล่าวอยู่ในโปรแกรมข้อความซึ่งมีการอ้างอิงถึงผู้ใช้ ที่นี่เรานำข้อมูลแบบ "เผชิญหน้า": แต่ละอินสแตนซ์ของโปรแกรมแชทจะถามอินสแตนซ์ของโปรแกรมข้อความทั้งหมดว่าพวกเขามีบทสนทนาที่ต้องการหรือไม่
เยี่ยมมาก - โปรแกรมแชทรู้ว่ามีแชทหลายแชทอะไรบ้างและรู้ว่ามีบทสนทนาใดบ้าง
คุณต้องรวมข้อความในการแชทหลายแชทเพื่อให้คุณได้รับรายการข้อความในการแชทแต่ละครั้ง ขั้นแรก โปรแกรมแชทจะดึงข้อความผู้ใช้ทั้งหมดจากการแชทนี้จากโปรแกรมข้อความ ในบางกรณีก็มีค่อนข้างมาก (มากถึงหลายร้อยล้าน) แต่มีข้อยกเว้นที่หายากมาก การแชทจะพอดีกับ RAM ทั้งหมด เรามีข้อความที่ไม่ได้เรียงลำดับ โดยแต่ละข้อความมีหลายสำเนา เพราะท้ายที่สุดแล้ว ข้อความทั้งหมดจะถูกดึงมาจากโปรแกรมส่งข้อความที่แตกต่างกันซึ่งสอดคล้องกับผู้ใช้ เป้าหมายคือการจัดเรียงข้อความและกำจัดสำเนาที่ใช้พื้นที่โดยไม่จำเป็น
แต่ละข้อความมีการประทับเวลาซึ่งประกอบด้วยเวลาที่ส่งและข้อความ เราใช้เวลาในการเรียงลำดับ - เราวางตัวชี้ไปยังข้อความที่เก่าแก่ที่สุดของผู้เข้าร่วมมัลติแชท และเปรียบเทียบแฮชจากข้อความของสำเนาที่ต้องการ โดยมุ่งไปสู่การประทับเวลาที่เพิ่มขึ้น เป็นเหตุผลที่สำเนาจะมีแฮชและการประทับเวลาเหมือนกัน แต่ในทางปฏิบัติไม่ได้เป็นเช่นนั้นเสมอไป อย่างที่คุณจำได้ PHP ทำการซิงโครไนซ์ในรูปแบบเก่า - และในบางกรณีที่หายาก เวลาในการส่งข้อความเดียวกันจะแตกต่างกันไปตามผู้ใช้แต่ละราย ในกรณีเหล่านี้ เราอนุญาตให้ตัวเองแก้ไขการประทับเวลาได้ ซึ่งโดยปกติจะใช้เวลาไม่กี่วินาที ปัญหาที่สองคือลำดับข้อความที่แตกต่างกันสำหรับผู้รับที่แตกต่างกัน ในกรณีเช่นนี้ เราอนุญาตให้สร้างสำเนาเพิ่มเติม โดยมีตัวเลือกการสั่งซื้อที่แตกต่างกันสำหรับผู้ใช้ที่แตกต่างกัน
หลังจากนี้ข้อมูลเกี่ยวกับข้อความใน multichat จะถูกส่งไปยังเอ็นจิ้นผู้ใช้ และนี่คือคุณสมบัติอันไม่พึงประสงค์ของข้อความที่นำเข้ามา ในการทำงานปกติ ข้อความที่มายังเอ็นจิ้นจะถูกเรียงลำดับอย่างเคร่งครัดจากน้อยไปมากตาม user_local_id ข้อความที่นำเข้าจากกลไกเก่าไปยังกลไกผู้ใช้สูญเสียคุณสมบัติที่มีประโยชน์นี้ ในขณะเดียวกัน เพื่อความสะดวกในการทดสอบ คุณจะต้องสามารถเข้าถึงได้อย่างรวดเร็ว ค้นหาบางสิ่งในนั้น และเพิ่มรายการใหม่
เราใช้โครงสร้างข้อมูลพิเศษเพื่อจัดเก็บข้อความที่นำเข้า
มันแสดงถึงเวกเตอร์ขนาด  ทุกคนอยู่ที่ไหน
ทุกคนอยู่ที่ไหน  - มีความแตกต่างและเรียงลำดับจากมากไปหาน้อย โดยมีองค์ประกอบตามลำดับพิเศษ ในแต่ละส่วนด้วยดัชนี
- มีความแตกต่างและเรียงลำดับจากมากไปหาน้อย โดยมีองค์ประกอบตามลำดับพิเศษ ในแต่ละส่วนด้วยดัชนี  องค์ประกอบจะถูกจัดเรียง การค้นหาองค์ประกอบในโครงสร้างดังกล่าวต้องใช้เวลา
องค์ประกอบจะถูกจัดเรียง การค้นหาองค์ประกอบในโครงสร้างดังกล่าวต้องใช้เวลา  ตลอด
ตลอด  การค้นหาแบบไบนารี การเพิ่มองค์ประกอบจะถูกตัดจำหน่ายไป
การค้นหาแบบไบนารี การเพิ่มองค์ประกอบจะถูกตัดจำหน่ายไป  .
.
ดังนั้นเราจึงหาวิธีถ่ายโอนข้อมูลจากเอ็นจิ้นเก่าไปยังเอ็นจิ้นใหม่ แต่กระบวนการนี้ใช้เวลาหลายวัน และไม่น่าเป็นไปได้ที่ผู้ใช้ของเราจะเลิกนิสัยการเขียนถึงกันในระหว่างวันดังกล่าว เพื่อไม่ให้ข้อความสูญหายในช่วงเวลานี้ เราจึงเปลี่ยนไปใช้รูปแบบการทำงานที่ใช้ทั้งคลัสเตอร์เก่าและคลัสเตอร์ใหม่
ข้อมูลถูกเขียนไปยังสมาชิกแชทและเอ็นจิ้นผู้ใช้ (และไม่ใช่เอ็นจิ้นข้อความ เช่นเดียวกับการทำงานปกติตามรูปแบบเก่า) พรอกซีของโปรแกรมผู้ใช้ร้องขอให้โปรแกรมแชท - และลักษณะการทำงานที่นี่ขึ้นอยู่กับว่าแชทนี้ได้ถูกรวมเข้าด้วยกันแล้วหรือไม่ หากการแชทยังไม่ได้ถูกรวมเข้าด้วยกัน โปรแกรมแชทจะไม่เขียนข้อความถึงตัวเอง และการประมวลผลจะเกิดขึ้นในโปรแกรมข้อความเท่านั้น หากการแชทถูกรวมเข้ากับ chat-engine แล้ว มันจะส่งคืน chat_local_id ไปยัง user-engine และส่งข้อความไปยังผู้รับทั้งหมด user-engine พรอกซีข้อมูลทั้งหมดไปยัง text-engine ดังนั้นหากมีอะไรเกิดขึ้น เราก็สามารถย้อนกลับได้ตลอดเวลา โดยมีข้อมูลปัจจุบันทั้งหมดในเอ็นจิ้นเก่า text-engine ส่งคืน user_local_id ซึ่งเอ็นจิ้นผู้ใช้จัดเก็บและส่งคืนไปยังแบ็กเอนด์
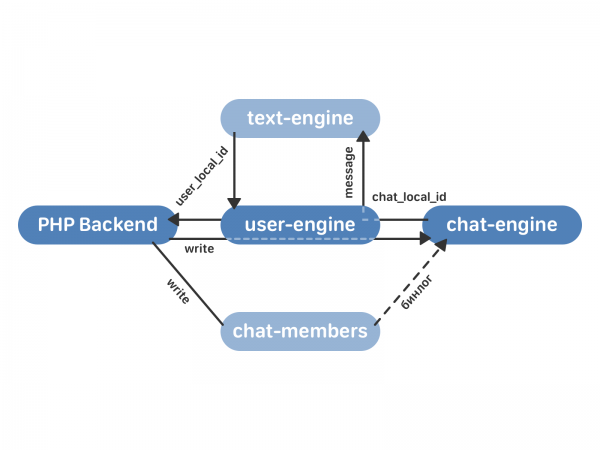
ด้วยเหตุนี้ กระบวนการเปลี่ยนแปลงจึงมีลักษณะดังนี้: เราเชื่อมต่อคลัสเตอร์ของกลไกผู้ใช้และเครื่องมือแชทที่ว่างเปล่า chat-engine จะอ่าน binlog ของสมาชิกแชททั้งหมด จากนั้นการพร็อกซีจะเริ่มต้นตามรูปแบบที่อธิบายไว้ข้างต้น เราถ่ายโอนข้อมูลเก่าและรับคลัสเตอร์ที่ซิงโครไนซ์สองคลัสเตอร์ (เก่าและใหม่) สิ่งที่เหลืออยู่คือเปลี่ยนการอ่านจาก text-engine เป็น user-engine และปิดการใช้งานพรอกซี
ผลการวิจัย
ด้วยแนวทางใหม่นี้ ตัวชี้วัดประสิทธิภาพทั้งหมดของเครื่องยนต์ได้รับการปรับปรุง และปัญหาเกี่ยวกับความสอดคล้องของข้อมูลได้รับการแก้ไขแล้ว ตอนนี้เราสามารถใช้ฟีเจอร์ใหม่ๆ ในข้อความได้อย่างรวดเร็ว (และได้เริ่มดำเนินการแล้ว - เราได้เพิ่มจำนวนผู้เข้าร่วมแชทสูงสุด ใช้การค้นหาข้อความที่ส่งต่อ เปิดตัวข้อความที่ปักหมุด และเพิ่มขีดจำกัดจำนวนข้อความทั้งหมดต่อผู้ใช้) .
การเปลี่ยนแปลงทางตรรกะนั้นยิ่งใหญ่มาก และฉันอยากจะทราบว่านี่ไม่ได้หมายถึงการพัฒนาโดยทีมงานขนาดใหญ่และโค้ดจำนวนมากมายตลอดทั้งปีเสมอไป chat-engine และ user-engine พร้อมด้วยเรื่องราวเพิ่มเติมทั้งหมด เช่น Huffman สำหรับการบีบอัดข้อความ Splay tree และโครงสร้างสำหรับข้อความที่นำเข้ามีโค้ดน้อยกว่า 20 บรรทัด และเขียนโดยนักพัฒนา 3 คนในเวลาเพียง 10 เดือน (แต่ก็ควรจำไว้ด้วย - แชมป์โลก ).
ยิ่งไปกว่านั้น แทนที่จะเพิ่มจำนวนเซิร์ฟเวอร์เป็นสองเท่า เราได้ลดจำนวนเซิร์ฟเวอร์ลงครึ่งหนึ่ง - ขณะนี้กลไกผู้ใช้และกลไกแชทใช้งานจริงบนเครื่องจริง 500 เครื่อง ในขณะที่รูปแบบใหม่มีพื้นที่ว่างขนาดใหญ่สำหรับการโหลด เราประหยัดเงินค่าอุปกรณ์ได้มาก - ประมาณ 5 ล้านดอลลาร์ + ค่าใช้จ่ายในการดำเนินงาน 750 ดอลลาร์ต่อปี
เรามุ่งมั่นที่จะค้นหาแนวทางแก้ไขที่ดีที่สุดสำหรับปัญหาที่ซับซ้อนและมีขนาดใหญ่ที่สุด เรามีนักพัฒนามากมาย - และนั่นคือเหตุผลที่เรากำลังมองหานักพัฒนาที่มีความสามารถในแผนกฐานข้อมูล หากคุณรักและรู้วิธีการแก้ปัญหาดังกล่าว มีความรู้ที่ยอดเยี่ยมเกี่ยวกับอัลกอริทึมและโครงสร้างข้อมูล เราขอเชิญคุณเข้าร่วมทีม ติดต่อเรา สำหรับรายละเอียด
แม้ว่าเรื่องราวนี้ไม่เกี่ยวกับคุณ แต่โปรดทราบว่าเราให้ความสำคัญกับคำแนะนำ เล่าให้เพื่อนฟัง และหากเขาผ่านช่วงทดลองงานได้สำเร็จ คุณจะได้รับโบนัส 100 รูเบิล
ที่มา: will.com
