

บันทึก. แปล: ผู้เขียนเนื้อหานี้คือ Cindy Sridharan วิศวกรของ imgix ซึ่งเชี่ยวชาญด้านการพัฒนา API และโดยเฉพาะอย่างยิ่งการทดสอบไมโครเซอร์วิส ในเอกสารนี้ เธอแบ่งปันวิสัยทัศน์โดยละเอียดเกี่ยวกับปัญหาในปัจจุบันในด้านการติดตามแบบกระจาย ซึ่งในความเห็นของเธอ ขาดเครื่องมือที่มีประสิทธิภาพอย่างแท้จริงในการแก้ปัญหาเร่งด่วน
[ภาพประกอบนำมาจาก. เกี่ยวกับการติดตามแบบกระจาย]
เป็นที่เชื่อกันว่า ยากที่จะปฏิบัติและผลตอบแทนของมัน . มีสาเหตุหลายประการที่ทำให้การติดตามเป็นปัญหา โดยมักอ้างถึงการทำงานที่เกี่ยวข้องกับการกำหนดค่าแต่ละองค์ประกอบของระบบเพื่อส่งส่วนหัวที่เหมาะสมกับคำขอแต่ละรายการ แม้ว่าปัญหานี้จะเกิดขึ้น แต่ก็ไม่สามารถผ่านพ้นไปได้ อย่างไรก็ตาม มันไม่ได้อธิบายว่าทำไมนักพัฒนาถึงไม่ชอบการติดตาม (แม้ว่าจะใช้งานได้แล้วก็ตาม)
ความท้าทายหลักของการติดตามแบบกระจายไม่ได้รวบรวมข้อมูล สร้างมาตรฐานรูปแบบสำหรับการกระจายและการนำเสนอผลลัพธ์ หรือการกำหนดเวลา สถานที่ และวิธีการสุ่มตัวอย่าง ฉันไม่ได้พยายามที่จะจินตนาการ เล็กน้อย "ปัญหาด้านความเข้าใจ" เหล่านี้ แท้จริงแล้วเป็นปัญหาทางเทคนิคที่ค่อนข้างสำคัญ และ (หากเรากำลังพิจารณาโอเพ่นซอร์สอย่างแท้จริง) ) ความท้าทายทางการเมืองที่ต้องเอาชนะเพื่อแก้ไขปัญหาเหล่านี้
อย่างไรก็ตาม ถ้าเราจินตนาการว่าปัญหาทั้งหมดนี้ได้รับการแก้ไขแล้ว มีความเป็นไปได้สูงที่จะไม่มีอะไรเปลี่ยนแปลงอย่างมีนัยสำคัญในแง่ของ ประสบการณ์ผู้ใช้ปลายทาง. การติดตามอาจยังใช้ไม่ได้ในทางปฏิบัติในสถานการณ์การตรวจแก้จุดบกพร่องทั่วไป—แม้ว่าจะถูกปรับใช้แล้วก็ตาม
ร่องรอยที่แตกต่างออกไป
การติดตามแบบกระจายประกอบด้วยองค์ประกอบที่แตกต่างกันหลายประการ:
- จัดเตรียมแอปพลิเคชันและมิดเดิลแวร์ด้วยเครื่องมือควบคุม
- การถ่ายโอนบริบทแบบกระจาย
- การรวบรวมร่องรอย
- การจัดเก็บร่องรอย
- การสกัดและการแสดงภาพ
การพูดคุยกันมากมายเกี่ยวกับการติดตามแบบกระจายมีแนวโน้มที่จะถือว่าเป็นการดำเนินการแบบเอกเทศซึ่งมีวัตถุประสงค์เพียงอย่างเดียวคือช่วยวินิจฉัยระบบได้อย่างสมบูรณ์ สาเหตุส่วนใหญ่มาจากแนวคิดเกี่ยวกับการติดตามแบบกระจายที่เกิดขึ้นในอดีต ใน ซึ่งทำตอนเปิดแหล่ง Zipkin ก็มีบอกไว้ว่า มัน [Zipkin] ทำให้ Twitter เร็วขึ้น. การเสนอขายเชิงพาณิชย์ครั้งแรกสำหรับการติดตามก็ได้รับการส่งเสริมเช่นกัน .
บันทึก. แปล: เพื่อให้ข้อความเพิ่มเติมเข้าใจง่ายขึ้น ให้เรานิยามคำศัพท์พื้นฐานสองคำตาม :
- ระยะ — องค์ประกอบพื้นฐานของการติดตามแบบกระจาย เป็นคำอธิบายของเวิร์กโฟลว์บางอย่าง (เช่น การสืบค้นฐานข้อมูล) พร้อมด้วยชื่อ เวลาเริ่มต้นและเวลาสิ้นสุด แท็ก บันทึก และบริบท
- โดยปกติ Span จะมีลิงก์ไปยัง Span อื่นๆ เพื่อให้สามารถรวม Span หลายอันเข้าด้วยกันได้ ติดตาม — การแสดงภาพอายุของคำขอขณะเคลื่อนที่ผ่านระบบแบบกระจาย
ติดตามประกอบด้วยข้อมูลที่มีค่าอย่างไม่น่าเชื่อซึ่งสามารถช่วยในงานต่างๆ เช่น การทดสอบการผลิต การทดสอบการกู้คืนความเสียหาย การทดสอบการฉีดข้อผิดพลาด ฯลฯ ที่จริงแล้ว บางบริษัทใช้การติดตามเพื่อจุดประสงค์ที่คล้ายกันอยู่แล้ว เริ่มต้นด้วย มีประโยชน์อื่นนอกเหนือจากการย้ายสแปนไปยังระบบจัดเก็บข้อมูล:
- ตัวอย่างเช่น อูเบอร์ ติดตามผลเพื่อแยกความแตกต่างระหว่างปริมาณข้อมูลทดสอบและปริมาณการใช้งานจริง
- Facebook ติดตามข้อมูลสำหรับการวิเคราะห์เส้นทางที่สำคัญและการสลับการรับส่งข้อมูลในระหว่างการทดสอบการกู้คืนระบบตามปกติ
- โซเชียลเน็ตเวิร์กอีกด้วย สมุดบันทึก Jupyter ที่ช่วยให้นักพัฒนาสามารถเรียกใช้คำสั่งตามต้องการเกี่ยวกับผลลัพธ์การติดตาม
- สมัครพรรคพวก (การฉีดความล้มเหลวที่ขับเคลื่อนด้วยเชื้อสาย) กระจายการติดตามสำหรับการทดสอบด้วยการแทรกข้อผิดพลาด
ไม่มีตัวเลือกใดที่กล่าวข้างต้นใช้ได้กับสถานการณ์ทั้งหมด การดีบักซึ่งในระหว่างที่วิศวกรพยายามแก้ไขปัญหาด้วยการดูร่องรอย
เมื่อมันมาถึง ยัง ถึงสคริปต์การดีบัก อินเทอร์เฟซหลักยังคงเป็นไดอะแกรม ติดตามดู (แม้ว่าบางคนจะเรียกมันว่า "แผนภูมิแกนต์" หรือ "แผนภาพน้ำตก"). ภายใต้ ติดตามดู я ช่วงทั้งหมดและข้อมูลเมตาประกอบที่รวมกันเป็นการติดตาม ระบบการติดตามโอเพ่นซอร์สทุกระบบ รวมถึงโซลูชันการติดตามเชิงพาณิชย์ทุกระบบ นำเสนอ ติดตามดู ส่วนติดต่อผู้ใช้สำหรับการแสดงภาพ รายละเอียด และการกรองร่องรอย
ปัญหาเกี่ยวกับระบบการติดตามทั้งหมดที่ฉันเคยพบเห็นคือผลลัพธ์ที่ได้ การแสดงภาพ (traceview) สะท้อนให้เห็นถึงคุณสมบัติของกระบวนการสร้างร่องรอยเกือบทั้งหมด แม้ว่าจะมีการนำเสนอการแสดงภาพข้อมูลทางเลือก: แผนที่ความร้อน โทโพโลยีบริการ ฮิสโตแกรมเวลาแฝง แต่ท้ายที่สุดก็ยังคงลงมาที่ ติดตามดู.
ในอดีตฉัน "นวัตกรรม" ส่วนใหญ่ในการติดตาม UI/UX ดูเหมือนจะจำกัดอยู่เพียงเท่านี้ เมตาดาต้าเพิ่มเติมในการติดตาม ลงทุนในข้อมูลที่มีความมีความสำคัญสูง (คาร์ดินัลลิตีสูง) หรือให้ความสามารถในการเจาะลึกลงไปในช่วงเฉพาะหรือเรียกใช้การสืบค้น การติดตามระหว่างและภายใน... โดยที่ ติดตามดู ยังคงเป็นเครื่องมือแสดงภาพหลัก ตราบใดที่สถานการณ์นี้ยังคงดำเนินต่อไป การติดตามแบบกระจาย (อย่างดีที่สุด) จะกลายเป็นเครื่องมือแก้ไขข้อบกพร่องอันดับที่ 4 รองจากเมตริก บันทึก และการติดตามสแต็ก และที่แย่ที่สุดจะกลายเป็นการสิ้นเปลืองเงินและเวลา
ปัญหาเกี่ยวกับการติดตามมุมมอง
โชคชะตา ติดตามดู — ให้ภาพที่สมบูรณ์ของการเคลื่อนไหวของคำขอเดียวในทุกองค์ประกอบของระบบแบบกระจายที่เกี่ยวข้องกัน ระบบติดตามขั้นสูงบางระบบช่วยให้คุณสามารถเจาะลึกลงในแต่ละช่วงและดูรายละเอียดเมื่อเวลาผ่านไป ภายใน กระบวนการเดียว (เมื่อสแปนมีขอบเขตการทำงาน)
พื้นฐานพื้นฐานของสถาปัตยกรรมไมโครเซอร์วิสคือแนวคิดที่ว่าโครงสร้างองค์กรเติบโตไปพร้อมกับความต้องการของบริษัท ผู้เสนอไมโครเซอร์วิสให้เหตุผลว่าการกระจายงานทางธุรกิจต่างๆ ไปยังบริการแต่ละอย่างทำให้ทีมพัฒนาขนาดเล็กที่เป็นอิสระสามารถควบคุมวงจรการใช้งานทั้งหมดของบริการดังกล่าวได้ ทำให้สามารถสร้าง ทดสอบ และปรับใช้บริการเหล่านั้นได้อย่างอิสระ อย่างไรก็ตาม ข้อเสียของการกระจายนี้คือการสูญเสียข้อมูลเกี่ยวกับวิธีที่แต่ละบริการโต้ตอบกับผู้อื่น ในเงื่อนไขดังกล่าว การติดตามแบบกระจายอ้างว่าเป็นเครื่องมือที่ขาดไม่ได้สำหรับ การดีบัก การโต้ตอบที่ซับซ้อนระหว่างบริการ
ถ้าคุณจริงๆ ถ้าอย่างนั้นก็ไม่มีใครสามารถเก็บมันไว้ในหัวได้ เสร็จสมบูรณ์ รูปภาพ. ในความเป็นจริง การพัฒนาเครื่องมือบนพื้นฐานสมมติฐานที่ว่าเป็นไปได้นั้นเป็นสิ่งที่ต่อต้านรูปแบบ (แนวทางที่ไม่มีประสิทธิภาพและไม่เกิดผล) ตามหลักการแล้ว การดีบักต้องใช้เครื่องมือที่ช่วย จำกัดพื้นที่การค้นหาของคุณให้แคบลงเพื่อให้วิศวกรสามารถมุ่งเน้นไปที่ชุดย่อยของมิติ (บริการ/ผู้ใช้/โฮสต์ ฯลฯ) ที่เกี่ยวข้องกับสถานการณ์ปัญหาที่กำลังพิจารณา เมื่อระบุสาเหตุของความล้มเหลว วิศวกรไม่จำเป็นต้องเข้าใจว่าเกิดอะไรขึ้นในระหว่างนั้น บริการทั้งหมดในครั้งเดียวเนื่องจากข้อกำหนดดังกล่าวจะขัดแย้งกับแนวคิดของสถาปัตยกรรมไมโครเซอร์วิส
อย่างไรก็ตาม Traceview คือ คือ นี้. ใช่ ระบบการติดตามบางระบบเสนอมุมมองการติดตามแบบบีบอัด เมื่อจำนวนช่วงในการติดตามมีขนาดใหญ่มากจนไม่สามารถแสดงในการแสดงภาพเดียวได้ อย่างไรก็ตาม เนื่องจากข้อมูลจำนวนมากมีอยู่แม้ในรูปแบบการแสดงภาพแบบแยกส่วน วิศวกรจึงยังคงอยู่ ถูกบังคับ “กรอง” โดยจำกัดการเลือกให้แคบลงด้วยตนเองไปยังชุดบริการที่เป็นสาเหตุของปัญหา น่าเสียดายที่ในสาขานี้ เครื่องจักรเร็วกว่ามนุษย์มาก มีแนวโน้มที่จะเกิดข้อผิดพลาดน้อยกว่า และผลลัพธ์สามารถทำซ้ำได้มากกว่า
อีกเหตุผลหนึ่งที่ฉันคิดว่า Traceview ผิดก็คือเพราะมันไม่ดีสำหรับการดีบักที่ขับเคลื่อนด้วยสมมติฐาน โดยแก่นแท้แล้ว การดีบักคือ วนซ้ำ กระบวนการที่เริ่มต้นด้วยสมมติฐาน ตามด้วยการตรวจสอบข้อสังเกตและข้อเท็จจริงต่างๆ ที่ได้รับจากระบบตามเวกเตอร์ต่างๆ ข้อสรุป/ลักษณะทั่วไป และการประเมินความจริงของสมมติฐานเพิ่มเติม
โอกาส รวดเร็วและราคาถูก การทดสอบสมมติฐานและปรับปรุงแบบจำลองทางจิตตามลำดับคือ หลักสำคัญ การดีบัก เครื่องมือแก้ไขข้อบกพร่องใด ๆ ควรจะเป็น เชิงโต้ตอบ และจำกัดพื้นที่การค้นหาให้แคบลง หรือในกรณี Lead ปลอม ให้ผู้ใช้สามารถย้อนกลับและมุ่งความสนใจไปยังพื้นที่อื่นของระบบได้ เครื่องมือที่สมบูรณ์แบบจะทำสิ่งนี้ เชิงรุกดึงความสนใจของผู้ใช้ไปยังพื้นที่ที่อาจเกิดปัญหาได้ทันที
อนิจจา, ติดตามดู ไม่สามารถเรียกได้ว่าเป็นเครื่องมือที่มีอินเทอร์เฟซแบบโต้ตอบ สิ่งที่ดีที่สุดที่คุณคาดหวังได้เมื่อใช้มันคือการค้นหาแหล่งที่มาของเวลาแฝงที่เพิ่มขึ้น และดูแท็กและบันทึกที่เป็นไปได้ทั้งหมดที่เกี่ยวข้องกับมัน สิ่งนี้ไม่ได้ช่วยให้วิศวกรระบุได้ รูปแบบ ในการรับส่งข้อมูล เช่น ข้อมูลเฉพาะของการกระจายความล่าช้า หรือตรวจจับความสัมพันธ์ระหว่างการวัดที่แตกต่างกัน อาจช่วยแก้ไขปัญหาเหล่านี้ได้บ้าง จริงหรือ, การวิเคราะห์ที่ประสบความสำเร็จโดยใช้การเรียนรู้ของเครื่องเพื่อระบุช่วงที่ผิดปกติและระบุชุดย่อยของแท็กที่อาจเกี่ยวข้องกับพฤติกรรมที่ผิดปกติ อย่างไรก็ตาม ฉันยังไม่เห็นการแสดงภาพที่น่าสนใจของการเรียนรู้ของเครื่องหรือการค้นพบการขุดข้อมูลที่นำไปใช้กับช่วงที่แตกต่างอย่างมีนัยสำคัญจาก Tracview หรือ DAG (กราฟอะไซคลิกแบบกำหนดทิศทาง)
ช่วงอยู่ในระดับต่ำเกินไป
ปัญหาพื้นฐานของ Traceview ก็คือ ช่วง เป็นข้อมูลพื้นฐานระดับต่ำเกินไปสำหรับทั้งการวิเคราะห์เวลาแฝงและการวิเคราะห์สาเหตุที่แท้จริง เหมือนกับการแยกวิเคราะห์คำสั่งของโปรเซสเซอร์แต่ละตัวเพื่อพยายามแก้ไขข้อยกเว้น โดยรู้ว่ามีเครื่องมือระดับที่สูงกว่ามาก เช่น backtrace ที่ใช้งานสะดวกกว่ามาก
ยิ่งกว่านั้น ฉันจะใช้เสรีภาพในการยืนยันสิ่งต่อไปนี้: โดยหลักการแล้ว เราไม่ต้องการ ภาพเต็ม เกิดขึ้นระหว่างวงจรการร้องขอ ซึ่งแสดงโดยเครื่องมือติดตามสมัยใหม่ แต่จำเป็นต้องมีรูปแบบนามธรรมระดับสูงกว่าบางรูปแบบที่มีข้อมูลเกี่ยวกับอะไร ผิดพลาด (คล้ายกับการย้อนรอย) พร้อมด้วยบริบทบางอย่าง แทนที่จะดูร่องรอยทั้งหมด ฉันอยากจะเห็นมันมากกว่า частьซึ่งมีบางสิ่งที่น่าสนใจหรือผิดปกติเกิดขึ้น ขณะนี้การค้นหาดำเนินการด้วยตนเอง: วิศวกรได้รับการติดตามและวิเคราะห์ช่วงอย่างอิสระเพื่อค้นหาสิ่งที่น่าสนใจ วิธีการของผู้คนที่จ้องไปที่ช่วงต่างๆ ในการติดตามแต่ละรายการโดยหวังว่าจะตรวจจับกิจกรรมที่น่าสงสัยนั้นไม่ได้ปรับขนาดเลย (โดยเฉพาะอย่างยิ่งเมื่อพวกเขาต้องทำความเข้าใจกับข้อมูลเมตาทั้งหมดที่เข้ารหัสในช่วงต่างๆ เช่น span ID ชื่อวิธี RPC ระยะเวลาของช่วง 'a บันทึก แท็ก ฯลฯ)
ทางเลือกอื่นในการติดตามดู
ผลลัพธ์การติดตามจะมีประโยชน์มากที่สุดเมื่อสามารถแสดงภาพในลักษณะที่ให้ข้อมูลเชิงลึกที่ไม่สำคัญเกี่ยวกับสิ่งที่เกิดขึ้นในส่วนที่เชื่อมต่อถึงกันของระบบ จนกว่าจะเกิดเหตุการณ์เช่นนี้ กระบวนการตรวจแก้จุดบกพร่องจะยังคงอยู่เป็นส่วนใหญ่ เฉื่อย และขึ้นอยู่กับความสามารถของผู้ใช้ในการสังเกตความสัมพันธ์ที่ถูกต้อง ตรวจสอบส่วนที่ถูกต้องของระบบ หรือนำชิ้นส่วนของปริศนามารวมกัน - ตรงข้ามกับ เครื่องมือช่วยให้ผู้ใช้กำหนดสมมติฐานเหล่านี้ได้
ฉันไม่ใช่นักออกแบบภาพหรือผู้เชี่ยวชาญด้าน UX แต่ในส่วนถัดไป ฉันต้องการแบ่งปันแนวคิดบางประการเกี่ยวกับลักษณะของการแสดงภาพเหล่านี้
มุ่งเน้นไปที่บริการเฉพาะ
ในช่วงเวลาที่อุตสาหกรรมกำลังรวบรวมแนวคิดต่างๆ ดูเหมือนว่าสมเหตุสมผลที่แต่ละทีมควรจัดลำดับความสำคัญเพื่อให้แน่ใจว่าบริการของตนสอดคล้องกับเป้าหมายเหล่านี้ มันเป็นไปตามนั้น มุ่งเน้นการบริการ การแสดงภาพเหมาะที่สุดสำหรับทีมดังกล่าว
ร่องรอยโดยเฉพาะอย่างยิ่งเมื่อไม่มีการสุ่มตัวอย่างถือเป็นขุมสมบัติของข้อมูลเกี่ยวกับแต่ละองค์ประกอบของระบบแบบกระจาย ข้อมูลนี้สามารถป้อนให้กับโปรเซสเซอร์ที่มีไหวพริบที่จะจัดหาผู้ใช้ มุ่งเน้นการบริการ การค้นพบ สามารถระบุได้ล่วงหน้า - ก่อนที่ผู้ใช้จะดูร่องรอย:
- ไดอะแกรมการกระจายเวลาในการตอบสนองสำหรับคำขอที่มีความโดดเด่นสูงเท่านั้น (คำขอนอกระบบ);
- แผนภาพการกระจายความล่าช้าสำหรับกรณีที่บริการ SLO ไม่บรรลุเป้าหมาย
- แท็ก "ทั่วไป" "น่าสนใจ" และ "แปลก" มากที่สุดในข้อความค้นหาที่บ่อยที่สุด ซ้ำแล้วซ้ำอีก;
- รายละเอียดเวลาในการตอบสนองสำหรับกรณีที่ ขึ้นอยู่กับ บริการไม่บรรลุเป้าหมาย SLO
- รายละเอียดเวลาแฝงสำหรับบริการดาวน์สตรีมต่างๆ
คำถามเหล่านี้บางข้อไม่ได้รับคำตอบจากเมตริกในตัว ทำให้ผู้ใช้ต้องพิจารณา Span อย่างละเอียด ด้วยเหตุนี้ เราจึงมีกลไกที่ไม่เป็นมิตรต่อผู้ใช้อย่างยิ่ง
สิ่งนี้ทำให้เกิดคำถาม: แล้วการโต้ตอบที่ซับซ้อนระหว่างบริการที่หลากหลายที่ควบคุมโดยทีมต่าง ๆ ล่ะ? ไม่ใช่เหรอ. ติดตามดู ไม่ถือเป็นเครื่องมือที่เหมาะสมที่สุดในการเน้นย้ำสถานการณ์เช่นนี้?
นักพัฒนามือถือ เจ้าของบริการไร้สัญชาติ เจ้าของบริการ stateful ที่มีการจัดการ (เช่น ฐานข้อมูล) และเจ้าของแพลตฟอร์ม อาจสนใจอย่างอื่น การนำเสนอ ระบบกระจาย; ติดตามดู เป็นโซลูชันที่กว้างเกินไปสำหรับความต้องการที่แตกต่างกันโดยพื้นฐานเหล่านี้ แม้แต่ในสถาปัตยกรรมไมโครเซอร์วิสที่ซับซ้อนมาก เจ้าของบริการก็ไม่จำเป็นต้องมีความรู้เชิงลึกเกี่ยวกับบริการต้นน้ำและปลายน้ำมากกว่าสองหรือสามบริการ โดยพื้นฐานแล้ว ในสถานการณ์ส่วนใหญ่ ผู้ใช้จะต้องตอบคำถามที่เกี่ยวข้องเท่านั้น ชุดบริการมีจำกัด.
เหมือนกับการดูบริการย่อยเล็กๆ น้อยๆ ผ่านแว่นขยายเพื่อประโยชน์ในการพิจารณาอย่างละเอียด ซึ่งจะช่วยให้ผู้ใช้ถามคำถามเร่งด่วนมากขึ้นเกี่ยวกับการโต้ตอบที่ซับซ้อนระหว่างบริการเหล่านี้และการขึ้นต่อกันในทันที สิ่งนี้คล้ายกับการย้อนรอยในโลกบริการที่วิศวกรรู้ ที่ ผิดและยังมีความเข้าใจในสิ่งที่เกิดขึ้นในบริการโดยรอบเพื่อทำความเข้าใจ ทำไม.
แนวทางที่ฉันกำลังส่งเสริมนั้นตรงกันข้ามกับแนวทางจากบนลงล่างแบบอิงมุมมอง โดยที่การวิเคราะห์จะเริ่มต้นด้วยการติดตามทั้งหมด จากนั้นจึงค่อย ๆ พิจารณาไปจนถึงแต่ละช่วง ในทางตรงกันข้าม วิธีการจากล่างขึ้นบนเริ่มต้นด้วยการวิเคราะห์พื้นที่เล็กๆ ใกล้กับสาเหตุที่เป็นไปได้ของเหตุการณ์ จากนั้นจึงขยายพื้นที่การค้นหาตามความจำเป็น (โดยมีศักยภาพในการนำทีมอื่นเข้ามาวิเคราะห์บริการในวงกว้างมากขึ้น) แนวทางที่สองเหมาะกว่าสำหรับการทดสอบสมมติฐานเบื้องต้นอย่างรวดเร็ว เมื่อได้ผลลัพธ์ที่เป็นรูปธรรมแล้ว จะสามารถไปสู่การวิเคราะห์ที่ตรงเป้าหมายและมีรายละเอียดมากขึ้นได้
การสร้างโทโพโลยี
มุมมองเฉพาะบริการจะมีประโยชน์อย่างเหลือเชื่อหากผู้ใช้รู้ อันไหน บริการหรือกลุ่มบริการมีหน้าที่ในการเพิ่มเวลาแฝงหรือทำให้เกิดข้อผิดพลาด อย่างไรก็ตาม ในระบบที่ซับซ้อน การระบุบริการที่ละเมิดอาจเป็นงานที่ไม่สำคัญในระหว่างเกิดความล้มเหลว โดยเฉพาะอย่างยิ่งหากไม่มีการรายงานข้อความแสดงข้อผิดพลาดจากบริการ
การสร้างโทโพโลยีบริการสามารถช่วยได้มากในการพิจารณาว่าบริการใดกำลังประสบกับอัตราข้อผิดพลาดที่เพิ่มขึ้นอย่างรวดเร็วหรือเวลาแฝงที่เพิ่มขึ้น ซึ่งทำให้บริการลดลงอย่างเห็นได้ชัด เมื่อฉันพูดถึงการสร้างโทโพโลยี ฉันไม่ได้หมายถึง แผนที่บริการแสดงทุกบริการที่มีอยู่ในระบบและเป็นที่รู้จัก . มุมมองนี้ไม่ดีไปกว่า Traceview ที่อิงตามกราฟอะไซคลิกโดยตรง เลยอยากดูแทน. โทโพโลยีบริการที่สร้างขึ้นแบบไดนามิกโดยอิงตามคุณลักษณะบางอย่าง เช่น อัตราข้อผิดพลาด เวลาตอบสนอง หรือพารามิเตอร์ที่ผู้ใช้กำหนดซึ่งช่วยชี้แจงสถานการณ์ด้วยบริการที่น่าสงสัยโดยเฉพาะ
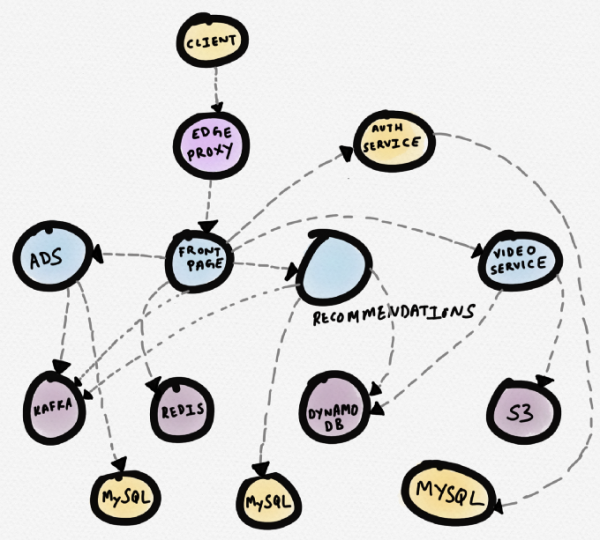
ลองมาตัวอย่าง. ลองจินตนาการถึงไซต์ข่าวสมมุติ บริการหน้าแรก (หน้าแรก) แลกเปลี่ยนข้อมูลกับ Redis พร้อมบริการแนะนำ พร้อมบริการโฆษณาและบริการวิดีโอ บริการวิดีโอใช้วิดีโอจาก S3 และข้อมูลเมตาจาก DynamoDB บริการแนะนำได้รับข้อมูลเมตาจาก DynamoDB โหลดข้อมูลจาก Redis และ MySQL และเขียนข้อความไปยัง Kafka บริการโฆษณารับข้อมูลจาก MySQL และเขียนข้อความถึง Kafka
ด้านล่างนี้คือการแสดงแผนผังของโทโพโลยีนี้ (โปรแกรมการกำหนดเส้นทางเชิงพาณิชย์จำนวนมากสร้างโทโพโลยี) อาจมีประโยชน์หากคุณต้องการเข้าใจการพึ่งพาบริการ อย่างไรก็ตามในระหว่าง การดีบักเมื่อบริการบางอย่าง (เช่น บริการวิดีโอ) แสดงเวลาตอบสนองที่เพิ่มขึ้น โทโพโลยีดังกล่าวจะไม่มีประโยชน์มากนัก
แผนภาพบริการของเว็บไซต์ข่าวสมมุติ
แผนภาพด้านล่างน่าจะเหมาะกว่า มีปัญหากับการบริการ (วิดีโอ) ปรากฏอยู่ตรงกลาง ผู้ใช้จะสังเกตเห็นได้ทันที จากการแสดงภาพนี้ เห็นได้ชัดว่าบริการวิดีโอทำงานผิดปกติเนื่องจากเวลาตอบสนอง S3 เพิ่มขึ้น ซึ่งส่งผลต่อความเร็วในการโหลดของบางส่วนของหน้าหลัก
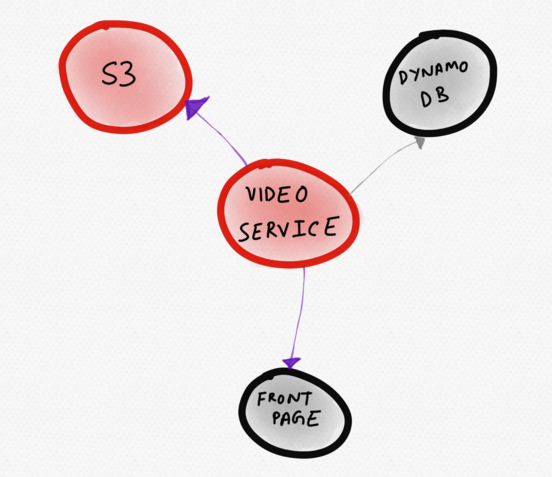
โทโพโลยีแบบไดนามิกที่แสดงเฉพาะบริการที่ “น่าสนใจ” เท่านั้น
โทโพโลยีที่สร้างขึ้นแบบไดนามิกสามารถมีประสิทธิภาพมากกว่าแผนที่บริการแบบคงที่ โดยเฉพาะอย่างยิ่งในโครงสร้างพื้นฐานที่ยืดหยุ่นและปรับขนาดอัตโนมัติ ความสามารถในการเปรียบเทียบและเปรียบเทียบโทโพโลยีบริการทำให้ผู้ใช้สามารถถามคำถามที่เกี่ยวข้องได้มากขึ้น คำถามที่แม่นยำยิ่งขึ้นเกี่ยวกับระบบมีแนวโน้มที่จะนำไปสู่ความเข้าใจเกี่ยวกับวิธีการทำงานของระบบมากขึ้น
การแสดงผลเปรียบเทียบ
การแสดงภาพข้อมูลที่มีประโยชน์อีกประการหนึ่งคือการแสดงภาพเปรียบเทียบ การติดตามในปัจจุบันไม่เหมาะนักสำหรับการเปรียบเทียบแบบเคียงข้างกัน ดังนั้น การเปรียบเทียบจึงมักจะเป็นเช่นนั้น ช่วง. และแนวคิดหลักของบทความนี้ก็คือว่าช่วงนั้นอยู่ในระดับต่ำเกินไปที่จะดึงข้อมูลที่มีค่าที่สุดจากผลลัพธ์การติดตาม
การเปรียบเทียบการติดตามสองรายการไม่จำเป็นต้องมีการแสดงภาพข้อมูลใหม่โดยพื้นฐาน อันที่จริง ฮิสโตแกรมที่แสดงข้อมูลเดียวกันกับเทรซวิวก็เพียงพอแล้ว น่าประหลาดใจที่แม้แต่วิธีการง่ายๆ นี้ยังให้ผลมากกว่าแค่ศึกษาร่องรอยสองอย่างแยกกัน มีพลังยิ่งกว่านั้นก็เป็นไปได้ นึกภาพ การเปรียบเทียบร่องรอย เบ็ดเสร็จ. จะมีประโยชน์อย่างยิ่งหากเห็นว่าการเปลี่ยนแปลงการกำหนดค่าฐานข้อมูลที่เพิ่งปรับใช้เมื่อเร็วๆ นี้เพื่อเปิดใช้งาน GC (การรวบรวมขยะ) ส่งผลต่อเวลาตอบสนองของบริการดาวน์สตรีมในระดับหลายชั่วโมงอย่างไร หากสิ่งที่ฉันอธิบายในที่นี้ฟังดูเหมือนการวิเคราะห์ A/B ของผลกระทบของการเปลี่ยนแปลงโครงสร้างพื้นฐาน ในบริการต่างๆ มากมาย ใช้ผลการติดตามแล้วคุณก็จะไม่ไกลจากความจริงมากนัก
ข้อสรุป
ฉันไม่สงสัยถึงประโยชน์ของการติดตาม ฉันเชื่ออย่างจริงใจว่าไม่มีวิธีอื่นใดในการรวบรวมข้อมูลที่สมบูรณ์ มีเหตุผล และบริบทมากเท่ากับที่มีอยู่ในการติดตาม อย่างไรก็ตาม ฉันยังเชื่อด้วยว่าโซลูชันการติดตามทั้งหมดใช้ข้อมูลนี้อย่างไม่มีประสิทธิภาพอย่างยิ่ง ตราบใดที่เครื่องมือติดตามยังคงติดอยู่บนการแสดง Traceview เครื่องมือเหล่านี้จะถูกจำกัดความสามารถในการใช้ประโยชน์สูงสุดจากข้อมูลอันมีค่าที่สามารถดึงมาจากข้อมูลที่มีอยู่ในการติดตามได้ นอกจากนี้ ยังมีความเสี่ยงในการพัฒนาอินเทอร์เฟซแบบภาพที่ไม่เป็นมิตรและใช้งานไม่ได้โดยสิ้นเชิง ซึ่งจะจำกัดความสามารถของผู้ใช้ในการแก้ไขข้อผิดพลาดในแอปพลิเคชันอย่างรุนแรง
การดีบักระบบที่ซับซ้อน แม้จะใช้เครื่องมือล่าสุด แต่ก็เป็นเรื่องยากอย่างไม่น่าเชื่อ เครื่องมือควรช่วยให้นักพัฒนากำหนดและทดสอบสมมติฐาน จัดหาอย่างแข็งขัน ข้อมูลที่เกี่ยวข้อง การระบุค่าผิดปกติและการสังเกตคุณลักษณะในการกระจายความล่าช้า สำหรับการติดตามว่าจะกลายเป็นเครื่องมือที่นักพัฒนาเลือกใช้เมื่อแก้ไขปัญหาความล้มเหลวในการผลิตหรือแก้ไขปัญหาที่ครอบคลุมบริการต่างๆ จำเป็นต้องมีอินเทอร์เฟซผู้ใช้ดั้งเดิมและการแสดงภาพซึ่งสอดคล้องกับรูปแบบทางจิตของนักพัฒนาที่สร้างและดำเนินการบริการเหล่านั้นมากกว่า
ต้องใช้ความพยายามอย่างมากในการออกแบบระบบที่จะแสดงสัญญาณต่างๆ ที่มีอยู่ในผลลัพธ์การติดตามในลักษณะที่ได้รับการปรับปรุงให้เหมาะสมเพื่อความสะดวกในการวิเคราะห์และการอนุมาน คุณต้องคิดถึงวิธีสรุปโทโพโลยีของระบบในระหว่างการดีบักในลักษณะที่ช่วยให้ผู้ใช้เอาชนะจุดบอดโดยไม่ต้องดูร่องรอยหรือช่วงแต่ละช่วง
เราต้องการความสามารถในการนามธรรมและการแบ่งชั้นที่ดี (โดยเฉพาะใน UI) สิ่งที่เหมาะสมอย่างยิ่งกับกระบวนการแก้ไขจุดบกพร่องที่ขับเคลื่อนด้วยสมมติฐาน ซึ่งคุณสามารถถามคำถามและทดสอบสมมติฐานซ้ำได้ พวกเขาจะไม่แก้ปัญหาความสามารถในการสังเกตทั้งหมดโดยอัตโนมัติ แต่จะช่วยให้ผู้ใช้ปรับสัญชาตญาณให้คมชัดขึ้นและตั้งคำถามที่ชาญฉลาดยิ่งขึ้น ฉันเรียกร้องให้มีแนวทางที่รอบคอบและสร้างสรรค์มากขึ้นในการแสดงภาพ มีโอกาสที่แท้จริงที่จะขยายขอบเขตอันไกลโพ้น
ปล.จากผู้แปล
อ่านเพิ่มเติมในบล็อกของเรา:
- «";
- «";
- «'
ที่มา: will.com
