

คำศัพท์ด้าน Data Science ทั้งสองคำนี้สร้างความสับสนให้กับผู้คนจำนวนมาก Data Mining มักถูกเข้าใจผิดว่าเป็นการแยกและดึงข้อมูล แต่ในความเป็นจริงนั้นซับซ้อนกว่ามาก ในโพสต์นี้ เราจะมาพูดถึงประเด็น Mining และค้นหาความแตกต่างระหว่าง Data Mining และ Data Extraction
การทำเหมืองข้อมูลคืออะไร?
การทำเหมืองข้อมูลหรือที่เรียกว่า การค้นพบความรู้ฐานข้อมูล (KDD)เป็นเทคนิคที่มักใช้ในการวิเคราะห์ชุดข้อมูลขนาดใหญ่โดยใช้วิธีทางสถิติและคณิตศาสตร์เพื่อค้นหารูปแบบหรือแนวโน้มที่ซ่อนอยู่และดึงคุณค่าออกมา
Data Mining ทำอะไรได้บ้าง?
โดยการทำให้กระบวนการเป็นอัตโนมัติ สามารถเรียกดูฐานข้อมูลและค้นพบรูปแบบที่ซ่อนอยู่ได้อย่างมีประสิทธิภาพ สำหรับธุรกิจ การทำเหมืองข้อมูลมักใช้เพื่อค้นหารูปแบบและความสัมพันธ์ในข้อมูลเพื่อช่วยในการตัดสินใจทางธุรกิจได้ดีขึ้น
ตัวอย่างการใช้งาน
หลังจากที่การทำเหมืองข้อมูลแพร่หลายในช่วงทศวรรษ 1990 บริษัทในอุตสาหกรรมต่างๆ มากมาย รวมถึงการค้าปลีก การเงิน การดูแลสุขภาพ การขนส่ง โทรคมนาคม อีคอมเมิร์ซ ฯลฯ ได้เริ่มใช้เทคนิคการทำเหมืองข้อมูลเพื่อรับข้อมูลโดยอาศัยข้อมูล การขุดข้อมูลสามารถช่วยแบ่งกลุ่มลูกค้า ตรวจจับการฉ้อโกง คาดการณ์ยอดขาย และอื่นๆ อีกมากมาย
- การแบ่งส่วนลูกค้า
ด้วยการวิเคราะห์ข้อมูลลูกค้าและระบุคุณลักษณะของลูกค้าเป้าหมาย บริษัทสามารถจัดกลุ่มพวกเขาออกเป็นกลุ่มแยกต่างหากและมอบข้อเสนอพิเศษที่ตรงตามความต้องการของพวกเขา - การวิเคราะห์ตะกร้าตลาด
เทคนิคนี้อิงตามทฤษฎีที่ว่าหากคุณซื้อผลิตภัณฑ์กลุ่มใดกลุ่มหนึ่ง คุณมีแนวโน้มที่จะซื้อผลิตภัณฑ์กลุ่มอื่นมากขึ้น ตัวอย่างหนึ่งที่โด่งดัง: เมื่อพ่อซื้อผ้าอ้อมให้ลูก พวกเขามักจะซื้อเบียร์ควบคู่กับผ้าอ้อม - การพยากรณ์การขาย
อาจดูคล้ายกับการวิเคราะห์ตะกร้าตลาด แต่การวิเคราะห์ข้อมูลในครั้งนี้ใช้เพื่อคาดการณ์ว่าลูกค้าจะซื้อผลิตภัณฑ์อีกครั้งเมื่อใดในอนาคต ตัวอย่างเช่น โค้ชซื้อโปรตีนหนึ่งกระป๋องซึ่งน่าจะอยู่ได้ 9 เดือน ร้านค้าที่ขายโปรตีนนี้วางแผนที่จะออกโปรตีนตัวใหม่ภายใน 9 เดือนเพื่อให้โค้ชซื้ออีกครั้ง - การตรวจจับการฉ้อโกง
การทำเหมืองข้อมูลช่วยในการสร้างแบบจำลองเพื่อตรวจจับการฉ้อโกง ด้วยการรวบรวมตัวอย่างรายงานการฉ้อโกงและเป็นความจริง ธุรกิจต่างๆ มีอำนาจในการพิจารณาว่าธุรกรรมใดที่น่าสงสัย - การตรวจจับรูปแบบในการผลิต
ในอุตสาหกรรมการผลิต การทำเหมืองข้อมูลจะใช้เพื่อช่วยออกแบบระบบโดยระบุความสัมพันธ์ระหว่างสถาปัตยกรรมผลิตภัณฑ์ โปรไฟล์ และความต้องการของลูกค้า การทำเหมืองข้อมูลยังสามารถคาดการณ์เวลาและต้นทุนในการพัฒนาผลิตภัณฑ์ได้อีกด้วย
และนี่เป็นเพียงตัวอย่างบางส่วนสำหรับการใช้การขุดข้อมูล
ขั้นตอนของการขุดข้อมูล
การทำเหมืองข้อมูลเป็นกระบวนการแบบองค์รวมในการรวบรวม การเลือก การล้าง การแปลง และการดึงข้อมูลเพื่อประเมินรูปแบบ และสุดท้ายคือดึงคุณค่าออกมา
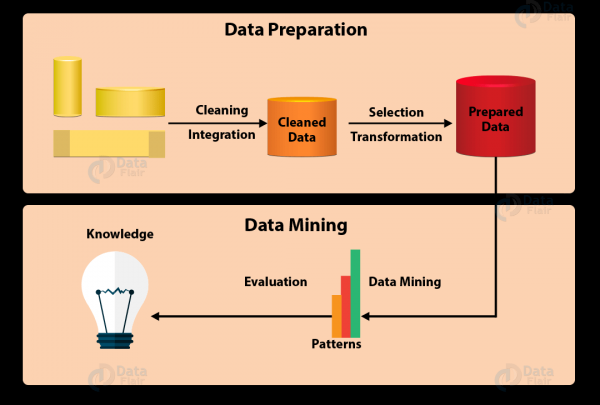
โดยทั่วไปกระบวนการขุดข้อมูลทั้งหมดสามารถสรุปได้เป็น 7 ขั้นตอน:
- การล้างข้อมูล
ในโลกแห่งความเป็นจริง ข้อมูลไม่ได้รับการทำความสะอาดและจัดโครงสร้างเสมอไป มักจะมีเสียงดัง ไม่สมบูรณ์ และอาจมีข้อผิดพลาด เพื่อให้แน่ใจว่าผลลัพธ์การขุดข้อมูลนั้นถูกต้อง คุณต้องล้างข้อมูลก่อน วิธีการทำความสะอาดบางอย่างรวมถึงการกรอกค่าที่หายไป การควบคุมอัตโนมัติและด้วยตนเอง และอื่นๆ - การรวมข้อมูล
นี่คือขั้นตอนที่ข้อมูลจากแหล่งต่างๆ จะถูกแยก รวม และบูรณาการ แหล่งที่มาอาจเป็นฐานข้อมูล ไฟล์ข้อความ สเปรดชีต เอกสาร ชุดข้อมูลหลายมิติ อินเทอร์เน็ต และอื่นๆ - การสุ่มตัวอย่างข้อมูล
โดยปกติแล้ว ไม่จำเป็นต้องใช้ข้อมูลแบบรวมทั้งหมดในการทำเหมืองข้อมูล การสุ่มตัวอย่างข้อมูลเป็นขั้นตอนในการเลือกและแยกเฉพาะข้อมูลที่เป็นประโยชน์จากฐานข้อมูลขนาดใหญ่ - การแปลงข้อมูล
เมื่อเลือกข้อมูลแล้ว ข้อมูลจะถูกแปลงเป็นรูปแบบที่เหมาะสมสำหรับการขุด กระบวนการนี้รวมถึงการทำให้เป็นมาตรฐาน การรวมกลุ่ม การทำให้เป็นลักษณะทั่วไป ฯลฯ - การทำเหมืองข้อมูล
มาถึงส่วนที่สำคัญที่สุดของการขุดข้อมูลโดยใช้วิธีการที่ชาญฉลาดเพื่อค้นหารูปแบบในนั้น กระบวนการนี้รวมถึงการถดถอย การจำแนกประเภท การทำนาย การจัดกลุ่ม การเรียนรู้แบบเชื่อมโยง และอื่นๆ - การประเมินแบบจำลอง
ขั้นตอนนี้มีจุดมุ่งหมายเพื่อระบุรูปแบบที่อาจเป็นประโยชน์ เข้าใจง่าย และสนับสนุนสมมติฐาน - การเป็นตัวแทนความรู้
ในขั้นตอนสุดท้าย ข้อมูลที่ได้รับจะถูกนำเสนอในรูปแบบที่น่าสนใจโดยใช้วิธีการแสดงความรู้และการแสดงภาพ
ข้อเสียของการขุดข้อมูล
- ลงทุนเวลาและแรงงานจำนวนมาก
เนื่องจากการขุดข้อมูลเป็นกระบวนการที่ยาวและซับซ้อน จึงต้องใช้แรงงานที่มีประสิทธิผลและมีทักษะเป็นจำนวนมาก นักขุดข้อมูลสามารถใช้ประโยชน์จากเครื่องมือขุดข้อมูลที่มีประสิทธิภาพ แต่พวกเขาต้องการผู้เชี่ยวชาญในการเตรียมข้อมูลและทำความเข้าใจผลลัพธ์ ด้วยเหตุนี้จึงอาจต้องใช้เวลาสักระยะในการประมวลผลข้อมูลทั้งหมด - ความเป็นส่วนตัวและความปลอดภัยของข้อมูล
เนื่องจากการขุดข้อมูลรวบรวมข้อมูลลูกค้าผ่านวิธีการทางการตลาด จึงสามารถละเมิดความเป็นส่วนตัวของผู้ใช้ได้ นอกจากนี้แฮกเกอร์ยังสามารถรับข้อมูลที่จัดเก็บไว้ในระบบการทำเหมืองข้อมูลได้อีกด้วย สิ่งนี้ก่อให้เกิดภัยคุกคามต่อความปลอดภัยของข้อมูลลูกค้า หากข้อมูลที่ขโมยไปถูกใช้ในทางที่ผิด อาจเป็นอันตรายต่อผู้อื่นได้อย่างง่ายดาย
ข้างต้นเป็นการแนะนำโดยย่อเกี่ยวกับการขุดข้อมูล ดังที่ได้กล่าวไปแล้ว การทำเหมืองข้อมูลประกอบด้วยกระบวนการรวบรวมและบูรณาการข้อมูล ซึ่งรวมถึงกระบวนการแยกข้อมูล (data extraction) ในกรณีนี้ พูดได้อย่างปลอดภัยว่าการดึงข้อมูลอาจเป็นส่วนหนึ่งของกระบวนการขุดข้อมูลที่ยาวนาน
การสกัดข้อมูลคืออะไร?
กระบวนการนี้เรียกอีกอย่างว่า "การขุดข้อมูลเว็บ" และ "การขูดเว็บ" ซึ่งเป็นการแยกข้อมูลจากแหล่งข้อมูล (โดยปกติจะไม่มีโครงสร้างหรือมีโครงสร้างไม่ดี) ไปยังตำแหน่งรวมศูนย์และรวมศูนย์ไว้ในที่เดียวเพื่อจัดเก็บหรือประมวลผลเพิ่มเติม โดยเฉพาะแหล่งข้อมูลที่ไม่มีโครงสร้าง ได้แก่ เว็บเพจ อีเมล เอกสาร ไฟล์ PDF ข้อความที่สแกน รายงานเมนเฟรม ไฟล์ม้วน ประกาศ และอื่นๆ ที่จัดเก็บข้อมูลแบบรวมศูนย์อาจเป็นแบบโลคัล คลาวด์ หรือแบบไฮบริด สิ่งสำคัญคือต้องจำไว้ว่าการดึงข้อมูลไม่รวมถึงการประมวลผลหรือการวิเคราะห์อื่น ๆ ที่อาจเกิดขึ้นในภายหลัง
Data Extraction ทำอะไรได้บ้าง?
โดยพื้นฐานแล้ว วัตถุประสงค์ในการดึงข้อมูลแบ่งออกเป็น 3 ประเภท
- การเก็บถาวร
การดึงข้อมูลสามารถแปลงข้อมูลจากรูปแบบทางกายภาพ เช่น หนังสือ หนังสือพิมพ์ ใบแจ้งหนี้ เป็นรูปแบบดิจิทัล เช่น ฐานข้อมูลสำหรับจัดเก็บหรือสำรองข้อมูล - การเปลี่ยนรูปแบบข้อมูล
เมื่อคุณต้องการย้ายข้อมูลจากไซต์ปัจจุบันของคุณไปยังไซต์ใหม่ที่อยู่ระหว่างการพัฒนา คุณสามารถรวบรวมข้อมูลจากไซต์ของคุณเองได้โดยการแตกข้อมูล - Анализданных
การวิเคราะห์ข้อมูลเพิ่มเติมที่แยกออกมาเพื่อให้ได้ข้อมูลเชิงลึกเป็นเรื่องปกติ สิ่งนี้อาจดูคล้ายกับการขุดข้อมูล แต่โปรดจำไว้ว่าการขุดข้อมูลเป็นจุดประสงค์ของการขุดข้อมูล ไม่ใช่ส่วนหนึ่งของจุดประสงค์ดังกล่าว นอกจากนี้ข้อมูลยังได้รับการวิเคราะห์ที่แตกต่างกันอีกด้วย ตัวอย่างหนึ่ง: เจ้าของร้านค้าออนไลน์ดึงข้อมูลผลิตภัณฑ์จากไซต์อีคอมเมิร์ซ เช่น Amazon เพื่อติดตามกลยุทธ์ของคู่แข่งแบบเรียลไทม์ เช่นเดียวกับการขุดข้อมูล การดึงข้อมูลเป็นกระบวนการอัตโนมัติที่มีประโยชน์มากมาย ในอดีต ผู้คนเคยคัดลอกและวางข้อมูลด้วยตนเองจากที่หนึ่งไปยังอีกที่หนึ่ง ซึ่งใช้เวลานานมาก การดึงข้อมูลช่วยเพิ่มความเร็วในการรวบรวมและปรับปรุงความแม่นยำของข้อมูลที่แยกออกมาอย่างมาก
ตัวอย่างการใช้ Data Extraction
เช่นเดียวกับการขุดข้อมูล การทำเหมืองข้อมูลถูกนำมาใช้กันอย่างแพร่หลายในอุตสาหกรรมต่างๆ นอกเหนือจากการติดตามราคาอีคอมเมิร์ซแล้ว การขุดข้อมูลยังสามารถช่วยคุณในการค้นคว้า การรวบรวมข่าว การตลาด อสังหาริมทรัพย์ การเดินทางและการท่องเที่ยว การให้คำปรึกษา การเงิน และอื่นๆ อีกมากมาย
- รุ่นนำ
บริษัทสามารถดึงข้อมูลจากไดเร็กทอรี: Yelp, Crunchbase, Yellowpages และสร้างโอกาสในการขายสำหรับการพัฒนาธุรกิจ คุณสามารถชมวิดีโอด้านล่างเพื่อเรียนรู้วิธีดึงข้อมูลจากสมุดหน้าเหลืองด้วย . - การรวมเนื้อหาและข่าวสาร
เว็บไซต์รวบรวมเนื้อหาสามารถรับกระแสข้อมูลอย่างสม่ำเสมอจากหลายแหล่งและทำให้ไซต์ของตนทันสมัยอยู่เสมอ - การวิเคราะห์ความรู้สึก
หลังจากแยกบทวิจารณ์ ความคิดเห็น และคำรับรองจากโซเชียลเน็ตเวิร์ก เช่น Instagram และ Twitter แล้ว ผู้เชี่ยวชาญสามารถวิเคราะห์ทัศนคติพื้นฐานและรับข้อมูลเชิงลึกเกี่ยวกับวิธีการรับรู้แบรนด์ ผลิตภัณฑ์ หรือปรากฏการณ์
ขั้นตอนการสกัดข้อมูล
การดึงข้อมูลเป็นขั้นตอนแรกของ ETL (แยก, แปลง, โหลด: แยก, แปลง, โหลด) และ ELT (แยก, โหลด และแปลง) ETL และ ELT เป็นส่วนหนึ่งของกลยุทธ์การรวมข้อมูลที่สมบูรณ์ กล่าวอีกนัยหนึ่ง การดึงข้อมูลอาจเป็นส่วนหนึ่งของการดึงข้อมูล
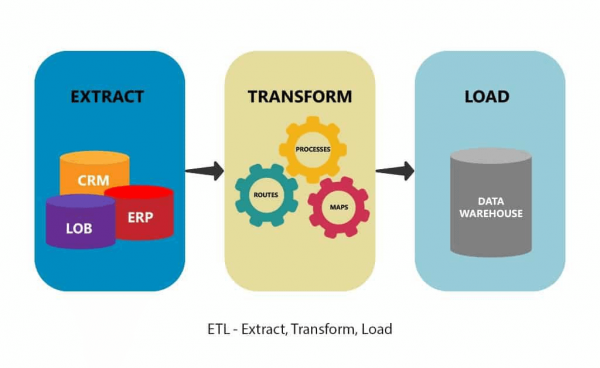
แยก แปลง โหลด
แม้ว่าการขุดข้อมูลจะเป็นการดึงข้อมูลจากข้อมูลจำนวนมาก แต่การดึงข้อมูลนั้นเป็นกระบวนการที่สั้นกว่าและง่ายกว่ามาก สามารถลดลงได้เป็นสามขั้นตอน:
- การเลือกแหล่งข้อมูล
เลือกแหล่งที่มาที่คุณต้องการดึงข้อมูล เช่น เว็บไซต์ - การเก็บรวบรวมข้อมูล
ส่งคำขอ "GET" ไปยังไซต์และแยกวิเคราะห์เอกสาร HTML ที่ได้โดยใช้ภาษาการเขียนโปรแกรมเช่น Python, PHP, R, Ruby เป็นต้น - การจัดเก็บข้อมูล
บันทึกข้อมูลลงในฐานข้อมูลท้องถิ่นหรือที่เก็บข้อมูลบนคลาวด์ของคุณเพื่อใช้ในอนาคต หากคุณเป็นโปรแกรมเมอร์ที่มีประสบการณ์และต้องการดึงข้อมูล ขั้นตอนข้างต้นอาจดูเหมือนง่ายสำหรับคุณ อย่างไรก็ตามหากคุณไม่ใช่โปรแกรมเมอร์ก็มีทางลัด - ใช้เครื่องมือขุดข้อมูลเช่น . เครื่องมือดึงข้อมูล เช่นเดียวกับเครื่องมือขุดข้อมูล ได้รับการออกแบบมาเพื่อประหยัดพลังงานและทำให้การประมวลผลข้อมูลเป็นเรื่องง่ายสำหรับทุกคน เครื่องมือเหล่านี้ไม่เพียงแต่ประหยัด แต่ยังเป็นมิตรกับผู้เริ่มต้นอีกด้วย ช่วยให้ผู้ใช้สามารถรวบรวมข้อมูลได้ภายในไม่กี่นาที เก็บไว้ในระบบคลาวด์ และส่งออกไปยังหลายรูปแบบ: Excel, CSV, HTML, JSON หรือไปยังฐานข้อมูลบนไซต์ผ่านทาง API
ข้อเสียของการดึงข้อมูล
- เซิร์ฟเวอร์ขัดข้อง
เมื่อแยกข้อมูลในปริมาณมาก เว็บเซิร์ฟเวอร์ของไซต์เป้าหมายอาจมีการโอเวอร์โหลด ซึ่งอาจทำให้เซิร์ฟเวอร์ล่มได้ สิ่งนี้จะส่งผลเสียต่อผลประโยชน์ของเจ้าของเว็บไซต์ - แบนโดย IP
เมื่อบุคคลรวบรวมข้อมูลบ่อยเกินไป เว็บไซต์สามารถบล็อกที่อยู่ IP ของตนได้ ทรัพยากรสามารถแบนที่อยู่ IP ได้อย่างสมบูรณ์หรือจำกัดการเข้าถึงโดยการทำให้ข้อมูลไม่สมบูรณ์ หากต้องการดึงข้อมูลและหลีกเลี่ยงการบล็อก คุณต้องดำเนินการด้วยความเร็วปานกลางและใช้เทคนิคป้องกันการบล็อกบางอย่าง - ปัญหาเกี่ยวกับกฎหมาย
การดึงข้อมูลจากเว็บถือเป็นพื้นที่สีเทาเมื่อพูดถึงเรื่องความถูกต้องตามกฎหมาย ไซต์หลักๆ เช่น Linkedin และ Facebook ระบุอย่างชัดเจนในเงื่อนไขการใช้งานว่าห้ามดึงข้อมูลโดยอัตโนมัติ มีการฟ้องร้องระหว่างบริษัทมากมายเนื่องจากกิจกรรมบอท
ความแตกต่างที่สำคัญระหว่างการขุดข้อมูลและการดึงข้อมูล
- การทำเหมืองข้อมูลเรียกอีกอย่างว่าการค้นพบความรู้ในฐานข้อมูล การดึงความรู้ การวิเคราะห์ข้อมูล/รูปแบบ การรวบรวมข้อมูล การดึงข้อมูลใช้สลับกันได้กับการดึงข้อมูลเว็บ การสแกนหน้าเว็บ การรวบรวมข้อมูล และอื่นๆ
- การวิจัยการทำเหมืองข้อมูลจะขึ้นอยู่กับข้อมูลที่มีโครงสร้างเป็นหลัก ในขณะที่การทำเหมืองข้อมูลมักจะดึงมาจากแหล่งข้อมูลที่ไม่มีโครงสร้างหรือมีโครงสร้างไม่ดี
- เป้าหมายของการขุดข้อมูลคือการทำให้ข้อมูลมีประโยชน์มากขึ้นสำหรับการวิเคราะห์ การดึงข้อมูลคือการรวบรวมข้อมูลไว้ในที่เดียวซึ่งสามารถจัดเก็บหรือประมวลผลได้
- การวิเคราะห์การทำเหมืองข้อมูลขึ้นอยู่กับวิธีการทางคณิตศาสตร์ในการระบุรูปแบบหรือแนวโน้ม การดึงข้อมูลขึ้นอยู่กับภาษาการเขียนโปรแกรมหรือเครื่องมือแยกข้อมูลเพื่อหลีกเลี่ยงแหล่งที่มา
- วัตถุประสงค์ของการขุดข้อมูลคือการค้นหาข้อเท็จจริงที่ไม่เคยรู้หรือละเลยมาก่อน ในขณะที่การดึงข้อมูลเกี่ยวข้องกับข้อมูลที่มีอยู่
- การทำเหมืองข้อมูลมีความซับซ้อนมากขึ้นและต้องใช้เงินลงทุนจำนวนมากในการฝึกอบรมบุคลากร การดึงข้อมูลด้วยเครื่องมือที่เหมาะสมสามารถทำได้ง่ายและคุ้มค่าอย่างยิ่ง
เราช่วยให้ผู้เริ่มต้นไม่สับสนกับข้อมูล โดยเฉพาะอย่างยิ่งสำหรับ habravchans เราได้จัดทำรหัสส่งเสริมการขาย ฮาเบอร์ให้ส่วนลดเพิ่มอีก 10% จากส่วนลดที่ระบุไว้บนแบนเนอร์
หลักสูตรเพิ่มเติม
บทความที่แนะนำ
ที่มา: will.com
