


ในที่สุด เราตรวจสอบรากฐานทางทฤษฎีของสถาปัตยกรรมเชิงโต้ตอบ ถึงเวลาพูดคุยเกี่ยวกับกระแสข้อมูล วิธีใช้งานระบบ Erlang/Elixir แบบโต้ตอบ และรูปแบบการส่งข้อความในระบบ:
- คำขอ-การตอบกลับ
- การตอบสนองคำขอเป็นก้อน
- ตอบสนองด้วยการร้องขอ
- เผยแพร่สมัครสมาชิก
- Inverted Publish-สมัครสมาชิก
- การกระจายงาน
SOA, MSA และการส่งข้อความ
SOA, MSA เป็นสถาปัตยกรรมระบบที่กำหนดกฎสำหรับการสร้างระบบ ในขณะที่การส่งข้อความให้พื้นฐานสำหรับการใช้งาน
ฉันไม่ต้องการโปรโมตสถาปัตยกรรมระบบนี้หรือสถาปัตยกรรมระบบนั้น ฉันใช้แนวปฏิบัติที่มีประสิทธิภาพและมีประโยชน์สูงสุดสำหรับโครงการและธุรกิจเฉพาะ ไม่ว่าเราจะเลือกกระบวนทัศน์แบบใด จะดีกว่าถ้าสร้างบล็อกระบบโดยคำนึงถึงแนวทาง Unix: ส่วนประกอบที่มีการเชื่อมต่อน้อยที่สุด รับผิดชอบสำหรับแต่ละเอนทิตี วิธีการ API ดำเนินการที่ง่ายที่สุดที่เป็นไปได้กับเอนทิตี
การส่งข้อความเป็นเหมือนนายหน้าข้อความ วัตถุประสงค์หลักคือเพื่อรับและส่งข้อความ มีหน้าที่รับผิดชอบอินเทอร์เฟซสำหรับการส่งข้อมูล การสร้างช่องทางลอจิคัลสำหรับการส่งข้อมูลภายในระบบ การกำหนดเส้นทางและการปรับสมดุล รวมถึงการจัดการข้อผิดพลาดในระดับระบบ
ข้อความที่เรากำลังพัฒนาไม่ได้พยายามแข่งขันหรือแทนที่ rabbitmq คุณสมบัติหลัก:
- การกระจาย.
สามารถสร้างจุดแลกเปลี่ยนได้บนโหนดคลัสเตอร์ทั้งหมด โดยให้ใกล้เคียงกับโค้ดที่ใช้จุดเหล่านั้นมากที่สุด - ความง่าย
มุ่งเน้นไปที่การลดขนาดโค้ดสำเร็จรูปและความสะดวกในการใช้งาน - ประสิทธิภาพที่ดีขึ้น
เราไม่ได้พยายามทำซ้ำฟังก์ชันการทำงานของ rabbitmq แต่เน้นเฉพาะเลเยอร์สถาปัตยกรรมและการขนส่ง ซึ่งเราใส่ลงใน OTP ได้ง่ายที่สุด เพื่อลดต้นทุน - ความยืดหยุ่น
แต่ละบริการสามารถรวมเทมเพลตการแลกเปลี่ยนจำนวนมากได้ - ความยืดหยุ่นโดยการออกแบบ
- ความสามารถในการปรับขนาด
การส่งข้อความเติบโตขึ้นพร้อมกับแอปพลิเคชัน เมื่อโหลดเพิ่มขึ้น คุณสามารถย้ายจุดแลกเปลี่ยนไปยังแต่ละเครื่องได้
หมายเหตุ ในแง่ของการจัดระเบียบโค้ด เมตาโปรเจ็กต์เหมาะอย่างยิ่งสำหรับระบบ Erlang/Elixir ที่ซับซ้อน รหัสโปรเจ็กต์ทั้งหมดอยู่ในที่เก็บข้อมูลเดียว - โปรเจ็กต์หลัก ในเวลาเดียวกัน ไมโครเซอร์วิสจะถูกแยกออกจากกันสูงสุดและดำเนินการง่ายๆ ที่รับผิดชอบเอนทิตีที่แยกจากกัน ด้วยวิธีนี้ ทำให้ง่ายต่อการรักษา API ของทั้งระบบ ง่ายต่อการเปลี่ยนแปลง สะดวกในการเขียนหน่วยและการทดสอบการรวม
ส่วนประกอบของระบบโต้ตอบโดยตรงหรือผ่านนายหน้า จากมุมมองของการรับส่งข้อความ แต่ละบริการมีหลายช่วงชีวิต:
- การเริ่มต้นบริการ
ในขั้นตอนนี้ กระบวนการและการขึ้นต่อกันที่ดำเนินการบริการได้รับการกำหนดค่าและเปิดใช้งาน - การสร้างจุดแลกเปลี่ยน
บริการสามารถใช้จุดแลกเปลี่ยนคงที่ที่ระบุในการกำหนดค่าโหนด หรือสร้างจุดแลกเปลี่ยนแบบไดนามิก - การลงทะเบียนบริการ
เพื่อให้บริการตามคำขอจะต้องลงทะเบียนที่จุดแลกเปลี่ยน - การทำงานปกติ
การบริการก่อให้เกิดผลงานที่เป็นประโยชน์ - ปิดตัวลง.
การปิดระบบทำได้ 2 แบบ คือ แบบปกติและแบบฉุกเฉิน ในระหว่างการดำเนินการตามปกติ บริการจะถูกตัดการเชื่อมต่อจากจุดแลกเปลี่ยนและหยุดลง ในสถานการณ์ฉุกเฉิน การส่งข้อความจะดำเนินการหนึ่งในสคริปต์เฟลโอเวอร์
มันดูค่อนข้างซับซ้อน แต่โค้ดก็ไม่ได้น่ากลัวขนาดนั้น ตัวอย่างโค้ดพร้อมความคิดเห็นจะได้รับในการวิเคราะห์เทมเพลตในภายหลัง
แลกเปลี่ยน
จุดแลกเปลี่ยนคือกระบวนการส่งข้อความที่ใช้ตรรกะของการโต้ตอบกับส่วนประกอบภายในเทมเพลตการส่งข้อความ ในตัวอย่างทั้งหมดที่นำเสนอด้านล่าง ส่วนประกอบโต้ตอบผ่านจุดแลกเปลี่ยน ซึ่งรวมกันเป็นรูปแบบการส่งข้อความ
รูปแบบการแลกเปลี่ยนข้อความ (MEP)
รูปแบบการแลกเปลี่ยนทั่วโลกสามารถแบ่งออกเป็นสองทางและทางเดียว แบบแรกหมายถึงการตอบสนองต่อข้อความที่เข้ามา ส่วนแบบหลังไม่ได้หมายความว่าจะตอบกลับ ตัวอย่างคลาสสิกของรูปแบบสองทางในสถาปัตยกรรมไคลเอ็นต์-เซิร์ฟเวอร์คือรูปแบบการตอบกลับคำขอ มาดูเทมเพลตและการแก้ไขกัน
คำขอตอบกลับหรือ RPC
RPC (Remote Client Process) ใช้เมื่อเราต้องการรับการตอบกลับจากกระบวนการอื่น กระบวนการนี้อาจทำงานอยู่บนโหนดเดียวกันหรืออยู่คนละทวีปก็ได้ แผนภาพด้านล่างแสดงการโต้ตอบระหว่างไคลเอ็นต์และ RPC เซิร์ฟเวอร์ ผ่านการส่งข้อความ
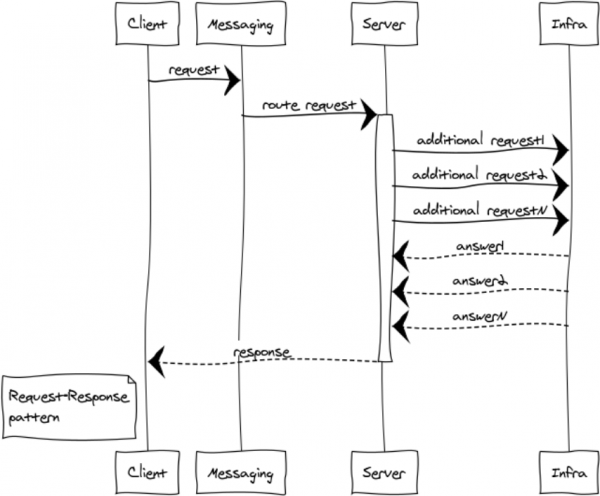
เนื่องจากการส่งข้อความเป็นแบบอะซิงโครนัสโดยสิ้นเชิง สำหรับลูกค้า การแลกเปลี่ยนจึงแบ่งออกเป็น 2 ระยะ:
กำลังส่งคำขอ
messaging:request(Exchange, ResponseMatchingTag, RequestDefinition, HandlerProcess).แลกเปลี่ยน – ชื่อเฉพาะของจุดแลกเปลี่ยน
แท็กการจับคู่การตอบสนอง ป้ายกำกับท้องถิ่นสำหรับการประมวลผลการตอบสนอง ตัวอย่างเช่น ในกรณีที่ส่งคำขอที่เหมือนกันหลายคำขอของผู้ใช้ที่แตกต่างกัน
คำนิยาม คำร้องขอ - คำขอร่างกาย
กระบวนการจัดการ – PID ของตัวจัดการ กระบวนการนี้จะได้รับการตอบกลับจากเซิร์ฟเวอร์กำลังประมวลผลการตอบสนอง
handle_info(#'$msg'{exchange = EXCHANGE, tag = ResponseMatchingTag,message = ResponsePayload}, State)การตอบสนองเพย์โหลด - การตอบสนองของเซิร์ฟเวอร์
สำหรับเซิร์ฟเวอร์ กระบวนการยังประกอบด้วย 2 เฟส:
- กำลังเริ่มต้นจุดแลกเปลี่ยน
- การประมวลผลคำขอที่ได้รับ
มาแสดงเทมเพลตนี้ด้วยโค้ดกัน สมมติว่าเราจำเป็นต้องใช้บริการง่ายๆ ที่ให้วิธีการเวลาที่แน่นอนเพียงวิธีเดียว
รหัสเซิร์ฟเวอร์
มากำหนดบริการ API ใน api.hrl:
%% =====================================================
%% entities
%% =====================================================
-record(time, {
unixtime :: non_neg_integer(),
datetime :: binary()
}).
-record(time_error, {
code :: non_neg_integer(),
error :: term()
}).
%% =====================================================
%% methods
%% =====================================================
-record(time_req, {
opts :: term()
}).
-record(time_resp, {
result :: #time{} | #time_error{}
}).มากำหนด service controller ใน time_controller.erl กัน
%% В примере показан только значимый код. Вставив его в шаблон gen_server можно получить рабочий сервис.
%% инициализация gen_server
init(Args) ->
%% подключение к точке обмена
messaging:monitor_exchange(req_resp, ?EXCHANGE, default, self())
{ok, #{}}.
%% обработка события потери связи с точкой обмена. Это же событие приходит, если точка обмена еще не запустилась.
handle_info(#exchange_die{exchange = ?EXCHANGE}, State) ->
erlang:send(self(), monitor_exchange),
{noreply, State};
%% обработка API
handle_info(#time_req{opts = _Opts}, State) ->
messaging:response_once(Client, #time_resp{
result = #time{ unixtime = time_utils:unixtime(now()), datetime = time_utils:iso8601_fmt(now())}
});
{noreply, State};
%% завершение работы gen_server
terminate(_Reason, _State) ->
messaging:demonitor_exchange(req_resp, ?EXCHANGE, default, self()),
ok.รหัสลูกค้า
หากต้องการส่งคำขอไปยังบริการ คุณสามารถเรียก API คำขอส่งข้อความได้ทุกที่ในไคลเอ็นต์:
case messaging:request(?EXCHANGE, tag, #time_req{opts = #{}}, self()) of
ok -> ok;
_ -> %% repeat or fail logic
endในระบบแบบกระจาย การกำหนดค่าส่วนประกอบอาจแตกต่างกันมากและในขณะที่ร้องขอ การส่งข้อความอาจยังไม่เริ่มต้น หรือตัวควบคุมบริการไม่พร้อมที่จะให้บริการตามคำขอ ดังนั้นเราจึงจำเป็นต้องตรวจสอบการตอบกลับข้อความและจัดการกับกรณีความล้มเหลว
หลังจากส่งสำเร็จ ลูกค้าจะได้รับการตอบสนองหรือข้อผิดพลาดจากบริการ
มาจัดการทั้งสองกรณีใน handle_info:
handle_info(#'$msg'{exchange = ?EXCHANGE, tag = tag, message = #time_resp{result = #time{unixtime = Utime}}}, State) ->
?debugVal(Utime),
{noreply, State};
handle_info(#'$msg'{exchange = ?EXCHANGE, tag = tag, message = #time_resp{result = #time_error{code = ErrorCode}}}, State) ->
?debugVal({error, ErrorCode}),
{noreply, State};การตอบสนองคำขอเป็นก้อน
ทางที่ดีควรหลีกเลี่ยงการส่งข้อความขนาดใหญ่ การตอบสนองและการทำงานที่เสถียรของทั้งระบบขึ้นอยู่กับสิ่งนี้ หากการตอบกลับแบบสอบถามใช้หน่วยความจำจำนวนมาก จำเป็นต้องแบ่งออกเป็นส่วนๆ
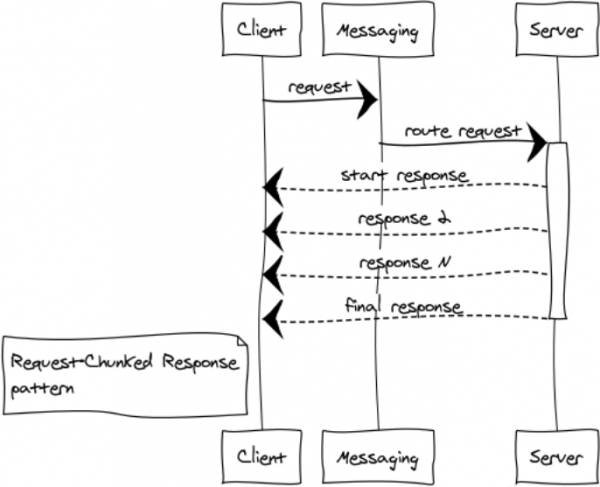
ฉันขอยกตัวอย่างบางส่วนของกรณีดังกล่าว:
- ส่วนประกอบจะแลกเปลี่ยนข้อมูลไบนารี เช่น ไฟล์ การแบ่งการตอบสนองออกเป็นส่วนเล็กๆ ช่วยให้คุณทำงานได้อย่างมีประสิทธิภาพกับไฟล์ทุกขนาด และหลีกเลี่ยงหน่วยความจำล้น
- รายการ ตัวอย่างเช่น เราจำเป็นต้องเลือกบันทึกทั้งหมดจากตารางขนาดใหญ่ในฐานข้อมูลและถ่ายโอนไปยังส่วนประกอบอื่น
ฉันเรียกสิ่งเหล่านี้ว่าหัวรถจักรตอบสนอง ไม่ว่าในกรณีใด 1024 ข้อความขนาด 1 MB ย่อมดีกว่าข้อความเดียวขนาด 1 GB
ในคลัสเตอร์ Erlang เราได้รับประโยชน์เพิ่มเติม - ลดภาระบนจุดแลกเปลี่ยนและเครือข่าย เนื่องจากการตอบกลับจะถูกส่งไปยังผู้รับทันที โดยข้ามจุดแลกเปลี่ยน
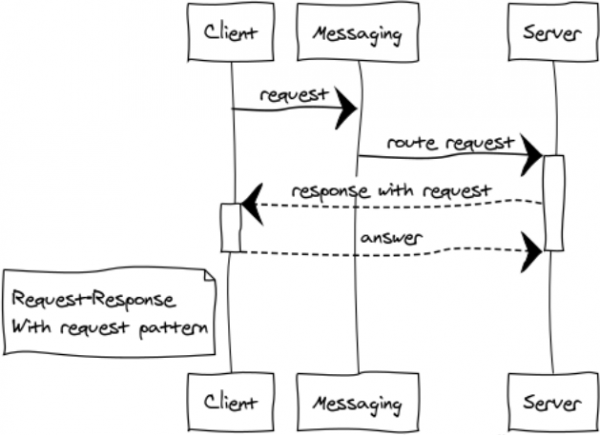
ตอบสนองด้วยการร้องขอ
นี่เป็นการปรับเปลี่ยนรูปแบบ RPC ที่ค่อนข้างหายากสำหรับการสร้างระบบโต้ตอบ
เผยแพร่-สมัครสมาชิก (แผนผังการกระจายข้อมูล)
ระบบที่ขับเคลื่อนด้วยเหตุการณ์จะส่งมอบให้กับผู้บริโภคทันทีที่ข้อมูลพร้อม ดังนั้น ระบบจึงมีแนวโน้มที่จะใช้โมเดลพุชมากกว่าโมเดลแบบดึงหรือสำรวจความคิดเห็น คุณสมบัตินี้ช่วยให้คุณหลีกเลี่ยงการสิ้นเปลืองทรัพยากรโดยการร้องขอและรอข้อมูลอย่างต่อเนื่อง
รูปภาพนี้แสดงกระบวนการเผยแพร่ข้อความถึงผู้บริโภคที่สมัครรับข้อมูลหัวข้อใดหัวข้อหนึ่ง
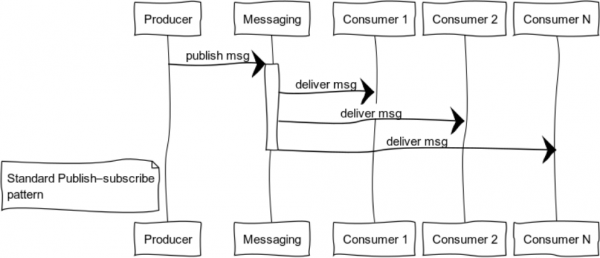
ตัวอย่างคลาสสิกของการใช้รูปแบบนี้คือการกระจายสถานะ: โลกของเกมในเกมคอมพิวเตอร์ ข้อมูลตลาดในการแลกเปลี่ยน ข้อมูลที่เป็นประโยชน์ในฟีดข้อมูล
ลองดูรหัสสมาชิก:
init(_Args) ->
%% подписываемся на обменник, ключ = key
messaging:subscribe(?SUBSCRIPTION, key, tag, self()),
{ok, #{}}.
handle_info(#exchange_die{exchange = ?SUBSCRIPTION}, State) ->
%% если точка обмена недоступна, то пытаемся переподключиться
messaging:subscribe(?SUBSCRIPTION, key, tag, self()),
{noreply, State};
%% обрабатываем пришедшие сообщения
handle_info(#'$msg'{exchange = ?SUBSCRIPTION, message = Msg}, State) ->
?debugVal(Msg),
{noreply, State};
%% при остановке потребителя - отключаемся от точки обмена
terminate(_Reason, _State) ->
messaging:unsubscribe(?SUBSCRIPTION, key, tag, self()),
ok.แหล่งที่มาสามารถเรียกใช้ฟังก์ชันเพื่อเผยแพร่ข้อความในตำแหน่งที่สะดวก:
messaging:publish_message(Exchange, Key, Message).แลกเปลี่ยน - ชื่อของจุดแลกเปลี่ยน
คีย์ - รหัสเส้นทาง
ระบุความประสงค์หรือข้อมูลเพิ่มเติม - น้ำหนักบรรทุก
Inverted Publish-สมัครสมาชิก
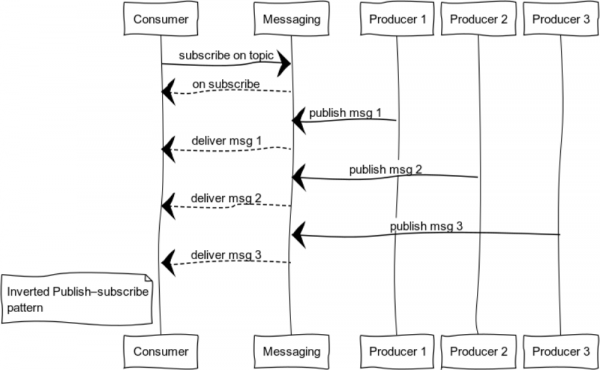
ด้วยการขยาย pub-sub คุณจะได้รูปแบบที่สะดวกสำหรับการบันทึก ชุดของแหล่งที่มาและผู้บริโภคอาจแตกต่างกันอย่างสิ้นเชิง รูปภาพนี้แสดงกรณีและปัญหาที่มีผู้บริโภครายเดียวและหลายแหล่งที่มา
รูปแบบการกระจายงาน
เกือบทุกโปรเจ็กต์เกี่ยวข้องกับงานการประมวลผลที่เลื่อนออกไป เช่น การสร้างรายงาน การส่งการแจ้งเตือน และการดึงข้อมูลจากระบบของบุคคลที่สาม ปริมาณงานของระบบที่ดำเนินงานเหล่านี้สามารถปรับขนาดได้อย่างง่ายดายโดยการเพิ่มตัวจัดการ สิ่งที่เหลืออยู่สำหรับเราคือการสร้างคลัสเตอร์ของโปรเซสเซอร์และกระจายงานระหว่างกันอย่างเท่าเทียมกัน
ลองดูสถานการณ์ที่เกิดขึ้นโดยใช้ตัวอย่างตัวจัดการ 3 ตัว แม้แต่ในขั้นตอนของการกระจายงาน คำถามเกี่ยวกับความเป็นธรรมในการกระจายและจำนวนผู้จัดการล้นมือก็ยังเกิดขึ้น การกระจายแบบพบกันหมดจะต้องรับผิดชอบต่อความเป็นธรรม และเพื่อหลีกเลี่ยงสถานการณ์ที่มีผู้ดูแลล้น เราจะแนะนำข้อจำกัด prefetch_limit. ในสภาวะชั่วคราว prefetch_limit จะป้องกันไม่ให้ตัวจัดการรายหนึ่งรับงานทั้งหมด
การส่งข้อความจัดการคิวและลำดับความสำคัญในการประมวลผล ผู้ประมวลผลได้รับงานเมื่อมาถึง งานสามารถทำได้สำเร็จหรือล้มเหลว:
messaging:ack(Tack)- เรียกว่าถ้าข้อความได้รับการประมวลผลสำเร็จmessaging:nack(Tack)- เรียกได้ในทุกสถานการณ์ฉุกเฉิน เมื่องานถูกส่งคืนแล้ว การส่งข้อความจะส่งต่อไปยังตัวจัดการรายอื่น
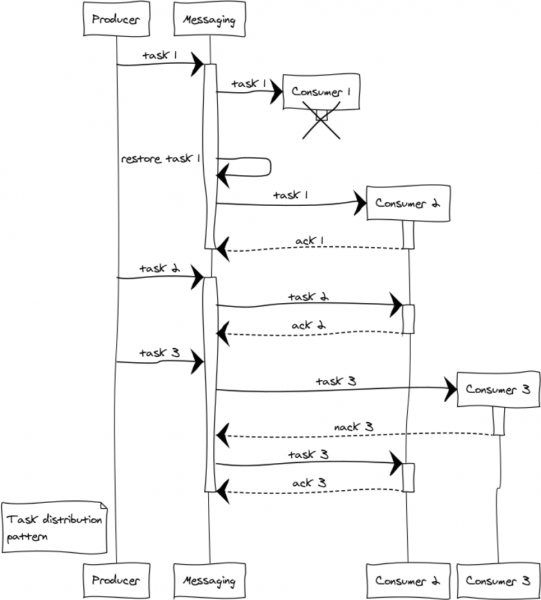
สมมติว่ามีความล้มเหลวที่ซับซ้อนเกิดขึ้นขณะประมวลผลสามงาน: โปรเซสเซอร์ 1 หลังจากได้รับงาน เกิดขัดข้องโดยไม่มีเวลาในการรายงานสิ่งใดไปยังจุดแลกเปลี่ยน ในกรณีนี้ จุดแลกเปลี่ยนจะโอนงานไปยังตัวจัดการอื่นหลังจากหมดเวลาการตอบรับแล้ว ด้วยเหตุผลบางประการ ตัวจัดการ 3 จึงละทิ้งงานและส่ง nack ออกไป ผลก็คือ งานจึงถูกโอนไปยังตัวจัดการอื่นที่ทำสำเร็จด้วย
สรุปเบื้องต้น
เราได้ครอบคลุมองค์ประกอบพื้นฐานของระบบแบบกระจาย และได้รับความเข้าใจพื้นฐานเกี่ยวกับการใช้งานระบบเหล่านี้ใน Erlang/Elixir
ด้วยการรวมรูปแบบพื้นฐานเข้าด้วยกัน คุณสามารถสร้างกระบวนทัศน์ที่ซับซ้อนเพื่อแก้ไขปัญหาที่เกิดขึ้นใหม่ได้
ในส่วนสุดท้ายของซีรีส์นี้ เราจะดูประเด็นทั่วไปของการจัดระเบียบบริการ การกำหนดเส้นทางและการปรับสมดุล และยังพูดคุยเกี่ยวกับด้านการปฏิบัติของความสามารถในการปรับขนาดและความทนทานต่อข้อผิดพลาดของระบบ
จบภาคสอง.
Фото
ภาพประกอบที่จัดทำขึ้นโดยใช้ websequencediagrams.com
ที่มา: will.com
