

เกริ่นนำสั้นๆ
ฉันเชื่อว่าเราสามารถทำสิ่งต่างๆ ได้มากขึ้นหากเราได้รับคำแนะนำทีละขั้นตอนที่จะบอกเราว่าต้องทำอะไรและต้องทำอย่างไร ตัวฉันเองจำช่วงเวลาในชีวิตที่ฉันไม่สามารถเริ่มต้นบางสิ่งบางอย่างได้เพราะมันยากที่จะเข้าใจว่าจะเริ่มต้นจากตรงไหน บางที กาลครั้งหนึ่งบนอินเทอร์เน็ต คุณเห็นคำว่า "วิทยาศาสตร์ข้อมูล" และตัดสินใจว่าคุณห่างไกลจากสิ่งนี้ และผู้คนที่ทำสิ่งนี้ก็อยู่ที่ไหนสักแห่งในโลกอื่น ไม่ พวกเขาอยู่ที่นี่ และบางทีอาจเป็นเพราะผู้คนจากสาขานี้ บทความจึงปรากฏบนฟีดของคุณ มีหลักสูตรมากมายที่จะช่วยให้คุณคุ้นเคยกับงานฝีมือนี้ แต่ที่นี่ฉันจะช่วยให้คุณเริ่มก้าวแรก
คุณพร้อมหรือยัง? ฉันขอบอกคุณทันทีว่าคุณจะต้องรู้จัก Python 3 เนื่องจากนั่นคือสิ่งที่ฉันจะใช้ที่นี่ ฉันแนะนำให้คุณติดตั้งบน Jupyter Notebook ล่วงหน้าหรือดูวิธีใช้ google colab
ขั้นตอนที่หนึ่ง

Kaggle คือผู้ช่วยคนสำคัญของคุณในเรื่องนี้ โดยหลักการแล้วคุณสามารถทำได้โดยไม่มีมัน แต่ฉันจะพูดถึงเรื่องนี้ในบทความอื่น นี่คือแพลตฟอร์มที่จัดการแข่งขัน Data Science ในการแข่งขันแต่ละครั้ง ในระยะแรก คุณจะได้รับประสบการณ์ที่ไม่สมจริงในการแก้ปัญหาประเภทต่างๆ ประสบการณ์การพัฒนา และประสบการณ์การทำงานเป็นทีม ซึ่งเป็นสิ่งสำคัญในยุคของเรา
เราจะรับหน้าที่ของเราจากที่นั่น มันถูกเรียกว่า "ไททานิค" เงื่อนไขคือ ทำนายว่าแต่ละคนจะรอดหรือไม่ โดยทั่วไปแล้ว งานของบุคคลที่เกี่ยวข้องกับ DS คือการรวบรวมข้อมูล ประมวลผล ฝึกอบรมแบบจำลอง พยากรณ์ และอื่นๆ ใน kaggle เราได้รับอนุญาตให้ข้ามขั้นตอนการรวบรวมข้อมูลได้ - ข้อมูลเหล่านี้จะถูกนำเสนอบนแพลตฟอร์ม เราจำเป็นต้องดาวน์โหลดและเริ่มต้นได้!
คุณสามารถทำได้ดังนี้:
แท็บข้อมูลมีไฟล์ที่มีข้อมูล


เราดาวน์โหลดข้อมูล เตรียมสมุดบันทึก Jupyter และ...
ขั้นตอนที่สอง
ตอนนี้เราจะโหลดข้อมูลนี้อย่างไร?
ขั้นแรก เรามานำเข้าไลบรารีที่จำเป็นกันก่อน:
import pandas as pd
import numpy as np
Pandas จะอนุญาตให้เราดาวน์โหลดไฟล์ .csv เพื่อการประมวลผลต่อไป
จำเป็นต้องใช้ Numpy เพื่อแสดงตารางข้อมูลของเราเป็นเมทริกซ์พร้อมตัวเลข
ไปข้างหน้า. ลองใช้ไฟล์ train.csv แล้วอัปโหลดให้เรา:
dataset = pd.read_csv('train.csv')
เราจะอ้างอิงถึงการเลือกข้อมูล train.csv ของเราผ่านตัวแปรชุดข้อมูล มาดูกันว่ามีอะไรบ้าง:
dataset.head()

ฟังก์ชัน head() ช่วยให้เราสามารถดูแถวแรกของ dataframe ได้
คอลัมน์ Survived คือผลลัพธ์ของเราอย่างชัดเจน ซึ่งทราบใน dataframe นี้ สำหรับคำถามเกี่ยวกับงาน เราต้องทำนายคอลัมน์ Survived สำหรับข้อมูล test.csv ข้อมูลนี้จัดเก็บข้อมูลเกี่ยวกับผู้โดยสารคนอื่น ๆ ของ Titanic ซึ่งเราแก้ไขปัญหาโดยไม่ทราบผลลัพธ์
เรามาแบ่งตารางของเราออกเป็นข้อมูลที่ขึ้นต่อกันและเป็นอิสระกัน ทุกอย่างเรียบง่ายที่นี่ ข้อมูลที่ขึ้นต่อกันคือข้อมูลที่ขึ้นอยู่กับข้อมูลอิสระที่อยู่ในผลลัพธ์ ข้อมูลที่เป็นอิสระคือข้อมูลที่มีอิทธิพลต่อผลลัพธ์
ตัวอย่างเช่น เรามีชุดข้อมูลต่อไปนี้:
“ Vova สอนวิทยาการคอมพิวเตอร์ - ไม่
Vova ได้รับ 2 คะแนนในด้านวิทยาการคอมพิวเตอร์”
เกรดในสาขาวิทยาการคอมพิวเตอร์ขึ้นอยู่กับคำตอบของคำถาม: Vova เรียนวิทยาการคอมพิวเตอร์หรือไม่? ชัดเจนไหม? เดินหน้าต่อไปเราใกล้ถึงเป้าหมายแล้ว!
ตัวแปรดั้งเดิมสำหรับข้อมูลอิสระคือ X สำหรับข้อมูลอิสระ y
เราทำสิ่งต่อไปนี้:
X = dataset.iloc[ : , 2 : ]
y = dataset.iloc[ : , 1 : 2 ]
มันคืออะไร? ด้วยฟังก์ชัน iloc[:, 2: ] เราบอก Python: ฉันต้องการดูตัวแปร X ข้อมูลที่เริ่มต้นจากคอลัมน์ที่สอง (รวมและโดยมีเงื่อนไขว่าการนับเริ่มจากศูนย์) ในบรรทัดที่สอง เราบอกว่าเราต้องการดูข้อมูลในคอลัมน์แรก
[ a:b, c:d ] คือการสร้างสิ่งที่เราใช้ในวงเล็บ หากคุณไม่ระบุตัวแปรใดๆ ตัวแปรเหล่านั้นจะถูกบันทึกเป็นค่าเริ่มต้น นั่นคือเราสามารถระบุ [:,: d] จากนั้นเราจะได้คอลัมน์ทั้งหมดใน dataframe ยกเว้นคอลัมน์ที่เริ่มจากหมายเลข d เป็นต้นไป ตัวแปร a และ b กำหนดสตริง แต่เราต้องการทั้งหมด ดังนั้นเราจึงปล่อยให้สิ่งนี้เป็นค่าเริ่มต้น
มาดูกันว่าเราได้อะไรบ้าง:
X.head()
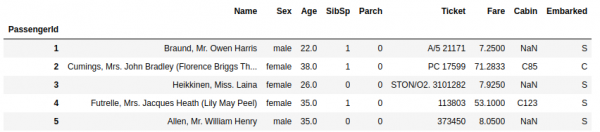
y.head()
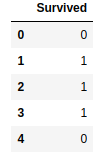
เพื่อทำให้บทเรียนเล็กๆ นี้ง่ายขึ้น เราจะลบคอลัมน์ที่ต้องได้รับการดูแลเป็นพิเศษหรือไม่ส่งผลกระทบต่อการเอาตัวรอดเลย มีข้อมูลประเภท str
count = ['Name', 'Ticket', 'Cabin', 'Embarked']
X.drop(count, inplace=True, axis=1)
สุด ๆ ! เรามาดูขั้นตอนต่อไปกันดีกว่า
ขั้นตอนที่สาม
ที่นี่เราจำเป็นต้องเข้ารหัสข้อมูลของเราเพื่อให้เครื่องเข้าใจได้ดีขึ้นว่าข้อมูลนี้ส่งผลต่อผลลัพธ์อย่างไร แต่เราจะไม่เข้ารหัสทุกอย่าง แต่จะเข้ารหัสเฉพาะข้อมูล str ที่เราทิ้งไว้เท่านั้น คอลัมน์ "เพศ" เราต้องการรหัสอย่างไร? เรามาแสดงข้อมูลเกี่ยวกับเพศของบุคคลเป็นเวกเตอร์: 10 - ชาย, 01 - หญิง
ก่อนอื่น มาแปลงตารางของเราให้เป็นเมทริกซ์ NumPy:
X = np.array(X)
y = np.array(y)
และตอนนี้เรามาดูกัน:
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder
ct = ColumnTransformer(transformers=[('encoder', OneHotEncoder(), [1])],
remainder='passthrough')
X = np.array(ct.fit_transform(X))
ห้องสมุด sklearn เป็นห้องสมุดที่ยอดเยี่ยมที่ช่วยให้เราสามารถทำงานด้าน Data Science ได้อย่างสมบูรณ์ ประกอบด้วยโมเดล Machine Learning ที่น่าสนใจจำนวนมาก และยังช่วยให้เราสามารถเตรียมข้อมูลได้อีกด้วย
OneHotEncoder จะอนุญาตให้เราเข้ารหัสเพศของบุคคลในการเป็นตัวแทนนั้น ตามที่เราอธิบายไว้ จะสร้าง 2 คลาส: ชาย, หญิง หากบุคคลนั้นเป็นผู้ชาย 1 จะถูกเขียนในคอลัมน์ "ชาย" และ 0 ในคอลัมน์ "หญิง" ตามลำดับ
หลังจาก OneHotEncoder() จะมี [1] - หมายความว่าเราต้องการเข้ารหัสคอลัมน์หมายเลข 1 (นับจากศูนย์)
สุด ๆ ก้าวไปอีกขั้น!
ตามกฎแล้วสิ่งนี้จะเกิดขึ้นโดยที่ข้อมูลบางส่วนเว้นว่างไว้ (นั่นคือ NaN - ไม่ใช่ตัวเลข) ตัวอย่างเช่น มีข้อมูลเกี่ยวกับบุคคล: ชื่อของเขา เพศ แต่ไม่มีข้อมูลเกี่ยวกับอายุของเขา ในกรณีนี้ เราจะใช้วิธีการต่อไปนี้: เราจะหาค่าเฉลี่ยเลขคณิตเหนือคอลัมน์ทั้งหมด และหากข้อมูลบางส่วนหายไปในคอลัมน์ เราก็จะเติมช่องว่างด้วยค่าเฉลี่ยเลขคณิต
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(missing_values=np.nan, strategy='mean')
imputer.fit(X)
X = imputer.transform(X)
ตอนนี้เรามาดูกันว่าสถานการณ์เกิดขึ้นเมื่อข้อมูลมีขนาดใหญ่มาก ข้อมูลบางส่วนอยู่ในช่วงเวลา [0:1] ในขณะที่ข้อมูลบางส่วนอาจมีค่าเกินร้อยนับพัน เพื่อกำจัดการกระจายดังกล่าวและทำให้คอมพิวเตอร์แม่นยำยิ่งขึ้นในการคำนวณ เราจะสแกนข้อมูลและปรับขนาด ให้ตัวเลขทั้งหมดไม่เกินสาม เมื่อต้องการทำเช่นนี้ เราจะใช้ฟังก์ชัน StandardScaler
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X[:, 2:] = sc.fit_transform(X[:, 2:])
ตอนนี้ข้อมูลของเรามีลักษณะดังนี้:

ระดับ. เราใกล้บรรลุเป้าหมายแล้ว!
ขั้นตอนที่สี่
มาฝึกโมเดลรุ่นแรกกันเถอะ! จากห้องสมุด sklearn เราพบสิ่งที่น่าสนใจมากมาย ฉันใช้โมเดล Gradient Boosting Classifier กับปัญหานี้ เราใช้ลักษณนามเพราะงานของเราคืองานการจัดหมวดหมู่ การพยากรณ์โรคควรกำหนดให้เป็น 1 (รอด) หรือ 0 (ไม่รอด)
from sklearn.ensemble import GradientBoostingClassifier
gbc = GradientBoostingClassifier(learning_rate=0.5, max_depth=5, n_estimators=150)
gbc.fit(X, y)
ฟังก์ชัน fit จะบอก Python ว่าให้โมเดลค้นหาการขึ้นต่อกันระหว่าง X และ y
ไม่ถึงวินาที โมเดลก็พร้อม

วิธีการสมัคร? เราจะได้เห็นกันตอนนี้!
ขั้นตอนที่ห้า บทสรุป
ตอนนี้เราจำเป็นต้องโหลดตารางที่มีข้อมูลการทดสอบของเราซึ่งเราจำเป็นต้องทำการคาดการณ์ ด้วยตารางนี้ เราจะดำเนินการแบบเดียวกับที่เราทำกับ X
X_test = pd.read_csv('test.csv', index_col=0)
count = ['Name', 'Ticket', 'Cabin', 'Embarked']
X_test.drop(count, inplace=True, axis=1)
X_test = np.array(X_test)
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder
ct = ColumnTransformer(transformers=[('encoder', OneHotEncoder(), [1])],
remainder='passthrough')
X_test = np.array(ct.fit_transform(X_test))
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(missing_values=np.nan, strategy='mean')
imputer.fit(X_test)
X_test = imputer.transform(X_test)
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_test[:, 2:] = sc.fit_transform(X_test[:, 2:])
ลองใช้โมเดลของเราตอนนี้เลย!
gbc_predict = gbc.predict(X_test)
ทั้งหมด. เราทำการคาดการณ์ ตอนนี้จะต้องบันทึกเป็น CSV และส่งไปที่เว็บไซต์
np.savetxt('my_gbc_predict.csv', gbc_predict, delimiter=",", header = 'Survived')
พร้อม. เราได้รับไฟล์ที่มีคำทำนายสำหรับผู้โดยสารแต่ละคน สิ่งที่เหลืออยู่คือการอัปโหลดโซลูชันเหล่านี้ไปยังเว็บไซต์และรับการประเมินการคาดการณ์ วิธีแก้ปัญหาแบบดั้งเดิมดังกล่าวไม่เพียงแต่ให้คำตอบที่ถูกต้องต่อสาธารณะเพียง 74% เท่านั้น แต่ยังเป็นแรงผลักดันใน Data Science อีกด้วย ผู้ที่อยากรู้อยากเห็นมากที่สุดสามารถเขียนถึงฉันในข้อความส่วนตัวได้ตลอดเวลาและถามคำถาม ขอบคุณทุกคน!
ที่มา: will.com
