

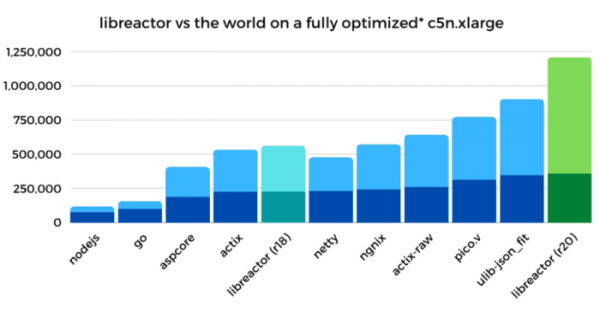
คู่มือฉบับละเอียดเกี่ยวกับการปรับแต่งสภาพแวดล้อมได้รับการเผยแพร่แล้ว Linux เพื่อให้ได้ประสิทธิภาพสูงสุดในการประมวลผลคำขอ HTTP วิธีการที่เสนอช่วยให้เราเพิ่มประสิทธิภาพของตัวแยกวิเคราะห์ JSON ที่ใช้ไลบรารี libreactor ในสภาพแวดล้อม Amazon EC2 (4 vCPU) จาก 224 คำขอ API ต่อวินาที ภายใต้การตั้งค่ามาตรฐานของ Amazon Linux การปรับปรุงประสิทธิภาพด้วยเคอร์เนลเวอร์ชัน 4.14 ทำให้ปริมาณงานเพิ่มขึ้นเป็น 1.2 ล้านคำขอต่อวินาที (เพิ่มขึ้น 436%) และยังลดเวลาแฝงในการประมวลผลคำขอลง 79% วิธีการที่เสนอมานี้ไม่จำกัดเฉพาะ Libreactor และใช้งานได้กับเซิร์ฟเวอร์ HTTP อื่นๆ รวมถึง nginx, Actix, Netty และ Node.js (ในการทดสอบใช้ Libreactor เนื่องจากโซลูชันที่ใช้ Libreactor แสดงให้เห็นถึงประสิทธิภาพที่ดีกว่า)
การเพิ่มประสิทธิภาพขั้นพื้นฐาน:
- การเพิ่มประสิทธิภาพโค้ด libreactor ตัวเลือก R18 จากชุด Techempower ถูกใช้เป็นพื้นฐาน ซึ่งได้รับการปรับปรุงโดยการลบโค้ดเพื่อจำกัดจำนวนคอร์ CPU ที่ใช้ (การเพิ่มประสิทธิภาพอนุญาตให้เร่งการทำงานได้ 25-27%) โดยประกอบใน GCC ด้วยตัวเลือก "-O3" (เพิ่มขึ้น 5-10% ) และ "-march-native" (5-10%) แทนที่การเรียกอ่าน/เขียนด้วย recv/send (5-10%) และลดค่าใช้จ่ายเมื่อใช้ pthreads (2-3%) . ประสิทธิภาพโดยรวมเพิ่มขึ้นหลังจากการเพิ่มประสิทธิภาพโค้ดคือ 55% และปริมาณงานเพิ่มขึ้นจาก 224k req/s เป็น 347k req/s
- การปิดใช้งานการป้องกันช่องโหว่ที่เกิดจากการประมวลผลคำสั่งแบบคาดการณ์ล่วงหน้า การใช้พารามิเตอร์การบูตเคอร์เนล "nospectre_v1 nospectre_v2 pti=off mds=off tsx_async_abort=off" ช่วยเพิ่มประสิทธิภาพได้ 28% และปริมาณงานเพิ่มขึ้นจาก 347k คำขอ/วินาที เป็น 446k คำขอ/วินาที โดยแยกเป็นรายพารามิเตอร์แล้ว การเพิ่มประสิทธิภาพจาก "nospectre_v1" (การป้องกัน Spectre v1 + SWAPGS) อยู่ที่ 1-2%, "nospectre_v2" (การป้องกัน Spectre v2) อยู่ที่ 15-20%, "pti=off" (Spectre v3/Meltdown) อยู่ที่ 6%, และ "mds=off tsx_async_abort=off" (MDS/Zombieload และ TSX Asynchronous Abort) อยู่ที่ 6% การตั้งค่าสำหรับการป้องกันการโจมตี L1TF/Foreshadow (l1tf=flush), iTLB multihit, Speculative Store Bypass และ SRBDS ซึ่งไม่ส่งผลกระทบต่อประสิทธิภาพการทำงานนั้น ยังคงไม่เปลี่ยนแปลง เนื่องจากไม่ได้ทับซ้อนกับการกำหนดค่าที่ทดสอบ (ตัวอย่างเช่น การตั้งค่าเหล่านี้เฉพาะเจาะจงสำหรับ...) KVM(รวมถึงการจำลองเสมือนแบบซ้อนกันและโมเดล CPU อื่นๆ)
- ปิดใช้งานกลไกการตรวจสอบและการบล็อกการโทรของระบบโดยใช้คำสั่ง "auditctl -a never,task" และระบุตัวเลือก "--security-opt seccomp=unconfined" เมื่อเริ่มต้นคอนเทนเนอร์นักเทียบท่า ประสิทธิภาพโดยรวมเพิ่มขึ้น 11% และปริมาณงานเพิ่มขึ้นจาก 446k req/s เป็น 495k req/s
- การปิดใช้งาน iptables/netfilter โดยการยกเลิกการโหลดโมดูลเคอร์เนลที่เกี่ยวข้อง แนวคิดในการปิดใช้งานไฟร์วอลล์ที่ไม่ได้ใช้ในโซลูชันเซิร์ฟเวอร์เฉพาะนั้น เกิดจากผลการวิเคราะห์ประสิทธิภาพ ซึ่งแสดงให้เห็นว่าฟังก์ชัน nf_hook_slow ใช้เวลาในการทำงาน 18% เป็นที่ทราบกันดีว่า nftables มีประสิทธิภาพมากกว่า iptables แต่ใน Amazon Linux iptables ยังคงถูกใช้งานอยู่ หลังจากปิดใช้งาน iptables แล้ว ประสิทธิภาพเพิ่มขึ้น 22% และปริมาณงานเพิ่มขึ้นจาก 495 คำขอต่อวินาที เป็น 603 คำขอต่อวินาที
- ลดการย้ายตัวจัดการระหว่างคอร์ CPU ที่แตกต่างกันเพื่อปรับปรุงประสิทธิภาพของการใช้แคชของโปรเซสเซอร์ การเพิ่มประสิทธิภาพดำเนินการทั้งในระดับของกระบวนการผูก libreactor กับคอร์ CPU (CPU Pinning) และผ่านการปักหมุดตัวจัดการเครือข่ายเคอร์เนล (Receive Side Scaling) ตัวอย่างเช่น irqbalance ถูกปิดใช้งาน และความสัมพันธ์ของคิวกับ CPU ถูกตั้งค่าอย่างชัดเจนใน /proc/irq/$IRQ/smp_affinity_list หากต้องการใช้ CPU core เดียวกันในการประมวลผลกระบวนการ libreactor และคิวเครือข่ายของแพ็กเก็ตขาเข้า ระบบจะใช้ตัวจัดการ BPF แบบกำหนดเอง เชื่อมต่อโดยการตั้งค่าแฟล็ก SO_ATTACH_REUSEPORT_CBPF เมื่อสร้างซ็อกเก็ต หากต้องการผูกคิวของแพ็กเก็ตขาออกเข้ากับ CPU การตั้งค่า /sys/class/net/eth0/queues/tx- ได้ถูกเปลี่ยนแปลงแล้ว /xps_cpus. ประสิทธิภาพโดยรวมเพิ่มขึ้น 38% และปริมาณงานเพิ่มขึ้นจาก 603k req/s เป็น 834k req/s
- การเพิ่มประสิทธิภาพการจัดการการขัดจังหวะและการใช้โพล การเปิดใช้งานโหมด Adaptive-rx ในไดรเวอร์ ENA และการจัดการ sysctl net.core.busy_read เพิ่มประสิทธิภาพขึ้น 28% (ปริมาณงานเพิ่มขึ้นจาก 834k req/s เป็น 1.06M req/s และเวลาแฝงลดลงจาก 361μs เป็น 292μs)
- ปิดใช้งานบริการระบบที่ทำให้เกิดการล็อกสแต็กเครือข่ายโดยไม่จำเป็น ปิดใช้งาน dhclient และติดตั้งใหม่ ที่อยู่ IP การดำเนินการนี้ด้วยตนเองส่งผลให้ประสิทธิภาพเพิ่มขึ้น 6% โดยปริมาณงานเพิ่มขึ้นจาก 1.06 ล้านคำขอต่อวินาที เป็น 1.12 ล้านคำขอต่อวินาที สาเหตุที่ dhclient มีผลต่อประสิทธิภาพนั้นเกิดจากการวิเคราะห์ปริมาณการรับส่งข้อมูลโดยใช้ raw socket
- ต่อสู้ล็อคสปิน การสลับสแต็กเครือข่ายเป็นโหมด “noqueue” ผ่าน sysctl “net.core.default_qdisc=noqueue” และ “tc qdisc แทนที่ dev eth0 root mq” ส่งผลให้ประสิทธิภาพเพิ่มขึ้น 2% และปริมาณงานเพิ่มขึ้นจาก 1.12M req/s เป็น 1.15M ความต้องการ/s
- การปรับปรุงประสิทธิภาพเล็กๆ น้อยๆ ในขั้นสุดท้าย เช่น การปิดใช้งาน GRO (การรับส่งข้อมูลทั่วไป) ด้วยคำสั่ง “ethtool -K eth0 gro off” และแทนที่อัลกอริธึมควบคุมความแออัดแบบลูกบาศก์ด้วย reno โดยใช้ sysctl “net.ipv4.tcp_congestion_control=reno” ผลผลิตโดยรวมเพิ่มขึ้น 4% ปริมาณงานเพิ่มขึ้นจาก 1.15M req/s เป็น 1.2M req/s
นอกเหนือจากการเพิ่มประสิทธิภาพที่ได้ผลแล้ว บทความนี้ยังกล่าวถึงวิธีการที่ไม่นำไปสู่การเพิ่มประสิทธิภาพที่คาดหวังอีกด้วย ตัวอย่างเช่น สิ่งต่อไปนี้กลับกลายเป็นว่าไม่ได้ผล:
- การเรียกใช้ libreactor แบบแยกกันไม่ได้ทำให้ประสิทธิภาพแตกต่างจากการรันในคอนเทนเนอร์ การแทนที่ writev ด้วย send การเพิ่ม maxevents ใน epoll_wait และการทดลองกับเวอร์ชันและแฟล็ก GCC ไม่มีผลใด ๆ (ผลกระทบจะสังเกตเห็นได้เฉพาะสำหรับแฟล็ก "-O3" และ "-march-native")
- การอัปเดตเคอร์เนลไม่ได้ส่งผลกระทบต่อประสิทธิภาพการทำงาน Linux จนถึงเวอร์ชัน 4.19 และ 5.4 โดยใช้ตัวกำหนดตารางเวลา SCHED_FIFO และ SCHED_RR โดยปรับแต่งค่า sysctl kernel.sched_min_granularity_ns, kernel.sched_wakeup_granularity_ns, transparent_hugepages=never, skew_tick=1 และ clocksource=tsc
- ในไดรเวอร์ ENA การเปิดใช้งานโหมดออฟโหลด (การแบ่งส่วน, การรวบรวมกระจาย, การตรวจสอบ rx/tx), การสร้างด้วยแฟล็ก “-O3” และการใช้พารามิเตอร์ ena.rx_queue_size และ ena.force_large_llq_header ไม่มีผลใดๆ
- การเปลี่ยนแปลงในสแต็กเครือข่ายไม่ได้ปรับปรุงประสิทธิภาพ:
- ปิดการใช้งาน IPv6: ipv6.disable=1
- ปิดการใช้งาน VLAN: modprobe -rv 8021q
- ปิดใช้การตรวจสอบแหล่งที่มาของแพ็กเกจ
- net.ipv4.conf.all.rp_filter=0
- net.ipv4.conf.eth0.rp_filter=0
- net.ipv4.conf.all.accept_local=1 (ผลเสีย)
- net.ipv4.tcp_sack = 0
- net.ipv4.tcp_dsack=0
- net.ipv4.tcp_mem/tcp_wmem/tcp_rmem
- net.core.netdev_budget
- net.core.dev_weight
- net.core.netdev_max_backlog
- net.ipv4.tcp_slow_start_after_idle=0
- net.ipv4.tcp_moderate_rcvbuf=0
- net.ipv4.tcp_timestamps=0
- net.ipv4.tcp_low_latency = 1
- SO_ลำดับความสำคัญ
- TCP_NODELAY
ที่มา: opennet.ru
