

Sa ngayon, ang serbisyo ng Bitrix24 ay walang daan-daang gigabits ng trapiko, at wala rin itong napakalaking fleet ng mga server (bagaman, siyempre, medyo marami ang umiiral). Ngunit para sa maraming mga kliyente ito ang pangunahing tool para sa pagtatrabaho sa kumpanya; ito ay isang tunay na aplikasyon na kritikal sa negosyo. Samakatuwid, walang paraan upang mahulog. Paano kung nangyari nga ang pag-crash, ngunit ang serbisyo ay "nabawi" nang napakabilis na walang nakapansin ng anuman? At paano posible na ipatupad ang failover nang hindi nawawala ang kalidad ng trabaho at ang bilang ng mga kliyente? Si Alexander Demidov, direktor ng mga serbisyo sa cloud sa Bitrix24, ay nagsalita para sa aming blog tungkol sa kung paano umunlad ang sistema ng reserbasyon sa loob ng 7 taon ng pagkakaroon ng produkto.

"Inilunsad namin ang Bitrix24 bilang isang SaaS 7 taon na ang nakakaraan. Ang pangunahing kahirapan ay marahil ang mga sumusunod: bago ito inilunsad sa publiko bilang SaaS, ang produktong ito ay umiral lamang sa format ng isang boxed solution. Binili ito ng mga kliyente mula sa amin, na-host ito sa kanilang mga server, nag-set up ng corporate portal - isang pangkalahatang solusyon para sa komunikasyon ng empleyado, pag-iimbak ng file, pamamahala ng gawain, CRM, iyon lang. At noong 2012, napagpasyahan namin na gusto naming ilunsad ito bilang SaaS, pinangangasiwaan ito mismo, tinitiyak ang pagpapahintulot at pagiging maaasahan ng pagkakamali. Nakakuha kami ng karanasan sa daan, dahil hanggang noon ay wala kami nito - kami ay mga tagagawa lamang ng software, hindi mga service provider.
Kapag inilunsad ang serbisyo, naunawaan namin na ang pinakamahalagang bagay ay upang matiyak ang pagpapahintulot sa pagkakamali, pagiging maaasahan at patuloy na pagkakaroon ng serbisyo, dahil kung mayroon kang isang simpleng ordinaryong website, isang tindahan, halimbawa, at ito ay nahuhulog sa iyo at nakaupo doon para sa isang oras, ikaw lang ang nagdurusa, nawalan ka ng mga order , nawalan ka ng mga kliyente, ngunit para sa iyong kliyente mismo, hindi ito masyadong kritikal para sa kanya. Nagalit siya, siyempre, ngunit pumunta siya at binili ito sa ibang site. At kung ito ay isang application kung saan ang lahat ng trabaho sa loob ng kumpanya, komunikasyon, mga desisyon ay nakatali, kung gayon ang pinakamahalagang bagay ay upang makuha ang tiwala ng mga gumagamit, iyon ay, hindi upang pabayaan sila at hindi mahulog. Dahil lahat ng trabaho ay maaaring huminto kung ang isang bagay sa loob ay hindi gumagana.
Bitrix.24 bilang SaaS
Binuo namin ang unang prototype isang taon bago ang pampublikong paglulunsad, noong 2011. Binubuo namin ito sa loob ng halos isang linggo, tiningnan ito, pinaikot-ikot - ito ay gumagana. Iyon ay, maaari kang pumunta sa form, ipasok ang pangalan ng portal doon, magbubukas ang isang bagong portal, at isang user base ang gagawin. Tiningnan namin ito, tinasa ang produkto sa prinsipyo, tinanggal ito, at ipinagpatuloy itong pinuhin sa loob ng isang buong taon. Dahil mayroon kaming malaking gawain: hindi namin gustong gumawa ng dalawang magkaibang base ng code, hindi namin gustong suportahan ang isang hiwalay na naka-package na produkto, hiwalay na mga solusyon sa cloud - gusto naming gawin ang lahat sa loob ng isang code.
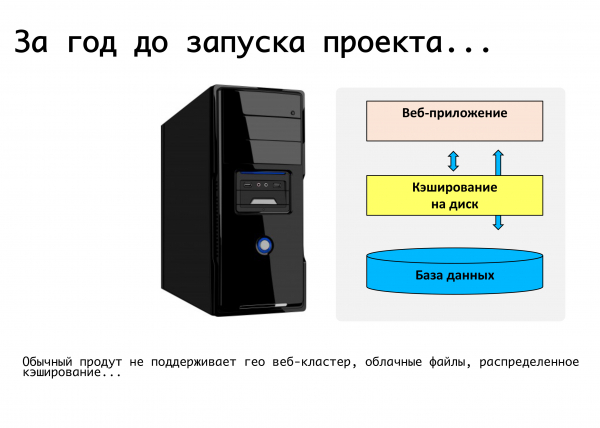
Ang isang tipikal na web application sa oras na iyon ay isang server kung saan tumatakbo ang ilang PHP code, isang mysql database, mga file ay na-upload, mga dokumento, mga larawan ay inilalagay sa folder ng pag-upload - mabuti, gumagana ang lahat. Sa kasamaang palad, imposibleng maglunsad ng isang kritikal na matatag na serbisyo sa web gamit ito. Doon, hindi sinusuportahan ang ibinahagi na cache, hindi sinusuportahan ang pagtitiklop ng database.
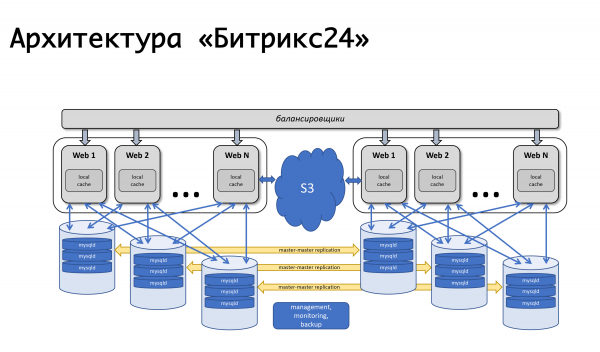
Binuo namin ang mga kinakailangan: ito ay ang kakayahang matatagpuan sa iba't ibang lokasyon, sumusuporta sa pagkopya, at perpektong matatagpuan sa iba't ibang mga sentro ng data na nahahati sa heograpiya. Paghiwalayin ang lohika ng produkto at, sa katunayan, imbakan ng data. Magagawang dynamic na mag-scale ayon sa pagkarga, at ganap na tiisin ang mga estatika. Mula sa mga pagsasaalang-alang na ito, sa katunayan, lumitaw ang mga kinakailangan para sa produkto, na aming pinino sa paglipas ng taon. Sa panahong ito, sa platform, na naging pinag-isa - para sa mga naka-box na solusyon, para sa sarili naming serbisyo - gumawa kami ng suporta para sa mga bagay na kailangan namin. Suporta para sa pagtitiklop ng mysql sa antas ng produkto mismo: iyon ay, ang nag-develop na nagsusulat ng code ay hindi nag-iisip tungkol sa kung paano ipapamahagi ang kanyang mga kahilingan, ginagamit niya ang aming api, at alam namin kung paano wastong ipamahagi ang pagsulat at pagbabasa ng mga kahilingan sa pagitan ng mga master. at mga alipin.
Gumawa kami ng suporta sa antas ng produkto para sa iba't ibang cloud object storage: google storage, amazon s3, at suporta para sa open stack swift. Samakatuwid, ito ay maginhawa para sa amin bilang isang serbisyo at para sa mga developer na nagtatrabaho sa isang naka-package na solusyon: kung gagamitin lang nila ang aming API para sa trabaho, hindi nila iniisip kung saan ang file ay tuluyang mase-save, lokal sa file system o sa object file storage .
Bilang resulta, agad kaming nagpasya na magreserba kami sa antas ng buong data center. Noong 2012, ganap kaming naglunsad sa Amazon AWS dahil mayroon na kaming karanasan sa platform na ito - ang aming sariling website ay naka-host doon. Naakit kami sa katotohanan na sa bawat rehiyon ang Amazon ay may ilang mga availability zone - sa katunayan, (sa kanilang terminolohiya) ilang mga sentro ng data na higit pa o hindi gaanong independyente sa isa't isa at nagpapahintulot sa amin na magreserba sa antas ng isang buong data center: kung bigla itong mabigo, ang mga database ay ginagaya ang master-master, ang mga web application server ay naka-back up, at ang static na data ay inilipat sa s3 object storage. Ang pag-load ay balanse - sa oras na iyon ng Amazon elb, ngunit ilang sandali ay dumating kami sa aming sariling mga balanse ng pagkarga, dahil kailangan namin ng mas kumplikadong lohika.
Kung ano ang gusto nila ay kung ano ang nakuha nila...
Ang lahat ng mga pangunahing bagay na gusto naming tiyakin - ang pagpapahintulot sa kasalanan ng mga server mismo, mga web application, mga database - lahat ay gumana nang maayos. Ang pinakasimpleng sitwasyon: kung ang isa sa aming mga web application ay nabigo, kung gayon ang lahat ay simple - ang mga ito ay inililipat mula sa pagbabalanse.
Ang balancer (sa oras na iyon ay ang elb ng Amazon) ay minarkahan ang mga makina na wala sa ayos bilang hindi malusog at pinatay ang pamamahagi ng load sa kanila. Gumagana ang autoscaling ng Amazon: nang lumaki ang load, nagdagdag ng mga bagong machine sa autoscaling group, naipamahagi ang load sa mga bagong machine - maayos ang lahat. Sa aming mga tagabalanse, ang lohika ay halos pareho: kung may mangyari sa server ng application, inaalis namin ang mga kahilingan mula dito, itinatapon ang mga makinang ito, magsimula ng mga bago at patuloy na magtrabaho. Ang pamamaraan ay nagbago nang kaunti sa mga nakaraang taon, ngunit patuloy na gumagana: ito ay simple, naiintindihan, at walang mga paghihirap dito.
Nagtatrabaho kami sa buong mundo, ganap na naiiba ang mga peak ng load ng customer, at, sa isang mapayapang paraan, dapat naming magawa ang ilang partikular na gawain sa serbisyo sa anumang bahagi ng aming system anumang oras - nang hindi napapansin ng mga customer. Samakatuwid, mayroon kaming pagkakataon na i-off ang database mula sa operasyon, muling pamamahagi ng load sa pangalawang data center.
Paano gumagana ang lahat ng ito? — Inilipat namin ang trapiko sa isang gumaganang data center - kung may aksidente sa data center, pagkatapos ay ganap, kung ito ang aming nakaplanong trabaho sa isang database, pagkatapos ay inililipat namin ang bahagi ng trapiko na nagsisilbi sa mga kliyenteng ito sa pangalawang data center, na sinuspinde pagtitiklop nito. Kung kailangan ng mga bagong machine para sa mga web application dahil tumaas ang load sa pangalawang data center, awtomatiko silang magsisimula. Natapos namin ang trabaho, naibalik ang pagtitiklop, at ibinabalik namin ang buong pagkarga. Kung kailangan nating i-mirror ang ilang trabaho sa pangalawang DC, halimbawa, i-install ang mga update sa system o baguhin ang mga setting sa pangalawang database, kung gayon, sa pangkalahatan, inuulit namin ang parehong bagay, sa kabilang direksyon lamang. At kung ito ay isang aksidente, ginagawa namin ang lahat nang walang kabuluhan: ginagamit namin ang mekanismo ng mga tagapangasiwa ng kaganapan sa sistema ng pagsubaybay. Kung maraming pagsusuri ang na-trigger at ang katayuan ay napupunta sa kritikal, pagkatapos ay pinapatakbo namin ang handler na ito, isang handler na maaaring magsagawa ng ganito o ganoong lohika. Para sa bawat database, tinutukoy namin kung aling server ang failover para dito, at kung saan kailangang ilipat ang trapiko kung hindi ito available. Sa kasaysayan, ginagamit namin ang nagios o ilan sa mga tinidor nito sa isang anyo o iba pa. Sa prinsipyo, ang mga katulad na mekanismo ay umiiral sa halos anumang sistema ng pagsubaybay; hindi pa kami gumagamit ng anumang mas kumplikado, ngunit marahil balang araw ay gagawin namin. Ngayon ang pagsubaybay ay na-trigger ng hindi available at may kakayahang lumipat ng isang bagay.
Na-reserve na ba natin ang lahat?
Marami kaming kliyente mula sa USA, maraming kliyente mula sa Europa, maraming kliyente na mas malapit sa Silangan - Japan, Singapore at iba pa. Siyempre, isang malaking bahagi ng mga kliyente ang nasa Russia. Ibig sabihin, wala sa isang rehiyon ang trabaho. Gusto ng mga user ng mabilis na pagtugon, may mga kinakailangan upang sumunod sa iba't ibang lokal na batas, at sa loob ng bawat rehiyon ay nagrereserba kami ng dalawang data center, at may ilang karagdagang serbisyo, na, muli, ay maginhawang ilagay sa loob ng isang rehiyon - para sa mga kliyente na nasa gumagana ang rehiyong ito. Ang mga tagapangasiwa ng REST, mga server ng awtorisasyon, ang mga ito ay hindi gaanong kritikal para sa pagpapatakbo ng kliyente sa kabuuan, maaari kang lumipat sa pamamagitan ng mga ito sa isang maliit na katanggap-tanggap na pagkaantala, ngunit hindi mo nais na muling baguhin ang gulong kung paano susubaybayan ang mga ito at kung ano ang gagawin kasama nila. Samakatuwid, sinusubukan naming gamitin ang mga umiiral na solusyon sa maximum, sa halip na bumuo ng ilang uri ng kakayahan sa mga karagdagang produkto. At sa isang lugar ay hindi gaanong ginagamit namin ang paglipat sa antas ng DNS, at tinutukoy namin ang kasiglahan ng serbisyo sa pamamagitan ng parehong DNS. Ang Amazon ay may serbisyo ng Route 53, ngunit hindi lamang ito isang DNS kung saan maaari kang gumawa ng mga entry at iyon lang—ito ay mas nababaluktot at maginhawa. Sa pamamagitan nito maaari kang bumuo ng mga geo-distributed na serbisyo na may mga geolocation, kapag ginamit mo ito upang matukoy kung saan nanggaling ang kliyente at bigyan siya ng ilang mga talaan - sa tulong nito maaari kang bumuo ng mga failover architecture. Ang parehong mga pagsusuri sa kalusugan ay na-configure sa Ruta 53 mismo, itinakda mo ang mga endpoint na sinusubaybayan, itinakda ang mga sukatan, itinakda kung aling mga protocol ang tutukuyin ang "liveness" ng serbisyo - tcp, http, https; itakda ang dalas ng mga pagsusuri na tumutukoy kung ang serbisyo ay buhay o hindi. At sa DNS mismo ay tinukoy mo kung ano ang magiging pangunahin, kung ano ang magiging pangalawa, kung saan lilipat kung ang pagsusuri sa kalusugan ay na-trigger sa loob ng ruta 53. Ang lahat ng ito ay maaaring gawin sa ilang iba pang mga tool, ngunit bakit ito maginhawa - itinakda namin ito up ng isang beses at pagkatapos ay huwag isipin ang tungkol dito sa lahat ng kung paano namin suriin, kung paano kami lumipat: lahat ay gumagana sa sarili nitong.
Ang unang "ngunit": paano at kung ano ang magpareserba mismo ng ruta 53? Who knows, paano kung may mangyari sa kanya? Buti na lang at hindi namin naapakan ang kalaykay na ito, ngunit muli, magkakaroon ako ng isang kuwento sa unahan kung bakit naisip namin na kailangan pa naming magpareserba. Dito kami naglatag ng mga straw para sa ating sarili nang maaga. Ilang beses sa isang araw ginagawa namin ang kumpletong pagbabawas ng lahat ng mga zone na mayroon kami sa ruta 53. Ang API ng Amazon ay nagbibigay-daan sa iyo na madaling ipadala ang mga ito sa JSON, at mayroon kaming ilang mga backup na server kung saan namin ito kino-convert, ina-upload ito sa anyo ng mga config at may, sa halos pagsasalita, isang backup na configuration. Kung may mangyari, mabilis naming mai-deploy ito nang manu-mano nang hindi nawawala ang data ng mga setting ng DNS.
Pangalawa "ngunit": Ano sa larawang ito ang hindi pa nakareserba? Ang balancer mismo! Ang aming pamamahagi ng mga kliyente ayon sa rehiyon ay ginawang napakasimple. Mayroon kaming mga domain na bitrix24.ru, bitrix24.com, .de - ngayon ay mayroong 13 iba't ibang mga domain, na gumagana sa iba't ibang mga zone. Dumating kami sa mga sumusunod: bawat rehiyon ay may kanya-kanyang balanse. Ginagawa nitong mas maginhawang ipamahagi sa mga rehiyon, depende kung nasaan ang peak load sa network. Kung ito ay isang pagkabigo sa antas ng isang solong balancer, pagkatapos ito ay tinanggal lamang sa serbisyo at tinanggal mula sa dns. Kung may ilang problema sa isang grupo ng mga balancer, sila ay naka-back up sa ibang mga site, at ang paglipat sa pagitan ng mga ito ay ginagawa gamit ang parehong ruta53, dahil dahil sa maikling TTL, ang paglipat ay nangyayari sa loob ng maximum na 2, 3, 5 minuto .
Pangatlo "ngunit": Ano ang hindi pa nakareserba? S3, tama. Noong inilagay namin ang mga file na iniimbak namin para sa mga user sa s3, taos-puso kaming naniwala na ito ay nakasuot ng sandata at hindi na kailangang magreserba ng kahit ano doon. Ngunit ipinapakita ng kasaysayan na iba ang nangyayari. Sa pangkalahatan, inilalarawan ng Amazon ang S3 bilang isang pangunahing serbisyo, dahil ang Amazon mismo ay gumagamit ng S3 upang mag-imbak ng mga larawan ng makina, mga config, mga larawan ng AMI, mga snapshot... At kung nag-crash ang s3, tulad ng nangyari nang isang beses sa loob ng 7 taon na ito, hangga't ginagamit namin bitrix24, sinusundan ito tulad ng isang tagahanga Mayroong isang buong grupo ng mga bagay na lumalabas - kawalan ng kakayahang magsimula ng mga virtual machine, pagkabigo ng api, at iba pa.
At maaaring mahulog ang S3 - nangyari ito nang isang beses. Samakatuwid, dumating kami sa sumusunod na pamamaraan: ilang taon na ang nakalilipas walang malubhang pasilidad sa pag-iimbak ng mga pampublikong bagay sa Russia, at isinasaalang-alang namin ang opsyon na gumawa ng sarili naming bagay... Sa kabutihang palad, hindi namin sinimulan itong gawin, dahil gagawin namin naghukay sa kadalubhasaan na wala sa amin, at malamang na magulo. Ngayon ang Mail.ru ay may s3-compatible na storage, Yandex ay mayroon nito, at ilang iba pang provider ang mayroon nito. Sa kalaunan ay naisip namin na gusto naming magkaroon, una, backup, at pangalawa, ang kakayahang magtrabaho kasama ang mga lokal na kopya. Para sa rehiyon ng Russia partikular, ginagamit namin ang serbisyo ng Mail.ru Hotbox, na tugma sa API sa s3. Hindi namin kailangan ng anumang malalaking pagbabago sa code sa loob ng application, at ginawa namin ang sumusunod na mekanismo: sa s3 may mga trigger na nagti-trigger sa paglikha/pagtanggal ng mga bagay, ang Amazon ay may serbisyong tinatawag na Lambda - ito ay isang serverless na paglulunsad ng code ipapatupad iyon kapag na-trigger ang ilang partikular na trigger.
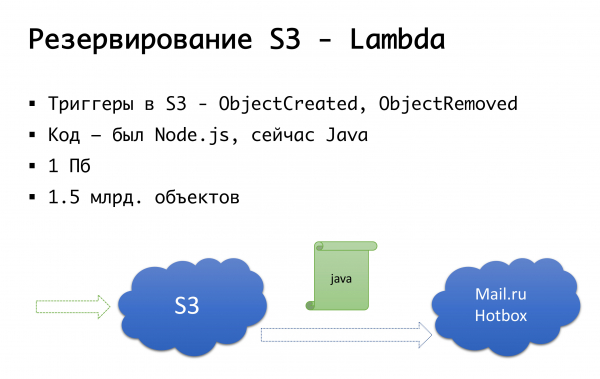
Ginawa namin ito nang napakasimple: kung gagana ang aming trigger, ipapatupad namin ang code na kokopya sa bagay sa imbakan ng Mail.ru. Upang ganap na mailunsad ang trabaho gamit ang mga lokal na kopya ng data, kailangan din namin ng reverse synchronization upang ang mga kliyenteng nasa segment ng Russia ay maaaring gumana sa storage na mas malapit sa kanila. Malapit nang makumpleto ng Mail ang mga trigger sa storage nito - posibleng magsagawa ng reverse synchronization sa antas ng imprastraktura, ngunit sa ngayon ginagawa namin ito sa antas ng sarili naming code. Kung nakita namin na ang isang kliyente ay nag-post ng isang file, pagkatapos ay sa antas ng code ilalagay namin ang kaganapan sa isang pila, iproseso ito at gawin ang reverse replication. Bakit ito masama: kung gumawa kami ng ilang uri ng trabaho sa aming mga bagay sa labas ng aming produkto, iyon ay, sa ilang panlabas na paraan, hindi namin ito isasaalang-alang. Samakatuwid, naghihintay kami hanggang sa katapusan, kapag lumitaw ang mga pag-trigger sa antas ng imbakan, upang kahit saan namin isagawa ang code, ang bagay na dumating sa amin ay kinopya sa kabilang direksyon.
Sa antas ng code, inirehistro namin ang parehong mga imbakan para sa bawat kliyente: ang isa ay itinuturing na pangunahing isa, ang isa ay itinuturing na isang backup. Kung maayos ang lahat, nakikipagtulungan kami sa storage na mas malapit sa amin: iyon ay, ang aming mga kliyente na nasa Amazon, nagtatrabaho sila sa S3, at ang mga nagtatrabaho sa Russia, nagtatrabaho sila sa Hotbox. Kung na-trigger ang flag, dapat na konektado ang failover, at ililipat namin ang mga kliyente sa ibang storage. Maaari naming suriin ang kahon na ito nang hiwalay ayon sa rehiyon at maaari naming ilipat ang mga ito pabalik-balik. Hindi pa namin ito ginagamit sa pagsasanay, ngunit ibinigay namin ang mekanismong ito at sa palagay namin balang araw kakailanganin namin ang mismong switch na ito at magiging kapaki-pakinabang. Nangyari na ito minsan.
Oh, at tumakas si Amazon...
Ngayong Abril ay minarkahan ang anibersaryo ng pagsisimula ng pagharang ng Telegram sa Russia. Ang pinaka-apektadong provider na nahulog sa ilalim nito ay ang Amazon. At, sa kasamaang-palad, ang mga kumpanyang Ruso na nagtrabaho para sa buong mundo ay higit na nagdusa.
Kung ang kumpanya ay pandaigdigan at ang Russia ay isang napakaliit na segment para dito, 3-5% - mabuti, sa isang paraan o iba pa, maaari mong isakripisyo ang mga ito.
Kung ito ay isang purong Russian na kumpanya - sigurado ako na kailangan itong matatagpuan sa lokal - mabuti, ito ay magiging maginhawa para sa mga gumagamit mismo, komportable, at magkakaroon ng mas kaunting mga panganib.
Paano kung ito ay isang kumpanya na nagpapatakbo sa buong mundo at may humigit-kumulang pantay na bilang ng mga kliyente mula sa Russia at sa isang lugar sa buong mundo? Ang pagkakakonekta ng mga segment ay mahalaga, at dapat silang gumana sa isa't isa sa isang paraan o iba pa.
Noong huling bahagi ng Marso 2018, nagpadala ang Roskomnadzor ng liham sa pinakamalalaking operator na nagpapaalam sa kanila ng kanilang mga plano na harangan ang ilang milyong Amazon IP address upang harangan... ang Zello messenger. Dahil sa mga provider na iyon, matagumpay nilang naipaalam ang liham sa lahat, at naging malinaw na maaaring bumagsak ang koneksyon sa Amazon. Biyernes noon, at nataranta kaming tumakbo sa aming mga kasamahan sa servers.ru, na nagsasabing, "Mga kaibigan, kailangan namin ng ilang server na wala sa Russia, hindi sa Amazon, kundi, halimbawa, sa isang lugar sa Amsterdam," para kahit papaano ay makapag-set up kami ng sarili naming mga server doon. vpn At mga proxy para sa ilang endpoint na wala kaming kontrol, tulad ng mga S3 endpoint—hindi namin maaaring subukang mag-set up ng bagong serbisyo at kumuha ng ibang IP address; kailangan pa rin naming maabot ang mga ito. Sa loob ng ilang araw, na-configure, na-activate, at napatakbo na namin ang mga server na ito, at handa na kami para sa pagsisimula ng pagharang. Kapansin-pansin, matapos makita ang kaguluhan at pagkataranta, sinabi ng Roskomnadzor, "Hindi, wala kaming hinaharangan ngayon." (Pero iyon ay hanggang sa sandaling sinimulan nilang harangan ang Telegram.) Matapos mag-set up ng mga opsyon sa bypass at mapagtanto na hindi pa naipatupad ang pagharang, nagpasya pa rin kaming huwag imbestigahan ang buong bagay. Kung sakali.

At sa 2019, nabubuhay pa rin tayo sa mga kondisyon ng pagharang. Tumingin ako kagabi: halos isang milyong IP ang patuloy na hinaharang. Totoo, ang Amazon ay halos ganap na na-unblock, sa tuktok nito ay umabot sa 20 milyong mga address... Sa pangkalahatan, ang katotohanan ay maaaring walang pagkakaugnay-ugnay, magandang pagkakaugnay-ugnay. Bigla. Maaaring wala ito para sa mga teknikal na kadahilanan - sunog, excavator, lahat ng iyon. O, tulad ng nakita natin, hindi ganap na teknikal. Samakatuwid, ang isang tao na malaki at malaki, na may sariling mga AS, ay maaaring pamahalaan ito sa ibang mga paraan - direktang kumonekta at iba pang mga bagay ay nasa l2 na antas na. Ngunit sa isang simpleng bersyon, tulad ng sa amin o kahit na mas maliit, maaari kang, kung sakali, magkaroon ng redundancy sa antas ng mga server na itinaas sa ibang lugar, na na-configure nang maaga vpn, proxy, na may kakayahang mabilis na ilipat ang configuration sa kanila sa mga segment na iyon na kritikal para sa iyong koneksyon. Ito ay naging kapaki-pakinabang para sa amin nang higit sa isang beses, nang magsimula ang pagharang ng Amazon; sa pinakamasamang sitwasyon, pinapayagan lamang namin ang trapiko ng S3 sa pamamagitan ng mga ito, ngunit unti-unting nalutas ang lahat ng ito.
Paano magpareserba... isang buong provider?
Sa ngayon, wala kaming senaryo kung sakaling bumagsak ang buong Amazon. Mayroon kaming katulad na senaryo para sa Russia. Sa Russia, na-host kami ng isang provider, kung saan pinili naming magkaroon ng ilang site. At isang taon na ang nakalipas, nagkaroon kami ng problema: kahit na ito ay dalawang data center, maaaring may mga problema na sa antas ng network configuration ng provider na makakaapekto pa rin sa parehong data center. At maaari kaming maging hindi magagamit sa parehong mga site. Syempre yun ang nangyari. Nauwi kami sa muling pagsasaalang-alang sa arkitektura sa loob. Hindi ito masyadong nagbago, ngunit para sa Russia mayroon na kaming dalawang site, na hindi mula sa parehong provider, ngunit mula sa dalawang magkaibang mga site. Kung nabigo ang isa, maaari tayong lumipat sa isa.
Hypothetically, para sa Amazon ay isinasaalang-alang namin ang posibilidad ng pagpapareserba sa antas ng isa pang provider; maaaring Google, maaaring ibang tao... Ngunit sa ngayon ay naobserbahan namin sa pagsasanay na habang ang Amazon ay may mga aksidente sa antas ng isang availability zone, ang mga aksidente sa antas ng isang buong rehiyon ay medyo bihira. Samakatuwid, ayon sa teorya ay mayroon kaming ideya na maaari kaming gumawa ng reserbasyon na "Ang Amazon ay hindi Amazon", ngunit sa pagsasagawa ay hindi pa ito ang kaso.
Ilang salita tungkol sa automation
Lagi bang kailangan ang automation? Dito angkop na alalahanin ang Dunning-Kruger effect. Sa axis ng "x" ay ang ating kaalaman at karanasan na nakukuha natin, at sa "y" axis ay ang tiwala sa ating mga aksyon. Sa una ay wala tayong alam at hindi talaga sigurado. Pagkatapos ay alam natin ng kaunti at naging mega-confident - ito ang tinatawag na "peak of stupidity", na mahusay na inilarawan ng larawang "dementia at tapang". Pagkatapos ay natuto na kami ng kaunti at handa na kaming sumabak sa labanan. Pagkatapos ay humakbang tayo sa ilang malalaking pagkakamali at natagpuan ang ating sarili sa isang lambak ng kawalan ng pag-asa, kapag tila may alam tayo, ngunit sa katunayan ay wala tayong masyadong alam. Pagkatapos, habang nagkakaroon tayo ng karanasan, nagiging mas kumpiyansa tayo.
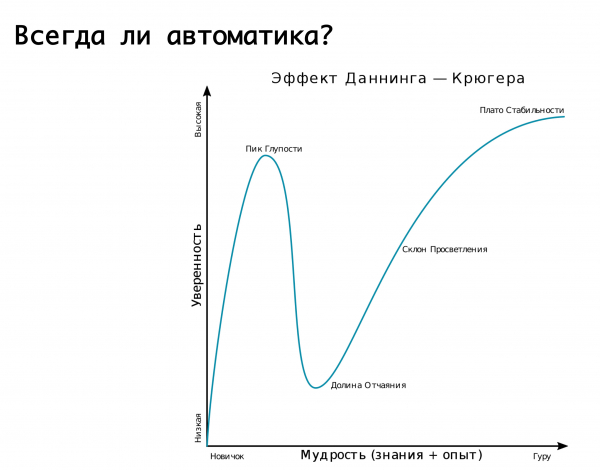
Ang aming lohika tungkol sa iba't ibang awtomatikong paglipat sa ilang aksidente ay napakahusay na inilarawan ng graph na ito. Nagsimula kami - hindi namin alam kung paano gumawa ng anuman, halos lahat ng gawain ay ginawa sa pamamagitan ng kamay. Pagkatapos ay napagtanto namin na maaari naming ilakip ang automation sa lahat at, tulad ng, matulog nang mapayapa. At bigla kaming tumapak sa isang mega-rake: na-trigger ang isang false positive, at nagpapalipat-lipat kami ng trapiko kapag, sa mabuting paraan, hindi namin dapat ginawa ito. Dahil dito, nasisira ang pagtitiklop o iba pa—ito ang pinakalambak ng kawalan ng pag-asa. At pagkatapos ay dumating tayo sa pagkaunawa na dapat nating lapitan ang lahat nang matalino. Iyon ay, makatuwiran na umasa sa automation, na nagbibigay para sa posibilidad ng mga maling alarma. Ngunit! kung ang kahihinatnan ay maaaring maging mapahamak, pagkatapos ay mas mahusay na ipaubaya ito sa shift ng tungkulin, sa mga inhinyero na naka-duty, na sisiguraduhin at susubaybayan na talagang may aksidente, at manu-manong isasagawa ang mga kinakailangang aksyon...
Konklusyon
Sa paglipas ng 7 taon, napunta kami mula sa katotohanan na kapag ang isang bagay ay nahulog, nagkaroon ng panic-panic, hanggang sa pag-unawa na ang mga problema ay hindi umiiral, mayroon lamang mga gawain, dapat - at maaari - malutas. Kapag gumagawa ka ng isang serbisyo, tingnan ito mula sa itaas, suriin ang lahat ng mga panganib na maaaring mangyari. Kung makikita mo sila kaagad, pagkatapos ay magbigay ng kalabisan nang maaga at ang posibilidad ng pagbuo ng isang fault-tolerant na imprastraktura, dahil ang anumang punto na maaaring mabigo at humantong sa inoperability ng serbisyo ay tiyak na gagawin ito. At kahit na tila sa iyo na ang ilang mga elemento ng imprastraktura ay tiyak na hindi mabibigo - tulad ng parehong s3, tandaan pa rin na magagawa nila. At least in theory, magkaroon ng ideya kung ano ang gagawin mo sa kanila kung may mangyari. Magkaroon ng plano sa pamamahala ng panganib. Kapag iniisip mong gawin ang lahat nang awtomatiko o manu-mano, suriin ang mga panganib: ano ang mangyayari kung sisimulan ng automation ang paglipat ng lahat - hindi ba ito hahantong sa mas masahol pang sitwasyon kumpara sa isang aksidente? Marahil sa isang lugar ay kinakailangan na gumamit ng isang makatwirang kompromiso sa pagitan ng paggamit ng automation at ang reaksyon ng engineer na naka-duty, na susuriin ang tunay na larawan at mauunawaan kung ang isang bagay ay kailangang ilipat sa lugar o "oo, ngunit hindi ngayon."
Isang makatwirang kompromiso sa pagitan ng pagiging perpekto at tunay na pagsisikap, oras, pera na maaari mong gastusin sa pamamaraan na sa kalaunan ay magkakaroon ka.
Ang tekstong ito ay isang na-update at pinalawak na bersyon ng ulat ni Alexander Demidov sa kumperensya .
Pinagmulan: www.habr.com
