

Kumusta, mga residente ng Khabrovsk. Ang mga klase sa unang pangkat ng kurso ay magsisimula ngayon . Kaugnay nito, nais naming sabihin sa iyo kung paano naganap ang bukas na webinar sa kursong ito.

В pinag-usapan namin ang mga hamon na kinakaharap ng mga database ng SQL sa panahon ng mga ulap at Kubernetes. Kasabay nito, tiningnan namin kung paano umaangkop at nag-mutate ang mga database ng SQL sa ilalim ng impluwensya ng mga hamong ito.
Ginanap ang webinar , Google Cloud Practice Delivery Manager sa EPAM Systems.
Noong maliliit pa ang mga puno...
Una, tandaan natin kung paano nagsimula ang pagpili ng DBMS sa pagtatapos ng huling siglo. Gayunpaman, hindi ito magiging mahirap, dahil ang pagpili ng isang DBMS noong mga panahong iyon ay nagsimula at natapos Orakulo.

Sa huling bahagi ng 90s at unang bahagi ng 2s, walang mapagpipilian pagdating sa mga pang-industriyang nasusukat na database. Oo, mayroong IBM DBXNUMX, Sybase at ilang iba pang mga database na dumating at umalis, ngunit sa pangkalahatan ay hindi sila masyadong kapansin-pansin laban sa background ng Oracle. Alinsunod dito, ang mga kasanayan ng mga inhinyero noong mga panahong iyon ay sa paanuman ay nakatali sa tanging pagpipilian na umiiral.
Kailangang magawa ng Oracle DBA na:
- i-install ang Oracle Server mula sa distribution kit;
- i-configure ang Oracle Server:
- init.ora;
- tagapakinig.ora;
- lumikha:
- mga tablespace;
- mga scheme;
- mga gumagamit;
— magsagawa ng backup at pagpapanumbalik;
- magsagawa ng pagsubaybay;
— harapin ang mga suboptimal na kahilingan.
Kasabay nito, walang espesyal na kinakailangan mula sa Oracle DBA:
- mapili ang pinakamainam na DBMS o iba pang teknolohiya para sa pag-iimbak at pagproseso ng data;
- magbigay ng mataas na kakayahang magamit at pahalang na scalability (ito ay hindi palaging isang isyu sa DBA);
- mahusay na kaalaman sa lugar ng paksa, imprastraktura, arkitektura ng aplikasyon, OS;
- mag-load at mag-unload ng data, mag-migrate ng data sa pagitan ng iba't ibang DBMS.
Sa pangkalahatan, kung pinag-uusapan natin ang pagpipilian sa mga araw na iyon, ito ay kahawig ng pagpipilian sa isang tindahan ng Sobyet noong huling bahagi ng 80s:

Ang ating oras
Simula noon, siyempre, lumago ang mga puno, nagbago ang mundo, at naging ganito:

Ang merkado ng DBMS ay nagbago din, tulad ng malinaw na makikita mula sa pinakabagong ulat mula sa Gartner:
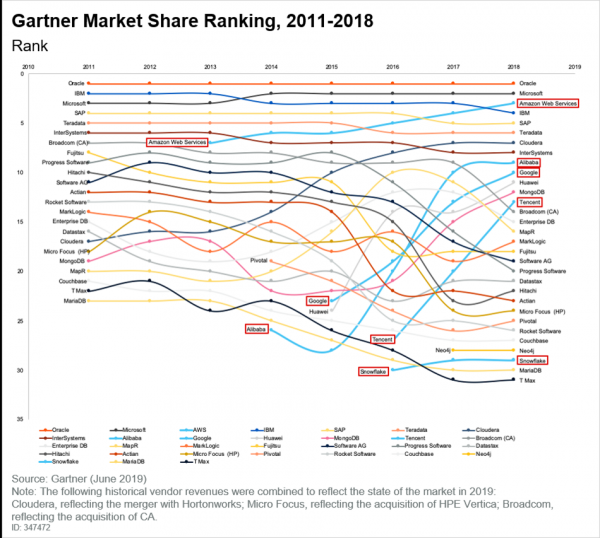
At dito dapat tandaan na ang mga ulap, na ang katanyagan ay lumalaki, ay sinakop ang kanilang angkop na lugar. Kung babasahin natin ang parehong ulat ng Gartner, makikita natin ang mga sumusunod na konklusyon:
- Maraming mga customer ang nasa landas sa paglipat ng mga application sa cloud.
- Ang mga bagong teknolohiya ay unang lumitaw sa cloud at ito ay hindi isang katotohanan na ang mga ito ay lilipat sa hindi ulap na imprastraktura.
- Ang modelo ng pagpepresyo ng pay-as-you-go ay naging pangkaraniwan. Nais ng lahat na magbayad lamang para sa kung ano ang kanilang ginagamit, at ito ay hindi kahit isang trend, ngunit isang pahayag lamang ng katotohanan.
Ano ngayon?
Ngayon lahat tayo ay nasa ulap. At ang mga tanong na lumalabas para sa atin ay mga katanungan ng pagpili. At ito ay napakalaki, kahit na pag-uusapan lang natin ang tungkol sa pagpili ng mga teknolohiya ng DBMS sa On-premises na format. Mayroon din kaming mga pinamamahalaang serbisyo at SaaS. Kaya, ang pagpili ay nagiging mas mahirap lamang bawat taon.
Kasama ng mga tanong na mapagpipilian, mayroon din naglilimita sa mga kadahilanan:
- presyo. Maraming mga teknolohiya pa rin ang nagkakahalaga ng pera;
- kasanayan. Kung pinag-uusapan natin ang tungkol sa libreng software, ang tanong ng mga kasanayan ay lumitaw, dahil ang libreng software ay nangangailangan ng sapat na kakayahan mula sa mga taong nag-deploy at nagpapatakbo nito;
- nagagamit. Hindi lahat ng serbisyo na available sa cloud at binuo, sabihin nating, kahit na sa parehong Postgres, ay may parehong mga feature gaya ng Postgres On-premises. Ito ay isang mahalagang kadahilanan na kailangang malaman at maunawaan. Bukod dito, nagiging mas mahalaga ang salik na ito kaysa sa kaalaman sa ilang mga nakatagong kakayahan ng isang solong DBMS.
Ano ang inaasahan ngayon mula sa DA/DE:
- mahusay na pag-unawa sa lugar ng paksa at arkitektura ng aplikasyon;
- ang kakayahang piliin nang tama ang naaangkop na teknolohiya ng DBMS, na isinasaalang-alang ang gawain sa kamay;
- ang kakayahang piliin ang pinakamainam na paraan para sa pagpapatupad ng napiling teknolohiya sa konteksto ng mga umiiral na limitasyon;
- kakayahang magsagawa ng paglipat ng data at paglipat;
- kakayahang ipatupad at patakbuhin ang mga napiling solusyon.
Halimbawa sa ibaba batay sa GCP nagpapakita kung paano gumagana ang pagpili ng isa o ibang teknolohiya para sa pagtatrabaho sa data depende sa istraktura nito:
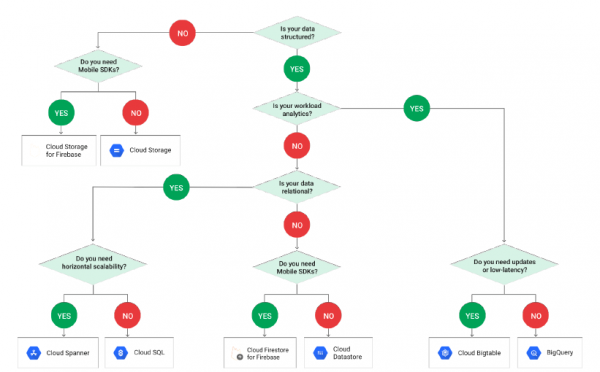
Pakitandaan na ang PostgreSQL ay hindi kasama sa schema, at ito ay dahil nakatago ito sa ilalim ng terminolohiya Cloud SQL. At kapag nakarating na tayo sa Cloud SQL, kailangan nating pumili muli:
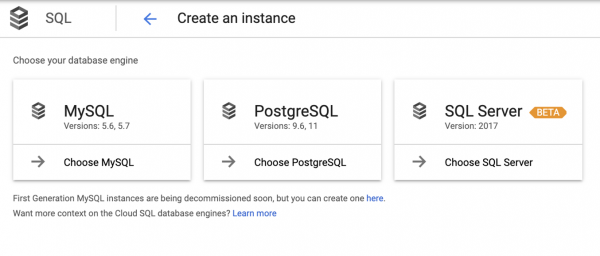
Dapat tandaan na ang pagpipiliang ito ay hindi palaging malinaw, kaya ang mga developer ng application ay madalas na ginagabayan ng intuwisyon.
Kabuuan:
- Habang lumalayo ka, mas lalong tumitindi ang tanong ng pagpili. At kahit na tumingin ka lang sa GCP, mga pinamamahalaang serbisyo at SaaS, lalabas lang ang ilang pagbanggit sa RDBMS sa ika-4 na hakbang (at doon malapit ang Spanner). Dagdag pa, ang pagpili ng PostgreSQL ay lilitaw sa ika-5 hakbang, at sa tabi nito ay mayroon ding MySQL at SQL Server, iyon ay marami ang lahat, ngunit kailangan mong pumili.
- Hindi natin dapat kalimutan ang tungkol sa mga paghihigpit laban sa background ng mga tukso. Karaniwang gusto ng lahat ng isang Spanner, ngunit ito ay mahal. Bilang resulta, ang isang karaniwang kahilingan ay ganito ang hitsura: "Mangyaring gawin kaming isang Spanner ngunit para sa presyo ng Cloud SQL, kayo ay mga propesyonal!"

Anong gagawin ko?
Nang hindi inaangkin na siya ang tunay na katotohanan, sabihin natin ang sumusunod:
Kailangan nating baguhin ang ating diskarte sa pag-aaral:
- walang saysay ang pagtuturo ng paraan ng pagtuturo sa mga DBA noon;
- hindi na sapat ang kaalaman sa isang produkto;
- ngunit ang pag-alam ng dose-dosenang sa antas ng isa ay imposible.
Kailangan mong malaman hindi lamang at hindi kung magkano ang produkto, ngunit:
- kaso ng paggamit ng aplikasyon nito;
- iba't ibang paraan ng pag-deploy;
- mga pakinabang at disadvantages ng bawat pamamaraan;
- katulad at alternatibong mga produkto upang makagawa ng matalino at pinakamainam na pagpipilian at hindi palaging pabor sa isang pamilyar na produkto.
Kailangan mo ring makapag-migrate ng data at maunawaan ang mga pangunahing prinsipyo ng pagsasama sa ETL.
Totoong kaso
Sa kamakailang nakaraan, kinakailangan na gumawa ng backend para sa isang mobile application. Sa oras na nagsimula ang trabaho dito, ang backend ay nabuo na at handa na para sa pagpapatupad, at ang development team ay gumugol ng halos dalawang taon sa proyektong ito. Ang mga sumusunod na gawain ay itinakda:
- bumuo ng CI/CD;
- suriin ang arkitektura;
- ilagay ang lahat sa operasyon.
Ang application mismo ay mga microservice, at ang Python/Django code ay binuo mula sa simula at direkta sa GCP. Tulad ng para sa target na madla, ipinapalagay na magkakaroon ng dalawang rehiyon - US at EU, at ang trapiko ay ipinamahagi sa pamamagitan ng Global Load balancer. Ang lahat ng Workload at compute workload ay tumakbo sa Google Kubernetes Engine.
Tulad ng para sa data, mayroong 3 istruktura:
- Cloud Storage;
- Datastore;
- Cloud SQL (PostgreSQL).
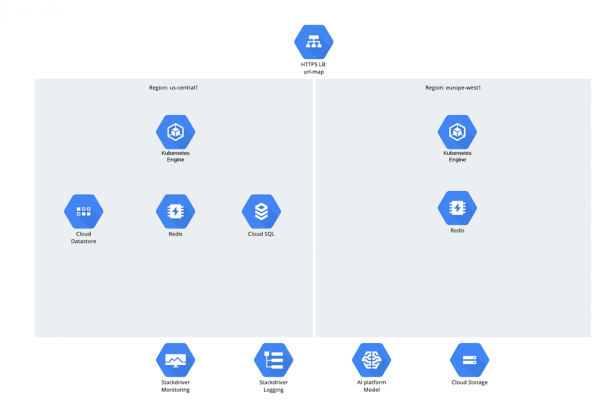
Maaaring magtaka ang isa kung bakit napili ang Cloud SQL? Upang sabihin ang katotohanan, ang gayong tanong ay nagdulot ng ilang uri ng hindi magandang pag-pause sa mga nakaraang taon - may pakiramdam na ang mga tao ay nahihiya tungkol sa mga relational na database, ngunit gayunpaman, patuloy silang aktibong ginagamit ang mga ito ;-).
Para sa aming kaso, pinili ang Cloud SQL para sa mga sumusunod na dahilan:
- Tulad ng nabanggit, ang application ay binuo gamit ang Django, at mayroon itong modelo para sa pagmamapa ng patuloy na data mula sa isang database ng SQL hanggang sa mga bagay na Python (Django ORM).
- Ang balangkas mismo ay sumuporta sa isang medyo may hangganan na listahan ng mga DBMS:
- PostgreSQL;
- MariaDB;
- MySQL;
- mga orakulo;
- SQLite.
Alinsunod dito, ang PostgreSQL ay pinili mula sa listahang ito sa halip na intuitively (well, hindi Oracle ang pumili, talaga).
Ano ang kulang:
- ang aplikasyon ay na-deploy lamang sa 2 rehiyon, at isang pangatlo ang lumitaw sa mga plano (Asia);
- Ang database ay matatagpuan sa rehiyon ng Hilagang Amerika (Iowa);
- sa bahagi ng customer ay may mga alalahanin tungkol sa posible mga pagkaantala sa pag-access mula sa Europa at Asya at mga pagkagambala sa serbisyo sa kaso ng DBMS downtime.
Sa kabila ng katotohanan na ang Django mismo ay maaaring gumana sa ilang mga database nang magkatulad at hatiin ang mga ito sa pagbabasa at pagsusulat, walang gaanong pagsusulat sa application (higit sa 90% ay nagbabasa). At sa pangkalahatan, at sa pangkalahatan, kung posible na gawin read-replica ng pangunahing base sa Europa at Asya, ito ay magiging solusyon sa kompromiso. Well, ano ang kumplikado tungkol dito?
Ang kahirapan ay ayaw ng customer na sumuko sa paggamit ng mga pinamamahalaang serbisyo at Cloud SQL. At ang mga kakayahan ng Cloud SQL ay kasalukuyang limitado. Sinusuportahan ng Cloud SQL ang High availability (HA) at Read Replica (RR), ngunit ang parehong RR ay sinusuportahan lamang sa isang rehiyon. Kapag nakagawa na ng database sa rehiyon ng Amerika, hindi ka makakagawa ng read replica sa European region gamit ang Cloud SQL, bagama't hindi ka pinipigilan mismo ng Postgres na gawin ito. Ang pakikipag-ugnayan sa mga empleyado ng Google ay hindi humantong sa kung saan at nagtapos sa mga pangako sa istilong "alam namin ang problema at ginagawa namin ito, balang araw ay malulutas ang isyu."
Kung ililista namin nang maikli ang mga kakayahan ng Cloud SQL, magiging ganito ang hitsura nito:
1. Mataas na kakayahang magamit (HA):
- sa loob ng isang rehiyon;
- sa pamamagitan ng pagtitiklop ng disk;
- Hindi ginagamit ang mga postgreSQL engine;
- posible ang awtomatiko at manu-manong kontrol - failover/failback;
- Kapag lumilipat, ang DBMS ay hindi magagamit sa loob ng ilang minuto.
2. Basahin ang Replica (RR):
- sa loob ng isang rehiyon;
- mainit na standby;
- PostgreSQL streaming replication.
Bilang karagdagan, tulad ng nakaugalian, kapag pumipili ng isang teknolohiya palagi kang nahaharap sa ilan mga paghihigpit:
- ayaw ng customer na lumikha ng mga entity at gumamit ng IaaS, maliban sa pamamagitan ng GKE;
- ayaw ng customer na mag-deploy ng self service na PostgreSQL/MySQL;
- Well, sa pangkalahatan, ang Google Spanner ay magiging angkop kung hindi ito para sa presyo nito, gayunpaman, ang Django ORM ay hindi maaaring gumana dito, ngunit ito ay isang magandang bagay.
Isinasaalang-alang ang sitwasyon, nakatanggap ang customer ng follow-up na tanong: "Maaari ka bang gumawa ng katulad na bagay upang ito ay tulad ng Google Spanner, ngunit gumagana din sa Django ORM?"
Opsyon sa solusyon No. 0
Ang unang bagay na pumasok sa isip:
- manatili sa loob ng CloudSQL;
- hindi magkakaroon ng built-in na pagtitiklop sa pagitan ng mga rehiyon sa anumang anyo;
- subukang mag-attach ng replica sa isang umiiral na Cloud SQL ng PostgreSQL;
- maglunsad ng isang PostgreSQL instance sa isang lugar at sa anumang paraan, ngunit hindi bababa sa huwag hawakan ang master.
Sa kasamaang palad, ito ay hindi maaaring gawin, dahil walang access sa host (ito ay nasa ibang proyekto sa kabuuan) - pg_hba at iba pa, at wala ring access sa ilalim ng superuser.
Opsyon sa solusyon No. 1
Pagkatapos ng karagdagang pagninilay at pagsasaalang-alang sa mga nakaraang pangyayari, medyo nagbago ang tren ng pag-iisip:
- Sinusubukan pa rin naming manatili sa loob ng CloudSQL, ngunit lilipat kami sa MySQL, dahil ang Cloud SQL ng MySQL ay may panlabas na master, na:
— ay isang proxy para sa panlabas na MySQL;
- mukhang isang halimbawa ng MySQL;
- naimbento para sa paglipat ng data mula sa iba pang mga ulap o Nasa nasasakupan.
Dahil ang pag-set up ng pagtitiklop ng MySQL ay hindi nangangailangan ng access sa host, sa prinsipyo ang lahat ay nagtrabaho, ngunit ito ay napaka-unstable at hindi maginhawa. At nang lumayo kami, naging ganap na nakakatakot, dahil na-deploy namin ang buong istraktura na may terraform, at biglang lumabas na ang panlabas na master ay hindi suportado ng terraform. Oo, may CLI ang Google, ngunit sa ilang kadahilanan ay gumagana ang lahat dito paminsan-minsan - kung minsan ito ay nilikha, kung minsan ay hindi ito nilikha. Marahil dahil naimbento ang CLI para sa panlabas na paglipat ng data, at hindi para sa mga replika.
Sa totoo lang, sa puntong ito naging malinaw na ang Cloud SQL ay hindi talaga angkop. Sabi nga nila, ginawa namin ang lahat ng aming makakaya.
Opsyon sa solusyon No. 2
Dahil hindi posibleng manatili sa loob ng Cloud SQL framework, sinubukan naming bumalangkas ng mga kinakailangan para sa isang solusyon sa kompromiso. Ang mga kinakailangan ay naging mga sumusunod:
- magtrabaho sa Kubernetes, maximum na paggamit ng mga mapagkukunan at kakayahan ng Kubernetes (DCS, ...) at GCP (LB, ...);
- kakulangan ng ballast mula sa isang grupo ng mga hindi kinakailangang bagay sa cloud tulad ng HA proxy;
- ang kakayahang magpatakbo ng PostgreSQL o MySQL sa pangunahing rehiyon ng HA; sa ibang mga rehiyon - HA mula sa RR ng pangunahing rehiyon kasama ang kopya nito (para sa pagiging maaasahan);
- multi master (Ayaw kong makipag-ugnayan sa kanya, ngunit hindi ito napakahalaga)
.
Bilang resulta ng mga kahilingang ito, pangkop na DBMS at mga opsyon sa pagbubuklod:
- MySQL Galera;
- CockroachDB;
- Mga tool sa PostgreSQL
:
- pgpool-II;
— Patroni.
MySQL Galera
Ang teknolohiyang MySQL Galera ay binuo ng Codership at isang plugin para sa InnoDB. Mga Katangian:
- multi master;
- kasabay na pagtitiklop;
- pagbabasa mula sa anumang node;
- pag-record sa anumang node;
- built-in na mekanismo ng HA;
- Mayroong Helm chart mula sa Bitnami.
IpisDB
Ayon sa paglalarawan, ang bagay ay ganap na bomba at ito ay isang open source na proyekto na nakasulat sa Go. Ang pangunahing kalahok ay Cockroach Labs (itinatag ng mga tao mula sa Google). Ang relational na DBMS na ito ay orihinal na idinisenyo upang ipamahagi (na may pahalang na pag-scale sa labas ng kahon) at fault-tolerant. Ang mga may-akda nito mula sa kumpanya ay binalangkas ang layunin ng "pagsasama-sama ng kayamanan ng SQL functionality na may pahalang na accessibility na pamilyar sa mga solusyon sa NoSQL."
Ang isang magandang bonus ay suporta para sa post-gress connection protocol.
Pgpool
Isa itong add-on sa PostgreSQL, sa katunayan, isang bagong entity na tumatagal sa lahat ng koneksyon at nagpoproseso sa kanila. Mayroon itong sariling load balancer at parser, na lisensyado sa ilalim ng lisensya ng BSD. Nagbibigay ito ng maraming pagkakataon, ngunit mukhang nakakatakot, dahil ang pagkakaroon ng bagong entity ay maaaring maging mapagkukunan ng ilang karagdagang pakikipagsapalaran.
Patroni
Ito ang huling bagay na nakita ng aking mga mata, at, bilang ito ay naging, hindi walang kabuluhan. Ang Patroni ay isang open source na utility, na mahalagang isang Python daemon na nagbibigay-daan sa iyong awtomatikong mapanatili ang mga PostgreSQL cluster na may iba't ibang uri ng replikasyon at awtomatikong paglipat ng tungkulin. Ang bagay ay naging napaka-interesante, dahil ito ay mahusay na pinagsama sa cuber at hindi nagpapakilala ng anumang mga bagong nilalang.
Ano ang pinili mo sa huli?
Hindi naging madali ang pagpili:
- IpisDB - apoy, ngunit madilim;
- MySQL Galera - hindi rin masama, ginagamit ito sa maraming lugar, ngunit MySQL;
- Pgpool — maraming mga hindi kinakailangang entity, kaya-kaya pagsasama sa cloud at K8s;
- Patroni - mahusay na pagsasama sa mga K8, walang mga hindi kinakailangang entity, mahusay na pinagsama sa GCP LB.
Kaya, ang pagpili ay nahulog kay Patroni.
Natuklasan
Panahon na upang buod nang maikli. Oo, ang mundo ng imprastraktura ng IT ay nagbago nang malaki, at ito ay simula pa lamang. At kung dati ang mga ulap ay isa lamang uri ng imprastraktura, ngayon ay iba na ang lahat. Bukod dito, ang mga inobasyon sa mga ulap ay patuloy na lumilitaw, sila ay lilitaw at, marahil, sila ay lilitaw lamang sa mga ulap at pagkatapos lamang, sa pamamagitan ng mga pagsisikap ng mga startup, sila ay ililipat sa On-premises.
Tulad ng para sa SQL, mabubuhay ang SQL. Nangangahulugan ito na kailangan mong malaman ang PostgreSQL at MySQL at magagawa mong magtrabaho sa kanila, ngunit ang mas mahalaga ay magamit mo ang mga ito nang tama.
Pinagmulan: www.habr.com
