


Ang pangunahing layunin ng Patroni ay magbigay ng High Availability para sa PostgreSQL. Ngunit ang Patroni ay isang template lamang, hindi isang handa na tool (na, sa pangkalahatan, ay sinabi sa dokumentasyon). Sa unang sulyap, nang na-set up ang Patroni sa test lab, makikita mo kung gaano ito kahusay na tool at kung gaano kadali nitong pinangangasiwaan ang aming mga pagtatangka na masira ang cluster. Gayunpaman, sa pagsasagawa, sa isang kapaligiran ng produksyon, ang lahat ay hindi palaging nangyayari nang kasing ganda at elegante gaya ng sa isang test lab.

Magsasabi ako ng kaunti tungkol sa aking sarili. Nagsimula ako bilang isang system administrator. Nagtatrabaho sa web development. Nagtatrabaho ako sa Data Egret mula noong 2014. Ang kumpanya ay nakikibahagi sa pagkonsulta sa larangan ng Postgres. At eksaktong nagse-serve kami ng mga Postgres, at nakikipagtulungan kami sa Postgres araw-araw, kaya may iba't ibang kadalubhasaan kami na may kaugnayan sa operasyon.
At sa pagtatapos ng 2018, nagsimula kaming dahan-dahang gumamit ng Patroni. At ilang karanasan ang naipon. Na-diagnose namin ito kahit papaano, na-tune ito, dumating sa aming pinakamahuhusay na kagawian. At sa ulat na ito ay pag-uusapan ko sila.
Bukod sa Postgres, gusto ko LinuxGustung-gusto ko ang pag-aayos at paggalugad nito, at gustung-gusto ko ang pagbuo ng mga kernel. Gustung-gusto ko ang virtualization, mga container, Docker, at Kubernetes. Interesado ako sa lahat ng ito dahil nahuhuli na ang mga dati kong gawi sa admin. Gustung-gusto ko ang pag-aayos sa monitoring. Gustung-gusto ko rin ang mga bagay na may kaugnayan sa Postgres na may kaugnayan sa admin, tulad ng replication at backups. At sa aking libreng oras, nagsusulat ako sa Go. Hindi ako isang software engineer, nagsusulat lang ako sa Go para sa aking sarili. At nasisiyahan ako dito.

- Sa tingin ko marami sa inyo ang nakakaalam na ang Postgres ay walang HA (High Availability) out of the box. Upang makakuha ng HA, kailangan mong mag-install ng isang bagay, i-configure ito, magsikap at makuha ito.
- Mayroong ilang mga tool at ang Patroni ay isa sa mga ito na malulutas ang HA medyo cool at napakahusay. Ngunit sa pamamagitan ng paglalagay ng lahat ng ito sa isang test lab at pagpapatakbo nito, makikita natin na gumagana ang lahat, maaari tayong magparami ng ilang mga problema, tingnan kung paano sila pinaglilingkuran ni Patroni. At makikita natin na ang lahat ay gumagana nang mahusay.
- Ngunit sa pagsasanay, kami ay nahaharap sa iba't ibang mga problema. At pag-uusapan ko ang mga problemang ito.
- Sasabihin ko sa iyo kung paano namin na-diagnose ito, kung ano ang na-tweak namin - kung ito ay nakatulong sa amin o hindi.

- Hindi ko sasabihin sa iyo kung paano i-install ang Patroni, dahil maaari kang mag-google sa Internet, maaari mong tingnan ang mga file ng pagsasaayos upang maunawaan kung paano nagsisimula ang lahat, kung paano ito na-configure. Maaari mong maunawaan ang mga scheme, arkitektura, paghahanap ng impormasyon tungkol dito sa Internet.
- Hindi ako magsasalita tungkol sa karanasan ng ibang tao. Pag-uusapan ko lang ang mga problemang ating kinaharap.
- At hindi ako magsasalita tungkol sa mga problema na nasa labas ng Patroni at PostgreSQL. Kung, halimbawa, may mga problema na nauugnay sa pagbabalanse, kapag ang aming cluster ay bumagsak, hindi ko ito pag-uusapan.

At isang maliit na disclaimer bago natin simulan ang ating ulat.
Ang lahat ng mga problemang ito na nakatagpo namin, mayroon kami sa unang 6-7-8 na buwan ng operasyon. Sa paglipas ng panahon, dumating kami sa aming mga panloob na pinakamahuhusay na kagawian. At nawala ang mga problema namin. Samakatuwid, ang ulat ay inihayag mga anim na buwan na ang nakalilipas, nang ang lahat ay sariwa sa aking isipan at naalala ko ang lahat ng ito nang perpekto.
Sa kurso ng paghahanda ng ulat, itinaas ko na ang mga lumang postmortem, tumingin sa mga log. At ang ilan sa mga detalye ay maaaring makalimutan, o ang ilan sa ilang mga detalye ay hindi maaaring ganap na maimbestigahan sa panahon ng pagsusuri ng mga problema, kaya sa ilang mga punto ay maaaring tila ang mga problema ay hindi ganap na isinasaalang-alang, o may ilang kakulangan ng impormasyon. At kaya hinihiling ko sa iyo na patawarin mo ako para sa sandaling ito.

Ano ang Patroni?
- Ito ay isang template para sa pagbuo ng HA. Iyan ang sinasabi sa dokumentasyon. At mula sa aking pananaw, ito ay isang napakatamang paglilinaw. Ang Patroni ay hindi isang pilak na bala na lulutasin ang lahat ng iyong mga problema, ibig sabihin, kailangan mong gumawa ng pagsisikap upang ito ay gumana at magdala ng mga benepisyo.
- Ito ay isang serbisyo ng ahente na naka-install sa bawat serbisyo ng database at isang uri ng init system para sa iyong mga Postgres. Nagsisimula ito ng mga Postgres, huminto, nagre-restart, nag-reconfigure, at nagbabago sa topology ng iyong cluster.
- Alinsunod dito, upang maiimbak ang estado ng kumpol, ang kasalukuyang representasyon nito, sa hitsura nito, kailangan ang ilang uri ng imbakan. At mula sa puntong ito ng pananaw, kinuha ni Patroni ang landas ng pag-iimbak ng estado sa isang panlabas na sistema. Ito ay isang distributed configuration storage system. Maaari itong maging Etcd, Consul, ZooKeeper, o kubernetes Etcd, ibig sabihin, isa sa mga opsyong ito.
- At isa sa mga tampok ng Patroni ay na makuha mo ang autofiler sa labas ng kahon, sa pamamagitan lamang ng pag-set up nito. Kung kukuha kami ng Repmgr para sa paghahambing, kung gayon ang filer ay kasama doon. Sa Repmgr, nakakakuha kami ng switchover, ngunit kung gusto namin ng autofiler, kailangan namin itong i-configure bilang karagdagan. May autofiler na si Patroni sa labas ng kahon.
- At marami pang ibang bagay. Halimbawa, ang pagpapanatili ng mga pagsasaayos, pagbuhos ng mga bagong replika, backup, atbp. Ngunit ito ay lampas sa saklaw ng ulat, hindi ako magsasalita tungkol dito.

At ang isang maliit na resulta ay ang pangunahing gawain ng Patroni ay ang gumawa ng isang autofile nang maayos at mapagkakatiwalaan upang ang aming cluster ay mananatiling operational at ang application ay hindi mapansin ang mga pagbabago sa cluster topology.

Ngunit kapag nagsimula kaming gumamit ng Patroni, ang aming sistema ay nagiging mas kumplikado. Kung mas maaga ay mayroon kaming mga Postgres, pagkatapos kapag gumagamit ng Patroni ay nakukuha namin ang Patroni mismo, nakakakuha kami ng DCS kung saan naka-imbak ang estado. At lahat ng ito ay kailangang gumana kahit papaano. Kaya ano ang maaaring magkamali?
Maaaring masira:
- Maaaring masira ang mga postgres. Maaari itong maging master o replica, maaaring mabigo ang isa sa kanila.
- Ang Patroni mismo ay maaaring masira.
- Ang DCS kung saan nakaimbak ang estado ay maaaring masira.
- At ang network ay maaaring masira.
Ang lahat ng mga puntong ito ay isasaalang-alang ko sa ulat.

Isasaalang-alang ko ang mga kaso habang nagiging mas kumplikado ang mga ito, hindi mula sa pananaw na ang kaso ay nagsasangkot ng maraming bahagi. At mula sa punto ng view ng subjective na damdamin, na ang kaso na ito ay mahirap para sa akin, ito ay mahirap na i-disassemble ito ... at vice versa, ang ilang mga kaso ay magaan at ito ay madaling i-disassemble ito.

At ang unang kaso ay ang pinakamadali. Ito ang kaso noong kumuha kami ng database cluster at na-deploy ang aming DCS storage sa parehong cluster. Ito ang pinakakaraniwang pagkakamali. Ito ay isang pagkakamali sa pagbuo ng mga arkitektura, ibig sabihin, pagsasama-sama ng iba't ibang mga bahagi sa isang lugar.
So, may nag-file, tara na sa nangyari.

At dito kami ay interesado kung kailan nangyari ang filer. Ibig sabihin, interesado kami sa sandaling ito sa oras na nagbago ang estado ng cluster.
Ngunit ang filer ay hindi palaging madalian, ibig sabihin, hindi ito tumatagal ng anumang yunit ng oras, maaari itong maantala. Maaari itong magtagal.
Samakatuwid, mayroon itong oras ng pagsisimula at oras ng pagtatapos, ibig sabihin, ito ay isang tuluy-tuloy na kaganapan. At hinahati namin ang lahat ng mga kaganapan sa tatlong pagitan: mayroon kaming oras bago ang filer, sa panahon ng filer at pagkatapos ng filer. Ibig sabihin, isinasaalang-alang namin ang lahat ng kaganapan sa timeline na ito.

And the first thing, when a filer happened, we look for the cause of what happened, what was the cause of what led to the filer.
Kung titingnan natin ang mga log, sila ay magiging mga klasikong log ng Patroni. Sinasabi niya sa amin sa kanila na ang server ay naging master, at ang papel ng master ay naipasa sa node na ito. Dito ito ay naka-highlight.

Susunod, kailangan nating maunawaan kung bakit nangyari ang filer, ibig sabihin, kung anong mga kaganapan ang naganap na naging sanhi ng paglipat ng master role mula sa isang node patungo sa isa pa. At sa kasong ito, ang lahat ay simple. Mayroon kaming error sa pakikipag-ugnayan sa storage system. Napagtanto ng master na hindi siya makakatrabaho sa DCS, iyon ay, mayroong ilang uri ng problema sa pakikipag-ugnayan. At sinabi niya na hindi na siya maaaring maging master at magbitiw. Ang linyang ito na "binaba ang sarili" ay eksaktong sinasabi niyan.

Kung titingnan natin ang mga kaganapan na nauna sa filer, makikita natin doon ang mismong mga dahilan na naging problema para sa pagpapatuloy ng wizard.
Kung titingnan natin ang mga log ng Patroni, makikita natin na marami tayong error, timeout, ibig sabihin, hindi maaaring gumana ang ahente ng Patroni sa DCS. Sa kasong ito, ito ay ahente ng Consul, na nakikipag-ugnayan sa port 8500.
Ang problema rito ay ang Patroni at ang database ay tumatakbo sa iisang host. Ang mga consul server ay tumatakbo rin sa parehong host na ito. Sa pamamagitan ng paglikha ng load sa server, lumikha kami ng mga problema para sa mga server Konsul. Hindi sila nakapag-usap nang normal.

Makalipas ang ilang oras, nang humupa ang load, muling nakipag-ugnayan ang ating Patroni sa mga ahente. Ipinagpatuloy ang normal na trabaho. At ang parehong Pgdb-2 server ay naging master muli. Iyon ay, mayroong isang maliit na pitik, dahil sa kung saan ang node ay nagbitiw sa mga kapangyarihan ng master, at pagkatapos ay kinuha muli ang mga ito, iyon ay, ang lahat ay bumalik sa dati.

At ito ay maaaring ituring na isang maling alarma, o maaari itong ituring na ginawa ni Patroni ang lahat ng tama. Iyon ay, napagtanto niya na hindi niya mapanatili ang estado ng kumpol at tinanggal ang kanyang awtoridad.
At dito lumitaw ang problema dahil sa katotohanan na ang mga server ng Consul ay nasa parehong hardware bilang mga base. Alinsunod dito, ang anumang load: ito man ay ang load sa mga disk o processor, nakakaapekto rin ito sa pakikipag-ugnayan sa cluster ng Consul.

At napagdesisyunan namin na hindi dapat tumira, naglaan kami ng hiwalay na cluster para sa Consul. At nagtatrabaho na si Patroni sa isang hiwalay na Consul, iyon ay, mayroong isang hiwalay na cluster ng Postgres, isang hiwalay na cluster ng Consul. Ito ay isang pangunahing pagtuturo kung paano dalhin at panatilihin ang lahat ng mga bagay na ito upang hindi ito mabuhay nang magkasama.
Bilang opsyon, maaari mong i-twist ang mga parameter na ttl, loop_wait, retry_timeout, ibig sabihin, subukang makaligtas sa mga panandaliang load peak na ito sa pamamagitan ng pagtaas ng mga parameter na ito. Ngunit hindi ito ang pinaka-angkop na opsyon, dahil ang pag-load na ito ay maaaring mahaba sa oras. At lalampas lang tayo sa mga limitasyong ito ng mga parameter na ito. At maaaring hindi talaga makakatulong iyon.
Ang unang problema, tulad ng naiintindihan mo, ay simple. Kinuha namin at inilagay ang DCS kasama ang base, nagkaroon kami ng problema.

Ang pangalawang problema ay katulad ng una. Ito ay katulad na mayroon tayong mga problema sa interoperability sa DCS system.

Kung titingnan natin ang mga log, makikita natin na muli tayong nagkaroon ng error sa komunikasyon. At sinabi ni Patroni na hindi ako maaaring makipag-ugnayan sa DCS kaya ang kasalukuyang master ay napupunta sa replica mode.
Ang matandang master ay naging isang replika, dito gumagana ang Patroni, tulad ng nararapat. Nagpapatakbo ito ng pg_rewind upang i-rewind ang log ng transaksyon at pagkatapos ay kumonekta sa bagong master upang makahabol sa bagong master. Dito gumagana si Patroni, gaya ng nararapat.

Dito kailangan nating hanapin ang lugar na nauna sa filer, ibig sabihin, iyong mga error na naging dahilan upang magkaroon tayo ng filer. At sa bagay na ito, ang mga log ng Patroni ay medyo maginhawa upang gumana. Sinusulat niya ang parehong mga mensahe sa isang tiyak na pagitan. At kung sisimulan nating mag-scroll nang mabilis sa mga log na ito, makikita natin mula sa mga log na nagbago ang mga log, na nangangahulugan na nagsimula na ang ilang mga problema. Mabilis kaming bumalik sa lugar na ito, tingnan kung ano ang mangyayari.
At sa isang normal na sitwasyon, ang mga log ay ganito ang hitsura. Sinusuri ang may-ari ng lock. At kung ang may-ari, halimbawa, ay nagbago, kung gayon ang ilang mga kaganapan ay maaaring mangyari na dapat tumugon sa Patroni. Ngunit sa kasong ito, maayos kami. Hinahanap namin ang lugar kung saan nagsimula ang mga pagkakamali.

At sa pag-scroll sa punto kung saan nagsimulang lumitaw ang mga error, nakita namin na nagkaroon kami ng auto-fileover. And since our errors were related to interaction with DCS and in our case we used Consul, we also look at the Consul logs, what happened there.
Sa halos paghahambing ng oras ng filer at ang oras sa Consul logs, nakita namin na ang aming mga kapitbahay sa Consul cluster ay nagsimulang magduda sa pagkakaroon ng iba pang miyembro ng Consul cluster.

At kung titingnan mo rin ang logs ng ibang Consul agents, makikita mo rin na may nangyayaring pagbagsak ng network doon. At lahat ng miyembro ng Consul cluster ay nagdududa sa pagkakaroon ng isa't isa. At ito ang naging impetus para sa filer.
Kung titingnan mo kung ano ang nangyari bago ang mga error na ito, makikita mo na mayroong lahat ng uri ng mga pagkakamali, halimbawa, ang deadline, bumagsak ang RPC, iyon ay, malinaw na mayroong isang uri ng problema sa pakikipag-ugnayan ng mga miyembro ng cluster ng Consul sa bawat isa. .

Ang pinakasimpleng sagot ay ang pag-aayos ng network. Ngunit para sa akin, nakatayo sa podium, madaling sabihin ito. Ngunit ang mga pangyayari ay tulad na hindi palaging kayang bayaran ng customer na ayusin ang network. Maaaring nakatira siya sa isang DC at maaaring hindi maayos ang network, maapektuhan ang kagamitan. At kaya kailangan ang ilang iba pang mga pagpipilian.

Mayroong mga pagpipilian:
- Ang pinakasimpleng opsyon, na nakasulat, sa palagay ko, kahit na sa dokumentasyon, ay hindi paganahin ang mga tseke ng Consul, iyon ay, ipasa lamang ang isang walang laman na hanay. At sinasabi namin sa ahente ng Consul na huwag gumamit ng anumang mga tseke. Sa pamamagitan ng mga pagsusuring ito, maaari naming balewalain ang mga bagyo sa network na ito at hindi magpasimula ng filer.
- Ang isa pang pagpipilian ay i-double check ang raft_multiplier. Ito ay isang parameter ng Consul server mismo. Bilang default, ito ay nakatakda sa 5. Ang halagang ito ay inirerekomenda ng dokumentasyon para sa mga kapaligiran sa pagtatanghal. Sa katunayan, nakakaapekto ito sa dalas ng pagmemensahe sa pagitan ng mga miyembro ng network ng Consul. Sa katunayan, ang parameter na ito ay nakakaapekto sa bilis ng komunikasyon ng serbisyo sa pagitan ng mga miyembro ng cluster ng Consul. At para sa produksyon, inirerekumenda na bawasan ito upang ang mga node ay makipagpalitan ng mga mensahe nang mas madalas.
- Ang isa pang pagpipilian na aming naisip ay ang pagtaas ng priyoridad ng mga proseso ng Consul sa iba pang mga proseso para sa scheduler ng proseso ng operating system. Mayroong isang "maganda" na parameter, tinutukoy lamang nito ang priyoridad ng mga proseso na isinasaalang-alang ng scheduler ng OS kapag nag-iiskedyul. Binawasan din namin ang magandang halaga para sa mga ahente ng Consul, i.e. pinataas ang priyoridad upang ang operating system ay nagbibigay sa mga proseso ng Consul ng mas maraming oras upang gumana at isagawa ang kanilang code. Sa aming kaso, nalutas nito ang aming problema.
- Ang isa pang pagpipilian ay ang hindi paggamit ng Consul. Mayroon akong isang kaibigan na isang malaking tagasuporta ng Etcd. At palagi kaming nakikipagtalo sa kanya kung alin ang mas mahusay na Etcd o Consul. Ngunit sa mga tuntunin kung alin ang mas mahusay, kadalasan ay sumasang-ayon kami sa kanya na ang Consul ay may isang ahente na dapat na tumatakbo sa bawat node na may database. Ibig sabihin, ang pakikipag-ugnayan ni Patroni sa cluster ng Consul ay dumadaan sa ahente na ito. At nagiging bottleneck ang ahente na ito. Kung may mangyari sa ahente, hindi na makakatrabaho si Patroni sa cluster ng Consul. At ito ang problema. Walang ahente sa Etcd plan. Maaaring gumana nang direkta si Patroni sa isang listahan ng mga server ng Etcd at nakikipag-ugnayan na sa kanila. Sa pagsasaalang-alang na ito, kung gagamit ka ng Etcd sa iyong kumpanya, malamang na ang Etcd ay isang mas mahusay na pagpipilian kaysa sa Consul. Ngunit kami sa aming mga customer ay palaging limitado sa kung ano ang pinili at ginagamit ng kliyente. At mayroon kaming Consul para sa karamihan para sa lahat ng mga kliyente.
- At ang huling punto ay upang baguhin ang mga halaga ng parameter. Maaari naming itaas ang mga parameter na ito sa pag-asa na ang aming mga panandaliang problema sa network ay magiging maikli at hindi lalampas sa saklaw ng mga parameter na ito. Sa ganitong paraan maaari naming bawasan ang pagiging agresibo ng Patroni upang mag-autofile kung may nangyaring ilang problema sa network.
Sa tingin ko maraming gumagamit ng Patroni ay pamilyar sa utos na ito.
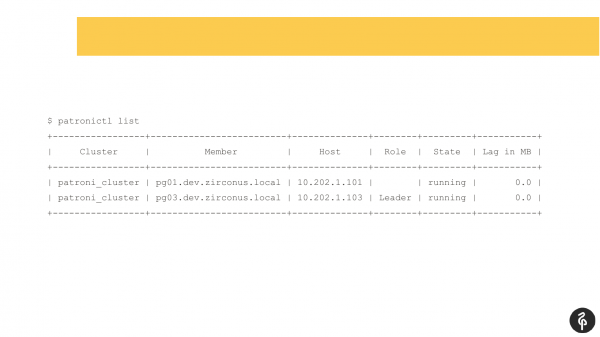
Ipinapakita ng command na ito ang kasalukuyang estado ng cluster. At sa unang tingin, ang larawang ito ay maaaring mukhang normal. Meron tayong master, meron tayong replica, walang replication lag. Ngunit ang larawang ito ay eksaktong normal hanggang sa malaman natin na ang cluster na ito ay dapat magkaroon ng tatlong node, hindi dalawa.

Alinsunod dito, nagkaroon ng autofile. At pagkatapos ng autofile na ito, nawala ang aming replika. Kailangan nating malaman kung bakit siya nawala at ibalik, ibalik. At muli kaming pumunta sa mga log at tingnan kung bakit nagkaroon kami ng auto-fileover.

Sa kasong ito, ang pangalawang replika ang naging master. Ayos lang dito.

At kailangan nating tingnan ang replica na nahulog at wala sa cluster. Binuksan namin ang mga log ng Patroni at nakita namin na nagkaroon kami ng problema sa proseso ng pagkonekta sa cluster sa yugto ng pg_rewind. Upang kumonekta sa cluster, kailangan mong i-rewind ang log ng transaksyon, hilingin ang kinakailangang log ng transaksyon mula sa master, at gamitin ito para makahabol sa master.
Sa kasong ito, wala kaming log ng transaksyon at hindi maaaring magsimula ang replika. Alinsunod dito, hinihinto namin ang Postgres na may error. At samakatuwid ito ay wala sa kumpol.

Kailangan nating maunawaan kung bakit wala ito sa cluster at kung bakit walang mga log. Pumunta kami sa bagong master at tingnan kung ano ang mayroon siya sa mga log. Lumalabas na noong ginawa ang pg_rewind, may naganap na checkpoint. At ang ilan sa mga lumang log ng transaksyon ay pinalitan lamang ng pangalan. Nang sinubukan ng matandang master na kumonekta sa bagong master at humiling ng mga log na ito, pinalitan na ang mga ito ng pangalan, wala lang ang mga ito.

Inihambing ko ang mga timestamp noong nangyari ang mga kaganapang ito. At doon ang pagkakaiba ay literal na 150 millisecond, iyon ay, ang checkpoint na nakumpleto sa 369 milliseconds, ang mga segment ng WAL ay pinalitan ng pangalan. At literal noong 517, pagkatapos ng 150 millisecond, nagsimula ang pag-rewind sa lumang replica. Ibig sabihin, literal na 150 milliseconds ay sapat na para sa amin upang ang replica ay hindi makakonekta at kumita.

Ano ang mga pagpipilian?
Una naming ginamit ang mga puwang ng pagtitiklop. Akala namin ito ay mabuti. Bagaman sa unang yugto ng operasyon ay pinatay namin ang mga puwang. Tila sa amin na kung ang mga puwang ay makaipon ng maraming mga segment ng WAL, maaari naming i-drop ang master. Babagsak siya. Nagdusa kami ng ilang oras na walang slot. At napagtanto namin na kailangan namin ng mga slot, ibinalik namin ang mga puwang.
Ngunit mayroong isang problema dito, na kapag ang master ay pumunta sa replica, tinanggal nito ang mga puwang at tinatanggal ang mga segment ng WAL kasama ang mga puwang. At para maalis ang problemang ito, nagpasya kaming itaas ang parameter na wal_keep_segments. Nagde-default ito sa 8 segment. Itinaas namin ito sa 1 at tiningnan kung gaano karaming libreng espasyo ang mayroon kami. At nag-donate kami ng 000 gigabytes para sa wal_keep_segments. Iyon ay, kapag lumilipat, palagi kaming may reserbang 16 gigabytes ng mga log ng transaksyon sa lahat ng mga node.
At plus - ito ay may kaugnayan pa rin para sa pangmatagalang mga gawain sa pagpapanatili. Sabihin nating kailangan nating i-update ang isa sa mga replika. At gusto naming i-off ito. Kailangan nating i-update ang software, marahil ang operating system, iba pa. At kapag pinatay namin ang isang replica, ang slot para sa replica na iyon ay tinanggal din. At kung gagamit tayo ng maliit na wal_keep_segments, pagkatapos ay sa mahabang kawalan ng replica, mawawala ang mga log ng transaksyon. Magtataas kami ng replica, hihilingin nito ang mga log ng transaksyon kung saan ito huminto, ngunit maaaring wala sila sa master. At hindi rin makakakonekta ang replica. Kaya naman, nagtatabi kami ng malaking stock ng mga magasin.

Mayroon kaming isang base ng produksyon. Mayroon nang mga proyektong isinasagawa.
Nagkaroon ng filer. Pumasok kami at tumingin - lahat ay maayos, ang mga replika ay nasa lugar, walang replication lag. Wala ring mga error sa mga log, maayos ang lahat.
Sinasabi ng pangkat ng produkto na dapat mayroong ilang data, ngunit nakikita namin ito mula sa isang pinagmulan, ngunit hindi namin ito nakikita sa database. At kailangan nating maunawaan kung ano ang nangyari sa kanila.

Malinaw na na-miss sila ng pg_rewind. Agad naming naintindihan ito, ngunit nagpunta upang tingnan kung ano ang nangyayari.

Sa mga log, palagi nating mahahanap kung kailan nangyari ang filer, sino ang naging master, at matutukoy natin kung sino ang matandang master at kung kailan niya gustong maging replica, ibig sabihin, kailangan natin ang mga log na ito para malaman ang halaga ng mga log ng transaksyon na nawala.
Nag-reboot ang aming matandang master. At si Patroni ay nakarehistro sa autorun. Inilunsad ang Patroni. Pagkatapos ay sinimulan niya ang Postgres. Mas tiyak, bago simulan ang Postgres at bago gawin itong replica, inilunsad ni Patroni ang pg_rewind na proseso. Alinsunod dito, binura niya ang bahagi ng mga log ng transaksyon, nag-download ng mga bago at nakakonekta. Dito nagtrabaho nang matalino si Patroni, iyon ay, tulad ng inaasahan. Ang kumpol ay naibalik. Nagkaroon kami ng 3 node, pagkatapos ng filer 3 node - lahat ay cool.

Nawalan kami ng ilang data. At kailangan nating maunawaan kung gaano kalaki ang nawala sa atin. Hinahanap namin ang sandali kung kailan kami nagkaroon ng rewind. Mahahanap natin ito sa mga naturang journal entries. Nagsimula ang rewind, may ginawa doon at natapos.

Kailangan nating hanapin ang posisyon sa log ng transaksyon kung saan huminto ang matandang master. Sa kasong ito, ito ang marka. At kailangan namin ng pangalawang marka, iyon ay, ang distansya kung saan ang lumang master ay naiiba mula sa bago.
Kinukuha namin ang karaniwang pg_wal_lsn_diff at ihambing ang dalawang markang ito. At sa kasong ito, nakakakuha tayo ng 17 megabytes. Marami o kaunti, lahat ay nagpapasya para sa kanyang sarili. Dahil para sa isang tao 17 megabytes ay hindi gaanong, para sa isang tao ito ay marami at hindi katanggap-tanggap. Dito, tinutukoy ng bawat indibidwal para sa kanyang sarili alinsunod sa mga pangangailangan ng negosyo.

Ngunit ano ang nalaman natin para sa ating sarili?
Una, dapat tayong magpasya para sa ating sarili - palagi ba nating kailangan ang Patroni na mag-autostart pagkatapos ng pag-reboot ng system? Madalas na nangyayari na kailangan nating pumunta sa matandang panginoon, tingnan kung gaano kalayo na siya. Marahil ay siyasatin ang mga segment ng log ng transaksyon, tingnan kung ano ang naroroon. At upang maunawaan kung maaari naming mawala ang data na ito o kung kailangan naming patakbuhin ang lumang master sa standalone mode upang makuha ang data na ito.
At pagkatapos lamang nito ay dapat tayong gumawa ng mga pagpapasya na maaari nating itapon ang data na ito o maaari nating ibalik ito, ikonekta ang node na ito bilang isang replica sa ating cluster.
Bilang karagdagan, mayroong parameter na "maximum_lag_on_failover". Bilang default, kung ang aking memorya ay nagsisilbi sa akin, ang parameter na ito ay may halaga na 1 megabyte.
Paano siya nagtatrabaho? Kung ang aming replica ay nasa likod ng 1 megabyte ng data sa replication lag, ang replica na ito ay hindi nakikibahagi sa mga halalan. At kung biglang may fileover, tinitingnan ni Patroni kung aling mga replika ang nahuhuli. Kung sila ay nasa likod ng isang malaking bilang ng mga log ng transaksyon, hindi sila maaaring maging isang master. Ito ay isang napakahusay na tampok sa seguridad na pumipigil sa iyong mawalan ng maraming data.
Ngunit mayroong isang problema sa na ang replication lag sa Patroni cluster at DCS ay na-update sa isang tiyak na agwat. Sa tingin ko, ang 30 segundo ay ang default na halaga ng ttl.
Alinsunod dito, maaaring mayroong isang sitwasyon kung saan mayroong isang replication lag para sa mga replika sa DCS, ngunit sa katunayan ay maaaring may ganap na naiibang lag o maaaring walang lag sa lahat, ibig sabihin, ang bagay na ito ay hindi realtime. At hindi ito palaging sumasalamin sa totoong larawan. At hindi ito nagkakahalaga ng paggawa ng magarbong lohika dito.
At ang panganib ng pagkawala ay palaging nananatili. At sa pinakamasamang kaso, isang formula, at sa karaniwang kaso, isa pang formula. Ibig sabihin, kapag pinaplano namin ang pagpapatupad ng Patroni at sinusuri kung gaano karaming data ang maaari naming mawala, dapat kaming umasa sa mga formula na ito at halos isipin kung gaano karaming data ang maaari naming mawala.
At may magandang balita. Kapag nauna na ang matandang master, maaari siyang magpatuloy dahil sa ilang proseso sa background. Iyon ay, mayroong ilang uri ng autovacuum, isinulat niya ang data, nai-save ang mga ito sa log ng transaksyon. At madali nating balewalain at mawala ang data na ito. Walang problema dito.

At ganito ang hitsura ng mga log kung nakatakda ang maximum_lag_on_failover at may naganap na filer, at kailangan mong pumili ng bagong master. Tinatasa ng replika ang sarili nito bilang walang kakayahang makibahagi sa halalan. At tumanggi siyang lumahok sa karera para sa pinuno. At naghihintay siya ng bagong master na mapili, para makakonekta siya rito. Ito ay isang karagdagang panukala laban sa pagkawala ng data.

Narito mayroon kaming pangkat ng produkto na sumulat na ang kanilang produkto ay nagkakaroon ng mga problema sa Postgres. Kasabay nito, ang master mismo ay hindi ma-access, dahil hindi ito magagamit sa pamamagitan ng SSH. At hindi rin nangyayari ang autofile.
Napilitang mag-reboot ang host na ito. Dahil sa pag-reboot, isang auto-file ang nangyari, kahit na posible na gumawa ng isang manu-manong auto-file, tulad ng naiintindihan ko na ngayon. At pagkatapos ng pag-reboot, makikita na natin kung ano ang mayroon tayo sa kasalukuyang master.
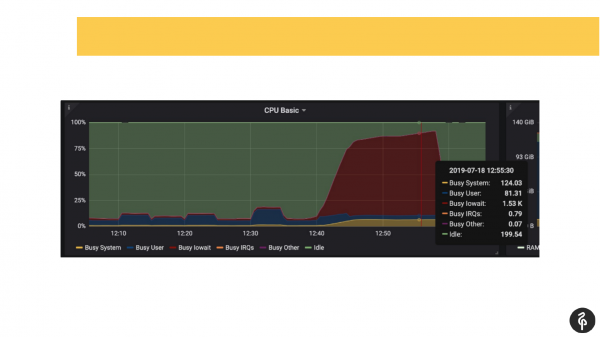
Kasabay nito, alam namin nang maaga na mayroon kaming mga problema sa mga disk, iyon ay, alam na namin mula sa pagsubaybay kung saan maghukay at kung ano ang hahanapin.

Pumasok kami sa postgres log, nagsimulang makita kung ano ang nangyayari doon. Nakita namin ang mga commit na tumatagal doon ng isa, dalawa, tatlong segundo, na hindi naman normal. Nakita namin na ang aming autovacuum ay nagsisimula nang napakabagal at kakaiba. At nakakita kami ng mga pansamantalang file sa disk. Iyon ay, ang lahat ng ito ay mga tagapagpahiwatig ng mga problema sa mga disk.

Tiningnan namin ang system dmesg (kernel log). At nakita namin na mayroon kaming mga problema sa isa sa mga disk. Ang disk subsystem ay software Raid. Tumingin kami sa /proc/mdstat at nakita namin na kulang kami ng isang drive. Ibig sabihin, may Raid ng 8 disk, kulang tayo ng isa. Kung maingat mong titingnan ang slide, pagkatapos ay sa output makikita mo na wala kaming sde doon. Sa amin, kondisyon na nagsasalita, ang disk ay bumaba. Nag-trigger ito ng mga problema sa disk, at nakaranas din ang mga application ng mga problema kapag nagtatrabaho sa cluster ng Postgres.

At sa kasong ito, hindi kami tutulungan ni Patroni sa anumang paraan, dahil walang tungkulin si Patroni na subaybayan ang estado ng server, ang estado ng disk. At dapat nating subaybayan ang mga ganitong sitwasyon sa pamamagitan ng panlabas na pagsubaybay. Mabilis kaming nagdagdag ng disk monitoring sa external monitoring.
At nagkaroon ng ganoong pag-iisip - makakatulong ba sa atin ang fencing o watchdog software? Naisip namin na halos hindi niya kami matutulungan sa kasong ito, dahil sa panahon ng mga problema, patuloy na nakikipag-ugnayan si Patroni sa cluster ng DCS at walang nakitang problema. Iyon ay, mula sa punto ng view ng DCS at Patroni, ang lahat ay maayos sa kumpol, kahit na sa katunayan may mga problema sa disk, may mga problema sa pagkakaroon ng database.
Sa aking palagay, ito ang isa sa mga kakaibang problema na aking sinaliksik sa napakatagal na panahon, marami akong nabasang log, muling pinili at tinawag itong cluster simulator.

Ang problema ay ang matandang master ay hindi maaaring maging isang normal na replika, ibig sabihin, sinimulan ito ni Patroni, ipinakita ni Patroni na ang node na ito ay naroroon bilang isang replika, ngunit sa parehong oras ay hindi ito isang normal na replika. Ngayon makikita mo kung bakit. Ito ang itinago ko sa pagsusuri sa problemang iyon.

At paano nagsimula ang lahat? Nagsimula ito, tulad ng sa nakaraang problema, sa mga disc brakes. Nagkaroon kami ng commit sa isang segundo, dalawa.

May mga break sa mga koneksyon, ibig sabihin, napunit ang mga kliyente.

Nagkaroon ng mga blockage ng iba't ibang kalubhaan.

At, nang naaayon, ang disk subsystem ay hindi masyadong tumutugon.

At ang pinaka mahiwagang bagay para sa akin ay ang agarang kahilingan sa pag-shutdown na dumating. Ang mga postgres ay may tatlong shutdown mode:
- Napakaganda kapag hinihintay natin na mag-isa ang lahat ng kliyente na madiskonekta.
- May mabilis kapag pinipilit nating idiskonekta ang mga kliyente dahil magsasara na tayo.
- At agad-agad. Sa kasong ito, hindi man lang sinasabi ni immediate sa mga kliyente na mag-shut down, magsasara lang ito nang walang babala. At sa lahat ng mga kliyente, ang operating system ay nagpapadala na ng isang RST na mensahe (isang TCP na mensahe na ang koneksyon ay nagambala at ang kliyente ay wala nang mahuhuli).
Sino ang nagpadala ng signal na ito? Ang mga proseso sa background ng postgres ay hindi nagpapadala ng mga ganoong signal sa isa't isa, ibig sabihin, ito ay kill-9. Hindi sila nagpapadala ng mga ganoong bagay sa isa't isa, nagre-react lang sila sa mga ganoong bagay, ibig sabihin, ito ay emergency restart ng Postgres. Kung sino ang nagpadala nito, hindi ko alam.
Tiningnan ko ang "huling" utos at nakita ko ang isang tao na nag-log in din sa server na ito sa amin, ngunit nahihiya akong magtanong. Marahil ito ay pumatay -9. Makakakita ako ng pumatay -9 sa mga log, dahil Sinabi ng mga postgres na kinuha nito ang pagpatay -9, ngunit hindi ko ito nakita sa mga log.

Sa karagdagang pagtingin, nakita ko na hindi sumulat si Patroni sa log sa loob ng mahabang panahon - 54 segundo. At kung ihahambing natin ang dalawang timestamp, walang mga mensahe sa loob ng humigit-kumulang 54 segundo.
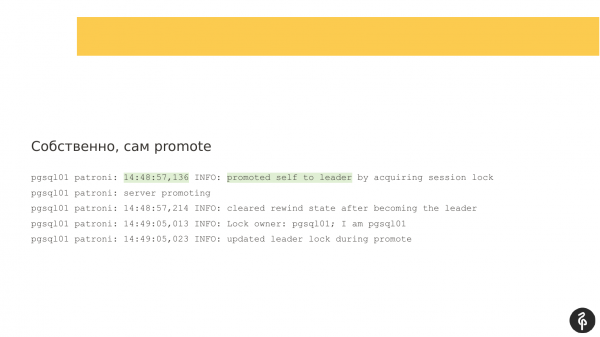
At sa panahong ito ay mayroong isang autofile. Napakaganda ng ginawa ni Patroni dito. Hindi available ang matandang master namin, may nangyari sa kanya. At nagsimula ang pagpili ng isang bagong master. Naging maayos ang lahat dito. Ang aming pgsql01 ay naging bagong pinuno.

Mayroon kaming isang replika na naging master. At may pangalawang tugon. At may mga problema sa pangalawang replika. Sinubukan niyang i-configure muli. Sa pagkakaintindi ko, sinubukan niyang baguhin ang recovery.conf, i-restart ang Postgres at kumonekta sa bagong master. Nagsusulat siya ng mga mensahe tuwing 10 segundo na sinusubukan niya, ngunit hindi siya nagtagumpay.

At sa panahon ng mga pagtatangka na ito, isang signal ng agarang-shutdown ang dumating sa matandang master. Ang master ay na-restart. At huminto rin ang pagbawi dahil nagre-reboot ang lumang master. Ibig sabihin, hindi makakonekta ang replica dito, dahil nasa shutdown mode ito.

Sa ilang mga punto, ito ay nagtrabaho, ngunit ang pagtitiklop ay hindi nagsimula.
Ang hula ko lang ay mayroong lumang master address sa recovery.conf. At nang lumitaw ang isang bagong master, sinubukan pa rin ng pangalawang replika na kumonekta sa lumang master.
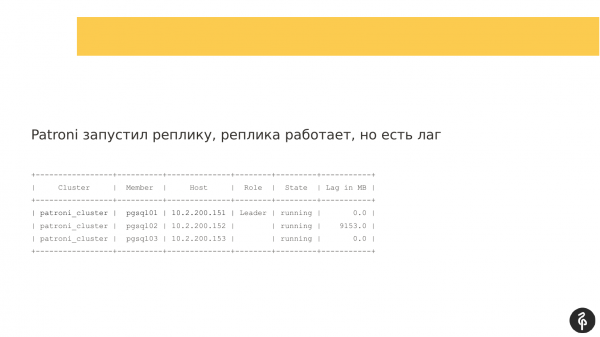
Nang magsimula si Patroni sa pangalawang replika, nagsimula ang node ngunit hindi maaaring magtiklop. At nabuo ang isang replication lag, na mukhang ganito. Iyon ay, lahat ng tatlong node ay nasa lugar, ngunit ang pangalawang node ay nahuli.
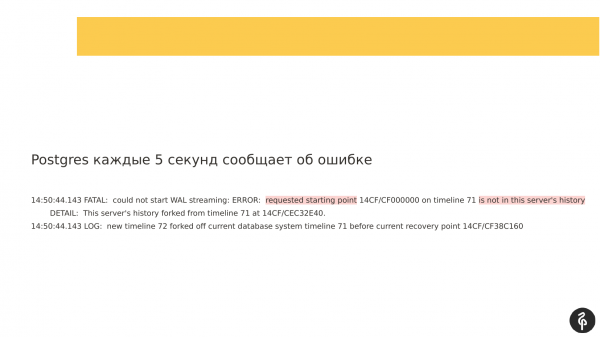
Kasabay nito, kung titingnan mo ang mga log na isinulat, makikita mo na ang pagtitiklop ay hindi maaaring magsimula dahil ang mga log ng transaksyon ay iba. At ang mga log ng transaksyon na inaalok ng master, na tinukoy sa recovery.conf, ay hindi magkasya sa aming kasalukuyang node.

At dito ako nagkamali. Kailangan kong pumunta at tingnan kung ano ang nasa recovery.conf upang subukan ang aking hypothesis na kami ay kumukonekta sa maling master. Ngunit pagkatapos ay nakikitungo lang ako dito at hindi ito nangyari sa akin, o nakita ko na ang replika ay nahuhuli at kailangang mapunan muli, iyon ay, kahit papaano ay nagtrabaho ako nang walang ingat. Ito ang aking pinagsamahan.

After 30 minutes, dumating na ang admin, ibig sabihin, ni-restart ko si Patroni sa replica. Tinapos ko na ito, naisip ko na ito ay kailangang i-refill. At naisip ko - I'll restart Patroni, baka may magandang mangyari. Nagsimula ang pagbawi. At nagbukas pa ang base, handa na itong tumanggap ng mga koneksyon.
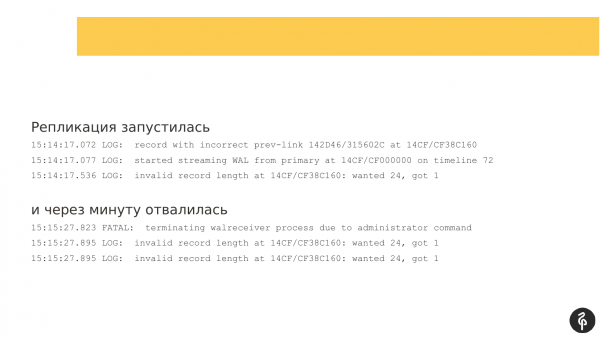
Nagsimula na ang pagtitiklop. Ngunit makalipas ang isang minuto, nahulog siya nang may error na hindi angkop sa kanya ang mga log ng transaksyon.

Akala ko mag restart ulit. Ni-restart ko muli ang Patroni, at hindi ko na-restart ang Postgres, ngunit na-restart ang Patroni sa pag-asang magsisimula ito sa database.

Nagsimula muli ang pagtitiklop, ngunit ang mga marka sa log ng transaksyon ay iba, hindi sila katulad ng nakaraang pagtatangka sa pagsisimula. Huminto muli ang pagtitiklop. At medyo iba na ang mensahe. At hindi ito masyadong informative para sa akin.

At pagkatapos ito ay nangyayari sa akin - paano kung i-restart ko ang Postgres, sa oras na ito gumawa ako ng isang tsekpoint sa kasalukuyang master upang ilipat ang punto sa log ng transaksyon nang kaunti pasulong upang ang pagbawi ay magsimula mula sa isa pang sandali? Dagdag pa, mayroon pa kaming mga stock ng WAL.

Ni-restart ko ang Patroni, gumawa ng ilang checkpoints sa master, ilang restart point sa replica noong binuksan ito. At nakatulong ito. Matagal kong iniisip kung bakit ito nakatulong at kung paano ito gumagana. At nagsimula na ang replica. At hindi na napunit ang pagtitiklop.

Ang ganoong problema para sa akin ay isa sa mga mas mahiwaga, kung saan hanggang ngayon ay naguguluhan pa rin ako sa kung ano talaga ang nangyari doon.
Ano ang mga implikasyon dito? Maaaring gumana ang Patroni ayon sa nilalayon at walang anumang mga pagkakamali. Ngunit sa parehong oras, ito ay hindi isang 100% na garantiya na ang lahat ay maayos sa amin. Maaaring magsimula ang replica, ngunit maaaring nasa semi-working na estado, at hindi maaaring gumana ang application sa ganoong replica, dahil magkakaroon ng lumang data.
At pagkatapos ng filer, kailangan mong palaging suriin kung ang lahat ay maayos sa kumpol, iyon ay, mayroong kinakailangang bilang ng mga replika, walang replication lag.
At habang pinagdaraanan natin ang mga isyung ito, gagawa ako ng mga rekomendasyon. Sinubukan kong pagsamahin ang mga ito sa dalawang slide. Malamang, lahat ng kwento ay maaaring pagsamahin sa dalawang slide at isalaysay lamang.

Kapag gumamit ka ng Patroni, dapat may monitoring ka. Dapat mong laging malaman kung kailan naganap ang isang autofileover, dahil kung hindi mo alam na mayroon kang autofileover, wala kang kontrol sa cluster. At masama iyon.
Pagkatapos ng bawat filer, palagi naming kailangang manual na suriin ang cluster. Kailangan nating tiyakin na palagi tayong may up-to-date na bilang ng mga replika, walang replication lag, walang mga error sa mga log na nauugnay sa streaming replication, kasama ang Patroni, kasama ang DCS system.
Maaaring matagumpay na gumana ang automation, ang Patroni ay isang napakahusay na tool. Maaari itong gumana, ngunit hindi nito dadalhin ang kumpol sa nais na estado. At kung hindi natin malalaman ang tungkol dito, magkakaproblema tayo.
At si Patroni ay hindi isang pilak na bala. Kailangan pa rin nating maunawaan kung paano gumagana ang Postgres, kung paano gumagana ang replikasyon at kung paano gumagana ang Patroni sa Postgres, at kung paano ibinibigay ang komunikasyon sa pagitan ng mga node. Ito ay kinakailangan upang magawang ayusin ang mga problema sa iyong mga kamay.

Paano ko lalapitan ang isyu ng diagnosis? Nagkataon na nagtatrabaho kami sa iba't ibang mga kliyente at walang sinuman ang may ELK stack, at kailangan naming ayusin ang mga log sa pamamagitan ng pagbubukas ng 6 na console at 2 tab. Sa isang tab, ito ang mga Patroni log para sa bawat node, sa kabilang tab, ito ang mga Consul log, o Postgres kung kinakailangan. Napakahirap i-diagnose ito.
Anong mga diskarte ang aking binuo? Una, palagi akong tumitingin kapag dumating na ang filer. At para sa akin ito ay isang watershed. Tinitingnan ko kung ano ang nangyari bago ang filer, sa panahon ng filer at pagkatapos ng filer. Ang fileover ay may dalawang marka: ito ang oras ng pagsisimula at pagtatapos.
Susunod, tinitingnan ko ang mga log para sa mga kaganapan bago ang filer, na nauna sa filer, ibig sabihin, hinahanap ko ang mga dahilan kung bakit nangyari ang filer.
At ito ay nagbibigay ng isang larawan ng pag-unawa kung ano ang nangyari at kung ano ang maaaring gawin sa hinaharap upang ang mga ganitong pangyayari ay hindi mangyari (at bilang isang resulta, walang filer).
At saan tayo madalas tumingin? tumingin ako:
- Una, sa mga tala ng Patroni.
- Susunod, tinitingnan ko ang mga log ng Postgres, o ang mga log ng DCS, depende sa kung ano ang natagpuan sa mga log ng Patroni.
- At ang mga log ng system ay nagbibigay din minsan ng pag-unawa sa kung ano ang sanhi ng filer.

Ano ang nararamdaman ko kay Patroni? Mayroon akong napakagandang relasyon kay Patroni. Sa aking palagay, ito ang pinakamahusay na mayroon ngayon. Marami pa akong alam na produkto. Ito ay Stolon, Repmgr, Pg_auto_failover, PAF. 4 na kasangkapan. Sinubukan ko silang lahat. Patroni ang paborito ko.
Kung tatanungin nila ako: "Inirerekomenda ko ba si Patroni?". Sasabihin ko oo, dahil gusto ko si Patroni. At parang natuto akong magluto nito.
Kung interesado kang makita kung ano ang iba pang mga problema sa Patroni bukod sa mga problemang nabanggit ko, maaari mong palaging tingnan ang pahina sa GitHub. Maraming iba't ibang kwento at maraming mga interesanteng isyu ang tinatalakay doon. At bilang isang resulta, ang ilang mga bug ay ipinakilala at nalutas, iyon ay, ito ay isang kawili-wiling basahin.
Mayroong ilang mga kagiliw-giliw na kuwento tungkol sa mga tao na nagbaril sa kanilang sarili sa paa. Napaka informative. Nabasa at nauunawaan mo na hindi kinakailangan na gawin ito. Kinurot ko ang sarili ko.
At nais kong magpasalamat sa Zalando sa pagbuo ng proyektong ito, lalo na kina Alexander Kukushkin at Alexey Klyukin. Si Aleksey Klyukin ay isa sa mga co-authors, hindi na siya nagtatrabaho sa Zalando, ngunit ito ay dalawang tao na nagsimulang magtrabaho sa produktong ito.
At sa tingin ko ang Patroni ay isang napaka-cool na bagay. Masaya ako na nag-e-exist siya, nakakatuwa sakanya. At isang malaking pasasalamat sa lahat ng mga nag-ambag na sumulat ng mga patch sa Patroni. Umaasa ako na si Patroni ay maging mas mature, cool at mahusay sa edad. Ito ay gumagana na, ngunit umaasa ako na ito ay mapabuti pa. Samakatuwid, kung plano mong gamitin ang Patroni, pagkatapos ay huwag matakot. Ito ay isang magandang solusyon, maaari itong ipatupad at gamitin.
Iyon lang. Kung mayroon kang mga katanungan, magtanong.

mga katanungan
Salamat sa ulat! Kung pagkatapos ng isang filer kailangan mo pa ring tumingin doon nang mabuti, kung gayon bakit kailangan natin ng isang awtomatikong filer?
Dahil ito ay mga bagong bagay. Isang taon pa lang namin siya. Mas mabuting maging ligtas. Gusto naming pumasok at makita na ang lahat ay talagang gumana sa paraang nararapat. Ito ang antas ng kawalan ng tiwala ng may sapat na gulang - mas mainam na suriin at tingnan.
Halimbawa, pumunta kami sa umaga at tumingin, tama?
Hindi sa umaga, kadalasang natututo kami tungkol sa autofile nang halos kaagad. Nakatanggap kami ng mga notification, nakita namin na may naganap na autofile. Halos agad kaming pumunta at tumingin. Ngunit ang lahat ng mga pagsusuring ito ay dapat dalhin sa antas ng pagsubaybay. Kung na-access mo ang Patroni sa pamamagitan ng REST API, mayroong isang kasaysayan. Ayon sa kasaysayan, makikita mo ang mga timestamp kung kailan nangyari ang filer. Batay dito, maaaring gawin ang pagsubaybay. Makikita mo ang kasaysayan, kung gaano karaming mga kaganapan ang naroon. Kung mayroon kaming higit pang mga kaganapan, pagkatapos ay isang autofile ang naganap. Maaari kang pumunta at tingnan. O sinuri ng aming monitoring automation na mayroon kaming lahat ng mga replika sa lugar, walang lag at lahat ay maayos.
Salamat sa iyo!
Maraming salamat sa magandang kwento! Kung inilipat namin ang kumpol ng DCS sa isang lugar na malayo sa kumpol ng Postgres, kailangan ding serbisyuhan ang kumpol na ito sa pana-panahon? Ano ang mga pinakamahusay na kagawian na kailangang i-off ang ilang piraso ng DCS cluster, may kinalaman sa mga ito, atbp.? Paano nabubuhay ang buong istrukturang ito? At paano mo ginagawa ang mga bagay na ito?
Para sa isang kumpanya, kinakailangan na gumawa ng isang matrix ng mga problema, kung ano ang mangyayari kung ang isa sa mga bahagi o ilang mga bahagi ay nabigo. Ayon sa matrix na ito, sunud-sunod kaming dumaan sa lahat ng mga bahagi at bumuo ng mga sitwasyon kung sakaling mabigo ang mga sangkap na ito. Alinsunod dito, para sa bawat senaryo ng pagkabigo, maaari kang magkaroon ng plano ng pagkilos para sa pagbawi. At sa kaso ng DCS, ito ay bahagi ng karaniwang imprastraktura. At pinangangasiwaan ito ng admin, at umaasa na kami sa mga admin na nangangasiwa nito at sa kanilang kakayahang ayusin ito kung sakaling magkaroon ng aksidente. Kung wala man lang DCS, ipapatupad namin ito, ngunit sa parehong oras ay hindi namin ito partikular na sinusubaybayan, dahil hindi kami responsable para sa imprastraktura, ngunit nagbibigay kami ng mga rekomendasyon kung paano at kung ano ang susubaybayan.
Iyon ay, naiintindihan ko ba nang tama na kailangan kong huwag paganahin ang Patroni, huwag paganahin ang filer, huwag paganahin ang lahat bago gumawa ng anuman sa mga host?
Depende ito sa kung ilang node ang mayroon tayo sa cluster ng DCS. Kung maraming node at kung isa lang sa mga node ang idi-disable natin (ang replica), ang cluster ay nagpapanatili ng isang quorum. At nananatiling operational ang Patroni. At walang na-trigger. Kung mayroon kaming ilang kumplikadong mga operasyon na nakakaapekto sa higit pang mga node, ang kawalan nito ay maaaring makasira sa korum, kung gayon - oo, maaaring makatuwirang ilagay si Patroni sa paghinto. Mayroon itong kaukulang utos - patronictl pause, patronictl resume. Naka-pause lang kami at hindi gumagana ang autofiler sa oras na iyon. Nagsasagawa kami ng pagpapanatili sa kumpol ng DCS, pagkatapos ay tinanggal namin ang pag-pause at patuloy na nabubuhay.
Maraming salamat sa inyo!
Maraming salamat sa iyong ulat! Ano ang pakiramdam ng pangkat ng produkto tungkol sa pagkawala ng data?
Walang pakialam ang mga team ng produkto, at nag-aalala ang mga lead team.
Anong mga garantiya ang mayroon?
Ang mga garantiya ay napakahirap. Si Alexander Kukushkin ay may ulat na "Paano kalkulahin ang RPO at RTO", ibig sabihin, oras ng pagbawi at kung gaano karaming data ang maaari naming mawala. Sa tingin ko kailangan nating hanapin ang mga slide na ito at pag-aralan ang mga ito. Sa pagkakatanda ko, may mga tiyak na hakbang kung paano kalkulahin ang mga bagay na ito. Gaano karaming mga transaksyon ang maaari nating mawala, kung gaano karaming data ang maaari nating mawala. Bilang isang opsyon, maaari naming gamitin ang kasabay na pagtitiklop sa antas ng Patroni, ngunit ito ay isang tabak na may dalawang talim: mayroon kaming pagiging maaasahan ng data, o nawawalan kami ng bilis. Mayroong sabay-sabay na pagtitiklop, ngunit hindi rin nito ginagarantiyahan ang 100% na proteksyon laban sa pagkawala ng data.
Alexey, salamat sa magandang ulat! Anumang karanasan sa paggamit ng Patroni para sa zero level na proteksyon? Ibig sabihin, kasabay ng kasabay na standby? Ito ang unang tanong. At ang pangalawang tanong. Gumamit ka ng iba't ibang solusyon. Ginamit namin ang Repmgr, ngunit walang autofiler, at ngayon ay pinaplano naming isama ang autofiler. At itinuturing namin ang Patroni bilang isang alternatibong solusyon. Ano ang masasabi mo bilang mga pakinabang kumpara sa Repmgr?
Ang unang tanong ay tungkol sa magkasabay na mga replika. Walang gumagamit ng sabay-sabay na pagtitiklop dito, dahil ang lahat ay natatakot (Maraming mga kliyente ang gumagamit na nito, sa prinsipyo, hindi nila napansin ang mga problema sa pagganap - Tala ng tagapagsalita). Ngunit nakabuo kami ng panuntunan para sa ating sarili na dapat mayroong hindi bababa sa tatlong node sa isang kasabay na cluster ng pagtitiklop, dahil kung mayroon tayong dalawang node at kung nabigo ang master o replica, inililipat ni Patroni ang node na ito sa Standalone mode upang ang application ay magpatuloy sa trabaho. Sa kasong ito, may panganib ng pagkawala ng data.
Tungkol sa pangalawang tanong, ginamit namin ang Repmgr at ginagawa pa rin namin ang ilang mga kliyente para sa mga makasaysayang dahilan. Ano ang masasabi? Ang Patroni ay may kasamang autofiler sa labas ng kahon, ang Repmgr ay may kasamang autofiler bilang karagdagang feature na kailangang paganahin. Kailangan nating patakbuhin ang Repmgr daemon sa bawat node at pagkatapos ay maaari nating i-configure ang autofiler.
Sinusuri ng Repmgr kung buhay ang mga postgres node. Sinusuri ng mga proseso ng Repmgr ang pagkakaroon ng bawat isa, hindi ito isang napakahusay na diskarte. maaaring magkaroon ng mga kumplikadong kaso ng paghihiwalay ng network kung saan ang isang malaking Repmgr cluster ay maaaring magkahiwa-hiwalay sa ilang mas maliliit at magpatuloy sa pagtatrabaho. Matagal na akong hindi nasusubaybayan ang Repmgr, baka naayos na ... o baka hindi. Ngunit ang pag-alis ng impormasyon tungkol sa estado ng cluster sa DCS, tulad ng ginagawa ni Stolon, Patroni, ay ang pinaka-mabubuhay na opsyon.
Alexey, may tanong ako, baka lamer. Sa isa sa mga unang halimbawa, inilipat mo ang DCS mula sa lokal na makina patungo sa isang malayong host. Naiintindihan namin na ang network ay isang bagay na may sariling katangian, nabubuhay ito sa sarili nitong. At ano ang mangyayari kung sa ilang kadahilanan ay hindi magagamit ang kumpol ng DCS? Hindi ko na sasabihin ang mga dahilan, maaaring marami sa kanila: mula sa baluktot na kamay ng mga networker hanggang sa mga totoong problema.
Hindi ko ito sinabi nang malakas, ngunit ang cluster ng DCS ay dapat ding failover, ibig sabihin, ito ay isang kakaibang bilang ng mga node, upang matugunan ang isang korum. Ano ang mangyayari kung ang DCS cluster ay hindi magagamit, o ang isang korum ay hindi matugunan, ibig sabihin, ilang uri ng network split o node failure? Sa kasong ito, ang Patroni cluster ay napupunta sa read only mode. Hindi matukoy ng cluster ng Patroni ang estado ng cluster at kung ano ang gagawin. Hindi ito maaaring makipag-ugnayan sa DCS at iimbak ang bagong estado ng cluster doon, kaya ang buong cluster ay napupunta sa read only. At naghihintay para sa manu-manong interbensyon mula sa operator o para sa pagbawi ng DCS.
Sa halos pagsasalita, ang DCS ay nagiging isang serbisyo para sa amin na kasinghalaga ng base mismo?
Oo Oo. Sa napakaraming modernong kumpanya, ang Service Discovery ay isang mahalagang bahagi ng imprastraktura. Ito ay ipinatutupad bago pa man magkaroon ng database sa imprastraktura. Sa relatibong pagsasalita, ang imprastraktura ay inilunsad, na-deploy sa DC, at mayroon kaming Service Discovery kaagad. Kung ito ay Consul, kung gayon ang DNS ay maaaring itayo dito. Kung ito ay Etcd, maaaring mayroong isang bahagi mula sa Kubernetes cluster, kung saan ang lahat ng iba pa ay ide-deploy. Para sa akin, ang Service Discovery ay isa nang mahalagang bahagi ng mga modernong imprastraktura. At iniisip nila ito nang mas maaga kaysa sa mga database.
Salamat sa iyo!
Pinagmulan: www.habr.com
