

Alalahanin natin na ang Elastic Stack ay batay sa hindi nauugnay na Elasticsearch database, ang Kibana web interface at mga data collector at processor (ang pinakasikat na Logstash, iba't ibang Beats, APM at iba pa). Ang isa sa mga magagandang karagdagan sa buong nakalistang stack ng produkto ay ang pagsusuri ng data gamit ang mga algorithm ng machine learning. Sa artikulong naiintindihan namin kung ano ang mga algorithm na ito. Mangyaring sa ilalim ng pusa.
Ang machine learning ay isang bayad na feature ng shareware Elastic Stack at kasama sa X-Pack. Upang simulan ang paggamit nito, i-activate lamang ang 30-araw na pagsubok pagkatapos ng pag-install. Pagkatapos mag-expire ang panahon ng pagsubok, maaari kang humiling ng suporta upang palawigin ito o bumili ng subscription. Ang halaga ng isang subscription ay kinakalkula hindi batay sa dami ng data, ngunit sa bilang ng mga node na ginamit. Hindi, ang dami ng data, siyempre, ay nakakaapekto sa bilang ng mga kinakailangang node, ngunit ang pamamaraang ito sa paglilisensya ay mas makatao kaugnay sa badyet ng kumpanya. Kung hindi kailangan ng mataas na produktibidad, makakatipid ka ng pera.
Ang ML sa Elastic Stack ay nakasulat sa C++ at tumatakbo sa labas ng JVM, kung saan tumatakbo ang Elasticsearch mismo. Iyon ay, ang proseso (sa pamamagitan ng paraan, ito ay tinatawag na autodetect) kumokonsumo ng lahat ng bagay na hindi nilalamon ng JVM. Sa isang demo stand na ito ay hindi masyadong kritikal, ngunit sa isang kapaligiran ng produksyon mahalaga na maglaan ng hiwalay na mga node para sa mga gawain sa ML.
Ang mga algorithm ng machine learning ay nahahati sa dalawang kategorya − и . Sa Elastic Stack, ang algorithm ay nasa kategoryang "unsupervised". Sa pamamagitan ng Makikita mo ang mathematical apparatus ng machine learning algorithm.
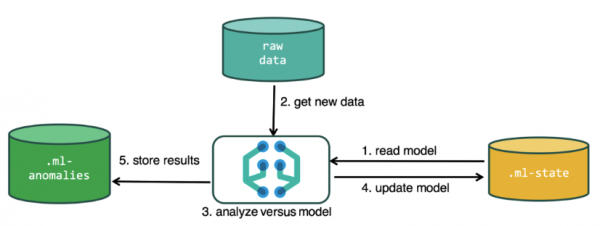
Upang maisagawa ang pagsusuri, ginagamit ng machine learning algorithm ang data na nakaimbak sa mga index ng Elasticsearch. Maaari kang lumikha ng mga gawain para sa pagsusuri kapwa mula sa interface ng Kibana at sa pamamagitan ng API. Kung gagawin mo ito sa pamamagitan ng Kibana, hindi mo kailangang malaman ang ilang bagay. Halimbawa, ang mga karagdagang index na ginagamit ng algorithm sa panahon ng operasyon nito.
Mga karagdagang indeks na ginamit sa proseso ng pagsusuri.ml-state — impormasyon tungkol sa mga istatistikal na modelo (mga setting ng pagsusuri);
.ml-anomalies-* — mga resulta ng mga ML algorithm;
.ml-notifications — mga setting para sa mga notification batay sa mga resulta ng pagsusuri.
Ang istruktura ng data sa database ng Elasticsearch ay binubuo ng mga index at dokumentong nakaimbak sa mga ito. Kung ihahambing sa isang relational database, ang isang index ay maaaring ihambing sa isang database schema, at isang dokumento sa isang talaan sa isang talahanayan. Ang paghahambing na ito ay may kondisyon at ibinigay upang pasimplehin ang pag-unawa sa karagdagang materyal para sa mga nakarinig lamang tungkol sa Elasticsearch.
Ang parehong functionality ay magagamit sa pamamagitan ng API tulad ng sa pamamagitan ng web interface, kaya para sa kalinawan at pag-unawa sa mga konsepto, ipapakita namin kung paano ito i-configure sa pamamagitan ng Kibana. Sa menu sa kaliwa ay mayroong seksyong Machine Learning kung saan maaari kang lumikha ng bagong Trabaho. Sa interface ng Kibana, kamukha ito ng larawan sa ibaba. Ngayon ay susuriin natin ang bawat uri ng gawain at ipapakita ang mga uri ng pagsusuri na maaaring itayo dito.
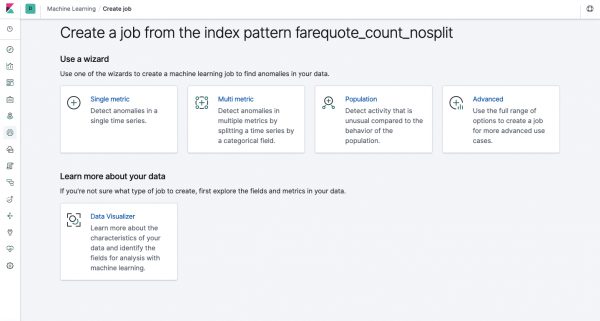
Single Sukatan - pagsusuri ng isang sukatan, Multi Sukatan - pagsusuri ng dalawa o higit pang sukatan. Sa parehong mga kaso, ang bawat sukatan ay sinusuri sa isang nakahiwalay na kapaligiran, i.e. hindi isinasaalang-alang ng algorithm ang pag-uugali ng mga parallel na nasuri na sukatan, na maaaring mukhang sa kaso ng Multi Metric. Upang magsagawa ng mga kalkulasyon na isinasaalang-alang ang ugnayan ng iba't ibang sukatan, maaari mong gamitin ang pagsusuri ng Populasyon. At pino-pino ng Advanced ang mga algorithm na may mga karagdagang opsyon para sa ilang partikular na gawain.
Isang Sukatan
Ang pagsusuri sa mga pagbabago sa isang sukatan ay ang pinakasimpleng bagay na maaaring gawin dito. Pagkatapos mag-click sa Lumikha ng Trabaho, ang algorithm ay maghahanap ng mga anomalya.
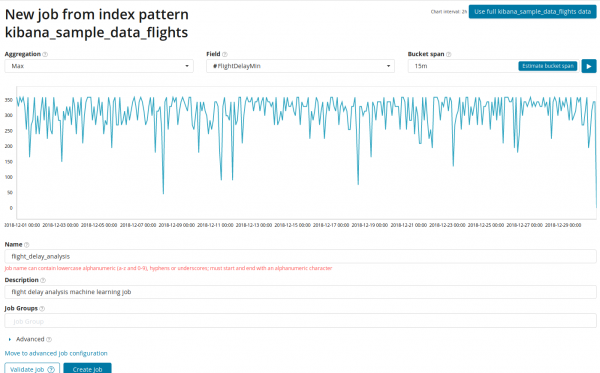
Sa larangan Pagsasama-sama maaari kang pumili ng diskarte sa paghahanap ng mga anomalya. Halimbawa, kapag Min ang mga halagang mas mababa sa karaniwang mga halaga ay ituturing na anomalya. Kumain Max, High Mean, Low, Mean, Distinct at iba pa. Ang mga paglalarawan ng lahat ng mga function ay matatagpuan .
Sa larangan Patlang ay nagpapahiwatig ng numeric field sa dokumento kung saan namin isasagawa ang pagsusuri.
Sa larangan — granularity ng mga agwat sa timeline kung saan isasagawa ang pagsusuri. Maaari mong pagkatiwalaan ang automation o manu-manong pumili. Ang larawan sa ibaba ay isang halimbawa ng pagiging napakababa ng granularity - maaaring makaligtaan mo ang anomalya. Gamit ang setting na ito, maaari mong baguhin ang sensitivity ng algorithm sa mga anomalya.
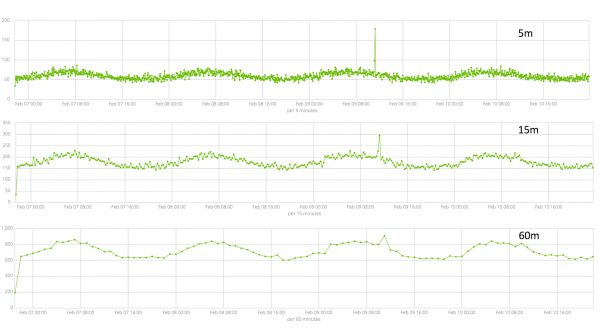
Ang tagal ng data na nakolekta ay isang mahalagang bagay na nakakaapekto sa pagiging epektibo ng pagsusuri. Sa panahon ng pagsusuri, kinikilala ng algorithm ang mga umuulit na agwat, kinakalkula ang mga agwat ng kumpiyansa (mga baseline) at kinikilala ang mga anomalya - mga hindi tipikal na paglihis mula sa karaniwang gawi ng sukatan. Halimbawa lang:
Mga baseline na may maliit na piraso ng data:
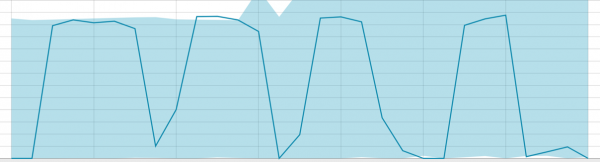
Kapag may matututunan ang algorithm, ganito ang hitsura ng baseline:
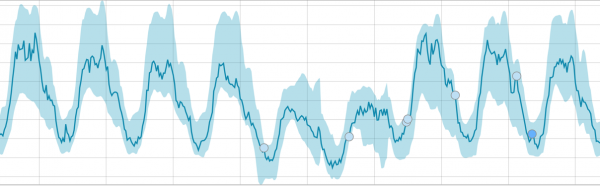
Matapos simulan ang gawain, tinutukoy ng algorithm ang mga anomalyang paglihis mula sa pamantayan at niraranggo ang mga ito ayon sa posibilidad ng isang anomalya (ang kulay ng kaukulang label ay ipinahiwatig sa mga panaklong):
Babala (asul): mas mababa sa 25
Minor (dilaw): 25-50
Major (kahel): 50-75
Kritikal (pula): 75-100
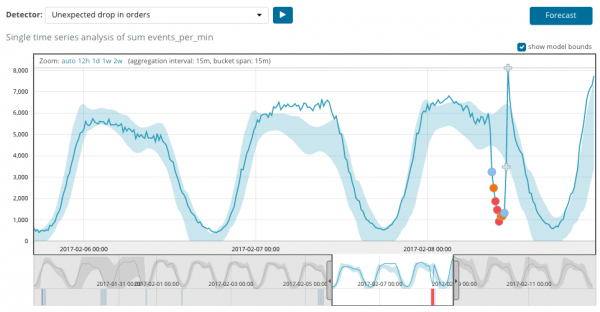
Ang graph sa ibaba ay nagpapakita ng isang halimbawa ng mga anomalyang natagpuan.
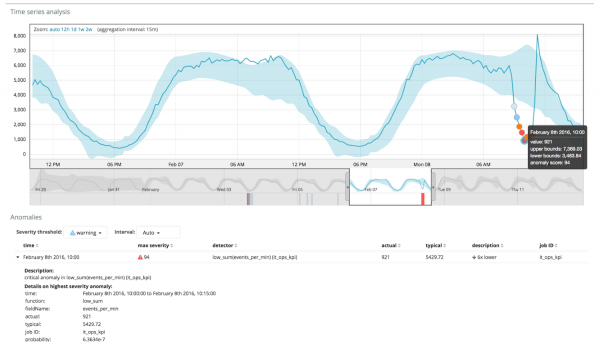
Dito makikita mo ang numero 94, na nagpapahiwatig ng posibilidad ng isang anomalya. Malinaw na dahil malapit sa 100 ang value, ibig sabihin mayroon tayong anomalya. Ang column sa ibaba ng graph ay nagpapakita ng pejoratively small probability na 0.000063634% ng metric value na lumalabas doon.
Bilang karagdagan sa paghahanap ng mga anomalya, maaari kang magpatakbo ng pagtataya sa Kibana. Ginagawa ito nang simple at mula sa parehong view na may mga anomalya - pindutan Manghula sa kanang sulok sa itaas.
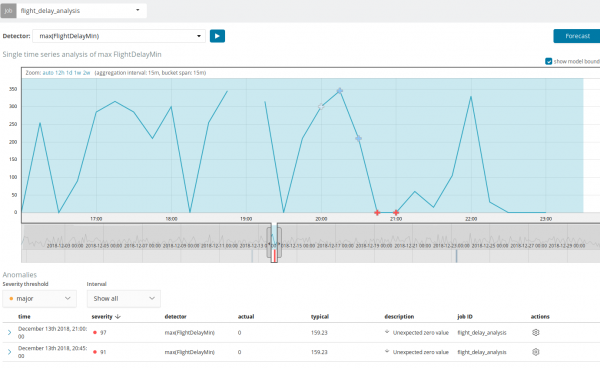
Ang pagtataya ay ginawa para sa maximum na 8 linggo nang maaga. Kahit na gusto mo talaga, hindi na ito posible sa pamamagitan ng disenyo.
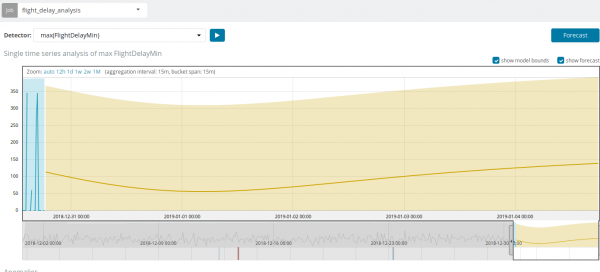
Sa ilang mga sitwasyon, ang forecast ay magiging lubhang kapaki-pakinabang, halimbawa, kapag sinusubaybayan ang pagkarga ng user sa imprastraktura.
Maramihang Sukatan
Lumipat tayo sa susunod na feature ng ML sa Elastic Stack - pag-aaral ng ilang sukatan sa isang batch. Ngunit hindi ito nangangahulugan na ang pag-asa ng isang sukatan sa isa pa ay susuriin. Pareho ito sa Single Sukatan, ngunit may maraming sukatan sa isang screen para sa madaling paghahambing ng epekto ng isa sa isa. Pag-uusapan natin ang tungkol sa pagsusuri sa pagdepende ng isang sukatan sa isa pa sa seksyong Populasyon.
Pagkatapos mag-click sa parisukat na may Multi Metric, lalabas ang isang window na may mga setting. Tingnan natin ang mga ito nang mas detalyado.
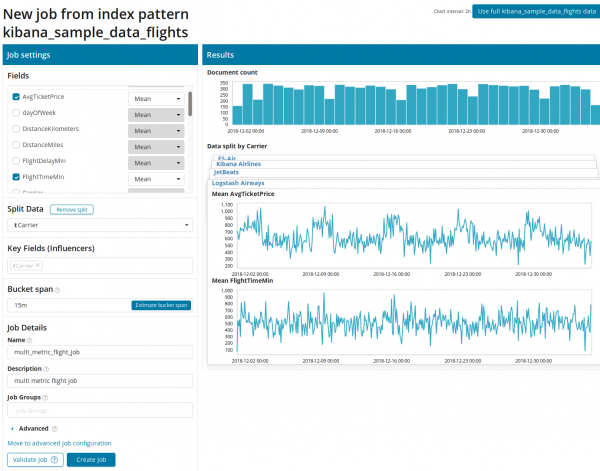
Una kailangan mong piliin ang mga field para sa pagsusuri at pagsasama-sama ng data sa mga ito. Ang mga opsyon sa pagsasama-sama dito ay kapareho ng para sa Single Sukatan (Max, High Mean, Low, Mean, Distinct at iba pa). Dagdag pa, kung ninanais, ang data ay nahahati sa isa sa mga patlang (field Hatiin ang Data). Sa halimbawa, ginawa namin ito sa pamamagitan ng field OriginAirportID. Pansinin na ang graph ng mga sukatan sa kanan ay ipinakita na ngayon bilang maramihang mga graph.
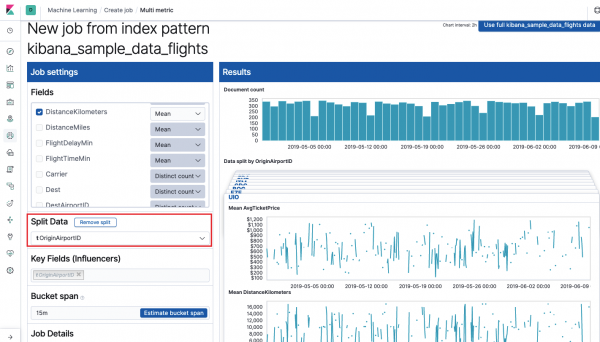
Field Mga Key Field (Mga Influencer) direktang nakakaapekto sa mga nakitang anomalya. Bilang default, palaging mayroong kahit isang value dito, at maaari kang magdagdag ng mga karagdagang halaga. Isasaalang-alang ng algorithm ang impluwensya ng mga field na ito kapag sinusuri at ipinapakita ang pinaka "maimpluwensyang" mga halaga.
Pagkatapos ng paglunsad, may lalabas na tulad nito sa interface ng Kibana.
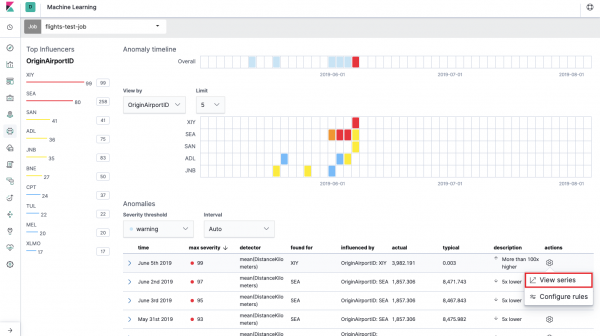
Ito ang tinatawag na mapa ng init ng mga anomalya para sa bawat halaga ng field OriginAirportID, na ipinahiwatig namin sa Hatiin ang Data. Tulad ng Single Sukatan, ang kulay ay nagpapahiwatig ng antas ng abnormal na paglihis. Maginhawang gumawa ng katulad na pagsusuri, halimbawa, sa mga workstation upang subaybayan ang mga may kahina-hinalang malaking bilang ng mga pahintulot, atbp. Nagsulat na kami , na maaari ding kolektahin at suriin dito.
Sa ibaba ng heat map ay isang listahan ng mga anomalya, mula sa bawat isa ay maaari kang lumipat sa view ng Single Sukatan para sa detalyadong pagsusuri.
Populasyon
Upang maghanap ng mga anomalya sa mga ugnayan sa pagitan ng iba't ibang sukatan, ang Elastic Stack ay may espesyal na pagsusuri sa Populasyon. Sa tulong nito maaari kang maghanap ng mga anomalyang halaga sa pagganap ng isang server kumpara sa iba kapag, halimbawa, ang bilang ng mga kahilingan sa target na sistema ay tumataas.
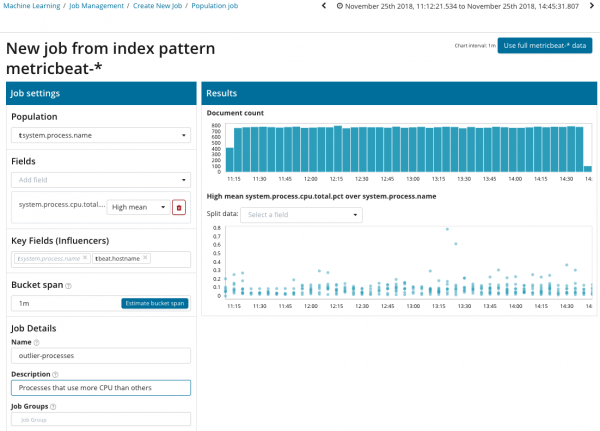
Sa paglalarawang ito, isinasaad ng field ng Populasyon ang halaga kung saan maiuugnay ang nasuri na mga sukatan. Sa kasong ito, ito ang pangalan ng proseso. Bilang resulta, makikita natin kung paano naimpluwensyahan ng processor load ng bawat proseso ang isa't isa.
Pakitandaan na ang graph ng nasuri na data ay naiiba sa mga kaso na may Single Sukatan at Multi Sukatan. Ginawa ito sa Kibana sa pamamagitan ng disenyo para sa isang pinahusay na pang-unawa sa pamamahagi ng mga halaga ng nasuri na data.
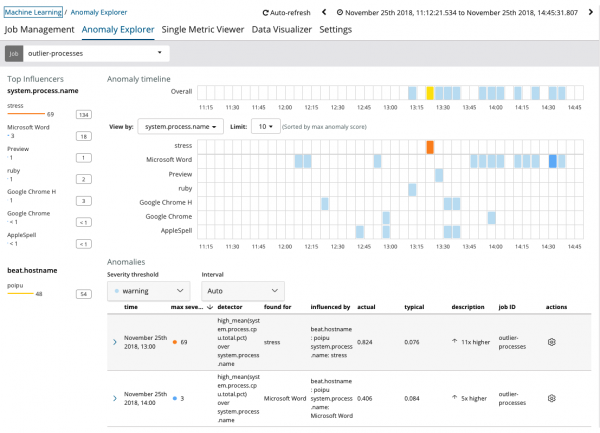
Ipinapakita ng graph na hindi normal ang pag-uugali ng proseso diin (nga pala, nabuo ng isang espesyal na utility) sa server poipu, na nag-impluwensya (o naging influencer) sa paglitaw ng anomalyang ito.
Advanced
Analytics na may fine tuning. Sa Advanced na pagsusuri, lalabas ang mga karagdagang setting sa Kibana. Pagkatapos mag-click sa Advanced na tile sa menu ng paglikha, lilitaw ang window na ito na may mga tab. Tab mga detalye ng trabaho Sinadya namin itong nilaktawan, may mga pangunahing setting na hindi direktang nauugnay sa pag-set up ng pagsusuri.
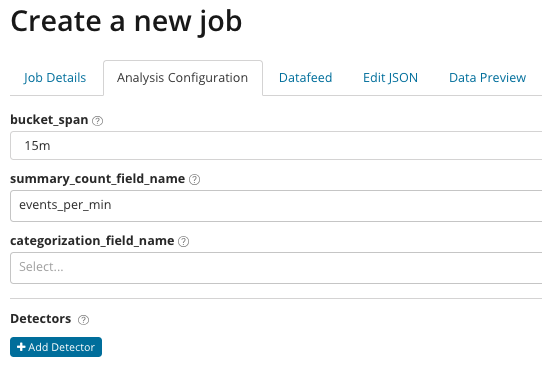
В summary_count_field_name Opsyonal, maaari mong tukuyin ang pangalan ng isang field mula sa mga dokumentong naglalaman ng mga pinagsama-samang halaga. Sa halimbawang ito, ang bilang ng mga kaganapan kada minuto. SA ay nagpapahiwatig ng pangalan at halaga ng isang field mula sa dokumentong naglalaman ng ilang variable na halaga. Gamit ang mask sa field na ito, maaari mong hatiin ang nasuri na data sa mga subset. Bigyang-pansin ang pindutan Magdagdag ng detector sa nakaraang ilustrasyon. Nasa ibaba ang resulta ng pag-click sa button na ito.
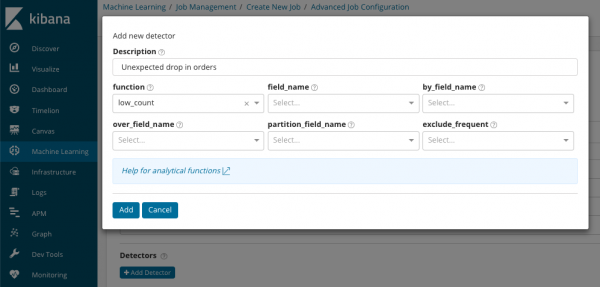
Narito ang isang karagdagang bloke ng mga setting para sa pag-configure ng anomalya detector para sa isang partikular na gawain. Plano naming talakayin ang mga partikular na kaso ng paggamit (lalo na ang mga seguridad) sa mga sumusunod na artikulo. Halimbawa, isa sa mga disassembled na kaso. Ito ay nauugnay sa paghahanap para sa mga bihirang lumalabas na mga halaga at ipinatupad .
Sa larangan tungkulin Maaari kang pumili ng isang partikular na function upang maghanap ng mga anomalya. Maliban sa bihira, may ilang mas kawili-wiling mga function - . Tinutukoy nila ang mga anomalya sa pag-uugali ng mga sukatan sa buong araw o linggo, ayon sa pagkakabanggit. Iba pang mga function ng pagsusuri .
В field_name ay nagpapahiwatig ng larangan ng dokumento kung saan isasagawa ang pagsusuri. Sa pamamagitan ng_field_name ay maaaring gamitin upang paghiwalayin ang mga resulta ng pagsusuri para sa bawat indibidwal na halaga ng field ng dokumento na tinukoy dito. Kung pupunuin mo over_field_name makuha mo ang pagsusuri ng populasyon na tinalakay natin sa itaas. Kung tumukoy ka ng halaga sa partition_field_name, pagkatapos para sa field na ito ng dokumento ay kakalkulahin ang mga hiwalay na baseline para sa bawat halaga (ang halaga ay maaaring, halimbawa, ang pangalan ng server o proseso sa server). SA ibukod_madalas maaaring pumili lahat o wala, na nangangahulugan ng pagbubukod (o pagsasama) ng mga madalas na nagaganap na mga halaga ng field ng dokumento.
Sa artikulong ito, sinubukan naming magbigay ng maikling ideya hangga't maaari tungkol sa mga kakayahan ng machine learning sa Elastic Stack; marami pa ring detalye ang naiwan sa likod ng mga eksena. Sabihin sa amin sa mga komento kung anong mga kaso ang nagawa mong lutasin gamit ang Elastic Stack at para sa anong mga gawain mo ito ginagamit. Para makipag-ugnayan sa amin, maaari kang gumamit ng mga personal na mensahe sa Habré o .
Pinagmulan: www.habr.com
