

Makalenin çevirisi kursun başlamasının arifesinde hazırlanmıştır. .

Kubernetes ile çalışırken bulut maliyetlerinden nasıl tasarruf edilir? Tek bir doğru çözüm yoktur ancak bu makalede, kaynaklarınızı daha etkili bir şekilde yönetmenize ve bulut bilişim maliyetlerinizi azaltmanıza yardımcı olabilecek çeşitli araçlar açıklanmaktadır.
Bu makaleyi AWS için Kubernetes'i düşünerek yazdım, ancak diğer bulut sağlayıcıları için de (neredeyse) tamamen aynı şekilde geçerli olacak. Kümelerinizin zaten yapılandırılmış otomatik ölçeklendirmeye sahip olduğunu varsayıyorum (). Kaynakları kaldırmak ve dağıtımınızın ölçeğini küçültmek, yalnızca çalışan düğüm filonuzu (EC2 bulut sunucuları) da azalttığı takdirde paradan tasarruf etmenizi sağlar.
Bu makale şunları kapsayacaktır:
- kullanılmayan kaynakların temizlenmesi ()
- Çalışma saatleri dışında ölçeklendirmeyi azaltın ()
- yatay otomatik ölçeklendirmeyi (HPA) kullanarak,
- aşırı kaynak rezervasyonunun azaltılması (, VPA)
- Spot örneklerini kullanma
Kullanılmayan kaynakların temizlenmesi
Hızlı tempolu bir ortamda çalışmak harikadır. Teknoloji organizasyonları istiyoruz . Daha hızlı yazılım teslimi aynı zamanda daha fazla PR dağıtımı, önizleme ortamı, prototip ve analiz çözümü anlamına da gelir. Her şey Kubernetes'te konuşlandırılmıştır. Kimin test dağıtımlarını manuel olarak temizlemeye zamanı var? Bir haftalık bir denemeyi silmeyi unutmak kolaydır. Kapatmayı unuttuğumuz bir şey yüzünden bulut faturası artacak:
(Henning Jacobs:
- Jiza:
(alıntılar) Corey Quinn:
Efsane: AWS hesabınız, sahip olduğunuz kullanıcı sayısının bir fonksiyonudur.
Gerçek: AWS puanınız sahip olduğunuz mühendis sayısının bir fonksiyonudur.
Ivan Kurnosov (yanıt olarak):
Gerçek gerçek: AWS puanınız, devre dışı bırakmayı/silmeyi unuttuğunuz şeylerin sayısının bir fonksiyonudur.)
(kube-hademe) kümenizin temizlenmesine yardımcı olur. Kapıcı yapılandırması hem küresel hem de yerel kullanım için esnektir:
- Küme çapındaki kurallar, PR/test dağıtımları için maksimum yaşam süresini (TTL) tanımlayabilir.
- Bireysel kaynaklara hademe/ttl ile açıklama eklenebilir, örneğin 7 gün sonra ani/prototipin otomatik olarak kaldırılması için.
YAML dosyasında genel kurallar tanımlanmıştır. Yolu parametreden geçirilir --rules-file kube-hademede. İşte tüm ad alanlarını kaldırmak için örnek bir kural: -pr- iki gün sonra adına:
- id: cleanup-resources-from-pull-requests
resources:
- namespaces
jmespath: "contains(metadata.name, '-pr-')"
ttl: 2dAşağıdaki örnek, 2020'deki tüm yeni Deployments/StatefulSet'ler için Deployment ve StatefulSet bölmelerindeki uygulama etiketinin kullanımını düzenler, ancak aynı zamanda testlerin bir hafta boyunca bu etiket olmadan yürütülmesine de izin verir:
- id: require-application-label
# удалить deployments и statefulsets без метки "application"
resources:
- deployments
- statefulsets
# см. http://jmespath.org/specification.html
jmespath: "!(spec.template.metadata.labels.application) && metadata.creationTimestamp > '2020-01-01'"
ttl: 7dKube-janitor çalıştıran bir kümede 30 dakika süreyle sınırlı bir demo çalıştırın:
kubectl run nginx-demo --image=nginx
kubectl annotate deploy nginx-demo janitor/ttl=30mArtan maliyetlerin bir başka kaynağı da kalıcı hacimlerdir (AWS EBS). Kubernetes StatefulSet'in silinmesi onun kalıcı birimlerini (PVC - PersistentVolumeClaim) silmez. Kullanılmayan EBS hacimleri kolaylıkla ayda yüzlerce dolarlık maliyete neden olabilir. Kubernetes Janitor'un kullanılmayan PVC'leri temizleme özelliği vardır. Örneğin, bu kural, bir modül tarafından monte edilmeyen ve StatefulSet veya CronJob tarafından referans verilmeyen tüm PVC'leri kaldıracaktır:
# удалить все PVC, которые не смонтированы и на которые не ссылаются StatefulSets
- id: remove-unused-pvcs
resources:
- persistentvolumeclaims
jmespath: "_context.pvc_is_not_mounted && _context.pvc_is_not_referenced"
ttl: 24hKubernetes Janitor, kümenizi temiz tutmanıza ve bulut bilişim maliyetlerinin yavaş yavaş artmasını önlemenize yardımcı olabilir. Dağıtım ve yapılandırma talimatları için aşağıdakileri izleyin .
Çalışma saatleri dışında ölçeklendirmeyi azaltın
Test ve hazırlama sistemleri genellikle yalnızca iş saatlerinde çalışmak üzere gereklidir. Arka ofis/yönetici araçları gibi bazı üretim uygulamaları da yalnızca sınırlı kullanılabilirlik gerektirir ve bir gecede devre dışı bırakılabilir.
(kube-downscaler), kullanıcıların ve operatörlerin çalışma saatleri dışında sistemin ölçeğini küçültmesine olanak tanır. Dağıtımlar ve StatefulSet'ler sıfır kopyaya ölçeklenebilir. CronJob'lar askıya alınabilir. Kubernetes Downscaler, kümenin tamamı, bir veya daha fazla ad alanı veya bireysel kaynaklar için yapılandırılmıştır. "Boş kalma süresini" veya tersine "çalışma süresini" ayarlayabilirsiniz. Örneğin, geceleri ve hafta sonları ölçeklendirmeyi mümkün olduğunca azaltmak için:
image: hjacobs/kube-downscaler:20.4.3
args:
- --interval=30
# не отключать компоненты инфраструктуры
- --exclude-namespaces=kube-system,infra
# не отключать kube-downscaler, а также оставить Postgres Operator, чтобы исключенными БД можно было управлять
- --exclude-deployments=kube-downscaler,postgres-operator
- --default-uptime=Mon-Fri 08:00-20:00 Europe/Berlin
- --include-resources=deployments,statefulsets,stacks,cronjobs
- --deployment-time-annotation=deployment-timeHafta sonları küme çalışan düğümlerini ölçeklendirmeye yönelik bir grafik aşağıda verilmiştir:
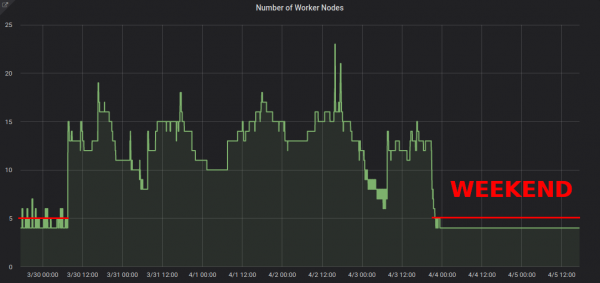
Ölçeklendirmeyi ~13'ten 4'e düşürmek, AWS faturanızda kesinlikle gözle görülür bir fark yaratacaktır.
Peki ya kümenin "kapalı kalma süresi" sırasında çalışmam gerekirse? Belirli dağıtımlar, ölçek küçültücü/hariç tut: doğru ek açıklaması eklenerek kalıcı olarak ölçeklendirmenin dışında bırakılabilir. Dağıtımlar, YYYY-AA-GG SS:DD (UTC) biçiminde mutlak bir zaman damgasına sahip küçültücü/hariç tut ek açıklaması kullanılarak geçici olarak hariç tutulabilir. Gerekirse ek açıklamaya sahip bir bölme dağıtılarak kümenin tamamı küçültülebilir downscaler/force-uptimeörneğin nginx'i boş başlatarak:
kubectl run scale-up --image=nginx
kubectl annotate deploy scale-up janitor/ttl=1h # удалить развертывание через час
kubectl annotate pod $(kubectl get pod -l run=scale-up -o jsonpath="{.items[0].metadata.name}") downscaler/force-uptime=trueBkz Dağıtım talimatları ve ek seçeneklerle ilgileniyorsanız.
Yatay otomatik ölçeklendirmeyi kullan
Birçok uygulama/hizmet dinamik bir yükleme düzeniyle uğraşır: bazen modülleri boşta kalır, bazen de tam kapasiteyle çalışır. Maksimum pik yük ile başa çıkmak için kalıcı bir bölme filosunu çalıştırmak ekonomik değildir. Kubernetes, bir kaynak genelinde yatay otomatik ölçeklendirmeyi destekler (HPA). CPU kullanımı genellikle ölçeklendirme için iyi bir göstergedir:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: my-app
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: my-app
minReplicas: 3
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
averageUtilization: 100
type: UtilizationZalando, ölçeklendirmeye yönelik özel metrikleri kolayca bağlamak için bir bileşen oluşturdu: (kube-metrics-adapter), bölmelerin yatay otomatik ölçeklendirilmesi için özel ve harici ölçümleri toplayıp sunabilen Kubernetes'e yönelik genel bir ölçüm bağdaştırıcısıdır. Prometheus metriklerine, SQS kuyruklarına ve diğer ayarlara dayalı ölçeklendirmeyi destekler. Örneğin, dağıtımınızı uygulamanın kendisi tarafından /metrics'te JSON olarak temsil edilen özel bir metriğe ölçeklendirmek için şunu kullanın:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: myapp-hpa
annotations:
# metric-config.<metricType>.<metricName>.<collectorName>/<configKey>
metric-config.pods.requests-per-second.json-path/json-key: "$.http_server.rps"
metric-config.pods.requests-per-second.json-path/path: /metrics
metric-config.pods.requests-per-second.json-path/port: "9090"
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: myapp
minReplicas: 1
maxReplicas: 10
metrics:
- type: Pods
pods:
metric:
name: requests-per-second
target:
averageValue: 1k
type: AverageValueHPA ile yatay otomatik ölçeklendirmeyi yapılandırmak, durum bilgisi olmayan hizmetlerin verimliliğini artırmaya yönelik varsayılan eylemlerden biri olmalıdır. Spotify'ın HPA'ya yönelik deneyimlerini ve önerilerini içeren bir sunumu var: .
Kaynak fazla rezervasyonunu azaltın
Kubernetes iş yükleri, CPU/bellek ihtiyaçlarını "kaynak istekleri" aracılığıyla belirler. CPU kaynakları sanal çekirdeklerde veya daha yaygın olarak "miliçekirdek" cinsinden ölçülür; örneğin 500 m, %50 vCPU anlamına gelir. Bellek kaynakları bayt cinsinden ölçülür ve 500 megabayt anlamına gelen 500Mi gibi yaygın son ekler kullanılabilir. Kaynak istekleri, çalışan düğümlerdeki kapasiteyi "kilitler"; bu, 1000 vCPU'lu bir düğümde 4 m CPU isteği olan bir bölmenin, diğer bölmeler için yalnızca 3 vCPU'yu kullanılabilir bırakacağı anlamına gelir.
Gevşeklik (fazla rezerv) talep edilen kaynaklar ile fiili kullanım arasındaki farktır. Örneğin, 2 GiB bellek isteyen ancak yalnızca 200 MiB kullanan bir bölme, ~1,8 GiB "fazla" belleğe sahiptir. Fazlalık paraya mal olur. Kabaca 1 GiB yedek belleğin aylık maliyetinin ~10$ olduğu tahmin edilebilir.
(kube-resource-report) fazla rezervleri görüntüler ve tasarruf potansiyelini belirlemenize yardımcı olabilir:
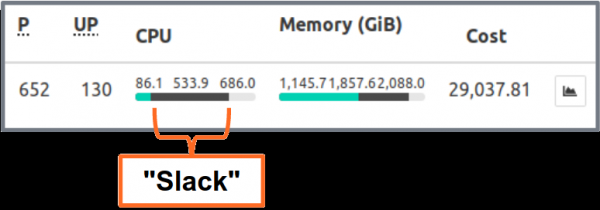
uygulama ve komut tarafından toplanan fazlalığı gösterir. Bu, kaynak taleplerinin azaltılabileceği yerleri bulmanızı sağlar. Oluşturulan HTML raporu yalnızca kaynak kullanımının anlık görüntüsünü sağlar. Yeterli kaynak isteklerini belirlemek için zaman içindeki CPU/bellek kullanımına bakmalısınız. İşte "tipik" CPU ağırlıklı bir hizmet için bir Grafana grafiği: tüm bölmeler, istenen 3 CPU çekirdeğinden önemli ölçüde daha azını kullanıyor:
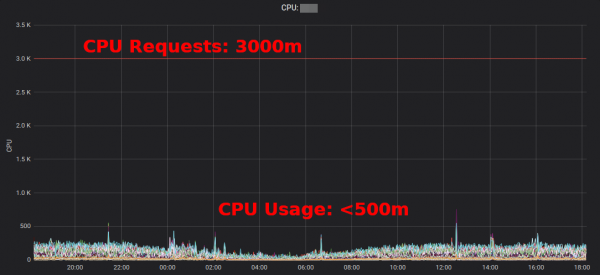
CPU isteğinin 3000m'den ~400m'ye düşürülmesi, diğer iş yükleri için kaynakların serbest kalmasını sağlar ve kümenin daha küçük olmasına olanak tanır.
"EC2 bulut sunucularının ortalama CPU kullanımı genellikle tek haneli yüzde aralığında seyrediyor." . EC2 için iken YAML dosyasındaki bazı Kubernetes kaynak sorgularını değiştirmek kolaydır ve büyük tasarruflar sağlayabilir.
Peki insanların YAML dosyalarındaki değerleri değiştirmesini gerçekten istiyor muyuz? Hayır, makineler bunu çok daha iyi yapabilir! Kubernet'ler (VPA) tam da bunu yapar: kaynak isteklerini ve kısıtlamalarını iş yüküne göre uyarlar. VPA tarafından zaman içinde uyarlanan Prometheus CPU isteklerinin (ince mavi çizgi) örnek grafiğini burada bulabilirsiniz:
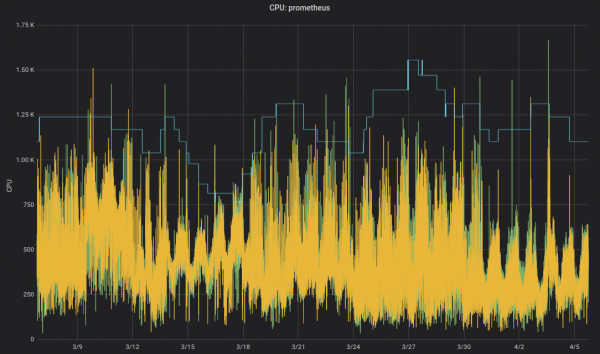
Altyapı bileşenleri için. Kritik olmayan uygulamalar da VPA'yı kullanabilir.
Fairwind'den, bir ad alanındaki her dağıtım için bir VPA oluşturan ve ardından kontrol panelinde bir VPA önerisi görüntüleyen bir araçtır. Geliştiricilerin uygulamaları için doğru CPU/bellek isteklerini ayarlamalarına yardımcı olabilir:
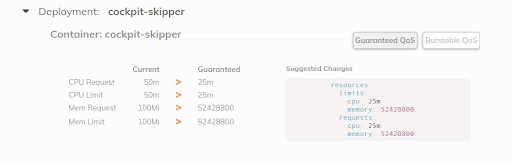
küçük yazdım 2019'da ve yakın zamanda .
EC2 Spot Bulut Sunucularını Kullanma
Son olarak, Spot bulut sunucularının Kubernetes çalışan düğümleri olarak kullanılmasıyla AWS EC2 maliyetleri azaltılabilir . Spot bulut sunucuları, İsteğe Bağlı fiyatlara kıyasla %90'a varan indirimlerle sunulmaktadır. Kubernetes'i EC2 Spot'ta çalıştırmak iyi bir kombinasyondur: Daha yüksek kullanılabilirlik için birkaç farklı bulut sunucusu türü belirtmeniz gerekir; bu, aynı veya daha düşük fiyata daha büyük bir düğüm alabileceğiniz ve artan kapasitenin konteynerli Kubernetes iş yükleri tarafından kullanılabileceği anlamına gelir.
Kubernetes EC2 Spot'ta nasıl çalıştırılır? Birkaç seçenek vardır: SpotInst gibi bir üçüncü taraf hizmeti kullanın (artık adı "Spot", nedenini bana sormayın) veya kümenize bir Spot AutoScalingGroup (ASG) ekleyin. Örneğin, burada birden fazla örnek türüne sahip "kapasite açısından optimize edilmiş" bir Spot ASG için CloudFormation pasajı verilmiştir:
MySpotAutoScalingGroup:
Properties:
HealthCheckGracePeriod: 300
HealthCheckType: EC2
MixedInstancesPolicy:
InstancesDistribution:
OnDemandPercentageAboveBaseCapacity: 0
SpotAllocationStrategy: capacity-optimized
LaunchTemplate:
LaunchTemplateSpecification:
LaunchTemplateId: !Ref LaunchTemplate
Version: !GetAtt LaunchTemplate.LatestVersionNumber
Overrides:
- InstanceType: "m4.2xlarge"
- InstanceType: "m4.4xlarge"
- InstanceType: "m5.2xlarge"
- InstanceType: "m5.4xlarge"
- InstanceType: "r4.2xlarge"
- InstanceType: "r4.4xlarge"
LaunchTemplate:
LaunchTemplateId: !Ref LaunchTemplate
Version: !GetAtt LaunchTemplate.LatestVersionNumber
MinSize: 0
MaxSize: 100
Tags:
- Key: k8s.io/cluster-autoscaler/node-template/label/aws.amazon.com/spot
PropagateAtLaunch: true
Value: "true"Spot'u Kubernetes ile kullanmaya ilişkin bazı notlar:
- Örneğin, örnek durdurulduğunda düğümü birleştirerek Spot sonlandırmaları halletmeniz gerekir
- Zalando'nun kullandığı Düğüm havuzu öncelikleriyle resmi küme otomatik ölçeklendirmesi
- Nokta düğümleri Spot'ta çalıştırılacak iş yüklerinin "kayıtlarını" kabul edin
Özet
Umarım sunulan araçlardan bazılarını bulut faturanızı azaltmada faydalı bulursunuz. Makalenin içeriğinin çoğunu şu adreste de bulabilirsiniz: .
Kubernetes'te bulut maliyetlerinden tasarruf etmek için en iyi uygulamalarınız nelerdir? Lütfen bana bildirin .
Aslında, ayrılmış sistem kaynakları nedeniyle düğümün verimi azaldığı için 3'ten az vCPU kullanılabilir durumda kalacaktır. Kubernetes, fiziksel düğüm kapasitesi ile "tedarik edilen" kaynaklar arasında ayrım yapar ().
Hesaplama örneği: 5 GiB belleğe sahip bir m8.large bulut sunucusu aylık ~84 ABD dolarıdır (eu-central-1, On-Demand), yani. 1/8 düğümün engellenmesi ayda yaklaşık ~10$'dır.
EC2 faturanızı azaltmanın Rezerve Edilmiş Bulut Sunucuları, Tasarruf Planı vb. gibi daha birçok yolu vardır. Bu konulara burada değinmeyeceğim ancak bunları kesinlikle incelemelisiniz!
Kaynak: habr.com
