


Merhaba Habr.
Son zamanlarda, ben Ekip olarak garantili teslimata yaklaşmak için Kafka Üreticisi ve Tüketicisi için en sık hangi parametreleri kullandığımız hakkında. Bu yazımda Kafka'dan alınan bir olayın dış sistemin geçici olarak kullanılamaması sonucu yeniden işlenmesini nasıl düzenlediğimizi anlatmak istiyorum.
Modern uygulamalar çok karmaşık bir ortamda çalışır. Modern bir teknoloji yığınına sarılmış, Kubernetes veya OpenShift gibi bir orkestratör tarafından yönetilen bir Docker görüntüsünde çalışan ve fiziksel ve sanal yönlendiriciler zinciri aracılığıyla diğer uygulamalarla veya kurumsal çözümlerle iletişim kuran iş mantığı. Böyle bir ortamda bir şeyler her zaman bozulabilir, dolayısıyla harici sistemlerden birinin kullanılamaması durumunda olayların yeniden işlenmesi iş süreçlerimizin önemli bir parçasıdır.
Kafka'dan önce nasıldı?
Projenin başlarında eşzamansız mesaj teslimi için IBM MQ'yu kullandık. Hizmetin çalışması sırasında herhangi bir hata meydana gelirse, alınan mesaj daha fazla manuel ayrıştırma için bir ölü mektup kuyruğuna (DLQ) yerleştirilebilir. DLQ, gelen kuyruğun yanında oluşturuldu, mesaj IBM MQ'nun içine aktarıldı.
Hata geçiciyse ve bunu belirleyebiliyorsak (örneğin, bir HTTP çağrısında bir ResourceAccessException veya bir MongoDb isteğinde bir MongoTimeoutException varsa), yeniden deneme stratejisi etkili olur. Uygulamanın dallanma mantığından bağımsız olarak, orijinal mesaj ya gecikmeli gönderim için sistem kuyruğuna ya da mesajların yeniden gönderilmesi için uzun zaman önce yapılmış ayrı bir uygulamaya taşınıyordu. Bu, mesaj başlığında gecikme aralığına veya uygulama düzeyindeki stratejinin sonuna bağlanan bir yeniden gönderme numarasını içerir. Stratejinin sonuna ulaştıysak ancak harici sistem hala kullanılamıyorsa, mesaj manuel ayrıştırma için DLQ'ya yerleştirilecektir.
Çözüm araması
, aşağıdakileri bulabilirsiniz . Kısaca her gecikme aralığı için bir konu oluşturularak yanda mesajları gereken gecikmeyle okuyacak Tüketici uygulamalarının hayata geçirilmesi öneriliyor.
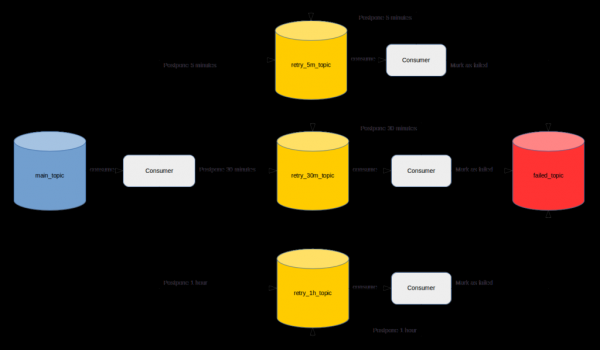
Çok sayıda olumlu eleştiriye rağmen bana tamamen başarılı görünmüyor. Her şeyden önce, geliştiricinin iş gereksinimlerini uygulamanın yanı sıra açıklanan mekanizmayı uygulamaya çok zaman harcaması gerekeceği için.
Ayrıca Kafka kümesinde erişim kontrolü etkinleştirilmişse konuları oluşturmak ve bunlara gerekli erişimi sağlamak için biraz zaman harcamanız gerekecektir. Buna ek olarak, mesajların yeniden gönderilmesi ve kaybolmaması için yeniden deneme konularının her biri için doğru residence.ms parametresini seçmeniz gerekecektir. Uygulamanın ve erişim talebinin mevcut veya yeni her hizmet için tekrarlanması gerekecektir.
Şimdi genel olarak yayların ve özel olarak da yay-kafka'nın mesajın yeniden işlenmesi için bize hangi mekanizmaları sağladığını görelim. Spring-kafka'nın, farklı BackOffPolicies'i yönetmek için soyutlamalar sağlayan yay yeniden denemesine geçişli bir bağımlılığı vardır. Bu oldukça esnek bir araçtır ancak önemli dezavantajı, mesajların yeniden gönderilmek üzere uygulama belleğinde saklanmasıdır. Bu, bir güncelleme veya operasyonel hata nedeniyle uygulamanın yeniden başlatılmasının, yeniden işlenmeyi bekleyen tüm mesajların kaybolmasıyla sonuçlanacağı anlamına gelir. Bu nokta sistemimiz açısından kritik olduğu için üzerinde daha fazla durmadık.
spring-kafka'nın kendisi ContainerAwareErrorHandler'ın çeşitli uygulamalarını sağlar, örneğin , hata durumunda ofseti değiştirmeden mesajı daha sonra işleyebilirsiniz. Spring-kafka 2.3 sürümünden itibaren BackOffPolicy'yi ayarlamak mümkün hale geldi.
Bu yaklaşım, yeniden işlenen mesajların uygulama yeniden başlatıldığında hayatta kalmasına izin verir, ancak hala bir DLQ mekanizması yoktur. DLQ'ya ihtiyaç duyulmayacağına iyimser bir şekilde inanarak bu seçeneği 2019'un başında seçtik (şanslıydık ve uygulamayı böyle bir yeniden işleme sistemiyle birkaç ay çalıştırdıktan sonra aslında buna ihtiyacımız yoktu). Geçici hatalar SeekToCurrentErrorHandler'ın tetiklenmesine neden oldu. Kalan hatalar günlüğe yazdırıldı, bu da bir sapmaya yol açtı ve işleme bir sonraki mesajla devam edildi.
Son karar
SeekToCurrentErrorHandler'ı temel alan uygulama, mesajları yeniden göndermek için kendi mekanizmamızı geliştirmemizi sağladı.
Öncelikle mevcut tecrübeyi kullanıp uygulama mantığına bağlı olarak genişletmek istedik. Doğrusal bir mantık uygulaması için, yeniden deneme stratejisi tarafından belirlenen kısa bir süre boyunca yeni mesajları okumayı durdurmak en uygunudur. Diğer uygulamalar için yeniden deneme stratejisini uygulayacak tek bir noktaya sahip olmak istedim. Ayrıca bu tek noktanın her iki yaklaşım için de DLQ işlevselliğine sahip olması gerekir.
Yeniden deneme stratejisinin kendisi, geçici bir hata oluştuğunda bir sonraki aralığın alınmasından sorumlu olan uygulamada saklanmalıdır.
Doğrusal Mantık Uygulaması İçin Tüketiciyi Durdurmak
Spring-kafka ile çalışırken Tüketiciyi durduracak kod şöyle görünebilir:
public void pauseListenerContainer(MessageListenerContainer listenerContainer,
Instant retryAt) {
if (nonNull(retryAt) && listenerContainer.isRunning()) {
listenerContainer.stop();
taskScheduler.schedule(() -> listenerContainer.start(), retryAt);
return;
}
// to DLQ
}Örnekte retryAt, eğer hala çalışıyorsa, MesajListenerContainer'ı yeniden başlatma zamanıdır. Yeniden başlatma, uygulaması yine bahar tarafından sağlanan TaskScheduler'da başlatılan ayrı bir iş parçacığında gerçekleşecektir.
retryAt değerini şu şekilde buluyoruz:
- Tekrar arama sayacının değeri aranır.
- Sayaç değerine bağlı olarak yeniden deneme stratejisindeki mevcut gecikme aralığı aranır. Strateji uygulamanın kendisinde bildirildi; depolamak için JSON formatını seçtik.
- JSON dizisinde bulunan aralık, işlemin tekrarlanması gereken saniye sayısını içerir. Bu saniye sayısı, retryAt değerini oluşturmak için geçerli zamana eklenir.
- Aralık bulunamazsa retryAt'ın değeri null olur ve mesaj manuel ayrıştırma için DLQ'ya gönderilir.
Bu yaklaşımla geriye kalan tek şey, o anda işlenmekte olan her mesaj için tekrarlanan çağrı sayısını örneğin uygulama belleğine kaydetmektir. Doğrusal bir mantık uygulaması işlemi bir bütün olarak ele alamayacağından, yeniden deneme sayısını bellekte tutmak bu yaklaşım için kritik değildir. Yaylı yeniden denemeden farklı olarak, uygulamanın yeniden başlatılması tüm mesajların yeniden işlenmesi için kaybolmasına neden olmaz, yalnızca stratejiyi yeniden başlatır.
Bu yaklaşım, çok ağır yük nedeniyle kullanılamayan harici sistem yükünün hafifletilmesine yardımcı olur. Yani yeniden işlemenin yanı sıra desenin uygulanmasını da sağladık. .
Bizim durumumuzda hata eşiği yalnızca 1'dir ve geçici ağ kesintileri nedeniyle sistemin kapalı kalma süresini en aza indirmek için küçük gecikme aralıklarına sahip çok ayrıntılı bir yeniden deneme stratejisi kullanıyoruz. Bu, tüm grup uygulamaları için uygun olmayabilir, dolayısıyla hata eşiği ile aralık değeri arasındaki ilişki sistemin özelliklerine göre seçilmelidir.
Belirleyici olmayan mantığa sahip uygulamalardan gelen mesajları işlemek için ayrı bir uygulama
Aşağıda, RETRY_AT zamanına ulaşıldığında DESTINATION konusuna yeniden gönderilecek olan böyle bir uygulamaya (Retryer) mesaj gönderen bir kod örneği verilmiştir:
public <K, V> void retry(ConsumerRecord<K, V> record, String retryToTopic,
Instant retryAt, String counter, String groupId, Exception e) {
Headers headers = ofNullable(record.headers()).orElse(new RecordHeaders());
List<Header> arrayOfHeaders =
new ArrayList<>(Arrays.asList(headers.toArray()));
updateHeader(arrayOfHeaders, GROUP_ID, groupId::getBytes);
updateHeader(arrayOfHeaders, DESTINATION, retryToTopic::getBytes);
updateHeader(arrayOfHeaders, ORIGINAL_PARTITION,
() -> Integer.toString(record.partition()).getBytes());
if (nonNull(retryAt)) {
updateHeader(arrayOfHeaders, COUNTER, counter::getBytes);
updateHeader(arrayOfHeaders, SEND_TO, "retry"::getBytes);
updateHeader(arrayOfHeaders, RETRY_AT, retryAt.toString()::getBytes);
} else {
updateHeader(arrayOfHeaders, REASON,
ExceptionUtils.getStackTrace(e)::getBytes);
updateHeader(arrayOfHeaders, SEND_TO, "backout"::getBytes);
}
ProducerRecord<K, V> messageToSend =
new ProducerRecord<>(retryTopic, null, null, record.key(), record.value(), arrayOfHeaders);
kafkaTemplate.send(messageToSend);
}Örnek, başlıklarda çok fazla bilginin iletildiğini göstermektedir. RETRY_AT değeri, Tüketici durağı aracılığıyla yeniden deneme mekanizmasıyla aynı şekilde bulunur. DESTINATION ve RETRY_AT'ye ek olarak şunu da geçiyoruz:
- GROUP_ID, manuel analiz ve basitleştirilmiş arama için mesajları gruplandırıyoruz.
- ORIGINAL_PARTITION, aynı Tüketiciyi yeniden işlenmek üzere tutmaya çalışmak için. Bu parametre null olabilir, bu durumda yeni bölüm orijinal mesajın Record.key() anahtarı kullanılarak elde edilecektir.
- Yeniden deneme stratejisini takip etmek için COUNTER değeri güncellendi.
- SEND_TO, mesajın RETRY_AT'ye ulaşıldığında yeniden işlenmek üzere gönderilip gönderilmediğini veya DLQ'ya yerleştirilip gönderilmediğini gösteren bir sabittir.
- NEDEN - mesaj işlemenin kesintiye uğramasının nedeni.
Retryer, PostgreSQL'de yeniden göndermek ve manuel ayrıştırmak için mesajları saklar. Bir zamanlayıcı, RETRY_AT içeren mesajları bulan ve bunları, Record.key() anahtarıyla DESTINATION konusunun ORIGINAL_PARTITION bölümüne geri gönderen bir görevi başlatır.
Mesajlar gönderildikten sonra PostgreSQL'den silinir. İletilerin manuel olarak ayrıştırılması, REST API aracılığıyla Retryer ile etkileşime giren basit bir kullanıcı arayüzünde gerçekleşir. Ana özellikleri, mesajları DLQ'dan yeniden göndermek veya silmek, hata bilgilerini görüntülemek ve mesajları örneğin hata adına göre aramaktır.
Clusterlarımızda erişim kontrolü etkin olduğundan, Retryer'ın dinlediği konuya ek olarak erişim talebinde bulunmak ve Retryer'ın DESTINATION konusuna yazmasına izin vermek gerekir. Bu sakıncalıdır, ancak aralıklı konu yaklaşımının aksine, bunu yönetmek için tam teşekküllü bir DLQ'ya ve kullanıcı arayüzüne sahibiz.
Gelen bir konunun, uygulamaları farklı mantık uygulayan birkaç farklı tüketici grubu tarafından okunduğu durumlar vardır. Bu uygulamalardan biri için bir mesajın Retryer aracılığıyla yeniden işlenmesi, diğerinde bir kopyanın oluşmasına neden olacaktır. Bundan korunmak için yeniden işleme için ayrı bir konu oluşturuyoruz. Gelen ve tekrar denenen konular aynı Tüketici tarafından herhangi bir kısıtlama olmaksızın okunabilir.
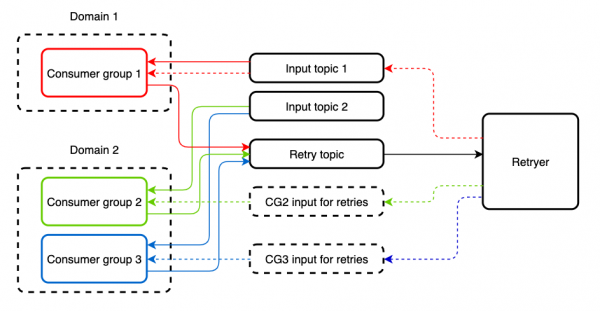
Varsayılan olarak bu yaklaşım devre kesici işlevselliği sağlamaz ancak kullanılarak uygulamaya eklenebilir. veya yeni , dış hizmetlerin çağrıldığı yerleri uygun soyutlamalara sararak. Ayrıca, bir strateji seçmek de mümkün hale gelir. aynı zamanda yararlı olabilecek bir desen. Örneğin, spring-cloud-netflix'te bu bir iş parçacığı havuzu veya bir semafor olabilir.
Aviator apk
Sonuç olarak, herhangi bir harici sistemin geçici olarak kullanılamaması durumunda mesaj işlemeyi tekrarlamamıza olanak tanıyan ayrı bir uygulamamız var.
Uygulamanın ana avantajlarından biri, aynı Kafka kümesi üzerinde çalışan harici sistemler tarafından, kendi taraflarında önemli değişiklikler yapılmadan kullanılabilmesidir! Böyle bir uygulamanın yalnızca yeniden deneme konusuna erişmesi, birkaç Kafka başlığını doldurması ve Yeniden Denemeye bir mesaj göndermesi gerekecektir. Herhangi bir ek altyapı yükseltmeye gerek yoktur. Uygulamadan Retryer'a ve geri aktarılan mesaj sayısını azaltmak için uygulamaları doğrusal mantıkla tanımladık ve Consumer stop üzerinden yeniden işledik.
Kaynak: habr.com
