

У міру вичерпання адрес IPv4, багато операторів зв'язку зіткнулися з необхідністю організовувати доступ своїх клієнтів в мережу за допомогою трансляції адрес. У цій статті я розповім, як можна отримати продуктивність рівня Carrier Grade NAT на серверах commodity.
Трохи історії
Тема вичерпання адресного простору IPv4 не нова. У якийсь момент у RIPE з'явилися черги очікування (waiting list), потім виникли біржі, на яких торгували блоками адрес і укладалися угоди щодо їх оренди. Поступово оператори зв'язку почали надавати послуги доступу до Інтернету за допомогою трансляції адрес та портів. Хтось не встиг отримати достатньо адрес, щоб видати «білу» адресу кожному абоненту, а хтось почав економити кошти, відмовившись від купівлі адрес на вторинному ринку. Виробники мережного устаткування підтримали цю ідею, т.к. цей функціонал зазвичай потребує додаткових модулів розширення чи ліцензій. Наприклад, у Juniper у лінійці маршрутизаторів MX (крім останніх MX104 та MX204) виконувати NAPT можна на окремій сервісній карті MS-MIC, на Cisco ASR1k потрібна ліцензія СGN license, на Cisco ASR9k – окремий модуль A9K-ISM-100 та ліцензія A9K-CG -LIC до нього. Загалом задоволення коштує чималих грошей.
IP-таблиці
Завдання виконання NAT не вимагає спеціалізованих обчислювальних ресурсів, її може вирішувати процесори загального призначення, які встановлені, наприклад, у будь-якому домашньому роутері. У масштабах оператора зв'язку це завдання можна вирішити, використовуючи commodity сервери під керуванням FreeBSD (ipfw/pf) або GNU/Linux (iptables). Розглядати FreeBSD нічого очікувати, т.к. я досить давно відмовився від використання цієї ОС, тому зупинимося на GNU/Linux.
Включити трансляцію адрес зовсім не складно. Для початку необхідно прописати правило iptables в таблицю nat:
iptables -t nat -A POSTROUTING -s 100.64.0.0/10 -j SNAT --to <pool_start_addr>-<pool_end_addr> --persistent
Операційна система завантажить модуль nf_conntrack, який стежитиме за всіма активними з'єднаннями та виконуватиме необхідні перетворення. Тут є кілька тонкощів. По-перше, оскільки йдеться про NAT у масштабах оператора зв'язку, то необхідно підкрутити timeout'и, тому що зі значеннями за умовчанням розмір таблиці трансляцій досить швидко зросте до катастрофічних значень. Нижче наведено приклад налаштувань, які я використовував на своїх серверах:
net.ipv4.ip_forward = 1
net.ipv4.ip_local_port_range = 8192 65535
net.netfilter.nf_conntrack_generic_timeout = 300
net.netfilter.nf_conntrack_tcp_timeout_syn_sent = 60
net.netfilter.nf_conntrack_tcp_timeout_syn_recv = 60
net.netfilter.nf_conntrack_tcp_timeout_established = 600
net.netfilter.nf_conntrack_tcp_timeout_fin_wait = 60
net.netfilter.nf_conntrack_tcp_timeout_close_wait = 45
net.netfilter.nf_conntrack_tcp_timeout_last_ack = 30
net.netfilter.nf_conntrack_tcp_timeout_time_wait = 120
net.netfilter.nf_conntrack_tcp_timeout_close = 10
net.netfilter.nf_conntrack_tcp_timeout_max_retrans = 300
net.netfilter.nf_conntrack_tcp_timeout_unacknowledged = 300
net.netfilter.nf_conntrack_udp_timeout = 30
net.netfilter.nf_conntrack_udp_timeout_stream = 60
net.netfilter.nf_conntrack_icmpv6_timeout = 30
net.netfilter.nf_conntrack_icmp_timeout = 30
net.netfilter.nf_conntrack_events_retry_timeout = 15
net.netfilter.nf_conntrack_checksum=0
І по-друге, оскільки за умовчанням розмір таблиці трансляцій не розрахований на роботу в умовах оператора зв'язку, його необхідно збільшити:
net.netfilter.nf_conntrack_max = 3145728
Також необхідно збільшити кількість buckets для хеш-таблиці, що зберігає всі трансляції (це опція модуля nf_conntrack):
options nf_conntrack hashsize=1572864
Після цих нехитрих маніпуляцій виходить конструкція, що цілком працює, яка може транслювати велику кількість клієнтських адрес в пул зовнішніх. Однак продуктивність цього рішення залишає бажати кращого. У перших спробах використання GNU/Linux для NAT (приблизно 2013) я зміг отримати продуктивність близько 7Gbit/s при 0.8Mpps на один сервер (Xeon E5-1650v2). З того часу в мережевому стеку ядра GNU/Linux було зроблено багато різних оптимізації, продуктивність одного сервера на тому ж залізі зросла практично до 18-19 Gbit/s при 1.8-1.9 Mpps (це були граничні значення), але потреба в обсязі трафіку, що обробляється одним сервером, зростала набагато швидше. У результаті були вироблені схеми балансування навантаження на різні сервери, але все це збільшило складність налаштування, обслуговування та підтримки якості послуг.
NFTтаблиці
Наразі модним напрямком у програмному «перекладанні пакетиків» є використання DPDK та XDP. На цю тему написано купу статей, зроблено багато різних виступів, з'являються комерційні продукти (наприклад, СКАТ від VasExperts). Але в умовах обмежених ресурсів програмістів у операторів зв'язку, пиляти самостійно якесь «поділ» на базі цих фреймворків досить проблематично. Експлуатувати таке рішення надалі буде набагато складніше, зокрема доведеться розробляти інструменти діагностики. Наприклад, штатний tcpdump з DPDK просто так не запрацює, та й пакети, відправлені назад у дроти за допомогою XDP, він не побачить. На тлі всіх розмов про нові технології виведення форвардингу пакетів у user-space непоміченими залишилися и Pablo Neira Ayuso, меінтейнера iptables, для розробки flow offloading на nftables. Давайте розглянемо цей механізм докладніше.
Основна ідея полягає в тому, що якщо роутер пропустив пакети однієї сесії в обидві сторони потоку (TCP сесія перейшла у стан ESTABLISHED), немає необхідності пропускати наступні пакети цієї сесії через всі правила firewall, т.к. всі ці перевірки все одно закінчаться передачею пакету далі в роутинг. Та й власне вибір маршруту виконувати не треба — ми вже знаємо, в який інтерфейс і якому хосту треба переслати пакети в межах цієї сесії. Залишається лише зберегти цю інформацію та використовувати її для маршрутизації на ранній стадії обробки пакета. При виконанні NAT необхідно додатково зберегти інформацію про зміни адрес та портів, перетворених модулем nf_conntrack. Так, звичайно, в цьому випадку перестають працювати різні полісери та інші інформаційно-статистичні правила в iptables, але в рамках завдання окремого NAT або, наприклад, бордера — це не так вже й важливо, тому що сервіси розподілені по пристроях.
Конфігурація
Щоб скористатися цією функцією, нам треба:
- Використовуйте свіже ядро. Незважаючи на те, що сам функціонал з'явився ще в ядрі 4.16, досить довго він був дуже «сирою» та регулярно викликав kernel panic. Стабілізувалося все приблизно у грудні 2019 року, коли вийшли LTS ядра 4.19.90 та 5.4.5.
- Переписати правила iptables у форматі nftables, використовуючи досить свіжу версію nftables. Точно працює у версії 0.9.0
Якщо з першим пунктом все в принципі зрозуміло, головне не забути включити модуль у конфігурацію при збиранні (CONFIG_NFT_FLOW_OFFLOAD=m), другий пункт вимагає пояснень. Правила nftables описуються зовсім не так, як у iptables. розкриває практично всі моменти, також є спеціальні правил з iptables до nftables. Тому я наведу лише приклад налаштування NAT та flow offload. Невелика легенда для прикладу: , - це мережні інтерфейси, через які проходить трафік, реально їх може бути більше двох. , — початкова та кінцева адреса діапазону «білих» адрес.
Конфігурація NAT дуже проста:
#! /usr/sbin/nft -f
table nat {
chain postrouting {
type nat hook postrouting priority 100;
oif <o_if> snat to <pool_addr_start>-<pool_addr_end> persistent
}
}
З flow offload трохи складніше, але цілком зрозуміло:
#! /usr/sbin/nft -f
table inet filter {
flowtable fastnat {
hook ingress priority 0
devices = { <i_if>, <o_if> }
}
chain forward {
type filter hook forward priority 0; policy accept;
ip protocol { tcp , udp } flow offload @fastnat;
}
}
Ось, власне, і все налаштування. Тепер весь TCP/UDP трафік потраплятиме в таблицю fastnat і оброблятиметься набагато швидше.
Результати
Щоб стало зрозуміло, наскільки це «набагато швидше», я докладу скріншот навантаження на два реальні сервери, з однаковою начинкою (Xeon E5-1650v2), однаково налаштованих, що використовують одне ядро Linuxале виконують NAT в iptables (NAT4) і nftables (NAT5).
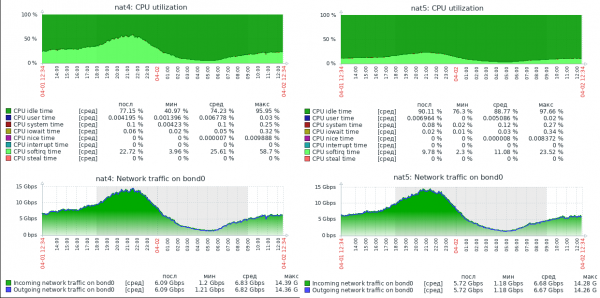
На скріншоті немає графіка пакетів за секунду, але в профілі навантаження цих серверів середній розмір пакета в районі 800 байт, тому значення сягають 1.5Mpps. Як видно, запас продуктивності сервера з nftables величезний. На даний момент цей сервер обробляє до 30Gbit/s при 3Mpps і явно здатний упертися у фізичне обмеження мережі 40Gbps, маючи вільні ресурси CPU.
Сподіваюся, цей матеріал буде корисним мережевим інженерам, які намагаються покращити продуктивність своїх серверів.
Джерело: habr.com
