


3. Варіанти структур під час використання глобалів
Така структура як упорядковане дерево має різні окремі випадки. Розглянемо ті, що мають практичну цінність під час роботи з глобалами.
3.1 Частина 1. Один вузол без гілок
 Глобали можна використовувати не тільки подібно до масиву, але і як звичайні змінні. Наприклад як лічильник:
Глобали можна використовувати не тільки подібно до масиву, але і як звичайні змінні. Наприклад як лічильник:
Set ^counter = 0 ; установка счётчика
Set id=$Increment(^counter) ; атомарное инкрементированиеПри цьому глобал, крім значення, може мати ще й гілки. Одне не виключає другого.
3.2 Частина 2. Одна вершина і безліч гілок
Взагалі це класична key-value база. А якщо як значення ми зберігатимемо кортеж значень, то отримаємо звичайнісіньку таблицю з первинним ключем.
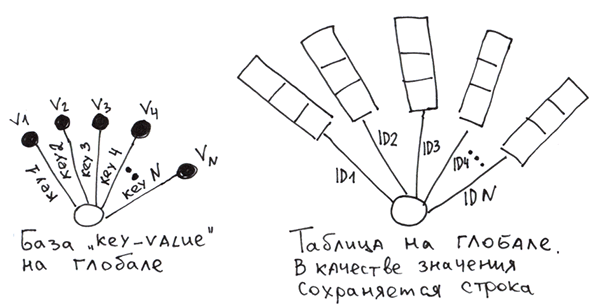
Для реалізації таблиці на глобалах нам доведеться самим формувати рядки із значень колонок, а потім зберігати їх у глобал за первинним ключем. Щоб при зчитуванні можна було розділити рядок знову на колонки можна використовувати:
- символи-розділювачі.
Set ^t(id1) = "col11/col21/col31" Set ^t(id2) = "col12/col22/col32" - жорстку схему, за якою кожне поле займає заздалегідь певну кількість байт. Як і робиться у реляційних БД.
- спеціальну функцію $LB (є в Cache), яка складає рядок із значень.
Set ^t(id1) = $LB("col11", "col21", "col31") Set ^t(id2) = $LB("col12", "col22", "col32")
Що цікаво, не важко на глобалах зробити щось подібне до вторинних індексів у реляційних БД. Назвемо такі структури індексними глобалами. Індексний глобал - це допоміжне дерево для швидкого пошуку по полях, що не є складовими частинами первинного ключа основного глобалу. Для його заповнення та використання потрібно написати додатковий код.
Давайте створимо індексний глобал по першій колонці.
Set ^i("col11", id1) = 1
Set ^i("col12", id2) = 1Тепер для швидкого пошуку інформації по першій колонці ми маємо заглянути в глобал. ^i і знайти первинні ключі (id), що відповідають потрібному значенню першої колонки.
При вставці значення ми можемо одночасно створювати значення і індексні глобали по потрібних полях. А для надійності обернемо все це на транзакцію.
TSTART
Set ^t(id1) = $LB("col11", "col21", "col31")
Set ^i("col11", id1) = 1
TCOMMITПодробиці як зробити на M , .
Працювати такі таблиці будуть також швидко як і традиційних БД (чи навіть швидше), якщо функції вставки/оновлення/видалення рядків написати на COS/M і скомпілювати.Це твердження я перевіряв тестами на масових INSERT та SELECT в одну двоколоночну таблицю, у тому числі з використанням команд TSTART та TCOMMIT (транзакцій).
Більш складні сценарії з конкурентним доступом та паралельними транзакціями не тестував.
Без використання транзакцій швидкість інсертів була мільйоном значень 778 361 вставок/секунду.
При 300 мільйонів значень - 422 141 вставок/секунду.
При використанні транзакцій - 572 вставок/секунду на 082М вставок. Усі операції проводилися зі скомпільованого M-коду.
Жорсткі диски звичайні, не SSD. RAID5 з Write-back. Процесор Phenom II 1100T.
Для аналогічного тестування SQL-бази потрібно написати процедуру, що зберігається, яка в циклі буде робити вставки. При тестуванні MySQL 5.5 (сховище InnoDB) за такою методикою отримував цифри не більше ніж 11К вставок за секунду.
Так, реалізація таблиць на глобалах виглядає складнішою, ніж у реляційних БД. Тому промислові БД на глобалах мають SQL доступ для спрощення роботи з табличними даними.
 Взагалі, якщо схема даних не часто змінюватиметься, швидкість вставки некритична і всю базу можна легко уявити у вигляді нормалізованих таблиць, то простіше працювати саме з SQL, оскільки він забезпечує більш високий рівень абстракції.
Взагалі, якщо схема даних не часто змінюватиметься, швидкість вставки некритична і всю базу можна легко уявити у вигляді нормалізованих таблиць, то простіше працювати саме з SQL, оскільки він забезпечує більш високий рівень абстракції.
 У цьому випадку я хотів показати, що глобали можуть виступати як конструктор для створення інших БД. Як асемблер, яким можна написати інші мови. А ось приклади, як можна створити на глобалах аналоги
У цьому випадку я хотів показати, що глобали можуть виступати як конструктор для створення інших БД. Як асемблер, яким можна написати інші мови. А ось приклади, як можна створити на глобалах аналоги
Якщо потрібно створити якусь нестандартну БД мінімальними зусиллями, варто поглянути у бік глобалів.
3.3 Частка 3. Двохрівневе дерево, у кожного вузла другого рівня фіксована кількість гілок
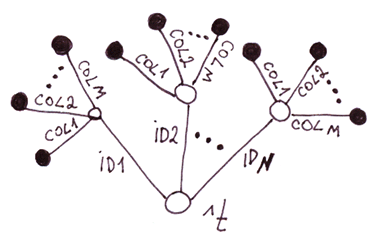 Ви напевно здогадалися: це альтернативна реалізація таблиць на глобалах. Порівняємо цю реалізацію із попередньою.
Ви напевно здогадалися: це альтернативна реалізація таблиць на глобалах. Порівняємо цю реалізацію із попередньою.
Таблиці на дворівневе дерево vs. на однорівневому дереві.
Мінуси
Плюси
- Повільніше на вставку, так як потрібно встановлювати число вузлів, що дорівнює кількості колонок.
- Більше витрати дискового простору. Так як індекси глобалу (в розумінні як індекси у масивів) з назвами колонок займають місце на диску та дублюються для кожного рядка.
- Швидше доступ до значень окремих колонок, тому що не потрібно ширяти рядок. За моїми тестами швидше на 11,5% на 2-х колонках і більше на більшій кількості колонок.
- Простіше змінювати схему даних
- Наочніший код
Висновок: на аматора. Оскільки швидкість — одна з найголовніших переваг глобалів, то майже немає сенсу використовувати цю реалізацію, оскільки вона швидше за все працюватиме не швидше за таблиці на реляційних базах даних.
3.4. Загальний випадок. Дерева та впорядковані дерева
Будь-яка структура даних, яка може бути представлена у вигляді дерева, чудово лягає на глобали.
3.4.1 Об'єкти з подібними об'єктами
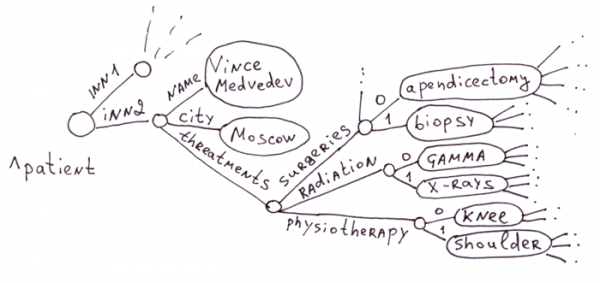
Це сфера традиційного застосування глобалів. У медичній сфері дуже багато захворювань, антибіотиків, симптомів, способів лікування. Створювати кожного пацієнта таблицю з мільйоном полів нераціонально. Тим більше що 99% полів будуть порожніми.
Уявіть SQL БД з таблиць: "пацієнт" ~ 100 000 полів, "Ліки" - 100 000 полів, "Терапія" - 100 000 полів, "Ускладнення" - 100 000 полів і т.д. і т.п. Або можна створити БД з багатьох тисяч таблиць, кожна під певний тип пацієнта (а вони можуть перетинатися!), лікування, ліки, і ще тисячі таблиць для зв'язків між цими таблицями.
Глобали ідеально підійшли для медицини, тому що дозволяють створити для кожного пацієнта точний опис його історії хвороби, різних терапій, дій ліків, у вигляді дерева, не витрачаючи при цьому зайвого дискового простору на порожні колонки, як було б у реляційному випадку.
 На глобалах зручно робити БД із даними про людей, коли важливо накопичити та систематизувати максимум різноманітної інформації про клієнта. Це затребуване в медицині, банківській сфері, маркетингу, архівній справі та інших галузях
На глобалах зручно робити БД із даними про людей, коли важливо накопичити та систематизувати максимум різноманітної інформації про клієнта. Це затребуване в медицині, банківській сфері, маркетингу, архівній справі та інших галузях
.
Безумовно, на SQL теж можна емулювати дерево всього кількома таблицями (, ,,,,,,,,,), проте це суттєво складніше і повільніше працюватиме. По суті довелося б написати глобал, що працює на таблицях і сховати всю роботу з таблицями під шаром абстракції. Неправильно емулювати більш низькорівневу технологію (глобали) засобами більш високорівневої (SQL). Недоцільно.
Не секрет, що зміна схеми даних на гігантських таблицях (ALTER TABLE) може зайняти пристойний час. MySQL, наприклад, робить ALTER TABLE ADD | DROP COLUMN повним копіюванням інформації зі старої до нової таблиці (тестував движки MyISAM, InnoDB). Що може повісити робочу базу із мільярдами записів на дні, якщо не тижня.
 Зміна структури даних, якщо ми використовуємо глобали, нам нічого не варті. У будь-який момент ми можемо додати будь-які необхідні нові властивості до будь-якого об'єкта, на будь-якому рівні ієрархії. Зміни, пов'язані з перейменуванням гілок, можна запускати у фоновому режимі на працюючій БД.
Зміна структури даних, якщо ми використовуємо глобали, нам нічого не варті. У будь-який момент ми можемо додати будь-які необхідні нові властивості до будь-якого об'єкта, на будь-якому рівні ієрархії. Зміни, пов'язані з перейменуванням гілок, можна запускати у фоновому режимі на працюючій БД.
Тому коли йдеться про зберігання об'єктів з величезною кількістю необов'язкових властивостей, глобали — відмінний вибір.
Причому, нагадаю, доступ до будь-якої з властивостей моментальний, тому що в глобалі всі шляхи є B-tree.
Бази даних на глобалах, у випадку, це різновид документно-ориентированных БД, з можливістю зберігання ієрархічної інформації. Тому у сфері зберігання медичних карток із глобалами можуть конкурувати документно-орієнтовані БД. Але все одно це не зовсім теВізьмемо для порівняння, наприклад MongoDB. В цій сфері вона програє глобалам з причин:
- Розмір документа. Одиницею зберігання є текст формату JSON (точніше BSON) максимального обсягу близько 16МБ. Обмеження зроблено спеціально, щоб JSON-база не гальмувала при парсингу, якщо в ній збережуть величезний JSON-документ, а потім звертатимуться до нього полями. У цьому документі має бути зосереджена вся інформація про пацієнта. Ми всі знаємо, якими товстими можуть бути карти пацієнтів. Максимальний розмір карти в 16МБ одразу ставить хрест на пацієнтах, у карту хвороб яких включені файли МРТ, скани ренгенографії та інших досліджень. В одній гілки глобалу можна мати інформацію на гігабайти і терабайти. У принципі, на цьому можна поставити крапку, але я продовжу.
- Час свідомості/зміни/видалення нових властивостей у карті пацієнта. Така БД повинна рахувати в пам'ять всю карту повністю (це великий обсяг!), розпарити BSON, внести/змінити/видалити новий вузол, оновити індекси, запакувати в BSON, зберегти на диск. Глобалу ж достатньо лише звернутися до конкретної якості та зробити з ним маніпуляції.
- Швидкість доступу до окремих властивостей. При безлічі властивостей у документі та його багаторівневій структурі доступ до окремих властивостей буде швидшим за рахунок того, що кожен шлях у глобалі це B-tree. У BSON доведеться лінійно розпарити документ, щоб знайти потрібну властивість.
3.3.2 Асоціативні масиви
Асоціативні масиви (навіть із вкладеними масивами) чудово лягають на глобали. Наприклад, такий масив з PHP відобразиться в першу картинку 3.3.1.
$a = array(
"name" => "Vince Medvedev",
"city" => "Moscow",
"threatments" => array(
"surgeries" => array("apedicectomy", "biopsy"),
"radiation" => array("gamma", "x-rays"),
"physiotherapy" => array("knee", "shoulder")
)
);3.3.3 Ієрархічні документи: XML, JSON
Також легко зберігаються у глобалах. Для зберігання можна розкласти у різний спосіб.
XML
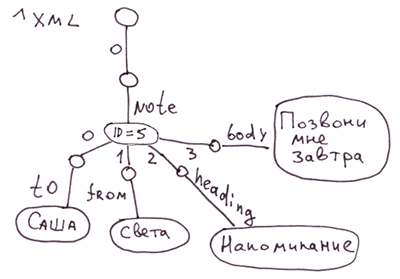
Найпростіший спосіб розкладки XML на глобали, коли у вузлах зберігаємо атрибути тегів. А якщо буде потрібний швидкий доступ до атрибутів тегів, то ми можемо їх винести в окремі гілки.
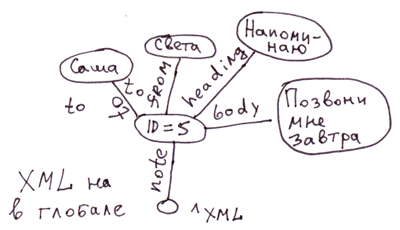
<note id=5>
<to>Вася</to>
<from>Света</from>
<heading>Напоминание</heading>
<body>Позвони мне завтра!</body>
</note>На COS цьому відповідатиме код:
Set ^xml("note")="id=5"
Set ^xml("note","to")="Саша"
Set ^xml("note","from")="Света"
Set ^xml("note","heading")="Напоминание"
Set ^xml("note","body")="Позвони мне завтра!"зауваження: Для XML, JSON, асоціативних масивів можна вигадати багато різних способів відображення на глобалах. В даному випадку ми не відобразили порядок вкладених тегів у note. У глобалі ^xml вкладені теги відображатимуться в алфавітному порядку. Для строго відображення порядку можна використовувати, наприклад, таке відображення:
JSON.
На першій картинці розділу 3.3.1 показано відображення цього JSON-документа:
var document = {
"name": "Vince Medvedev",
"city": "Moscow",
"threatments": {
"surgeries": ["apedicectomy", "biopsy"],
"radiation": ["gamma", "x-rays"],
"physiotherapy": ["knee", "shoulder"]
},
};3.3.4 Однакові структури, пов'язані ієрархічними відносинами
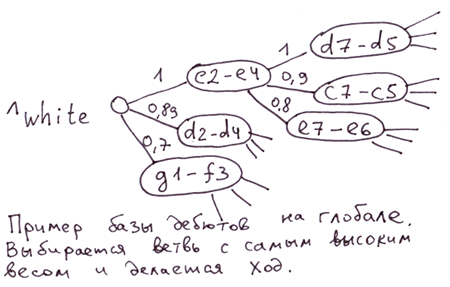
Приклади: структура офісів продажу, розташування людей у МЛМ-структурі, база дебютів у шахах.
Основа дебютів. Можна як значення індексу вузла глобалу використати оцінку сили ходу. Тоді, щоб вибрати найсильніший хід, достатньо буде вибрати гілку з найбільшою вагою. У глобалі всі гілки на кожному рівні будуть відсортовані за силою ходу.
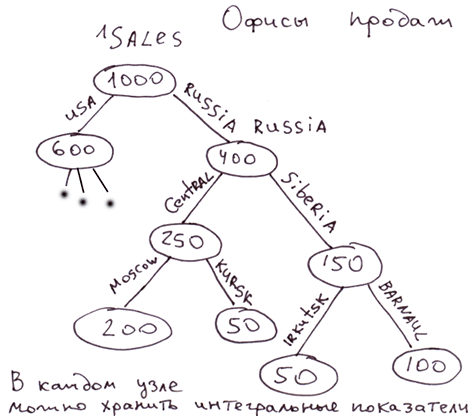
Структура офісів продажів, структура людей у МЛМ. У вузлах можна зберігати якісь кешируючі значення відбивають властивості всього поддерева. Наприклад, обсяг продажів цього піддерева. У будь-який момент ми можемо отримати цифру, яка відображатиме досягнення будь-якої гілки.
4. У яких випадках найвигідніше використовувати глобали
У першій колонці представлені випадки, коли ви отримаєте суттєвий виграш у швидкості при використанні глобалів, а у другій коли спроститься розробка або модель даних.
Швидкість
Зручність обробки/подання даних
- Вставка [з автоматичним сортуванням на кожному рівні], [індексування за головним ключем]
- Видалення піддерев
- Об'єкти з масою вкладених властивостей, до яких потрібен індивідуальний доступ
- Ієрархічна структура з можливістю обходу дочірніх гілок з будь-якої, що навіть не існує
- Обхід піддерев у глибину
- Об'єкти/сутності з величезною кількістю необов'язкових [і/або вкладених] властивостей/сутностей
- Безсхемні дані (schema-less). Коли часто можуть з'являтися нові властивості та зникати старі.
- Потрібно створити нестандартну базу даних.
- Бази шляхів та дерева рішень. Коли шляхи зручно представляти у вигляді дерева.
- Видалення ієрархічних структур без використання рекурсії
Продовження .
відмова: Ця стаття та мої коментарі до неї є моєю думкою і не мають відношення до офіційної позиції корпорації InterSystems.
Джерело: habr.com
