

Пропоную ознайомитись із розшифровкою доповіді кінця 2019 року Олександра Валялкіна "Go optimizations in VictoriaMetrics"
- швидка і масштабована СУБД для зберігання та обробки даних у формі часового ряду (запис утворює час і набір відповідних цьому часу значень, наприклад, отриманих через періодичне опитування стану датчиків або збирання метрик).

Ось посилання на відео цієї доповіді

Розповім трохи про себе. Я – Олександр Валялкін. Ось . Я захоплююся Go та оптимізацією продуктивності. Написав багато корисних і не дуже бібліотек. Вони починаються або з fast, Або з quick префіксу.
На даний момент я працюю над VictoriaMetrics. Що це таке та що я там роблю? Про це я розповім у цій презентації.

План доповіді такий:
- Спочатку я розповім вам, що таке VictoriaMetrics.
- Потім розповім, що таке часові лави.
- Потім розповім, як працює база даних часових рядів.
- Далі розповім про архітектуру бази даних: із чого вона складається.
- І потім перейдемо до оптимізацій, які є у VictoriaMetrics. Це оптимізація інвертованого індексу та оптимізація для bitset-реалізації на Go.

Що таке VictoriaMetrics хтось в аудиторії знає? Нічого, вже багато людей знають. Це хороша новина. Для тих, хто не знає, це база даних для тимчасових рядів. Вона заснована на архітектурі ClickHouse, на деяких деталях реалізації ClickHouse. Наприклад, на таких, як MergeTree, паралельне обчислення на всіх доступних ядрах процесора і оптимізація продуктивності за допомогою роботи над блоками даних, які поміщаються в кеш процесора.
VictoriaMetrics надає найкраще стиснення даних у порівнянні з іншими базами даних для тимчасових рядів.
Вона масштабується вертикально - тобто ви можете додавати більшу кількість процесорів, більшу кількість оперативної пам'яті на одному комп'ютері. VictoriaMetrics успішно утилізуватиме ці доступні ресурси і підвищуватиме лінійну продуктивність.
Також VictoriaMetrics масштабується горизонтально - тобто ви можете додавати додаткові ноди в кластер VictoriaMetrics, і її продуктивність зростатиме майже лінійно.
Як ви здогадалися, VictoriaMetrics швидка база даних, тому що інші я не можу писати. І вона написана на Go, тож я про неї розповідаю на цьому мітапі.

Хто знає, що таке часовий ряд? Теж багато людей знає. Тимчасово ряд - це серія пар (timestamp, значение)де ці пари відсортовані за часом. Значення є число з плаваючою точкою – float64.
Кожен часовий ряд унікально ідентифікований ключем. Із чого складається цей ключ? Він складається з непустого набору пар ключ-значення.
Ось приклад часового ряду. Ключем цього ряду є список пар: __name__="cpu_usage" – це назва метрики, instance="my-server" - Це комп'ютер, на якому ця метрика зібрана, datacenter="us-east" - Це датацентр, де стоїть цей комп'ютер.
У нас вийшло ім'я часового ряду, що складається з трьох пар ключ-значення. Цьому ключу відповідає список пар (timestamp, value). t1, t3, t3, ..., tN - це timestamps, 10, 20, 12, ..., 15 - Відповідні значення. Це cpu-usage в даний момент для даного ряду.

Де можуть бути використані часові лави? У кого є ідеї?
- У DevOps можна вимірювати показання завантаження CPU, RAM, мережі, rps, кількість помилок тощо.
- IoT – можемо міряти температуру тиск, geo coordinates та ще щось.
- Також фінанси – можемо моніторити ціни на будь-які акції та валюти.
- Крім того, тимчасові ряди можуть використовуватися в моніторингу виробничих процесів на заводах. У нас є користувачі, які використовують VictoriaMetrics для моніторингу вітрових турбін для роботів.
- Також тимчасові ряди корисні збору інформації з датчиків різних пристроїв. Наприклад, для двигуна; для вимірювання тиску у шинах; для виміру швидкості, відстані; для виміру витрати бензину і т.д.
- Також тимчасові лави можуть використовуватися для моніторингу літаків. У кожному літаку є чорна скринька, яка збирає тимчасові ряди за різними параметрами здоров'я літака. Тимчасові ряди також використовуються в аерокосмічній промисловості.
- Healthcare – це тиск крові, пульс тощо.
Можливо, є ще застосування, про які я забув, але, сподіваюся, що ви зрозуміли, що тимчасові ряди активно використовуються в сучасному світі. І обсяг їхнього використання з кожним роком зростає.

Навіщо потрібна база даних для часових рядів? Чому не можна використовувати звичайну реляційну базу для зберігання тимчасових лав?
Тому що в часових лавах зазвичай великий обсяг інформації, який складно зберігати та обробляти у звичайних базах даних. Тому з'явилися спеціалізовані БД для тимчасових лав. Ці бази ефективно зберігають точки (timestamp, value) із заданим ключем. Вони надають API для читання збережених даних по ключу, по одній парі ключ-значення, або кількох таких пар, або regexp. Наприклад, ви хочете знайти завантаження процесора всіх ваших сервісів у датацентрі в Америці, то потрібно використовувати такий псевдозапит.
Зазвичай, бази даних для тимчасових рядів представляють спеціалізовані мови запитів, тому що SQL для тимчасових рядів не дуже добре підходить. Хоча є бази даних, які підтримують SQL, але він не дуже добре підходить. Більше добре підходять такі мови запитів, як , , , . Я сподіваюся, що хтось чув хоча б одну з цих мов. Про PromQL, напевно, чули багато хто. Це мова запитів Prometheus.
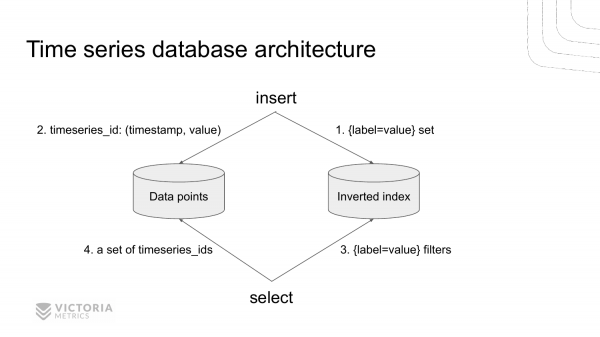
Ось як виглядає архітектура сучасної бази даних для часових рядів з прикладу VictoriaMetrics.
Вона складається із двох частин. Це сховище для інвертованого індексу та сховище для значень тимчасових рядів. Ці сховища поділені.
Коли приходить новий запис до бази даних, ми спочатку звертаємося до інвертованого індексу, щоб знайти ідентифікатор часового ряду по заданому набору label=value для цієї метрики. Знаходимо цей ідентифікатор та зберігаємо значення у сховищі даних.
Коли приходить якийсь запит на вибірку даних із TSDB, ми в першу чергу ліземо в інвертований індекс. Дістаємо все timeseries_ids записи, які відповідають даному набору label=value. І потім дістаємо всі необхідні дані зі сховища даних, індексованого по timeseries_ids.

Розглянемо приклад, як база даних для часових рядів обробляє вхідний select-запит.
- Насамперед вона дістає все
timeseries_idsз інвертованого індексу, що містять задані париlabel=value, або задовольняють заданого регулярного виразу. - Потім вона дістає всі data points із сховища даних на заданому інтервалі часу для знайдених
timeseries_ids. - Після цього база даних здійснює якісь обчислення над цими data points, згідно з запитом користувача. І після цього повертає відповідь.
У цій презентації я вам розповім про першу частину. Це пошук timeseries_ids за інвертованим індексом. Про другу частину та третю частину ви можете потім подивитися , або зачекати, поки я підготую інші доповіді 🙂

Приступимо до інвертованого індексу. Багатьом може здатись, що це просто. Хто знає, що таке інвертований індекс та як він працює? О, вже не так багато людей. Спробуймо зрозуміти, що це таке.
Насправді, все просто. Це просто словник, який відображає ключ до значення. Що таке ключ? Ця пара label=value, Де label и value - Це рядки. А значення – це набір timeseries_ids, до якого входить задана пара label=value.
Інвертований індекс дозволяє швидко знаходити все timeseries_ids, які мають задані label=value.
А також він дозволяє швидко знаходити timeseries_ids тимчасових рядів для кількох пар label=value, або для пар label=regexp. Як це відбувається? За допомогою знаходження перетину множини timeseries_ids для кожної пари label=value.

Розглянемо різні реалізації інвертованого індексу. Почнемо з найпростішої наївної реалізації. Вона виглядає так.
Функція getMetricIDs отримує список рядків. Кожен рядок містить label=value. Ця функція повертає список metricIDs.
Як це працює? Ось у нас є глобальна змінна, яка називається invertedIndex. Це звичайний словник (map), який відображає рядок на slice int-ів. Рядок містить label=value.
Реалізація функції: дістаємо metricIDs для першого label=valueпотім проходимося по всіх інших label=value, дістаємо metricIDs для них. І викликаємо функцію intersectInts, Про яку буде розказано далі. І ця функція повертає перетин цих списків.

Як ви бачите, реалізація інвертованого індексу не надто складна. Але це наївна реалізація. Які має недоліки? Головний недолік наївної реалізації полягає в тому, що такий інвертований індекс у нас зберігається в оперативній пам'яті. Після перезапуску програми ми втрачаємо цей індекс. Нема збереження цього індексу на диск. Для бази даних такий інвертований індекс навряд чи підійде.
Другий недолік також пов'язаний із пам'яттю. Інвертований індекс повинен розміщуватися в оперативній пам'яті. Якщо він перевищить обсяг оперативної пам'яті, очевидно, що ми отримаємо – out of memory error. І програма не працюватиме.

Цю проблему можна вирішити за допомогою готових рішень, таких як , або .
Якщо стисло, то нам потрібна база даних, яка дозволяє зробити швидко три операції.
- Перша операція – це запис
ключ-значениеу цю базу. Це вона робить дуже швидко, деключ-значение- Це довільні рядки. - Друга операція – це швидкий пошук за заданим ключем.
- І третя операція – це швидкий пошук усіх значень по заданому префіксу.
LevelDB та RocksDB – ці бази розроблені в Google та Facebook. Спершу з'явилася LevelDB. Потім хлопці з Facebook взяли LevelDB та почали її покращувати, зробив RocksDB. Зараз на RocksDB усередині Facebook працюють майже всі внутрішні бази даних, у тому числі вони перевели на RocksDB та MySQL. Вони назвали його .
Інвертований індекс можна реалізувати за допомогою LevelDB. Як це зробити? Ми зберігаємо як ключ label=value. А як значення – ідентифікатор тимчасового ряду, де є пара label=value.
Якщо у нас є багато тимчасових рядів з цією парою label=value, то буде багато рядків у цій базі даних з однаковим ключем і різними timeseries_ids. Щоб отримати список усіх timeseries_ids, які починаються з даної label=prefix, ми робимо range scan, під який оптимізовано цю базу даних. Т. е. вибираємо всі рядки, які починаються з label=prefix і отримуємо необхідні timeseries_ids.

Ось зразкова реалізація, як вона виглядала б на Go. Ми маємо інвертований індекс. Це LevelDB.
Функція така сама, як для наївної реалізації. Вона майже рядок у рядок повторює наївну реалізацію. Єдиний момент, що замість звернення до map ми звертаємось до інвертованого індексу. Дістаємо всі значення для першої label=value. Потім проходимося по всіх парах, що залишилися. label=value та дістаємо відповідні набори metricIDs для них. Потім знаходимо перетин.
Начебто все добре, але в цьому рішенні є недоліки. VictoriaMetrics спочатку реалізовувала інвертований індекс з урахуванням LevelDB. Але зрештою довелося відмовитися від нього.
Чому? Тому що LevelDB повільніша, ніж наївна реалізація. У наївній реалізації за заданим ключем ми відразу дістаємо весь slice metricIDs. Ця дуже швидка операція - весь slice готовий до використання.
У LevelDB при кожному виклику функції GetValues потрібно пройтися по всіх рядках, які починаються з label=value. І для кожного рядка дістати значення timeseries_ids. З таких timeseries_ids зібрати slice цих timeseries_ids. Очевидно, що це набагато повільніше, ніж просто звернення до звичайного map'у по ключу.
Другий недолік у тому, що LevelDB написаний на C. Звернення до C-функцій з Go не є дуже швидким. Воно займає сотні наносекунд. Це не дуже швидко, тому що в порівнянні зі звичайним викликом функції, написаної на go, яка займає 1-5 наносекунд, різниця у продуктивності виходить у десятки разів. Для VictoriaMetrics це було фатальним недоліком 🙂

Тому я написав власну реалізацію інвертованого індексу. І назвав її .
Mergeset базується на структурі даних MergeTree. Ця структура даних запозичена з ClickHouse. Очевидно, що mergeset має бути оптимізовано для швидкого пошуку timeseries_ids за заданим ключем. Mergeset написано повністю на Go. Ви можете подивитись . Реалізація mergeset лежить у татку . Ви можете спробувати зрозуміти, що там відбувається.
API mergeset дуже схожий на LevelDB і RocksDB. Т. е. він дозволяє швидко зберегти туди нові записи і швидко вибрати записи по заданому префіксу.

Про недоліки mergeset ми поговоримо пізніше. Зараз поговоримо про те, які виникли проблеми з VictoriaMetrics у production під час реалізації інвертованого індексу.
Чому вони з'явилися?
Перша причина – це high churn rate. У перекладі російською – це часта зміна часових рядів. Це коли тимчасовий ряд закінчується і починається новий ряд, або починаються багато нових часових рядів. І це відбувається часто.
Друга причина – це багато тимчасових рядів. Спочатку, коли моніторинг набирав популярності, кількість тимчасових рядів була невеликою. Наприклад, на кожен комп'ютер потрібно моніторити завантаження процесора, пам'яті, мережі та диска. 4 тимчасові ряди на кожен комп'ютер. У вас, скажімо, 100 комп'ютерів і 400 часових рядів. Це дуже мало.
З часом люди вигадали, що можна вимірювати більш детальну інформацію. Наприклад, вимірювати завантаження не лише процесора, а окремо кожного процесорного ядра. Якщо у вас є 40 процесорних ядер, то, відповідно, у вас з'являється в 40 разів більше часових рядів для вимірювання завантаження процесора.
Але це ще не все. У кожного процесорного ядра може бути кілька станів таких, як idle, коли він простоює. А також робота в user space, робота в kernel space та інші стани. І кожен такий стан також можна вимірювати, як окремий часовий ряд. Це додатково збільшує кількість рядів у 7-8 разів.
У нас з однієї метрики вийшло 40х8 = 320 метрик лише на один комп'ютер. Множимо на 100, отримуємо 32 000 замість 400.
Далі з'явився Kubernetes. І все ще погіршив, тому що в Kubernetes може хоститися багато різних сервісів. Кожен сервіс у Kubernetes складається з багатьох подів. І все це потрібно моніторити. Крім цього, у нас є постійний deployment нових версій ваших сервісів. Для кожної нової версії потрібно створювати нові часові ряди. У результаті кількість часових рядів зростає експоненційно і ми стикаємося з проблемою великої кількості часових рядів, яка називається high-cardinality. VictoriaMetrics успішно справляється з нею в порівнянні з іншими базами даних для тимчасових рядів.

Розглянемо докладніше high churn rate. Чому з'являється high churn rate на production? Тому що деякі значення лейблів та тегів постійно змінюються.
Наприклад, візьмемо Kubernetes, у якому є поняття deployment, тобто коли викочується нова версія вашої програми. Розробники Kubernetes чомусь вирішили додати id'шку deployment'а в label.
До чого це спричинило? До того, що при кожному новому deployment'і у нас усі старі часові ряди перериваються, а замість них починаються нові часові ряди з новим значенням лейбла. deployment_id. Таких лав може бути сотні тисяч і навіть мільйони.
Важлива особливість цього в тому, що загальна кількість часових рядів зростає, але кількість часових рядів, які в даний момент активні, на які приходять дані, залишається постійною. Такий стан називається – high churn rate.
Основна проблема high churn rate у тому, щоб забезпечити постійну швидкість пошуку всіх часових рядів за заданим набором лейблів за якийсь інтервал часу. Зазвичай, це інтервал часу за останню годину або за останній день.
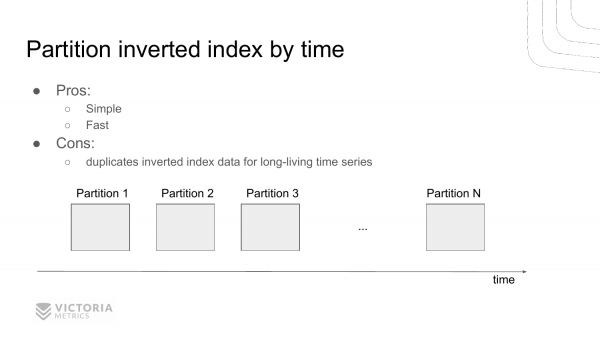
Як цю проблему вирішити? Ось перший варіант. Це розділяти інвертований індекс на незалежні частини за часом. Т. е. проходить якийсь інтервал часу, закінчуємо працювати з поточним інвертованим індексом. І створюємо новий інвертований індекс. Проходить ще один інтервал часу, створюємо ще один та ще один.
І при вибірці цих інвертованих індексів ми знаходимо набір інвертованих індексів, які потрапляють у заданий інтервал. І, відповідно, вибираємо звідти id тимчасових рядів.
Це дозволяє заощадити ресурси, тому що нам не потрібно переглядати частини, які не потрапляють до заданого інтервалу. Т. е. зазвичай, якщо ми вибираємо дані за останню годину, то за попередні часові інтервали ми пропускаємо запити.

Є ще один варіант вирішення цієї проблеми. Це зберігати для кожного дня окремий список id тимчасових рядів, які зустрілися за цей день.
Перевага цього рішення порівняно з попереднім рішенням у тому, що ми не дублюємо інформацію про тимчасові ряди, які не зникають з часом. Вони постійно перебувають і змінюються.
Недолік у тому, що таке рішення складніше у реалізації та складніше у дебазі. І VictoriaMetrics обрала це рішення. Так склалося історично. Таке рішення теж показує себе непогано порівняно з попереднім. Тому що це рішення не було реалізовано через те, що доводиться дублювати дані в кожному partition для тимчасових рядів, які не змінюються, тобто які не зникають з часом. VictoriaMetrics була в першу чергу оптимізована щодо споживання дискового простору, і попередня реалізація погіршувала споживання дискового простору. А ось ця реалізація найкраще підходить для мінімізації споживання дискового простору, тому вона була обрана.
Довелося з нею боротися. Боротьба полягала в тому, що в цій реалізації потрібно однаково вибирати набагато більшу кількість timeseries_ids для даних, ніж коли інвертований індекс розділений за часом.

Як ми вирішили цю проблему? Ми її вирішили оригінальним чином – шляхом збереження кількох ідентифікаторів часових рядів у кожному записі інвертованого індексу замість одного ідентифікатора. Т. е. у нас є ключ label=value, Що зустрічається в кожному тимчасовому ряду. І тепер ми зберігаємо кілька timeseries_ids в одному записі.
Ось приклад. Раніше у нас було N записів, а тепер у нас є один запис, префікс у якого такий самий, як і у всіх інших. У попередньому записі значення містить усі id тимчасових рядів.
Це дозволило збільшити швидкість сканування такого інвертованого індексу до 10 разів. І дозволило зменшити споживання пам'яті для кешу, тому що тепер ми зберігаємо рядок label=value лише один раз у кеші разом N разів. І цей рядок може бути великий, якщо у вас у тегах і labels зберігаються довгі рядки, які любить туди пхати Kubernetes.
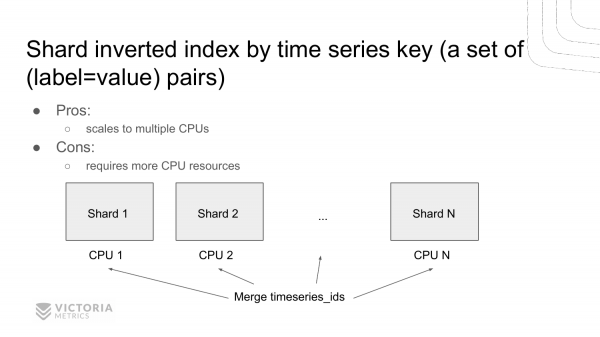
Ще один варіант прискорення пошуку за інвертованим індексом – це шардування. Створення декількох інвертованих індексів замість одного та шардування даних між ними за ключом. Це набір key=value пар. Т. е. у нас виходить кілька незалежних інвертованих індексів, які ми можемо опитувати паралельно на кількох процесорах. Попередні реалізації дозволяли працювати тільки в однопроцесорному режимі, тобто сканувати дані лише на одному ядрі. Це рішення дозволяє сканувати дані відразу на декількох ядрах, як це любить робити ClickHouse. Це ми плануємо реалізувати.

А тепер повернемося до наших баранів – до функції перетину timeseries_ids. Розглянемо, які можуть бути реалізації. Ця функція дозволяє знаходити timeseries_ids для заданого набору label=value.

Перший варіант – це наївна реалізація. Два вкладені цикли. Ось ми отримуємо на вході функції intersectInts два slices - a и b. На виході вона мусить повернути нам перетин цих slices.
Наївна реалізація має такий вигляд. Ми проходимося по всіх значеннях з slice a, всередині цього циклу проходимося за всіма значеннями slice b. І порівнюємо їх. Якщо вони збігаються, то ми знайшли перетин. І зберігаємо його в result.

Які недоліки? Квадратична складність – це головний її недолік. Наприклад, якщо у вас розміри slice a и b по одному мільйону, то ця функція ніколи не поверне вам відповідь. Тому що їй потрібно буде зробити трильйон ітерацій, що дуже багато навіть для сучасних комп'ютерів.

Друга реалізація полягає в map. Ми створюємо map. Поміщаємо в цю map всі значення з slice a. Потім пробігаємось окремим циклом по slice b. І перевіряємо – чи є це значення з slice b у map. Якщо воно є, то додаємо його до результату.

Які переваги? Перевага в тому, що тут лише лінійна складність. Т. е. функція набагато швидше виконається для великих розмірів slices. Для мільйонного розміру slice ця функція виконається за 2 мільйони ітерацій, на відміну від трильйона ітерацій, як у попередній функції.
А недолік у тому, що ця функція потребує більшої пам'яті для того, щоб створити цю map.
Другий недолік - великий overhead на хешування. Ця вада не дуже очевидна. І для нас він теж був не дуже очевидним, тому спочатку у VictoriaMetrics реалізація intersection була через map. Але потім профіль показало, що основний процесорний час витрачається на запис у map і на перевірку наявності значення в цій map.
Чому у цих місцях витрачається процесорний час? Тому що в цих рядках Go здійснює операцію хешування. Т. е. він обчислює hash від ключа, щоб звернутися потім за заданим індексом в HashMap. Операція з обчислення hash'а виконується за десятки наносекунд. Це повільно для VictoriaMetrics.

Я вирішив продати bitset, оптимізований спеціально для цього випадку. Ось як тепер виглядає перетинання двох slices. Тут створюємо bitset. Додаємо до нього елементи з першого slice. Потім перевіряємо наявність цих елементів у другому slice. І додаємо їх у результат. Т. е. майже відрізняється від попереднього прикладу. Єдине, що ми тут замінили звернення до map кастомними функціями add и has.

З першого погляду здається, що це має працювати повільніше, якщо раніше там використовувалася стандартна map, а тут ще якісь функції викликаються, але профіль показує, що ця штука працює в 10 разів швидше, ніж стандартна map для випадку з VictoriaMetrics.
Крім цього, вона використовує набагато менше пам'яті порівняно з реалізацією на map. Тому що ми зберігаємо тут біти замість восьмибайтових значень.
Нестача такої реалізації в тому, що вона не така очевидна, не тривіальна.
Ще один недолік, який багато хто може не помічати - це те, що дана реалізація може погано працювати в деяких випадках. Т. е. вона оптимізована для конкретного випадку, для даного випадку перетину ids тимчасових рядів VictoriaMetrics. Не означає, що вона підійде всім випадків. Якщо її неправильно використовувати, то отримаємо не приріст продуктивності, а out of memory error та уповільнення продуктивності.

Розглянемо реалізацію цієї структури. Якщо хочете подивитися, вона знаходиться у вихідниках VictoriaMetrics, в папці . Вона оптимізована саме для випадку VictoriaMetrics, де timeseries_id являє собою 64-бітове значення, де перші 32 біти в основному постійні і змінюються лише останні 32 біти.
Ця структура даних не зберігається на диску, вона працює лише у пам'яті.

Ось її API. Він дуже складний. API підігнано саме під конкретний приклад використання VictoriaMetrics. Т. е. тут немає зайвих функцій. Тут є функції, які явно використовуються VictoriaMetrics.
Є функції addяка додає нові значення. Є функція hasяка перевіряє нові значення. І є функція delяка видаляє значення. Є допоміжна функція lenяка повертає розмір множини. Функція clone клонує безліч. І функція appendto перетворює цей сет на slice timeseries_ids.

Ось як виглядає реалізація цієї структури даних. У set є два елементи:
ItemsCount– це допоміжне поле, щоб швидко повернути кількість елементів у set. Можна було б обійтися без цього допоміжного поля, але його довелося додати сюди, тому що VictoriaMetrics часто опитує у своїх алгоритмах довжину bitset.Друге поле – це
buckets. Це slice з структуриbucket32. У кожній структурі зберігаєтьсяhiполе. Це верхні 32 біти. І два slice -b16hisиbucketsзbucket16структур.
Тут зберігаються верхні 16 біт другої частини 64-бітової структури. А тут зберігаються bitsets для молодших 16 біт кожного байта.
Bucket64 складається з масиву uint64. Довжина обчислюється за допомогою цих констант. В одному bucket16 максимум може зберігатися 2^16=65536 біт. Якщо це поділити на 8, це 8 кілобайт. Якщо поділити ще раз на 8, то це 1000 uint64 значенні. Т. е. Bucket16 - Це у нас 8-кілобайтна структура.

Розглянемо, як реалізовано один із методів цієї структури додавання нового значення.
Все починається з uint64 значення. Обчислюємо верхні 32 біти, обчислюємо нижні 32 біти. Проходимося по всіх buckets. Порівнюємо верхні 32 біти в кожному bucket з значенням, що додається. І якщо вони збігаються, то викликаємо функцію add у структурі b32 buckets. І додаємо туди нижні 32 біти. І якщо це повернуло true, то це означає, що ми додали таке значення туди і ми такого значення не було. Якщо він повертає false, то таке значення вже було. Потім збільшуємо кількість елементів у структурі.
Якщо ми не знайшли потрібного bucket з потрібним hi-значенням, то ми викликаємо функцію addAllocяка виробить новий bucket, Додаючи його в bucket-структуру.

Це реалізація функції b32.add. Вона схожа на попередню реалізацію. Ми обчислюємо старші 16 біт, молодші 16 біт.
Потім ми проходимося по всіх 16 верхніх бітах. Знаходимо збіги. І при збігу викликаємо метод add, який розглянемо на наступній сторінці для bucket16.

І ось найнижчий рівень, який має бути максимально оптимізований. Ми обчислюємо для uint64 id значення в slice bit, а також bitmask. Це маска для даного 64-бітного значення, за якою можна перевірити наявність цього біта або встановити його. Ми перевіряємо наявність цього біта, встановленого та встановлюємо його, та повертаємо наявність. Ось така реалізація у нас, яка дозволила прискорити операцію перетину ids тимчасових рядів у 10 разів у порівнянні зі звичайними maps.

У VictoriaMetrics крім цієї оптимізації є багато інших оптимізацій. Більшість із цих оптимізацій додані не просто так, а після профілювання коду в production.
Це головне правило оптимізації - не додавати оптимізацію, припускаючи, що тут буде вузьке місце, тому що може виявитися, що там не буде вузького місця. Оптимізація зазвичай погіршує якість коду. Тому варто оптимізувати лише після профілювання та бажано у production, щоб це були реальні дані. Кому цікаво, можете подивитися вихідники VictoriaMetrics та вивчити інші оптимізації, які там є.

У мене питання про bitset. Дуже схоже реалізацію C++ vector bool, оптимізований bitset. Ви звідти взяли реалізацію?
Ні, не звідти. При реалізації цього bitset я орієнтувався на знання структури цих ids timeseries, які використовують у VictoriaMetrics. А структура у них така, що верхні 32 біти переважно постійні. Нижні 32 біти можуть змінюватися. Що нижче біт, то частіше він може змінюватися. Тому ця реалізація саме оптимізована під цю структуру даних. C++ реалізація, наскільки знаю, оптимізована під загальний випадок. Якщо робити оптимізацію під загальний випадок, то це означає, що вона буде не оптимальною під конкретний випадок.
Раджу вам ще переглянути доповідь Олексія Міловида. Він десь із місяць тому розповідав про оптимізацію в ClickHouse під конкретні спеціалізації. Він якраз розповідає, що у випадку C++ реалізація чи якась інша реалізація заточені під хорошу роботу у середньому лікарні. Вона може працювати гірше, ніж спеціалізована реалізація під конкретні знання, як у нас, коли ми знаємо, що верхні 32 біти переважно постійні.
У мене друге питання. У чому кардинальна відмінність від InfluxDB?
Кардинальних відмінностей багато. Якщо за продуктивністю і споживанням пам'яті, то InfluxDB у тестах показує в 10 разів більше споживання пам'яті для high cardinality часових рядів, коли їх у вас багато, наприклад, мільйони. Наприклад, VictoriaMetrics споживає 1 GB на мільйон активних рядів, а InfluxDB споживає 10 Gb. І це велика різниця.
Друга кардинальна відмінність у тому, що у InfluxDB дивні мови запитів – Flux та InfluxQL. Вони не дуже зручні для роботи з тимчасовими рядами порівняно з , який підтримується у VictoriaMetrics. PromQL – це мова запитів із Prometheus.
І ще одна відмінність - це те, що у InfluxDB трохи дивна модель даних, де в кожному рядку може зберігатися кілька fields з різним набором тегів. Ці рядки діляться ще різні таблиці. Ось ці додаткові ускладнення ускладнюють подальшу роботу з базою. Її складно підтримувати та розуміти.
У VictoriaMetrics все набагато простіше. Там кожен часовий ряд являє собою ключ-значення. Значення – це набір точок – (timestamp, value), а ключ – це набір label=value. Немає ніякого поділу на поля і міри. Це дозволяє вибирати будь-які дані, а потім їх комбінувати, складати, віднімати, множити, ділити на відміну від InfluxDB, де обчислення між різними рядами досі не реалізовані, наскільки я знаю. Якщо навіть реалізовані, то складно треба писати купу коду.
Я маю уточнююче питання. Я правильно зрозумів, що була якась проблема, про яку ви розповідали, що цей інвертований індекс не вміщується на згадку, тому там партикування йде?
Спочатку я показав наївну реалізацію інвертованого індексу на стандартній Go'шній map'і. Така реалізація не підходить для баз даних, тому що цей індекс не зберігається на диску, а база даних повинна зберігати на диск, щоб при рестарті ці дані залишалися доступними. У цій реалізації при рестарті програми у вас інвертований індекс зникне. І ви втратите доступ до всіх даних, тому що не зможете знайти їх.
Вітаю! Дякую за доповідь! Мене звати Павел. Я із компанії Wildberries. У мене є кілька запитань до вас. Питання перше. Як вам здається, якби ви обрали інший принцип при побудові архітектури свого додатка і партиціонували дані за часом, то, можливо, у вас вийшло б робити перетин даних при пошуку, ґрунтуючись лише на тому, що в одній партиції знаходиться дані за один проміжок часу , тобто за один інтервал часу і вам не довелося б дбати про те, що у вас шматки по-різному розкидані? Питання номер 2 - якщо ви реалізуєте подібний алгоритм з bitset і рештою, то, можливо, ви пробували використовувати інструкції процесора? Може, ви пробували такі оптимізації?
На другий одразу відповім. Ми ще не дійшли. Але якщо треба буде, дійдемо. А перше, яке було питання?
Ви обговорювали два сценарії. І сказали, що обрали другий із більш складною імплементацією. І не віддали перевагу першому, де дані партиціоновані за часом.
Так. У першому випадку сумарний обсяг індексу був би більшим, тому що ми в кожній партиції мали б зберігати дублі даних для тих тимчасових рядів, які продовжуються крізь ці всі партиції. І якщо у вас churn rate у тимчасових рядів невеликий, тобто постійно одні й ті ж ряди використовуються, то в першому випадку ми набагато сильніше програли б в обсязі займаного дискового простору в порівнянні з другим випадком.
А так – так, партиціювання за часом – гарний варіант. Його Prometheus використовує. Але в Prometheus є інший недолік. При злитті цих шматків даних, йому потрібно тримати в пам'яті мета-інформацію по всіх марках і timeseries. Тому, якщо шматки даних великі, які він зливає, то споживання пам'яті дуже зростає при злитті, на відміну від VictoriaMetrics. При злитті VictoriaMetrics взагалі не споживає пам'ять, там якісь пари кілобайт споживаються, незалежно від розмірів об'єднаних шматків даних.
Алгоритм, який використовується, він використовує пам'ять. У ній відзначаються timeseries-мітки, у яких є значення. І таким чином ви перевіряєте парну наявність в одному масиві даних та в іншому. І розумієте – чи відбувся intersect чи ні. Зазвичай у базах даних реалізують курсори, ітератори, що зберігають поточний свій стан і біжить за відсортованими даними за рахунок ви маєте просту складність у даних операцій.
Чому ми не використовуємо курсори для перетину даних?
Так.
У нас у LevelDB або в mergeset зберігаються саме відсортовані рядки. Ми можемо курсором пройтись і знайти перетин. А чому не використовуємо? Тому що це повільно. Тому що курсори мають на увазі під собою, що на кожен рядок потрібно викликати функцію. Виклик функції – 5 наносекунд. І якщо у вас 100 000 000 рядків, виходить, що ми витрачаємо півсекунди тільки на виклик функції.
Таке є так. І останнє у мене питання. Питання, можливо, трохи дивно прозвучить. Чому в момент надходження даних не можна вважати всі необхідні агрегати та у необхідному вигляді їх зберігати? Навіщо зберігати величезні обсяги в якісь системи типу VictoriaMetrics, ClickHouse і т.д., щоб потім багато часу витрачати на них?
Наведу приклад, щоб було зрозуміліше. Допустимо, як працює маленький іграшковий спідометр? Він записує відстань, яку ви проїхали, весь час додаючи його в одну величину, в другу – час. І ділить. І отримує середню швидкість. Можна робити приблизно те саме. Складати нальоту всі потрібні факти.
Добре, зрозумів питання. Ваш приклад має місце для життя. Якщо ви знаєте, які вам потрібні агрегати, то це найкраща реалізація. Але проблема в тому, що люди зберігають ці метрики, якісь дані в ClickHouse і вони не знають ще, як вони в майбутньому їх агрегуватимуть, фільтруватимуть, тому доводиться зберігати всі сирі дані. Але якщо ви знаєте, що вам потрібно підрахувати щось середнє, то чому б не підрахувати його замість того, щоб зберігати там купу сирих значень? Але це тільки в тому випадку, якщо ви знаєте, що вам потрібно.
До речі, бази зберігання тимчасових рядів підтримують підрахунок агрегатів. Наприклад, Prometheus підтримує . Т. е. це можна зробити, якщо ви знаєте, які вам знадобляться агрегати. У VictoriaMetrics цього поки немає, але перед нею зазвичай ставиться Prometheus, в якому це можна зробити в recoding rules.
Наприклад, на попередній роботі потрібно було підраховувати кількість подій у ковзному вікні за останню годину. Проблема у цьому, що довелося робити кастомну реалізацію на Go, т. е. сервіс підрахунку цієї штуки. Цей сервіс був у результаті нетривіальним, тому що це важко вважати. Реалізація може бути простою, якщо вам потрібно рахувати якісь агрегати на фіксованих інтервалах часу. Якщо ж ви хочете рахувати події у ковзному вікні, то це не так просто, як здається. Я думаю, що це не реалізовано досі в ClickHouse або в timeseries-базах, тому що складно в реалізації.
І ще одне питання. Ми зараз говорили про усереднення, і я згадав, що колись була така штука як Graphite з бекендом Carbon. І він умів старі дані проріджувати, тобто залишати одну точку на хвилину, одну точку на годину і т.д. У принципі, це досить зручно, якщо нам потрібні сирі дані, умовно кажучи, за місяць, а все інше можна проредити . Але Prometheus, VictoriaMetrics цю функціональність не підтримують. Чи планується підтримувати? Якщо ні, то чому?
Дякую за питання. Наші користувачі його періодично задають. Запитують, коли ми додамо підтримку проріджування (downsampling). Тут є кілька проблем. По-перше, кожен користувач розуміє під downsampling щось своє: хтось хоче отримати будь-яку довільну точку на заданому інтервалі, хтось хоче максимальні, мінімальні, середні значення. Якщо у вашу базу пишуть дані багато систем, то не можна їх гребти під один гребінець. Може виявитися, що для кожної системи потрібно використовувати різне проріджування. І це складно у реалізації.
І друге - це те, що VictoriaMetrics, як і ClickHouse, оптимізована під роботу над великим обсягом сирих даних, тому вона може перелопатити мільярд рядків менше, ніж за секунду, якщо у вас є багато ядер у вашій системі. Сканування точок тимчасового ряду VictoriaMetrics – 50 000 000 точок в секунду на одне ядро. І ця продуктивність масштабується на наявні ядра. Т. е. якщо у вас 20 ядер, наприклад, то вийде сканування мільярда крапок за секунду. І ця властивість VictoriaMetrics і ClickHouse знижує потребу в downsamling.
Ще одна властивість у тому, що VictoriaMetrics ефективно стискає ці дані. Стиснення в середньому на виробництво від 0,4 до 0,8 байт на точку. Кожна точка – це timestamp + значення. І вона стискується менше, ніж за один байт у середньому.
Сергій. У мене є питання. Який мінімальний квант часу запису?
Одна мілісекунда. Нещодавно ми мали розмову з іншими розробниками баз даних для тимчасових рядів. Вони мають мінімальний квант часу – це одна секунда. І у Graphite, наприклад, теж одна секунда. У OpenTSDB також одна секунда. У InfluxDB – наносекундна точність. У VictoriaMetrics – одна мілісекунда, тому що у Prometheus одна мілісекунда. Та VictoriaMetrics розроблялася як remote storage для Prometheus спочатку. Але зараз вона може зберігати дані з інших систем.
Людина, з якою я розмовляв, каже, що вони мають секундну точність — їм цього достатньо, тому що це залежить від типу даних, які зберігаються в базу часових рядів. Якщо це DevOps-дані або дані з інфраструктури, де ви збираєте їх з інтервалом у 30 секунд, за хвилину, то там секундної точності достатньо, менше вже не треба. А якщо ви збираєте ці дані high frequency trading systems, то потрібна наносекундна точність.
Міллісекундна точність у VictoriaMetrics підходить і для DevOps-кейсу, і може підійти для більшості кейсів, які я згадав на початку доповіді. Єдине, навіщо вона може не підійти – це high frequency trading systems.
Дякую! І ще питання. Яка сумісність у PromQL?
Повна зворотна сумісність. VictoriaMetrics повністю підтримує PromQL. Крім цього, вона додає ще додаткову розширену функціональність на PromQL, яка називається . Щодо цієї розширеної функціональності є доповідь на YouTube. Я розповідав на Monitoring Meetup навесні у Пітері.
Телеграм канал .
Тільки зареєстровані користувачі можуть брати участь в опитуванні. , будь ласка.
Що вам заважає перейти на VictoriaMetrics як довгострокове сховище для Prometheus? (Пишіть у коментарях, я додам до опитування))
71,4%Не використовую Prometheus5
28,6%Не знав про VictoriaMetrics2
Проголосували 7 користувачів. Утрималися 12 користувачів.
Джерело: habr.com
