

Ми розглянемо роботу Zabbix з базою даних TimescaleDB як backend. Покажемо, як запустити з нуля та як мігрувати з PostgreSQL. Також наведемо порівняльні випробування продуктивності двох конфігурацій.

HighLoad++ Siberia 2019. Зал "Томськ". 24 червня, 16. Тези та . Наступна конференція HighLoad++ пройде 6 та 7 квітня 2020 року в Санкт-Петербурзі. Подробиці та квитки .
Андрій Гущин (далі – АГ): – Я – інженер технічної підтримки ZABBIX (далі – «Заббікс»), тренер. Працюю понад 6 років у технічній підтримці та безпосередньо стикався з продуктивністю. Сьогодні я розповідатиму про продуктивність, яку може дати TimescaleDB, при порівнянні зі звичайним PostgreSQL 10. Також деяка вступна частина – про те, як взагалі працює.
Головні виклики продуктивності: від збору до очищення даних
Почнемо з того, що існують певні виклики продуктивності, з якими зустрічається кожна система моніторингу. Перший виклик продуктивності – це швидкий збір та обробка даних.

Хороша система моніторингу повинна оперативно, своєчасно отримувати всі дані, обробляти їх згідно з тригерними виразами, тобто обробляти за якимись критеріями (у різних системах це по-різному) і зберігати в базі даних, щоб надалі використовувати ці дані.

Другий виклик продуктивності – збереження історії. Зберігати в базі даних найчастіше і мати швидкий та зручний доступ до цих метриків, які були зібрані за якийсь період часу. Найголовніше, щоб ці дані було зручно отримати, використовувати їх у звітах, графіках, тригерах, в якихось порогових значеннях для оповіщень і т.д.

Третій виклик продуктивності – це очищення історії, тобто коли у вас настає такий день, що вам не потрібно зберігати якісь докладні метрики, зібрані за 5 років (навіть місяці або два місяці). Якісь вузли мережі були видалені або якісь хости, метрики вже не потрібні тому, що вони вже застаріли і перестали збиратися. Це все потрібно вичищати, щоб база даних не розрослася до великого розміру. І взагалі, очищення історії найчастіше є серйозним випробуванням для сховища – дуже часто впливає на продуктивність.
Як вирішити проблеми кешування?
Я зараз говоритиму конкретно про «Заббікс». У «Заббіксі» перший та другий дзвінки вирішені за допомогою кешування.

Збір та обробка даних – ми використовуємо оперативну пам'ять для зберігання цих даних. Зараз про ці дані буде детальніше розказано.
Також за бази даних є певне кешування для основних вибірок – для графіків, інших речей.
Кешування на стороні самого Zabbix-сервера: у нас є ConfigurationCache, ValueCache, HistoryCache, TrendsCache. Що це таке?

ConfigurationCache – це основний кеш, у якому ми зберігаємо метрики, хости, елементи даних, тригери; все, що необхідно для обробки препроцессингу, збору даних, з яких хостів збирати, з якою частотою. Все це зберігається в ConfigurationCache, щоб не ходити до бази даних, не створювати зайвих запитів. Після старту сервера ми оновлюємо цей кеш (створюємо) і періодично оновлюємо (залежно від налаштувань конфігурації).
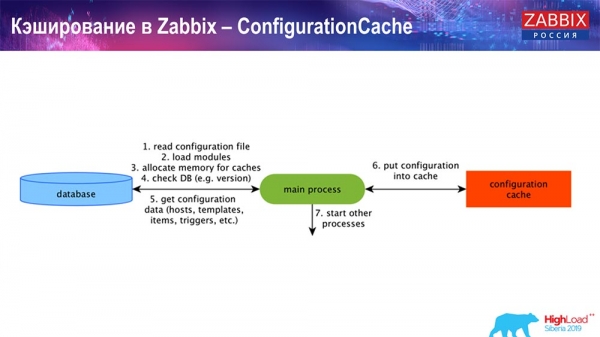
Кешування в Zabbix. Збір даних
Тут схема досить велика:
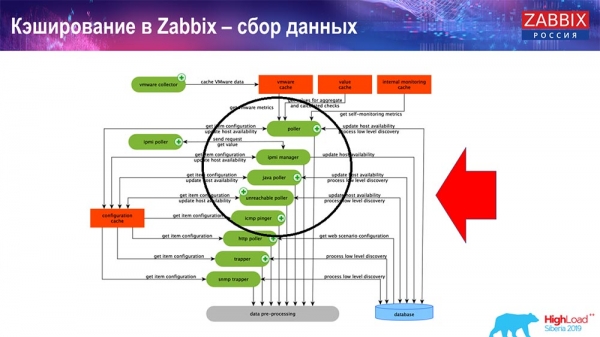
Основні у схемі – ось ці збирачі:
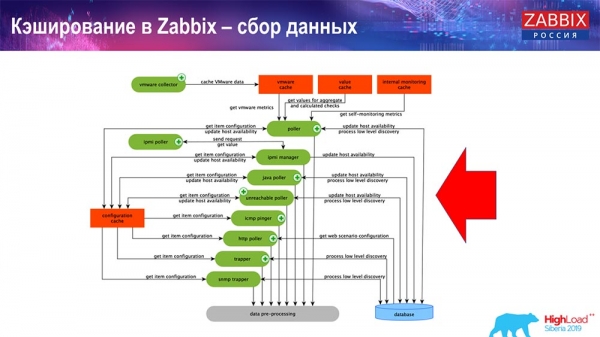
Це самі процеси збирання, різні «полери», які відповідають за різні види збирання. Вони збирають дані з icmp, ipmi, з різних протоколів і передають це все на препроцесинг.
PreProcessing HistoryCache
Також, якщо у нас є елементи даних, що обчислюються, (хто знайомий з «Заббіксом» – знає), тобто обчислювані, агрегаційні елементи даних, – ми їх забираємо безпосередньо з ValueCache. Про те, як він наповнюється, я розповім згодом. Всі ці збирачі використовують ConfigurationCache для отримання своїх завдань і далі передають препроцесинг.
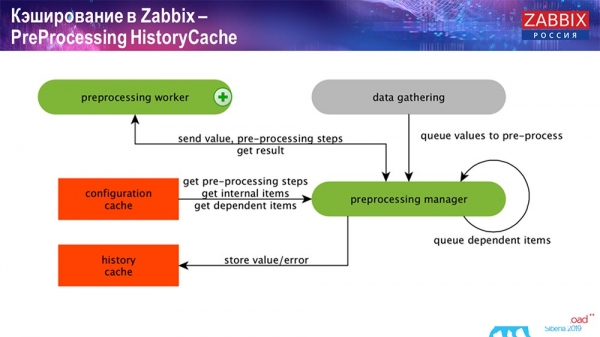
Препроцесинг також використовує ConfigurationCache для отримання кроків препроцессингу, обробляє ці дані у різний спосіб. Починаючи з версії 4.2 він у нас винесений на проксі. Це дуже зручно, тому що сам препроцесинг – досить важка операція. І якщо у вас дуже великий "Заббікс", з великою кількістю елементів даних та високою частотою збору, то це сильно полегшує роботу.
Відповідно, після того, як ми обробили ці дані будь-яким чином за допомогою препроцессингу, зберігаємо їх у HistoryCache для того, щоб їх далі обробити. На цьому закінчується збирання даних. Ми переходимо до головного процесу.
Робота History syncer
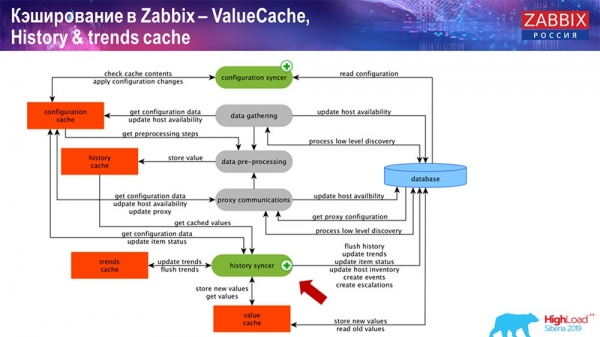
Головний у «Заббікс» процес (оскільки це монолітна архітектура) – History syncer. Це головний процес, який займається саме атомарною обробкою кожного елемента даних, тобто кожного значення:
- приходить значення (він бере його з HistoryCache);
- перевіряє у Configuration syncer: чи є якісь тригери для обчислення – обчислює їх;
якщо є – створює події, створює ескалацію у тому, щоб створити оповіщення, якщо необхідно по конфігурації; - записує тригери для подальшої обробки, агрегації; якщо ви агрегуєте за останню годину і таке інше, це значення запам'ятовує ValueCache, щоб не звертатися до таблиці історії; таким чином, ValueCache наповнюється потрібними даними, які необхідні для обчислення тригерів, елементів, що обчислюються, і т. д.;
- далі History syncer записує всі дані до бази даних;
- база даних записує їх у диск – цьому процес обробки закінчується.
Бази даних. Кешування
На боці БД, коли ви хочете подивитися графіки або якісь звіти щодо подій, є різні кеші. Але в рамках цієї доповіді я не про них розповідатиму.
Для MySQL є Innodb_buffer_pool, ще купа різних кешів, які також можна налаштувати.
Але це – основні:
- shared_buffers;
- effective_cache_size;
- shared_pool.

Я для всіх баз даних привів, що є певні кеші, які дозволяють тримати в оперативній пам'яті ті дані, які часто потрібні для запитів. Там вони мають свої технології для цього.
Про продуктивність бази даних
Відповідно є конкурентне середовище, тобто «Заббікс»-сервер збирає дані та записує їх. При перезапуску він також читає з історії для наповнення ValueCache і так далі. Тут же у вас можуть бути скрипти та звіти, які використовують Заббікс-API, який на базі веб-інтерфейсу побудований. «Заббікс»-API входить у БД і отримує необхідні дані отримання графіків, звітів чи якогось списку подій, останніх проблем.
Також дуже популярне рішення для візуалізації – це Grafana, яку використовують наші користувачі. Вміє безпосередньо входити як через Заббікс-API, так і через БД. Воно теж створює певну конкуренцію для отримання даних: потрібна тонша, хороша настройка БД, щоб відповідати швидкій видачі результатів та тестування.

Очищення історії. У Zabbix є Housekeeper
Третій виклик, який використовується в Заббікс - це очищення історії за допомогою Housekeeper. «Хаускіпер» дотримується всіх налаштувань, тобто у нас в елементах даних зазначено, скільки зберігати (в днях), скільки зберігати тренди, динаміку змін.
Я не розповів про ТрендКеш, який ми вираховуємо на льоту: надходять дані, ми їх агрегуємо за одну годину (в основному це числа за останню годину), кількість середня / мінімальна і записуємо це раз на годину в таблицю динаміки змін («Трендс») . Хаускіпер запускається і видаляє звичайними селектами дані з БД, що не завжди ефективно.
Як зрозуміти, що це неефективно? Ви можете на графіках продуктивності внутрішніх процесів бачити таку картину:
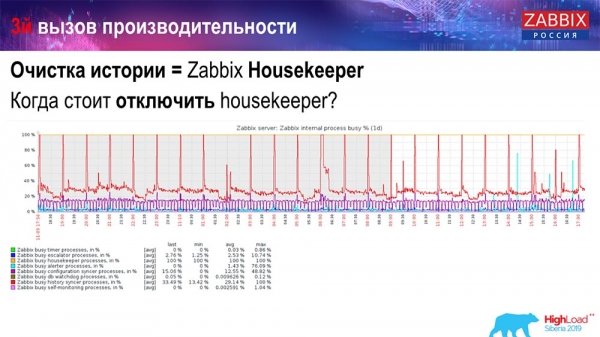
У вас History syncer постійно зайнятий (червоний графік). І «рудий» графік, який зверху йде. Це «Хаускіпер», який запускається та чекає від БД, коли вона видалить усі рядки, які він задав.
Візьмемо якийсь Item ID: потрібно видалити останні 5 тисяч; звичайно, за індексами. Але зазвичай датасет досить великий - база даних все одно це зчитує з диска і піднімає в кеш, а це дорога операція для БД. Залежно від її розмірів це може призводити до певних проблем продуктивності.
Вимкнути «Хаускіпер» можна простим способом – у нас є всім знайомий веб-інтерфейс. Налаштування в Administration general (налаштування для Хаускіпера) ми відключаємо внутрішній housekeeping для внутрішньої історії та трендів. Відповідно, «Хаускіпер» більше не керує цим:

Що можна робити далі? Ви відключили, у вас графіки вирівнялися… Які в цьому випадку можуть бути проблеми? Що може допомогти?
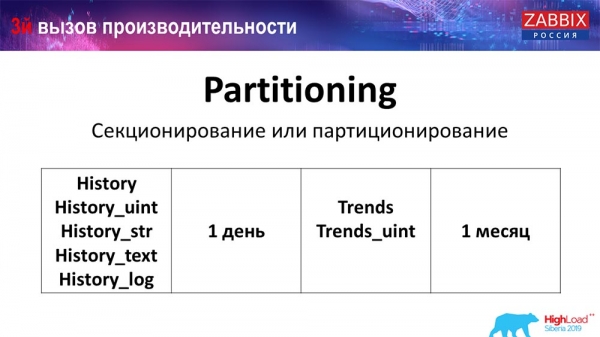
Партиціонування (секціонування)
Зазвичай це налаштовується на кожній реляційній базі даних, які я перерахував, у різний спосіб. MySQL має свою технологію. Але в цілому вони дуже схожі, якщо говорити про PostgreSQL 10 та MySQL. Звичайно, там дуже багато внутрішніх відмінностей, як це все реалізовано і як це впливає на продуктивність. Але загалом створення нової партиції часто також призводить до певних проблем.

Залежно від вашого setup'у (наскільки багато у вас створюється даних за один день), зазвичай виставляють найменший – це 1 день/партиція, а для «трендів», динаміки змін – 1 місяць/нова партиція. Це може змінюватись, якщо у вас дуже великий setup.
Відразу давайте скажу про розміри setup'у: до 5 тисяч нових значень за секунду (nvps так званий) – це вважатиметься малий «сетап». Середній – від 5 до 25 тисяч значень за секунду. Все, що згори – це вже великі та дуже великі інсталяції, які вимагають дуже ретельного налаштування саме бази даних.
На великих установках 1 день – це може бути не оптимально. Я особисто бачив на MySQL партиції по 40 гігабайт на день (і більше може бути). Це дуже великий обсяг даних, який може спричинити якісь проблеми. Його треба зменшувати.
Навіщо потрібне партиціонування?
Що дає Partitioning, я думаю, всі знають – це секціонування таблиць. Найчастіше це окремі файли на диску та спан-запитах. Він оптимально вибирає одну партицію, якщо це входить у звичайне партиціонування.
Для «Заббікса», зокрема, використовується по ренджу, діапазону, тобто ми використовуємо таймстамп (число звичайне, час з початку епохи). Ви задаєте початок дня/кінець дня, і це є партицією. Відповідно, якщо ви звертаєтеся за даними дводенної давності, це все вибирається з бази даних швидше, тому що потрібно лише один файл завантажити в кеш і видати (а не велику таблицю).

Багато БД також прискорює insert (вставка в одну child-таблицю). Поки що я говорю абстрактно, але це теж можливо. Partitoning часто допомагає.
Elasticsearch для NoSQL
Нещодавно в 3.4 ми впровадили рішення для NoSQL. Додали можливість писати в Elasticsearch. Ви можете писати окремі якісь типи: вибираєте – чи числа пишіть, чи якісь знаки; у нас є стрінг-текст, логи можете писати в Elasticsearch… Відповідно, веб-інтерфейс теж буде звертатися до Elasticsearch. Це добре в якихось випадках працює, але зараз це можна використовувати.

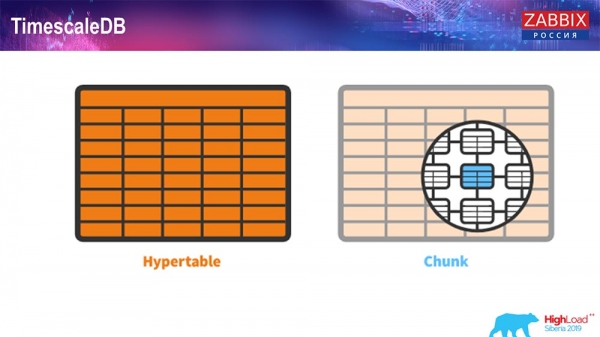
TimescaleDB. Гіпертаблиці
Для 4.4.2 ми звернули увагу на одну річ, як TimescaleDB. Що це таке? Це розширення для "Постгрес", тобто воно має нативний інтерфейс PostgreSQL. Плюс, це розширення дозволяє набагато ефективніше працювати з timeseries-даними та мати автоматичне партицирование. Як це виглядає:

Це hypertable – є таке поняття у Timescale. Це гіпертаблиця, яку ви створюєте, і в ній є чанки (chunk). Чанки – це партиції, це чайлд-таблиці, якщо не помиляюсь. Це справді ефективно.
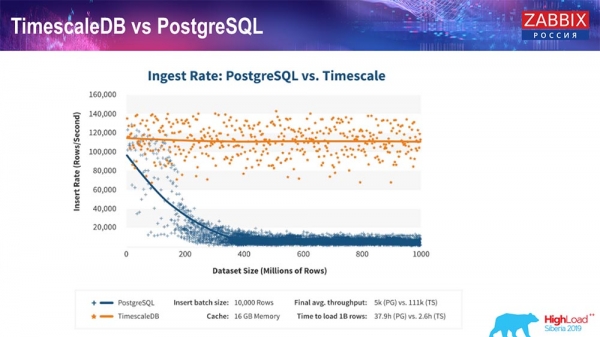
TimescaleDB і PostgreSQL
Як запевняють виробники TimescaleDB, вони використовують більш правильний алгоритм обробки запитів, зокрема insert'ів, який дозволяє мати приблизно постійну продуктивність при збільшенні розміру датасет-вставки. Тобто після 200 мільйонів рядків «Постгрес» звичайний починає дуже сильно просідати і втрачає продуктивність буквально до нуля, тоді як «Таймскейл» дозволяє вставляти інсерти якомога ефективніше за будь-якої кількості даних.
Як встановити TimescaleDB? Все просто!
Є в нього документація, описано – можна поставити з пакетів для будь-яких… Він залежить від офіційних пакетів «Постгресу». Можна скомпілювати вручну. Так сталося, що мені довелося компілювати для БД.
На Заббікс ми просто активуємо Extention. Я думаю, що ті, хто користувався в «Постгресі» Extention… Ви просто активуєте Extention, створюєте його для використовуваної БД «Заббікс».
І останній крок…
TimescaleDB. Міграція таблиць історії
Вам потрібно створити hypertable. Для цього є спеціальна функція Create hypertable. У ній першим параметром вказуєте таблицю, яка у цій БД потрібна (для якої потрібно створити гіпертаблицю).

Поле, яким потрібно створити, і chunk_time_interval (це інтервал чанків (партицій, які потрібно використовувати). 86 400 – це один день.
Параметр migrate_data: якщо ви вставляєте в true, це переносить всі поточні дані в заздалегідь створені чанки.
Я сам використав migrate_data - це займає пристойний час, залежно від того, яких розмірів у вас є БД. У мене було більше терабайта – створення зайняло понад годину. У деяких випадках при тестуванні я видаляв історичні дані для тексту (history_text) та стрінга (history_str), щоб не переносити – вони мені насправді були не цікаві.
І останній апдейт ми робимо в нашому db_extention: ми ставимо timescaledb, щоб БД і, зокрема, наш «Заббікс» розумів, що є db_extention. Він активує і використовує правильно синтаксис і запити до БД, використовуючи вже ті «фічі», які необхідні TimescaleDB.
Конфігурація сервера
Я використовував два сервери. Перший сервер - це віртуальна машина досить маленька, 20 процесорів, 16 гігабайт оперативної пам'яті. Налаштував на ній "Постгрес" 10.8:

Операційна система була Debian, Файлова система - xfs. Зробив мінімальні налаштування, щоб використовувати саме цю базу даних, за винятком того, що використовуватиме сам Заббікс. На цій же машині стояв «Заббікс»-сервер, PostgreSQL та навантажувальні агенти.

Я використовував 50 активних агентів, які використовують LoadableModule для швидкого генерування різних результатів. Це вони згенерували рядки, числа і таке інше. Я забивав БД великою кількістю даних. Спочатку конфігурація містила 5 тисяч елементів даних на кожен хост, і приблизно кожен елемент даних містив тригер для того, щоб це був реальний setup. Іноді для використання навіть потрібно більше одного тригера.

Інтервал оновлення, саме навантаження я регулював тим, що не тільки 50 агентів використовував (додав ще), але й за допомогою динамічних елементів даних та знижував апдейт-інтервал до 4 секунд.
Тест продуктивності. PostgreSQL: 36 тисяч NVPs
Перший запуск, перший setup у мене був на чистому PostreSQL 10 на цьому залізі (35 тисяч значень за секунду). Загалом, як видно на екрані, вставка даних займає фракції секунди – все добре та швидко, SSD-диски (200 гігабайт). Єдине, що 20 ГБ досить швидко заповнюються.
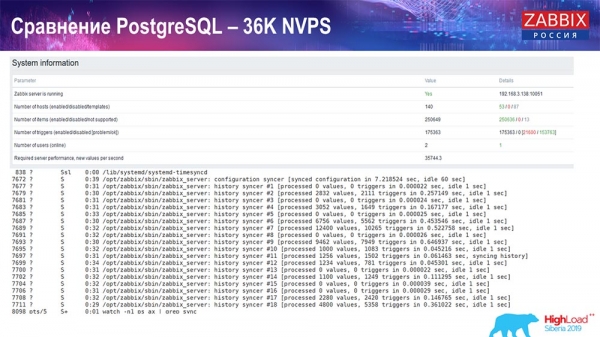
Буде далі чимало таких графіків. Це стандартний dashboard продуктивності "Заббікс"-сервера.
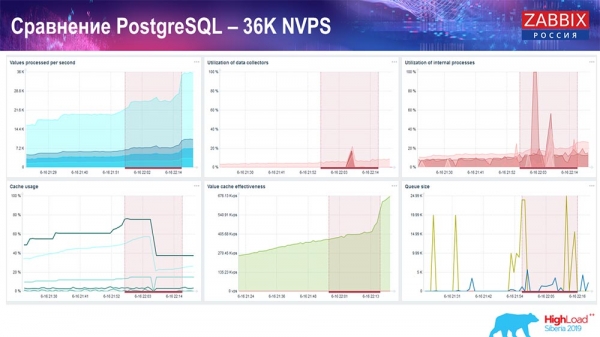
Перший графік – кількість значень за секунду (блакитний, зверху зліва), 35 тисяч значень у разі. Це (нагорі в центрі) завантаження процесів складання, а це (нагорі праворуч) – завантаження саме внутрішніх процесів: history syncers і housekeeper, який тут (внизу в центрі) виконувався достатній час.
Цей графік (внизу в центрі) показує використання ValueCache – скільки хітів ValueCache для тригерів (кілька тисяч значень за секунду). Ще важливий графік – четвертий (знизу зліва), який показує використання HistoryCache, про який я розповів, який є буфером перед вставкою в БД.
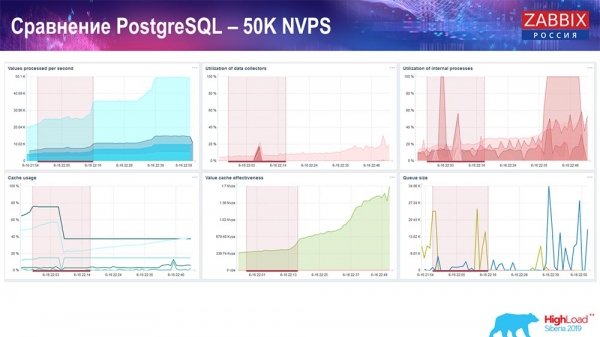
Тест продуктивності. PostgreSQL: 50 тисяч NVPs
Далі я збільшив навантаження до 50 тисяч значень за секунду на цьому ж залозі. При завантаженні Хаускіпером 10 тисяч значень записувалося вже в 2-3 секунди з обчисленням. Що, власне, показано на наступному скріншоті:
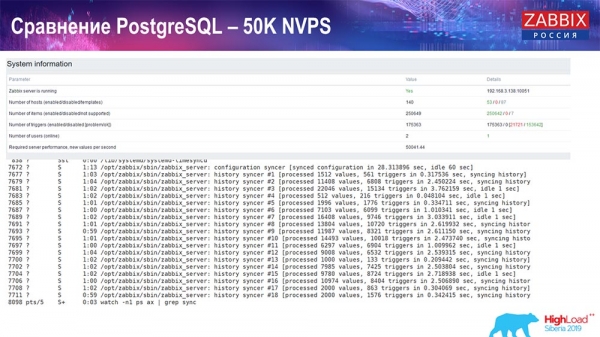
«Хаускіпер» вже починає заважати роботі, але загалом завантаження траперів хісторі-синкерів поки що знаходиться на рівні 60 % (третій графік, вгорі праворуч). HistoryCache вже під час роботи «Хаускіпера» починає активно заповнюватись (внизу зліва). Він був близько півгігабайта, заповнювався на 20%.
Тест продуктивності. PostgreSQL: 80 тисяч NVPs
Далі збільшив до 80 тисяч значень за секунду:
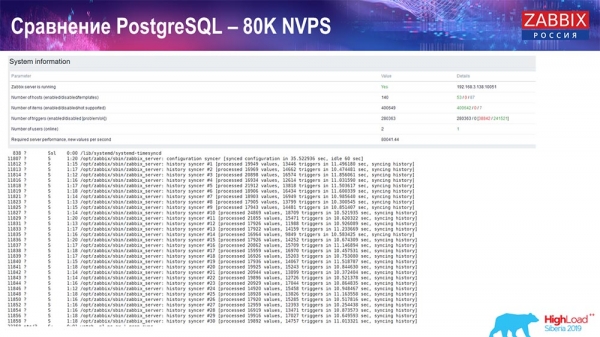
Це було приблизно 400 тисяч елементів даних, 280 тисяч тригерів. Вставка, як бачите, по завантаженню хісторі-синкерів (їх було 30 штук) була досить висока. Далі я збільшував різні параметри: хістори-синкери, кеш... На даному залозі завантаження хісторі-синкерів почало збільшуватися до максимуму, практично «в полку» – відповідно, HistoryCache пішов у дуже високе завантаження:
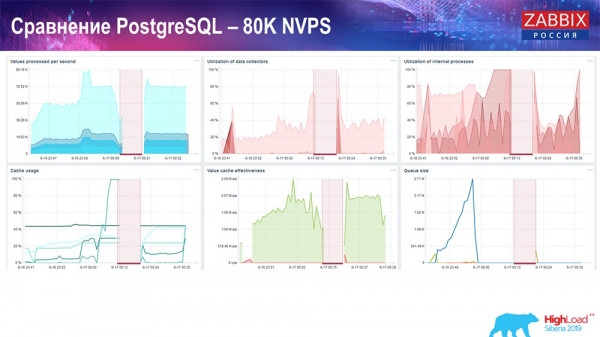
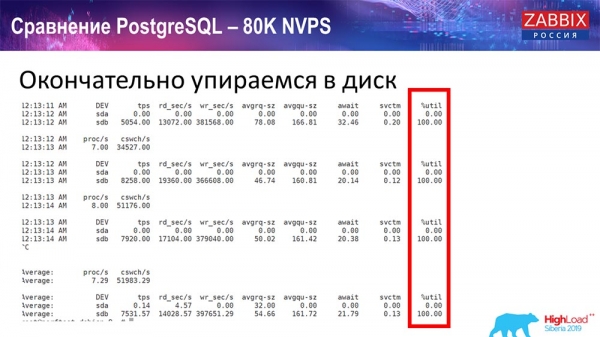
Весь цей час я спостерігав за всіма параметрами системи (як процесор використовується, оперативна пам'ять) і виявив, що утилізація дисків була максимальною – я досяг максимальної можливості цього диска на цьому залізі, на цій віртуальній машині. «Постгрес» почав за такої інтенсивності скидати дані досить активно, і диск уже не встигав на запис, читання...
Я взяв інший сервер, який вже мав 48 процесорів 128 гігабайт оперативної пам'яті:
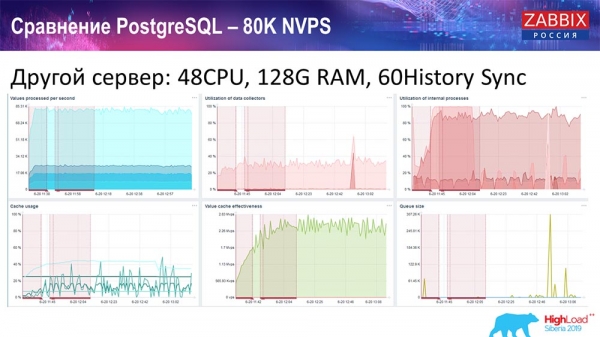
Також я його «затюнив» – поставив History syncer (60 штук) і домігся прийнятної швидкодії. Фактично ми не «в полиці», але це вже, напевно, межа продуктивності, де вже необхідно щось робити.
Тест продуктивності. TimescaleDB: 80 тисяч NVPs
У мене було головне завдання – використовувати TimescaleDB. На кожному графіку видно провал:
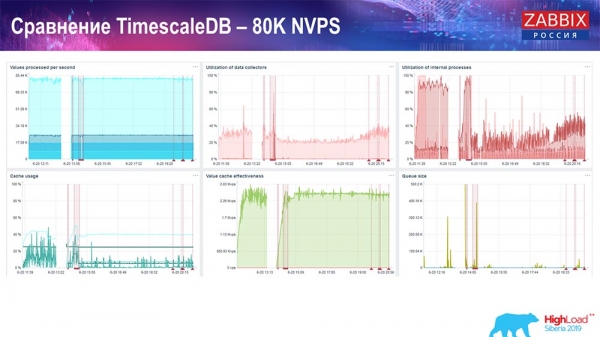
Ці провали – саме міграція даних. Після цього в «Заббікс»-сервері профіль завантаження хісторі-синкерів, як ви бачите, дуже змінився. Він практично в 3 рази швидше дозволяє вставляти дані та використовувати менше HistoryCache – відповідно, у вас вчасно будуть поставлятися дані. Знову ж таки, 80 тисяч значень за секунду – це досить високий rate (звісно, не для «Яндекса»). Загалом це досить великий setup, з одним сервером.
Тест продуктивності PostgreSQL: 120 тисяч NVPs
Далі я збільшив значення кількості елементів даних до півмільйона і отримав розрахункове значення 125 тисяч за секунду:
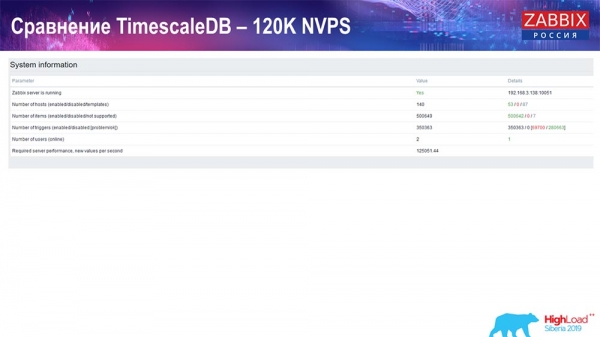
І отримав такі графіки:
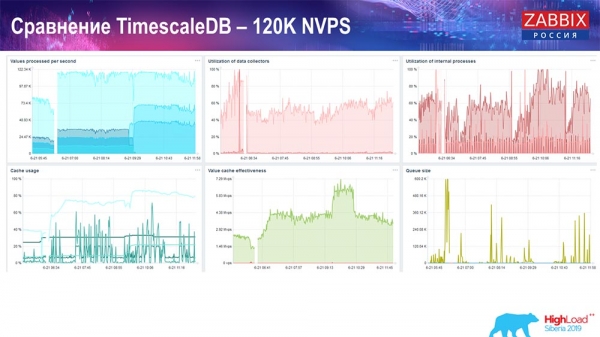
В принципі це робочий setup, він може досить тривалий час працювати. Але так як у мене був диск лише на 1,5 терабайта, то я його витрачав за пару днів. Найважливіше, що в той же час створювалися нові партиції на TimescaleDB, і це для продуктивності проходило зовсім непомітно, чого не скажеш про MySQL.
Зазвичай партиції створюються вночі, тому що це взагалі блокує вставку і роботу з таблицями, може призводити до деградації сервісу. У цьому випадку цього немає! Головне завдання було перевірити можливості TimescaleDB. Вийшла така цифра: 120 тисяч значень за секунду.
Також є у «комньюніті» приклади:
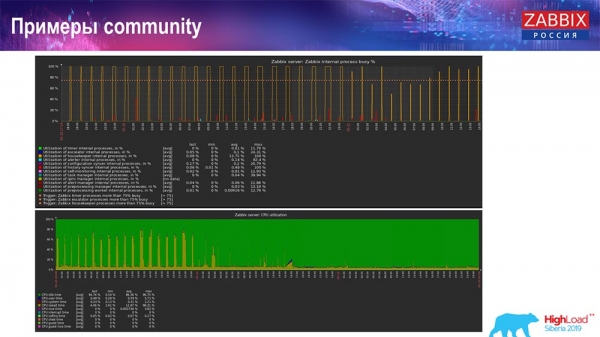
Людина теж увімкнула TimescaleDB і завантаження з використання io.weight впала на процесорі; і використання елементів внутрішніх процесів також знизилося завдяки включенню TimescaleDB. Причому це звичайні млинці, тобто звичайна віртуалка на звичайних дисках (не SSD)!
Для якихось маленьких setup'ів, які впираються у продуктивність диска, TimescaleDB, як на мене, дуже гарне рішення. Воно непогано дозволить продовжувати працювати доти, як мігрувати більш швидке залізо для бази даних.
Запрошую всіх вас на наші заходи: Conference – у Москві, Summit – у Ризі. Використовуйте наші канали - Телеграм, форум, IRC. Якщо ви маєте якісь питання – приходьте до нас на стійку, можемо поговорити про все.
Питання аудиторії
Питання з аудиторії (далі – А): – Якщо TimescaleDB так просто в налаштуванні, і він дає такий приріст продуктивності, то, можливо, це варто використовувати як найкращу практику налаштування Заббікса з Постгресом? І чи є якесь підводне каміння та мінуси цього рішення, чи все-таки, якщо я вирішив собі робити «Заббікс», я можу спокійно брати «Постгрес», ставити туди «Таймскейл» відразу, користуватися і не думати про жодні проблеми ?

АГ: – Так, я сказав би, що це гарна рекомендація: використовувати «Постгрес» одразу з розширенням TimescaleDB. Як я вже казав, безліч хороших відгуків, незважаючи на те, що ця «фіча» є експериментальною. Але насправді тести показують, що це чудове рішення (з TimescaleDB), і я думаю, що воно буде розвиватися! Ми стежимо за тим, як це розширення розвивається і правитимемо те, що потрібно.
Ми навіть під час розробки спиралися на одну їхню відому «фічу»: там можна було з чанками трохи по-іншому працювати. Але потім вони це у наступному релізі випилили, і нам довелося вже не спиратися на цей код. Я рекомендував би використовувати це рішення на багатьох setup'ах. Якщо ви використовуєте MySQL… Для середніх setup'ів будь-яке рішення добре працює.
А: – На останніх графіках, які від community, був графік із «Хаускіпером»:
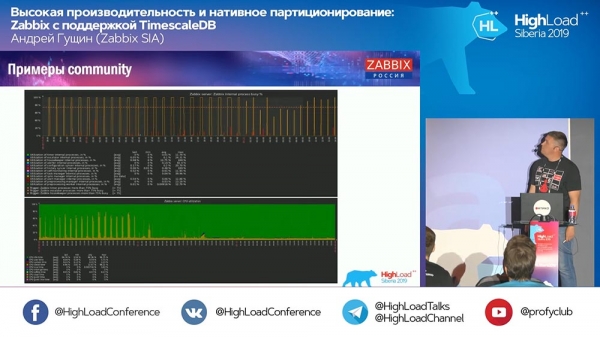
Він продовжив працювати. Що "Хаускіпер" робить у випадку з TimescaleDB?
АГ: - Зараз не можу точно сказати - подивлюся код і скажу детальніше. Він використовує запити саме TimescaleDB не для видалення чанків, а якось агрегує. Поки що я не готовий відповісти на це технічне запитання. На стенді сьогодні чи завтра уточнимо.
А: - У мене схоже питання - про продуктивність операції видалення в Таймскейл.
А (відповідь з аудиторії): Коли ви видаляєте дані з таблиці, якщо ви це робите через delete, то вам потрібно пройтися по таблиці видалити, почистити, помітити все на майбутній вакуум. У «Таймскейл», тому що ви маєте чанки, ви можете дропати. Грубо кажучи, ви просто кажете файлу, який лежить у big data: "Видалити!"
"Таймскейл" просто розуміє, що такого чанка більше немає. І так як він інтегрується в планувальник запиту, він на хуках ловить ваші умови в select'і або в інших операціях і одразу розуміє, що цього чанка більше немає - Я туди більше не піду! (дані відсутні). От і все! Тобто скан таблиці замінюється видалення бінарного файлу, тому це швидко.
А: – Вже торкалися теми не SQL. Наскільки я розумію, "Заббіксу" не дуже потрібно модифікувати дані, а все це - щось на зразок лога. Чи можна використовувати спеціалізовані БД, які не можуть змінювати свої дані, але при цьому набагато швидше зберігають, накопичують, віддають - Clickhouse, припустимо, що-небудь кафка-подібне?.. Kafka - це теж лог! Чи можна їх якось інтегрувати?
АГ: - Вивантаження можна зробити. Ми маємо певну «фічу» з версії 3.4: ви можете писати у файли всі історичні файли, івенти, все інше; і далі якимсь обробником відсилати до будь-якої іншої БД. Насправді багато хто переробляє і пише безпосередньо у БД. На льоту хістори-синкери все це пишуть у файли, ротують ці файли і так далі, і це ви можете перекидати в Клікхаус. Не можу сказати про плани, але, можливо, подальша підтримка NoSQL-рішень (таких, як Клікхаус) буде продовжуватися.
А: - Взагалі, виходить, можна повністю позбутися постгресу?
АГ: – Звичайно, найскладніша частина у «Заббіксі» – це історичні таблиці, які створюють найбільше проблем та події. У цьому випадку, якщо ви не довго зберігатимете події і зберігатимете історію з трендами в якомусь іншому швидкому сховищі, то в цілому ніяких проблем, думаю, не буде.
А: – Можете оцінити, наскільки швидше все працюватиме, якщо перейти на «Клікхаус», допустимо?
АГ: – Я не тестував. Думаю, що як мінімум тих же цифр можна буде досягти досить просто з огляду на те, що «Клікхаус» має свій інтерфейс, але не можу сказати однозначно. Найкраще протестувати. Все залежить від конфігурації: скільки у вас хостів і таке інше. Вставка – це одне, але потрібно ще забирати ці дані – Grafana чи ще чимось.
А: – Тобто йдеться про рівну боротьбу, а не про велику перевагу цих швидких БД?
АГ: – Думаю, коли інтегруємо, будуть точніші тести.
А: - А куди подівся старий добрий RRD? Що змусило перейти на бази даних SQL? Спочатку ж на RRD усі метрики збиралися.
АГ: – У «Zabbix» RRD, можливо, у дуже давній версії був. Завжди були SQL бази - класичний підхід. Класичний підхід – це MySQL, PostgreSQL (дуже давно вже є). У нас загальний інтерфейс для баз даних SQL та RRD ми практично ніколи не використовували.


Небагато реклами 🙂
Дякую, що залишаєтеся з нами. Вам подобаються наші статті? Бажаєте бачити більше цікавих матеріалів? Підтримайте нас, оформивши замовлення або порекомендувавши знайомим, , унікальний аналог entry-level серверів, який був винайдений нами для Вас: (Доступні варіанти з RAID1 і RAID10, до 24 ядер і до 40GB DDR4).
Dell R730xd вдвічі дешевше в дата-центрі Equinix Tier IV в Амстердамі? Тільки в нас у Нідерландах! Dell R420 – 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB – від $99! Читайте про те
Джерело: habr.com
