


За останні кілька років бази даних тимчасових рядів (Time-series databases) перетворилися з дивовижної штуки (вузькоспеціалізовано застосовується або у відкритих системах моніторингу (і прив'язаної до конкретних рішень), або у Big Data проектах) на «товар народного споживання». На території РФ окреме спасибі за це треба сказати Яндексу та ClickHouse'у. До цього моменту, якщо вам необхідно зберегти велику кількість time-series даних, доводилося або змиритися з необхідністю підняти монструозний Hadoop-стек і супроводжувати його, або спілкуватися з протоколами, індивідуальними для кожної системи.
Може здатися, що в 2019 році стаття про те, яку TSDB варто використовувати, складатиметься лише з однієї пропозиції: «просто використовуйте ClickHouse». Але є нюанси.
Справді, ClickHouse активно розвивається, база користувача зростає, а підтримка ведеться дуже активно, але чи не стали ми заручниками публічної успішності ClickHouse'у, яка затьмарила інші, можливо, більш ефективні/надійні рішення?
На початку минулого року ми зайнялися переробкою нашої власної системи моніторингу, в процесі якої постало питання про вибір бази для зберігання даних. Про історію цього вибору я хочу тут розповісти.
Постановка завдання
Насамперед — необхідна передмова. Навіщо нам взагалі власна система моніторингу та як вона була влаштована?
Ми почали надавати послуги підтримки в 2008 році, і до 2010-го стало зрозуміло, що агрегувати дані про процеси, що відбуваються в клієнтській інфраструктурі, рішеннями, що існували на той момент, стало складно (ми говоримо про, пробач господи, Cacti, Zabbix-е і зароджуваному Graphite).
Основними нашими вимогами були:
- супровід (на той момент – десятків, а в перспективі – сотень) клієнтів у межах однієї системи і при цьому наявність централізованої системи управління оповіщеннями;
- гнучкість в управлінні системою оповіщень (ескалація сповіщень між черговими, облік розкладу, база знань);
- можливість глибокої деталізації графіків (Zabbix на той момент малював графіки у вигляді картинок);
- тривале зберігання великої кількості даних (рік і більше) та можливість їх швидкої вибірки.
У цій статті нас цікавить останній пункт.
Говорячи про сховище, вимоги були такі:
- система має швидко працювати;
- бажано, щоб система мала SQL-інтерфейс;
- система повинна бути стабільною і мати активну базу користувача і підтримку (колись ми зіткнулися з необхідністю підтримувати такі системи, як наприклад MemcacheDB, яку перестали розвивати, або розподілене сховище MooseFS, багтрекер якого вівся китайською мовою: повторення цієї історії для свого проекту нам не хотілось);
- відповідність CAP-теоремі: Consitency (необхідно) — дані мають бути актуальними, ми не хочемо, щоб система управління оповіщеннями не отримала нових даних та плюнулася алертами про неприхід даних за всіма проектами; Partition Tolerance (необхідно) ми не хочемо отримати Split Brain системи; Availability (не критично, у разі існування активної репліки) – можемо самі переключитися на резервну систему у разі аварії кодом.
Як не дивно, на той момент ідеальним рішенням для нас виявився MySQL. Наша структура даних була гранично проста: ID сервера, ID лічильника, Timestamp і значення; швидка вибірка гарячих даних забезпечувалася великим розміром buffer pool, а вибірка історичних даних – SSD.
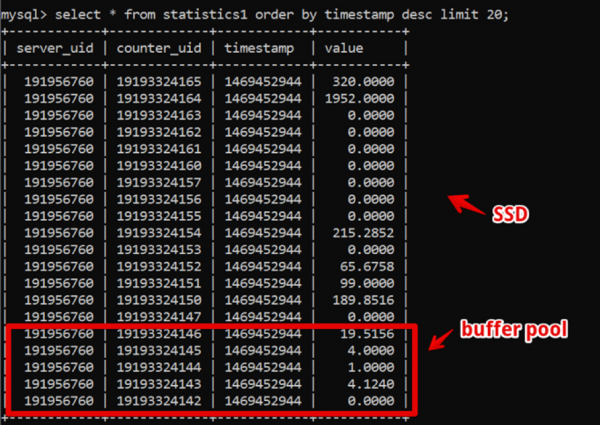
Таким чином, ми досягли вибірки свіжих двотижневих даних, з деталізацією до секунди за 200 мс до моменту повного малювання даних, і жили в цій системі досить довго.
Тим часом час йшов і кількість даних зростала. До 2016 року обсяги даних досягали десятків терабайт, що в умовах орендованих SSD-сховищ було суттєвою витратою.
До цього моменту активного поширення набули колонкові бази даних, про які ми стали активно думати: у колонкових БД дані зберігаються, як це можна зрозуміти, колонками, і якщо подивитися на наші дані, то легко побачити велику кількість дублів, які можна було б, у разі використання колонкової БД, стиснути компресією.
Однак ключова для роботи компанії система продовжувала працювати стабільно і експериментувати з переходом на щось інше не хотілося.
У 2017 році на конференції Percona Live в Сан-Хосе, напевно, вперше про себе заявили розробники Clickhouse. На перший погляд система була production-ready (ну, Яндекс.Метрика — це суворий продакшн), підтримка була швидкою і простою, і, головне, експлуатація була простою. З 2018 року ми затіяли процес переходу. Але на той час «дорослих» і перевірених часом систем TSDB стало багато, і ми вирішили виділити значний час і порівняти альтернативи, щоб переконатися, що альтернативних Clickhouse рішень, згідно з нашими вимогами, немає.
На додаток до вже зазначених вимог до сховища з'явилися свіжі:
- нова система повинна забезпечувати, як мінімум, таку ж продуктивність, що і MySQL, на тій самій кількості заліза;
- сховище нової системи повинне займати значно менше місця;
- СУБД, як і раніше, має бути простою в управлінні;
- хотілося мінімально змінювати програму при зміні СУБД.
Які системи ми почали розглядати
Apache Hive/Apache Impala
Старий перевірений боями Hadoop стек. По суті, це SQL-інтерфейс, побудований поверх зберігання даних у форматах на HDFS.
Плюси.
- При стабільній експлуатації дуже просто масштабувати дані.
- Є колонкові рішення щодо зберігання даних (менше місця).
- Дуже швидке виконання розпаралелених завдань за наявності ресурсів.
Мінуси.
- Це Hadoop і він складний в експлуатації. Якщо ми не готові брати готове рішення у хмарі (а ми не готові за вартістю), весь стек доведеться збирати та підтримувати руками адмінів, а цього дуже не хочеться.
- Дані агрегуються .
Однак:

Швидкість досягається масштабуванням числа обчислювальних серверів. Простіше кажучи, якщо ми велика компанія, займаємося аналітикою та бізнесом критично важливо максимально швидко агрегувати інформацію (нехай навіть ціною використання великої кількості обчислювальних ресурсів), це може бути нашим вибором. Але ми не були готові кратно збільшувати залізний парк для швидкості виконання завдань.
Druid/Pinot
Вже набагато більше для конкретно TSDB, але знову ж таки - Hadoop-стек.
є .
Якщо в кількох словах: Druid/Pinot виглядають краще за Clickhouse'а у випадках, коли:
- У вас гетерогенний характер даних (у нашому випадку ми записуємо лише таймсерії серверних метрик, і, по суті, це одна таблиця. Але можуть бути й інші кейси: тимчасові ряди обладнання, економічні тимчасові ряди і т.д. які треба агрегувати та обробляти).
- При цьому цих даних дуже багато.
- Таблиці та дані з тимчасовими рядами з'являються та пропадають (тобто якийсь набір даних прийшов, його проаналізували та видалили).
- Немає чіткого критерію, за яким дані можуть бути партиціоновані.
У протилежних випадках краще за себе показує ClickHouse, а це наш випадок.
Натисніть Будинок
- SQL-like.
- Простий в управлінні.
- Люди кажуть, що він працює.
Потрапляє у шорт-лист тестування.
InfluxDB
Зарубіжна альтернатива ClickHouse'у. З мінусів: High Availability є тільки в комерційній версії, але треба порівняти.
Потрапляє у шорт-лист тестування.
Кассандра
З одного боку, ми знаємо, що її використовують для зберігання метричних таймсерій таких систем моніторингу, як, наприклад, або OkMeter. Проте, є специфіка.
Cassandra не є колонковою базою даних у звичному її розумінні. Виглядає вона більше як мала, але в кожному рядку може бути різна кількість стовпців, за рахунок чого легко організувати колонкову виставу. У цьому сенсі зрозуміло, що при обмеженні 2 мільярди стовпців можна зберігати якісь дані саме в стовпцях (та й ті ж тимчасові ряди). Наприклад, MySQL коштує обмеження на 4096 стовпців і там легко натрапити на помилку з кодом 1117, якщо спробувати зробити те саме.
Двигун Cassandra орієнтований на зберігання великих обсягів даних у розподіленій системі без майстра, і у вищезгаданій CAP-теоремі Cassandra більше про AP, тобто доступність даних і стійкість до поділу партицій. Таким чином, цей інструмент може чудово підійти, якщо потрібно тільки писати в цю базу і досить рідко читати. І тут логічно використовувати Cassandra як "холодне" сховище. Тобто як довготривале надійне місце зберігання великих масивів історичних даних, які рідко потрібні, але при необхідності їх можна дістати. Проте заради повноти картини протестуємо і її. Але, як я говорив раніше, немає бажання активно переписувати код під обране БД-рішення, тому тестувати ми її будемо дещо обмежено — без адаптації структури бази під специфіку Cassandra.
Прометей
Ну, і вже з інтересу ми вирішили протестувати продуктивність сторожа Prometheus — просто для того, щоб зрозуміти, швидше ми поточних рішень чи повільніше і наскільки.
Методика та результати тестування
Отже, ми протестували 5 баз даних у наступних 6 конфігураціях: ClickHouse (1 нода), ClickHouse (розподілена таблиця на 3 ноди), InfluxDB, Mysql 8, Cassandra (3 ноди) та Prometheus. План тестування такий:
- заливаємо історичні дані за тиждень (840 млн значень за добу; 208 тисяч метрик);
- генеруємо навантаження на запис (розглядали 6 режимів навантаження, див. нижче);
- паралельно із записом періодично робимо вибірки, емулюючи запити користувача, що працює з графіками. Щоб не надто ускладнювати, вибирали дані за 10 метриками (якраз стільки їх на графіку CPU) за тиждень.
Навантажуємо, емулюючи поведінку агента нашого моніторингу, який відправляє у кожну метрику значення раз на 15 секунд. При цьому нам цікаво варіювати:
- загальна кількість метрик, до яких пишуться дані;
- інтервал відправлення значень одну метрику;
- розмір батчу.
Про розмір батчу. Оскільки майже всі наші піддослідні бази не рекомендується навантажувати одиничними інсертами, нам потрібен буде релей, який збирає метрики, що приходять, і групує їх по скільки-небудь і пише в базу пакетним інсертом.
Також, щоб краще розуміти, як потім інтерпретувати отримані дані, уявімо, що ми не просто шлемо купу метрик, а метрики організовані на сервери — по 125 метрик на сервер. Тут сервер просто віртуальна сутність — просто щоб розуміти, що, наприклад, 10000 80 метрик відповідають приблизно XNUMX серверам.
І ось, з урахуванням цього всього, наші 6 режимів навантаження бази на запис:
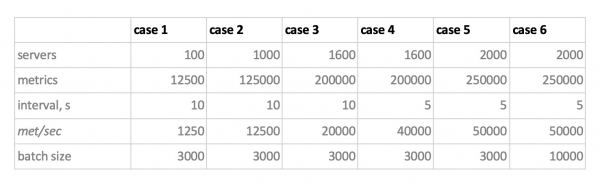
Тут є два моменти. По-перше, для кассандри такі розміри батчів виявилися занадто великими, там ми використовували значення 50 або 100. А по-друге, оскільки прометеус працює строго в режимі pull, тобто. сам ходить і забирає дані із джерел метрик (і навіть pushgateway, незважаючи на назву, докорінно ситуацію не змінює), відповідні навантаження були реалізовані за допомогою комбінації static configs.
Результати тестування такі:
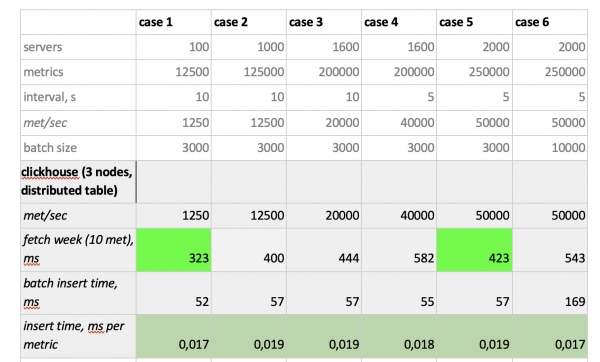
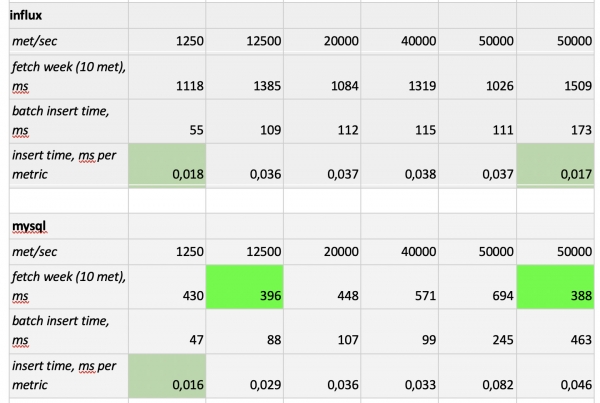
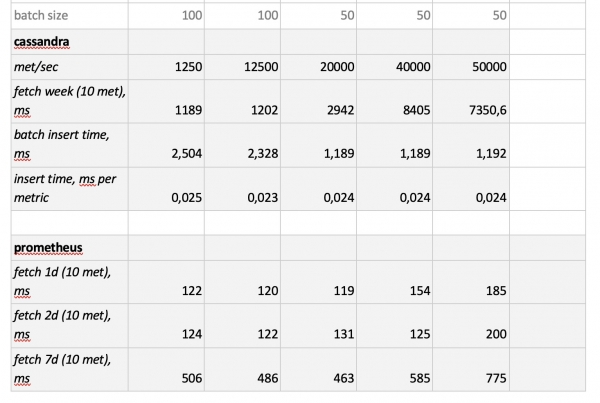
Що варто відзначити: фантастично швидкі вибірки з Prometheus'a, жахливо повільні вибірки з Cassandra, неприйнятно повільні вибірки з InfluxDB; за швидкістю запису всіх переміг ClickHouse, а Prometheus у конкурсі не бере участі, тому що він робить інсерти сам усередині себе і ми нічого не заміряємо.
У підсумку: найкраще себе показали ClickHouse і InfluxDB, але кластер з Influx'а можна побудувати тільки на основі Enterprise-версії, яка коштує грошей, а ClickHouse нічого не вартий і зроблений в Росії. Логічно, що у США вибір, мабуть, на користь inInfluxDB, а в нас - на користь ClickHouse'а.
Джерело: habr.com
