

Про що ми розповімо:
Як швидко розгорнути загальне сховище для двох серверів на базі рішень DRBD+OCFS2.
Для кого це буде корисно:
Туторіал стане корисним системним адміністраторам та всім, хто обирає спосіб реалізації сховища або хочуть спробувати рішення.
Від яких рішень ми відмовилися і чому
Часто ми стикаємося із ситуацією, коли нам потрібно реалізувати на невеликому web-кластері загальне сховище з гарною продуктивністю на читання – запис. Ми пробували різні варіанти реалізації загального сховища для наших проектів, але мало що було здатне задовольнити нас одразу за декількома показниками. Зараз розповімо чому.
- Glusterfs не влаштував нас продуктивністю на читання та запис, виникали проблеми з одночасним читанням великої кількості файлів, було високе навантаження на CPU. Проблему з читанням файлів можна було вирішити, звертаючись за ними безпосередньо в brick-і, але це не завжди можна застосувати і в цілому неправильно.
- Ceph не сподобався надмірною складністю, яка може бути шкідливою на проектах з 2-4 серверамиособливо якщо проект згодом обслуговують. Знову ж таки, є серйозні обмеження щодо продуктивності, що змушують будувати окремі storage кластери, як і з glusterfs.
- Використання одного nfs сервера для реалізації загального сховища викликає питання щодо відмовостійкості.
- s3 - відмінне популярне рішення для деякого кола завдань, але це і не файлова система, що звужує сферу застосування.
- lsyncd. Якщо ми вже почали говорити про «не-файлові системи», то варто пройтися і з цього популярного рішення. Мало того, що воно не підходить для двостороннього обміну (але якщо дуже хочеться, то можна), то ще й не стабільно працює на великій кількості файлів. Приємним доповненням до всього є те, що воно є однопоточним. Причина в архітектурі програми: вона використовує inotify для моніторингу об'єктів роботи, які навішує при запуску та при перескануванні. Як засіб передачі використовується rsync.
Туторіал: як розгорнути загальне сховище на базі drbd+ocfs2
Одним із найбільш зручних рішень для нас стала зв'язка ocfs2+drbd. Зараз ми розповімо, як можна швидко розгорнути спільне сховище для двох серверів з урахуванням даних рішень. Але спочатку трохи про компоненти:
ДРБД - Система зберігання зі стандартного постачання Linuxщо дозволяє реплікувати дані між серверами блоками. Основне застосування полягає у побудові відмовостійких сховищ.
OCFS2 — файлова система, що забезпечує використання одного і того ж сховища декількома системами. Входить у постачання Linux і представляє собою модуль ядра і userspace інструментарій для роботи з ФС. OCFS2 можна використовувати не тільки поверх DRBD, а й поверх iSCSI з множинним підключенням. У прикладі ми використовуємо DRBD.
Усі дії виробляються на ubuntu server 18.04 у мінімальній конфігурації.
Крок 1. Налаштовуємо DRBD:
У файлі /etc/drbd.d/drbd0.res описуємо наш віртуальний блоковий пристрій /dev/drbd0:
resource drbd0 {
syncer { rate 1000M; }
net {
allow-two-primaries;
after-sb-0pri discard-zero-changes;
after-sb-1pri discard-secondary;
after-sb-2pri disconnect;
}
startup { become-primary-on both; }
on drbd1 {
meta-disk internal;
device /dev/drbd0;
disk /dev/vdb1;
address 10.10.10.192:7789;
}
on drbd2 {
meta-disk internal;
device /dev/drbd0;
disk /dev/vdb1;
address 10.10.10.193:7789;
}
}
meta-disk internal — використовувати ті ж самі блокові пристрої для зберігання метаданих
device /dev/drbd0 використовувати /dev/drbd0 як шлях до drbd тому.
disk /dev/vdb1 - Використовувати /dev/vdb1
syncer { rate 1000M; } - Використовувати гігабіт пропускної спроможності каналу
allow-two-primaries - важлива опція, що дозволяє ухвалення змін на двох primary серверах
after-sb-0pri, after-sb-1pri, after-sb-2pri - Опції, що відповідають за дії вузла при виявленні splitbrain. Докладніше можна переглянути в документації.
become-primary-on both - Встановлює обидві ноди в primary.
У нашому випадку ми маємо дві абсолютно однакові ВМ, з виділеною віртуальною мережею пропускною здатністю 10 гігабіт.
У прикладі мережеві імена двох нод кластера — це drbd1 і drbd2. Для правильної роботи необхідно зіставити в / etc / hosts імена та ip адреси вузлів.
10.10.10.192 drbd1
10.10.10.193 drbd2Крок 2. Налаштовуємо ноди:
На обох серверах виконуємо:
drbdadm create-md drbd0
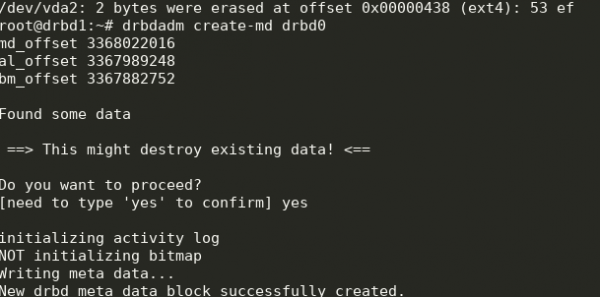
modprobe drbd
drbdadm up drbd0
cat /proc/drbdОтримуємо таке:

Можна запускати синхронізацію. На першій ноді потрібно виконати:
drbdadm primary --force drbd0Дивимося статус:
cat /proc/drbd

Чудово, почалася синхронізація. Чекаємо на закінчення і бачимо картину:

Крок 3. Запускаємо синхронізацію на другій ноді:
drbdadm primary --force drbd0
Отримуємо таке:

Тепер ми можемо писати в DRBD з двох серверів.
Крок 4. Встановлення та налаштування ocfs2.
Будемо використовувати досить тривіальну конфігурацію:
cluster:
node_count = 2
name = ocfs2cluster
node:
number = 1
cluster = ocfs2cluster
ip_port = 7777
ip_address = 10.10.10.192
name = drbd1
node:
number = 2
cluster = ocfs2cluster
ip_port = 7777
ip_address = 10.10.10.193
name = drbd2
Її потрібно записати в /etc/ocfs2/cluster.conf на обох нодах.
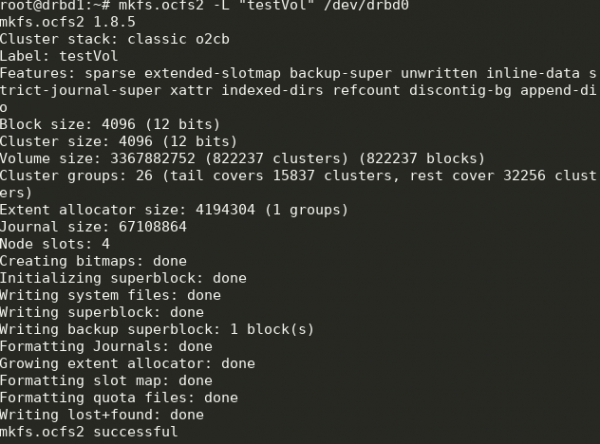
Створюємо ФС на drbd0 на будь-якій ноді:
mkfs.ocfs2 -L "testVol" /dev/drbd0
Тут ми створили ФС із міткою testVol на drbd0, використовуючи параметри за замовчуванням.
У /etc/default/o2cb необхідно виставити (як у файлі конфігурації)
O2CB_ENABLED=true
O2CB_BOOTCLUSTER=ocfs2cluster і виконати на кожній ноді:
o2cb register-cluster ocfs2clusterПісля цього вмикаємо і додаємо в автозапуск всі необхідні нам unit-и:
systemctl enable drbd o2cb ocfs2
systemctl start drbd o2cb ocfs2Частина цього вже буде запущена у процесі налаштування.
Крок 5. Додаємо точки монтування до fstab на обох нодах:
/dev/drbd0 /media/shared ocfs2 defaults,noauto,heartbeat=local 0 0Директорія /media/shared при цьому має бути створена заздалегідь.
Тут ми використовуємо опції noauto, яка означає, що ФС не буде змонтована при старті (вважаю за краще монтувати мережеві фс через systemd) і heartbeat = local, що означає використання сервісу heartbeat на кожній ноді. Існує ще global heartbeat, який більше підходить для великих кластерів.
Далі можна змонтувати /media/shared та перевірити синхронізацію вмісту.
Готово!
В результаті ми отримуємо більш-менш стійке до відмови сховище з можливістю масштабування і пристойною продуктивністю.
Джерело: habr.com
