

Прим. перев.: Ця стаття, написана Galo Navarro, що обіймає посаду Principal Software Engineer в європейській компанії Adevinta, - захоплююче і повчальне «розслідування» в галузі експлуатації інфраструктури. Її оригінальна назва була трохи доповнена у перекладі через те, що пояснює автор на самому початку.
Примітка від автора: Схоже, ця публікація набагато більше уваги, ніж очікувалося. Я досі отримую гнівні коментарі про те, що назва статті вводить в оману і деякі читачі засмучені. Я розумію причини того, що відбувається, тому, незважаючи на ризик зірвати всю інтригу, хочу відразу розповісти, про що ця стаття. При переході команд на Kubernetes я спостерігаю цікаву річ: щоразу, коли виникає проблема (наприклад, зростання затримок після міграції), насамперед звинувачують Kubernetes, проте потім виявляється, що оркестратор загалом не винен. Ця стаття розповідає про один із таких випадків. Її назва повторює вигук одного з наших розробників (потім ви переконаєтеся, що Kubernetes тут зовсім ні до чого). У ній ви не знайдете несподіваних одкровень про Kubernetes, але можете розраховувати на пару хороших уроків про складні системи.
Кілька тижнів тому моя команда займалася міграцією одного мікросервісу на основну платформу, що включає CI/CD, робоче середовище на основі Kubernetes, метрики та інші корисності. Переїзд мав пробний характер: ми планували взяти його за основу та перенести ще приблизно 150 сервісів у найближчі місяці. Всі вони відповідають за роботу деяких із найбільших онлайн-майданчиків Іспанії (Infojobs, Fotocasa та ін.).
Після того, як ми розгорнули додаток у Kubernetes і перенаправили на нього частину трафіку, на нас чекав тривожний сюрприз. Затримка (latency) запитів у Kubernetes була в 10 разів вищою, ніж у EC2. Загалом було необхідно або шукати вирішення цієї проблеми, або відмовлятися від міграції мікросервісу (і, можливо, від усього проекту).
Чому в Kubernetes затримка настільки вища, ніж у EC2?
Щоб знайти вузьке місце, ми зібрали метрики по всьому шляху запиту. Наша архітектура проста: API-шлюз (Zuul) проксирує запити до екземплярів мікросервісу в EC2 або Kubernetes. У Kubernetes ми використовуємо NGINX Ingress Сontroller, а бекенди є звичайними об'єктами типу з JVM-додатком на платформі Spring.
EC2
+---------------+
| +---------+ |
| | | |
+-------> BACKEND | |
| | | | |
| | +---------+ |
| +---------------+
+------+ |
Public | | |
-------> ZUUL +--+
traffic | | | Kubernetes
+------+ | +-----------------------------+
| | +-------+ +---------+ |
| | | | xx | | |
+-------> NGINX +------> BACKEND | |
| | | xx | | |
| +-------+ +---------+ |
+-----------------------------+Здавалося, що проблема пов'язана із затримкою на початковому етапі роботи в бекенді (я помітив проблемну ділянку на графіку як «хх»). У EC2 відповідь програми займав близько 20 мс. У Kubernetes затримка зростала до 100-200 мс.
Ми швидко відкинули ймовірних підозрюваних, пов'язаних із зміною середовища виконання. Версія JVM залишилася незмінною. Проблеми контейнеризації також були ні до чого: програма вже успішно працювала в контейнерах у EC2. Завантаження? Але ми спостерігали високі затримки навіть у 1 запиті на секунду. Паузами на складання сміття також можна було знехтувати.
Один із наших адміністраторів Kubernetes поцікавився, чи немає у додатку зовнішніх залежностей, оскільки в минулому запити до DNS викликали схожі проблеми.
Гіпотеза 1: роздільна здатність імен DNS
При кожному запиті наша програма від одного до трьох разів звертається до екземпляра AWS Elasticsearch у домені на кшталт elastic.spain.adevinta.com. Усередині контейнерів у нас тому ми можемо перевірити, чи дійсно пошук домену займає тривалий час.
DNS-запити із контейнера:
[root@be-851c76f696-alf8z /]# while true; do dig "elastic.spain.adevinta.com" | grep time; sleep 2; done
;; Query time: 22 msec
;; Query time: 22 msec
;; Query time: 29 msec
;; Query time: 21 msec
;; Query time: 28 msec
;; Query time: 43 msec
;; Query time: 39 msecАналогічні запити з одного з екземплярів EC2, де працює програма:
bash-4.4# while true; do dig "elastic.spain.adevinta.com" | grep time; sleep 2; done
;; Query time: 77 msec
;; Query time: 0 msec
;; Query time: 0 msec
;; Query time: 0 msec
;; Query time: 0 msecВраховуючи, що пошук займає близько 30 мс, стало зрозуміло, що дозвіл DNS при зверненні до Elasticsearch дійсно робить внесок у зростання затримки.
Однак це було дивно з двох причин:
- У нас вже є маса додатків у Kubernetes, які взаємодіють із ресурсами AWS, але не страждають від великих затримок. Якою б не була причина, вона стосується саме цієї нагоди.
- Ми знаємо, що JVM здійснює in-memory-кешування DNS. У наших образах значення TTL прописано в
$JAVA_HOME/jre/lib/security/java.securityта встановлено на 10 секунд:networkaddress.cache.ttl = 10. Іншими словами, JVM має кешувати всі DNS-запити на 10 секунд.
Щоб підтвердити першу гіпотезу, ми вирішили на якийсь час відмовитися від звернень до DNS і подивитися, чи проблема зникне. Спочатку ми вирішили переналаштувати додаток, щоб він зв'язувався з Elasticsearch безпосередньо за IP-адресою, а не через доменне ім'я. Це потребувало б виправлення коду і нового розгортання, тому ми просто зіставили домен з його IP-адресою в /etc/hosts:
34.55.5.111 elastic.spain.adevinta.comТепер контейнер отримував IP майже миттєво. Це призвело до деякого покращення, але ми лише трохи наблизилися до очікуваного рівня затримки. Хоча дозвіл DNS займав багато часу, справжня причина, як і раніше, вислизала від нас.
Діагностика за допомогою мережі
Ми вирішили проаналізувати трафік із контейнера за допомогою tcpdump, щоб простежити, що саме відбувається в мережі:
[root@be-851c76f696-alf8z /]# tcpdump -leni any -w capture.pcap Потім ми надіслали кілька запитів і завантажили їх capture (kubectl cp my-service:/capture.pcap capture.pcap) для подальшого аналізу в .
У DNS-запитах не було нічого підозрілого (крім однієї дрібниці, про яку я розповім пізніше). Але були певні дива у тому, як наш сервіс обробляв кожен запит. Нижче наведено скріншот capture'а, що показує прийняття запиту до початку відповіді:
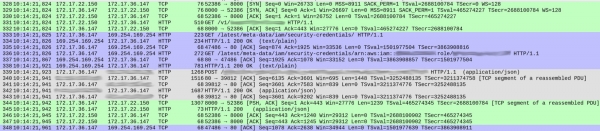
Номери пакетів наведено у першому стовпці. Для ясності я виділив кольором різні потоки TCP.
Зелений потік, що починається з 328 пакета, показує, як клієнт (172.17.22.150) встановив TCP-з'єднання з контейнером (172.17.36.147). Після первинного рукостискання (328-330), пакет 331 приніс HTTP GET /v1/.. - Вхідний запит до нашого сервісу. Весь процес зайняв 1 мс.
Сірий потік (з пакета 339) показує, що наш сервіс надіслав HTTP-запит до екземпляра Elasticsearch (TCP-рукостискання відсутнє, оскільки використовується вже наявне з'єднання). На це пішло 18 мс.
Поки що все нормально, і часи приблизно відповідають очікуваним затримкам (20-30 мс при вимірах з клієнта).
Однак синя секція займає 86 мс. Що у ній відбувається? З пакетом 333 наш сервіс надіслав HTTP GET-запит на /latest/meta-data/iam/security-credentials, а відразу після нього, за тим же TCP-з'єднанням, ще один GET-запит на /latest/meta-data/iam/security-credentials/arn:...
Ми виявили, що це повторюється з кожним запитом у всьому трасуванні. Дозвіл DNS дійсно трохи повільніший у наших контейнерах (пояснення цього феномена дуже цікаво, але я прибережу його для окремої статті). Виявилося, що причиною великих затримок є звернення до сервісу AWS Instance Metadata під час кожного запиту.
Гіпотеза 2: зайві звернення до AWS
Обидва endpoint'а належать . Наш мікросервіс використовує цей сервіс під час роботи з Elasticsearch. Обидва дзвінки є частиною базового процесу авторизації. Endpoint, до якого звертається при першому запиті, видає роль IAM, пов'язану з екземпляром.
/ # curl http://169.254.169.254/latest/meta-data/iam/security-credentials/
arn:aws:iam::<account_id>:role/some_roleДругий запит звертається до другого endpoint'у за тимчасовими повноваженнями для цього екземпляра:
/ # curl http://169.254.169.254/latest/meta-data/iam/security-credentials/arn:aws:iam::<account_id>:role/some_role`
{
"Code" : "Success",
"LastUpdated" : "2012-04-26T16:39:16Z",
"Type" : "AWS-HMAC",
"AccessKeyId" : "ASIAIOSFODNN7EXAMPLE",
"SecretAccessKey" : "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY",
"Token" : "token",
"Expiration" : "2017-05-17T15:09:54Z"
} Клієнт може користуватися ними протягом невеликого періоду часу і періодично повинен отримувати нові сертифікати (до них Expiration). Модель проста: AWS проводить часту ротацію тимчасових ключів з міркувань безпеки, але клієнти можуть кешувати їх на кілька хвилин, компенсуючи зниження продуктивності, пов'язане з отриманням нових сертифікатів.
AWS Java SDK має на себе взяти обов'язки щодо організації цього процесу, проте з якоїсь причини цього не відбувається.
Провівши пошук по issues на GitHub, ми натрапили на проблему . Вона допомогла нам визначити напрямок, у якому слід «копати» далі.
AWS SDK оновлює сертифікати під час однієї з наступних умов:
- Термін закінчення їхньої дії (
Expiration) потрапляє вEXPIRATION_THRESHOLD, жорстко встановлений код на 15 хвилин. - З моменту останньої спроби оновити сертифікати пройшло більше часу, ніж
REFRESH_THRESHOLD, за'hardcode'ений на 60 хвилин.
Щоб переглянути фактичний термін закінчення одержуваних нами сертифікатів, ми виконали наведені вище cURL-команди з контейнера та з екземпляра EC2. Час дії сертифіката, отриманого з контейнера, виявився набагато коротшим: рівно 15 хвилин.
Тепер все стало зрозумілим: для першого запиту наш сервіс отримував тимчасові сертифікати. Оскільки термін їхньої дії не перевищував 15 хвилин, при подальшому запиті AWS SDK вирішував оновити їх. І таке відбувалося з кожним запитом.
Чому термін дії сертифікатів став коротшим?
Сервіс AWS Instance Metadata призначений для роботи з екземплярами EC2, а не Kubernetes. З іншого боку, нам не хотілося змінювати додатковий інтерфейс. Для цього ми скористалися — інструментом, який за допомогою агентів на кожному вузлі Kubernetes дозволяє користувачам (інженерам, що розгортають додатки в кластер), привласнювати IAM-ролі контейнерам у pod'ах так, ніби вони є інстансами EC2. KIAM перехоплює виклики до сервісу AWS Instance Metadata та обробляє їх зі свого кешу, попередньо отримавши від AWS. З погляду програми нічого не змінюється.
KIAM постачає короткострокові сертифікати pod'ам. Це розумно, якщо врахувати, що середня тривалість існування pod'а менша, ніж екземпляра EC2. За замовчуванням термін дії сертифікатів .
У результаті, якщо накласти обидва значення за умовчанням одна на одну, виникає проблема. Кожен сертифікат, наданий програмою, закінчується через 15 хвилин. При цьому AWS Java SDK примусово оновлює будь-який сертифікат, до закінчення якого залишається менше 15 хвилин.
В результаті, тимчасовий сертифікат примусово оновлюється з кожним запитом, що спричиняє пару звернень до API AWS і призводить до значного збільшення затримки. В AWS Java SDK ми знайшли , В якому згадується аналогічна проблема.
Рішення виявилося простим. Ми просто переналаштували KIAM на запит сертифікатів із більш тривалим терміном дії. Як тільки це сталося, запити стали проходити без участі сервісу AWS Metadata, а затримка впала навіть до більш низького рівня, ніж у EC2.
Висновки
Виходячи з нашого досвіду з міграціями, можна сказати, що одне з найчастіших джерел проблем — це не помилки в Kubernetes чи інших елементах платформи. Також він не пов'язаний з будь-якими фундаментальними вадами в мікросервісах, які ми переносимо. Проблеми часто виникають тому, що ми з'єднуємо разом різні елементи.
Ми перемішуємо складні системи, які ніколи раніше не взаємодіяли одна з одною, очікуючи, що разом вони утворюють єдину, більшу систему. На жаль, чим більше елементів, тим більше простір для помилок, тим вища ентропія.
У нашому випадку висока затримка не була результатом помилок чи поганих рішень у Kubernetes, KIAM, AWS Java SDK чи нашому мікросервісі. Вона стала підсумком об'єднання двох незалежних параметрів, заданих за замовчуванням: одного в KIAM, іншого в AWS Java SDK. Окремо обидва параметри мають сенс: і активна політика оновлення сертифікатів в AWS Java SDK, і короткий термін дії сертифікатів у KAIM. Але якщо зібрати їх разом, результати стають непередбачуваними. Два незалежних і логічних рішення не повинні мати сенс при об'єднанні.
PS від перекладача
Дізнатися докладніше про архітектуру утиліти KIAM для інтеграції AWS IAM з Kubernetes можна в від її авторів.
А в нашому блозі також читайте:
- «»;
- «»;
- «»;
- «».
Джерело: habr.com
