

У цій статті я розповім про ситуацію, яка нещодавно сталася з одним із серверів нашої хмари VPS, поставивши мене в глухий кут на кілька годин. Я близько 15 років займаюся конфігуруванням і траблшутингом серверів Linux, але цей випадок зовсім не вкладається в мою практику - я зробив кілька хибних припущень і трохи зневірився до того, як зміг правильно визначити причину проблеми і вирішити її.
преамбула
Ми експлуатуємо хмару середніх розмірів, яку будуємо на типових серверах наступного конфігу – 32 ядра, 256 GB RAM та NVMe накопичувач PCI-E Intel P4500 розміром 4TB. Нам дуже подобається ця конфігурація, оскільки вона дозволяє не думати про нестачу IO, забезпечивши коректне обмеження на рівні типів інстансів (примірників) VM. Оскільки NVMe Intel має вражаючу продуктивність, ми можемо одночасно забезпечити як повне надання IOPS машинам, так і резервне копіювання сховища на сервер резервних копій з нульовим IOWAIT.
Ми ставимося до тих самих старовірів, які не використовують гіперконвергентні SDN та інші стильні, модні, молодіжні штуки для зберігання томів VM, вважаючи, що чим простіше система, тим простіше її блукати в умовах "головний гуру поїхав у гори". У підсумку ми зберігаємо томи VM у форматі QCOW2 у XFS або EXT4, яка розгорнута поверх LVM2.
Використовувати QCOW2 нас змушує ще й продукт, який ми використовуємо для оркестрації – Apache CloudStack.
Для виконання резервного копіювання ми знімаємо повний образ тому як знімок LVM2 (так, ми знаємо, що знімки LVM2 гальмівні, але Intel P4500 нас рятує і тут). Ми робимо lvmcreate -s .. та за допомогою dd надсилаємо резервну копію на віддалений сервер зі сховищем ZFS. Тут ми все ж таки злегка прогресивні — все ж таки ZFS вміє зберігати дані в стислому вигляді, а ми можемо їх швидко відновлювати за допомогою DD або діставати окремі томи VM за допомогою mount -o loop ....
Можна, звичайно, знімати і не повний образ LVM2, а монтувати файлову систему в режимі
ROі копіювати самі образи QCOW2, однак, ми стикалися з тим, що XFS від цього ставало погано, причому не відразу, а не прогнозовано. Ми дуже не любимо, коли хости-гіпервізори "залипають" раптово у вихідні, вночі чи свята через помилки, які незрозуміло коли відбудуться. Тому для XFS ми не використовуємо монтування знімків у режиміROдля отримання томів, а просто копіюємо весь том LVM2.
Швидкість резервного копіювання на сервер резервних копій визначається в нашому випадку продуктивністю сервера бекапу, яка становить близько 600-800 MB/s для даних, що не стискаються, подальший обмежувач — канал 10Gbit/s, яким підключений сервер резервних копій до кластера.
При цьому на один сервер резервних копій заливають одночасно резервні копії 8 серверів гіпервізорів. Таким чином, дискова та мережева підсистеми сервера резервних копій, будучи повільнішими, не дають перевантажити дискові підсистеми хостів-гіпервізорів, оскільки просто не в змозі обробити, скажімо, 8 GB/сек, які невимушено можуть видати хости-гіпервізори.
Вищеописаний процес копіювання дуже важливий для подальшого оповідання, включаючи і деталі - використання швидкого накопичувача Intel P4500, використання NFS і, ймовірно, використання ZFS.
Історія про резервне копіювання
На кожному вузлі-гіпервізорі у нас є невеликий розділ SWAP розміром 8 GB, а сам вузол-гіпервізор ми "розкочуємо" за допомогою DD із еталонного образу. Для системного тому на серверах ми використовуємо 2xSATA SSD RAID1 або 2xSAS HDD RAID1 на апаратному контролері LSI або HP. Загалом, нам абсолютно не різниці, що там усередині, оскільки системний том у нас працює в режимі "майже readonly", крім SWAP-а. А оскільки у нас дуже багато RAM на сервері, і вона на 30-40% вільна, то ми про SWAP не думаємо.
Процес створення резервної копії. Виглядає це завдання приблизно так:
#!/bin/bash
mkdir -p /mnt/backups/volumes
DIR=/mnt/images-snap
VOL=images/volume
DATE=$(date "+%d")
HOSTNAME=$(hostname)
lvcreate -s -n $VOL-snap -l100%FREE $VOL
ionice -c3 dd iflag=direct if=/dev/$VOL-snap bs=1M of=/mnt/backups/volumes/$HOSTNAME-$DATE.raw
lvremove -f $VOL-snapЗверніть увагу на ionice -c3, За фактом ця штука для NVMe пристроїв абсолютно марна, оскільки планувальник IO для них встановлений як:
cat /sys/block/nvme0n1/queue/scheduler
[none] Однак, у нас є ряд legacy-вузлів із звичайними SSD RAID-ами, для них це актуально, от і переїжджає ЯК Є. Загалом це просто цікавий шматочок коду, який пояснює марність ionice у разі такої конфігурації.
Зверніть увагу на прапор iflag=direct для DD. Ми використовуємо direct IO повз буферний кеш, щоб не робити зайвих заміщень буферів IO при читанні. Однак, oflag=direct ми не робимо, оскільки ми зустрічали проблеми з продуктивністю ZFS під час його використання.
Ця схема використовується нами успішно протягом кількох років без проблем.
І тут почалося… Ми виявили, що для одного з вузлів перестало виконуватися резервне копіювання, а попереднє виконалося із жахливим IOWAIT під 50%. При спробі зрозуміти чому не відбувається копіювання, ми зіткнулися з феноменом:
Volume group "images" not foundПочали думати про "кінець прийшов Intel P4500", проте, перед тим як вимкнути сервер для заміни накопичувача, було необхідно все ж таки виконати резервне копіювання. Полагодили LVM2 за допомогою відновлення метаданих з бекапу LVM2:
vgcfgrestore imagesЗапустили резервне копіювання і побачили таку картину маслом:
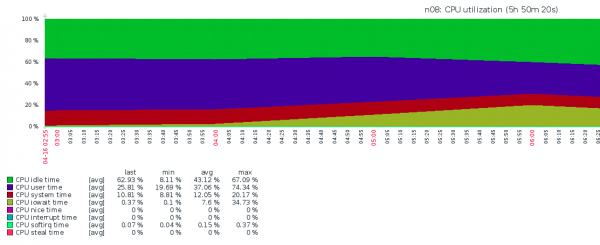
Знову дуже засумували — було зрозуміло, що так жити не можна, оскільки всі VPS будуть страждати, а значить страждатимемо і ми. Що відбувалося, зовсім незрозуміло. iostat показував жалюгідні IOPS-и і високий IOWAIT. Ідей, окрім як "давайте замінимо NVMe", не було, але вчасно сталося осяяння.
Розбір ситуації за кроками
Історичний журнал. Декілька днів раніше на даному сервері потрібно створити велику VPS-ку з 128 GB RAM. Пам'яті начебто вистачало, але для підстрахування виділили ще 32 GB для розділу підкачування. VPS була створена, успішно вирішила своє завдання та інцидент забутий, а SWAP-розділ залишився.
Особливості конфігурації. Для всіх серверів хмари параметр vm.swappiness був встановлений у значення за замовчуванням 60. А SWAP було створено на SAS HDD RAID1.
Що відбувалося (на думку редакції). При резервному копіюванні DD видавав багато даних для запису, які містилися в буфери RAM перед записом NFS. Ядро системи, керуючись політикою swappiness, переміщало багато сторінок пам'яті VPS в область підкачки, що знаходилася на повільному томі HDD RAID1. Це призводило до того, що IOWAIT дуже зростав, але не за рахунок IO NVMe, а за рахунок IO HDD RAID1.
Як проблему було вирішено. Було вимкнено розділ підкачки 32GB. Це зайняло 16 годин, про те, як і чому так повільно відключається SWAP можна почитати окремо. Змінено параметри swappiness на значення рівне 5 у всій хмарі.
Як би цього могло не статися. По-перше, якби SWAP був на SSD RAID або NVMe пристрої, по-друге, якби не було NVMe-пристрою, а був би повільніший пристрій, який би не видавав такий обсяг даних - за іронією, проблема трапилася від того, що NVMe надто швидкий.
Після цього все стало працювати як і раніше – з нульовим IOWAIT.
Джерело: habr.com
