

Хочу поділитись з вами моїм першим успішним досвідом відновлення повної працездатності бази даних Postgres. З СУБД Postgres я познайомився півроку тому, до цього досвіду адміністрування баз даних я не мав зовсім.

Я працюю напів-DevOps інженером у великій IT-компанії. Наша компанія займається розробкою програмного забезпечення для високонавантажених сервісів, я ж відповідаю за працездатність, супровід та деплою. Переді мною поставили стандартне завдання: оновити програму на одному сервері. Програма написана на Django, під час оновлення виконуються міграції (зміна структури бази даних), і перед цим процесом ми знімаємо повний дамп бази даних через стандартну програму pg_dump про всяк випадок.
Під час зняття дампи виникла непередбачена помилка (версія Postgres – 9.5):
pg_dump: Oumping the contents of table “ws_log_smevlog” failed: PQgetResult() failed.
pg_dump: Error message from server: ERROR: invalid page in block 4123007 of relatton base/16490/21396989
pg_dump: The command was: COPY public.ws_log_smevlog [...]
pg_dunp: [parallel archtver] a worker process dled unexpectedly Помилка "invalid page in block" говорить про проблеми на рівні файлової системи, що дуже погано. На різних форумах пропонували зробити FULL VACUUM з опцією zero_damaged_pages для вирішення цієї проблеми. Що ж, попрробеум...
Підготовка до відновлення
УВАГА! Обов'язково зробіть резервну копію Postgres перед спробою відновити базу даних. Якщо у вас віртуальна машина, зупиніть базу даних та зробіть снепшот. Якщо немає можливості зробити снепшот, зупиніть базу та скопіюйте вміст каталогу Postgres (включаючи wal-файли) у надійне місце. Головне у нашій справі – не зробити гірше. Прочитайте .
Оскільки в цілому база у мене працювала, я обмежився звичайним дампом бази даних, але виключив таблицю зі пошкодженими даними (опція -T, -exclude-table = TABLE pg_dump).
Сервер був фізичним, зняти снепшот було неможливо. Бекап знято, рухаємося далі.
Перевірка файлової системи
Перед спробою відновлення бази даних необхідно переконатися, що у нас все гаразд із файловою системою. І у разі помилок виправити їх, оскільки в іншому випадку можна зробити лише гірше.
У моєму випадку файлова система з базою даних була примонтована в "/srv" та тип був ext4.
Зупиняємо базу даних: systemctl stop postgresql@9.5-main.service та перевіряємо, що файлова система ніким не використовується і її можна відмонтувати за допомогою команди також:
lsof +D /srv
Мені довелося ще зупинити базу даних redis, оскільки вона також використовувала "/srv". Далі я відмонтував / SRV (umount).
Перевірка файлової системи була виконана за допомогою утиліти e2fsck з ключиком -f (Force checking even if filesystem is marked clean):
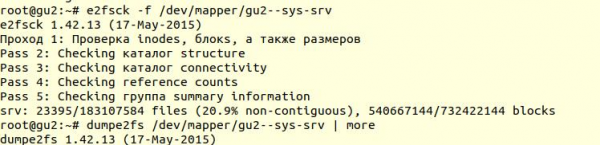
Далі за допомогою утиліти dumpe2fs (sudo dumpe2fs /dev/mapper/gu2-sys-srv | grep checked) можна переконатися, що перевірка дійсно була проведена:

e2fsck каже, що проблем на рівні файлової системи ext4 не знайдено, а це означає, що можна продовжувати спроби відновити базу даних, а точніше повернутися до vacuum full (Зрозуміло, необхідно примонтувати файлову систему назад і запустити базу даних).
Якщо у вас фізичний сервер, то обов'язково перевірте стан дисків (через smartctl -a /dev/XXX) або RAID-контролера, щоб переконатися, що проблема не на апаратному рівні. У моєму випадку RAID виявився «залізним», тому я попросив місцевого адміна перевірити стан RAID (сервер був за кілька сотень кілометрів від мене). Він сказав, що помилок немає, а це означає, що ми можемо точно почати відновлення.
Спроба 1: zero_damaged_pages
Підключаємося до бази через psql акаунтом, що має права суперкористувача. Нам потрібний саме суперкористувач, т.к. опцію zero_damaged_pages може міняти лише він. У моєму випадку це postgres:
psql -h 127.0.0.1 -U postgres -s [database_name]
Опція zero_damaged_pages потрібна для того, щоб проігнорувати помилки читання (з сайту postgrespro):
При виявленні пошкодженого заголовка сторінки Postgres Pro зазвичай повідомляє про помилку та перериває поточну транзакцію. Якщо параметр zero_damaged_pages увімкнено, система видає попередження, обнуляє пошкоджену сторінку в пам'яті і продовжує обробку. Ця поведінка руйнує дані, а саме усі рядки у пошкодженій сторінці.
Включаємо опцію та пробуємо робити full vacuum таблиці:
VACUUM FULL VERBOSE 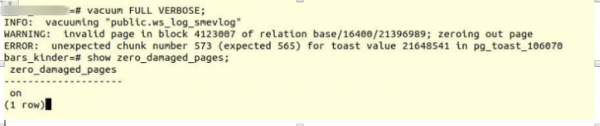
На жаль, невдача.
Ми зіткнулися з аналогічною помилкою:
INFO: vacuuming "“public.ws_log_smevlog”
WARNING: invalid page in block 4123007 of relation base/16400/21396989; zeroing out page
ERROR: unexpected chunk number 573 (expected 565) for toast value 21648541 in pg_toast_106070– механізм зберігання «довгих даних» у Poetgres, якщо вони не розміщуються в одну сторінку (за замовчуванням 8кб).
Спроба 2: reindex
Перша порада з гугла не допомогла. Після кількох хвилин пошуку я знайшов другу пораду – зробити переіндексувати ушкодженої таблиці. Цю пораду я зустрічав у багатьох місцях, але вона не вселяла довіри. Зробимо reindex:
reindex table ws_log_smevlog 
переіндексувати завершився без проблем.
Однак це не допомогло, VACUUM FULL аварійно завершувався із аналогічною помилкою. Оскільки я звик до невдач, я почав шукати порад в інтернеті далі і натрапив на досить цікаву .
Спроба 3: SELECT, LIMIT, OFFSET
У статті вище пропонували подивитися таблицю рядково та видалити проблемні дані. Для початку необхідно було переглянути всі рядки:
for ((i=0; i<"Number_of_rows_in_nodes"; i++ )); do psql -U "Username" "Database Name" -c "SELECT * FROM nodes LIMIT 1 offset $i" >/dev/null || echo $i; doneУ моєму випадку таблиця містила 1 628 991 рядків! По-хорошому потрібно було подбати про але це тема для окремого обговорення. Була субота, я запустив цю команду в tmux і пішов спати:
for ((i=0; i<1628991; i++ )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog LIMIT 1 offset $i" >/dev/null || echo $i; doneДо ранку я вирішив перевірити, як справи. На мій подив, я виявив, що за 20 годин було проскановано лише 2% даних! Чекати 50 днів я не хотів. Ще один повний провал.
Але я не став здаватися. Мені стало цікаво, чому ж сканування тривало так довго. З документації (знову на postgrespro) я дізнався:
OFFSET вказує пропустити вказану кількість рядків, перш ніж почати видавати рядки.
Якщо вказано і OFFSET, і LIMIT, система спочатку пропускає OFFSET рядків, а потім починає підраховувати рядки для обмеження LIMIT.Застосовуючи LIMIT, важливо також використовувати пропозицію ORDER BY, щоб рядки результату видавалися в певному порядку. Інакше повертатимуться непередбачувані підмножини рядків.
Очевидно, що вищенаписана команда була помилковою: по-перше, не було order by, Результат міг вийти хибним. По-друге, Postgres спочатку повинен був просканувати та пропустити OFFSET-рядок, і зі зростанням OFFSET продуктивність знижувалася б ще сильніше.
Спроба 4: зняти дамп у текстовому вигляді
Далі мені на думку спала, здавалося б, геніальна ідея: зняти дамп у текстовому вигляді і проаналізувати останній записаний рядок.
Але для початку ознайомимося зі структурою таблиці ws_log_smevlog:
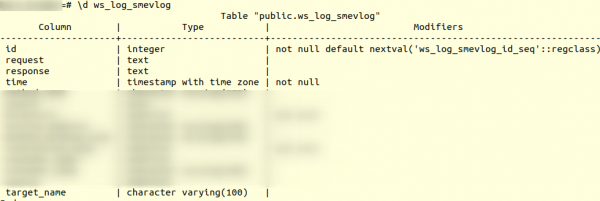
У нашому випадку у нас є стовпець "Ідентифікатор"що містить унікальний ідентифікатор (лічильник) рядка. План був такий:
- Починаємо знімати дамп у текстовому вигляді (у вигляді sql-команд)
- У певний момент часу зняття дампа перервалося б через помилку, але тектовий файл все одно зберігся б на диску
- Дивимося кінець текстового файлу, тим самим ми знаходимо ідентифікатор (id) останнього рядка, який успішно знявся
Я почав знімати дамп у текстовому вигляді:
pg_dump -U my_user -d my_database -F p -t ws_log_smevlog -f ./my_dump.dumpЗняття дампа, як і очікувалося, перервалося з тією ж помилкою:
pg_dump: Error message from server: ERROR: invalid page in block 4123007 of relatton base/16490/21396989 Далі через хвіст я переглянув кінець дампа (tail -5 ./my_dump.dump) виявив, що дамп перервався на рядку з id 186 525. «Отже, проблема у рядку з id 186, вона бита, її і треба видалити!» – подумав я. Але, зробивши запит до бази даних:
«select * from ws_log_smevlog where id=186529» виявилося, що з цим рядком все нормально ... Рядки з індексами 186 - 530 теж працювали без проблем. Чергова "геніальна ідея" провалилася. Пізніше я зрозумів, чому так сталося: при видаленні зміни даних з таблиці вони не видаляються фізично, а позначаються як «мертві кортежі», далі приходить автовакуум і позначає ці рядки віддаленими та дозволяє використовувати ці рядки повторно. Щоб зрозуміти, якщо дані в таблиці змінюються і включені autovacuum, то вони не зберігаються послідовно.
Спроба 5: SELECT, FROM, WHERE id=
Невдачі роблять нас сильнішими. Не варто ніколи здаватися, треба йти до кінця і вірити в себе та свої можливості. Тому я вирішив спробувати ще один варіант: просто переглянути всі записи в базі даних по одному. Знаючи структуру моєї таблиці (див. вище), ми маємо поле id, яке є унікальним (первинним ключем). У таблиці у нас 1 628 991 рядків та id йдуть по порядку, а це означає, що ми можемо просто перебрати їх по одному:
for ((i=1; i<1628991; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; doneЯкщо хтось не розуміє, команда працює наступним чином: переглядає рядково таблицю і відправляє stdout в / dev / nullале якщо команда SELECT провалюється, то виводиться текст помилки (stderr відправляється в консоль) і виводиться рядок, що містить помилку (завдяки ||, яка означає, що у select виникли проблеми (код повернення команди не 0)).
Мені пощастило, у мене були створені індекси по полю id:

А це означає, що знаходження рядка з потрібним ID не повинен займати багато часу. Теоретично має спрацювати. Що ж, запускаємо команду в tmux і йдемо спати.
На ранок я виявив, що переглянуто близько 90 000 записів, що становить трохи більше 5%. Відмінний результат, якщо порівнювати із попереднім способом (2%)! Але чекати 20 днів не хотілося.
Спроба 6: SELECT, FROM, WHERE id >= and id
У замовника під БД було виділено відмінний сервер: двопроцесорний Intel Xeon E5-2697 v2, у нашому розташуванні було цілих 48 потоків! Навантаження на сервері було середнє, ми без особливих проблем могли забрати близько 20 потоків. Оперативної пам'яті також було достатньо: аж 384 гігабайти!
Тому команду потрібно було розпаралелити:
for ((i=1; i<1628991; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; doneТут можна було написати красивий та елегантний скрипт, але я вибрав найшвидший спосіб розпаралелювання: розбити діапазон 0-1628991 вручну на інтервали по 100 000 записів та запустити окремо 16 команд виду:
for ((i=N; i<M; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; doneАле це не все. За ідеєю, підключення до бази даних також забирає якийсь час і системні ресурси. Підключати 1 було не дуже розумно, погодьтеся. Тому давайте при одному підключенні витягувати 628 рядків замість одного. У результаті команда перетворилася на це:
for ((i=N; i<M; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; doneВідкриваємо 16 вікон у сесії tmux та запускаємо команди:
1) for ((i=0; i<100000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done 2) for ((i=100000; i<200000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done … 15) for ((i=1400000; i<1500000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done 16) for ((i=1500000; i<1628991; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done
За день я отримав перші результати! А саме (значення XXX та ZZZ вже не збереглися):
ERROR: missing chunk number 0 for toast value 37837571 in pg_toast_106070
829000
ERROR: missing chunk number 0 for toast value XXX in pg_toast_106070
829000
ERROR: missing chunk number 0 for toast value ZZZ in pg_toast_106070
146000Це означає, що у нас три рядки містять помилку. id першого і другого проблемного запису перебували між 829 000 і 830 000, id третього – між 146 000 і 147 000. Далі ми мали просто знайти точне значення id проблемних записів. Для цього переглядаємо наш діапазон із проблемними записами з кроком 1 та ідентифікуємо id:
for ((i=829000; i<830000; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done 829417 ERROR: unexpected chunk number 2 (expected 0) for toast value 37837843 in pg_toast_106070 829449 for ((i=146000; i<147000; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done 829417 ERROR: unexpected chunk number ZZZ (expected 0) for toast value XXX in pg_toast_106070 146911
щасливий фінал
Ми знайшли проблемні рядки. Заходимо в базу через psql і пробуємо їх видалити:
my_database=# delete from ws_log_smevlog where id=829417;
DELETE 1
my_database=# delete from ws_log_smevlog where id=829449;
DELETE 1
my_database=# delete from ws_log_smevlog where id=146911;
DELETE 1На мій подив, записи віддалилися без будь-яких проблем навіть без опції zero_damaged_pages.
Потім я підключився до бази, зробив VACUUM FULL (думаю робити було необов'язково), і нарешті успішно зняв бекап за допомогою pg_dump. Дамп знявся без жодних помилок! Проблему вдалося вирішити у такий тупий спосіб. Радості не було меж, після стількох невдач вдалося знайти рішення!
Подяки та висновок
Ось так вийшов мій перший досвід відновлення реальної бази даних Postgres. Цей досвід запам'ятаю надовго.
Ну і насамкінець, хотів би сказати спасибі компанії PostgresPro за перекладену документацію російською мовою та за , які дуже допомогли під час аналізу проблеми.
Джерело: habr.com
