

Процес оновлення для вашого кластера Kubernetes
У якийсь момент при використанні кластера Kubernetes виникає потреба в оновленні працюючих нід. Воно може включати оновлення пакетів, оновлення ядра або розгортання нових образів віртуальних машин. У термінології Kubernetes це називається .
Цей пост є частиною циклу з 4 постів:
- Цей пост.
- Коректне завершення роботи pod'ів у Kubernetes-кластері.
- Відкладене завершення pod'а при його видаленні
- Як уникнути простою в роботі Kubernetes-кластера за допомогою PodDisruptionBudgets
(прим. пер. Переклади інших статей циклу чекайте найближчим часом)
У цій статті ми будемо описувати всі інструменти, які надає Kubernetes для досягнення нульового часу простою для працюючих у кластері нод.
визначення проблеми
Спочатку ми будемо використовувати наївний підхід, визначати проблеми та оцінювати потенційні ризики цього підходу та накопичувати знання для вирішення кожної з проблем, з якими зустрінемося протягом усього циклу. В результаті ми отримаємо конфігурацію, в якій використовуються lifecycle hooks, readiness probes та Pod disruption budgets для досягнення нашого нульового часу простою.
Щоб розпочати наш шлях, давайте візьмемо конкретний приклад. Припустимо, у нас є кластер Kubernetes з двох нод, в якому запущено додаток із двома pod'aми, що знаходяться за Service:
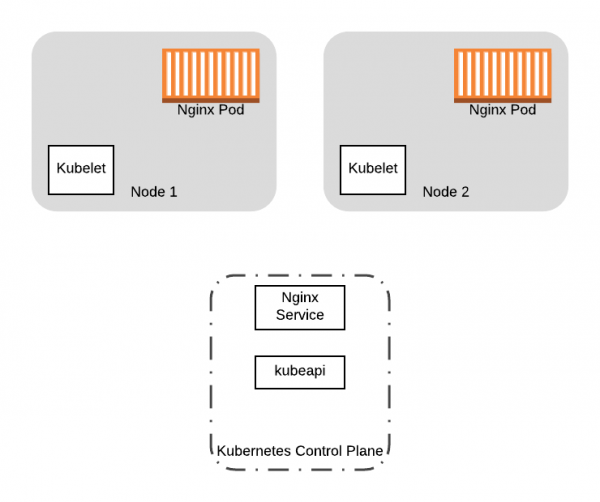
Почнемо з двох pod'ів з Nginx та Service запущених на наших двох нодах Kubernetes-кластера.
Ми хочемо оновити версію ядра двох робочих нод у нашому кластері. Як ми це зробимо? Простим рішенням було завантажити нові ноди з оновленою конфігурацією і потім вимкнути старі ноди, одночасно із запуском нових. Хоча це спрацює, буде кілька проблем із таким підходом:
- Коли ви вимкнете старі ноди, то запущені на них pod'и також будуть вимкнені. Що якщо pod'и потрібно очистити для коректного вимкнення? Система віртуалізації, яку ви використовуєте, може не дочекатися закінчення процесу очищення.
- Що якщо ви вимкнете всі ноди одночасно? Ви отримаєте пристойний простий доки pod'и переїдуть на нові ноди.
Нам потрібен спосіб коректної міграції pod'ів зі старих нод і при цьому потрібно бути впевненими, що жоден з наших робочих процесів не запущений, доки ми вносимо зміни для ноди. Або коли ми робимо повну заміну кластера, як у прикладі (тобто замінюємо образи VM), ми хочемо перенести працюючі програми зі старих нод на нові. В обох випадках ми хочемо запобігти плануванню нових pod'ів на старих нодах, а потім виселити з них усі запущені pod'и. Для досягнення цієї мети ми можемо використовувати команду kubectl drain.
Перерозподіл усіх pod'ів з ноди
Операція drain дозволяє перерозподілити всі pod'и з ноди. У процесі виконання drain нода позначається як unschedulable (прапор) NoSchedule). Це запобігає появі на ній нових pod'ів. Потім drain починає виселяти pod'и з ноди, завершує роботу контейнерів, які на даний момент запущені на ноді, відправляючи сигнал. TERM контейнерів у pod'є.
Хоча kubectl drain відмінно впорається з виселенням pod'ів, є ще два фактори, які можуть стати причиною збою при виконанні операції drain:
- Ваша програма повинна вміти коректно завершуватися при подачі
TERMсигналу. Коли pod'и виселяються, Kubernetes надсилає сигналTERMконтейнерів і чекає на їх зупинку задану кількість часу, після чого, якщо вони не зупинилися, завершує їх примусово. У будь-якому випадку, якщо Ваш контейнер не сприйме сигнал коректно, ви все ще можете згасити pod'и некоректно, якщо вони в даний момент працюють (наприклад, виконується транзакція в БД). - Ви втрачаєте всі pod'и, в яких міститься ваша програма. Воно може бути недоступне на момент запуску нових контейнерів на нових нодах або якщо ваші pod'и розгорнуті без контролерів, вони можуть не перезапуститися в принципі.
Уникаємо простою
Щоб мінімізувати час простою від voluntary disruption, як, наприклад, від операції drain для ноди, Kubernetes надає наступні варіанти обробки збоїв:
В інших частинах циклу ми будемо використовувати дані функції Kubernetes для пом'якшення наслідків перенесення pod'ів. Щоб легше простежити основну думку, ми будемо використовувати наш приклад вище з наступною ресурсною конфігурацією:
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.15
ports:
- containerPort: 80
---
kind: Service
apiVersion: v1
metadata:
name: nginx-service
spec:
selector:
app: nginx
ports:
- protocol: TCP
targetPort: 80
port: 80Ця конфігурація є мінімальним прикладом Deployment, що управляє pod'ами nginx в кластері. Крім того, конфігурація описує ресурс Service, який можна використовувати для доступу до pod'nginx в кластері.
Протягом усього циклу ми ітеративно розширюватимемо цю конфігурацію, щоб у фіналі вона включала всі можливості, що надаються Kubernetes для зменшення часу простою.
Щоб отримати повністю впроваджену та протестовану версію оновлень кластера Kubernetes для нульового часу простою на AWS та інших ресурсах, відвідайте .
Також читайте інші статті у нашому блозі:
Джерело: habr.com
