


Основна мета Patroni – це забезпечення High Availability для PostgreSQL. Але Patroni — це лише template, а чи не готовий інструмент (що, загалом, і в документації). На перший погляд, налаштувавши Patroni у тестовій лабі, можна побачити, який це чудовий інструмент і як він легко обробляє наші спроби розвалити кластер. Однак на практиці у виробничому середовищі не завжди все відбувається так красиво та елегантно, як у тестовій лабі.

Розповім трохи про себе. Я починав системним адміністратором. Працював у веб-розробці. З 2014-го року працюю у Data Egret. Компанія займається консалтингом у сфері Postgres. І ми обслуговуємо саме Postgres і щодня працюємо з Postgres, тому у нас є різна експертиза, пов'язана з експлуатацією.
І наприкінці 2018-го року ми почали потихеньку використовувати Patroni. І накопичився певний досвід. Ми якось діагностували його, тюнили, прийшли до своїх найкращих практик. І в цій доповіді я розповідатиму про них.
Крім Postgres, я люблю Linux. Люблю в ньому колупатися та досліджувати, люблю збирати ядра. Люблю віртуалізацію, контейнери, докер, Kubernetes. Мене це все цікавить, бо даються взнаки старі адмінські звички. Люблю розумітися на моніторингах. І люблю postgres'ові речі, пов'язані з адмінством, тобто реплікація, резервне копіювання. І у вільний час пишу на Go. Не являюсь software engineer, просто для себе пишу на Go. І мені це приносить задоволення.

- Я думаю, багато хто з вас знає, що в Postgres немає HA (High Availability) з коробки. Щоб отримати HA, потрібно щось поставити, налаштувати, докласти зусиль та отримати це.
- Є кілька інструментів і Patroni - це один з них, який вирішує HA досить круто і дуже добре. Але поставивши це все в тестовій лабі і запустивши, ми можемо подивитися, що все це працює, ми можемо відтворювати якісь проблеми, подивитися, як Patroni їх обслуговує. І побачимо, що все це чудово працює.
- Але на практиці ми стикалися з різними проблемами. І про ці проблеми я розповідатиму.
- Розповім, як ми це діагностували, що підкручували – чи це допомогло нам, чи не допомогло.

- Я не розповідатиму, як встановити Patroni, тому що можна нагуглити в інтернеті, можна подивитися файли конфігурації, щоб зрозуміти, як це все запускається, як налаштовується. Можна розібратися у схемах, архітектурах, знайшовши інформацію про це в інтернеті.
- Не розповідатиму про чужий досвід. Розповідатиму тільки про ті проблеми, з якими зіткнулися саме ми.
- І не розповідатиму про проблеми, які за межами Patroni та PostgreSQL. Якщо, наприклад, проблеми, пов'язані з балансуванням, коли у нас кластер розвалився, я про це не розповідатиму.

І невеликий disclaimer перед тим, як почати нашу доповідь.
Всі ці проблеми, з якими ми зіткнулися, були у нас у перші 6-7-8 місяців експлуатації. Згодом ми прийшли до своїх внутрішніх best practices. І проблеми у нас зникли. Тому доповідь заявлялася десь півроку тому, коли все це було свіжо в голові і я це все чудово пам'ятав.
Під час підготовки доповіді я вже піднімав старі постмортеми, дивився логи. І частина деталей могла забути, або частина якихось деталей могли бути недосліджена в ході розбору проблем, тому в якихось моментах може здатися, що проблеми розглянуті не повністю, або є недолік інформації. І тому прошу мене за цей момент вибачити.

Що таке Patroni?
- Це шаблон для побудови HA. Так написано у документації. І на мій погляд, це дуже правильне уточнення. Patroni – це не срібна куля, яка вирішить усі ваші проблеми, тобто потрібно докласти зусиль, щоб воно почало працювати та приносити користь.
- Це агентська служба, яка встановлюється на кожному сервісі з даною базою, і яка є свого роду init-системою для вашого Postgres. Вона запускає Postgres, зупиняє, перезапускає, змінює конфігурацію та змінює топологію вашого кластера.
- Відповідно, щоб зберігати стан кластера, його поточне уявлення, як він виглядає, потрібне якесь сховище. І з цього погляду Patroni пішов шляхом збереження State в зовнішній системі. Це система розподіленого сховища конфігурації. Це можуть бути Etcd, Consul, ZooKeeper, або kubernetes'кий Etcd, тобто якийсь із цих варіантів.
- І однією з особливостей Patroni - це те, що автофайловер ви отримуєте з коробки, тільки настроївши його. Якщо взяти для порівняння Repmgr, файловер там йде в комплекті. З Repmgr ми отримуємо switchover, але якщо хочемо автофайловер, його потрібно додатково налаштувати. У Patroni вже є автофайловер із коробки.
- І є багато інших речей. Наприклад, обслуговування конфігурацій, наливання нових реплік, резервне копіювання тощо. Але це за межами доповіді, про це я не розповідатиму.

І невеликий підсумок – це те, що основне завдання Patroni – це добре та надійно робити автофайловер, щоб кластер у нас залишався працездатним і додаток не помічав змін у топології кластера.

Але коли ми починаємо використовувати Patroni, наша система стає трохи складнішою. Якщо раніше у нас був Postgres, то за використання Patroni ми отримуємо сам Patroni, ми отримуємо DCS, де зберігається state. І все це має якось працювати. Тому що може зламатися?
Може зламатися:
- Може зламатися Postgres. Це може бути майстер або репліка, щось із них може вийти з ладу.
- Може зламатися сам Patroni.
- Може зламатися DCS де зберігається state.
- І може зламатися мережа.
Всі ці моменти я розглядатиму в доповіді.

Я розглядатиму випадки в міру їх ускладнення, не з точки зору того, що кейс зачіпає багато компонентів. А з погляду суб'єктивних відчуттів, що цей кейс був для мене складним, його було складно розбирати… і навпаки, якийсь кейс був легким і його було легко розбирати.

І перший випадок найпростіший. Це той випадок, коли ми взяли кластер баз даних і на цьому кластері розгорнули наше сховище DCS. Це найпоширеніша помилка. Це помилка побудови архітектур, тобто поєднання різних компонентів в одному місці.
Отже, відбувся файловер, ідемо розбиратися з тим, що сталося.

І тут нас цікавить, коли відбувся файловер. Т. е. нас цікавить ось цей момент часу, коли відбулася зміна стану кластера.
Але файловер який завжди одномоментний, т. е. не займає якусь одиницю часу, може затягтися. Він може бути тривалим у часі.
Тому він має час початку і час завершення, т. е. це тривала подія. І ми ділимо всі події на три інтервали: у нас є час до файловера, під час файловера та після файловера. Т. е. ми розглядаємо всі події в цій тимчасовій шкалі.

І насамперед, коли стався файловер, ми шукаємо причину, що сталося, що стало причиною того, що призвело до файловеру.
Якщо ми подивимось на логи, то це будуть класичні логі Patroni. Він у них повідомляє, що сервер став майстром, і роль майстра перейшла на цей вузол. Тут це підсвічено.

Далі нам потрібно зрозуміти, чому стався файловер, тобто які відбулися події, які змусили роль майстра переїхати з одного вузла на інший. І в цьому випадку тут все просто. У нас є помилка взаємодії із системою зберігання. Майстер зрозумів, що він не може працювати з DCS, тобто виникла якась проблема із взаємодією. І він каже, що не може бути більшим майстром і складає з себе повноваження. Ось цей рядок «demoted self» говорить саме про це.

Якщо подивитися на події, які передували файловеру, то ми там можемо побачити ті самі причини, які стали проблемою для продовження роботи майстра.
Якщо подивитися на логі Patroni, то ми побачимо, що у нас є безліч всяких помилок, тайм-аутів, тобто агент Patroni не може працювати з DCS. В даному випадку це Consul agent, з яким йде спілкування портом 8500.
І проблема тут полягає в тому, що Patroni та база даних запущені на одному хості. І на цьому ж вузлі було запущено Consul-сервер. Створивши навантаження на сервері, ми створили проблеми для серверів Consul. Вони не змогли нормально спілкуватись.

Через якийсь час, коли навантаження спало, наш Patroni зміг знову спілкуватися з агентами. Нормальна робота відновилась. І той самий сервер Pgdb-2 знову став майстром. Т. е. був невеликий фліп, через який вузол склав із себе повноваження майстра, а потім знову їх на себе взяв, тобто все повернулося, як було.

І це можна розцінювати як помилкове спрацювання, або можна розцінювати, що Patroni зробив все правильно. Т. е. він зрозумів, що не може підтримувати стан кластера і зняв із себе повноваження.
І тут проблема виникла через те, що Consul-сервера знаходяться на тому самому обладнанні, що й бази. Відповідно, будь-яке навантаження: чи це навантаження на диски чи процесори, воно також впливає на взаємодію з кластером Consul.

І ми вирішили, що це не повинно жити разом, ми виділили окремий кластер для Consul. І Patroni працював уже з окремим Consul'ом, тобто був окремо кластер Postgres, окремо кластер Consul. Це базова інструкція, як треба всі ці речі розносити та тримати, щоб вона не жила разом.
Як варіант, можна покрутити параметри ttl, loop_wait, retry_timeout, тобто спробувати за рахунок збільшення цих параметрів пережити ці короткочасні піки навантаження. Але це не найкращий варіант, тому що ось це навантаження може бути тривалим за часом. І ми просто вийдемо за ці ліміти цих параметрів. І це може не зовсім допомогти.
Перша проблема, як ви зрозуміли, є простою. Ми взяли та DCS поклали разом з базою, отримали проблему.

Друга проблема схожа на першу. Вона схожа на те, що у нас знову є проблеми взаємодії з системою DCS.

Якщо ми подивимося на логи, то побачимо, що ми знову помилка комунікації. І Patroni каже, що я не можу взаємодіяти з DCS, тому поточний майстер переходить у режим репліки.
Старий майстер стає реплікою, тут Patroni відпрацьовує, як і належить. Він запускає pg_rewind, щоб відмотати журнал транзакції і потім підключитися до нового майстра і вже наздогнати новий майстер. Тут Patroni відпрацьовує, як і належить.

Тут ми повинні знайти те місце, яке передувало файловеру, тобто ті помилки, які спричинили, чому у нас файловер стався. І в цьому плані із логами Patroni досить зручно працювати. Він із певним інтервалом пише одні й самі повідомлення. І якщо ми починаємо промотувати ці логи швидко, то ми з логів побачимо, що логи змінилися, отже, якісь проблеми почалися. Ми швидко повертаємось на це місце, дивимося, що відбувається.
І у нормальній ситуації логи виглядають приблизно так. Перевіряється власник блокування. І якщо власник, припустимо, змінився, то можуть настати якісь події, на які Patroni має відреагувати. Але в цьому випадку у нас все гаразд. Ми шукаємо те місце, коли почалися помилки.

І промотавши до того місця, коли помилки почали з'являтися, ми бачимо, що у нас відбувся автофайловер. І якщо у нас помилки були пов'язані з взаємодією з DCS і в нашому випадку ми використовували Consul, ми заразом дивимося і в логі Consul, що відбувалося там.
Приблизно зіставивши час файловера і час у логах Consul, бачимо, що у нас сусіди по Consul-кластеру почали сумніватися існування інших учасників Consul-кластера.

І якщо ще подивитися на логи інших Consul-агентів, там теж видно, що там якийсь мережевий колапс відбувається. І всі учасники Consul-кластера сумніваються у існуванні один одного. І це послужило поштовхом до файловеру.
Якщо подивитися, що відбувалося до цих помилок, то можна побачити, що є всякі помилки, наприклад, deadline, RPC falled, тобто явно якась проблема при взаємодії учасників Consul-кластера між собою.

Найпростіша відповідь – це лагодити мережу. Але мені стоячи на трибуні легко про це заявляти. Але обставини складаються так, що не завжди замовник може собі дозволити лагодити мережу. Він може жити в ДЦ і може не мати можливостей ремонтувати мережу, впливати на обладнання. І тому потрібні якісь інші варіанти.

Варіанти є:
- Найпростіший варіант, який написаний, на мою думку, навіть у документації, це відключити Consul-перевірки, тобто просто передати порожній масив. І ми говоримо Consul-агенту не використовувати жодних перевірок. За рахунок цих перевірок ми можемо ігнорувати ці мережеві шторми та не ініціювати файловер.
- Інший варіант - це перевіряти ще раз raft_multiplier. Це параметр самого Consul-сервера. За замовчуванням він виставлений у значення 5. Це значення рекомендовано для документації для staging оточення. По суті це впливає частоту обміну повідомленнями між учасниками Consul мережі. По суті цей параметр впливає на швидкості службового спілкування між учасниками Consul-кластера. І для production його вже рекомендується зменшувати, щоб вузли частіше обмінювалися повідомленнями.
- Інший варіант, який ми почали використовувати, це збільшення пріоритету Consul процесів серед інших процесів для планувальника операційної системи. Є такий параметр «nice», він визначає пріоритет процесів який враховується планувальником ОС при плануванні. Ми взяли та Consul-агентам зменшили значення nice, тобто. підвищили пріоритет, щоб операційна система давала Consul процесам більше часу на роботу та виконання свого коду. У нашому випадку це вирішило нашу проблему.
- Інший варіант – це не використовувати Consul. У мене є товариш, який є великий прихильник Etcd. І ми з ним регулярно сперечаємося, що краще за Etcd або Consul. Але в плані, що краще, ми зазвичай з ним сходимося на думці, що Consul є агент, який повинен бути запущений на кожному вузлі з базою даних. Т. е. взаємодія Patroni з Consul-кластером йде через цей агент. І цей агент стає вузьким місцем. Якщо з агентом щось відбувається, Patroni вже не може працювати з Consul-кластером. І це проблема. У плані Etcd жодного агента немає. Patroni може працювати безпосередньо зі списком Etcd-серверів і вже спілкуватися з ними. У цьому плані, якщо ви використовуєте у себе в компанії Etcd, Etcd буде, напевно, кращим вибором, ніж Consul. Але ми в наших замовників завжди обмежені тим, що вибрав і використовує клієнт. І у нас здебільшого Consul у всіх клієнтів.
- І останній пункт – це переглянути значення параметрів. Ми можемо підняти ці параметри у велику сторону, сподіваючись, що наші короткочасні мережеві проблеми будуть короткими і не потраплять за інтервал цих параметрів. Таким чином, ми можемо зменшити агресивність Patroni на виконання автофайловера, якщо якісь мережеві проблеми виникають.
Я думаю, багато хто, хто використовують Patroni, знайомі з цією командою.
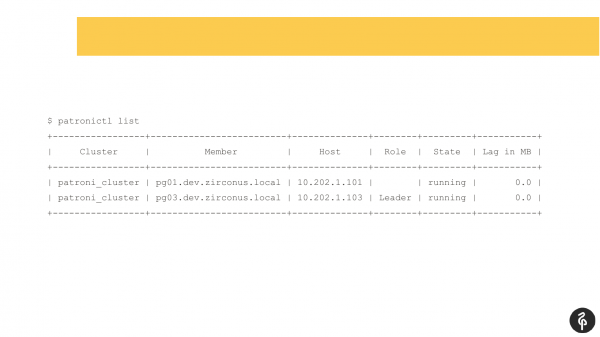
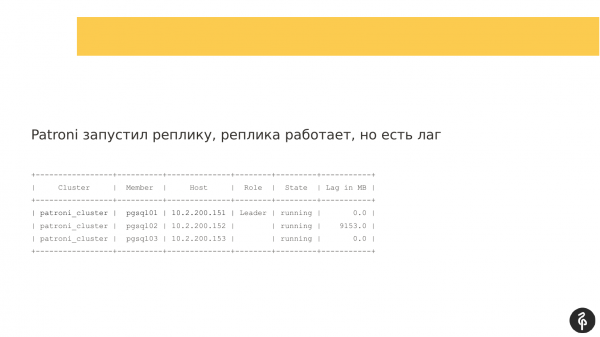
Ця команда показує стан кластера. І на перший погляд ця картина може видатися нормальною. У нас є майстер, у нас є репліка, лага реплікації немає. Але ця картина нормальна рівно доти, поки ми не знаємо, що в цьому кластері має бути три вузли, а не два.

Відповідно, відбувся автофайловер. І після цього автофайловера у нас репліка зникла. Нам потрібно з'ясувати, чому вона зникла і повернути її назад, відновити. І ми знову йдемо в логі та дивимося, чому у нас стався автофайловер.

У разі друга репліка стала майстром. Тут усе гаразд.

І нам треба дивитися вже на репліку, що відвалилася і яка не в кластері. Ми відкриваємо логі Patroni і дивимося, що в процесі підключення до кластера виникла проблема на стадії pg_rewind. Щоб підключитися до кластера потрібно відмотати журнал транзакції, запитати потрібний журнал транзакції з майстра і наздогнати майстра.
В даному випадку ми не маємо журналу транзакцій і репліка не може запуститися. Відповідно, ми Postgres зупиняємо помилково. І тому її немає у кластері.

Треба зрозуміти, чому її немає в кластері і чому не виявилося ліг. Ми йдемо на новий майстер і дивимось, що в нього в логах. Виявляється, коли робився pg_rewind відбувся checkpoint. І частину старих журналів транзакції просто перейменували. Коли старий майстер спробував підключитися до нового майстра та запросити ці логи, вони вже були перейменовані, їх просто не було.

Я порівнював timestamps, коли відбувалися ці події. І там різниця буквально в 150 мілісекунд, тобто в 369 мілісекунд завершився checkpoint, було перейменовано WAL-сегменти. І буквально в 517 за 150 мілісекунд запустився rewind на старій репліці. Т. е. буквально 150 мілісекунд нам вистачило, щоб репліка не змогла підключитися та заробити.

Які є варіанти?
Ми використовували спочатку слоти реплікації. Нам здавалося, що це добре. Хоча на першому етапі експлуатації ми слоти відключали. Нам здавалося, що, якщо слоти будуть накопичувати багато WAL-сегментів, ми можемо упустити майстер. Він упаде. Ми помучилися якийсь час без слотів. І зрозуміли, що нам слоти потрібні, ми повернули слоти.
Але тут є проблема, що коли майстер переходить у репліку, він видаляє слоти і разом зі слотами видаляє WAL-сегменти. І щоб унеможливити появу цієї проблеми, ми вирішили підняти параметр wal_keep_segments. Він за промовчанням 8 сегментів. Ми підняли до 1 і подивилися, скільки у нас вільного місця. І ми подарували 000 гігабайт на wal_keep_segments. Т. е. при перемиканні у нас завжди на всіх вузлах є запас у 16 гігабайтів журналів транзакцій.
І плюс - це ще актуально для тривалих maintenance завдань. Допустимо, нам треба оновити одну з реплік. І ми хочемо її вимкнути. Нам потрібно оновити софт, можливо, операційну систему, ще щось. І коли ми вимикаємо репліку, для цієї репліки також видаляється слот. І якщо ми використовуємо маленький wal_keep_segments, то за тривалої відсутності репліки, журнали транзакцій програються. Ми піднімемо репліку, вона запитатиме ті журнали транзакції, де вона зупинилася, але на майстрі їх може не опинитися. І репліка теж не зможе підключитись. Тому ми маємо великий запас журналів.

Ми маємо production-база. Там уже працюють проекти.
Відбувся файловер. Ми зайшли та подивилися – все гаразд, репліки на місці, лага реплікації немає. Помилок по журналах теж немає, все гаразд.
Продуктова команда каже, що начебто як мають бути якісь дані, але ми їх по одному джерелу бачимо, а в базі ми їх не бачимо. І треба зрозуміти, що з ними сталося.

Зрозуміло, що pg_rewind їх затер. Ми одразу це зрозуміли, але пішли дивитись, що відбувалося.

У логах ми завжди можемо знайти, коли стався файловер, хто став майстром і можемо визначити, хто був старим майстром і коли він захотів стати реплікою, тобто нам потрібні ці логи, щоб з'ясувати той обсяг журналів транзакцій, який був втрачений.
Наш старий майстер перезавантажився. І в автозапуску було прописано Patroni. Запустився Patroni. Він слідом запустив Postgres. Точніше перед запуском Postgres і перед тим як зробити його реплікою, Patroni запустив процес pg_rewind. Відповідно, він стер частину журналів транзакцій, скачав нові та підключився. Тут Patroni відпрацював шикарно, тобто як і належить. Кластер у нас відновився. У нас було 3 ноди, після файловера 3 ноди – все круто.

Ми втратили частину даних. І нам треба зрозуміти скільки ми втратили. Ми шукаємо саме той момент, коли у нас відбувався rewind. Ми можемо знайти це за такими записами у журналі. Запустився rewind, щось там зробив та закінчився.

Нам потрібно знайти ту позицію у журналі транзакцій, на якій зупинився старий майстер. В даному випадку – це ця позначка. І нам потрібна друга позначка, тобто та відстань, на яку відрізняється старий майстер від нового.
Ми беремо звичайний pg_wal_lsn_diff і порівнюємо ці дві позначки. І в цьому випадку ми отримуємо 17 мегабайт. Багато це чи мало кожен собі вирішує сам. Тому що для когось 17 мегабайт – це небагато, для когось це багато та неприпустимо. Тут вже кожен собі індивідуально визначає у відповідність до потребами бізнесу.

Але що ми з'ясували собі?
По-перше, ми повинні вирішити для себе – чи завжди нам потрібен автозапуск Patroni після перезавантаження системи? Найчастіше буває так, що ми маємо зайти на старий майстер, подивитися, як далеко він поїхав. Можливо проінспектувати сегменти журналу транзакцій, подивитися, що там. І зрозуміти – чи можемо ми ці дані втратити, чи нам потрібно в standalone-режимі запустити старий майстер, щоб витягти ці дані.
І тільки вже після цього маємо прийняти рішення, що ми можемо ці дані відкинути або ми можемо їх відновити, підключити цей вузол як репліку в наш кластер.
Крім цього, є параметр "maximum_lag_on_failover". За замовчуванням, якщо я не змінюю пам'ять, цей параметр має значення 1 мегабайт.
Як він працює? Якщо наша репліка відстає на 1 мегабайт даних з лагу реплікації, то ця репліка не бере участі у виборах. І якщо раптом відбувається файловер, Patroni дивиться, які репліки відстають. Якщо вони відстають на багато журналів транзакцій, вони не можуть стати майстром. Це дуже хороша захисна функція, що дозволяє не втратити багато даних.
Але тут є проблема в тому, що лаг реплікації у кластері Patroni та DCS оновлюється з певним інтервалом. На мою думку, 30 секунд значення ttl за промовчанням.
Відповідно, може бути ситуація, коли лаг реплікації для реплік в DCS один, а насправді може бути зовсім інший лаг або взагалі лага може не бути, тобто ця штука не є realtime. І вона завжди відображає реальну картину. І робити на ній наворочену логіку не варто.
І ризик втрати завжди залишається. І в гіршому випадку одна формула, а в середньому інша формула. Тобто, коли плануємо впровадження Patroni і оцінюємо, скільки даних ми можемо втратити, ми повинні закладатися на ці формули і приблизно представляти, скільки даних ми можемо втратити.
І гарна новина є. Коли старий майстер поїхав уперед, він може виїхати вперед за рахунок якихось фонових процесів. Т. е. якийсь був автовакуум, він написав дані, зберіг їх у журнал транзакції. І ці дані ми можемо легко ігнорувати і втратити. У цьому немає жодної проблеми.

І так виглядають логи у разі, якщо виставлений maximum_lag_on_failover і стався файловер, і потрібно вибрати нового майстра. Репліка оцінює себе як нездатну брати участь у виборах. І вона відмовляється від участі у перегонах за лідера. І вона чекає, коли буде обрано нового майстра, щоб потім до нього підключитися. Це додатковий захід від втрати даних.

Тут у нас продуктова команда написала, що їхній продукт має проблеми при роботі з Postgres. При цьому на сам майстер не можна зайти, тому що він недоступний за SSH. І автофайловер також не відбувається.
Цей хост відправили примусово у перезавантаження. Через перезавантаження стався автофайловер, хоча можна було зробити і ручний автофайловер, як я зараз розумію. І після перезавантаження ми вже йдемо дивитися, що ми мали з поточним майстром.
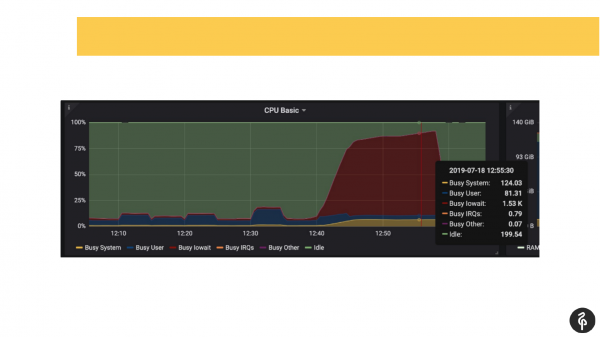
При цьому ми наперед знали, що у нас проблеми були з дисками, тобто ми вже з моніторингу знали, де копати і що шукати.

Ми залізли в postgres'овий лог, почали дивитися, що там відбувається. Ми побачили комміти, які тривають там по дві-три секунди, що зовсім не нормально. Ми побачили, що у нас автовакуум запускається дуже довго та дивно. І ми побачили часові файли на диску. Т. е. це все показники проблем з дисками.

Ми заглянули до системного dmesg (в лог ядерних повідомлень). І побачили, що ми маємо проблеми з одним із дисків. Дискова підсистемна була software Raid. Ми подивилися /proc/mdstat та побачили, що у нас не вистачає одного диска. Т. е. тут Raid з 8 дисків, у нас одного не вистачає. Якщо уважно роздивлятись слайд, то у висновку можна побачити, що у нас там sde відсутня. В нас, умовно кажучи, випав диск. Це стригерувало дискові проблеми, і програми теж зазнали проблем під час роботи з кластером Postgres.

І в даному випадку Patroni нам ніяк не допоміг би, тому що Patroni не має завдання відстежувати стан сервера, стан диска. І ми маємо такі ситуації відстежувати зовнішнім моніторингом. Ми до зовнішнього моніторингу додали моніторинг дисків оперативно.
І була така думка - а міг би нам допомогти фенсінг, чи софт watchdog? Ми подумали, що навряд чи він нам допоміг би в цьому випадку, тому що під час проблем Patroni продовжував взаємодіяти з кластером DCS і не бачив жодної проблеми. Т. е. з точки зору DCS і Patroni з кластером було все добре, хоча за фактом були проблеми з диском, були проблеми з доступністю бази.
На мій погляд, це одна з найдивніших проблем, яку я досліджував дуже довго, дуже багато ліг перечитав, переколупав і назвав її кластер-симулянтом.

Проблема полягала в тому, що старий майстер не міг стати нормальною реплікою, тобто Patroni його запускав, Patroni показував, що цей вузол присутня як репліка, але водночас не був нормальною реплікою. Зараз ви побачите чому. Це в мене збереглося з розбору проблеми.

І з чого все почалося? Почалося, як і в попередній проблемі, з дискових гальм. У нас були комміти за секунду, по дві.

Були обриви з'єднань, тобто клієнти рвалися.

Були блокування різної тяжкості.

І, відповідно, дискова підсистема не дуже чуйна.

І найзагадковіше для мене – це прилетів immediate shutdown request. Postgres має три режими вимкнення:
- Це graceful, коли ми чекаємо, коли всі клієнти відключаться самостійно.
- Є fast, коли ми змушуємо клієнтів вимкнутись, тому що ми йдемо на вимикання.
- І immediate. У цьому випадку immediate навіть не повідомляє клієнтам, що потрібно відключатися, він просто вимикається без попередження. А всім клієнтам вже операційною системою надсилається повідомлення RST (TCP-повідомлення, що з'єднання перервано і клієнту більше нічого ловити).
Хто надіслав цей сигнал? Фонові процеси Postgres один одному такі сигнали не надсилають, тобто це kill-9. Вони одне одному таке не шлють, вони тільки реагують, тобто це екстрений перезапуск Postgres. Хто його послав, я не знаю.
Я подивився по команді «last» і я побачив одну людину, яка теж залогінила цей сервер разом з нами, але я посоромився ставити запитання. Можливо, це був kill-9. Я в логах побачив kill -9, т.к. Postgres пише, що прийняв kill -9, але я не побачив цього у логах.

Розбираючись далі, я побачив, що Patroni не писав у ліг досить довго – 54 секунди. І якщо порівняти два timestamp, тут приблизно 54 секунди не було повідомлень.
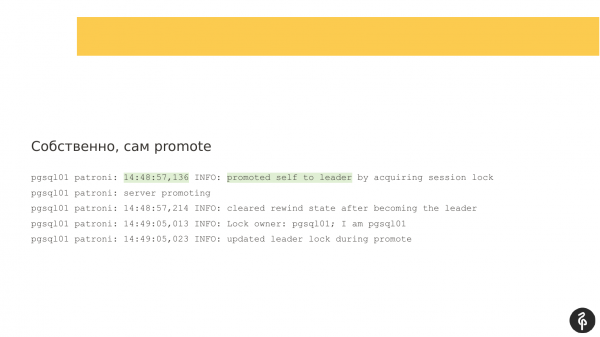
І за цей час відбувся автофайловер. Patroni тут знову відпрацював чудово. У нас старий майстер був недоступний, щось із ним відбувалося. І розпочалися вибори нового майстра. Тут усе відпрацювалося добре. У нас pgsql01 став новим лідером.

Ми маємо репліку, яка стала майстром. І є друга репліка. І з другою реплікою якраз були проблеми. Вона намагалася переконфігуруватись. Як я розумію, вона намагалася змінити recovery.conf, перезапустити Postgres та підключитися до нового майстра. Вона кожні 10 секунд пише повідомлення, що вона намагається, але в неї не виходить.

І під час цих спроб на старий майстер прилітає immediate-shutdown сигнал. Майстер перезапускається. І також recovery припиняється, тому що старий майстер іде у перезавантаження. Т. е. репліка не може до нього підключитися, тому що він в режимі вимкнення.

Якоїсь миті вона запрацювала, але реплікація при цьому не запустилася.
У мене є єдина гіпотеза, що в recovery.conf була адреса старого майстра. І коли з'явився новий майстер, то друга репліка, як і раніше, намагалася підключитися до старого майстра.
Коли Patroni запустився на другій репліці, вузол запустився, але не зміг підключитись по реплікації. І утворився лаг реплікації, який виглядав приблизно так. Т. е. всі три вузли були на місці, але другий вузол відставав.
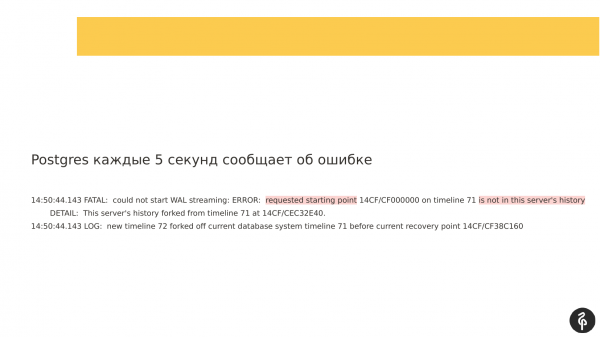
При цьому, якщо подивитися на логі, які писалися, можна було побачити, що реплікація не може запуститися, тому що журнали транзакцій відрізняються. І ті журнали транзакцій, які пропонує майстер, які вказані в recovery.conf, просто не підходять для нашого поточного вузла.

І тут я припустився помилки. Мені треба було прийти подивитися, що там у recovery.conf, щоб перевірити свою гіпотезу, що ми підключаємося не до того майстра. Але я тоді тільки-но розбирався з цим і мені це на думку не спало, або я побачив, що репліка відстає і її доведеться переналивати, тобто я якось абияк відпрацював. То був мій одвірок.

Через 30 хвилин уже прийшов адмін, тобто я перезапустив Patroni на репліці. Я вже на ній хрест поставив, я думав, що її доведеться переналивати. І подумав – перезапущу Patroni, можливо, вийде щось хороше. Запустився recovery. І база навіть відкрилася, вона була готова приймати з'єднання.
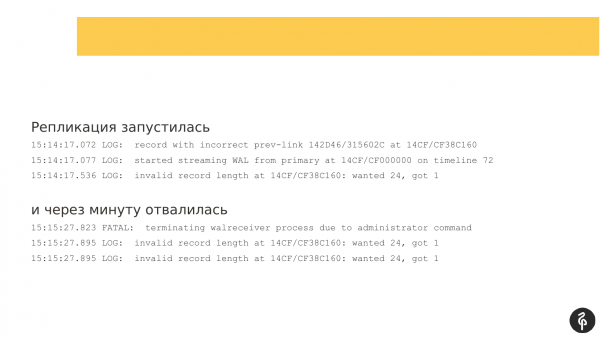
Реплікація запустилась. Але через хвилину вона відвалилася з помилкою, що їй не пасують журнали транзакцій.

Я подумав, що ще раз перезапущу. Я перезапустив ще раз Patroni, причому я не перезапускав Postgres, а перезапускав саме Patroni, сподіваючись, що він магічним чином запустить базу.

Реплікація знову запустилася, але позначки в журналі транзакцій відрізнялися, вони не були тими, які були за попередньої спроби запуску. Реплікація знову зупинилась. І повідомлення було вже трохи інше. І воно було для мене не надто інформативним.

І тут мені спадає на думку - а що, якщо я перезапущу Postgres, в цей час на поточному майстрі зроблю checkpoint, щоб посунути крапку в журналі транзакцій трохи вперед, щоб recovery почалося з іншого моменту? Плюс там ще були запаси WAL у нас.

Я перезапустив Patroni, зробив пару checkpoints на майстрі, пару рестарт-поінтів на репліці, коли вона відкрилася. І це допомогло. Я довго думав, чому це допомогло і як це спрацювало. І репліка запустилася. І реплікація більше не рвалася.

Така проблема для мене є однією з загадкових, над якою я досі ламаю голову, що там відбувалося насправді.
Які висновки тут? Patroni може відпрацювати, як задумано і без жодних помилок. Але при цьому це не 100% гарантія, що у нас все добре. Репліка може запуститися, але при цьому може перебувати у напів-робочому стані, і додатку не можна працювати з такою реплікою, тому що там будуть старі дані.
І після файловера завжди потрібно перевіряти, що у нас все гаразд із кластером, тобто є потрібна кількість реплік, немає лага реплікації.
І під час розгляду цих проблем я сформулюю рекомендації. Я спробував їх об'єднати у два слайди. Напевно, всі історії можна було поєднати у два слайди і лише їх розповісти.

Коли ви використовуєте Patroni, у вас обов'язково має бути моніторинг. Ви завжди повинні знати, коли відбувся автофайловер, тому що якщо ви не знаєте, що у вас був автофайловер, ви не контролюєте кластер. І це погано.
Після кожного файловера ми завжди повинні перевірити руками кластер. Ми повинні переконатися, що у нас завжди актуальна кількість реплік, немає лага реплікації, в логах немає помилок, пов'язаних із потоковою реплікацією, Patroni, системою DCS.
Автоматика може успішно відпрацювати, Patroni це дуже хороший інструмент. Він може відпрацювати, але це не спричинить кластер до потрібного стану. І якщо ми про це не дізнаємось, то у нас будуть проблеми.
І Patroni – це срібна куля. Ми все одно повинні мати уявлення, як працює Postgres, як працює реплікація та про те, як Patroni працює з Postgres, та як забезпечується взаємодія між вузлами. Це потрібно для того, щоб вміти лагодити руками проблеми, що виникають.

Як я підходжу до діагностики? Так склалося, що ми працюємо з різними клієнтами і стеку ELK ні в кого немає, і доводиться розбиратися в логах, відкривши 6 консолей і 2 вкладки. У одній вкладці – це логи Patroni кожному за вузла, на другий вкладці – це логи Consul, чи Postgres у разі потреби. Діагностувати це дуже важко.
Які я напрацював підходи? По-перше, я завжди дивлюся, коли прийшов файловер. І для мене це якийсь вододіл. Я дивлюся, що сталося до файловера, під час файловера та після файловера. Файловер має дві позначки: це час початку та кінця.
Далі я в логах дивлюся події до файловера, що передувало файловеру, тобто я шукаю причини, чому файловер стався.
І це дає картину розуміння, що відбувалося і що можна зробити в майбутньому, щоб такі обставини не настали (і як наслідок не відбулося файловерів).
І куди ми зазвичай дивимося? Я дивлюся:
- Спочатку у логі Patroni.
- Далі дивлюся логи Postgres, або логи DCS залежно від того, що в логах Patroni.
- І логи системи теж іноді дають розуміння того, що спричинило файловер.

Як я належу до Patroni? Patroni я ставлюся дуже добре. На мою думку, це найкраще, що є сьогодні. Я знаю багато інших продуктів. Це Stolon, Repmgr, Pg_auto_failover, PAF. 4 інструменти. Я пробував їх усі. Patroni мені сподобався найбільше.
Якщо мене запитають: «Я рекомендую Patroni?». Я скажу, що так, тому що Patroni мені подобається. І мені здається, я навчився його готувати.
Якщо вам цікаво подивитися, які ще бувають проблеми з Patroni, окрім тих проблем, які я озвучив, ви завжди можете сходити на сторінку на GitHub. Там багато різних історій та там обговорюється багато цікавих проблем. І за підсумком якісь баги були заведені та вирішені, тобто це цікаве чтиво.
Там є цікаві історії про те, як люди стріляють собі в ногу. Дуже пізнавально. Ти читаєш і розумієш, що так не треба робити. Поставив собі галочку.
І хотілося б сказати велике спасибі компанії Zalando за те, що вони розвивають цей проект, а саме Олександру Кукушкіну та Олексію Клюкіну. Олексій Клюкін – це один із співавторів, він уже в Zalando не працює, але це дві людини, які починали працювати з цим продуктом.
І я вважаю, що Patroni це дуже крута штука. Я задоволений, що вона є, із нею цікаво. І дякую всім контриб'юторам, які пишуть патчі в Patroni. Я сподіваюся, що Patroni буде з віком ставати більш зрілим, крутим та працездатним. Він і так працездатний, але, я сподіваюся, що він ставатиме ще кращим. Тому якщо ви плануєте використати у себе Patroni, то не бійтеся. Це гарне рішення, його можна впроваджувати та використовувати.
На цьому все. Якщо у вас є запитання, ставте.

Питання
Дякую за доповідь! Якщо після файловера все одно треба туди дивитись дуже уважно, то навіщо нам автоматичний файловер?
Тому що це нова штука. Ми працюємо з нею лише рік. Краще перестрахуватись. Ми хочемо зайти і подивитися, що справді все відпрацювало так, як треба. Це рівень дорослої недовіри – краще перевіряти ще раз і подивитися.
Наприклад, ми вранці зайшли та подивилися, так?
Не вранці, ми зазвичай дізнаємося про автофайловер практично відразу. У нас надходять повідомлення, бачимо, що стався автофайловер. Ми практично відразу заходимо та дивимося. Але всі ці перевірки мають бути винесені на рівень моніторингу. Якщо звертатися до Patroni за REST API, то є history. За history можна дивитися часові позначки, коли відбувався файловер. На основі цього можна зробити моніторинг. Можна дивитися історію, скільки там подій було. Якщо у нас побільшало подій, значить, стався автофайловер. Можна сходити та подивитися. Або наша автоматика в моніторингу перевірила, що у нас усі репліки на місці, лага немає і все гаразд.
Дякуємо!
Дуже дякую за чудову розповідь! Якщо ми винесли кластер DCS кудись вдалину від кластера Postgres, то цей кластер теж треба періодично обслуговувати? Які best practices у тому, що якісь шматки кластера DCS треба вимикати, щось з ними робити тощо? Як при цьому живе вся ця конструкція? І як ці речі робити?
Для однієї компанії потрібно було зробити матрицю проблем, що відбувається, якщо якийсь із компонентів або кілька компонентів виходить з ладу. За цією матрицею ми послідовно перебираємо всі компоненти та будуємо сценарії у разі відмови цих компонентів. Відповідно до кожного сценарію відмови можна мати план дій для відновлення. І у випадку DCS це йде як частина стандартної інфраструктури. І адмін це адмініструє, і ми вже покладаємося на адмінів, які це адмініструють і на його здатність чинити це у разі аварій. Якщо DCS взагалі немає, його розгортаємо ми, але при цьому особливо за ним не стежимо, тому що ми не відповідаємо за інфраструктуру, але даємо рекомендації як і що замоніторити.
Т. е. чи правильно я зрозумів, що треба відключити Patroni, відключити файловер, відключити все перед тим, як робити щось з хостами?
Це залежить від того, скільки у нас вузлів у DCS-кластері. Якщо вузлів багато і якщо ми виводимо з ладу лише один з вузлів (репліку), то в кластері зберігається кворум. І Patroni залишається працездатним. І нічого не тригірується. Якщо у нас якісь складні операції, які торкаються більше вузлів, відсутність яких може розвалити кворум, то так, можливо, є сенс поставити Patroni на паузу. Він має відповідну команду – patronictl pause, patronictl resume. Ми просто ставимо на паузу і автофайловер не спрацьовує в цей час. Ми робимо maintenance на DCS-кластері, потім знімаємо паузу і продовжуємо жити.
Спасибо большое!
Дякую за доповідь! Як продуктова команда стосується того, що дані можуть загубитися?
Продуктовим командам за фіг, а тимліди хвилюються.
Які там є гарантії?
Із гарантіями дуже важко. Є доповідь у Олександра Кукушкіна «Як розраховувати RPO та RTO», тобто час відновлення та скільки даних можемо втратити. Я думаю, потрібно знайти ці слайди та їх вивчити. Наскільки я пам'ятаю, є конкретні кроки, як розраховувати ці речі. Скільки транзакцій можемо втратити, скільки даних ми можемо втратити. Як варіант можемо використовувати синхронну реплікацію на рівні Patroni, але це палиця з двома кінцями: ми або маємо надійність даних, або втрачаємо у швидкості. Є синхронна реплікація, але вона теж не гарантує 100% захист від втрати даних.
Олексію, дякую за чудову доповідь! Чи є досвід використання Patroni для XNUMX-рівня захисту? Тобто в поєднанні з синхронним standby? Це перше питання. І друге питання. Ви використовували різні рішення. Ми використовували Repmgr, але без автофайловера і зараз плануємо підключати автофайловер. І розглядаємо Patroni як альтернативне рішення. Що ви можете сказати як плюси саме в порівнянні з Repmgr?
Перше питання про синхронні репліки було. У нас ніхто синхронну реплікацію не використовує, тому що всім страшно. Примітка доповідача). Але ми для себе виробили правило, що в кластері синхронної реплікації має бути три вузли мінімум, тому що, якщо у нас два вузли і якщо майстер або репліка вийшли з ладу, Patroni переводить цей вузол в Standalone-режим, щоб додаток продовжував працювати. І тут є ризики втрати даних.
Щодо другого питання, ми використовували Repmgr і досі використовуємо в деяких клієнтах з історичних причин. Що можна сказати? У Patroni автофайловер з коробки, Repmgr автофайловер йде вже як додаткова фіча, яку потрібно включити. Потрібно запустити Repmgr daemon на кожному вузлі і тоді ми можемо налаштувати автофайловер.
Repmgr перевіряє – чи живі вузли Postgres. Repmgr процеси перевіряють існування одне одного, це дуже ефективний підхід т.к. можуть бути складні випадки мережевої ізоляції, при якій великий Repmgr кластер може розвалитися на кілька невеликих і продовжити роботу. Давно не стежу за Repmgr, можливо це пофіксували ... а може і ні. А ось винесення інформації про стан кластера в DCS, як робить Stolon, Patroni, це найбільш життєздатний варіант.
Олексію, у мене питання, можливо, ламерське. Ви в одному з перших прикладів DCS винесли із локальної машини на віддалений вузол. Розуміємо, що мережа – це річ, яка має свої особливості, вона сама живе. І що станеться, якщо з якоїсь причини DCS-кластер став недоступним? Причини не говоритиму, їх може бути маса: від кривих рук мережевиків до реальних проблем.
Я не промовив це вголос, але кластер DCS повинен бути також стійким до відмов, тобто це непарна кількість вузлів, щоб кворум міг зібратися. Що відбувається, якщо кластер DCS став недоступним, або не може зібратися кворум, тобто якийсь спліт мережі або відмова вузлів? І тут кластер Patroni перетворюється на read only режим. Кластер Patroni не може визначити стан кластера і що робити. Він не може зв'язатися з DCS і зберегти там новий стан кластера, тому весь кластер переходить у read only. І чекає або ручного втручання від оператора або коли DCS відновиться.
Грубо кажучи, DCS для нас стає сервісом так само важливим, як і сама база?
Так Так. У багатьох сучасних компаніях Service Discovery – це невід'ємна частина інфраструктури. Він запроваджується навіть раніше, ніж з'явилася навіть база даних в інфраструктурі. Умовно кажучи, запустилися інфраструктуру, розгорнулися до ДЦ, а в нас одразу Service Discovery є. Якщо це Consul, то на ньому і DNS можна побудувати. Якщо це Etcd, то може бути частина з кластера Kubernetes, в якому буде все інше розгортатися. Мені здається, що Service Discovery – це невід'ємна частина сучасних інфраструктур. І про нього думають набагато раніше, ніж про бази даних.
Дякуємо!
Джерело: habr.com
