


Відмовостійкість і висока доступність — великі теми, тому присвятимо RabbitMQ та Kafka окремі статті. Дана стаття про RabbitMQ, а наступна про Kafka, в порівнянні з RabbitMQ. Стаття довга, так що влаштовуйтесь зручніше.
Розглянемо стратегії відмовостійкості, узгодженості та високої доступності (HA), а також компроміси, на які доводиться йти у кожній стратегії. RabbitMQ може працювати на кластері вузлів – і тоді класифікується як розподілена система. Коли йдеться про розподілені системи, ми часто говоримо про узгодженість та доступність.
Ці поняття описують, як система поводиться при збої. Збій мережного з'єднання, збій сервера, збій жорсткого диска, тимчасова недоступність сервера через складання сміття, втрату пакетів або уповільнення мережного з'єднання. Все це може призвести до втрати даних чи конфліктів. Виявляється, практично неможливо підняти систему, одночасно і повністю несуперечливу (без втрати даних, без розбіжності даних), і доступну (прийматиме операції читання та запису) для всіх варіантів збою.
Ми побачимо, що узгодженість та доступність знаходяться на різних кінцях спектру, і вам потрібно вибрати, в який бік оптимізувати. Хороша новина у тому, що з RabbitMQ такий вибір можливий. У вас такі собі "нердівські" важелі, щоб зрушувати баланс у бік більшої узгодженості або більшої доступності.
p align="justify"> Особливу увагу приділимо тому, які конфігурації призводять до втрати даних через підтверджених записів. Є ланцюжок відповідальності між паблішерами, брокерами та споживачами. Після того, як повідомлення передано брокеру, це його робота не втратити повідомлення. Коли брокер підтверджує паблішеру отримання повідомлення, ми не очікуємо, що воно буде втрачено. Але ми побачимо, що таке може статися залежно від конфігурації вашого брокера і видавця.
Примітиви стійкості одного вузла
Стійкі черги/маршрутизація
У RabbitMQ два типи черги: тривалі/стійкі (durable) та нестійкі (non-durable). Усі черги зберігаються у базі даних Mnesia. Стійкі черги повторно оголошуються при запуску вузла і таким чином переживають перезапуск, збій системи або збій сервера (доки зберігаються дані). Це означає, що поки ви декларуєте маршрутизацію (exchange) та чергу стійкими, інфраструктура черг/маршрутизації повернеться до оперативного режиму.
Нестійкі черги та маршрутизація видаляються під час перезапуску вузла.
Стійкі повідомлення
Одне те, що черга довговічна, значить, що її повідомлення переживуть перезапуск вузла. Будуть відновлені лише повідомлення, встановлені паблішером як стійкі (Persistent). Стійкі повідомлення справді створюють додаткове навантаження на брокера, але якщо втрата повідомлення неприйнятна, іншого виходу немає.
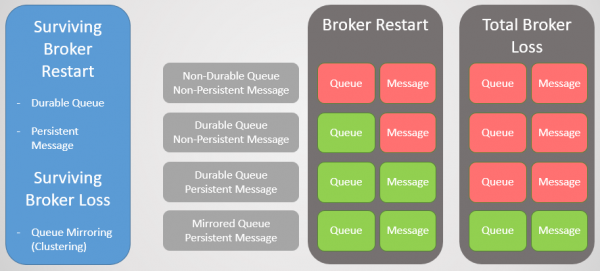
Мал. 1. Матриця стійкості
Кластеризація із дзеркалюванням черги
Щоб пережити втрату брокера, нам потрібна надмірність. Можемо об'єднати кілька вузлів RabbitMQ у кластер, а потім додати додаткову надмірність шляхом реплікації черг між кількома вузлами. Таким чином, якщо падає один вузол, ми не втрачаємо дані і залишаємось доступними.
Дзеркало черги:
- одна головна черга (майстер), яка отримує всі команди на запис та читання
- одне або кілька дзеркал, які отримують усі повідомлення та метадані із головної черги. Ці дзеркала є не для масштабування, а виключно для надмірності.
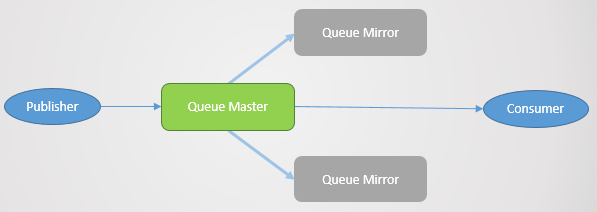
Мал. 2. Дзеркало черги
Дзеркало встановлюється відповідною політикою. У ній можна вибрати коефіцієнт реплікації і навіть вузли, на яких має розміщуватися черга. Приклади:
ha-mode: allha-mode: exactly, ha-params: 2(один майстер та одне дзеркало)ha-mode: nodes, ha-params: rabbit@node1, rabbit@node2
Підтвердження паблішеру
Для досягнення послідовного запису необхідні підтвердження паблішеру (Publisher Confirms). Без них є можливість втрати повідомлень. Підтвердження надсилається паблішеру після запису повідомлення на диск. RabbitMQ записує повідомлення на диск не при отриманні, а на періодичній основі, в районі кількох сотень мілісекунд. Коли черга віддзеркалюється, підтвердження надсилається лише після того, як усі дзеркала також записали свою копію повідомлення на диск. Це означає, що використання підтверджень додає затримку, але якщо безпека даних є важливою, то вони необхідні.
Відмовостійка черга
Коли брокер завершує роботу чи падає, всі провідні черги (майстри) цьому вузлі відвалюються разом із. Потім кластер вибирає найстаріше дзеркало кожного майстра і просуває його як новий майстр.
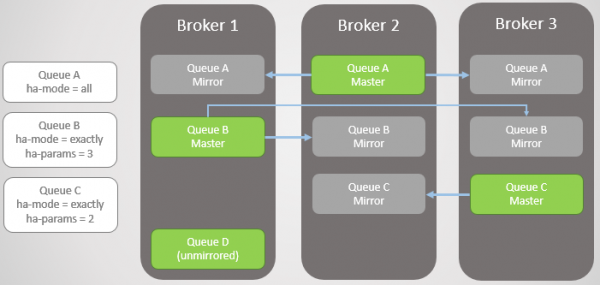
Мал. 3. Декілька дзеркальних черг та їх політики
Брокер 3 падає. Зверніть увагу, що дзеркало Черги С на брокері 2 підвищується до майстра. Також зверніть увагу, що для Черги C створено нове дзеркало на брокері 1. RabbitMQ завжди намагається підтримувати коефіцієнт реплікації, вказаний у ваших політиках.
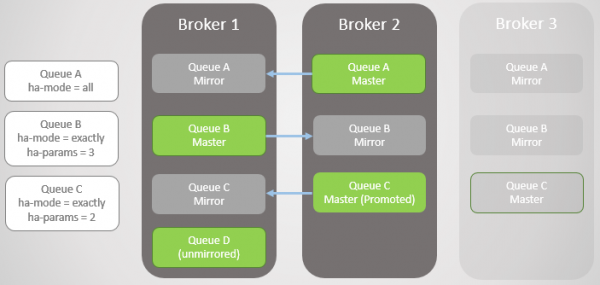
Мал. 4. Брокер 3 відвалюється, що викликає відмову черги C
Падає наступний брокер 1! У нас залишився лише один брокер. До майстра підвищується дзеркало Черги В.
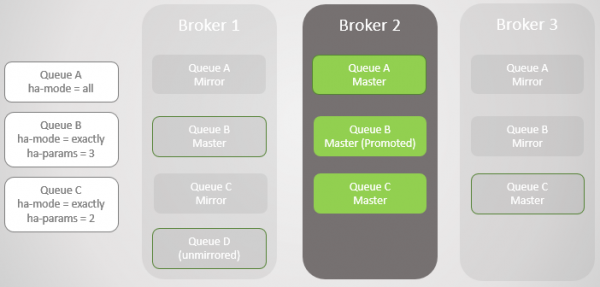
Рис. 5
Ми повернули Брокера 1. Незалежно від того, наскільки успішно дані пережили втрату та відновлення брокера, усі віддзеркалені повідомлення черги відкидаються при перезапуску. Це важливо наголосити, оскільки будуть наслідки. Ми незабаром розглянемо ці наслідки. Таким чином, Брокер 1 тепер знову є членом кластера, а кластер намагається дотримуватись політики і тому створює дзеркала на Брокері 1.
В цьому випадку втрата Брокера 1 була повною, як і даних, тому незеркована Черга В втрачена повністю.
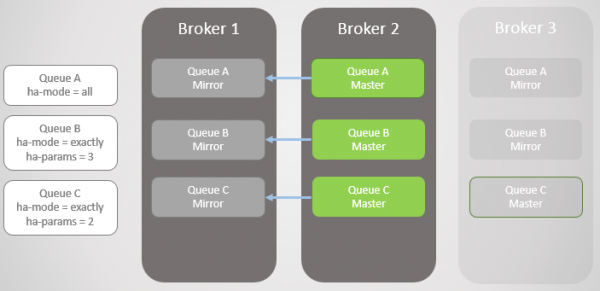
Мал. 6. Брокер 1 повертається до ладу
Брокер 3 повернувся в дію, так що черги A і B отримують назад створені на ньому дзеркала, щоб задовольнити своїх політиків HA. Але тепер усі головні черги на одному вузлі! Це не ідеально, краще рівномірний розподіл між вузлами. На жаль, тут немає особливих варіантів для перебалансування майстрів. Повернемося до цієї проблеми пізніше, оскільки спочатку потрібно розглянути синхронізацію черги.
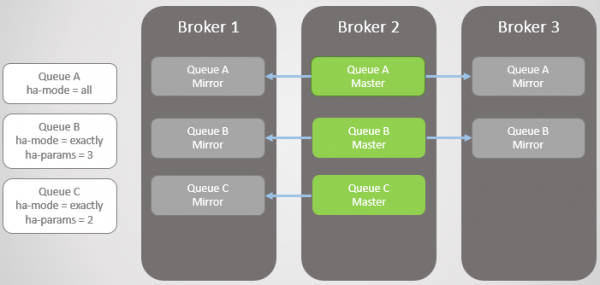
Мал. 7. Брокер 3 повертається до ладу. Усі головні черги на одному вузлі!
Таким чином, тепер у вас має бути уявлення, як дзеркала забезпечують надмірність та відмовостійкість. Це гарантує доступність у разі відмови одного вузла та захищає від втрати даних. Але ми ще не закінчили, бо насправді все набагато складніше.
Синхронізація
При створенні нового дзеркала все нові повідомлення завжди реплікуватимуться на це дзеркало та будь-які інші. Щодо існуючих даних у головній черзі, ми можемо їх реплікувати у нове дзеркало, яке стає повною копією майстра. Ми також можемо не реплікувати існуючі повідомлення та дозволити головній черзі і новому дзеркалу сходитися у часі, коли нові повідомлення надходять у хвіст, а існуючі повідомлення залишають голову черги.
Така синхронізація виконується автоматично або вручну та керується за допомогою політики черг. Розглянемо приклад.
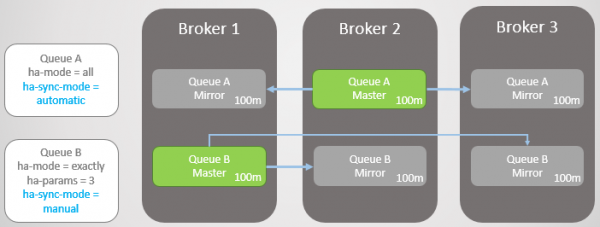
У нас дві дзеркальні черги. Черга A синхронізується автоматично, а Черга B – вручну. В обох чергах десять повідомлень.
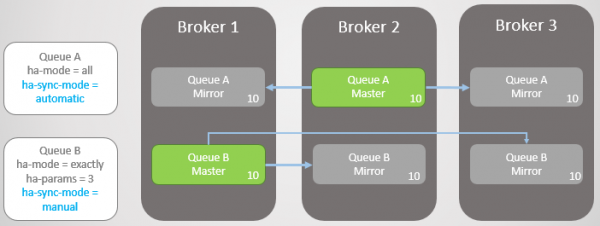
Мал. 8. Дві черги з різними режимами синхронізації
Тепер ми втрачаємо Брокера 3.
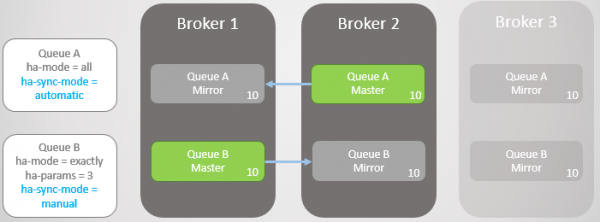
Мал. 9. Брокер 3 упав
Брокер 3 повертається до ладу. Кластер створює дзеркало для кожної черги на новому вузлі та автоматично синхронізує нову Чергу А з майстром. Однак дзеркало нової черги залишається пустим. Таким чином, ми маємо повну надмірність Черги A і тільки одне дзеркало для існуючих повідомлень Черги B.
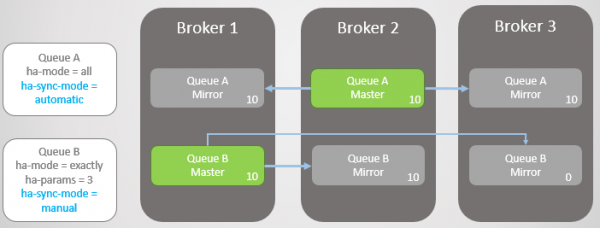
Мал. 10. Нове дзеркало Черги А отримує всі повідомлення, а нове дзеркало Черги B — ні
В обидві черги надходить ще по десять повідомлень. Потім Брокер 2 падає, а Черга А відкочується до найстарішого дзеркала, яке знаходиться на Брокері 1. При збої не відбувається втрати даних. У Черзі B двадцять повідомлень у майстрі і лише десять у дзеркалі, оскільки ця черга ніколи не реплікувала вихідні десять повідомлень.
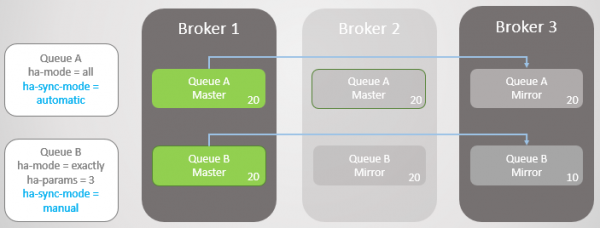
Мал. 11. Черга А відкочується Брокера 1 без втрати повідомлень
В обидві черги надходить ще по десять повідомлень. Тепер падає Брокер 1. Черга A без проблем перемикається на дзеркало без втрати повідомлень. Однак у Черги В виникають проблеми. На цьому етапі ми можемо оптимізувати доступність або узгодженість.
Якщо ми хочемо оптимізувати доступність, то політику ha-promote-on-failure слід встановити в завжди. Це значення за промовчанням, тому можна просто не вказувати політику взагалі. У такому разі, по суті, ми допускаємо збої у несинхронізованих дзеркалах. Це призведе до втрати повідомлень, але черга залишається доступною для читання та запису.
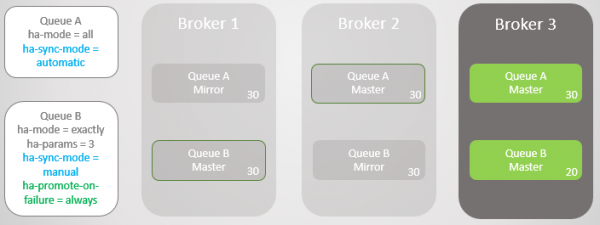
Мал. 12. Черга А відкочується до Брокера 3 без втрати повідомлень. Черга B відкочується на Брокера 3 із втратою десяти повідомлень
Ми також можемо встановити ha-promote-on-failure на значення when-synced. У цьому випадку замість відкату на дзеркало чергу чекатиме, поки Брокер 1 зі своїми даними повернеться до оперативного режиму. Після повернення головна черга знову опиняється на Брокері 1 без втрати даних. Доступність приноситься у жертву безпеки даних. Але це ризикований режим, який може призвести до повної втрати даних, що ми розглянемо найближчим часом.
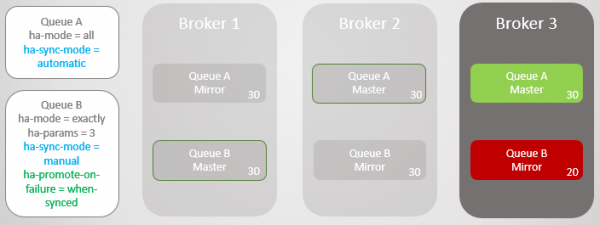
Мал. 13. Черга B залишається недоступною після втрати Брокера 1
Ви можете запитати: «Може, краще ніколи не використовувати автоматичну синхронізацію?». Відповідь у тому, що синхронізація є блокуючою операцією. Під час синхронізації головна черга не може виконувати жодних операцій читання чи запису!
Розглянемо приклад. Нині у нас дуже великі черги. Як вони можуть зрости до такого розміру? По деяким причинам:
- Черги не використовуються активно
- Це високошвидкісні черги, а зараз споживачі працюють повільно
- Це високошвидкісні черги, що стався збій, і споживачі наздоганяють
Мал. 14. Дві великі черги з різними режимами синхронізації
Тепер падає брокер 3.
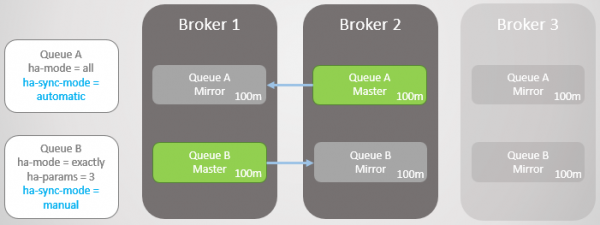
Мал. 15. Брокер 3 падає, залишаючи по одному майстру та дзеркалу в кожній черзі
Брокер 3 повертається в дію, і створюються нові дзеркала. Головна Черга А починає реплікувати існуючі повідомлення на нове дзеркало, і протягом цього часу Черга недоступна. Для реплікації даних потрібно дві години, що призводить до двох годин простою для цієї Черги!
Однак, Черга B залишається доступною протягом усього періоду. Вона пожертвувала деякою надмірністю задля доступності.
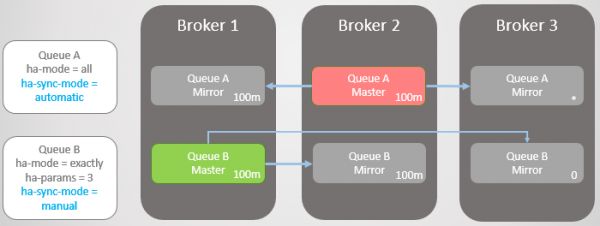
Мал. 16. Черга залишається недоступною під час синхронізації
Через дві години Черга A також стає доступною і може знову почати приймати операції читання та запису.
Оновлення
Така блокуюча поведінка під час синхронізації ускладнює оновлення кластерів із дуже великими чергами. У якийсь момент вузол з майстром потрібно перезапустити, що означає перехід на дзеркало, або відключення черги під час оновлення сервера. Якщо ми виберемо перехід, втратимо повідомлення, якщо дзеркала не синхронізовані. За замовчуванням під час відключення брокера перехід на несинхронізоване дзеркало не виконується. Це означає, що як тільки брокер повертається, ми не втрачаємо жодних повідомлень, єдиною шкодою став лише простий черги. Правила поведінки при відключенні брокера задаються політикою ha-promote-on-shutdown. Можна встановити одне з двох значень:
always= увімкнено перехід на несинхронізовані дзеркалаwhen-synced= перехід тільки на синхронізоване дзеркало, інакше черга стає недоступною для читання та запису. Черга повертається в дію, як тільки повернеться брокер
Так чи інакше, з великими чергами доводиться вибирати між втратою даних та недоступністю.
Коли доступність підвищує безпеку даних
Перш ніж ухвалювати рішення, потрібно врахувати ще одне ускладнення. Хоча автоматична синхронізація є кращою для надмірності, як вона впливає на безпеку даних? Звичайно, завдяки кращій надмірності RabbitMQ з меншою ймовірністю втратить існуючі повідомлення, але щодо нових повідомлень від паблішерів?
Тут потрібно врахувати таке:
- Чи може паблішер просто повернути помилку, а вища служба чи користувач пізніше повторять спробу?
- Чи може паблішер зберегти повідомлення локально або в базі даних, щоб повторити спробу пізніше?
Якщо паблішер здатний лише відкинути повідомлення, то, насправді, покращення доступності також підвищує безпеку даних.
Отже, потрібно шукати баланс, а рішення залежить від конкретної ситуації.
Проблеми з ha-promote-on-failure=when-synced
Ідея ha-promote-on-failure= when-synced полягає в тому, що ми запобігаємо переключенню на несинхронізоване дзеркало і тим самим уникаємо втрати даних. Черга залишається недоступною для читання чи запису. Натомість ми намагаємося повернути брокер, що впав, з непошкодженими даними, щоб він відновив роботу в якості майстра без втрати даних.
Але (і це велике але) якщо брокер втратив свої дані, то у нас велика проблема: черга втрачена! Усі дані зникли! Навіть якщо у вас є дзеркала, які переважно наздоганяють головну чергу, ці дзеркала теж відкидаються.
Щоб знову додати вузол з тим же ім'ям, ми говоримо кластеру забути втрачений вузол (командою rabbitmqctl forget_cluster_node) і запустити новий брокер з тим же ім'ям хоста. Поки кластер пам'ятає втрачений вузол, він пам'ятає стару чергу та несинхронізовані дзеркала. Коли кластеру кажуть забути втрачений вузол, ця черга також забувається. Тепер треба наново його оголосити. Ми втратили всі дані, хоча ми мали дзеркала з частковим набором даних. Найкраще було б перейти на несинхронізоване дзеркало!
Тому ручна синхронізація (і невиконання синхронізації) у поєднанні з ha-promote-on-failure=when-synced, мій погляд, досить ризикована. Документи кажуть, що такий варіант існує для безпеки даних, але це двогострий ніж.
Перебалансування майстрів
Як і було обіцяно, повертаємось до проблеми скупчення всіх майстрів на одному або кількох вузлах. Це може статися навіть у результаті «ковзного» (rolling) оновлення кластера. У кластері з трьома вузлами усі головні черги збираються на одному або двох вузлах.
Перебалансування майстрів може виявитися проблематичним з двох причин:
- Немає хороших інструментів для виконання перебалансування
- Синхронізація черг
Для перебалансування є сторонній , що не підтримується офіційно. Щодо сторонніх плагінів у посібнику RabbitMQ : «Плагін надає деякі додаткові інструменти налаштування та звітності, але не підтримується та не перевірений командою RabbitMQ. Використовуйте на свій страх та ризик».
Є ще один трюк, щоб перемістити головну чергу через HA політики. У посібнику згадується для цього. Він працює наступним чином:
- Видаляє всі дзеркала за допомогою тимчасової політики з більш високим пріоритетом, ніж існуюча політика HA.
- Змінює тимчасову політику HA використання режиму «вузли» із зазначенням вузла, який потрібно перенести головну чергу.
- Синхронізує чергу для примусової міграції.
- Після завершення міграції видаляє тимчасову політику. Набуває чинності вихідна політика HA і створюється необхідна кількість дзеркал.
Недолік в тому, що такий підхід може не спрацювати, якщо у вас є великі черги або суворі вимоги до надмірності.
Тепер подивимося, як кластери RabbitMQ працюють із мережевими розділами.
Порушення зв'язності
Вузли розподіленої системи з'єднуються мережевими зв'язками, а мережеві зв'язки можуть відключатися. Частота вимкнень залежить від локальної інфраструктури або надійності вибраної хмари. У будь-якому випадку, розподілені системи мають бути в змозі впоратися з ними. Знову перед нами вибір між доступністю та узгодженістю, і знову гарна новина в тому, що RabbitMQ забезпечує обидва варіанти (просто не одночасно).
З RabbitMQ у нас дві основні опції:
- Дозволити логічний поділ (split-brain). Це забезпечує доступність, але може спровокувати втрату даних.
- Заборонити логічний поділ. Може призвести до короткострокової втрати доступності залежно від способу підключення клієнтів до кластера. Також може спричинити повну недоступність у кластері з двох вузлів.
Але що таке логічний поділ? Це коли кластер поділяється надвоє через втрату мережевих зв'язків. На кожній стороні дзеркала підвищуються до майстра, тому в кожну чергу припадає кілька майстрів.
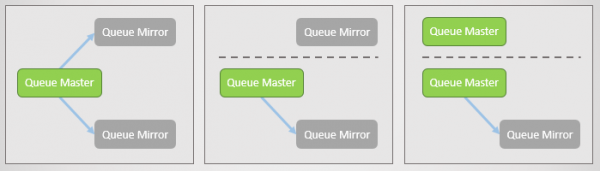
Мал. 17. Головна черга та два дзеркала, кожне на окремому вузлі. Потім виникає мережевий збій, і одне дзеркало відокремлюється. Відокремлений вузол бачить, що два інших відвалилися, і просуває свої дзеркала до майстра. Тепер у нас дві головні черги, і обидві допускають запис та читання.
Якщо паблішери відправляють дані в обидва майстри, у нас вийде дві копії черги, що розходяться.
Різні режими RabbitMQ забезпечують доступність або узгодженість.
Режим Ignore (за замовчуванням)
Цей режим забезпечує доступність. Після втрати зв'язності відбувається логічний поділ. Після відновлення зв'язності адміністратор повинен вирішити, якому розділу віддати перевагу. Сторона, що програє, буде перезапущена, і всі накопичені дані з цього боку губляться.
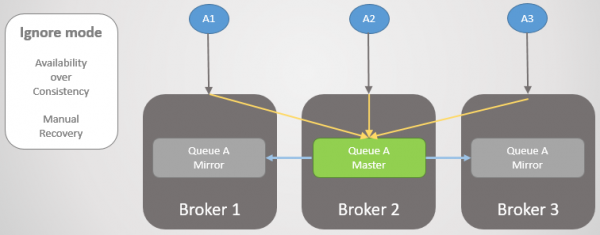
Мал. 18. Три паблішери пов'язані з трьома брокерами. Внутрішньо кластер надсилає всі запити в першу чергу на Брокері 2.
Тепер ми втрачаємо Брокера 3. Він бачить, що інші брокери відвалилися і просуває своє дзеркало до майстра. Так відбувається логічний поділ.
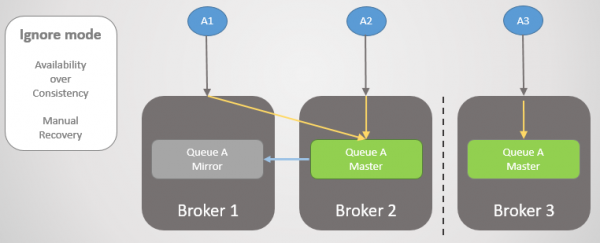
Мал. 19. Логічне поділ (split-brain). Записи йдуть у дві головні черги, і дві копії розходяться.
Зв'язок відновлюється, але логічний поділ залишається. Адміністратор повинен вручну вибрати сторону, що програла. У наведеному нижче випадку адміністратор перезавантажує Брокера 3. Втрачаються всі повідомлення, які той не встиг передати.
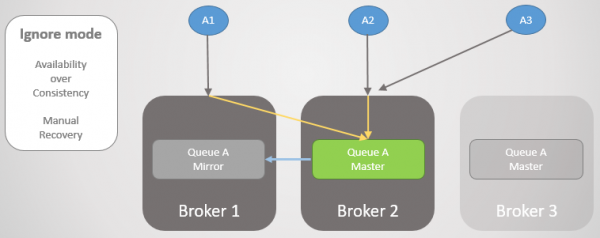
Мал. 20. Адміністратор вимикає Брокера 3.
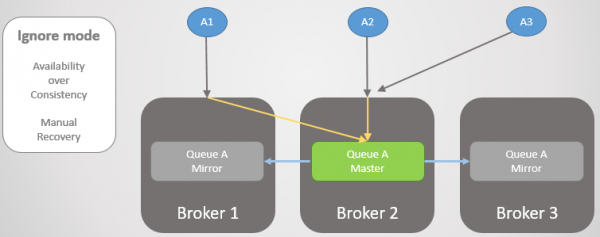
Мал. 21. Адміністратор запускає Брокера 3, і він приєднується до кластера, втрачаючи всі повідомлення, які там залишалися.
Під час втрати зв'язності та після її відновлення кластер і ця черга були доступні для читання та запису.
Режим Autoheal
Працює аналогічно режиму Ignore, за винятком того, що сам кластер автоматично вибирає сторону, що програла після поділу і відновлення зв'язності. Сторона, що програла, повертається в кластер порожньою, а черга втрачає всі повідомлення, які були відправлені тільки на той бік.
Режим Pause Minority
Якщо ми не хочемо допустити логічного поділу, то наш єдиний варіант – відмовитись від читання та запису на меншій стороні після розділу кластера. Коли брокер бачить, що знаходиться на меншій стороні, то зупиняє роботу, тобто закриває всі існуючі з'єднання та відмовляється від будь-яких нових. Один раз на секунду він перевіряє відновлення зв'язності. Як тільки зв'язок відновлено, він відновлює роботу і приєднується до кластера.
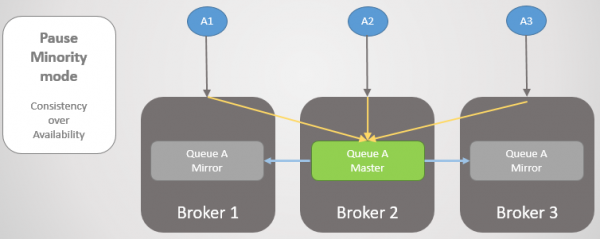
Мал. 22. Три паблішери пов'язані з трьома брокерами. Внутрішньо кластер надсилає всі запити в першу чергу на Брокері 2.
Потім Брокери 1 і 2 відокремлюються від Брокера 3. Замість того, щоб підвищувати своє дзеркало до майстра, Брокер 3 зупиняє роботу і стає недоступним.
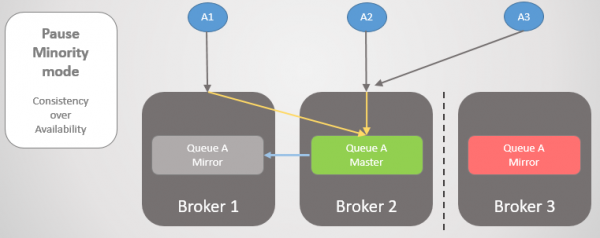
Мал. 23. Брокер 3 припиняє роботу, відключає всіх клієнтів та відкидає запити на підключення.
Як тільки зв'язок відновлено, він повертається в кластер.
Подивимося інший приклад, де головна черга перебуває в Брокере 3.
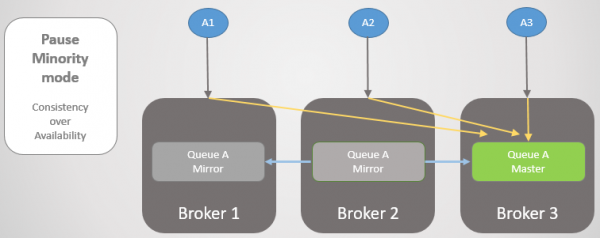
Мал. 24. Головна черга на Брокері 3.
Потім відбувається та сама втрата зв'язності. Брокер 3 стає на паузу, оскільки знаходиться на меншій стороні. З іншого боку вузли бачать, що Брокер 3 відвалився, отже старіше дзеркало з Брокеров 1 і 2 підвищується до майстра.
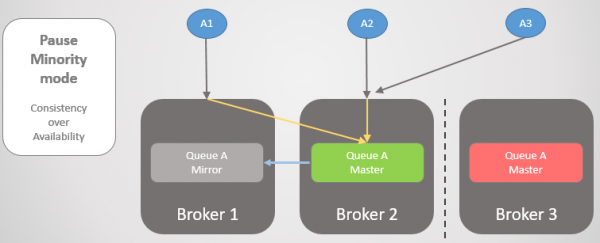
Мал. 25. Перехід до брокера 2 при недоступності брокера 3.
Коли зв'язок відновлено, Брокер 3 приєднається до кластера.

Мал. 26. Кластер повернувся до нормальної роботи.
Тут важливо розуміти, що ми отримуємо узгодженість, але також можемо отримати доступність, якщо успішно переведемо клієнтів на більшу частину розділу. Для більшості ситуацій особисто я вибрав би режим Pause Minority, але це реально залежить від конкретного випадку.
Для забезпечення доступності важливо переконатись, що клієнти успішно підключаються до вузла. Розглянемо наші варіанти.
Забезпечення зв'язності клієнтів
У нас кілька варіантів, як після втрати зв'язності направити клієнтів на основну частину кластера або на працюючі вузли (після збою одного вузла). Спочатку давайте згадаємо, що конкретна черга розміщується на певному вузлі, але маршрутизація та політики реплікуються на всіх вузлах. Клієнти можуть підключатися до будь-якого вузла, а внутрішня маршрутизація направить їх куди треба. Але коли вузол припинено, він відкидає з'єднання, тому клієнти повинні підключитися до іншого вузла. Якщо вузол відвалився, він взагалі мало що може зробити.
Наші варіанти:
- Доступ до кластера здійснюється за допомогою балансувальника навантаження, який просто циклічно перебирає вузли, а клієнти виконують повторні спроби підключення до успішного завершення. Якщо вузол не працює або призупинено, спроби підключення до цього вузла завершаться невдачею, але подальші спроби підуть на інші сервери (у циклічному режимі). Це підходить для короткочасної втрати зв'язності або сервера, що впав, який буде швидко піднятий.
- Доступ до кластера через балансувальник навантаження та видалення зупинених/упалих вузлів зі списку, як тільки вони виявлені. Якщо це швидко зробити, і якщо клієнти здатні на повторні спроби підключення, ми отримаємо постійну доступність.
- Дати кожному клієнту список всіх вузлів, а клієнт при підключенні випадково обирає один з них. Якщо під час спроби підключення він отримує помилку, то переходить до наступного вузла у списку, доки підключиться.
- Прибрати трафік від вузла/зупиненого вузла за допомогою DNS. Це робиться за допомогою малого TTL.
Висновки
У кластеризації RabbitMQ свої переваги та недоліки. Найбільш серйозні недоліки полягають у тому, що:
- при приєднанні до кластера вузли відкидають свої дані;
- блокуюча синхронізація призводить до недоступності черги.
Усі важкі рішення випливають із цих двох особливостей архітектури. Якби RabbitMQ міг зберігати дані при з'єднанні кластера, то синхронізація відбувалася швидше. Якби він був здатний на синхронізацію, що не блокує, то краще підтримував великі черги. Усунення цих двох проблем серйозно покращило б характеристики RabbitMQ як відмовостійку та високодоступну технологію обміну повідомленнями. Я б не наважився рекомендувати RabbitMQ із кластеризацією у таких ситуаціях:
- Ненадійна мережа.
- Ненадійне зберігання.
- Дуже великі черги.
Щодо налаштувань для високої доступності, то розгляньте такі:
ha-promote-on-failure=alwaysha-sync-mode=manualcluster_partition_handling=ignore(абоautoheal)- стійкі повідомлення
- переконайтеся, що клієнти підключаються до активного вузла, коли якийсь вузол виходить з ладу
Для узгодженості (безпеки даних) розгляньте такі настройки:
- Publisher Confirms та Manual Acknowledgements на стороні споживача
ha-promote-on-failure=when-syncedякщо видавці можуть повторити спробу пізніше і якщо у вас є дуже надійне сховище! Інакше ставте=always.ha-sync-mode=automatic(але для великих неактивних черг може знадобитися ручний режим; крім того, подумайте, чи не призведе недоступність втрати повідомлень)- режим Pause Minority
- стійкі повідомлення
Ми розглянули ще не всі питання відмовостійкості та високої доступності; наприклад, як безпечно виконувати адміністративні процедури (такі як ковзні оновлення). Потрібно поговорити також про федерування та плагін Shovel.
Якщо я ще щось упустив, будь ласка, дайте знати.
також мій , де я здійснюю погром у кластері RabbitMQ за допомогою Docker та Blockade, щоб перевірити деякі сценарії втрати повідомлень, описані в цій статті.
Попередні статті серії:
№1 -
№2 -
№3 -
Джерело: habr.com
