

Я розповім вам сьогодні історію. Історію еволюції обчислювальної техніки та появи віддалених робочих місць з найдавніших часів і до наших днів.
Розвиток ІТ
Головне, що можна винести з історії ІТ – це…

Вочевидь те, що ІТ розвивається по спіралі. Одні й ті самі рішення та концепції, які були відкинуті десятки років тому, знаходять новий зміст і успішно починають працювати в нових умовах, за нових завдань та нових потужностей. У цьому вся ІТ нічим не відрізняється від будь-якої іншої галузі людського знання та історії Землі в цілому.

Давним-давно, коли комп'ютери були більшими
"Я думаю, у світі є ринок приблизно для п'яти комп'ютерів", глава IBM Томас Вотсон в 1943.
Рання комп'ютерна техніка була великою. Ні, неправильно, рання техніка була жахливою, гігантською. Цілком обчислювальна машина займала площу, порівнянну зі спортивним залом, а коштувала зовсім нереальних грошей. Як приклад комплектуючих можна навести модуль оперативної пам'яті на феритових кільцях (1964).

Цей модуль має розмір 11 см * 11 см, і ємність 512 байт (4096 біт). Шафа, повністю набита цими модулями, навряд чи мала ємність древньої вже сьогодні дискети 3,5” (1.44 МБ = 2950 модулів), у своїй споживав дуже відчутну електричну потужність і грівся як паровоз.
Саме з величезними розмірами пов'язана й англомовна назва налагодження програмного коду - "debugging". Одна з перших в історії програмістів, Грейс Хоппер (так-так, жінка), офіцер військово-морських сил, зробила в 1945 запис у журналі дій після розслідування неполадки з програмою.

Оскільки moth (метелик) у загальному випадку це bug (комаха), всі подальші проблеми та дії за рішенням персонал доповідав начальству як “debugging” (буквально знежучування), то за збоєм програми та помилкою в коді намертво закріпилася назва баг, а налагодження стало дебагом .
З розвитком електроніки і напівпровідникової електроніки особливо, фізичні розміри машин стали зменшуватися, а обчислювальна потужність, навпаки, зростати. Але навіть у цьому випадку не можна було поставити кожному по комп'ютері персонально.
"Немає жодних причин, щоб хтось захотів тримати комп'ютер у себе вдома" - Кен Олсен, засновник DEC, 1977.
У 70-ті з'являється термін міні-комп'ютер. Пам'ятаю, що коли вперше прочитав цей термін багато років тому, мені здалося щось на кшталт нетбука, практично наладонник. Я не міг бути далі від істини.

Міні — він лише в порівнянні з величезними машинними залами, але це все ще кілька шаф із обладнанням вартістю сотні тисяч і мільйони доларів. Однак обчислювальна потужність вже зросла настільки, що не завжди була завантажена на 100%, і при цьому комп'ютери почали доступні студентам і викладачам університетів.
І тут прийшов ВІН!

Мало хто замислюється над латинським корінням в англійській мові, але саме він приніс нам віддалений доступ, як ми знаємо його зараз. Terminus (лат) - кінець, кордон, ціль. Метою Термінатора Т800 було закінчити життя Джона Коннора. Також ми знаємо, що транспортні станції, на яких проводиться посадка-висадка пасажирів або навантаження-розвантаження вантажів, називаються терміналами кінцевими цілями маршрутів.
Відповідно з'явилася концепція термінального доступу, і ви можете побачити найвідоміший у світі термінал, який досі живе у наших серцях.

DEC VT100 називається терміналом, оскільки закінчує інформаційну лінію. Має фактично нульову обчислювальну потужність, і його єдине завдання – відобразити отриману з великої машини інформацію, та передати на машину введення з клавіатури. І хоча VT100 фізично давно померли, ми все ще користуємось ними повною мірою.
Наші дні
"Наші дні" я б став відраховувати з початку 80-х, з моменту появи перших доступних широкому колу процесорів з скільки-небудь значущою обчислювальною потужністю. Традиційно вважається, що головним процесором епохи став Intel 8088 (родина x86) як родоначальник архітектури, що перемогла. У чому принципова різниця з концепцією 70х?
Вперше виникає тенденція перенесення обробки інформації з центру на периферію. Не всі завдання вимагають божевільних (проти слабким x86) потужностей мейнфрейма і навіть міні-комп'ютера. Intel не стоїть на місці, в 90-х випускає сімейство Pentium, яке стало по-справжньому першим масовим домашнім в Росії. Ці процесори вже здатні багато на що, не тільки написати листа — а й мультимедіа, і працювати з невеликими базами даних. Фактично для малого бізнесу повністю відпадає потреба у серверах — все можна виконувати на периферії, клієнтських машинах. З кожним роком процесори все потужніші, а різниця між серверами та персоналками все менше і менше з точки зору обчислювальної потужності, часто залишаючись тільки в резервуванні живлення, підтримки гарячої заміни та спеціальних корпусах для монтажу у стійки.
Якщо порівнювати сучасні клієнтські процесори “смішний” для адміністраторів важких серверів у 90-ті компанії Intel із суперкомп'ютерами минулого, то й зовсім стає трохи по собі.
Давайте поглянемо на дідуся, всього-то майже мого ровесника. Cray X-MP/24 1984 року.

Ця машина входила в топ суперкомп'ютерів 1984 року, маючи 2 процесори по 105 MHz з піковою обчислювальною потужністю 400 MFlops (мільйонів операцій з плаваючою точкою). Саме та машина, що зображена на фото, стояла в лабораторії криптографії АНБ США і займалася зломом шифрів. Якщо перевести 15 млн доларів 1984 року в долари 2020 року, то вартість складе 37,4 млн, або 93 500 доларів/MFlops.

У тій машині, на якій я пишу ці рядки, стоїть процесор Core i5-7400 2017 року, ті зовсім не новий, і навіть у рік свого виходу колишній наймолодший 4-ядерний з усіх десктопних процесорів середнього рівня. 4 ядра по 3.0 GHz базової частоти (3.5 з Turbo Boost) та подвоєння потоків HyperThreading дають від 19 до 47 GFlops потужності за різними тестами при ціні 16 тис руб за процесор. Якщо зібрати машинку цілком, то можна прийняти її вартість за 750 доларів (за цінами та курсом на 1 березня 2020 року).
Зрештою отримуємо перевагу цілком середнього десктопного процесора наших днів у 50-120 разів над суперкомп'ютером з топ10 цілком доступного для огляду минулого, а падіння питомої вартості MFlops стає дуже жахливими 93500 / 25 = 3700 разів.
Навіщо нам все ще потрібні сервери та централізація обчислень при подібних потужностях на периферії – зовсім незрозуміло!
Зворотний стрибок - спіраль зробила виток
Бездискові станції
Першим сигналом, що винесення обчислень на периферію буде остаточним, стала поява технології бездискових робочих станцій. При значному розподілі робочих станцій територією підприємства, і особливо у забруднених приміщеннях, дуже жорстко постає питання управління та підтримки цих станцій.

З'являється поняття "коридорний час" - відсоток часу, що співробітник техпідтримки знаходиться в коридорі, по дорозі до співробітника з проблемою. Це час оплачуваний, але зовсім непродуктивний. Не останню роль, і особливо у забруднених приміщеннях, становили виходи з ладу жорстких дисків. Давайте приберемо з робочої станції диск, а решту зробимо по мережі, у тому числі завантаження. Мережевий адаптер отримує крім адреси від DHCP сервера також додаткову інформацію - адресу сервера TFTP (спрощений файловий сервіс) та ім'я завантажувального образу, завантажує його в оперативну пам'ять і стартує машину.
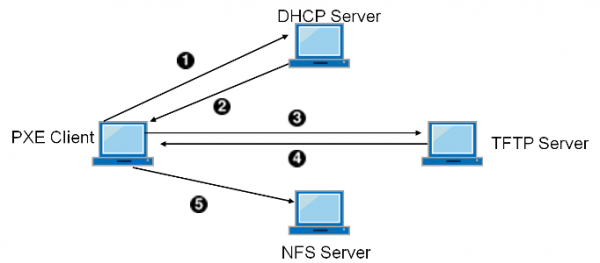
Крім меншої кількості поломок і зниження коридорного часу, машину тепер можна не налагоджувати на місці, а просто принести нову, і забрати стару діагностику на обладнане робоче місце. Але це ще не все!
Бездискова станція стає значно безпечнішою — якщо раптом хтось вдереться в приміщення і винесе всі комп'ютери, це лише втрати обладнання. Жодних даних не зберігається на бездискових станціях.
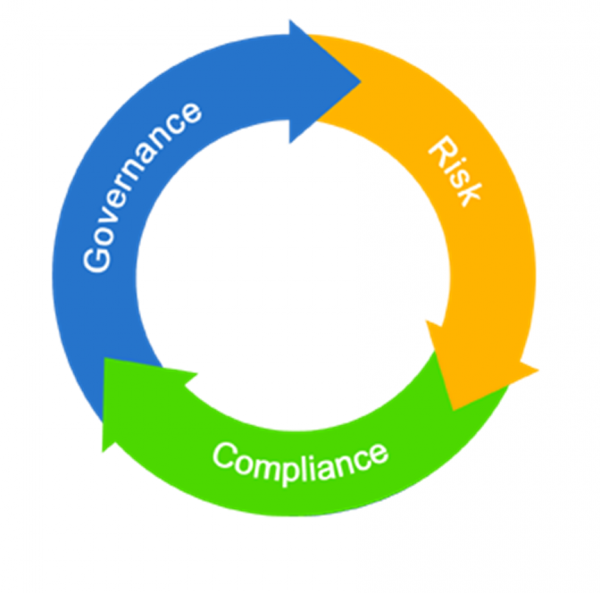
Запам'ятаємо цей момент, ІБ починає відігравати все більшу роль після "безпечного дитинства" інформаційних технологій. А в ІТ все сильніше вторгаються страшні і важливі 3 літери — GRC (Governance, Risk, Compliance), або російською мовою «Керування, Ризик, Відповідність».
Термінальні сервери
Повсюдне поширення дедалі більше потужних персоналок на периферії значно випереджало розвиток мереж загального доступу. Класичні для 90-початку 00 клієнт-серверні програми не дуже добре працювали по тонкому каналу, якщо обмін даними становив скільки-небудь значущі значення. Особливо це було важко для віддалених офісів, що підключалися за модемом та телефонною лінією, яка до того ж періодично підвисала або обривалася. І…
Спіраль зробила виток і знову опинилася в термінальному режимі з концепцією термінальних серверів.
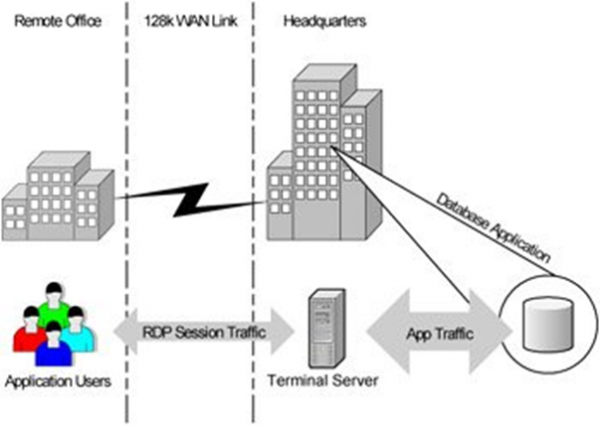
Фактично ми повернулися до 70м з їхніми нульовими замовниками та централізацією обчислювальної потужності. Дуже швидко стало очевидно, що крім суто економічного підґрунтя з каналами термінальний доступ дає величезні можливості щодо організації безпечного доступу зовні, у тому числі роботи з дому для співробітників, або вкрай обмеженого та підконтрольного доступу контракторам з недовірених мереж та недовірених/неконтрольованих пристроїв.
Однак термінальні сервери при всіх їх плюсах і прогресивності мали також і низку мінусів — низьку гнучкість, проблему галасливого сусіда, суворо серверну. Windows і т.д.
Народження прото VDI

Правда на початку-середині 00х вже виходила на сцену промислова віртуалізація x86 платформи. І хтось озвучив ідею, що просто витала в повітрі: а давайте замість централізації всіх клієнтів на серверних термінальних фермах дамо кожному його персональну ВМ з клієнтською Windows і навіть адміністраторським доступом?
Відмова від товстих клієнтів
Паралельно з віртуалізацією сесій та ОС розвивався підхід, пов'язаний із полегшенням функції клієнта на рівні програми.
Логіка за цим була досить проста, адже персональні ноутбуки були ще далеко не у всіх, інтернет так само був не у всіх, і багато хто міг підключитися тільки з інтернет кафе з дуже обмеженими, м'яко кажучи, правами. Фактично все що можна було запустити — це браузер. Браузер став неодмінним атрибутом ОС, інтернет міцно заходив у наше життя.
Іншими словами, паралельно йшов тренд на перенесення логіки з клієнта до центру у вигляді веб-додатків, для доступу до яких потрібен лише найпростіший клієнт, інтернет та браузер.
І ми виявилися не просто там, з чого починали — з нульових клієнтів та центральних серверів. Ми прийшли туди кількома незалежними шляхами.

Інфраструктура віртуальних робочих столів
Брокер
У 2007 лідер ринку промислової віртуалізації, VMware, випустила першу версію свого продукту VDM (Virtual Desktop Manager), що став фактично першим на ринку віртуальних десктопів, що тільки народжується. Зрозуміло, довго чекати відповіді від лідера термінальних серверів Citrix не довелося і в 2008 з придбанням XenSource з'являється XenDesktop. Безумовно були й інші вендори зі своїми пропозиціями, але не надто заглиблюватимемося в історію, відходячи від концепції.
І досі концепція зберігається. Ключовий компонент VDI – це брокер з'єднань.
Саме це є серце інфраструктури віртуальних десктопів.
Брокер відповідає за найголовніші процеси роботи VDI:
- Визначає доступні для клієнта, що підключився, ресурси (машини/сесії);
- Балансує при необхідності клієнтів з пулів машин/сесій;
- Прокидає клієнта на вибраний ресурс.
Сьогодні клієнтом (терміналом) для VDI може бути фактично все, що має екран — ноутбук, смартфон, планшет, кіоск, тонкий або нульовий клієнт. А частиною у відповідь, тією самою, що виконує продуктивне навантаження — сесія термінального сервера, фізична машина, віртуальна машина. Сучасні зрілі продукти VDI тісно інтегровані з віртуальною інфраструктурою і самостійно керують їй в автоматичному режимі, розгортаючи або набираючи, видаляючи вже непотрібні віртуальні машини.
Трохи осторонь, але для деяких клієнтів украй важливою технологією VDI стоїть підтримка апаратного прискорення 3D графіки для роботи проектувальників або дизайнерів.
протокол
Другою надзвичайно важливою частиною зрілого рішення VDI є протокол доступу до віртуальних ресурсів. Якщо йдеться про роботу всередині корпоративної локальної мережі з відмінною надійною мережею 1 Gbps до робочого місця та затримкою в 1 ms, то можна брати практично будь-хто і взагалі не думати.
Думати потрібно коли підключення йде по неконтрольованій мережі, а якість цієї мережі може абсолютно будь-яким, аж до швидкостей у десятки кілобіт та непередбачуваними затримками. Ті саме для організації справжньої віддаленої роботи, з дач, з дому, з аеропортів та закусочних.
Термінальні сервери vs клієнтські ВМ
З появою VDI здавалося, що настав час прощатися з термінальними серверами. Навіщо вони потрібні, якщо кожен має свою персональну ВМ?
Проте з погляду чистої економіки виявилося, що для типових масових робочих місць, однакових до нудоти — поки що немає нічого ефективнішого за термінальні сервери за співвідношенням ціна/сесія. За всіх своїх переваг підхід “1 користувач = 1 ВМ” витрачає значно більше ресурсів на віртуальне залізо та повноцінну ОС, що погіршує економіку на типових робочих місцях.
У разі робочих місць топ-менеджерів, нестандартних і навантажених робочих місць, необхідності мати високі права (аж до адміністратора), перевагу має виділена ВМ на користувача. В рамках цієї ВМ можна виділяти ресурси індивідуально, видавати права будь-якого рівня та балансувати ВМ між хостами віртуалізації при високому навантаженні.
VDI та економіка
Роками я чую те саме питання — а як, VDI дешевше ніж просто ноутбуки всім роздати? І роками мені доводиться відповідати рівно те саме: у випадку зі звичайними офісними співробітниками VDI не дешевше, якщо вважати чисті витрати на забезпечення обладнанням. Як не крути, ноутбуки дешевшають, а от сервери, СГД та системний софт коштують досить відчутних грошей. Якщо вам настав час оновлювати парк і ви думаєте заощадити за рахунок VDI - ні, не заощадите.
Я вище наводив страшні три літери GRC — отож, VDI це про GRC. Це про управління ризиками, це про безпеку та зручність контрольованого доступу до даних. І це все коштує зазвичай чималих грошей для впровадження на купі різнорідної техніки. За допомогою VDI контроль спрощується, безпека підвищується, а волосся стає м'яким і шовковистим.
Рішення HPE для віддаленої роботи
Віддалене та хмарне управління
iLO
Компанія HPE є далеко не новачком у віддаленому управлінні серверною інфраструктурою, чи жарт — у березні виповнилося 18 років легендарному iLO (Integrated Lights Out). Згадуючи свої адмінські часи у 00-ті, особисто не міг натішитися. Первинний монтаж у стійки та підключення кабелів - ось все, що потрібно було зробити в шумному та холодному ЦОДі. Решта конфігурування, включаючи заливку ОС, можна було вже робити з робочого місця, двох моніторів і з кухлем гарячої кави. І це 13 років тому!

На сьогодні HPE сервери неспроста є незаперечним багаторічним стандартом якості — і далеко не останню роль у цьому відіграє золотий стандарт системи віддаленого управління — iLO.
Хочеться окремо відзначити дії HPE утримання контролю людства над коронавірусом. , що до кінця 2020 року (як мінімум) ліцензія iLO Advanced доступна всім безкоштовно.
Infosight
Якщо у вас більше 10 серверів в інфраструктурі, і адміністратор не знемагає від нудьги, то, звичайно, відмінним доповненням до стандартних засобів моніторингу буде хмарна система HPE Infosight на основі штучного інтелекту. Система не просто моніторить стан та будує графіки, а й самостійно рекомендує подальші дії на основі поточної ситуації та трендів.
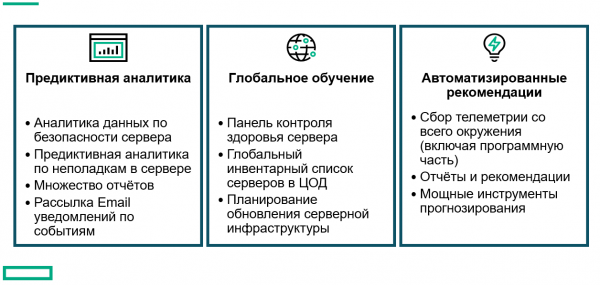
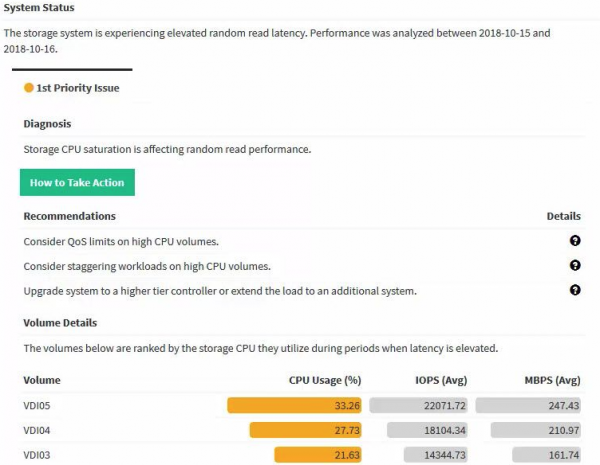
Будь розумним, , Спробуй Infosight!
OneView
Останнім по черзі, але не за значенням, хочу відзначити HPE OneView — цілий продуктовий портфель з величезними можливостями моніторингу та управління всією інфраструктурою. І все це не встаючи через робочий стіл, який, можливо, у вас знаходиться в поточній ситуації взагалі на дачі.
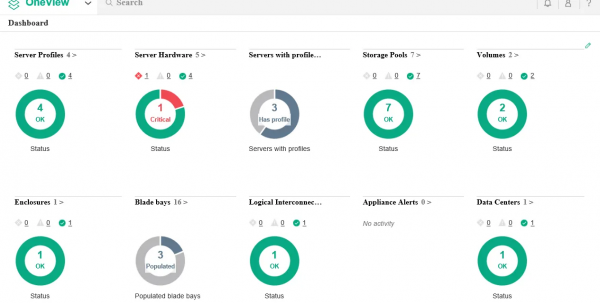
СГД теж не ликом шиті!
Зрозуміло, всі СГД віддалено управляються, моніторяться - так було ще багато років тому. Тому хочу поговорити сьогодні про інше, а саме метро-кластерів.
Метро-кластери зовсім не новинка на ринку, але саме завдяки цьому вони досі не надто популярні — позначається інерційність мислення та перші враження. Звичайно, 10 років тому вони вже були, але коштували як чавунний міст. Роки, що минули з перших метрокластерів, змінили промисловість і доступність технології широкому загалу.
Я пам'ятаю проекти, де спеціально розносили частини СГД — окремо під надкритичні сервіси в метрокластері, окремо на синхронну реплікацію (у рази дешевше).
Фактично, в 2020 метрокластер вам не варто нічого, якщо ви здатні організувати два майданчики та канали. Адже канали під синхронну реплікацію потрібні рівно ті самі, що й під метрокластери. Ліцензування софту давно вже йде пакетами - і синхронна реплікація йде відразу комплектом з метрокластером, і єдине, що поки що зберігає життя односпрямованої реплікації - це необхідність організації розтягнутої мережі L2. Та й те, L2 over L3 вже вже крокує країною.
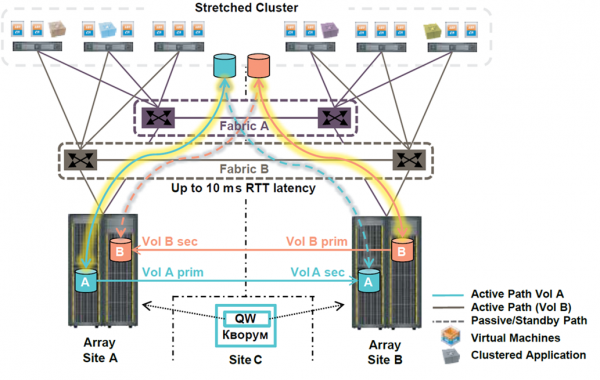
Тож у чому принципова різниця між синхронною реплікацією і метрокластером з погляду віддаленої роботи?
Все дуже просто. Метрокластер працює сам, автоматично, завжди практично миттєво.
Як виглядає процес перемикання навантаження на синхронній реплікації на інфраструктурі хоча б кілька сотень ВМ?
- Надходить сигнал про аварію.
- Чергова зміна аналізує обстановку — можна сміливо закладати від 10 до 30 хвилин лише на отримання сигналу та прийняття рішення.
- У разі відсутності повноважень у чергових інженерів на самостійний старт перемикання ще сміливо 30 хвилин на зв'язок з особою, яка має повноваження, і формальне підтвердження початку перемикання.
- Натискання Великої Червоної кнопки.
- 10-15 хвилин на таймаути та перемонтування томів, перереєстрацію ВМ.
- 30 хвилин на зміну IP адресації – оптимістична оцінка.
- І нарешті старт ВМ та запуск продуктивних сервісів.
Разом RTO (час до відновлення бізнес-процесів) можна сміливо оцінювати в 4 години.
Порівняємо із ситуацією на метрокластері.
- СГД розуміє, що зв'язок із плечем метрокластера втрачено — 15-30 секунд.
- Хости віртуалізації розуміють, що перший ЦОД втрачено - 15-30 секунд (одночасно з п 1).
- Автоматичний перезапуск від половини до третини ВМ у другому ЦОДі — 10-15 хвилин до завантаження сервісів.
- Приблизно в цей час чергова зміна розуміє, що сталося.
Разом: RTO = 0 окремих сервісів, 10-15 хвилин у випадку.
Чому ж перезапуск лише від половини до третини ВМ? Дивіться в чому річ:
- Ви все робите розумно, і включаєте автоматичне балансування ВМ. У результаті лише половина ВМ виконується у одному з ЦОДов. Адже весь сенс метрокластера в мінімізації простоїв, а отже у ваших інтересах мінімізувати кількість ВМ під ударом.
- Частину сервісів можна кластеризувати лише на рівні докладання, рознісши з різних ВМ. Відповідно ці парні ВМ по одній прибиваються цвяхами, або прив'язуються стрічкою до різних ЦОДів, щоб сервіс взагалі не чекав на перезапуск ВМ у разі аварії.
При грамотно побудованій інфраструктурі з розтягнутими метрокластерами бізнес-користувачі працюють з мінімальними затримками з будь-якої точки, навіть у разі аварії на рівні ЦОД. У гіршому випадку затримка становитиме час на одну чашку кави.
І, зрозуміло, метрокластери добре працюють як на HPE 3Par, що йдуть у бік Валінора, так і на новеньких Primera!

Інфраструктура віддалених робочих місць
Термінальні сервери
Для термінальних серверів не потрібно вигадувати нічого нового, вже багато років HPE постачає одні з найкращих серверів у світі для них. Нестаріюча класика – DL360 (1U) або DL380 (2U) або для любителів AMD – DL385. Звичайно, є і блейд сервери, як класичні C7000, так і нова платформа Synergy, що компонується.

На будь-який смак, будь-який колір, максимум сесій на сервер!
"Класичний" VDI + HPE Simplivity
У даному випадку кажучи “класичним VDI” я маю на увазі концепцію 1 користувач = 1 ВМ з клієнтською Windows. І звичайно ж, немає ближче і рідніше за VDI навантаження для гіперконвергентних систем, тим більше з дедуплікацією та компресією.

Тут HPE може запропонувати як власну гіперконвергентну платформу Simplivity, так і сервери/сертифіковані вузли під рішення партнерів, як VSAN Ready Nodes для побудови VDI на інфраструктурі VMware VSAN.
Давайте поговоримо трохи більше про своє рішення Simplivity. На чільне місце, як нам м'яко натякає назва, поставлена простота (англ simple — простий). Простота розгортання, простота керування, простота масштабування.
Гіперконвергентні системи на сьогодні — одна з найгарячіших тем в ІТ, а кількість вендорів різного рівня становить близько 40. Згідно з магічним квадратом Gartner, компанія HPE знаходиться в Тор5 глобально, і входить до квадрата лідерів — ті розуміє і куди розвивається індустрія, і здатна це розуміння втілити у залозі.
Архітектурно Simplivity є класичною гіперконвергентною системою з контролерними віртуальними машинами, а отже може підтримувати різні гіпервізори, на відміну від інтегрованих у гіпервізор систем. На квітень 2020 підтримуються VMware vSphere і Microsoft Hyper-V, і озвучені плани з підтримки KVM. Ключовою фішкою Simplivity з моменту її появи на ринку було апаратне прискорення компресії та дедуплікації за допомогою спеціальної картки-акселератора.
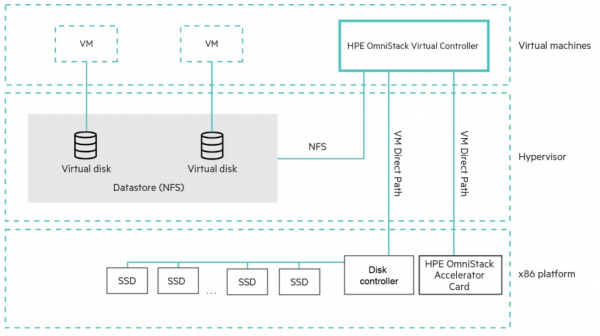
Слід зазначити, що компресія з дедуплікацією є глобальними і постійно включеними, це не опціональна фіча, а архітектура рішення.
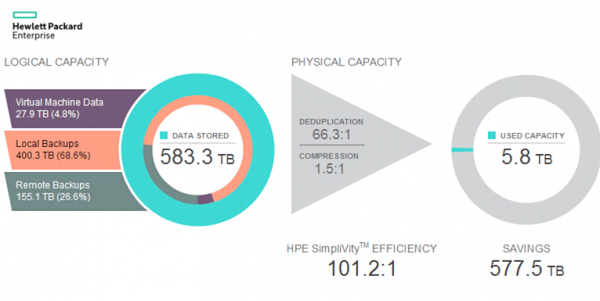
HPE звичайно дещо лукавить, стверджуючи ефективність 100:1, порахувавши особливим чином, але ефективність використання простору справді дуже висока. Просто цифра 100:1 дуже гарна. Давайте розберемося, як реалізована Simplivity технічно, щоб показати такі цифри.
Знімок. Снепшоти (миттєві знімки) - 100% правильно реалізовані як RoW (Redirect-on-Write), а отже відбуваються миттєво і не дають штрафу до продуктивності. Чим, наприклад, відрізняються від деяких інших систем. Навіщо нам потрібні локальні снепшоти без штрафів? Так дуже просто для зниження RPO з 24 годин (середнє RPO для резервного копіювання) до десятків або навіть одиниць хвилин.
резервна копія. Снепшот від бекапу відрізняється лише тим, як його сприймає система керування віртуальними машинами. Якщо при видаленні машини видаляється і все інше — це був снапшот. Якщо залишилося, значить бекап (резервна копія). Таким чином, будь-який снапшот може вважатися і повним бекапом, якщо його помітити в системі і не видаляти.
Звичайно, багато хто заперечить — який же це бекап, якщо він на тій самій системі зберігається? А тут є дуже проста відповідь у вигляді зустрічного питання: скажіть, а у вас є формальна модель загроз, яка встановлює правила зберігання резервної копії? Це абсолютно чесний бекап проти видалення файлу всередині ВМ, це бекап проти видалення самої ВМ. У разі необхідності зберігання резервної копії виключно на окремій системі є на вибір: реплікація цього снепшота на другий кластер Simplivity або на HPE StoreOnce.
І ось саме тут виявляється, що подібна архітектура просто ідеально підходить для будь-якого виду VDI. Адже VDI - це сотні або навіть тисячі вкрай схожих машин з однією і тією ж ОС, з тими самими додатками. Глобальна дедуплікація все це пережує і стисне навіть не 100:1, а набагато краще. Розгорнути 1000 ВМ із одного шаблону? Взагалі не проблема, ці машини довше реєструватимуться в vCenter, ніж клонуватися.
Спеціально для користувачів з особливими вимогами до продуктивності, і для тих, кому потрібні 3D-прискорювачі, була створена лінійка Simplivity G.

У цій серії не використовується апаратний прискорювач дедуплікації і тому знижена кількість дисків на вузол, щоб контролер справлявся програмно. Завдяки цьому звільняються слоти PCIe під будь-які інші прискорювачі. Також подвоєний обсяг доступної пам'яті на вузол до 3ТБ для найвибагливіших навантажень.

Simplivity ідеально підходить для організації географічно розподілених VDI інфраструктур з реплікацією даних до центрального ЦОД.
Подібна архітектура VDI (а втім і не тільки VDI) особливо цікава в умовах російських реалій — величезні відстані (а отже затримки) і далеко не ідеальні канали. Створюються регіональні центри (а навіть і просто 1-2 вузли Simplivity в зовсім віддалений офіс), куди підключаються місцеві користувачі по швидких каналах, зберігається повний контроль та управління з центру, а центр реплікується лише незначна кількість вже справжніх, цінних, а не сміттєвих. даних.
Зрозуміло, Simplivity повністю підключається до OneView та InfoSight.
Тонкі та нульові клієнти
Тонкі клієнти — спеціалізовані рішення для застосування виключно як термінали. Оскільки на клієнт фактично немає навантаження крім підтримки каналу і декодування відео - практично завжди стоїть процесор з пасивним охолодженням, невеликий завантажувальний диск тільки для старту спеціальної ОС, що вбудовується, та загалом і все. Ломатися в ньому практично нема чого, а красти марно. Вартість невелика і жодних даних у ньому не зберігається.
Існує особлива категорія тонких клієнтів, звані нульові клієнти. Їхня основна відмінність від тонких - відсутність навіть вбудовуваної ОС загального призначення, і робота виключно з мікрочіпа з прошивкою. Найчастіше в них ставлять спеціальні апаратні прискорювачі декодування відеопотоку в термінальних протоколах, таких як PCoIP або HDX.
Незважаючи на поділ великого "Хьюлетт Паккард" на окремі HPE та HP, не можна не згадати тонкі клієнти виробництва HP.
Вибір широкий, на будь-який смак та потреби – аж до багатомоніторних робочих місць з апаратним прискоренням відеопотоку.

Сервіс HPE для віддаленої роботи
І останнім за списком, але не за значенням хочу згадати сервіс HPE. Було б надто довго перераховувати всі рівні сервісу HPE та його можливості, але, як мінімум, є одна вкрай важлива пропозиція в умовах віддаленої роботи. А саме – сервісний інженер від HPE/авторизованого сервіс-центру. Ви продовжуєте працювати віддалено, з улюбленої дачі, слухаючи джмелів, поки бджілка від HPE, приїхавши в датацентр, замінює у ваших серверах диски або блок живлення, що вийшов з ладу.
HPE CallHome
В умовах сьогодення, при обмеженні пересування, як ніколи актуальною стає функція Call Home. Будь-яка система HPE з цією функцією може самостійно повідомити про апаратний або програмний збій до центру підтримки HPE. І цілком імовірно, деталь на заміну та/або сервісний інженер прибуде до вас ще задовго до того, як ви помітите неполадки та проблеми з продуктивними сервісами.
Особисто я цю функцію включати настійно рекомендую.
Джерело: habr.com
