

Ця стаття вже друга у темі про швидкісну компресію даних. У першій статті було описано компресор, що працює зі швидкістю 10Гбайт/сек. на одне процесорне ядро (мінімальний стиск, RTT-Min).
Цей компресор, уже впроваджений в обладнання криміналістичних дублікаторів для швидкісного стиснення дампів носіїв інформації та посилення стійкості криптографії, також може застосовуватися для стиснення образів віртуальних машин і своп файлів оперативної пам'яті при збереженні їх на швидкодіючих SSD накопичувачах.
У першій статті також анонсувалась розробка алгоритму компресії для стиснення резервних копій HDD та SSD дискових накопичувачів (середній стиск, RTT-Mid) із суттєво покращеними параметрами стиснення даних. На цей час цей компресор повністю готовий і дана стаття саме про нього.
Компресор, що реалізує алгоритм RTT-Mid, забезпечує ступінь стиснення порівнянну зі стандартними архіваторами типу WinRar, 7-Zip, що працюють у швидкісному режимі. При цьому швидкість його роботи як мінімум на порядок вища.
Швидкість упаковки/розпакування даних є критичним параметром, що визначає сферу застосування технологій компресії. Навряд чи кому спаде на думку стискати терабайт даних зі швидкістю 10-15 МегаБайт на секунду (саме така швидкість архіваторів у стандартному режимі компресії), адже на це доведеться витратити майже двадцять годин при повному завантаженні процесора.
З іншого боку, той же терабайт можна скопіювати на швидкостях порядку 2-3ГігаБайт в секунду хвилин за десять.
Тому стиснення інформації великого обсягу актуальне, якщо його робити зі швидкістю не нижче швидкості реального введення/виводу. Для сучасних систем це не менше 100 мегабайт в секунду.
Такі швидкості сучасні компресори можуть видавати лише у режимі «fast». Ось у цьому актуальному режимі і будемо проводити порівняння алгоритму RTT-Mid із традиційними компресорами.
Порівняльне тестування нового алгоритму компресії
Компресор RTT-Mid працював у складі тестової програми. У реальному "робочому" додатку він працює значно швидше, там грамотно використовується багатопоточність і застосовується "нормальний" компілятор, а не С #.
Оскільки компресори, що використовуються в порівняльному тесті, побудовані на різних принципах і різні типи даних стискають по-різному, то для об'єктивності тесту використовувався метод виміру «середньої температури по лікарні».
Було створено файл посекторного дампа логічного диска з операційною системою Windows 10, це найбільш природна суміш різних структур даних реально наявна кожному комп'ютері. Стиснення цього файлу дозволить провести порівняння за швидкістю і ступенем компресії нового алгоритму з найбільш просунутими компресорами, що використовуються в сучасних архіваторах.
Ось цей файл дампа:
Файл дампа стискався компресорами РТТ-Mid, 7-zip, WinRar. Компресор WinRar та 7-zip були виставлені на максимальну швидкість роботи.
Працює компресор 7-Zip:
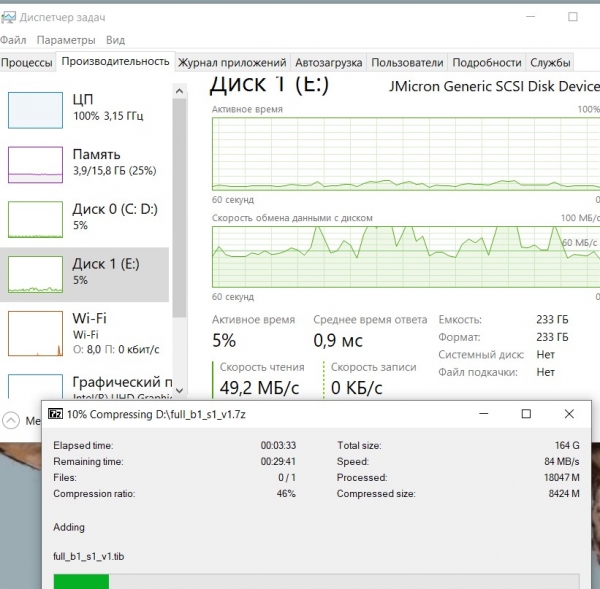
Він вантажить процесор на 100%, причому середня швидкість читання вихідного дампа близько 60 МегаБайт/сек.
Працює компресор WinRAR:
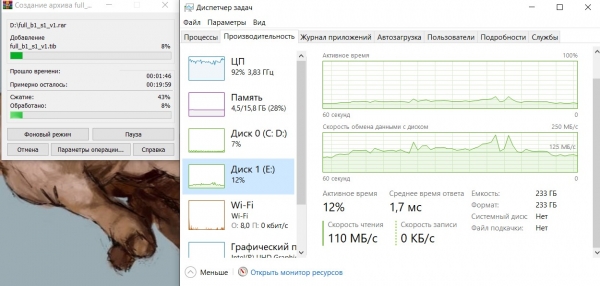
Ситуація аналогічна, завантаження процесора майже 100%, середня швидкість читання дампа близько 125 мегабайт/сек.
Як і попередньому випадку, швидкість роботи архіватора обмежена можливостями процесора.
Тепер працює тестова програма компресора RTT-Mid:
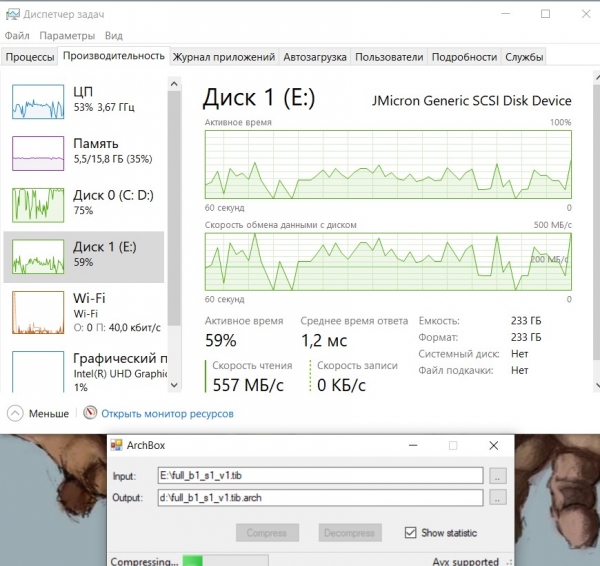
Скріншот показує, що процесор завантажений на 50% і простоює решту часу, тому що нікуди вивантажувати скомпресовані дані. Диск вивантаження даних (диск 0) завантажений практично повністю. Швидкість читання даних (диск 1) сильно скаче, але в середньому більше 200 мегабайт/сек.
Швидкість роботи компресора обмежується у разі можливістю запису стислих даних на Диск 0.
Тепер ступінь стиснення архівів, що вийшли:



Видно, що компресор RTT-Mid найкраще впорався з компресією, архів створений ним на 1,3 ГігаБайту менше архіву WinRar і на 2,1 ГігаБайта менше архіву 7z.
Час витрачений створення архіву:
- 7-zip - 26 хвилин 10 секунд;
- WinRar - 17 хвилин 40 секунд;
- RTT-Mid – 7 хвилин 30 секунд.
Таким чином, навіть тестова, не оптимізована програма, використовуючи алгоритм RTT-Mid, змогла більш ніж у два з половиною рази швидше створити архів, при цьому архів виявився значно меншим, ніж у конкурентів.
Ті, хто не вірить скріншотам, можуть перевірити їхню достовірність самостійно. Тестова програма доступна за , завантажуйте та перевіряйте.
Але тільки на процесорах з підтримкою AVX-2 без підтримки цих інструкцій компресор не працює, і не тестуйте алгоритм на старих процесорах AMD, вони повільні в частині виконання AVX команд.
Використовуваний метод компресії
В алгоритмі використовується метод індексування фрагментів тексту, що повторюються, в байтовій грануляції. Такий метод стиснення відомий давно, але не використовувався, оскільки операція пошуку збігів була дуже затратною за необхідними ресурсами і вимагала набагато більше часу, ніж побудова словника. Отже, алгоритм RTT-Mid є класичним прикладом руху «назад у майбутнє».
У компресорі РТТ використовують унікальний швидкісний сканер пошуку збігів, саме він дозволив прискорити процес компресії. Сканер власного виготовлення, це "моя краса ...", "Ціни він чималої, тому що повністю ручної роботи" (написаний на асемблері).
Сканер пошуку збігів виконаний за дворівневою схемою ймовірності, спочатку сканується наявність «ознака» збігу, і тільки після виявлення «ознака» в цьому місці запускається процедура виявлення реального збігу.
Вікно пошуку збігів має непередбачуваний розмір, що залежить від ступеня ентропії в блоці даних, що обробляється. Для цілком випадкових (нестисканих) даних воно має розмір мегабайт, для даних, що мають повтори, завжди має розмір більше мегабайта.
Але багато сучасних форматів даних не стисливі і «ганяти» за ними ресурсомісткий сканер марно і марнотратно, тому в сканері використовується два режими роботи. Спочатку шукаються ділянки вихідного тексту з можливими повторами, ця операція проводиться також імовірнісним методом і виконується дуже швидко (на швидкості 4-6 ГігаБайт/сек). Потім ділянки з можливими збігами обробляються основним сканером.
Індексне стиск не дуже ефективно, доводиться замінювати фрагменти, що повторюються індексами, і індексний масив істотно знижує коефіцієнт стиснення.
Для збільшення ступеня стиснення індексуються не тільки повні збіги байтових рядків, але і часткові, коли в рядку є байти, що збіглися і не збіглися. Для цього у формат індексу включено поле маски збігів, яка вказує на байти двох блоків, що збіглися. Для ще більшої компресії використовується індексування з накладенням кількох блоків, що частково збігаються, на поточний блок.
Все це дозволило отримати в компресорі РТТ-Mid ступінь стиснення, який можна порівняти з компресорами виконаними за словниковим методом, але працює набагато швидше.
Швидкість роботи нового алгоритму компресії
Якщо компресор працює з монопольним використанням кеш пам'яті (на один потік потрібно 4 мегабайти), то швидкість роботи коливається в діапазоні 700-2000 мегабайт/сек. на одне процесорне ядро в залежності від типу даних, що стискуються, і мало залежить від робочої частоти процесора.
При багатопотоковій реалізації компресора ефективна масштабованість визначається обсягом кеш-пам'яті третього рівня. Наприклад, маючи «на борту» 9 мегабайт кеш-пам'яті запускати більше двох потоків компресії немає сенсу, швидкість зростати від цього не буде. Але при кеші в 20 мегабайт можна вже запускати п'ять потоків компресії.
Також суттєвим параметром визначальним швидкість роботи компресора стає латентність оперативної пам'яті. Алгоритм використовує рандомні звернення до ОП, частина з яких не потрапляє в кеш пам'ять (близько 10%) і йому доводиться простоювати, чекаючи на дані з ОП, що знижує швидкість роботи.
Істотно впливає швидкість компресора і робота системи вводу/вывода даних. Запити до ВП від введення/виведення блокують звернення за даними з боку ЦП, що також знижує швидкість компресії. Ця проблема істотна для ноутбуків та десктопів, серверів вона менш істотна завдяки більш просунутому блоку керування доступом до системної шини та багатоканальної оперативної пам'яті.
Скрізь за текстом у статті йдеться про компресію, декомпресія залишається за рамками цієї статті, оскільки там «все в шоколаді». Декомпресія проводиться значно швидше і обмежується швидкістю введення/виведення. Одне фізичне ядро в одному потоці спокійно забезпечує швидкість розпакування на рівні 3-4 Гб/сек.
Це пов'язано з відсутністю в процесі розпакування операції пошуку збігів, яка зжирає основні ресурси процесора і кеш-пам'яті при компресії.
Надійність зберігання стислих даних
Як випливає з назви всього класу програмних засобів, які використовують компресію даних (архіватори), вони призначені для тривалого зберігання інформації, не роками, а століттями та тисячоліттями.
За час зберігання носії інформації втрачають частину даних, ось приклад:

Цьому «аналоговому» носієві інформації тисяча років деякі фрагменти втрачені, але в цілому інформація «читана»…
Жоден із відповідальних виробників сучасних цифрових систем зберігання даних та цифрових носіїв до них не дає гарантій повного збереження даних більш ніж на 75 років.
І це проблема, але проблема відкладена, вирішуватимуть її наші нащадки…
Системи зберігання цифрових даних можуть втрачати дані не тільки через 75 років, помилки даних можуть з'явитися в будь-який час, навіть під час їх запису, ці спотворення намагаються мінімізувати, використовуючи надмірність і коригуючи системами корекції помилок. Надмірність та системи корекції можуть відновити втрачену інформацію далеко не завжди, а якщо й відновлюють, то немає гарантій, що операція відновлення пройшла коректно.
І це також велика проблема, але не відкладена, а поточна.
Сучасні компресори, що використовуються для архівації цифрових даних, побудовані на різних модифікаціях словникового методу і для таких архівів втрата фрагмента інформації буде фатальною подією, існує навіть усталений термін для такої ситуації — «битий» архів.
Низька надійність зберігання інформації в архівах зі словниковим стиском пов'язана зі структурою стислих даних. Інформація в такому архіві не містить вихідний текст, там зберігаються номери записів у словнику, сам же словник динамічно модифікується поточним текстом. У разі втрати або спотворення фрагмента архіву всі наступні записи архіву неможливо ідентифікувати ні за вмістом, ні за довжиною запису в словнику, оскільки незрозуміло чому відповідає номер словникового запису.
Відновити інформацію з такого «битого» архіву неможливо.
Алгоритм RTT побудований на основі надійнішого методу зберігання стислих даних. У ньому застосовується індексний метод обліку фрагментів, що повторюються. Такий підхід до компресії дозволяє мінімізувати наслідки спотворення інформації на носії, і в багатьох випадках автоматично коригувати спотворення, що виникли при зберіганні інформації.
Це пов'язано з тим, що архівний файл у разі індексного стиснення містить два поля:
- поле вихідного тексту з віддаленими із нього ділянками повтору;
- поле індексів.
Критично важливе відновлення інформації поле індексів, невелике за розміром і його можна дублювати для надійності зберігання даних. Тому навіть якщо буде втрачено фрагмент вихідного тексту або індексного масиву, то решта інформації буде відновлюватися без проблем, як на картинці з «аналоговим» носієм інформації.
Недоліки алгоритму
Переваг не буває без недоліків. Індексний метод компресії не стискає послідовності малої довжини, що повторюються. Це з обмеженнями індексного методу. Індекси мають розмір щонайменше 3 байт і може бути розміром до 12байт. Якщо зустрічається повтор з меншим розміром ніж описує його індекс, то він не враховується, як часто такі повтори не виявлялися в стисливому файлі.
Традиційний, словниковий метод компресії ефективно стискає множинні повтори малої довжини і тому досягає більшого коефіцієнта стиснення ніж індексна компресія. Правда це досягається за рахунок високої завантаженості центрального процесора, щоб словниковий метод почав стискати дані ефективніше індексного методу, йому доводиться знижувати швидкість обробки даних до 10-20 мегабайт в секунду на реальних обчислювальних установках при повному завантаженні ЦП.
Такі низькі швидкості неприйнятні для сучасних систем зберігання даних і представляють більший «академічний» інтерес, ніж практичний.
Ступінь стиснення інформації буде суттєво підвищено в наступній модифікації алгоритму РТТ (RТТ-Max), він вже у розробці.
Тож як завжди, продовження слідує…
Джерело: habr.com
