


У наших проектах ми використовуємо мікросервісну архітектуру. У разі вузьких місць у продуктивності досить багато часу витрачається моніторинг і розбір логів. При логуванні таймінгів окремих операцій на лог-файл, зазвичай, складно зрозуміти що призвело до виклику цих операцій, відстежити послідовність дій чи усунення у часі однієї операції щодо інший у різних сервісах.
Для мінімізації ручної праці ми вирішили скористатися одним із інструментів трасування. Про те, як і для чого можна використовувати трасування і як це робили ми, і йтиметься у цій статті.
Які проблеми можна вирішити за допомогою трасування
- Знайти вузькі місця у продуктивності як усередині одного сервісу, так і у всьому дереві виконання між усіма сервісами, що беруть участь. Наприклад:
- Багато коротких послідовних викликів між сервісами, наприклад, на геокодинг чи базі даних.
- Довгі очікування введення виводу, наприклад, передача даних через мережу або читання з диска.
- Довгий парсинг даних.
- Довгі операції, що вимагають cpu.
- Ділянки коду, які не потрібні для отримання кінцевого результату і можуть бути видалені або запущені відкладено.
- Наочно зрозуміти в якій послідовності що викликається і що відбувається, коли виконується операція.

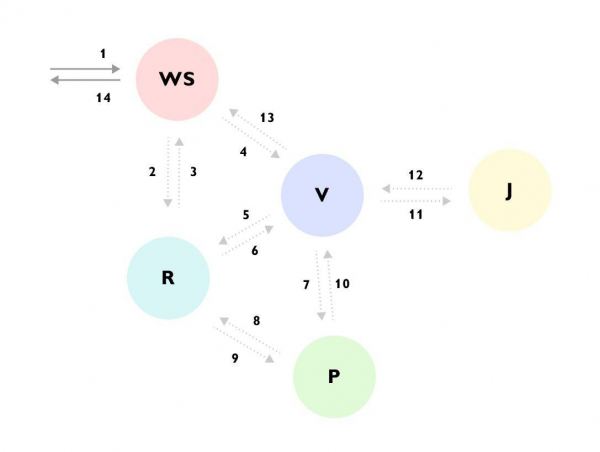
Видно що, наприклад, Запит прийшов у сервіс WS -> сервіс WS доповнив дані через сервіс R -> далі відправив запит у сервіс V -> сервіс V завантажив багато даних із сервісу R -> сходив у сервіс P -> сервіс Р ще раз сходив у сервіс R -> сервіс V проігнорував результат і пішов у сервіс J -> і лише потім повернув відповідь у сервіс WS, при цьому продовжуючи у фоні обчислювати щось ще.
Без такого трейсу або детальної документації на весь процес дуже складно зрозуміти, що відбувається, вперше глянувши на код, та й код розкиданий по різних сервісах і прихований за купою бінів та інтерфейсів. - Збір інформації про дерево виконання для подальшого відкладеного аналізу. На кожному етапі виконання в трейс можна додати інформацію, яка доступна на даному етапі і далі розібратися, які вхідні дані призвели до подібного сценарію. Наприклад:
- ID користувача
- Права
- Тип вибраного методу
- Лог чи помилка виконання
- Перетворення трейсів на підмножину метрик та подальший аналіз вже у вигляді метрик.
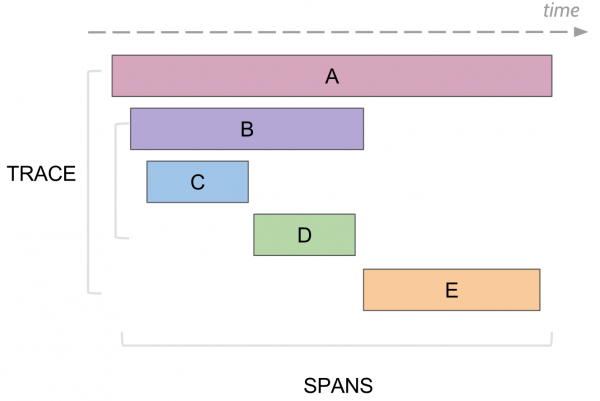
Що вміє логувати трасування. Span
У трасуванні є поняття «спан», це аналог одного лога, в консоль. У спана є:
- Назва, зазвичай це назва методу, який виконувався
- Назва сервісу, в якому було згенеровано спан
- Власний унікальний ID
- Якась мета інформація у вигляді key/value, яку залогували до нього. Наприклад, параметри методу чи закінчився метод помилкою чи ні
- Час початку та кінця виконання цього спану
- ID батьківського спану
Кожен спан відправляється в collector спанів для збереження в базу для подальшого перегляду, як тільки він завершив своє виконання. Надалі можна побудувати дерево всіх спанів з'єднуючи по id батька. При аналізі можна знайти, наприклад, всі спани в якомусь сервісі, які зайняли більше часу. Далі, перейшовши на конкретний спан, побачити все дерево вище та нижче цього спану.
Opentrace, Jagger та як ми реалізували це для своїх проектів
Є загальний стандарт , Який описує як і що має збиратися, не прив'язуючись трасуванням до конкретної реалізації в будь-якій мові. Наприклад, Java вся робота з трейсами ведеться через загальний API Opentrace, а під ним може ховатися, наприклад, Jaeger або порожня дефолтна реалізація яка нічого не робить.
У нас використовується як імпліментація Opentrace Він складається з кількох компонентів:
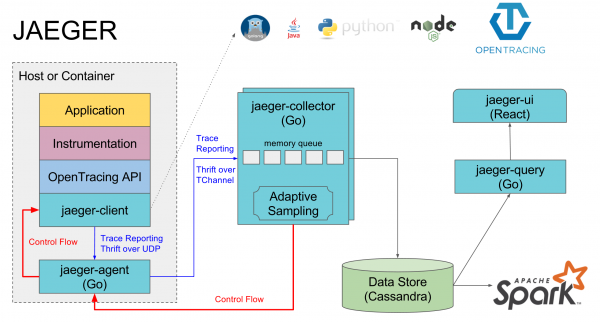
- Jaeger-agent - локальний агент, який зазвичай стоїть на кожній машині і в нього логують послуги на локальний дефолтний порт. Якщо агента немає, то трейси всіх сервісів на цій машині зазвичай вимкнені.
- Jaeger-collector - у нього всі агенти посилають зібрані трейси, а він кладе їх до обраної БД
- База даних - переважна у них cassandra, але у нас використовується elasticsearch, є реалізації ще під пару інших бд і in memory реалізація, яка нічого не зберігає на диск
- Jaeger-query - це сервіс, який ходить в базу даних і віддає вже зібрані трейси для аналізу
- Jaeger-ui - це веб-інтерфейс для пошуку та переглядів трейсів, він ходить в jaeger-query
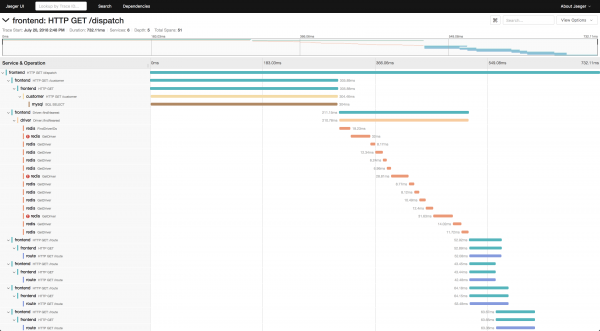
Окремим компонентом можна назвати реалізацію opentrace jaeger під конкретні мови, через яку спани відправляються в jaeger-agent.
зводиться до того, щоб заімпліментувати інтерфейс io.opentracing.Tracer, після чого всі трейси через нього будуть відлітати в реальний агент.
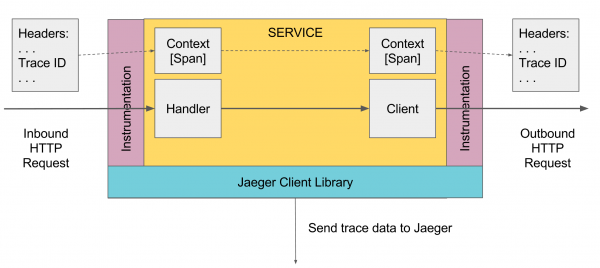
Також для компонент спрингу можна підключити та імплементацію від Jaeger яка законфігурить автоматично трасування на все, що проходить через ці компоненти, наприклад http запити в контролери, запити до БД через jdbc і т.д.
Логування трейсів у Java
Десь на самому верхньому рівні повинен бути створений перший Span, це може бути зроблено автоматично, наприклад, контролером спрингу при отриманні запиту, або вручну якщо такого немає. Далі він передається через Scope нижче. Якщо якийсь метод нижче хоче додати Span, він бере з Scope поточний activeSpan, створює новий Span і говорить, що його батьківський отриманий activeSpan, і робить новий Span active. При виклик зовнішніх сервісів їм передається поточний активний спан, і ті створюють нові спани з прив'язкою до цього спану.
Вся робота йде через інстанс Tracer, отримати його можна через механізм DI або GlobalTracer.get() як глобальну змінну, якщо механізм DI не працює. По дефолту якщо tracer не був проініціалізований повернеться NoopTracer котрий нічого не робить.
Далі з tracer через ScopeManager дістається поточний scope, створюється новий scope від поточного з прив'язкою нового спану, а надалі закривається створений Scope, який закриває створений спан і повертає в активний стан минулий Scope. Scope прив'язаний до потоку, тому при багатопоточному програмуванні треба не забувати передавати активний спан в інший потік для подальшої активації Scope іншого потоку з прив'язкою до цього спану.
io.opentracing.Tracer tracer = ...; // GlobalTracer.get()
void DoSmth () {
try (Scope scope = tracer.buildSpan("DoSmth").startActive(true)) {
...
}
}
void DoOther () {
Span span = tracer.buildSpan("someWork").start();
try (Scope scope = tracer.scopeManager().activate(span, false)) {
// Do things.
} catch(Exception ex) {
Tags.ERROR.set(span, true);
span.log(Map.of(Fields.EVENT, "error", Fields.ERROR_OBJECT, ex, Fields.MESSAGE, ex.getMessage()));
} finally {
span.finish();
}
}
void DoAsync () {
try (Scope scope = tracer.buildSpan("ServiceHandlerSpan").startActive(false)) {
...
final Span span = scope.span();
doAsyncWork(() -> {
// STEP 2 ABOVE: reactivate the Span in the callback, passing true to
// startActive() if/when the Span must be finished.
try (Scope scope = tracer.scopeManager().activate(span, false)) {
...
}
});
}
}Для багатопоточного програмування також є TracedExecutorService і аналогічні обгортки, які автоматично прокидають поточний спан у потік при запуску асинхронного таски:
private ExecutorService executor = new TracedExecutorService(
Executors.newFixedThreadPool(10), GlobalTracer.get()
);Для зовнішніх http запитів є
HttpClient httpClient = new TracingHttpClientBuilder().build();Проблеми, з якими ми зіткнулися
- Біни та DI не завжди працює якщо tracer використовується не в сервісі чи компоненті, тоді Tracer може не працювати і доведеться використовувати GlobalTracer.get().
- Не працюють інструкції якщо це не компонент або сервіс, або якщо виклик методу походить із сусіднього методу того ж класу. Потрібно бути акуратним, перевіряти, що працює, і використовувати ручне створення трейсу, якщо @Traced не працює. Також можна прикрутити додатковий компайлер для java анотацій, тоді повинні працювати скрізь.
- У старих spring та spring boot не працює автоконфігурація opentraing spring cloud через баги в DI, тоді якщо хочеться щоб працювали автоматично трейси в компонентах спрингу можна зробити за аналогією з
- У groovy не працює try with resources, треба обов'язково використовувати try finally.
- У кожного сервісу треба прописувати свій spring.application.name під яким логуватимуться трейси. При чому окремий name для прода та тесту, щоб не заважати їх разом.
- Якщо використовувати GlobalTracer і tomcat, то всі сервіси запущені в цьому tomcat мають один GlobalTracer, тому у них буде на всіх одне ім'я сервісу.
- При додаванні трейсів у метод, треба бути впевненим, що він не викликається в циклі багато разів. Потрібно додати один загальний трейс на всі виклики, що залогує сумарний час роботи. Інакше створюватиметься надмірне навантаження.
- Один раз у jaeger-ui робили надто великі запити на велику кількість трейсів і тому що не чекали відповіді робили ще раз. У результаті jaeger-query став їсти багато пам'яті та гальмувати еластик. Допомогло рестартом jaeger-query
Семплювання, зберігання та перегляд трейсів
Є три типи :
- Const який відправляє та зберігає всі трейси.
- Probabilistic котрий фільтрує трейси з якоюсь заданою ймовірністю.
- Ratelimiting котрий обмежує число трейсів за секунду. Можна налаштувати ці параметри на клієнті, або на jaeger-agent або в колекторі. Зараз у нас у стеку валюаторів використовується const 1, оскільки запитів не дуже багато, але вони займають тривалий час. Надалі, якщо це буде надавати зайве навантаження на систему, можна обмежити.
Якщо використовувати cassandra, то по дефолту вона зберігає трейси лише за два дні. У нас використовується і трейси зберігаються весь час і не видаляються. На кожен день створюється окремий індекс, наприклад, jaeger-service-2019-03-04. Надалі треба налаштувати автоматичне підчищення старих трейсів.
Для того щоб подивитися трейси потрібно:
- Вибрати сервіс, за яким хочеться пофільтрувати трейси, наприклад tomcat7-default для сервісу, який запущений у томкаті і не може мати свого імені.
- Далі вибрати операцію, часовий проміжок і мінімальний час операції, наприклад, від 10 секунд, щоб взяти тільки довгі виконання.

- Перейти в один з трейсів і дивитися, що там гальмувало.

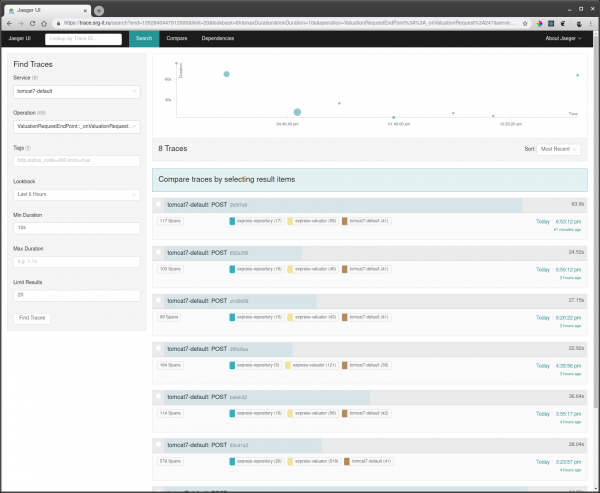
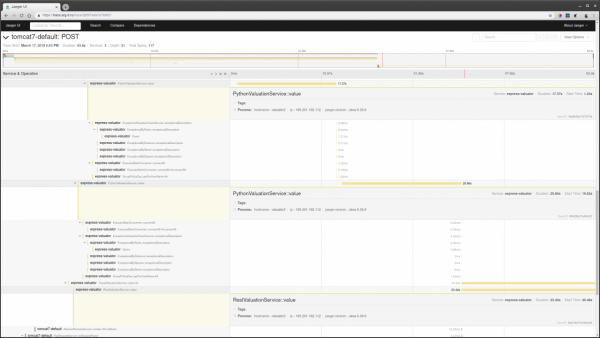
Також якщо відомий якийсь id запиту, можна знайти трейс з цього id через пошук за тегами, якщо цей id логується в спан трейса.
Документація
- Документація opentracing
- Документація jaeger
- Підключення jaeger java
- Підключення spring opentracing
Статті
- Jaeger Opentracing та Microservices у реальному проекті на PHP та Golang
- Evolving Distributed Tracing в Uber Engineering
- Running Jaeger Agent on bare metal
Відео
- How We Used Jaeger and Prometheus to Deliver Lightning-Fast User Queries — Bryan Boreham
- Intro: Jaeger - Yuri Shkuro, Uber & Pavol Loffay, Red Hat
- Serghei Iakovlev, “Маленька історія великої перемоги: OpenTracing, AWS та Jaeger”
Джерело: habr.com
