

Всім привіт. Нижче представлено розшифровку .
– система моніторингу різних систем та сервісів, за допомогою якої системні адміністратори можуть збирати інформацію про поточні параметри систем та налаштовувати оповіщення для отримання повідомлень про відхилення у роботі систем.
У доповіді буде порівняння и - Проектів для довгострокового зберігання метрик Prometheus.



Спочатку розповім про Prometheus. Це система моніторингу, яка збирає метрики із заданих target'ів та зберігає їх у локальне сховище. Prometheus вміє записувати метрики у віддалене сховище, вміє генерувати alert'и та recording rules.

Обмеження Prometheus:
- Він не має global query view. Це коли у вас є кілька незалежних екземплярів prometheus. Вони збирають метрики. І ви хочете зробити запит поверх всіх цих метрик, зібраних з різних екземплярів prometheus. Prometheus це не дозволяє.
- У prometheus продуктивність обмежена лише одним сервером. Prometheus автоматично не може масштабуватися на кілька серверів. Ви тільки можете вручну розділити ваші target'и між кількома Prometheus'ами.
- Обсяг метрик в Prometheus обмежений лише одним сервером з тієї ж причини, через яку він автоматично не може автоматично масштабуватися на кілька серверів.
- У Prometheus не так просто організувати збереження даних.

Вирішення цих проблем/завдань?
Рішення такі:
Всі ці рішення для віддаленого зберігання даних, зібраних Prometheus. Вони вирішують проблему remote storage з попереднього слайду по-різному. У цій презентації я розповім лише про перші два рішення: и .
Вперше інформація про з'явилася по . Там описано архітектуру та як він працює.

Thanos бере дані, які зберегли Prometheus на локальний диск, і копіюють їх в S3, в або в інший object storage.

Таким чином Thanos забезпечує global query view. Ви можете запитувати дані, збережені в object storage з кількох екземплярів Prometheus.

Thanos підтримує PromQL та .

Thanos використовує код Prometheus для зберігання даних.

Thanos розробляє самі розробники, як і Prometheus.
Про . Ось , де ми вперше розповіли про .
VictoriaMetrics отримує дані з декількох prometheus по протоколу, що підтримується Prometheus.
VictoriaMetrics забезпечує global query view, тому що кілька екземплярів Prometheus можуть записувати дані в одну VictoriaMetrics. Відповідно, ви можете зробити запити за цими всіма даними.

VictoriaMetrics також підтримує, як і Thanos - PromQL та Prometheus querying API.

На відміну від Thanos, вихідний код VictoriaMetrics написаний з нуля та оптимізований за швидкістю та споживаними ресурсами.

VictoriaMetrics на відміну Thanos, масштабується як вертикально і горизонтально. Є , Що масштабується вертикально. Ви можете почати з одного процесора та 1 ГБ пам'яті і поступово зростати до сотні процесорів та 1ТБ пам'яті. VictoriaMetrics вміє використовувати усі ці ресурси. Її продуктивність зросте приблизно 100 разів проти 1-ядерної системою.

Історія Thanos розпочалася у листопаді 2017 року, коли з'явився перший публічний коміт. До цього Thanos розроблявся всередині компанії .

У червні 2019 року був знаковий реліз 0.5.0, у якому протокол. Його прибрали з Thanos, тому що він показав себе не з кращого боку. Часто кластер Thanos неправильно працював, неправильно підключалися до нього ноди завдяки gossip протоколу. Тож вирішили його звідти прибрати. Я вважаю, що це правильне рішення.

У тому ж червні 2019 року вони надіслали заявку на номер в .

І через пару місяців Thanos прийняли в , До якої входить Prometheus, Kubernetes та інші популярні проекти.

У січні 2018 року розпочалася розробка VictoriaMetrics.

У вересні 2018 року я вперше публічно згадав про VictoriaMetrics.

У грудні 2018 року опублікували версію Single-node.

У травні 2019 Вихідники як Single-node, так і кластерної версії.

У червні 2019 року, також як Thanos, ми подали заявку в CNCF foundation під номером . Ми подали заявку на день раніше, ніж подав заявку Thanos.

Але, на жаль, нас і досі не прийняли туди. Потрібна допомога ком'юніті.

Розглянемо найголовніші слайди, що показують архітектуру Thanos та VictoriaMetrics.
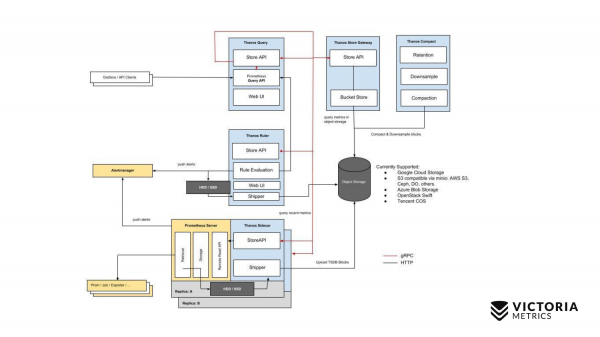
Почнемо із Thanos. Жовті компоненти – це компоненти Prometheus. Все інше – це компоненти Thanos. Почнемо з найголовнішого компонента. Thanos Sidecar – це компонент, який встановлюється поряд із кожним Prometheus. Він займається тим, що завантажує дані Prometheus з локального storage в S3 або в інший Object Storage.
Є ще такий компонент, як Thanos Store Gateway, який вміє зчитувати ці дані з Object Storage при запитах від Thanos Query. Thanos Query реалізує PromQL та Prometheus API. Тобто зовні він виглядає як Prometheus. Приймає запити PromQL, надсилає їх до Thanos Store Gateway, Thanos Store Gateway дістає потрібні дані з Object Storage, відправляє їх назад.
Але у нас в Object Storage зберігаються дані без останніх двох годин через особливості реалізації Thanos Sidecar, який не може закачати останні дві години в Object Storage S3, тому що для цих двох годин Prometheus ще не створив файли в локальному сховищі.
Як же це вирішили оминути? Thanos Query крім, запитів у Thanos Store Gateway, відправляє паралельно запити ще у кожен Thanos Sidecar, який знаходяться поряд із Prometheus.
А Thanos Sidecar, у свою чергу, проксує запити далі в Prometheus і дістає дані за останні дві години.
Крім цих компонентів, є ще опціональний компонент, без якого Thanos погано почуватиметься. Це Thanos Compact, який займається злиттям дрібних файлів на Object Storage в великі файли, які були завантажені сюди Thanos Sidecar'ами. Thanos Sidecar завантажує файли з даними за дві години. Ці файли, якщо їх не зливати в більші файли, їх кількість може виростити дуже істотно. Чим більше таких файлів, тим більше потрібно пам'яті для Thanos Store Gateway, тим більше ресурсів для передачі даних по мережі, метаданих. Робота Thanos Store Gateway стає неефективною. Тому потрібно обов'язково запускати Thanos Compact, який зливає дрібні файли у більші, щоб таких файлів було менше і щоб зменшити overhead на Thanos Store Gateway.
Є ще такий компонент, як Thanos Ruler. Він виконує Prometheus alerting rules і може обчислювати Prometheus recording rules, щоб записувати дані знову в Object Storage. Але це компонент рекомендується використовувати, т.к. він .
Ось така схема проста у Thanos.
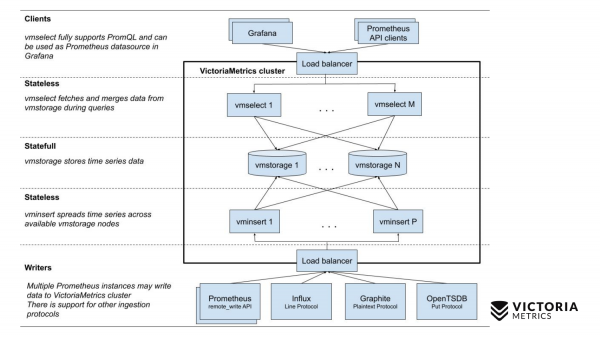
Тепер порівняємо із схемою VictoriaMetrics.
У VictoriaMetrics є 2 версії: Single-node та кластерна версія. Single-node працює на одному комп'ютері. У Single-node немає цих компонентів, просто один бінарник. Цей бінарник на слайді виглядає цим квадратом. Все, що знаходиться всередині квадрата, - це вміст бінарного файлу для Single-node версії. Вам необов'язково знати про нього. Просто запускаєте бінарник і все у нас працює.
Кластерна версія складніша. Усередині неї три різні компоненти: vmselect, vminsert і vmstorage. З їхньої назви має бути зрозуміло, чим кожен із них займається. Insert компонент приймає дані у різних форматах: з Prometheus remote write API, Influx line протоколу, Graphite протоколу та з OpenTSDB протоколу. Insert компонент приймає їх, парсит і розподіляє між наявними storage компонентами, де дані вже зберігаються. Select компонент, у свою чергу, приймає PromQL запити. Він реалізує , а також Prometheus querying API, і він може бути використаний як заміна Prometheus в Grafana або інших Prometheus API клієнтів. Select приймає promql запит, парсить його, зчитує необхідні дані для виконання цього запиту зі storage нод, процесує ці дані та повертає відповідь.

Порівняємо складність установки Thanos та VictoriaMetrics.

Почнемо з Thanos. Перед тим, як почати працювати з Thanos, потрібно створити bucket у Object Storage, такий як S3 або GCS, щоб Thanos Sidecar міг туди записувати дані.

Потім для кожного Prometheus необхідно встановити Thanos Sidecar. Перед цим потрібно не забути відключити data compaction у Prometheus. Data compaction періодично стискає дані в локальному сховищі Prometheus для того, щоб зменшити споживання ресурсів.
Коли ви встановлюєте Thanos Sidecar до ваших Prometheus'ів, ви повинні відключити цей data compaction, тому що Thanos Sidecar не вміє нормально працювати при включеному data compaction. Це означає, що ваш Prometheus починає зберігати дані блоками по дві години і перестає зливати ці блоки у більші. Відповідно, якщо ви робите запити, які перевищують тривалість протягом останніх двох годин, то вони будуть не настільки ефективно працювати, порівняно з тим, як могли б працювати, якщо був би включений data compaction.

Тому Thanos рекомендує зменшувати час зберігання даних (data retention) у локальному storage до 6-8 годин, щоб знизити цей overhead великої кількості дрібних блоків.
Після того, як ви встановили Thanos Sidecar, ви повинні для кожного Object Storage Bucket встановити два компоненти. Це Thanos Compactor та Thanos Store Gateway.

Після цього потрібно встановити Thanos Query і налаштувати його, щоб він умів підключатися до всіх Thanos Store Gateway, які у вас є, а також умів підключатися до всіх Thanos Sidecar.
Тут може бути маленька проблемка.

Вам потрібно налаштувати надійне та захищене підключення від Thanos Query до цих компонентів. І якщо у вас Prometheus'и знаходяться у різних дата-центрах, або у різних VPC, то до них заборонені підключення ззовні. Але для роботи Thanos Query вам потрібно налаштувати підключення туди, і ви повинні придумати спосіб.
Якщо у вас таких дата-центрів багато, то відповідно знижується надійність усієї системи. Так як Thanos Query повинен постійно тримати підключення до всіх Thanos Sidecar, які розташовані в різних дата-центрах. При кожному вхідному запиті він надсилатиме запити на всі Thanos Sidecar. Якщо з'єднання перерветься, ви отримаєте або повний набір даних, або отримаєте відповідь «кластер не працює».

У VictoriaMetrics дещо простіше. Для Single-node версії досить просто запустити один бінарник і все працює.

У кластерній на версії достатньо запустити всі вищезгадані три типи компонентів у будь-якій необхідній вам кількості, або використовувати для автоматизації запуску компонентів ціна в Kubernetes | Ми ще плануємо зробити Kubernetes оператора. Helm chart не покриває деякі кейси і дозволяє вам вистрілити ногу. Наприклад, він дозволяє зменшити кількість storage node, що призведе до втрати даних.

Після того, як ви запустили один бінарник або кластерну версію, вам достатньо додати до конфіг Prometheus , щоб він почав записувати дані паралельно в локальний storage і remote storage. Як ви помітили, така конфігурація повинна працювати набагато надійніше, ніж конфігурація Thanos. Нам не потрібно тримати підключення від VictoriaMetrics до всіх Prometheus, тому що Prometheus самі підключаються до VictoriaMetrics і передають дані.

Розглянемо супровід Thanos та VictoriaMetrics.

Thanos потрібно стежити за Sidecar, щоб вони не припиняли завантаження даних в Object Storage. Вони можуть припинити це завантаження даних внаслідок помилок завантаження, наприклад у вас тимчасово перервалося мережеве з'єднання з Object Storage або Object Storage тимчасово став недоступним. Thanos Sidecar в цей момент помітить це, повідомить про помилку, може впасти і після цього перестати працювати. Якщо ви не будете моніторити, то у вас перестануть передаватися дані в Object Storage. Якщо пройде час retention (6-8 годин рекомендований), то ви втрачатимете дані, які не потрапили в Object Storage.

Thanos сompactor-и можуть перестати працювати через . Компактори беруть дані з Object Storage і зливають їх у більші шматки даних. Так як сомpactor-и не синхронізовані з Sidecar'ами, то може статися ось що: Sidecar ще не встиг дописати блок, Compactor вирішує, що цей блок повністю записаний. Compactor починає його зчитувати. Він зчитує блок не в повному вигляді та перестає працювати. подробиці .

Store Gateway може віддавати неконсистентні дані через race'ів між Compactor'ом та Sidecar'ами. Тут така сама штука, тому що Store Gateway ніяк не синхронізований з Compactor'ами та Sidecar'ами. Відповідно можуть виникати стан гонок, коли Store Gateway не бачить частину даних, або бачить зайві дані.

Query компонент в Thanos за умовчанням дає частковий результат, якщо деякі Sidecar-и або Store Gateway не доступні в даний момент. Ви отримаєте частину даних і навіть не знатимете, що отримали не всі дані. Це він працює так за замовчуванням. У схожій ситуації VictoriaMetrics повертає позначені дані як часткові.

На відміну від Thanos, VictoriaMetrics рідко втрачає дані. Навіть якщо перервалося підключення від Prometheus до VictoriaMetrics, то не проблема, так як Prometheus продовжується записувати нові дані в Write Ahead Log, розмір якого дорівнює 2 годин. Якщо протягом двох годин відновите підключення до VictoriaMetrics, то дані не загубляться. Prometheus .

На відміну від Thanos, який записує дані в object storage тільки через дві години, Prometheus автоматично реплікує дані remote write протоколу в remote storage, такий як VictoriaMetrics. Вам не страшна втрата місцевої будівлі в Prometheus. Якщо він раптом втратив local storage, то ви найгіршому випадку втратите останні секунди даних, які не встигли записатися в remote storage.

Kubernetes автоматично управляє кластером на відміну Thanos. Всі компоненти Thanos складно помістити в один кластер Kubernetes, на відміну від кластерних компонент VictoriaMetrics.

VictoriaMetrics має дуже просте оновлення на нову версію. Просто зупиняєте VictoriaMetrics, оновлюєте бінарники та запускаєте. При зупинці через сигнал SIGINT всі бінарники VictoriaMetrics роблять gracefull shutdown. Вони правильно зберігають потрібні дані, закривають вхідні з'єднання, щоб нічого не втратити. Тому ви нічого не втратите під час оновлення.

У VictoriaMetrics дуже легко розширювати кластер. Просто додаєте необхідні компоненти та продовжуєте працювати.

Про підводні камені в Thanos та VictoriaMetrics.

У Thanos наступні підводні камені. Prometheus повинен зберігати дані протягом останніх двох годин. Якщо вони загубляться, ви їх повністю втратите, оскільки вони ще не встигли записатися в Object Storage, як S3.

Store Gateway компонент і сompactor компонент може вимагати багато пам'яті для роботи з великим Object Storage, якщо там зберігається багато дрібних файлів. Чим більша кількість та обсяг файлів, тим більше потрібна оперативна пам'ять Store Gateway і сompactor для зберігання метаінформації. У Thanos багато issues з приводу того, що .

Thanos рекламується, що він може скейліться нескінченно на кількість ваших Prometheus. Насправді, це неправда. Так як всі запити йдуть через Query компонент, який повинен паралельно опитати всі Store Gateway компоненти і всі Sidecar компоненти, витягнути звідти дані і потім їх перепроцесувати. Очевидно, що швидкість запитів обмежена найповільнішою слабкою ланкою, найповільнішою Store Gateway або найповільнішою Sidecar.
Ці компоненти можуть бути нерівномірно навантажені. Наприклад, у вас є Prometheus, який збирає мільйони метриків на секунду. І є Prometheus, у якому збирається тисячі метрик за секунду. Prometheus, в якому збираються мільйони метрик за секунду, набагато сильніше завантажує сервер, на якому він працює. Відповідно, Sidecar там працює повільніше. І взагалі, все там повільно працює. І Query компонент буде дуже повільно звідти дані витягувати. Відповідно продуктивність вашого всього кластера буде обмежена цим повільним Sidecar.

За промовчанням Thanos віддає часткове дані, якщо деякі Sidecar'и або Store Gateway недоступні. Наприклад, якщо у вас Sidecar'и розкидані у всьому світі в різних дата-центрах, то ймовірність розриву з'єднання і недоступності компонентів сильно зростає. Відповідно, в більшості випадків ви отримуватимете часткові дані, навіть не знаючи про це.
VictoriaMetrics теж має підводні камені. Перший підводний камінь - це опція, яка обмежує обсяг оперативної пам'яті, що використовується під кеш VictoriaMetrics. За умовчанням вона дорівнює 60% оперативної пам'яті на машині, де VictoriaMetrics запущена або 60% ОЗУ поданої VictoriaMetrics в Kubernetes.
Якщо неправильно змінити це значення, можна загробити продуктивність VictoriaMetrics. Наприклад, якщо встановити занадто низьке значення, дані можуть перестати поміщатися в кеш VictoriaMetrics. Через це їй доведеться робити зайву роботу та навантажувати процесор із диском. Якщо ви зробите цю опцію занадто великою, то це підвищує, по-перше, ймовірність того, що VictoriaMetrics вилітатиме з помилкою out of memory, і, по-друге, це призводитиме до того, що в операційній системі залишатиметься дуже мало оперативної. пам'яті для файлового кешу VictoriaMetrics покладається на файловий кеш для продуктивності. Якщо його недостатньо, може сильно збільшитися навантаження на диск. Тому порада: не змінювати параметр без нагальної потреби.
Друга опція. Це retentionPeriod - період, який за умовчанням виставлений на 1 місяць. Це час, протягом якого VictoriaMetrics зберігає дані. Після закінчення цього терміну VictoriaMetrics дані видаляє.
Багато хто запускає VictoriaMetrics без цього параметра, записує дані протягом місяця. А потім питають: чому дані зникли за попередній місяць? Тому що скиданняперіоду за умовчанням дорівнює 1 місяць. Тому потрібно знати і встановлювати правильний перехідперіоду.

Пройдемося за унікальними можливостями.

У Thanos є така фіча, як downsampling: 5-хвилинні та годинні інтервали, які найчастіше . Якщо погуглить і подивитися їх issue на github, там дуже багато issues, пов'язаних з цим downsampling, що він іноді неправильно працює, або працює не так, як очікують користувачі.

Thanos має дедуплікацію даних для Prometheus HA pairs. Коли два Prometheus'а збирають одні й ті самі метрики з тих самих target'в і Thanos їх складає в Object Storage. Thanos вміє правильно дедуплікувати ці дані, на відміну VictoriaMetrics.

Thanos має alert компонент, який був на схемі Thanos. Але його .

Thanos має перевагу, що код Thanos і Prometheus — загальний. Thanos і Prometheus розроблений одними і тими самими розробниками. При поліпшеннях у Thanos чи Prometheus виграє інший бік.

У VictoriaMetrics головна фіча - MetricsQL. Це розширення VictoriaMetrics для PromQL, про які я розповідав попередньому big monitoring metup.

VictoriaMetrics підтримує заливання даних по безлічі різних протоколів. VictoriaMetrics не тільки може приймати дані від Prometheus, але й за протоколами Influx, OpenTSDB та Graphite.

Дані VictoriaMetrics займають звичайні набагато менше місця порівняно з Thanos та Prometheus.
Якщо записувати реальні дані, то користувачі говорять про 2-5-кратне зменшення розміру даних на диску в порівнянні з Prometheus і Thanos.

Ще одна перевага VictoriaMetrics – вона оптимізована під швидкість.

Пройдемося за вартістю інфраструктури.

Одна з переваг Thanos в тому, що він зберігає дані в object storage, який порівняно дешевий.
При збереженні даних у object storage, ви повинні оплачувати операції запису та читання даних ($10 за мільйон операцій). Коли ви записуєте дані в object storage, ви оплачуєте витрати вашого хостингу на завантаження даних в інтернет, якщо ваш кластер не в AWS — там безкоштовно. Коли ви зчитуєте дані, ви сплачуєте від $10 до $230 за 1ТБ. Це може бути істотно, якщо ви часто запитуєте історичні дані з кластера Thanos.

Для Thanos кластера потрібно оплачувати сервери для Compact, Store Gateway, Query компонентів, які потребують багато пам'яті, ЦПУ для великих обсягів даних.

У VictoriaMetrics витрати такі. Якщо зберігати дані на дисках GCE HDD, то виходить $40 за 1ТБ. Для VictoriaMetrics досить звичайних HDD дисків, не потрібні ніякі SSD, які коштують разів на п'ять дорожче. VictoriaMetrics оптимізована під HDD.

Для VictoriaMetrics потрібні сервери для компонентів: або Single-nod або для кластерних компонентів, які, на відміну від Thanos компонентів, потребують набагато менше ЦПУ, ОЗУ — відповідно будуть дешевшими.

Приклади застосування.

У Thanos приклад застосування – це Gitlab. Gitlab повністю працює на Thanos. Але там не все так гладко. Якщо подивитися на них , то можна побачити, що у них постійно виникають якісь : бракує пам'яті для Store Gateway чи Query компонентів. Їм завжди доводиться збільшувати обсяг пам'яті.
Через це збільшуються витрати на вирішення цих проблем.
Друге впровадження, яке може бути більш успішним, — це компанія Improbable, які почали розробку Thanos. Вони опублікували вихідники Thanos. Improbable - компанія, яка займається розробкою ігрових двигунів.

У VictoriaMetrics громадські приклади застосування це:
- wix.com конструктор сайтів
- Adidas впроваджує VictoriaMetrics і навіть зробив доповідь на останньому PromCon 2019
- TrafficStars - ad network
- Seznam.cz — популярна чеська пошукова система.
А далі пішли ноунейми компанії, які я не можу назвати зараз. Вони не дали згоди.
- Один великий розробник ігор. Більше, ніж їм Improbable.
- Великий розробник графічного програмного забезпечення.
- Великий російський банк.
- Європейський виробник вітряних турбін, що успішно протестував VictoriaMetrics. Цей виробник впроваджує VictoriaMetrics для моніторингу даних, отриманих з вітряних турбін зі швидкістю 50 семплів на секунду на кожен датчик. У кожній вітряній турбіні кілька сотень датчиків. Вони мають кілька сотень вітряних турбін.
- Російські авіалінії, які хочуть запровадити VictoriaMetrics, але не можуть. Ми із ними на стадії договору.
 Висновки.
Висновки.
VictoriaMetrics і Thanos вирішують схожі завдання, але різними способами:
- Global query view
- горизонтальне масштабування
- довільний retention

Спасибо.
Чекаємо на вас нашому .

Тільки зареєстровані користувачі можуть брати участь в опитуванні. , будь ласка.
Що ви використовуєте як long term storage для Prometheus?
35,3%Танос6
0,0%Cortex0
0,0%M3DB0
41,2%VictoriaMetrics7
23,5%інше4
Проголосували 17 користувачів. Утрималися 16 користувачів.
Джерело: habr.com
