


Перед тобою знову завдання детектування об'єктів. Пріоритет - швидкість роботи за прийнятної точності. Береш архітектуру YOLOV3 і донавчаєш. Точність (mAp75) більша за 0.95. Але швидкість прогону все ще низька. Чорт.
Сьогодні обійдемо стороною квантизацію. А під катом розглянемо Модельна обрізка - обрізання надлишкових частин мережі для прискорення Inference без втрати точності. Наочно звідки, скільки і як можна вирізати. Розберемо, як це зробити вручну і де можна автоматизувати. Наприкінці – репозиторій на keras.
Запровадження
На минулому місці роботи, пермському Macroscop, я знайшов одну звичку завжди стежити за часом виконання алгоритмів. А час прогону мереж завжди перевірятиме через фільтр адекватності. Зазвичай state-of-the-art у проді не проходять цей фільтр, що й призвело до мене Pruning.
Pruning - тема стара, про яку розповідали в 2017 року. Основна ідея - зменшення розміру навченої мережі без втрати точності шляхом видалення різних вузлів. Звучить кльово, але я рідко чую про його застосування. Напевно, не вистачає імплементацій, немає російськомовних статей чи просто всі вважають pruning ноу-хау та мовчать.
Але го розбирати
Погляд у біологію
Люблю, коли в Deep Learning заглядають ідеї, які прийшли з біології. Їм, як і еволюції, можна довіряти (а ти знав, що ReLU дуже схожа на ?)
Процес Model Pruning також близький до біології. Реакцію мережі тут можна порівняти із пластичністю мозку. Пара цікавих прикладів є у книзі :
- Мозок жінки, яка мала від народження лише одну половину, перепрограмувала сама себе для виконання функцій відсутньої половини
- Хлопець відстрілив собі частину мозку, яка відповідає за зір. Згодом інші частини мозку взяли він ці функції. (повторити не намагаємось)
Так і з вашої моделі можна вирізати частину слабких згорток. У крайньому випадку, згортки, що залишилися, допоможуть замінити вирізані.
Любиш Transfer Learning чи вчиш з нуля?
Варіант номер один. Ви використовуєте Transfer Learning на Yolov3. Retina, Mask-RCNN чи U-Net. Але найчастіше нам не потрібно розпізнавати 80 класів об'єктів, як у COCO. У моїй практиці все обмежується 1-2 класами. Можна припустити, що архітектура для 80 класів тут надмірна. Напрошується думка, що архітектуру треба зменшити. Причому хотілося б зробити це без втрати наявних ваг.
Варіант номер два. Можливо, у тебе багато даних та обчислювальних ресурсів чи просто потрібна надкастомна архітектура. Неважливо. Але ти вчиш мережу з нуля. Звичайний порядок - дивимося на структуру даних, підбираємо надлишкову за потужністю архітектуру і пушим дропаути від перенавчання. Я бачив дропаути 0.6, Карле.
В обох випадках мережу можна зменшувати. Промотивували. Тепер ідемо розбиратися, що за обрізання pruning
Загальний алгоритм
Ми вирішили, що можемо видаляти пакунки. Виглядає це дуже просто:
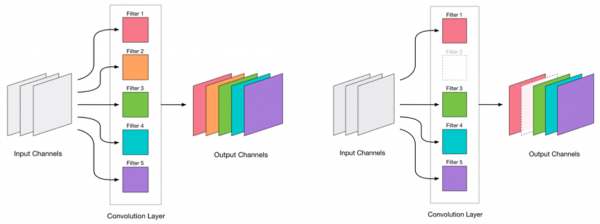
Видалення будь-якого пакунка - це стрес для мережі, який зазвичай веде за собою і деяке зростання помилки. З одного боку, це зростання помилки є показником того, наскільки правильно ми видаляємо пакунки (наприклад, велике зростання говорить про те, що ми робимо щось не так). Але невелике зростання цілком допустиме і часто усувається наступним легким донавчанням з невеликим LR. Додаємо крок донавчання:
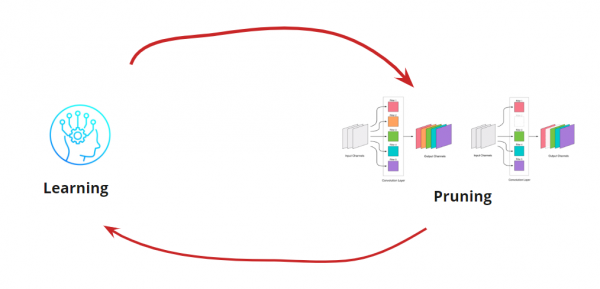
Тепер нам потрібно зрозуміти, коли ми хочемо зупинити наш цикл Learning<->Pruning. Тут можуть бути екзотичні варіанти, коли нам потрібно зменшувати мережу до певного розміру та швидкості прогону (наприклад, для мобільних пристроїв). Однак, найчастіший варіант — це продовження циклу, поки помилка не стане вищою за допустиму. Додаємо умову:
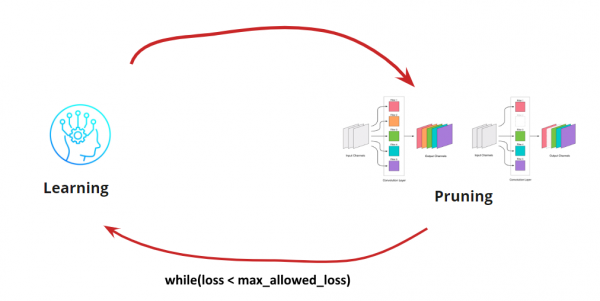
Отже, алгоритм стає зрозумілим. Залишається розібрати, як визначити згортки, що видаляються.
Пошук згорток, що видаляються.
Нам потрібно видалити якісь пакунки. Рватися напролом і «відстрілювати» будь-які — погана ідея, хоч і працюватиме. Але якщо є голова, можна подумати і спробувати виділити для видалення «слабкі» пакунки. Варіантів є кілька:
- . Ідея, що говорить про те, що згортки з малими значеннями ваг, роблять малий внесок у підсумкове прийняття рішення
- Найменша L1-міра з урахуванням середнього та стандартного відхилення. Доповнюємо оцінкою характеру розподілу.
- . Точніше визначення малозначимих згорток, але дуже затратне за часом і ресурсами.
- Інші
Кожен із варіантів має право життя і свої особливості реалізації. Тут розглянемо варіант із найменшою L1-мірою
Ручний процес для YOLOv3
У вихідній архітектурі містяться залишкові блоки. Але хоч би якими крутими вони були для глибоких мереж, нам вони дещо завадять. Складність у тому, що не можна видаляти звіряння з різними індексами у цих шарах:
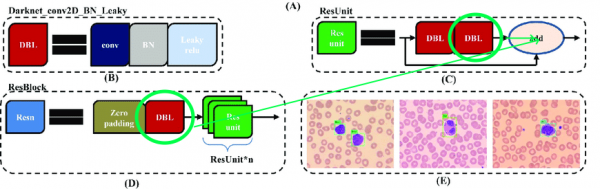
Тому виділимо шари, з яких ми можемо вільно видаляти звіряння:

Тепер збудуємо цикл роботи:
- Вивантажуємо активації
- Прикидаємо, скільки вирізати
- Вирізаємо
- Вчимо 10 епох з LR=1e-4
- Тестуємо
Вивантажувати пакунки корисно, щоб оцінити, яку частину ми можемо видалити на певному кроці. Приклади вивантаження:
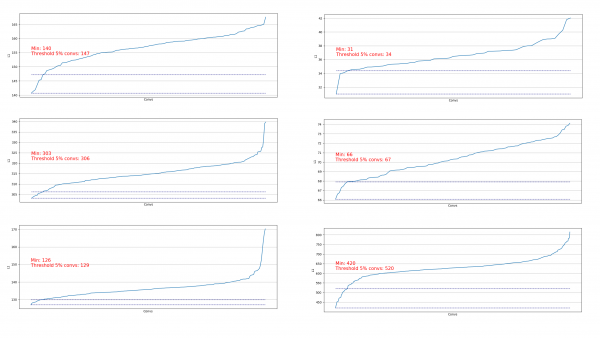
Бачимо, що майже скрізь 5% згорток мають дуже низьку L1-норму і ми можемо їх видалити. На кожному кроці таке вивантаження повторювалося і проводилася оцінка, з яких шарів і скільки можна вирізати.
Весь процес уклався в 4 кроки (тут і скрізь числа для RTX 2060 Super):
| Крок | mAp75 | Число параметрів, млн | Розмір мережі, мб | Від початкової, % | Час прогону, мс | Умова обрізання |
|---|---|---|---|---|---|---|
| 0 | 0.9656 | 60 | 241 | 100 | 180 | - |
| 1 | 0.9622 | 55 | 218 | 91 | 175 | 5% від усіх |
| 2 | 0.9625 | 50 | 197 | 83 | 168 | 5% від усіх |
| 3 | 0.9633 | 39 | 155 | 64 | 155 | 15% для шарів з 400+ згорток |
| 4 | 0.9555 | 31 | 124 | 51 | 146 | 10% для шарів з 100+ згорток |
До 2 кроку додався один позитивний ефект - на згадку вліз батч-сайз 4, що дуже прискорило процес донавчання.
На 4 етапі процес було зупинено, т.к. навіть тривале донавчання не піднімало mAp75 до старих значень.
У результаті вдалося прискорити інференс на 15%, зменшити розмір на 35% і не втратити точно.
Автоматизація для простих архітектур
Для більш простих архітектур мереж (без умовних add, concaternate і residual блоків) цілком можна орієнтуватися на обробку всіх згорткових шарів і автоматизувати процес вирізування згорток.
Такий варіант я заімплементував .
Все просто: з вас тільки функція втрат, оптимізатор та батч-генератори:
import pruning
from keras.optimizers import Adam
from keras.utils import Sequence
train_batch_generator = BatchGenerator...
score_batch_generator = BatchGenerator...
opt = Adam(lr=1e-4)
pruner = pruning.Pruner("config.json", "categorical_crossentropy", opt)
pruner.prune(train_batch, valid_batch)У разі потреби можна змінити параметри конфіги:
{
"input_model_path": "model.h5",
"output_model_path": "model_pruned.h5",
"finetuning_epochs": 10, # the number of epochs for train between pruning steps
"stop_loss": 0.1, # loss for stopping process
"pruning_percent_step": 0.05, # part of convs for delete on every pruning step
"pruning_standart_deviation_part": 0.2 # shift for limit pruning part
}Додатково реалізовано обмеження на основі стандартного відхилення. Мета — обмежити частину видалених, крім згортки з уже «достатніми» L1-мерами:
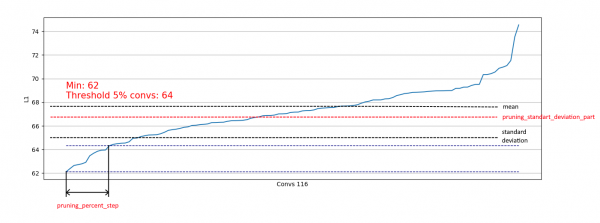
Тим самим ми дозволяємо видалити тільки слабкі згортки з розподілів подібних до правого і не впливати на видалення з розподілів подібних до лівого:

При наближенні розподілу до нормального коефіцієнт pruning_standart_deviation_part можна підібрати з:
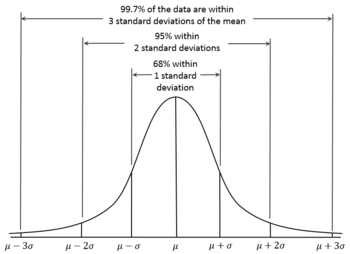
Я рекомендую припущення у 2 сигми. Або можна не орієнтуватися на цю особливість, залишивши значення <1.0.
На виході виходить графік розміру мережі, втрати та часу прогону мережі з усього тесту, віднормовані до 1.0. Наприклад, тут розмір мережі був зменшений майже в 2 рази без втрати в якості (невелика мережа згортки на 100к ваг):
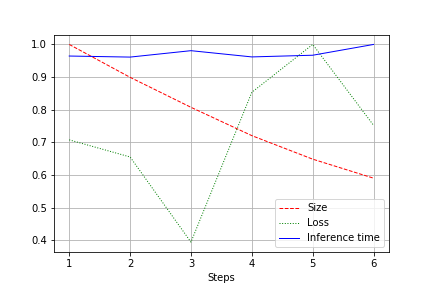
Швидкість прогону схильна до нормальних флуктуацій і практично не змінилася. Цьому є пояснення:
- Число згорток змінюється зі зручного (32, 64, 128) на не найзручніші для відеокарт - 27, 51 і тд. Тут можу помилитись, але швидше за все це впливає.
- Архітектура не широка, але послідовна. Зменшуючи ширину, ми не чіпаємо глибини. Тим самим зменшуємо завантаження, але не змінюємо швидкість.
Тому покращення виявилося у зменшенні завантаження CUDA при прогоні на 20-30%, але не у зменшенні часу прогону
Підсумки
Порефлексуємо. Ми розглянули 2 варіанти pruning - для YOLOV3 (коли доводиться працювати руками) і для мереж з простіше архітектурами. Видно, що в обох випадках можна досягти зменшення розміру мережі та прискорення без втрати точності. Результати:
- Зменшення розміру
- Прискорення прогону
- Зменшення завантаження CUDA
- Як наслідок, екологічність (Ми оптимізуємо майбутнє використання обчислювальних ресурсів. Десь радіє одна )
Додаток
- Після кроку pruning можна докрутити і квантизацію (наприклад, з TensorRT)
- Tensorflow надає можливості для . Працює.
- хочу розвивати і буду радий допомоги
Джерело: habr.com
