

Компанія Google представила новий аудіокодек Lyra, оптимізований для досягнення максимальної якості передачі мови навіть при використанні дуже повільних каналів зв'язку. Код реалізації Lyra написаний на C++ і відкритий під ліцензією Apache 2.0, але серед необхідних роботи залежностей присутня пропрієтарна бібліотека libsparse_inference.so з реалізацією ядра для математичних обчислень. Зазначається, що пропрієтарна бібліотека є тимчасовою – надалі Google обіцяє розробити відкриту заміну та забезпечити підтримку різних платформ.
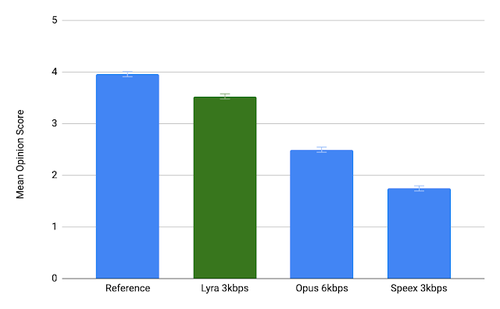
За якістю переданих голосових даних на низьких швидкостях Lyra значно перевершує традиційні кодеки, у яких використовуються методи цифрової обробки сигналів. Для досягнення високої якості передачі голосу в умовах обмеженого об'єму інформації, що передається, крім звичайних методів стиснення звуку і перетворення сигналів, в Lyra застосовується мовна модель на базі системи машинного навчання, що дозволяє відтворити відсутню інформацію на основі типових характеристик мови. Задіяна для генерації звуку модель навчена з використанням кількох тисяч годин з записами голосів більш ніж 70 мовами.
Кодек включає кодувальник і декодувальник. Алгоритм роботи кодувальника зводиться до вилучення параметрів голосових даних кожні 40 мілісекунд, їх стиску та передачі одержувачу по мережі. Для передачі даних достатньо каналу зв'язку зі швидкістю 3 кілобіти на секунду. Вилучені звукові параметри включають логарифмічні крейда-спектрограми, що враховують характеристики енергії мови в різних частотних діапазонах і підготовлені з урахуванням моделі людського слухового сприйняття.
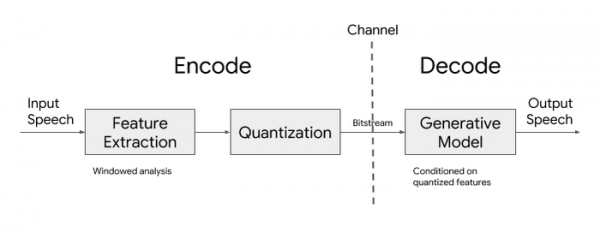
У декодировщике використовується генеративна модель, яка з урахуванням переданих звукових параметрів відтворює сигнал промовою. Для зниження складності обчислень застосована легка модель на основі рекурентної нейронної мережі, що є варіантом моделі синтезу мови WaveRNN, в якому використовується більш низька частота вибірок, але генерується паралельно відразу кілька сигналів в різному діапазоні частот. Отримані сигнали потім накладаються для отримання єдиного вихідного сигналу, що відповідає заданій частоті дискретизації.
Для прискорення також використані спеціалізовані процесорні інструкції, доступні в 64-розрядних процесорах ARM. У результаті, незважаючи на застосування машинного навчання, кодек Lyra може застосовуватися для кодування та декодування мови в реальному режимі часу на смартфонах середнього цінового діапазону, демонструючи затримку передачі сигналу на рівні 90 мілісекунд.
Джерело: opennet.ru
