


جدید ویب میڈیا مواد کے بغیر تقریباً ناقابل تصور ہے: تقریباً ہر دادی کے پاس اسمارٹ فون ہے، ہر کوئی سوشل نیٹ ورکس پر ہے، اور دیکھ بھال کا وقت کمپنیوں کے لیے مہنگا ہے۔ یہاں کمپنی کی کہانی کا ایک نقل ہے۔ اس کے بارے میں کہ اس نے ہارڈ ویئر کے حل کا استعمال کرتے ہوئے تصاویر کی ترسیل کو کس طرح منظم کیا، اس عمل میں اسے کارکردگی کے کن مسائل کا سامنا کرنا پڑا، ان کی وجہ کیا ہے، اور ان مسائل کو Nginx پر مبنی سافٹ ویئر حل کا استعمال کرتے ہوئے کیسے حل کیا گیا، ہر سطح پر غلطی کی رواداری کو یقینی بناتے ہوئے ()۔ ہم اولیگ کی کہانی کے مصنفین کا شکریہ ادا کرتے ہیں۔ ایفیمووا اور الیگزینڈرا ڈیمووا، جنہوں نے کانفرنس میں اپنا تجربہ شیئر کیا۔ .
- آئیے اس بارے میں ایک چھوٹا سا تعارف شروع کرتے ہیں کہ ہم فوٹوز کو کیسے اسٹور اور کیش کرتے ہیں۔ ہمارے پاس ایک پرت ہے جہاں ہم انہیں ذخیرہ کرتے ہیں، اور ایک پرت جہاں ہم تصاویر کو کیش کرتے ہیں۔ اس کے ساتھ ہی، اگر ہم ایک اعلی چال کی شرح حاصل کرنا چاہتے ہیں اور اسٹوریج پر بوجھ کو کم کرنا چاہتے ہیں، تو ہمارے لیے یہ ضروری ہے کہ ایک فرد صارف کی ہر تصویر ایک کیشنگ سرور پر ہو۔ بصورت دیگر، ہمیں اس سے کئی گنا زیادہ ڈسکیں انسٹال کرنی پڑیں گی جتنی ہمارے پاس زیادہ سرور ہیں۔ ہماری چال کی شرح تقریباً 99 فیصد ہے، یعنی ہم اپنے اسٹوریج پر بوجھ کو 100 گنا کم کر رہے ہیں، اور ایسا کرنے کے لیے، 10 سال پہلے، جب یہ سب کچھ بنایا جا رہا تھا، ہمارے پاس 50 سرور تھے۔ اس کے مطابق، ان تصاویر کو پیش کرنے کے لیے، ہمیں بنیادی طور پر 50 بیرونی ڈومینز کی ضرورت ہے جو یہ سرور پیش کرتے ہیں۔
قدرتی طور پر، فوری طور پر سوال پیدا ہوا: اگر ہمارا کوئی سرور ڈاون ہو جاتا ہے اور دستیاب نہیں ہو جاتا ہے، تو ہم ٹریفک کا کون سا حصہ کھو دیتے ہیں؟ ہم نے دیکھا کہ مارکیٹ میں کیا ہے اور ہارڈ ویئر کا ایک ٹکڑا خریدنے کا فیصلہ کیا تاکہ اس سے ہمارے تمام مسائل حل ہو جائیں۔ انتخاب F5-نیٹ ورک کمپنی کے حل پر پڑا (جس نے حال ہی میں NGINX, Inc خریدا): BIG-IP لوکل ٹریفک مینیجر۔

ہارڈ ویئر کا یہ ٹکڑا (LTM) کیا کرتا ہے: یہ ایک آئرن راؤٹر ہے جو اپنی بیرونی بندرگاہوں کو آئرن فالتو بناتا ہے اور آپ کو کچھ سیٹنگز پر، نیٹ ورک ٹوپولوجی کی بنیاد پر ٹریفک کو روٹ کرنے کی اجازت دیتا ہے، اور صحت کی جانچ کرتا ہے۔ ہمارے لیے یہ ضروری تھا کہ ہارڈ ویئر کے اس ٹکڑے کو پروگرام کیا جا سکے۔ اس کے مطابق، ہم اس منطق کی وضاحت کر سکتے ہیں کہ کس طرح کسی مخصوص صارف کی تصاویر کو مخصوص کیش سے پیش کیا گیا تھا۔ یہ کیسا لگتا ہے؟ ہارڈ ویئر کا ایک ٹکڑا ہے جو انٹرنیٹ کو ایک ڈومین، ایک IP پر دیکھتا ہے، ssl آف لوڈ کرتا ہے، HTTP درخواستوں کو پارس کرتا ہے، IRule سے کیش نمبر منتخب کرتا ہے، کہاں جانا ہے، اور ٹریفک کو وہاں جانے دیتا ہے۔ اسی وقت، یہ صحت کی جانچ کرتا ہے، اور کچھ مشین دستیاب نہ ہونے کی صورت میں، اس وقت ہم نے اسے اس طرح بنایا کہ ٹریفک ایک بیک اپ سرور پر چلا گیا۔ ترتیب کے نقطہ نظر سے، یقینا، کچھ باریکیاں موجود ہیں، لیکن عام طور پر سب کچھ بہت آسان ہے: ہم ایک کارڈ رجسٹر کرتے ہیں، نیٹ ورک پر ہمارے IP پر ایک مخصوص نمبر کی خط و کتابت، ہم کہتے ہیں کہ ہم بندرگاہوں پر سنیں گے 80 اور 443، ہم کہتے ہیں کہ اگر سرور دستیاب نہیں ہے، تو آپ کو بیک اپ والے پر ٹریفک بھیجنے کی ضرورت ہے، اس معاملے میں 35 ویں، اور ہم اس بارے میں منطق کا ایک گروپ بیان کرتے ہیں کہ اس فن تعمیر کو کیسے الگ کیا جانا چاہیے۔ مسئلہ صرف یہ تھا کہ جس زبان میں ہارڈ ویئر کو پروگرام کیا گیا تھا وہ Tcl تھی۔ اگر کسی کو یہ بالکل بھی یاد ہے... یہ زبان پروگرامنگ کے لیے آسان زبان سے زیادہ صرف لکھنے کے لیے ہے۔

ہمیں کیا ملا؟ ہمیں ہارڈ ویئر کا ایک ٹکڑا ملا ہے جو ہمارے بنیادی ڈھانچے کی اعلی دستیابی کو یقینی بناتا ہے، ہمارے تمام ٹریفک کو روٹ کرتا ہے، صحت کے فوائد فراہم کرتا ہے اور صرف کام کرتا ہے۔ اس کے علاوہ، یہ ایک طویل عرصے سے کام کرتا ہے: پچھلے 10 سالوں میں اس کے بارے میں کوئی شکایت نہیں ہوئی ہے. 2018 کے آغاز تک، ہم پہلے ہی فی سیکنڈ تقریباً 80k تصاویر بھیج رہے تھے۔ یہ ہمارے دونوں ڈیٹا سینٹرز سے تقریباً 80 گیگا بٹس ٹریفک ہے۔
لیکن…
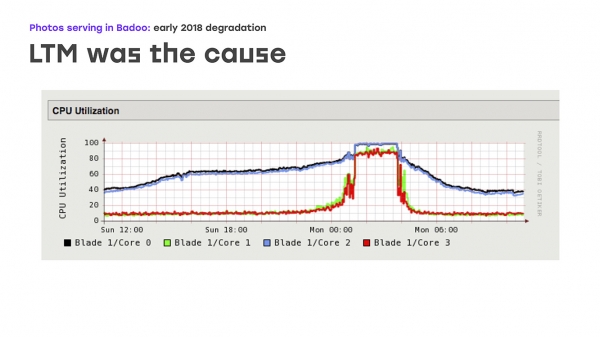
2018 کے آغاز میں، ہم نے چارٹس پر ایک بدصورت تصویر دیکھی: تصاویر بھیجنے میں لگنے والے وقت میں واضح طور پر اضافہ ہوا تھا۔ اور اس نے ہمیں سوٹ کرنا چھوڑ دیا۔ مسئلہ یہ ہے کہ یہ رویہ صرف ٹریفک کے عروج کے دوران ہی نظر آتا تھا - ہماری کمپنی کے لیے یہ اتوار سے پیر کی رات ہے۔ لیکن بقیہ وقت نظام نے معمول کے مطابق برتاؤ کیا، ناکامی کے کوئی آثار نظر نہیں آتے۔

بہر حال مسئلہ حل ہونا تھا۔ ہم نے ممکنہ رکاوٹوں کی نشاندہی کی اور انہیں ختم کرنا شروع کر دیا۔ سب سے پہلے، یقیناً، ہم نے بیرونی اپلنک کو بڑھایا، اندرونی اپلنک کا مکمل آڈٹ کیا، اور تمام ممکنہ رکاوٹیں تلاش کیں۔ لیکن یہ سب ایک واضح نتیجہ نہیں دیا، مسئلہ غائب نہیں ہوا.
ایک اور ممکنہ رکاوٹ خود فوٹو کیچز کی کارکردگی تھی۔ اور ہم نے فیصلہ کیا کہ شاید مسئلہ ان کے ساتھ ہے۔ ٹھیک ہے، ہم نے کارکردگی کو بڑھایا - بنیادی طور پر فوٹو کیشز پر نیٹ ورک پورٹس۔ لیکن پھر کوئی واضح بہتری نظر نہیں آئی۔ آخر میں، ہم نے خود LTM کی کارکردگی پر پوری توجہ دی، اور یہاں ہم نے گراف پر ایک افسوسناک تصویر دیکھی: تمام CPUs پر بوجھ آسانی سے چلنا شروع ہو جاتا ہے، لیکن پھر اچانک سطح مرتفع پر آ جاتا ہے۔ ایک ہی وقت میں، LTM صحت کی جانچ اور اپ لنکس کا مناسب جواب دینا بند کر دیتا ہے اور تصادفی طور پر انہیں بند کرنا شروع کر دیتا ہے، جس سے کارکردگی میں شدید کمی واقع ہوتی ہے۔
یعنی ہم نے مسئلے کے ماخذ کی نشاندہی کی ہے، رکاوٹ کی نشاندہی کی ہے۔ یہ فیصلہ کرنا باقی ہے کہ ہم کیا کریں گے۔
پہلی، سب سے واضح چیز جو ہم کر سکتے ہیں وہ یہ ہے کہ کسی نہ کسی طرح خود LTM کو جدید بنایا جائے۔ لیکن یہاں کچھ باریکیاں ہیں، کیونکہ یہ ہارڈویئر کافی منفرد ہے، آپ قریبی سپر مارکیٹ میں جا کر اسے نہیں خریدیں گے۔ یہ ایک الگ معاہدہ ہے، ایک علیحدہ لائسنس کا معاہدہ ہے، اور اس میں کافی وقت لگے گا۔ دوسرا آپشن یہ ہے کہ اپنے لیے سوچنا شروع کریں، اپنے اجزاء کا استعمال کرتے ہوئے اپنے حل کے ساتھ آئیں، ترجیحاً اوپن ایکسیس پروگرام کا استعمال کرتے ہوئے۔ بس یہ فیصلہ کرنا باقی ہے کہ ہم اس کے لیے بالکل کیا انتخاب کریں گے اور اس مسئلے کو حل کرنے میں کتنا وقت صرف کریں گے، کیونکہ صارفین کو کافی تصاویر نہیں مل رہی تھیں۔ لہذا، ہمیں یہ سب کچھ بہت جلد کرنے کی ضرورت ہے، کوئی کل کہہ سکتا ہے۔
چونکہ کام ایسا لگتا تھا کہ "جلد سے جلد کچھ کریں اور ہمارے پاس موجود ہارڈ ویئر کا استعمال کریں،" پہلی چیز جس کے بارے میں ہم نے سوچا وہ یہ تھا کہ سامنے سے کچھ زیادہ طاقتور مشینیں ہٹائیں، وہاں Nginx ڈالیں، جس کے ساتھ ہم جانتے ہیں کہ کیسے کام کریں اور وہی منطق نافذ کرنے کی کوشش کریں جو ہارڈ ویئر کرتا تھا۔ یعنی درحقیقت، ہم نے اپنا ہارڈویئر چھوڑ دیا، مزید 4 سرورز انسٹال کیے جنہیں ہمیں کنفیگر کرنا تھا، ان کے لیے بیرونی ڈومینز بنائے، جیسا کہ 10 سال پہلے تھا... اگر یہ مشینیں گر گئیں تو ہم نے دستیابی میں تھوڑا سا کھو دیا، لیکن پھر بھی کم، انہوں نے ہمارے صارفین کا مسئلہ مقامی طور پر حل کیا۔
اس کے مطابق، منطق ایک ہی رہتی ہے: ہم Nginx انسٹال کرتے ہیں، یہ SSL-offload کر سکتا ہے، ہم کسی نہ کسی طرح روٹنگ لاجک کو پروگرام کر سکتے ہیں، کنفیگرز میں ہیلتھ چیک کر سکتے ہیں اور صرف اس منطق کو نقل کر سکتے ہیں جو ہمارے پاس پہلے تھی۔
آئیے configs لکھنے بیٹھتے ہیں۔ سب سے پہلے ایسا لگتا تھا کہ سب کچھ بہت آسان ہے، لیکن بدقسمتی سے، ہر کام کے لئے دستورالعمل تلاش کرنا بہت مشکل ہے۔ لہذا، ہم صرف گوگلنگ کی سفارش نہیں کرتے ہیں کہ "تصاویر کے لئے Nginx کو کیسے ترتیب دیا جائے": بہتر ہے کہ سرکاری دستاویزات کا حوالہ دیا جائے، جو یہ ظاہر کرے گا کہ کن ترتیبات کو چھونا چاہئے۔ لیکن یہ بہتر ہے کہ مخصوص پیرامیٹر خود منتخب کریں۔ ٹھیک ہے، پھر سب کچھ آسان ہے: ہم اپنے پاس موجود سرورز کی وضاحت کرتے ہیں، ہم سرٹیفکیٹ کی وضاحت کرتے ہیں... لیکن سب سے دلچسپ بات، حقیقت میں، روٹنگ منطق ہی ہے۔
پہلے تو ہمیں ایسا لگتا تھا کہ ہم صرف اپنا مقام بیان کر رہے ہیں، اس میں اپنے فوٹو کیش کی تعداد کو ملا رہے ہیں، اپنے ہاتھوں یا جنریٹر کا استعمال کر رہے ہیں کہ ہمیں کتنے اپ اسٹریم کی ضرورت ہے، ہر اپ اسٹریم میں ہم اس سرور کی نشاندہی کر رہے ہیں جس پر ٹریفک ہونا چاہیے۔ جاؤ، اور ایک بیک اپ سرور - اگر مین سرور دستیاب نہیں ہے:

لیکن، شاید، اگر سب کچھ اتنا آسان ہوتا، تو ہم صرف گھر جاتے اور کچھ نہیں کہتے۔ بدقسمتی سے، پہلے سے طے شدہ Nginx ترتیبات کے ساتھ، جو عام طور پر کئی سالوں کی ترقی کے دوران بنائی گئی تھیں اور اس معاملے کے لیے مکمل طور پر موزوں نہیں ہیں... تشکیل اس طرح نظر آتی ہے: اگر کچھ upstream سرور میں درخواست کی غلطی یا ٹائم آؤٹ ہو، تو Nginx ہمیشہ ٹریفک کو اگلے ایک پر سوئچ کرتا ہے۔ مزید برآں، پہلی ناکامی کے بعد، 10 سیکنڈ کے اندر سرور بھی غلطی سے اور ٹائم آؤٹ دونوں طرح سے آف ہو جائے گا - اسے کسی بھی طرح سے ترتیب نہیں دیا جا سکتا۔ یعنی، اگر ہم اپ اسٹریم ڈائرکٹیو میں ٹائم آؤٹ آپشن کو ہٹاتے یا ری سیٹ کرتے ہیں، تو، اگرچہ Nginx اس درخواست پر کارروائی نہیں کرے گا اور کچھ بہت اچھی خرابی کے ساتھ جواب دے گا، سرور بند ہو جائے گا۔

اس سے بچنے کے لیے ہم نے دو کام کیے:
a) انہوں نے Nginx کو دستی طور پر ایسا کرنے سے منع کیا - اور بدقسمتی سے، ایسا کرنے کا واحد طریقہ صرف یہ ہے کہ زیادہ سے زیادہ ناکامی کی ترتیبات کو ترتیب دیا جائے۔
b) ہمیں یاد آیا کہ دوسرے پروجیکٹس میں ہم ایک ماڈیول استعمال کرتے ہیں جو ہمیں بیک گراؤنڈ ہیلتھ چیکس کرنے کی اجازت دیتا ہے - اس کے مطابق، ہم نے کافی بار بار صحت کی جانچ کی تاکہ کسی حادثے کی صورت میں ڈاؤن ٹائم کم سے کم ہو۔
بدقسمتی سے، یہ سب کچھ بھی نہیں ہے، کیونکہ لفظی طور پر اس اسکیم کے آپریشن کے پہلے دو ہفتوں نے ظاہر کیا کہ TCP ہیلتھ چیک بھی ایک ناقابل اعتبار چیز ہے: اپ اسٹریم سرور پر یہ Nginx، یا Nginx D-state میں نہیں ہوسکتا ہے، اور اس صورت میں دانا کنکشن کو قبول کرے گا، ہیلتھ چیک پاس ہو جائے گا، لیکن کام نہیں کرے گا۔ لہذا، ہم نے اسے فوری طور پر ہیلتھ چیک HTTP سے بدل دیا، ایک مخصوص بنایا، جو کہ اگر 200 لوٹاتا ہے، تو اس اسکرپٹ میں سب کچھ کام کرتا ہے۔ آپ اضافی منطق کر سکتے ہیں - مثال کے طور پر، کیشنگ سرورز کے معاملے میں، چیک کریں کہ فائل سسٹم درست طریقے سے نصب ہے:

اور یہ ہمارے مطابق ہوگا، سوائے اس کے کہ اس وقت سرکٹ مکمل طور پر دہرائے جو ہارڈ ویئر نے کیا تھا۔ لیکن ہم بہتر کرنا چاہتے تھے۔ پہلے، ہمارے پاس ایک بیک اپ سرور تھا، اور یہ شاید بہت اچھا نہیں ہے، کیونکہ اگر آپ کے پاس سو سرورز ہیں، تو جب ایک ساتھ کئی ناکام ہوجاتے ہیں، تو ایک بیک اپ سرور بوجھ سے نمٹنے کا امکان نہیں رکھتا ہے۔ لہذا، ہم نے تمام سرورز پر ریزرویشن تقسیم کرنے کا فیصلہ کیا: ہم نے صرف ایک اور الگ اپ اسٹریم بنایا، وہاں تمام سرورز کو کچھ پیرامیٹرز کے ساتھ اس بوجھ کے مطابق لکھا جو وہ پیش کر سکتے ہیں، وہی ہیلتھ چیکس شامل کیے جو پہلے ہمارے پاس تھے:

چونکہ ایک اپ اسٹریم کے اندر دوسرے اپ اسٹریم پر جانا ناممکن ہے، اس لیے یہ یقینی بنانا ضروری تھا کہ اگر مین اپ اسٹریم، جس میں ہم نے صرف درست، ضروری فوٹو کیش ریکارڈ کیا ہے، دستیاب نہیں تھا، تو ہم فال بیک کے لیے error_page سے گزرے، جہاں ہم بیک اپ اپ اسٹریم پر گئے تھے:

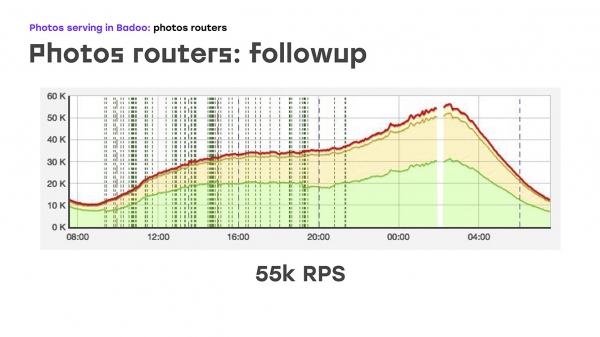
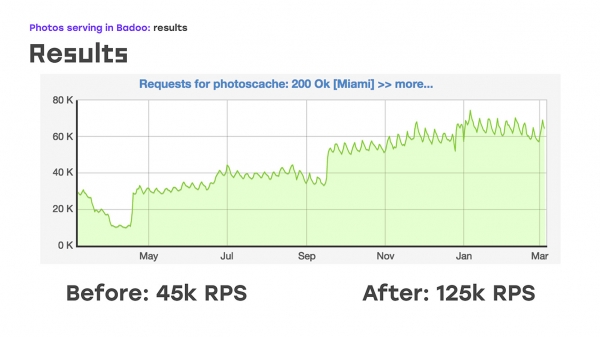
اور لفظی طور پر چار سرورز کو جوڑ کر، ہمیں یہ حاصل ہوا: ہم نے بوجھ کا کچھ حصہ بدل دیا - ہم نے اسے LTM سے ہٹا کر ان سرورز پر کیا، معیاری ہارڈ ویئر اور سافٹ ویئر کا استعمال کرتے ہوئے وہاں وہی منطق نافذ کی، اور فوری طور پر بونس حاصل کیا جو یہ سرورز کر سکتے ہیں۔ پیمانہ بنایا جائے، کیونکہ وہ صرف ضرورت کے مطابق فراہم کی جا سکتی ہیں۔ ٹھیک ہے، صرف منفی بات یہ ہے کہ ہم نے بیرونی صارفین کے لیے اعلیٰ دستیابی کو کھو دیا ہے۔ لیکن اس وقت ہمیں یہ قربانی دینا پڑی، کیونکہ اس مسئلے کو فوری طور پر حل کرنا ضروری تھا۔ لہذا، ہم نے بوجھ کا کچھ حصہ ہٹا دیا، اس وقت یہ تقریباً 40% تھا، LTM کو اچھا لگا، اور مسئلہ شروع ہونے کے دو ہفتے بعد، ہم نے فی سیکنڈ 45k نہیں بلکہ 55k درخواستیں بھیجنا شروع کر دیں۔ درحقیقت، ہم نے 20% اضافہ کیا - یہ واضح طور پر وہ ٹریفک ہے جو ہم نے صارف کو نہیں دیا۔ اور اس کے بعد انہوں نے اس بارے میں سوچنا شروع کیا کہ بقیہ مسئلہ کو کیسے حل کیا جائے - اعلیٰ بیرونی رسائی کو یقینی بنانے کے لیے۔
ہمارے پاس کچھ وقفہ تھا، جس کے دوران ہم نے اس کے لیے کون سا حل استعمال کیا اس پر تبادلہ خیال کیا۔ DNS کا استعمال کرتے ہوئے وشوسنییتا کو یقینی بنانے کے لیے تجاویز پیش کی گئیں، کچھ گھریلو تحریری اسکرپٹس، ڈائنامک روٹنگ پروٹوکولز کا استعمال کرتے ہوئے... بہت سے آپشنز موجود تھے، لیکن یہ پہلے ہی واضح ہو گیا ہے کہ تصاویر کی واقعی قابل اعتماد ترسیل کے لیے، آپ کو ایک اور پرت متعارف کرانے کی ضرورت ہے جو اس کی نگرانی کرے گی۔ . ہم نے ان مشینوں کو فوٹو ڈائریکٹر کہا۔ جس سافٹ ویئر پر ہم نے انحصار کیا وہ Keepalived تھا:

شروع کرنے کے لیے، Keepalived کیا پر مشتمل ہے؟ پہلا VRRP پروٹوکول ہے، جو نیٹ ورکرز کے لیے وسیع پیمانے پر جانا جاتا ہے، جو نیٹ ورک کے آلات پر واقع ہے جو خارجی آئی پی ایڈریس کے لیے غلطی کو برداشت کرتا ہے جس سے کلائنٹ جڑتے ہیں۔ دوسرا حصہ IPVS، IP ورچوئل سرور، فوٹو راؤٹرز کے درمیان توازن اور اس سطح پر غلطی برداشت کو یقینی بنانے کے لیے ہے۔ اور تیسرا - صحت کی جانچ۔
آئیے پہلے حصے کے ساتھ شروع کریں: VRRP - یہ کیسا لگتا ہے؟ ایک مخصوص ورچوئل آئی پی ہے، جس میں dns badoocdn.com میں ایک اندراج ہے، جہاں کلائنٹ جڑتے ہیں۔ کسی وقت، ہمارے پاس ایک سرور پر ایک IP ایڈریس ہوتا ہے۔ VRRP پروٹوکول کا استعمال کرتے ہوئے سرورز کے درمیان کیپ لیویڈ پیکٹ چلتے ہیں، اور اگر ماسٹر ریڈار سے غائب ہو جاتا ہے - سرور دوبارہ شروع ہو گیا ہے یا کچھ اور، تو بیک اپ سرور خود بخود اس IP ایڈریس کو اٹھا لیتا ہے - کسی دستی کارروائی کی ضرورت نہیں ہے۔ ماسٹر اور بیک اپ کے درمیان فرق بنیادی طور پر ترجیح ہے: یہ جتنا زیادہ ہوگا، مشین کے ماسٹر بننے کا امکان اتنا ہی زیادہ ہوگا۔ ایک بہت بڑا فائدہ یہ ہے کہ آپ کو سرور پر ہی آئی پی ایڈریسز کو کنفیگر کرنے کی ضرورت نہیں ہے، ان کو کنفیگریشن میں بیان کرنا کافی ہے، اور اگر آئی پی ایڈریسز کو کچھ حسب ضرورت روٹنگ رولز کی ضرورت ہو، تو یہ براہ راست کنفیگریشن میں بیان کیا جاتا ہے، وہی نحو جیسا کہ VRRP پیکیج میں بیان کیا گیا ہے۔ آپ کو کسی غیر مانوس چیزوں کا سامنا نہیں کرنا پڑے گا۔
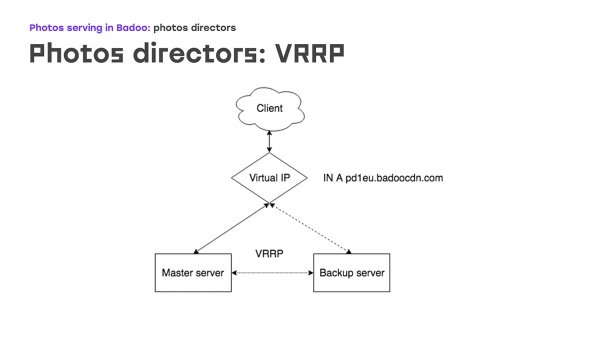
عملی طور پر یہ کیسا لگتا ہے؟ اگر سرورز میں سے ایک ناکام ہو جائے تو کیا ہوتا ہے؟ جیسے ہی ماسٹر غائب ہو جاتا ہے، ہمارا بیک اپ اشتہارات وصول کرنا بند کر دیتا ہے اور خود بخود ماسٹر بن جاتا ہے۔ کچھ وقت کے بعد، ہم نے ماسٹر کی مرمت کی، دوبارہ شروع کیا، Keepalived کو اٹھایا - اشتہارات بیک اپ سے زیادہ ترجیح کے ساتھ آتے ہیں، اور بیک اپ خود بخود واپس آجاتا ہے، آئی پی ایڈریس کو ہٹا دیتا ہے، کوئی دستی کارروائی کرنے کی ضرورت نہیں ہے۔

اس طرح، ہم نے بیرونی IP ایڈریس کی غلطی برداشت کو یقینی بنایا ہے۔ اگلا حصہ کسی نہ کسی طرح بیرونی IP ایڈریس سے فوٹو راؤٹرز تک ٹریفک کو متوازن کرنا ہے جو اسے پہلے ہی ختم کر رہے ہیں۔ توازن پروٹوکول کے ساتھ سب کچھ بالکل واضح ہے۔ یہ یا تو ایک سادہ راؤنڈ رابن ہے، یا قدرے پیچیدہ چیزیں، wrr، فہرست کنکشن وغیرہ۔ یہ بنیادی طور پر دستاویزات میں بیان کیا گیا ہے، کوئی خاص بات نہیں ہے۔ لیکن ترسیل کا طریقہ... یہاں ہم اس بات پر گہری نظر ڈالیں گے کہ ہم نے ان میں سے ایک کو کیوں منتخب کیا۔ یہ NAT، ڈائریکٹ روٹنگ اور TUN ہیں۔ حقیقت یہ ہے کہ ہم نے فوری طور پر سائٹس سے 100 گیگا بٹس ٹریفک فراہم کرنے کا منصوبہ بنایا۔ اگر آپ کا اندازہ ہے تو، آپ کو 10 گیگا بٹ کارڈز کی ضرورت ہے، ٹھیک ہے؟ ایک سرور میں 10 گیگا بٹ کارڈ پہلے سے ہی کم از کم ہمارے "معیاری سامان" کے تصور کے دائرہ کار سے باہر ہیں۔ اور پھر ہمیں یاد آیا کہ ہم صرف کچھ ٹریفک نہیں دیتے، ہم تصاویر بھی دیتے ہیں۔
کیا خاص بات ہے؟ - آنے والی اور جانے والی ٹریفک کے درمیان بہت زیادہ فرق۔ آنے والی ٹریفک بہت کم ہے، باہر جانے والی ٹریفک بہت بڑی ہے:
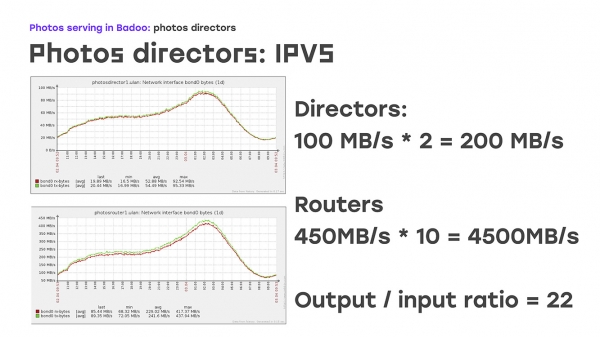
اگر آپ ان گرافس کو دیکھیں تو آپ دیکھ سکتے ہیں کہ اس وقت ڈائریکٹر تقریباً 200 ایم بی فی سیکنڈ وصول کر رہا ہے، یہ بہت عام دن ہے۔ ہم 4,500 MB فی سیکنڈ واپس دیتے ہیں، ہمارا تناسب تقریباً 1/22 ہے۔ یہ پہلے ہی واضح ہے کہ 22 ورکر سرورز کو مکمل طور پر باہر جانے والی ٹریفک فراہم کرنے کے لیے، ہمیں صرف ایک کی ضرورت ہے جو اس کنکشن کو قبول کرے۔ یہ وہ جگہ ہے جہاں براہ راست روٹنگ الگورتھم ہماری مدد کے لیے آتا ہے۔
یہ کیسا لگتا ہے؟ ہمارے فوٹو ڈائریکٹر، اس کی میز کے مطابق، تصویر روٹرز کو کنکشن منتقل کرتا ہے. لیکن فوٹو راؤٹرز واپسی ٹریفک کو براہ راست انٹرنیٹ پر بھیجتے ہیں، کلائنٹ کو بھیجتے ہیں، یہ فوٹو ڈائریکٹر کے ذریعے واپس نہیں جاتا، اس طرح، مشینوں کی کم از کم تعداد کے ساتھ، ہم تمام ٹریفک کو مکمل طور پر فالٹ ٹالرینس اور پمپنگ کو یقینی بناتے ہیں۔ کنفیگرز میں یہ اس طرح نظر آتا ہے: ہم الگورتھم کی وضاحت کرتے ہیں، ہمارے معاملے میں یہ ایک سادہ آر آر ہے، براہ راست روٹنگ کا طریقہ فراہم کریں اور پھر تمام حقیقی سرورز کی فہرست بنانا شروع کریں، ان میں سے ہمارے پاس کتنے ہیں۔ جو اس ٹریفک کا تعین کرے گا۔ اگر ہمارے پاس وہاں ایک یا دو اور سرور ہیں، یا کئی سرورز ہیں، تو ایسی ضرورت پیش آتی ہے - ہم صرف اس سیکشن کو تشکیل میں شامل کرتے ہیں اور زیادہ فکر نہ کریں۔ حقیقی سرورز کی طرف سے، فوٹو راؤٹر کی طرف سے، یہ طریقہ انتہائی کم سے کم ترتیب کی ضرورت ہے، یہ دستاویزات میں بالکل بیان کیا گیا ہے، اور وہاں کوئی نقصان نہیں ہے۔
خاص طور پر اچھی بات یہ ہے کہ اس طرح کے حل کا مطلب مقامی نیٹ ورک کی ریڈیکل ری ڈیزائن نہیں ہے؛ یہ ہمارے لیے اہم تھا؛ ہمیں اسے کم سے کم لاگت کے ساتھ حل کرنا تھا۔ اگر آپ دیکھیں ، پھر ہم دیکھیں گے کہ یہ کیسا لگتا ہے۔ یہاں ہمارے پاس ایک مخصوص ورچوئل سرور ہے، پورٹ 443 پر، کنکشن کو سنتا ہے، قبول کرتا ہے، تمام کام کرنے والے سرورز درج ہیں، اور آپ دیکھ سکتے ہیں کہ کنکشن، دینا یا لینا، ایک جیسا ہے۔ اگر ہم اسی ورچوئل سرور کے اعدادوشمار پر نظر ڈالیں تو ہمارے پاس آنے والے پیکٹ ہیں، آنے والے کنکشن ہیں، لیکن بالکل باہر جانے والے نہیں ہیں۔ آؤٹ گوئنگ کنکشن براہ راست کلائنٹ کے پاس جاتے ہیں۔ ٹھیک ہے، ہم اسے غیر متوازن کرنے کے قابل تھے۔ اب، اگر ہمارا کوئی فوٹو راؤٹر ناکام ہو جائے تو کیا ہوتا ہے؟ سب کے بعد، لوہا لوہا ہے. یہ کرنل گھبراہٹ میں جا سکتا ہے، یہ ٹوٹ سکتا ہے، بجلی کی فراہمی جل سکتی ہے۔ کچھ بھی۔ اس لیے صحت کی جانچ کی ضرورت ہے۔ وہ اتنے ہی آسان ہو سکتے ہیں جتنا یہ چیک کرنا کہ بندرگاہ کیسے کھلی ہے، یا کچھ زیادہ پیچیدہ، کچھ گھریلو تحریری اسکرپٹ تک جو کاروباری منطق کو بھی جانچیں گی۔
ہم درمیان میں کہیں رک گئے: ہمارے پاس ایک مخصوص مقام پر https کی درخواست ہے، اسکرپٹ کو کہا جاتا ہے، اگر یہ 200 ویں جواب کے ساتھ جواب دیتا ہے، تو ہمیں یقین ہے کہ اس سرور کے ساتھ سب کچھ ٹھیک ہے، کہ یہ زندہ ہے اور اسے کافی حد تک آن کیا جا سکتا ہے۔ آسانی سے
یہ، دوبارہ، عملی طور پر کیسے نظر آتا ہے؟ آئیے دیکھ بھال کے لیے سرور کو بند کر دیں - مثال کے طور پر BIOS کو چمکانا۔ نوشتہ جات میں، ہمارے پاس فوری طور پر ایک ٹائم آؤٹ ہوتا ہے، ہمیں پہلی لائن نظر آتی ہے، پھر تین کوششوں کے بعد اسے "ناکام" کے طور پر نشان زد کیا جاتا ہے، اور اسے آسانی سے فہرست سے ہٹا دیا جاتا ہے۔

دوسرا رویہ اختیار بھی ممکن ہے، جب VS کو صرف صفر پر سیٹ کیا جاتا ہے، لیکن اگر تصویر واپس کردی جاتی ہے، تو یہ اچھی طرح سے کام نہیں کرتا ہے۔ سرور آتا ہے، Nginx وہاں سے شروع ہوتا ہے، ہیلتھ چیک فوری طور پر سمجھتا ہے کہ کنکشن کام کر رہا ہے، کہ سب کچھ ٹھیک ہے، اور سرور ہماری فہرست میں ظاہر ہوتا ہے، اور فوری طور پر اس پر بوجھ لگنا شروع ہو جاتا ہے۔ ڈیوٹی ایڈمنسٹریٹر سے کسی دستی کارروائی کی ضرورت نہیں ہے۔ سرور رات کو ریبوٹ ہوا - مانیٹرنگ ڈیپارٹمنٹ ہمیں رات کو اس بارے میں کال نہیں کرتا ہے۔ وہ آپ کو بتاتے ہیں کہ یہ ہوا، سب کچھ ٹھیک ہے۔
لہذا، کافی آسان طریقے سے، سرورز کی ایک قلیل تعداد کی مدد سے، ہم نے بیرونی فالٹ ٹولرنس کا مسئلہ حل کیا۔
بس اتنا کہنا باقی ہے کہ یقیناً اس سب پر نظر رکھنے کی ضرورت ہے۔ علیحدہ طور پر، یہ واضح رہے کہ Keepalivede، جیسا کہ ایک طویل عرصہ پہلے لکھا گیا سافٹ ویئر ہے، اس کی نگرانی کرنے کے بہت سے طریقے ہیں، دونوں DBus، SMTP، SNMP، اور معیاری Zabbix کے ذریعے چیک کا استعمال کرتے ہوئے۔ اس کے علاوہ، وہ خود جانتا ہے کہ تقریباً ہر چھینک کے لیے خط کیسے لکھنا ہے، اور سچ پوچھیں تو، ہم نے اسے بند کرنے کا بھی سوچا، کیونکہ وہ ہر آئی پی کنکشن کے لیے کسی بھی ٹریفک سوئچنگ، سوئچ آن کرنے کے لیے بہت سارے خط لکھتا ہے، اور اسی طرح یقینا، اگر بہت سارے سرورز ہیں، تو آپ ان خطوط سے اپنے آپ کو مغلوب کر سکتے ہیں۔ ہم معیاری طریقوں کا استعمال کرتے ہوئے فوٹو راؤٹرز پر nginx کی نگرانی کرتے ہیں، اور ہارڈ ویئر کی نگرانی ختم نہیں ہوئی ہے۔ بلاشبہ ہم دو اور چیزوں کا مشورہ دیں گے: اول، بیرونی صحت کی جانچ اور دستیابی، کیونکہ اگر سب کچھ کام کرتا ہے تو بھی درحقیقت، شاید صارفین کو بیرونی فراہم کنندگان کے مسائل یا کسی اور پیچیدہ چیز کی وجہ سے تصاویر موصول نہیں ہوتیں۔ یہ ہمیشہ کسی دوسرے نیٹ ورک پر رکھنے کے قابل ہے، ایمیزون میں یا کسی اور جگہ، ایک علیحدہ مشین جو آپ کے سرور کو باہر سے پنگ کر سکتی ہے، اور یہ ان لوگوں کے لیے جو مشکل مشین لرننگ کرنا جانتے ہیں، یا سادہ نگرانی کرنا جانتے ہیں، یا تو بے ضابطگی کا پتہ لگانے کا استعمال کرنے کے قابل ہے۔ کم از کم یہ معلوم کرنے کے لیے کہ آیا درخواستوں میں تیزی سے کمی آئی ہے، یا، اس کے برعکس، اضافہ ہوا ہے۔ یہ مفید بھی ہو سکتا ہے۔
آئیے خلاصہ کرتے ہیں: ہم نے، درحقیقت، لوہے سے ملبوس محلول کی جگہ لے لی، جو کہ کسی وقت ہمارے موافق ہونا بند ہو گیا، کافی آسان نظام کے ساتھ جو سب کچھ ایک جیسا کرتا ہے، یعنی یہ HTTPS ٹریفک کو ختم کرتا ہے اور مزید سمارٹ روٹنگ فراہم کرتا ہے۔ ضروری صحت کی جانچ. ہم نے اس سسٹم کے استحکام میں اضافہ کیا ہے، یعنی ہمارے پاس اب بھی ہر پرت کے لیے اعلیٰ دستیابی ہے، اس کے علاوہ ہمارے پاس یہ بونس ہے کہ ہر ایک پرت پر اس کی پیمائش کرنا کافی آسان ہے، کیونکہ یہ معیاری سافٹ ویئر کے ساتھ معیاری ہارڈ ویئر ہے، یعنی ، ہم نے ممکنہ مسائل کی تشخیص کو آسان بنا دیا ہے۔
ہم نے آخر کیا کیا؟ 2018 کی جنوری کی تعطیلات کے دوران ہمیں ایک مسئلہ درپیش تھا۔ پہلے چھ مہینوں میں جب ہم نے اس اسکیم کو عمل میں لایا، ہم نے LTM سے تمام ٹریفک کو ہٹانے کے لیے اسے تمام ٹریفک تک بڑھا دیا، ہم نے صرف ایک ڈیٹا سینٹر میں ٹریفک میں 40 گیگا بٹس سے 60 گیگا بٹ تک اضافہ کیا، اور اسی وقت پورا 2018 سال فی سیکنڈ تقریباً تین گنا زیادہ تصاویر بھیجنے میں کامیاب رہا۔
ماخذ: www.habr.com
