

نوٹ. ترجمہیورپی کمپنی Adevinta کے پرنسپل سافٹ ویئر انجینئر Galo Navarro کی طرف سے لکھا گیا یہ مضمون، بنیادی ڈھانچے کے کاموں کے شعبے میں ایک دلچسپ اور سبق آموز "تحقیقات" ہے۔ اس کے اصل عنوان میں ترجمے میں قدرے ترمیم کی گئی ہے اس وجہ سے کہ مصنف شروع میں وضاحت کرتا ہے۔
مصنف کی طرف سے نوٹ: یہ اس اشاعت کی طرح لگتا ہے۔ اس مضمون کو توقع سے کہیں زیادہ توجہ ملی ہے۔ مجھے اب بھی گمراہ کن عنوان اور کچھ قارئین کے ناراض ہونے کے بارے میں ناراض تبصرے ملتے ہیں۔ میں اس کی وجوہات کو سمجھتا ہوں، اس لیے پوری کہانی کو بگاڑنے کے خطرے میں، میں یہ بتانا چاہتا ہوں کہ یہ مضمون کیا ہے۔ جب ٹیمیں Kubernetes کی طرف ہجرت کرتی ہیں، میں ایک دلچسپ چیز کا مشاہدہ کرتا ہوں: جب بھی کوئی مسئلہ پیدا ہوتا ہے (مثال کے طور پر، ہجرت کے بعد تاخیر میں اضافہ)، سب سے پہلے وہ Kubernetes کو مورد الزام ٹھہراتے ہیں، لیکن یہ پتہ چلتا ہے کہ اصل میں آرکیسٹریٹر قصوروار نہیں ہے۔ یہ مضمون ایسے ہی ایک کیس کے بارے میں ہے۔ اس کا عنوان ہمارے ایک ڈویلپر کی طرف سے ایک فجائیہ کی بازگشت ہے (آپ بعد میں دیکھیں گے کہ Kubernetes کا اس سے کوئی تعلق نہیں تھا)۔ آپ کو کبرنیٹس کے بارے میں کوئی حیران کن انکشافات نہیں ملیں گے، لیکن آپ پیچیدہ نظاموں کے بارے میں چند اچھے اسباق پر اعتماد کر سکتے ہیں۔
چند ہفتے پہلے، میری ٹیم ایک واحد مائیکرو سروس کو ایک بنیادی پلیٹ فارم پر منتقل کر رہی تھی جس میں CI/CD، Kubernetes پر مبنی پیداواری ماحول، میٹرکس اور دیگر مفید خصوصیات شامل تھیں۔ یہ ایک پائلٹ پروجیکٹ تھا: ہم نے اس پر تعمیر کرنے اور آنے والے مہینوں میں تقریباً 150 مزید سروسز کو منتقل کرنے کا منصوبہ بنایا۔ یہ تمام خدمات اسپین کے سب سے بڑے آن لائن بازاروں (Infojobs، Fotocasa، اور دیگر) کو طاقت دیتی ہیں۔
جب ہم نے ایپلیکیشن کوبرنیٹس پر تعینات کیا اور کچھ ٹریفک کو اس کی طرف ری ڈائریکٹ کیا تو ہمیں ایک خطرناک حیرت کا سامنا کرنا پڑا۔ تاخیر (دیر) Kubernetes میں درخواستوں کی تعداد EC2 کے مقابلے میں 10 گنا زیادہ تھی۔ بالآخر، یہ ضروری تھا کہ یا تو اس مسئلے کا حل تلاش کیا جائے یا مائیکرو سروس کی منتقلی (اور ممکنہ طور پر، پورے پروجیکٹ) کو ترک کر دیا جائے۔
EC2 کے مقابلے Kubernetes میں تاخیر اتنی زیادہ کیوں ہے؟
رکاوٹ تلاش کرنے کے لیے، ہم نے درخواست کے پورے راستے کے ساتھ میٹرکس اکٹھا کیا۔ ہمارا فن تعمیر آسان ہے: ایک API گیٹ وے (Zuul) پراکسیز EC2 یا Kubernetes میں مائیکرو سرویس مثالوں کی درخواست کرتی ہیں۔ Kubernetes میں، ہم ایک NGINX Ingress کنٹرولر استعمال کرتے ہیں، اور بیک اینڈ اس قسم کی باقاعدہ اشیاء ہیں اسپرنگ پلیٹ فارم پر JVM ایپلیکیشن کے ساتھ۔
EC2
+---------------+
| +---------+ |
| | | |
+-------> BACKEND | |
| | | | |
| | +---------+ |
| +---------------+
+------+ |
Public | | |
-------> ZUUL +--+
traffic | | | Kubernetes
+------+ | +-----------------------------+
| | +-------+ +---------+ |
| | | | xx | | |
+-------> NGINX +------> BACKEND | |
| | | xx | | |
| +-------+ +---------+ |
+-----------------------------+ایسا لگتا ہے کہ یہ مسئلہ بیک اینڈ پروسیسنگ کے ابتدائی مرحلے میں تاخیر سے متعلق ہے (میں نے گراف پر مسئلہ کے علاقے کو "xx" کے بطور نشان زد کیا)۔ EC2 میں، درخواست کے جواب میں تقریباً 20 ایم ایس لگے۔ Kubernetes میں، تاخیر 100-200 ms تک بڑھ گئی۔
ہم نے رن ٹائم تبدیلی سے متعلق ممکنہ مشتبہ افراد کو فوری طور پر مسترد کر دیا۔ JVM ورژن وہی رہا۔ کنٹینرائزیشن کے مسائل بھی غیر متعلقہ تھے: ایپلیکیشن EC2 میں کنٹینرز میں پہلے ہی کامیابی سے چل رہی تھی۔ لوڈ؟ لیکن ہم نے فی سیکنڈ ایک درخواست کے ساتھ بھی زیادہ تاخیر کا مشاہدہ کیا۔ کچرا اٹھانے کے وقفے بھی نہ ہونے کے برابر تھے۔
ہمارے کبرنیٹس کے منتظمین میں سے ایک نے پوچھا کہ کیا ایپلیکیشن کا کوئی بیرونی انحصار ہے، جیسا کہ ڈی این ایس کے سوالات نے ماضی میں اسی طرح کے مسائل پیدا کیے تھے۔
مفروضہ 1: DNS نام کی قرارداد
ہر درخواست کے لیے، ہماری درخواست AWS Elasticsearch مثال کے طور پر ایک ڈومین میں ایک سے تین کال کرتی ہے۔ elastic.spain.adevinta.comہمارے پاس موجود کنٹینرز کے اندر ، لہذا ہم چیک کر سکتے ہیں کہ آیا ڈومین کی تلاش میں واقعی زیادہ وقت لگتا ہے۔
کنٹینر سے DNS سوالات:
[root@be-851c76f696-alf8z /]# while true; do dig "elastic.spain.adevinta.com" | grep time; sleep 2; done
;; Query time: 22 msec
;; Query time: 22 msec
;; Query time: 29 msec
;; Query time: 21 msec
;; Query time: 28 msec
;; Query time: 43 msec
;; Query time: 39 msecدرخواست چلانے والے EC2 مثالوں میں سے ایک سے ملتی جلتی درخواستیں:
bash-4.4# while true; do dig "elastic.spain.adevinta.com" | grep time; sleep 2; done
;; Query time: 77 msec
;; Query time: 0 msec
;; Query time: 0 msec
;; Query time: 0 msec
;; Query time: 0 msecیہ دیکھتے ہوئے کہ تلاش میں لگ بھگ 30ms لگتے ہیں، یہ واضح ہو گیا کہ Elasticsearch تک رسائی حاصل کرنے پر DNS ریزولوشن درحقیقت بڑھتی ہوئی تاخیر میں معاون ہے۔
تاہم، یہ دو وجوہات کی بناء پر عجیب تھا:
- ہمارے پاس پہلے سے ہی ایک ٹن Kubernetes ایپلی کیشنز موجود ہیں جو AWS وسائل کے ساتھ اہم تاخیر کا تجربہ کیے بغیر تعامل کرتی ہیں۔ وجہ کچھ بھی ہو، یہ اس خاص معاملے سے مخصوص ہے۔
- ہم جانتے ہیں کہ JVM ان میموری DNS کیشنگ کو لاگو کرتا ہے۔ ہماری تصاویر میں، TTL ویلیو کو ہارڈ کوڈ کیا گیا ہے۔
$JAVA_HOME/jre/lib/security/java.securityاور 10 سیکنڈ پر سیٹ کریں:networkaddress.cache.ttl = 10دوسرے لفظوں میں، JVM کو تمام DNS سوالات کو 10 سیکنڈ کے لیے کیش کرنا چاہیے۔
پہلے مفروضے کی تصدیق کرنے کے لیے، ہم نے عارضی طور پر DNS تلاش کو غیر فعال کرنے کا فیصلہ کیا اور دیکھیں کہ آیا مسئلہ حل ہو جائے گا۔ سب سے پہلے، ہم نے ایپلیکیشن کو دوبارہ ترتیب دینے پر غور کیا تاکہ Elasticsearch کے ساتھ اس کے ڈومین نام کے بجائے براہ راست اس کے IP ایڈریس کے ذریعے رابطہ کیا جا سکے۔ اس کے لیے کوڈ میں تبدیلی اور ایک نئی تعیناتی کی ضرورت ہوگی، اس لیے ہم نے بس ڈومین کو اس کے آئی پی ایڈریس پر میپ کیا /etc/hosts:
34.55.5.111 elastic.spain.adevinta.comکنٹینر کو اب تقریباً فوری طور پر اس کا آئی پی ایڈریس مل گیا۔ اس کے نتیجے میں کچھ بہتری آئی، لیکن ہم متوقع تاخیر کی سطح کے صرف قدرے قریب تھے۔ اگرچہ DNS ریزولیوشن میں کافی وقت لگ رہا تھا، لیکن اصل وجہ اب بھی ہم سے دور تھی۔
نیٹ ورک کی تشخیص
ہم نے کنٹینر کا استعمال کرتے ہوئے ٹریفک کا تجزیہ کرنے کا فیصلہ کیا۔ tcpdumpنیٹ ورک پر کیا ہو رہا ہے اس کا پتہ لگانے کے لیے:
[root@be-851c76f696-alf8z /]# tcpdump -leni any -w capture.pcap پھر ہم نے کچھ درخواستیں بھیجیں اور ان کی گرفتاری کو ڈاؤن لوڈ کیا (kubectl cp my-service:/capture.pcap capture.pcap) میں مزید تجزیہ کے لیے .
DNS سوالات کے بارے میں کچھ بھی مشکوک نہیں تھا (سوائے ایک معمولی تفصیل کے جس پر میں بعد میں بات کروں گا)۔ تاہم، اس میں کچھ عجیب و غریب چیزیں تھیں کہ ہماری سروس نے ہر درخواست پر کیسے کارروائی کی۔ ذیل میں ایک کیپچر سے ایک اسکرین شاٹ ہے جس میں دکھایا گیا ہے کہ جواب شروع ہونے سے پہلے درخواست کو قبول کیا جا رہا ہے:
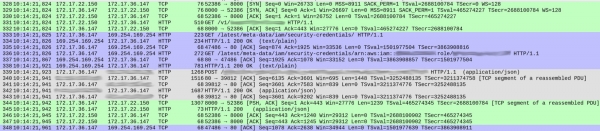
پیکٹ نمبر پہلے کالم میں دکھائے گئے ہیں۔ وضاحت کے لیے، میں نے مختلف ٹی سی پی اسٹریمز کو رنگ میں نمایاں کیا ہے۔
پیکٹ 328 سے شروع ہونے والی سبز ندی یہ ظاہر کرتی ہے کہ کس طرح کلائنٹ (172.17.22.150) نے کنٹینر (172.17.36.147) سے TCP کنکشن قائم کیا۔ ابتدائی مصافحہ (328-330) کے بعد، پیکٹ 331 لایا گیا۔ HTTP GET /v1/.. - ہماری خدمت میں آنے والی درخواست۔ پورے عمل میں 1 ایم ایس لگا۔
گرے اسٹریم (پیکٹ 339 سے شروع ہونے والا) ظاہر کرتا ہے کہ ہماری سروس نے ایلسٹک سرچ مثال کے لیے ایک HTTP درخواست بھیجی ہے (کوئی TCP ہینڈ شیک نہیں ہے کیونکہ یہ موجودہ کنکشن استعمال کرتا ہے)۔ اس میں 18 ایم ایس لگے۔
اب تک سب کچھ ٹھیک ہے، اور اوقات تقریباً متوقع تاخیر کے مطابق ہیں (20-30 ms جب کلائنٹ سے ماپا جاتا ہے)۔
تاہم، بلیو سیکشن 86 ایم ایس لیتا ہے۔ وہاں کیا ہو رہا ہے؟ پیکٹ 333 کے ساتھ، ہماری سروس نے ایک HTTP GET درخواست بھیجی۔ /latest/meta-data/iam/security-credentials، اور اس کے فوراً بعد، اسی TCP کنکشن پر، ایک اور GET کی درخواست /latest/meta-data/iam/security-credentials/arn:...
ہم نے پایا کہ یہ پورے ٹریس میں ہر درخواست کے مطابق تھا۔ ڈی این ایس ریزولوشن واقعی ہمارے کنٹینرز میں قدرے سست تھا (اس رجحان کی وضاحت کافی دلچسپ ہے، لیکن میں اسے ایک الگ مضمون کے لیے محفوظ کروں گا)۔ معلوم ہوا کہ بڑی تاخیر ہر درخواست کے لیے AWS انسٹینس میٹا ڈیٹا سروس کو کالز کی وجہ سے ہوئی تھی۔
مفروضہ 2: AWS کو ضرورت سے زیادہ کالز
دونوں اختتامی نقطوں کا تعلق ہے۔ Elasticsearch کے ساتھ کام کرتے وقت ہماری مائیکرو سروس اس سروس کو استعمال کرتی ہے۔ دونوں کالیں بنیادی اجازت کے عمل کا حصہ ہیں۔ ابتدائی درخواست کے دوران حاصل کردہ اختتامی نقطہ مثال سے وابستہ IAM کردار کو جاری کرتا ہے۔
/ # curl http://169.254.169.254/latest/meta-data/iam/security-credentials/
arn:aws:iam::<account_id>:role/some_roleدوسری درخواست اس مثال کے لیے عارضی اجازتوں کے لیے دوسرے اختتامی نقطہ سے رابطہ کرتی ہے:
/ # curl http://169.254.169.254/latest/meta-data/iam/security-credentials/arn:aws:iam::<account_id>:role/some_role`
{
"Code" : "Success",
"LastUpdated" : "2012-04-26T16:39:16Z",
"Type" : "AWS-HMAC",
"AccessKeyId" : "ASIAIOSFODNN7EXAMPLE",
"SecretAccessKey" : "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY",
"Token" : "token",
"Expiration" : "2017-05-17T15:09:54Z"
} کلائنٹ انہیں مختصر مدت کے لیے استعمال کر سکتا ہے اور اسے وقتاً فوقتاً نئے سرٹیفکیٹ حاصل کرنا ہوں گے (جب تک ان کی میعاد ختم نہ ہو جائے)۔ Expiration)۔ ماڈل آسان ہے: سیکیورٹی وجوہات کی بنا پر AWS اکثر عارضی کلیدوں کو گھماتا ہے، لیکن صارفین نئے سرٹیفکیٹس کے حصول سے وابستہ کارکردگی کے جرمانے کو پورا کرنے کے لیے انہیں چند منٹ کے لیے کیش کر سکتے ہیں۔
AWS Java SDK کو اس عمل کو منظم کرنے کی ذمہ داری سنبھالنی چاہیے، لیکن کسی وجہ سے ایسا نہیں ہوتا ہے۔
GitHub پر مسائل کو تلاش کرنے کے بعد، ہمیں ایک مسئلہ درپیش آیا اس نے ہمیں اس سمت کا تعین کرنے میں مدد کی جس میں مزید کھودنا ہے۔
AWS SDK سرٹیفکیٹس کی تجدید کرتا ہے جب مندرجہ ذیل میں سے کوئی ایک حالت ہوتی ہے:
- ان کی میعاد ختم ہونے کی تاریخ (
Expiration) میں داخل ہوتا ہے۔EXPIRATION_THRESHOLD15 منٹ کے لیے سخت کوڈ شدہ۔ - سرٹیفکیٹس کی تجدید کی آخری کوشش کے بعد سے زیادہ وقت ہو گیا ہے۔
REFRESH_THRESHOLD60 منٹ کے لیے ہارڈ کوڈ کیا گیا۔
سرٹیفکیٹس کی اصل میعاد ختم ہونے کی تاریخوں کو دیکھنے کے لیے جو ہم حاصل کر رہے تھے، ہم نے کنٹینر اور EC2 مثال دونوں سے اوپر دیے گئے cURL کمانڈز کو چلایا۔ کنٹینر سے موصول ہونے والے سرٹیفکیٹ کی میعاد ختم ہونے کی تاریخ بہت کم تھی: بالکل 15 منٹ۔
اب سب کچھ واضح ہو گیا: پہلی درخواست کے لیے، ہماری سروس کو عارضی سرٹیفکیٹ مل رہے تھے۔ چونکہ ان کی میعاد ختم ہونے کی تاریخ 15 منٹ تک محدود تھی، اس لیے AWS SDK بعد کی درخواستوں پر ان کی تجدید کرے گا۔ اور یہ ہر درخواست کے ساتھ ہوا۔
سرٹیفکیٹس کی میعاد کم کیوں ہو گئی ہے؟
AWS انسٹینس میٹا ڈیٹا سروس کو EC2 مثالوں کے ساتھ کام کرنے کے لیے ڈیزائن کیا گیا ہے، نہ کہ Kubernetes کے ساتھ۔ دوسری طرف، ہم ایپلیکیشن انٹرفیس کو تبدیل نہیں کرنا چاہتے تھے۔ اس کو حاصل کرنے کے لیے، ہم نے استعمال کیا۔ — ایک ٹول جو ہر Kubernetes نوڈ پر ایجنٹوں کا استعمال کرتے ہوئے، صارفین (کلسٹر میں ایپلی کیشنز تعینات کرنے والے انجینئرز) کو پوڈز میں کنٹینرز کو IAM رولز تفویض کرنے کی اجازت دیتا ہے گویا وہ EC2 مثالیں ہیں۔ KIAM AWS انسٹینس میٹا ڈیٹا سروس کو کالوں کو روکتا ہے اور انہیں اپنے کیشے سے پروسیس کرتا ہے، جو پہلے انہیں AWS سے موصول ہوا تھا۔ درخواست کے نقطہ نظر سے، کچھ بھی تبدیل نہیں ہوتا ہے۔
KIAM pods کو مختصر مدت کے سرٹیفکیٹ فراہم کرتا ہے۔ یہ سمجھ میں آتا ہے کہ پوڈ کی اوسط عمر EC2 مثال سے کم ہے۔ پہلے سے طے شدہ طور پر، سرٹیفکیٹس کی میعاد ختم ہوجاتی ہے۔ .
بالآخر، ان دو ڈیفالٹس کو یکجا کرنا ایک مسئلہ پیدا کرتا ہے۔ درخواست کو فراہم کردہ ہر سرٹیفکیٹ 15 منٹ کے بعد ختم ہو جاتا ہے۔ AWS Java SDK کسی بھی سرٹیفکیٹ کی تجدید پر مجبور کرتا ہے جس کی میعاد ختم ہونے تک 15 منٹ سے بھی کم وقت باقی ہے۔
نتیجے کے طور پر، عارضی سرٹیفکیٹ کو ہر درخواست کے ساتھ تجدید کرنے پر مجبور کیا جاتا ہے، جس میں AWS API کو کئی کالیں آتی ہیں اور تاخیر میں نمایاں اضافہ ہوتا ہے۔ ہم نے اسے AWS Java SDK میں دریافت کیا۔ ، جس میں اسی طرح کے مسئلے کا ذکر ہے۔
حل آسان نکلا۔ ہم نے طویل مدتی مدت کے ساتھ سرٹیفکیٹس کی درخواست کرنے کے لیے KIAM کو آسانی سے دوبارہ ترتیب دیا۔ ایک بار ایسا ہونے کے بعد، درخواستیں AWS میٹا ڈیٹا سروس کے بغیر آگے بڑھنا شروع ہو گئیں، اور لیٹنسی EC2 سے بھی کم سطح پر آ گئی۔
نتائج
ہجرت کے بارے میں ہمارے تجربے کی بنیاد پر، مسائل کے سب سے عام ذرائع میں سے ایک Kubernetes یا پلیٹ فارم کے دیگر عناصر میں کیڑے نہیں ہیں۔ نہ ہی اس کا تعلق ان مائیکرو سروسز میں کسی بنیادی خامیوں سے ہے جن کو ہم منتقل کر رہے ہیں۔ مسائل اکثر اس لیے پیدا ہوتے ہیں کہ ہم مختلف عناصر کو ایک ساتھ رکھتے ہیں۔
ہم پیچیدہ نظاموں کو ملاتے ہیں جو پہلے کبھی ایک دوسرے کے ساتھ بات چیت نہیں کرتے ہیں، ان سے توقع کرتے ہیں کہ وہ ایک واحد، بڑا نظام بنائیں گے۔ بدقسمتی سے، عناصر جتنے زیادہ ہوں گے، غلطی کا امکان اتنا ہی زیادہ ہوگا اور اینٹروپی بھی اتنی ہی زیادہ ہوگی۔
ہمارے معاملے میں، زیادہ تاخیر Kubernetes، KIAM، AWS Java SDK، یا ہماری مائیکرو سروس میں کیڑے یا خراب فیصلوں کا نتیجہ نہیں تھی۔ یہ دو آزاد ڈیفالٹ ترتیبات کا نتیجہ تھا: ایک KIAM میں اور ایک AWS Java SDK میں۔ انفرادی طور پر، دونوں ترتیبات معنی رکھتی ہیں: AWS Java SDK میں فعال سرٹیفکیٹ کی تجدید کی پالیسی اور KAIM میں مختصر سرٹیفکیٹ کی میعاد ختم ہونے کا وقت۔ لیکن جب یکجا کیا جائے تو نتائج غیر متوقع ہو جاتے ہیں۔ ضروری نہیں کہ دو آزاد اور منطقی حل یکجا ہونے پر کوئی معنی نہیں رکھتے۔
مترجم سے PS
آپ AWS IAM کو Kubernetes کے ساتھ مربوط کرنے کے لیے KIAM یوٹیلیٹی کے فن تعمیر کے بارے میں مزید جان سکتے ہیں۔ اس کے تخلیق کاروں سے۔
اور ہمارے بلاگ میں، آپ یہ بھی پڑھ سکتے ہیں:
- «؛ "
- «؛ "
- «؛ "
- «'.
ماخذ: www.habr.com
