

میں پوسٹگریس ڈیٹا بیس کو مکمل فعالیت میں بحال کرنے کا اپنا پہلا کامیاب تجربہ آپ کے ساتھ شیئر کرنا چاہتا ہوں۔ میں نے پہلی بار پوسٹگریس کا سامنا چھ ماہ قبل کیا تھا۔ اس سے پہلے، مجھے ڈیٹا بیس کے انتظام کا کوئی تجربہ نہیں تھا۔

میں ایک بڑی آئی ٹی کمپنی میں سیمی ڈی اوپس انجینئر کے طور پر کام کرتا ہوں۔ ہماری کمپنی زیادہ بوجھ والی خدمات کے لیے سافٹ ویئر تیار کرتی ہے، اور میں آپریشنل وشوسنییتا، دیکھ بھال، اور تعیناتی کے لیے ذمہ دار ہوں۔ مجھے ایک معیاری کام دیا گیا تھا: ایک ہی سرور پر ایپلیکیشن کو اپ ڈیٹ کرنا۔ ایپلیکیشن جینگو میں لکھی گئی ہے، اور اپ ڈیٹ کے دوران منتقلی (ڈیٹا بیس کے ڈھانچے میں تبدیلیاں) کی جاتی ہیں۔ اس عمل سے پہلے، ہم معیاری pg_dump پروگرام کا استعمال کرتے ہوئے ایک مکمل ڈیٹا بیس ڈمپ انجام دیتے ہیں، صرف اس صورت میں۔
ڈمپنگ کے دوران ایک غیر متوقع خرابی پیش آگئی (پوسٹگریس ورژن 9.5):
pg_dump: Oumping the contents of table “ws_log_smevlog” failed: PQgetResult() failed.
pg_dump: Error message from server: ERROR: invalid page in block 4123007 of relatton base/16490/21396989
pg_dump: The command was: COPY public.ws_log_smevlog [...]
pg_dunp: [parallel archtver] a worker process dled unexpectedly خرابی "بلاک میں غلط صفحہ" فائل سسٹم کی سطح پر مسائل کی نشاندہی کرتا ہے، جو بہت خراب ہے۔ مختلف فورمز نے کرنے کی تجویز دی ہے۔ مکمل ویکیوم اختیار کے ساتھ صفر_خراب_صفحات اس مسئلے کو حل کرنے کے لیے۔ ٹھیک ہے، پاپروبیم...
بحالی کی تیاری
انتباہ! اپنے ڈیٹا بیس کو بحال کرنے کی کوشش کرنے سے پہلے اپنی پوسٹگریس انسٹالیشن کا بیک اپ لینا یقینی بنائیں۔ اگر آپ ورچوئل مشین استعمال کر رہے ہیں تو ڈیٹا بیس کو روکیں اور اسنیپ شاٹ لیں۔ اگر آپ سنیپ شاٹ نہیں لے سکتے ہیں، تو ڈیٹا بیس کو روکیں اور پوسٹگریس ڈائرکٹری کے مواد (بشمول .wal فائلز) کو محفوظ مقام پر کاپی کریں۔ سب سے اہم بات یہ ہے کہ چیزوں کو خراب کرنے سے بچیں۔ پڑھیں .
چونکہ میرا ڈیٹا بیس عام طور پر کام کر رہا تھا، اس لیے میں نے اپنے آپ کو باقاعدہ ڈیٹا بیس ڈمپ تک محدود رکھا، لیکن خراب شدہ ڈیٹا کے ساتھ ٹیبل کو خارج کر دیا (آپشن -T، --exclude-table=TABLE pg_dump میں)۔
سرور جسمانی تھا، اس لیے اسنیپ شاٹ لینا ناممکن تھا۔ بیک اپ اپنی جگہ پر ہے، آئیے آگے بڑھتے ہیں۔
فائل سسٹم کی جانچ کر رہا ہے۔
ڈیٹابیس کو بحال کرنے کی کوشش کرنے سے پہلے، ہمیں یہ یقینی بنانا ہوگا کہ فائل سسٹم خود برقرار ہے۔ اور اگر کوئی غلطیاں ہیں، تو ہمیں ان کو ٹھیک کرنے کی ضرورت ہے، جیسا کہ دوسری صورت میں، ہم صرف چیزوں کو مزید خراب کر سکتے ہیں۔
میرے معاملے میں، ڈیٹا بیس کے ساتھ فائل سسٹم نصب تھا۔ "/srv" اور قسم ext4 تھی۔
ڈیٹا بیس کو روکیں: systemctl stop postgresql@9.5-main.service اور ہم چیک کرتے ہیں کہ فائل سسٹم کسی کے استعمال میں نہیں ہے اور کمانڈ کا استعمال کرکے ان ماؤنٹ کیا جا سکتا ہے۔ lsof:
lsof +D /srv
مجھے ریڈیس ڈیٹا بیس کو بھی روکنا پڑا کیونکہ یہ بھی استعمال کر رہا تھا۔ "/srv"پھر میں نے اسے ہٹا دیا۔ /ایس آر وی (umount)۔
فائل سسٹم کی جانچ یوٹیلیٹی کا استعمال کرتے ہوئے کی گئی۔ e2fsck -f کلید کے ساتھ (جب فائل سسٹم کو صاف نشان زد کیا گیا ہو تب بھی چیکنگ پر مجبور کریں۔):
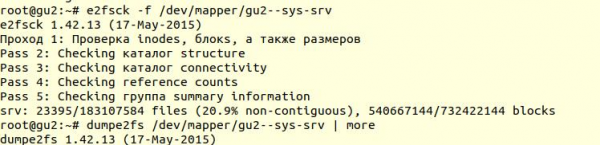
اگلا، افادیت کا استعمال کرتے ہوئے dumpe2fs (sudo dumpe2fs /dev/mapper/gu2—sys-srv | grep چیک کیا) آپ تصدیق کر سکتے ہیں کہ چیک اصل میں کیا گیا تھا:

e2fsck کہتے ہیں کہ ext4 فائل سسٹم کی سطح پر کوئی مسئلہ نہیں پایا گیا، جس کا مطلب ہے کہ آپ ڈیٹا بیس کو بحال کرنے کی کوشش جاری رکھ سکتے ہیں، یا زیادہ واضح طور پر، پر واپس جا سکتے ہیں۔ ویکیوم بھرا ہوا (یقینا، آپ کو فائل سسٹم کو واپس ماؤنٹ کرنے اور ڈیٹا بیس کو شروع کرنے کی ضرورت ہے)۔
اگر آپ کے پاس فزیکل سرور ہے تو، ڈسکوں کی حیثیت کو ضرور چیک کریں (بذریعہ smartctl -a /dev/XXX) یا RAID کنٹرولر یہ یقینی بنانے کے لیے کہ مسئلہ ہارڈ ویئر سے متعلق نہیں تھا۔ میرے معاملے میں، RAID ہارڈ ویئر پر مبنی نکلا، لہذا میں نے مقامی منتظم سے RAID کی حیثیت چیک کرنے کو کہا (سرور کئی سو کلومیٹر دور تھا)۔ انہوں نے کہا کہ کوئی خرابیاں نہیں ہیں، یعنی ہم یقینی طور پر بحالی شروع کر سکتے ہیں۔
کوشش 1: صفر_خراب_صفحات
سپر یوزر مراعات کے ساتھ اکاؤنٹ کا استعمال کرتے ہوئے psql کے ذریعے ڈیٹا بیس سے جڑیں۔ ہمیں ایک سپر یوزر کی ضرورت ہے کیونکہ آپشن صفر_خراب_صفحات صرف وہی اسے بدل سکتا ہے۔ میرے معاملے میں، یہ پوسٹگریس ہے:
psql -h 127.0.0.1 -U postgres -s [database_name]
آپشن صفر_خراب_صفحات پڑھنے کی غلطیوں کو نظر انداز کرنے کی ضرورت ہے (پوسٹگریسپرو ویب سائٹ سے):
جب ایک خراب صفحہ ہیڈر کا پتہ چلتا ہے، PostgreSQL عام طور پر ایک خرابی کی اطلاع دیتا ہے اور موجودہ لین دین کو روک دیتا ہے۔ اگر zero_damaged_pages پیرامیٹر فعال ہے، تو سسٹم اس کے بجائے ایک انتباہ جاری کرتا ہے، خراب صفحہ کو صفر کر دیتا ہے، اور کارروائی جاری رکھتا ہے۔ یہ رویہ ڈیٹا کو خراب کر دیتا ہے، خاص طور پر خراب شدہ صفحہ پر موجود تمام قطاریں۔
ہم آپشن کو فعال کرتے ہیں اور میز کا مکمل ویکیوم کرنے کی کوشش کرتے ہیں:
VACUUM FULL VERBOSE 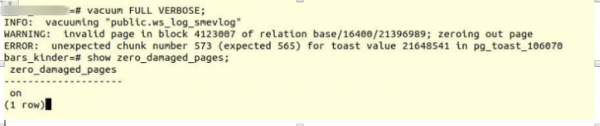
بدقسمتی سے، ناکامی.
ہمیں ایک ایسی ہی خرابی کا سامنا کرنا پڑا:
INFO: vacuuming "“public.ws_log_smevlog”
WARNING: invalid page in block 4123007 of relation base/16400/21396989; zeroing out page
ERROR: unexpected chunk number 573 (expected 565) for toast value 21648541 in pg_toast_106070- Poetgres میں "لمبا ڈیٹا" ذخیرہ کرنے کا طریقہ کار اگر وہ ایک صفحے پر فٹ نہیں ہوتے ہیں (پہلے سے طے شدہ 8kb)۔
کوشش 2: دوبارہ ترتیب دیں۔
گوگل کی طرف سے پہلی ٹپ نے مدد نہیں کی۔ چند منٹ کی تلاش کے بعد، مجھے دوسرا ٹپ ملا: ری انڈیکس خراب میز۔ میں نے اس مشورے کو بہت سی جگہوں پر دیکھا ہے، لیکن اس نے اعتماد کو متاثر نہیں کیا۔ آئیے ایک ری انڈیکس کرتے ہیں:
reindex table ws_log_smevlog 
ری انڈیکس بغیر کسی پریشانی کے مکمل.
تاہم، اس سے کوئی فائدہ نہیں ہوا، ویکیوم فل اسی طرح کی غلطی کے ساتھ کریش ہو گیا۔ چونکہ میں ناکامی کا عادی ہوں، اس لیے میں نے آن لائن مشورے کی تلاش جاری رکھی اور ایک دلچسپ بات سامنے آئی .
کوشش 3: منتخب کریں، حد کریں، آف سیٹ کریں۔
مندرجہ بالا مضمون نے ٹیبل کی قطار کا قطار در قطار جائزہ لینے اور دشواری والے ڈیٹا کو حذف کرنے کی تجویز دی ہے۔ سب سے پہلے، تمام قطاروں کا جائزہ لینا ضروری تھا:
for ((i=0; i<"Number_of_rows_in_nodes"; i++ )); do psql -U "Username" "Database Name" -c "SELECT * FROM nodes LIMIT 1 offset $i" >/dev/null || echo $i; doneمیرے معاملے میں ٹیبل پر مشتمل ہے۔ 1 628 991 لائنیں اس کا خیال رکھنا ضروری تھا۔ لیکن یہ ایک اور بحث کا موضوع ہے۔ یہ ہفتہ کا دن تھا، میں نے یہ حکم tmux میں چلایا اور بستر پر چلا گیا:
for ((i=0; i<1628991; i++ )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog LIMIT 1 offset $i" >/dev/null || echo $i; doneصبح تک، میں نے یہ دیکھنے کا فیصلہ کیا کہ حالات کیسے چل رہے ہیں۔ میری حیرت میں، میں نے دریافت کیا کہ 20 گھنٹوں کے بعد، صرف 2% ڈیٹا کو اسکین کیا گیا تھا! میں 50 دن انتظار نہیں کرنا چاہتا تھا۔ ایک اور مکمل ناکامی۔
لیکن میں نے ہمت نہیں ہاری۔ میں حیران تھا کہ اسکین میں اتنا وقت کیوں لگ رہا ہے۔ دستاویزات سے (دوبارہ postgrespro پر)، میں نے سیکھا:
OFFSET اس سے کہتا ہے کہ آؤٹ پٹ قطاروں کو شروع کرنے سے پہلے قطاروں کی مخصوص تعداد کو چھوڑ دے۔
اگر OFFSET اور LIMIT دونوں متعین ہیں، تو سسٹم پہلے OFFSET قطاروں کو چھوڑ دیتا ہے اور پھر LIMIT کے لیے قطاروں کی گنتی شروع کرتا ہے۔LIMIT کا استعمال کرتے وقت، یہ یقینی بنانے کے لیے ORDER BY شق کا استعمال کرنا بھی ضروری ہے کہ نتیجہ کی قطاریں ایک مخصوص ترتیب میں واپس آئیں۔ بصورت دیگر، قطاروں کے غیر متوقع ذیلی سیٹ واپس کر دیے جائیں گے۔
ظاہر ہے کہ اوپر کا حکم غلط تھا: اول تو نہیں تھا۔ کی طرف سے حکم، نتیجہ غلط ہو سکتا ہے۔ دوم، پوسٹگریس کو پہلے آف سیٹ قطاروں کو اسکین کرنا اور چھوڑنا پڑا، اور بڑھتے ہوئے آف سیٹ پیداواری صلاحیت مزید کم ہو جائے گی۔
کوشش 4: ٹیکسٹ ڈمپ کیپچر کریں۔
تب مجھے ایک بظاہر شاندار خیال آیا: ٹیکسٹ فارم میں ڈمپ لینا اور آخری ریکارڈ شدہ لائن کا تجزیہ کرنا۔
لیکن پہلے، آئیے ٹیبل کی ساخت سے واقف ہوں۔ ws_log_smevlog:
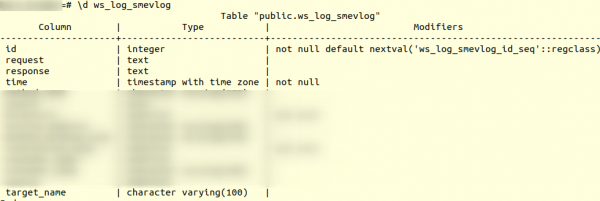
ہمارے معاملے میں ہمارے پاس ایک کالم ہے۔ "شناخت"، جس میں قطار کے لیے ایک منفرد شناخت کنندہ (کاؤنٹر) تھا۔ منصوبہ اس طرح تھا:
- ہم ڈیٹا کو ٹیکسٹ فارم میں ڈمپ کرنا شروع کر دیتے ہیں (SQL کمانڈز کی شکل میں)
- کسی وقت، ڈمپ میں خرابی کی وجہ سے خلل پڑ جائے گا، لیکن ٹیکسٹ فائل پھر بھی ڈسک پر محفوظ رہے گی۔
- ہم ٹیکسٹ فائل کے آخر کو دیکھتے ہیں، اس طرح ہمیں آخری لائن کا شناخت کنندہ (id) ملتا ہے جسے کامیابی سے ہٹا دیا گیا تھا۔
میں نے ٹیکسٹ فارم میں ڈمپنگ شروع کی:
pg_dump -U my_user -d my_database -F p -t ws_log_smevlog -f ./my_dump.dumpڈمپ، جیسا کہ توقع کی گئی تھی، اسی غلطی کے ساتھ ناکام ہوا:
pg_dump: Error message from server: ERROR: invalid page in block 4123007 of relatton base/16490/21396989 مزید کے ذریعے پونچھ میں نے ڈمپ کے آخر میں دیکھا (دم -5 ./my_dump.dump) نے پایا کہ id کے ساتھ لائن پر ڈمپ میں خلل پڑا تھا۔ 186 525"لہذا مسئلہ لائن ID 186 526 کا ہے، یہ ٹوٹ گیا ہے، اور اسے حذف کرنے کی ضرورت ہے!" میں نے سوچا۔ لیکن ڈیٹا بیس سے استفسار کرنے کے بعد:
«ws_log_smevlog سے * کو منتخب کریں جہاں id=186529 ہے۔"یہ پتہ چلا کہ اس قطار کے ساتھ سب کچھ ٹھیک تھا... 186,530 - 186,540 کے اشاریہ جات والی قطاریں بھی بغیر کسی پریشانی کے کام کرتی ہیں۔ ایک اور "شاندار خیال" ناکام رہا۔ بعد میں، میں سمجھ گیا کہ ایسا کیوں ہوا: جب کسی ٹیبل سے ڈیٹا کو حذف/تبدیل کیا جاتا ہے، تو اسے جسمانی طور پر حذف نہیں کیا جاتا، بلکہ "ڈیڈ ٹیپلز" کے طور پر نشان زد کیا جاتا ہے، پھر آتا ہے۔ آٹو ویکیوم اور ان قطاروں کو حذف شدہ کے بطور نشان زد کرتا ہے اور انہیں دوبارہ استعمال کرنے کی اجازت دیتا ہے۔ واضح کرنے کے لیے، اگر ٹیبل میں ڈیٹا تبدیل ہو جاتا ہے اور آٹو ویکیوم کو فعال کیا جاتا ہے، تو اسے ترتیب وار ذخیرہ نہیں کیا جاتا ہے۔
کوشش 5: SELECT, FROM, WHERE id=
ناکامیاں ہمیں مضبوط بناتی ہیں۔ آپ کو کبھی ہمت نہیں ہارنی چاہیے، آپ کو آگے بڑھتے رہنا چاہیے اور اپنے آپ پر اور اپنی صلاحیتوں پر یقین رکھنا چاہیے۔ لہذا میں نے ایک اور آپشن آزمانے کا فیصلہ کیا: صرف ایک ایک کرکے ڈیٹا بیس میں موجود تمام ریکارڈز کو دیکھیں۔ میرے ٹیبل کی ساخت کو جانتے ہوئے (اوپر دیکھیں)، ہمارے پاس ایک آئی ڈی فیلڈ ہے، جو منفرد ہے (بنیادی کلید)۔ ہمارے پاس ٹیبل میں 1,628,991 قطاریں ہیں۔ id وہ ترتیب میں ہیں، جس کا مطلب ہے کہ ہم ان پر ایک ایک کرکے اعادہ کرسکتے ہیں:
for ((i=1; i<1628991; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; doneان لوگوں کے لیے جو سمجھ نہیں پاتے، کمانڈ اس طرح کام کرتی ہے: یہ ٹیبل لائن کو لائن کے ذریعے اسکین کرتا ہے اور stdout بھیجتا ہے۔ / dev / null، لیکن اگر SELECT کمانڈ ناکام ہوجاتی ہے، تو غلطی کا متن پرنٹ ہوجاتا ہے (stderr کو کنسول پر بھیجا جاتا ہے) اور غلطی پر مشتمل لائن پرنٹ ہوجاتی ہے (بشکریہ ||، جس کا مطلب ہے کہ منتخب کرنے میں دشواری تھی (کمانڈ واپسی کوڈ 0 نہیں ہے))۔
میں خوش قسمت تھا، میں نے میدان میں اشاریہ جات بنائے تھے۔ id:

اس کا مطلب ہے کہ مطلوبہ آئی ڈی کے ساتھ قطار تلاش کرنے میں زیادہ وقت نہیں لگنا چاہیے۔ نظریہ میں، یہ کام کرنا چاہئے. تو، آئیے کمانڈ کو اندر چلائیں۔ tmux اور چلو بستر پر چلتے ہیں.
صبح تک، میں نے تقریباً 90,000 پوسٹس دیکھی ہوں گی، 5% سے کچھ زیادہ۔ پچھلے طریقہ (2%) کے مقابلے میں ایک بہترین نتیجہ! لیکن میں 20 دن انتظار نہیں کرنا چاہتا تھا۔
کوشش 6: SELECT, FROM, WHERE id >= اور id
کسٹمر کے پاس ڈیٹا بیس کے لیے ایک بہترین سرور مختص کیا گیا تھا: ایک ڈوئل پروسیسر۔ Intel Xeon E5-2697 v2ہمارے پاس کل 48 تھریڈز دستیاب تھے! سرور کا بوجھ اوسط تھا، اس لیے ہم تقریباً 20 تھریڈز کو آسانی سے سنبھال سکتے تھے۔ ہمارے پاس کافی مقدار میں RAM بھی تھی: ایک مکمل 384 گیگا بائٹس!
لہذا، ٹیم کو متوازی ہونا پڑا:
for ((i=1; i<1628991; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; doneمیں یہاں ایک خوبصورت اور خوبصورت اسکرپٹ لکھ سکتا تھا، لیکن میں نے سب سے تیز متوازی طریقہ کا انتخاب کیا: 0-1628991 کی حد کو دستی طور پر 100,000 ریکارڈ کے وقفوں میں تقسیم کریں اور درج ذیل قسم کے 16 کمانڈز کو الگ سے چلائیں۔
for ((i=N; i<M; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; doneلیکن یہ سب کچھ نہیں ہے۔ ڈیٹا بیس سے جڑنے میں کچھ وقت اور سسٹم کے وسائل بھی لگتے ہیں۔ 1,628,991 کو جوڑنا زیادہ سمارٹ نہیں تھا، آپ اتفاق کریں گے۔ تو آئیے صرف ایک کے بجائے فی کنکشن 1000 قطاریں بازیافت کریں۔ حکم اس طرح ختم ہوا:
for ((i=N; i<M; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; donetmux سیشن میں 16 ونڈوز کھولیں اور درج ذیل کمانڈز چلائیں۔
1) for ((i=0; i<100000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done 2) for ((i=100000; i<200000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done … 15) for ((i=1400000; i<1500000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done 16) for ((i=1500000; i<1628991; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done
ایک دن بعد، مجھے پہلے نتائج موصول ہوئے! خاص طور پر (XXX اور ZZZ اقدار کو مزید محفوظ نہیں کیا گیا تھا):
ERROR: missing chunk number 0 for toast value 37837571 in pg_toast_106070
829000
ERROR: missing chunk number 0 for toast value XXX in pg_toast_106070
829000
ERROR: missing chunk number 0 for toast value ZZZ in pg_toast_106070
146000اس کا مطلب ہے کہ ہمارے پاس غلطیوں والی تین قطاریں ہیں۔ پہلے اور دوسرے پرابلم والے ریکارڈز کی ID 829,000 اور 830,000 کے درمیان تھی، اور تیسرے کی ID 146,000 اور 147,000 کے درمیان تھی۔ اگلا، ہمیں صرف مشکل ریکارڈوں کی صحیح ID قدریں تلاش کرنے کی ضرورت تھی۔ ایسا کرنے کے لیے، ہم اپنے مشکل ریکارڈز کی رینج کو 1 کے اضافے میں اسکین کرتے ہیں اور IDs کی شناخت کرتے ہیں:
for ((i=829000; i<830000; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done 829417 ERROR: unexpected chunk number 2 (expected 0) for toast value 37837843 in pg_toast_106070 829449 for ((i=146000; i<147000; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done 829417 ERROR: unexpected chunk number ZZZ (expected 0) for toast value XXX in pg_toast_106070 146911
خوشی ختم ہونے والا
ہمیں پریشانی والی قطاریں مل گئی ہیں۔ آئیے psql کا استعمال کرتے ہوئے ڈیٹا بیس تک رسائی حاصل کریں اور انہیں حذف کرنے کی کوشش کریں:
my_database=# delete from ws_log_smevlog where id=829417;
DELETE 1
my_database=# delete from ws_log_smevlog where id=829449;
DELETE 1
my_database=# delete from ws_log_smevlog where id=146911;
DELETE 1میری حیرت کی بات یہ ہے کہ بغیر آپشن کے بھی ریکارڈز بغیر کسی پریشانی کے حذف کر دیے گئے۔ صفر_خراب_صفحات.
پھر میں نے ڈیٹا بیس سے منسلک کیا، کیا ویکیوم فل (میرے خیال میں ایسا کرنا ضروری نہیں تھا) اور آخر کار کامیابی کے ساتھ بیک اپ لے لیا۔ pg_dumpڈمپ بغیر کسی غلطی کے لیا گیا تھا! اس ناقابل یقین حد تک احمقانہ طریقہ سے مسئلہ حل ہو گیا۔ میں بہت ساری ناکامیوں کے بعد آخر کار ایک حل تلاش کرنے پر بہت خوش تھا!
اعترافات اور نتیجہ
یہ ایک حقیقی پوسٹگریس ڈیٹا بیس کو بحال کرنے کا میرا پہلا تجربہ تھا۔ مجھے یہ تجربہ طویل عرصے تک یاد رہے گا۔
اور آخر میں، میں پوسٹگریس پرو کا شکریہ ادا کرنا چاہوں گا کہ اس نے دستاویزات کا روسی اور اس کے لیے ترجمہ کیا۔ ، جو مسئلے کے تجزیہ کے دوران بہت مددگار تھے۔
ماخذ: www.habr.com
