

میرا مشورہ ہے کہ آپ Data Egret "Fundamentals of PostgreSQL مانیٹرنگ" سے Alexey Lesovsky کی رپورٹ کا ٹرانسکرپٹ پڑھیں۔
اس رپورٹ میں، الیکسی لیسوفسکی پوسٹ جاریس کے اعدادوشمار کے اہم نکات کے بارے میں بات کریں گے، ان کا کیا مطلب ہے، اور انہیں نگرانی میں کیوں موجود ہونا چاہیے؛ اس بارے میں کہ نگرانی میں کون سے گراف ہونے چاہئیں، انہیں کیسے شامل کیا جائے اور ان کی تشریح کیسے کی جائے۔ یہ رپورٹ ڈیٹا بیس کے منتظمین، سسٹم ایڈمنسٹریٹرز اور ڈیولپرز کے لیے کارآمد ہو گی جو پوسٹگریس ٹربل شوٹنگ میں دلچسپی رکھتے ہیں۔


میرا نام Alexey Lesovsky ہے، میں Data Egret کمپنی کی نمائندگی کرتا ہوں۔
اپنے بارے میں چند الفاظ۔ میں نے بہت پہلے ایک سسٹم ایڈمنسٹریٹر کی حیثیت سے شروعات کی تھی۔
ہر طرح کی مختلف چیزوں کا انتظام کیا۔ Linuxسے متعلق مختلف چیزوں میں ملوث تھا۔ Linux، یعنی، ورچوئلائزیشن، نگرانی، پراکسیز کے ساتھ کام کرنا، وغیرہ۔ لیکن کسی وقت، میں نے ڈیٹا بیس، PostgreSQL کے ساتھ زیادہ کام کرنا شروع کیا۔ مجھے واقعی یہ پسند آیا۔ اور کسی وقت، میں نے اپنا زیادہ تر وقت PostgreSQL کے ساتھ کام کرنا شروع کیا۔ اور اس طرح، آہستہ آہستہ، میں پوسٹگری ایس کیو ایل ڈی بی اے بن گیا۔
اور اپنے پورے کیریئر میں، میں نے ہمیشہ شماریات، نگرانی اور ٹیلی میٹری کے موضوعات میں دلچسپی لی ہے۔ اور جب میں سسٹم ایڈمنسٹریٹر تھا، میں نے زیبکس کے ساتھ بہت قریب سے کام کیا۔ اور میں نے اسکرپٹ کا ایک چھوٹا سیٹ لکھا جیسے یہ اپنے زمانے میں کافی مقبول تھا۔ اور آپ وہاں متعدد اہم چیزوں کی نگرانی کر سکتے ہیں، نہ صرف Linux، بلکہ مختلف اجزاء۔
اب میں PostgreSQL پر کام کر رہا ہوں۔ میں پہلے ہی ایک اور چیز لکھ رہا ہوں جو آپ کو PostgreSQL کے اعدادوشمار کے ساتھ کام کرنے کی اجازت دیتا ہے۔ یہ کہا جاتا ہے (Habré پر مضمون - ).

ایک چھوٹا سا تعارفی نوٹ۔ ہمارے گاہکوں، ہمارے گاہکوں کو کیا حالات ہیں؟ ڈیٹا بیس سے متعلق کسی قسم کا حادثہ ہے۔ اور جب ڈیٹا بیس پہلے ہی بحال ہو چکا ہوتا ہے، تو محکمہ کا سربراہ یا ترقی کا سربراہ آتا ہے اور کہتا ہے: "دوستو، ہمیں ڈیٹا بیس کی نگرانی کرنے کی ضرورت ہے، کیونکہ کچھ برا ہوا ہے اور ہمیں اسے مستقبل میں ہونے سے روکنے کی ضرورت ہے۔" اور یہاں سے ایک مانیٹرنگ سسٹم کو منتخب کرنے یا موجودہ مانیٹرنگ سسٹم کو اپنانے کا دلچسپ عمل شروع ہوتا ہے تاکہ آپ اپنے ڈیٹا بیس - PostgreSQL، MySQL یا کچھ دوسرے کی نگرانی کر سکیں۔ اور ساتھیوں نے مشورہ دینا شروع کیا: "میں نے سنا ہے کہ فلاں اور فلاں ڈیٹا بیس ہے۔ چلو اسے استعمال کرتے ہیں۔" ساتھی ایک دوسرے سے بحث کرنے لگتے ہیں۔ اور آخر میں یہ پتہ چلتا ہے کہ ہم کسی قسم کا ڈیٹا بیس منتخب کرتے ہیں، لیکن PostgreSQL مانیٹرنگ اس میں بہت خراب طریقے سے پیش کی گئی ہے اور ہمیں ہمیشہ کچھ شامل کرنا پڑتا ہے۔ GitHub سے کچھ ذخیرے لیں، انہیں کلون کریں، اسکرپٹس کو اپنائیں، اور کسی نہ کسی طرح انہیں اپنی مرضی کے مطابق بنائیں۔ اور آخر میں یہ کسی قسم کا دستی کام ہوتا ہے۔

لہذا، اس گفتگو میں میں آپ کو نہ صرف PostgreSQL بلکہ ڈیٹا بیس کے لیے بھی نگرانی کا انتخاب کرنے کے بارے میں کچھ معلومات دینے کی کوشش کروں گا۔ اور آپ کو وہ علم دیں جو آپ کو اس سے کچھ فائدہ حاصل کرنے کے لیے اپنی نگرانی کو مکمل کرنے کی اجازت دے، تاکہ آپ اپنے ڈیٹا بیس کو فائدہ کے ساتھ مانیٹر کر سکیں، تاکہ آنے والی کسی بھی ہنگامی صورت حال کو فوری طور پر روکا جا سکے۔
اور جو آئیڈیاز اس رپورٹ میں ہوں گے ان کو براہ راست کسی بھی ڈیٹا بیس میں ڈھال لیا جا سکتا ہے، چاہے وہ DBMS ہو یا noSQL۔ لہذا، صرف PostgreSQL نہیں ہے، لیکن PostgreSQL میں اسے کیسے کرنا ہے اس کے بارے میں بہت سی ترکیبیں موجود ہوں گی۔ سوالات کی مثالیں ہوں گی، ان اداروں کی مثالیں جو PostgreSQL کے پاس نگرانی کے لیے ہیں۔ اور اگر آپ کے DBMS میں وہی چیزیں ہیں جو آپ کو نگرانی میں رکھنے کی اجازت دیتی ہیں، تو آپ ان کو ڈھال سکتے ہیں، انہیں شامل کر سکتے ہیں اور یہ اچھا ہو گا۔
 میں رپورٹ میں نہیں ہوں گا۔
میں رپورٹ میں نہیں ہوں گا۔
میٹرکس کی فراہمی اور ذخیرہ کرنے کے طریقے کے بارے میں بات کریں۔ میں ڈیٹا کی پوسٹ پروسیسنگ اور اسے صارف کے سامنے پیش کرنے کے بارے میں کچھ نہیں کہوں گا۔ اور میں خبردار کرنے کے بارے میں کچھ نہیں کہوں گا۔
لیکن جیسے جیسے کہانی آگے بڑھے گی، میں موجودہ نگرانی کے مختلف اسکرین شاٹس دکھاؤں گا اور کسی نہ کسی طرح ان پر تنقید کروں گا۔ لیکن اس کے باوجود، میں برانڈز کا نام نہ دینے کی کوشش کروں گا تاکہ ان پروڈکٹس کے لیے اشتہارات یا اینٹی ایڈورٹائزنگ نہ بنیں۔ لہذا، تمام اتفاقات بے ترتیب ہیں اور آپ کے تخیل پر چھوڑ دیے گئے ہیں۔

سب سے پہلے، آئیے یہ معلوم کریں کہ نگرانی کیا ہے۔ نگرانی ایک بہت اہم چیز ہے۔ اس بات کو ہر کوئی سمجھتا ہے۔ لیکن ایک ہی وقت میں، نگرانی کا تعلق کسی کاروباری پروڈکٹ سے نہیں ہوتا اور نہ ہی کمپنی کے منافع پر براہ راست اثر پڑتا ہے، اس لیے وقت ہمیشہ بقایا بنیادوں پر نگرانی کے لیے مختص کیا جاتا ہے۔ اگر ہمارے پاس وقت ہے تو ہم مانیٹرنگ کرتے ہیں، اگر ہمارے پاس وقت نہیں ہے، تو ٹھیک ہے، ہم اسے بیک لاگ میں ڈال دیں گے اور کسی دن ہم ان کاموں پر واپس آجائیں گے۔
لہذا، ہماری مشق سے، جب ہم کلائنٹس کے پاس آتے ہیں، تو نگرانی اکثر نامکمل ہوتی ہے اور اس میں کوئی ایسی دلچسپ چیزیں نہیں ہوتی ہیں جو ڈیٹا بیس کے ساتھ بہتر کام کرنے میں ہماری مدد کرتی ہوں۔ اور اس لیے نگرانی کو ہمیشہ مکمل کرنے کی ضرورت ہے۔
ڈیٹا بیس ایسی پیچیدہ چیزیں ہیں جن پر نظر رکھنے کی بھی ضرورت ہے، کیونکہ ڈیٹا بیس معلومات کا ذخیرہ ہیں۔ اور معلومات کمپنی کے لیے بہت اہم ہیں؛ اسے کسی بھی طرح ضائع نہیں کیا جا سکتا۔ لیکن ایک ہی وقت میں، ڈیٹا بیس سافٹ ویئر کے بہت پیچیدہ ٹکڑے ہیں. وہ اجزاء کی ایک بڑی تعداد پر مشتمل ہے. اور ان میں سے بہت سے اجزاء کو مانیٹر کرنے کی ضرورت ہے۔
 اگر ہم خاص طور پر PostgreSQL کے بارے میں بات کر رہے ہیں، تو اسے ایک سکیم کی شکل میں پیش کیا جا سکتا ہے جو کہ بہت سے اجزاء پر مشتمل ہو۔ یہ اجزاء ایک دوسرے کے ساتھ تعامل کرتے ہیں۔ اور اسی وقت، PostgreSQL کے پاس نام نہاد Stats Collector سب سسٹم ہے، جو آپ کو ان سب سسٹمز کے آپریشن کے بارے میں اعداد و شمار جمع کرنے اور منتظم یا صارف کو کسی قسم کا انٹرفیس فراہم کرنے کی اجازت دیتا ہے تاکہ وہ ان اعدادوشمار کو دیکھ سکے۔
اگر ہم خاص طور پر PostgreSQL کے بارے میں بات کر رہے ہیں، تو اسے ایک سکیم کی شکل میں پیش کیا جا سکتا ہے جو کہ بہت سے اجزاء پر مشتمل ہو۔ یہ اجزاء ایک دوسرے کے ساتھ تعامل کرتے ہیں۔ اور اسی وقت، PostgreSQL کے پاس نام نہاد Stats Collector سب سسٹم ہے، جو آپ کو ان سب سسٹمز کے آپریشن کے بارے میں اعداد و شمار جمع کرنے اور منتظم یا صارف کو کسی قسم کا انٹرفیس فراہم کرنے کی اجازت دیتا ہے تاکہ وہ ان اعدادوشمار کو دیکھ سکے۔
یہ اعداد و شمار افعال اور نظریات کے ایک مخصوص سیٹ کی شکل میں پیش کیے جاتے ہیں۔ انہیں میزیں بھی کہا جا سکتا ہے۔ یعنی، ایک باقاعدہ psql کلائنٹ کا استعمال کرتے ہوئے، آپ ڈیٹا بیس سے منسلک ہو سکتے ہیں، ان فنکشنز اور ویوز پر ایک انتخاب کر سکتے ہیں، اور PostgreSQL سب سسٹم کے آپریشن کے بارے میں کچھ مخصوص نمبر حاصل کر سکتے ہیں۔
آپ ان نمبروں کو اپنے پسندیدہ مانیٹرنگ سسٹم میں شامل کر سکتے ہیں، گراف بنا سکتے ہیں، فنکشنز شامل کر سکتے ہیں اور طویل مدت میں تجزیات حاصل کر سکتے ہیں۔
لیکن اس رپورٹ میں میں ان تمام افعال کا مکمل احاطہ نہیں کروں گا، کیونکہ اس میں پورا دن لگ سکتا ہے۔ میں لفظی طور پر دو، تین یا چار چیزوں پر توجہ دوں گا اور آپ کو بتاؤں گا کہ وہ نگرانی کو بہتر بنانے میں کس طرح مدد کرتے ہیں۔

اور اگر ہم ڈیٹا بیس کی نگرانی کی بات کرتے ہیں، تو پھر نگرانی کرنے کی کیا ضرورت ہے؟ سب سے پہلے، ہمیں دستیابی کی نگرانی کرنے کی ضرورت ہے، کیونکہ ڈیٹا بیس ایک ایسی خدمت ہے جو کلائنٹس کو ڈیٹا تک رسائی فراہم کرتی ہے اور ہمیں دستیابی کی نگرانی کرنے کی ضرورت ہے، اور اس کی کچھ کوالیٹیٹیو اور مقداری خصوصیات بھی فراہم کرنی ہیں۔

ہمیں ان کلائنٹس کی نگرانی کرنے کی بھی ضرورت ہے جو ہمارے ڈیٹا بیس سے جڑتے ہیں، کیونکہ وہ عام کلائنٹ اور نقصان دہ کلائنٹ دونوں ہوسکتے ہیں جو ڈیٹا بیس کو نقصان پہنچا سکتے ہیں۔ ان پر نظر رکھنے اور ان کی سرگرمیوں پر نظر رکھنے کی بھی ضرورت ہے۔

جب کلائنٹس ڈیٹا بیس سے جڑتے ہیں، تو ظاہر ہے کہ وہ ہمارے ڈیٹا کے ساتھ کام کرنا شروع کر دیتے ہیں، اس لیے ہمیں یہ مانیٹر کرنے کی ضرورت ہے کہ کلائنٹس ڈیٹا کے ساتھ کیسے کام کرتے ہیں: کس ٹیبل کے ساتھ، اور کچھ حد تک، کن اشاریہ جات کے ساتھ۔ یعنی، ہمیں کام کے بوجھ کا اندازہ کرنے کی ضرورت ہے جو ہمارے کلائنٹس کے ذریعے پیدا ہوتا ہے۔

لیکن کام کا بوجھ بھی یقیناً درخواستوں پر مشتمل ہوتا ہے۔ ایپلیکیشنز ڈیٹا بیس سے جڑتی ہیں، سوالات کا استعمال کرتے ہوئے ڈیٹا تک رسائی حاصل کرتی ہیں، اس لیے یہ جانچنا ضروری ہے کہ ڈیٹا بیس میں ہمارے پاس کون سے سوالات ہیں، ان کی مناسبیت کی نگرانی کریں، کہ وہ ٹیڑھے طریقے سے نہیں لکھے گئے ہیں، کہ کچھ اختیارات کو دوبارہ لکھنے اور بنانے کی ضرورت ہے تاکہ وہ تیزی سے کام کریں۔ اور بہتر کارکردگی کے ساتھ۔

اور چونکہ ہم ایک ڈیٹا بیس کے بارے میں بات کر رہے ہیں، ڈیٹا بیس ہمیشہ پس منظر کے عمل ہوتا ہے۔ پس منظر کے عمل ڈیٹابیس کی کارکردگی کو اچھی سطح پر برقرار رکھنے میں مدد کرتے ہیں، اس لیے انہیں کام کرنے کے لیے اپنے لیے مخصوص وسائل کی ضرورت ہوتی ہے۔ اور ایک ہی وقت میں، وہ کلائنٹ کی درخواست کے وسائل کے ساتھ اوورلیپ کر سکتے ہیں، لہذا لالچی پس منظر کے عمل کلائنٹ کی درخواستوں کی کارکردگی کو براہ راست متاثر کر سکتے ہیں۔ لہذا، ان کی نگرانی اور ٹریک کرنے کی بھی ضرورت ہے تاکہ پس منظر کے عمل کے لحاظ سے کوئی بگاڑ نہ ہو۔

اور ڈیٹا بیس کی نگرانی کے لحاظ سے یہ سب سسٹم میٹرک میں رہتا ہے۔ لیکن اس بات پر غور کرتے ہوئے کہ ہمارا زیادہ تر انفراسٹرکچر بادلوں کی طرف بڑھ رہا ہے، انفرادی میزبان کے سسٹم میٹرکس ہمیشہ پس منظر میں دھندلا جاتے ہیں۔ لیکن ڈیٹا بیس میں وہ اب بھی متعلقہ ہیں اور یقیناً، سسٹم میٹرکس کی نگرانی کرنا بھی ضروری ہے۔

سسٹم میٹرکس کے ساتھ سب کچھ کم و بیش ٹھیک ہے، تمام جدید مانیٹرنگ سسٹم پہلے ہی ان میٹرکس کو سپورٹ کرتے ہیں، لیکن عام طور پر، کچھ اجزاء اب بھی کافی نہیں ہیں اور کچھ چیزوں کو شامل کرنے کی ضرورت ہے۔ میں ان کو بھی چھووں گا، ان کے بارے میں کئی سلائیڈز ہوں گی۔

منصوبے کا پہلا نکتہ رسائی ہے۔ رسائی کیا ہے؟ میری سمجھ میں دستیابی سروس کنکشن کے لیے بیس کی صلاحیت ہے، یعنی بیس کو بڑھایا جاتا ہے، یہ، بطور سروس، کلائنٹس سے کنکشن قبول کرتا ہے۔ اور اس رسائی کا اندازہ بعض خصوصیات سے لگایا جا سکتا ہے۔ ڈیش بورڈز پر ان خصوصیات کو ظاہر کرنا بہت آسان ہے۔

ہر کوئی جانتا ہے کہ ڈیش بورڈ کیا ہیں۔ یہ تب ہوتا ہے جب آپ نے اسکرین پر ایک نظر ڈالی جس پر ضروری معلومات کا خلاصہ کیا گیا ہے۔ اور آپ فوری طور پر تعین کر سکتے ہیں کہ ڈیٹا بیس میں کوئی مسئلہ ہے یا نہیں۔
اس کے مطابق، ڈیٹا بیس کی دستیابی اور دیگر اہم خصوصیات کو ہمیشہ ڈیش بورڈز پر ظاہر کیا جانا چاہیے تاکہ یہ معلومات آپ کے پاس موجود رہیں اور آپ کے لیے ہمیشہ دستیاب رہیں۔ کچھ اضافی تفصیلات جو پہلے سے ہی واقعات کی تحقیقات میں مدد کرتی ہیں، جب کچھ ہنگامی حالات کی تفتیش کرتے ہیں، تو انہیں پہلے سے ہی ثانوی ڈیش بورڈز پر رکھنے کی ضرورت ہوتی ہے، یا ڈرل ڈاؤن لنکس میں چھپنے کی ضرورت ہوتی ہے جو تھرڈ پارٹی مانیٹرنگ سسٹم کی طرف لے جاتے ہیں۔
ایک معروف مانیٹرنگ سسٹم کی مثال۔ یہ ایک بہت ہی ٹھنڈا مانیٹرنگ سسٹم ہے۔ وہ بہت سا ڈیٹا اکٹھا کرتی ہے، لیکن میرے نقطہ نظر سے، اس کے پاس ڈیش بورڈز کا ایک عجیب تصور ہے۔ "ڈیش بورڈ بنائیں" کا لنک ہے۔ لیکن جب آپ ڈیش بورڈ بناتے ہیں، تو آپ دو کالموں کی فہرست بناتے ہیں، گراف کی فہرست۔ اور جب آپ کو کسی چیز کو دیکھنے کی ضرورت ہوتی ہے، تو آپ ماؤس سے کلک کرنا شروع کرتے ہیں، اسکرول کرتے ہیں، مطلوبہ چارٹ تلاش کرتے ہیں۔ اور اس میں وقت لگتا ہے، یعنی اس طرح کے کوئی ڈیش بورڈز نہیں ہیں۔ صرف چارٹس کی فہرستیں ہیں۔

آپ کو ان ڈیش بورڈز میں کیا شامل کرنا چاہیے؟ آپ جوابی وقت جیسی خصوصیت کے ساتھ شروعات کر سکتے ہیں۔ PostgreSQL میں pg_stat_statements منظر ہے۔ یہ ڈیفالٹ کے طور پر غیر فعال ہے، لیکن یہ ان اہم سسٹم ویوز میں سے ایک ہے جسے ہمیشہ فعال اور استعمال کیا جانا چاہیے۔ یہ ڈیٹا بیس میں چلنے والے تمام سوالات کے بارے میں معلومات کو محفوظ کرتا ہے۔
اس کے مطابق، ہم اس حقیقت سے شروع کر سکتے ہیں کہ ہم تمام درخواستوں پر عمل درآمد کا کل وقت لے سکتے ہیں اور اسے مندرجہ بالا فیلڈز کا استعمال کرتے ہوئے درخواستوں کی تعداد سے تقسیم کر سکتے ہیں۔ لیکن یہ ہسپتال میں اوسط درجہ حرارت ہے۔ ہم دوسرے شعبوں سے شروع کر سکتے ہیں - کم از کم استفسار پر عمل درآمد کا وقت، زیادہ سے زیادہ اور درمیانی۔ اور ہم پرسنٹائل بھی بنا سکتے ہیں؛ PostgreSQL میں اس کے لیے متعلقہ افعال ہیں۔ اور ہم کچھ نمبر حاصل کر سکتے ہیں جو پہلے سے مکمل شدہ درخواستوں کے لیے ہمارے ڈیٹا بیس کے رسپانس ٹائم کی خصوصیت رکھتے ہیں، یعنی ہم جعلی درخواست 'سلیکٹ 1' پر عمل نہیں کرتے اور جوابی وقت کو دیکھتے ہیں، لیکن ہم پہلے سے مکمل شدہ درخواستوں کے جوابی وقت کا تجزیہ کرتے ہیں اور ڈرا کرتے ہیں۔ یا تو ایک الگ شکل، یا ہم اس کی بنیاد پر ایک گراف بناتے ہیں۔
نظام کی طرف سے اس وقت پیدا ہونے والی غلطیوں کی تعداد کی نگرانی کرنا بھی ضروری ہے۔ اور اس کے لیے آپ pg_stat_database view استعمال کر سکتے ہیں۔ ہم xact_rollback فیلڈ پر توجہ مرکوز کرتے ہیں۔ یہ فیلڈ نہ صرف ڈیٹا بیس میں ہونے والے رول بیکس کی تعداد کو ظاہر کرتی ہے بلکہ غلطیوں کی تعداد کو بھی مدنظر رکھتی ہے۔ نسبتاً، ہم اس اعداد و شمار کو اپنے ڈیش بورڈ میں ڈسپلے کر سکتے ہیں اور دیکھ سکتے ہیں کہ اس وقت ہمارے پاس کتنی غلطیاں ہیں۔ اگر بہت ساری خرابیاں ہیں، تو یہ ایک اچھی وجہ ہے کہ لاگز کو دیکھیں اور دیکھیں کہ وہ کس قسم کی خرابیاں ہیں اور کیوں ہوتی ہیں، اور پھر سرمایہ کاری کریں اور انہیں حل کریں۔

آپ ٹیکو میٹر جیسی چیز شامل کر سکتے ہیں۔ یہ فی سیکنڈ لین دین کی تعداد اور فی سیکنڈ درخواستوں کی تعداد ہے۔ نسبتاً، آپ ان نمبروں کو اپنے ڈیٹا بیس کی موجودہ کارکردگی کے طور پر استعمال کر سکتے ہیں اور مشاہدہ کر سکتے ہیں کہ آیا درخواستوں میں چوٹیاں ہیں، لین دین میں چوٹی ہے، یا، اس کے برعکس، آیا ڈیٹا بیس کو انڈر لوڈ کیا گیا ہے کیونکہ کچھ بیک اینڈ ناکام ہو گیا ہے۔ اس اعداد و شمار کو ہمیشہ دیکھنا اور یاد رکھنا ضروری ہے کہ ہمارے پروجیکٹ کے لیے اس قسم کی کارکردگی معمول کی بات ہے، لیکن اوپر اور نیچے کی قدریں پہلے سے ہی ایک قسم کی پریشانی اور ناقابل فہم ہیں، جس کا مطلب ہے کہ ہمیں یہ دیکھنا ہوگا کہ یہ اعداد کیوں ہیں؟ اتنا زیادہ.
ٹرانزیکشنز کی تعداد کا اندازہ لگانے کے لیے، ہم دوبارہ pg_stat_database ویو کا حوالہ دے سکتے ہیں۔ ہم کمٹ کی تعداد اور رول بیکس کی تعداد شامل کر سکتے ہیں اور فی سیکنڈ لین دین کی تعداد حاصل کر سکتے ہیں۔
کیا ہر کوئی سمجھتا ہے کہ ایک لین دین میں کئی درخواستیں فٹ ہو سکتی ہیں؟ لہذا TPS اور QPS قدرے مختلف ہیں۔
فی سیکنڈ درخواستوں کی تعداد pg_stat_statements سے حاصل کی جا سکتی ہے اور بس تمام مکمل شدہ درخواستوں کے مجموعے کا حساب لگائیں۔ یہ واضح ہے کہ ہم موجودہ قدر کا موازنہ سابقہ سے کرتے ہیں، اسے گھٹاتے ہیں، ڈیلٹا حاصل کرتے ہیں، اور مقدار حاصل کرتے ہیں۔

اگر آپ چاہیں تو اضافی میٹرکس شامل کر سکتے ہیں، جو ہمارے ڈیٹا بیس کی دستیابی کا اندازہ لگانے میں بھی مدد کرتے ہیں اور یہ مانیٹر کرتے ہیں کہ آیا کوئی کمی ہوئی ہے۔
ان میٹرکس میں سے ایک اپ ٹائم ہے۔ لیکن PostgreSQL میں اپ ٹائم تھوڑا مشکل ہے۔ میں آپ کو بتاؤں گا کیوں۔ جب PostgreSQL شروع ہو جاتا ہے، اپ ٹائم رپورٹنگ شروع ہو جاتا ہے۔ لیکن اگر کسی موقع پر، مثال کے طور پر، رات کو کوئی کام چل رہا تھا، ایک OOM-قاتل آیا اور زبردستی PostgreSQL چائلڈ پروسیس کو ختم کر دیا، تو اس صورت میں PostgreSQL تمام کلائنٹس کا کنکشن ختم کر دیتا ہے، یادداشت کے شارڈ ایریا کو دوبارہ سیٹ کرتا ہے اور اس سے ریکوری شروع کر دیتا ہے۔ آخری چوکی اور جب کہ چیک پوائنٹ سے یہ ریکوری جاری رہتی ہے، ڈیٹا بیس کنکشن کو قبول نہیں کرتا، یعنی اس صورتحال کا اندازہ ڈاؤن ٹائم کے طور پر کیا جا سکتا ہے۔ لیکن اپ ٹائم کاؤنٹر کو دوبارہ ترتیب نہیں دیا جائے گا، کیونکہ یہ پوسٹ ماسٹر کے آغاز کے وقت کو پہلے ہی لمحے سے مدنظر رکھتا ہے۔ اس لیے ایسے حالات کو چھوڑا جا سکتا ہے۔
آپ کو ویکیوم ورکرز کی تعداد کی بھی نگرانی کرنی چاہیے۔ کیا ہر کوئی جانتا ہے کہ PostgreSQL میں آٹو ویکیوم کیا ہے؟ یہ PostgreSQL میں ایک دلچسپ سب سسٹم ہے۔ ان کے بارے میں کئی مضامین لکھے گئے، کئی رپورٹیں بنیں۔ ویکیوم کے بارے میں بہت سی بحثیں ہیں اور اسے کیسے کام کرنا چاہیے۔ بہت سے لوگ اسے ایک ضروری برائی سمجھتے ہیں۔ لیکن ایسا ہی ہے۔ یہ کچرا جمع کرنے والے کا ایک قسم کا اینالاگ ہے جو قطاروں کے پرانے ورژن کو صاف کرتا ہے جن کی کسی لین دین کے لیے ضرورت نہیں ہوتی ہے اور نئی قطاروں کے لیے ٹیبلز اور انڈیکس میں جگہ خالی کردیتی ہے۔
آپ کو اس کی نگرانی کرنے کی ضرورت کیوں ہے؟ کیونکہ خلا کبھی کبھی بہت تکلیف دیتا ہے۔ یہ وسائل کی ایک بڑی مقدار استعمال کرتا ہے اور اس کے نتیجے میں کلائنٹ کی درخواستیں متاثر ہونے لگتی ہیں۔
اور اسے pg_stat_activity ویو کے ذریعے مانیٹر کیا جانا چاہیے، جس کے بارے میں میں اگلے حصے میں بات کروں گا۔ یہ منظر ڈیٹا بیس میں موجودہ سرگرمی کو ظاہر کرتا ہے۔ اور اس سرگرمی کے ذریعے ہم ان ویکیوم کی تعداد کا پتہ لگا سکتے ہیں جو ابھی کام کر رہے ہیں۔ ہم ویکیوم کو ٹریک کر سکتے ہیں اور دیکھ سکتے ہیں کہ اگر ہم نے حد سے تجاوز کیا ہے، تو یہ PostgreSQL سیٹنگز کو دیکھنے اور کسی نہ کسی طرح ویکیوم کے آپریشن کو بہتر بنانے کی ایک وجہ ہے۔
PostgreSQL کے بارے میں ایک اور بات یہ ہے کہ PostgreSQL طویل لین دین سے بہت بیمار ہے۔ خاص طور پر ان لین دین سے جو کافی دیر تک لٹکتے رہتے ہیں اور کچھ نہیں کرتے۔ یہ نام نہاد اسٹیٹ آئیڈل ان ٹرانزیکشن ہے۔ اس طرح کا لین دین تالے رکھتا ہے اور خلا کو کام کرنے سے روکتا ہے۔ اور اس کے نتیجے میں، میزیں پھول جاتی ہیں اور سائز میں اضافہ کرتی ہیں. اور ان ٹیبلز کے ساتھ کام کرنے والے سوالات آہستہ سے کام کرنا شروع کر دیتے ہیں، کیونکہ آپ کو میموری سے لے کر ڈسک اور بیک تک قطاروں کے تمام پرانے ورژن کو بیلنا پڑتا ہے۔ لہذا، وقت، طویل ترین لین دین کی مدت، سب سے طویل ویکیوم درخواستوں کو بھی مانیٹر کرنے کی ضرورت ہے۔ اور اگر ہم کچھ ایسے عمل کو دیکھتے ہیں جو بہت طویل عرصے سے چل رہے ہیں، پہلے ہی OLTP لوڈ کے لیے 10-20-30 منٹ سے زیادہ، تو ہمیں ان پر توجہ دینے کی ضرورت ہے اور انہیں زبردستی ختم کرنا ہوگا، یا ایپلی کیشن کو بہتر بنانا ہوگا تاکہ وہ نہیں بلائے جاتے ہیں اور اتنی دیر تک نہیں لٹکتے۔ تجزیاتی کام کے بوجھ کے لیے، 10-20-30 منٹ معمول کی بات ہے؛ اس میں طویل بھی ہیں۔

اگلا ہمارے پاس منسلک کلائنٹس کے ساتھ آپشن ہے۔ جب ہم پہلے ہی ڈیش بورڈ بنا چکے ہیں اور اس پر دستیابی کے کلیدی میٹرکس پوسٹ کر چکے ہیں، تو ہم وہاں منسلک کلائنٹس کے بارے میں اضافی معلومات بھی شامل کر سکتے ہیں۔
منسلک کلائنٹس کے بارے میں معلومات اہم ہیں کیونکہ، PostgreSQL نقطہ نظر سے، کلائنٹس مختلف ہیں۔ اچھے گاہک ہیں اور برے گاہک ہیں۔
ایک سادہ سی مثال۔ کلائنٹ کے ذریعہ میں درخواست کو سمجھتا ہوں۔ ایپلیکیشن ڈیٹا بیس سے منسلک ہو گئی ہے اور فوری طور پر وہاں اپنی درخواستیں بھیجنا شروع کر دیتی ہے، ڈیٹا بیس ان پر عمل کرتا ہے اور ان پر عملدرآمد کرتا ہے، اور نتائج کلائنٹ کو واپس کر دیتا ہے۔ یہ اچھے اور درست کلائنٹ ہیں۔
ایسے حالات ہوتے ہیں جب کلائنٹ جڑ جاتا ہے، وہ کنکشن رکھتا ہے، لیکن کچھ نہیں کرتا۔ یہ بیکار حالت میں ہے۔
لیکن برا گاہک ہیں. مثال کے طور پر، اسی کلائنٹ نے منسلک کیا، ایک ٹرانزیکشن کھولی، ڈیٹا بیس میں کچھ کیا اور پھر کوڈ میں چلا گیا، مثال کے طور پر، کسی بیرونی ذریعہ تک رسائی حاصل کرنے یا وہاں موصول ہونے والے ڈیٹا کو پروسیس کرنے کے لیے۔ لیکن اس نے لین دین بند نہیں کیا۔ اور لین دین ڈیٹا بیس میں ہینگ ہوتا ہے اور لائن پر ایک لاک میں رکھا جاتا ہے۔ یہ ایک بری حالت ہے۔ اور اگر اچانک اپنے اندر کہیں کوئی درخواست کسی استثناء کے ساتھ ناکام ہوجاتی ہے، تو یہ لین دین کافی دیر تک کھلا رہ سکتا ہے۔ اور یہ PostgreSQL کی کارکردگی کو براہ راست متاثر کرتا ہے۔ PostgreSQL سست ہوگا۔ اس لیے ایسے کلائنٹس کو بروقت ٹریک کرنا اور ان کے کام کو زبردستی ختم کرنا ضروری ہے۔ اور آپ کو اپنی درخواست کو بہتر بنانے کی ضرورت ہے تاکہ ایسے حالات پیدا نہ ہوں۔
دوسرے برے کلائنٹ کلائنٹس کا انتظار کر رہے ہیں۔ لیکن وہ حالات کی وجہ سے برے ہو جاتے ہیں۔ مثال کے طور پر، ایک سادہ بیکار لین دین: یہ لین دین کو کھول سکتا ہے، کچھ لائنوں پر تالے لے سکتا ہے، پھر کوڈ میں کہیں یہ ناکام ہو جائے گا، جس سے لین دین ہینگ رہ جائے گا۔ ایک اور کلائنٹ آئے گا اور اسی ڈیٹا کی درخواست کرے گا، لیکن اسے ایک تالے کا سامنا کرنا پڑے گا، کیونکہ اس ہینگنگ ٹرانزیکشن میں پہلے سے ہی کچھ مطلوبہ قطاروں پر تالے موجود ہیں۔ اور دوسری ٹرانزیکشن پہلے ٹرانزیکشن کے مکمل ہونے کے انتظار میں یا ایڈمنسٹریٹر کے ذریعہ زبردستی اسے بند کرنے کے منتظر رہے گی۔ لہذا، زیر التواء لین دین ڈیٹا بیس کنکشن کی حد کو جمع اور بھر سکتا ہے۔ اور جب حد پوری ہو جائے تو ایپلیکیشن ڈیٹا بیس کے ساتھ مزید کام نہیں کر سکتی۔ یہ پہلے ہی اس منصوبے کے لیے ہنگامی صورتحال ہے۔ لہذا، برے گاہکوں کو ٹریک کرنے اور بروقت طریقے سے جواب دینے کی ضرورت ہے.
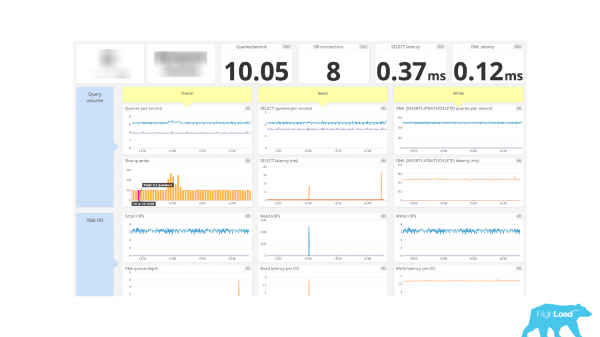
نگرانی کی ایک اور مثال۔ اور یہاں پہلے سے ہی ایک مہذب ڈیش بورڈ موجود ہے۔ اوپر کنکشن کے بارے میں معلومات موجود ہیں۔ ڈی بی کنکشن - 8 ٹکڑے۔ اور یہ سب ہے. ہمارے پاس اس بارے میں کوئی معلومات نہیں ہیں کہ کون سے کلائنٹ ایکٹو ہیں، کون سے کلائنٹ صرف بیکار ہیں، کچھ نہیں کر رہے۔ زیر التواء لین دین اور زیر التواء کنکشن کے بارے میں کوئی معلومات نہیں ہے، یعنی یہ ایک ایسا اعداد و شمار ہے جو کنکشن کی تعداد کو ظاہر کرتا ہے اور بس۔ اور پھر خود ہی اندازہ لگائیں۔

اس کے مطابق، نگرانی میں اس معلومات کو شامل کرنے کے لیے، آپ کو pg_stat_activity سسٹم ویو تک رسائی حاصل کرنے کی ضرورت ہے۔ اگر آپ PostgreSQL میں بہت زیادہ وقت گزارتے ہیں، تو یہ ایک بہت اچھا نقطہ نظر ہے جو آپ کا دوست بن جانا چاہیے، کیونکہ یہ PostgreSQL میں موجودہ سرگرمی کو ظاہر کرتا ہے، یعنی اس میں کیا ہو رہا ہے۔ ہر عمل کے لیے ایک الگ لائن ہوتی ہے جو اس عمل کے بارے میں معلومات کو ظاہر کرتی ہے: کس میزبان سے کنکشن بنایا گیا، کس صارف کے تحت، کس نام سے، لین دین کب شروع کیا گیا، فی الحال کون سی درخواست چل رہی ہے، آخری بار کون سی درخواست پر عمل ہوا تھا۔ اور، اسی کے مطابق، ہم اسٹیٹ فیلڈ کا استعمال کرتے ہوئے کلائنٹ کی حالت کا اندازہ لگا سکتے ہیں۔ نسبتاً، ہم اس فیلڈ کے مطابق گروپ بنا سکتے ہیں اور وہ اعدادوشمار حاصل کر سکتے ہیں جو فی الحال ڈیٹا بیس میں ہیں اور کنکشنز کی تعداد جو ڈیٹا بیس میں یہ اسٹیٹ رکھتے ہیں۔ اور ہم پہلے سے موصول ہونے والے نمبرز کو اپنی نگرانی میں بھیج سکتے ہیں اور ان کی بنیاد پر گراف بنا سکتے ہیں۔
لین دین کی مدت کا اندازہ لگانا بھی ضروری ہے۔ میں نے پہلے ہی کہا تھا کہ خلا کی مدت کا اندازہ لگانا ضروری ہے، لیکن لین دین کا اندازہ اسی طرح کیا جاتا ہے۔ xact_start اور query_start فیلڈز ہیں۔ وہ، نسبتاً بولتے ہوئے، لین دین کے آغاز کا وقت اور درخواست کے آغاز کا وقت دکھاتے ہیں۔ ہم now() فنکشن لیتے ہیں، جو موجودہ ٹائم اسٹیمپ کو ظاہر کرتا ہے، اور ٹرانزیکشن کو گھٹا کر ٹائم اسٹیمپ کی درخواست کرتے ہیں۔ اور ہمیں لین دین کی مدت، درخواست کی مدت ملتی ہے۔
اگر ہم لمبے لین دین دیکھتے ہیں، تو ہمیں انہیں پہلے ہی مکمل کرنا چاہیے۔ OLTP بوجھ کے لیے، طویل لین دین پہلے ہی 1-2-3 منٹ سے زیادہ ہے۔. OLAP کے کام کے بوجھ کے لیے، طویل لین دین معمول کی بات ہے، لیکن اگر ان کو مکمل ہونے میں دو گھنٹے سے زیادہ وقت لگتا ہے، تو یہ بھی اس بات کی علامت ہے کہ ہمارے پاس کہیں ترچھا ہے۔

ایک بار جب کلائنٹس ڈیٹا بیس سے جڑ جاتے ہیں، تو وہ ہمارے ڈیٹا کے ساتھ کام کرنا شروع کر دیتے ہیں۔ وہ میزوں تک رسائی حاصل کرتے ہیں، وہ میز سے ڈیٹا حاصل کرنے کے لیے اشاریہ جات تک رسائی حاصل کرتے ہیں۔ اور یہ جانچنا ضروری ہے کہ کلائنٹ اس ڈیٹا کے ساتھ کیسے تعامل کرتے ہیں۔
یہ ہمارے کام کے بوجھ کا اندازہ لگانے اور تقریباً یہ سمجھنے کے لیے ضروری ہے کہ کون سی میزیں ہمارے لیے "سب سے زیادہ گرم" ہیں۔ مثال کے طور پر، اس کی ضرورت ایسے حالات میں ہے جہاں ہم کسی قسم کے تیز SSD اسٹوریج پر "ہاٹ" ٹیبل رکھنا چاہتے ہیں۔ مثال کے طور پر، کچھ آرکائیو ٹیبل جو ہم نے طویل عرصے سے استعمال نہیں کیے ہیں، انہیں کسی قسم کے "کولڈ" آرکائیو میں، SATA ڈرائیوز میں منتقل کیا جا سکتا ہے اور انہیں وہاں رہنے دیا جائے گا، ضرورت کے مطابق ان تک رسائی حاصل کی جائے گی۔
یہ کسی بھی ریلیز اور تعیناتی کے بعد بے ضابطگیوں کا پتہ لگانے کے لیے بھی مفید ہے۔ ہم کہتے ہیں کہ پروجیکٹ نے کچھ نیا فیچر جاری کیا ہے۔ مثال کے طور پر، ہم نے ڈیٹا بیس کے ساتھ کام کرنے کے لیے نئی فعالیت شامل کی ہے۔ اور اگر ہم ٹیبل کے استعمال کے گراف کو پلاٹ کرتے ہیں، تو ہم آسانی سے ان گرافس پر ان بے ضابطگیوں کا پتہ لگا سکتے ہیں۔ مثال کے طور پر، برسٹ کو اپ ڈیٹ کریں یا برسٹ کو حذف کریں۔ یہ بہت نظر آئے گا۔
آپ "تیرتے" کے اعدادوشمار میں بے ضابطگیوں کا بھی پتہ لگا سکتے ہیں۔ اس کا کیا مطلب ہے؟ PostgreSQL ایک بہت مضبوط اور بہت اچھا استفسار کرنے والا منصوبہ ساز ہے۔ اور ڈویلپرز اس کی ترقی کے لیے بہت زیادہ وقت لگاتے ہیں۔ وہ کیسے کام کرتا ہے؟ اچھے منصوبے بنانے کے لیے، PostgreSQL ایک مخصوص وقت کے وقفے اور ایک خاص تعدد کے ساتھ جدولوں میں ڈیٹا کی تقسیم کے اعداد و شمار جمع کرتا ہے۔ یہ سب سے عام اقدار ہیں: منفرد اقدار کی تعداد، ٹیبل میں NULL کے بارے میں معلومات، بہت ساری معلومات۔
ان اعدادوشمار کی بنیاد پر، منصوبہ ساز کئی سوالات تیار کرتا ہے، سب سے بہترین کو منتخب کرتا ہے، اور اس استفسار کے منصوبے کو خود استفسار کرنے اور ڈیٹا واپس کرنے کے لیے استعمال کرتا ہے۔
اور ایسا ہوتا ہے کہ اعدادوشمار "فلوٹ" ہوتے ہیں۔ ٹیبل میں معیار اور مقدار کا ڈیٹا کسی نہ کسی طرح تبدیل ہوا، لیکن اعداد و شمار جمع نہیں کیے گئے۔ اور جو منصوبے بنائے گئے وہ بہترین نہیں ہو سکتے۔ اور اگر ہمارے منصوبے میزوں کی بنیاد پر جمع کی گئی نگرانی کی بنیاد پر سب سے زیادہ بہتر ثابت ہوتے ہیں، تو ہم ان بے ضابطگیوں کو دیکھ سکیں گے۔ مثال کے طور پر، کہیں ڈیٹا کوالٹیٹو تبدیل کیا گیا اور انڈیکس کی بجائے ٹیبل کے ذریعے ایک ترتیب وار پاس استعمال ہونے لگا، یعنی اگر کسی سوال کو صرف 100 قطاریں واپس کرنے کی ضرورت ہے (100 کی حد ہے)، تو اس سوال کے لیے مکمل تلاش کی جائے گی۔ اور اس کا ہمیشہ کارکردگی پر بہت برا اثر پڑتا ہے۔
اور ہم اسے نگرانی میں دیکھ سکتے ہیں۔ اور پہلے ہی اس استفسار کو دیکھیں، اس کی وضاحت کریں، اعداد و شمار جمع کریں، ایک نیا اضافی انڈیکس بنائیں۔ اور پہلے ہی اس مسئلے کا جواب دے دیں۔ اس لیے یہ ضروری ہے۔
نگرانی کی ایک اور مثال۔ میرے خیال میں بہت سے لوگوں نے اسے پہچانا کیونکہ وہ بہت مشہور ہے۔ جو اسے اپنے پروجیکٹس میں استعمال کرتے ہیں۔ ? کون اس پروڈکٹ کو Prometheus کے ساتھ مل کر استعمال کرتا ہے؟ حقیقت یہ ہے کہ اس مانیٹرنگ کے معیاری ذخیرہ میں PostgreSQL کے ساتھ کام کرنے کے لیے ایک ڈیش بورڈ موجود ہے۔ پرومیتھیس۔ لیکن ایک بری تفصیل ہے۔
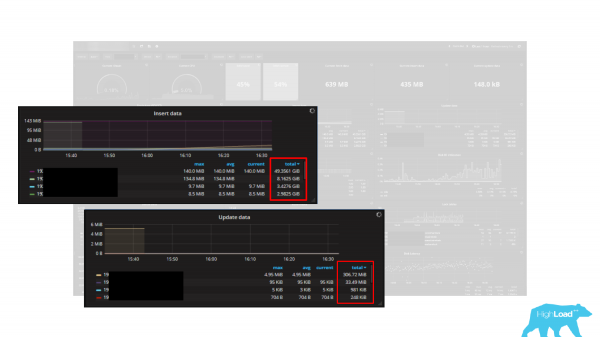
کئی گرافس ہیں۔ اور بائٹس کو اتحاد کے طور پر اشارہ کیا گیا ہے، یعنی 5 گراف ہیں۔ یہ ڈیٹا داخل کریں، ڈیٹا کو اپ ڈیٹ کریں، ڈیٹا کو حذف کریں، ڈیٹا بازیافت کریں اور ڈیٹا واپس کریں۔ یونٹ کی پیمائش بائٹس ہے۔ لیکن بات یہ ہے کہ PostgreSQL میں اعدادوشمار ٹپل (قطاروں) میں ڈیٹا واپس کرتے ہیں۔ اور، اس کے مطابق، یہ گراف آپ کے کام کے بوجھ کو کئی بار، دسیوں بار کم کرنے کا ایک بہت اچھا طریقہ ہیں، کیونکہ ایک ٹپل بائٹ نہیں ہوتا، ایک ٹیپل ایک سٹرنگ ہوتا ہے، یہ کئی بائٹس کا ہوتا ہے اور یہ ہمیشہ متغیر لمبائی کا ہوتا ہے۔ یعنی ٹوپلز کا استعمال کرتے ہوئے بائٹس میں کام کے بوجھ کا حساب لگانا ایک غیر حقیقی کام یا بہت مشکل ہے۔ اس لیے، جب آپ ڈیش بورڈ یا بلٹ ان مانیٹرنگ کا استعمال کرتے ہیں، تو یہ سمجھنا ہمیشہ ضروری ہوتا ہے کہ یہ صحیح طریقے سے کام کرتا ہے اور آپ کو درست طریقے سے تشخیص شدہ ڈیٹا واپس کرتا ہے۔

ان میزوں پر اعداد و شمار کیسے حاصل کیے جائیں؟ اس مقصد کے لیے، PostgreSQL کے خیالات کا ایک مخصوص خاندان ہے۔ اور اہم نقطہ نظر ہے . User_tables - اس کا مطلب ہے کہ صارف کی جانب سے بنائی گئی میزیں۔ اس کے برعکس، ایسے سسٹم ویوز ہیں جو خود PostgreSQL استعمال کرتے ہیں۔ اور ایک سمری ٹیبل Alltables ہے، جس میں سسٹم اور صارف دونوں شامل ہیں۔ آپ ان میں سے کسی سے شروع کر سکتے ہیں جو آپ کو سب سے زیادہ پسند ہے۔
مندرجہ بالا فیلڈز کا استعمال کرتے ہوئے آپ انسرٹس، اپ ڈیٹس اور ڈیلیٹس کی تعداد کا اندازہ لگا سکتے ہیں۔ ایک ڈیش بورڈ کی مثال جسے میں نے استعمال کیا ہے ان فیلڈز کو کام کے بوجھ کی خصوصیات کا اندازہ کرنے کے لیے استعمال کرتا ہے۔ لہذا، ہم ان پر بھی تعمیر کر سکتے ہیں. لیکن یہ یاد رکھنے کے قابل ہے کہ یہ ٹیپلز ہیں، بائٹس نہیں، لہذا ہم اسے صرف بائٹس میں نہیں کر سکتے۔
اس ڈیٹا کی بنیاد پر، ہم نام نہاد TopN ٹیبل بنا سکتے ہیں۔ مثال کے طور پر، ٹاپ-5، ٹاپ-10۔ اور آپ ان گرم میزوں کو ٹریک کرسکتے ہیں جو دوسروں کے مقابلے میں زیادہ ری سائیکل کی جاتی ہیں۔ مثال کے طور پر، داخل کرنے کے لیے 5 "گرم" میزیں۔ اور ان TopN ٹیبلز کا استعمال کرتے ہوئے ہم اپنے کام کے بوجھ کا اندازہ لگاتے ہیں اور کسی بھی ریلیز، اپ ڈیٹس اور تعیناتیوں کے بعد کام کے بوجھ کے پھٹ جانے کا اندازہ لگا سکتے ہیں۔
ٹیبل کے سائز کا اندازہ لگانا بھی ضروری ہے، کیونکہ بعض اوقات ڈویلپرز ایک نئی خصوصیت کو رول آؤٹ کرتے ہیں، اور ہماری میزیں اپنے بڑے سائز میں پھولنے لگتی ہیں، کیونکہ انہوں نے ڈیٹا کی اضافی مقدار شامل کرنے کا فیصلہ کیا، لیکن یہ پیش گوئی نہیں کی کہ یہ کیسے ہو گا۔ ڈیٹا بیس کے سائز کو متاثر کرتا ہے۔ ایسے واقعات بھی ہمارے لیے حیران کن ہوتے ہیں۔

اور اب آپ کے لیے ایک چھوٹا سا سوال۔ جب آپ اپنے ڈیٹا بیس سرور پر بوجھ محسوس کرتے ہیں تو کیا سوال پیدا ہوتا ہے؟ آپ کا اگلا سوال کیا ہے؟

لیکن درحقیقت سوال کچھ یوں پیدا ہوتا ہے۔ بوجھ کی وجہ سے کیا درخواستیں ہوتی ہیں؟ یعنی بوجھ کی وجہ سے ہونے والے عمل کو دیکھنا دلچسپ نہیں ہے۔ یہ واضح ہے کہ اگر میزبان کے پاس ڈیٹا بیس ہے، تو ڈیٹا بیس وہاں چل رہا ہے اور یہ واضح ہے کہ وہاں صرف ڈیٹا بیس کو ضائع کیا جائے گا۔ اگر ہم Top کو کھولتے ہیں، تو ہمیں PostgreSQL میں عمل کی ایک فہرست نظر آئے گی جو کچھ کر رہے ہیں۔ اوپر سے یہ واضح نہیں ہو گا کہ وہ کیا کر رہے ہیں۔

اس کے مطابق، آپ کو ان سوالات کو تلاش کرنے کی ضرورت ہے جو سب سے زیادہ بوجھ کا سبب بنتے ہیں، کیونکہ ٹیوننگ سوالات، ایک اصول کے طور پر، PostgreSQL یا آپریٹنگ سسٹم کنفیگریشن کو ٹیون کرنے، یا ہارڈ ویئر کو ٹیون کرنے سے زیادہ منافع دیتا ہے۔ میرے اندازے کے مطابق، یہ تقریباً 80-85-90% ہے۔ اور یہ بہت تیزی سے کیا جاتا ہے۔ کنفیگریشن کو درست کرنے، دوبارہ شروع کرنے کا شیڈول بنانے کے بجائے درخواست کو درست کرنا تیز تر ہے، خاص طور پر اگر ڈیٹا بیس کو دوبارہ شروع نہیں کیا جا سکتا، یا ہارڈ ویئر شامل کرنا۔ اس استفسار سے بہتر نتیجہ حاصل کرنے کے لیے استفسار کو کہیں دوبارہ لکھنا یا انڈیکس شامل کرنا آسان ہے۔
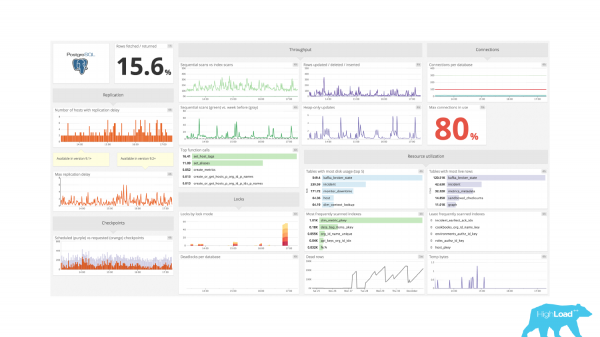
اس کے مطابق، درخواستوں اور ان کی مناسبیت کی نگرانی کرنا ضروری ہے۔ آئیے مانیٹرنگ کی ایک اور مثال لیتے ہیں۔ اور یہاں بھی، بہترین مانیٹرنگ دکھائی دیتی ہے۔ نقل کے بارے میں معلومات ہے، تھرو پٹ، بلاک کرنے، وسائل کے استعمال کے بارے میں معلومات موجود ہیں۔ سب کچھ ٹھیک ہے، لیکن درخواستوں پر کوئی معلومات نہیں ہے۔ یہ واضح نہیں ہے کہ ہمارے ڈیٹا بیس میں کون سے سوالات چل رہے ہیں، وہ کتنے عرصے سے چل رہے ہیں، ان میں سے کتنے سوالات ہیں۔ ہمیں اپنی نگرانی میں یہ معلومات ہمیشہ رکھنے کی ضرورت ہے۔

اور یہ معلومات حاصل کرنے کے لیے ہم pg_stat_statements ماڈیول استعمال کر سکتے ہیں۔ اس کی بنیاد پر، آپ مختلف قسم کے گراف بنا سکتے ہیں۔ مثال کے طور پر، آپ اکثر پوچھے جانے والے سوالات کے بارے میں معلومات حاصل کر سکتے ہیں، یعنی ان سوالات کے بارے میں جو اکثر کیے جاتے ہیں۔ ہاں، تعیناتی کے بعد اسے دیکھنا اور یہ سمجھنا بھی بہت مفید ہے کہ آیا درخواستوں میں کوئی اضافہ ہے۔
آپ طویل ترین سوالات کی نگرانی کر سکتے ہیں، یعنی وہ سوالات جن کو مکمل ہونے میں سب سے زیادہ وقت لگتا ہے۔ وہ پروسیسر پر چلتے ہیں، وہ I/O استعمال کرتے ہیں۔ ہم کل_وقت، اوسط_وقت، blk_write_time اور blk_read_time فیلڈز کا استعمال کرتے ہوئے بھی اس کا اندازہ لگا سکتے ہیں۔
ہم وسائل کے استعمال کے لحاظ سے سب سے بھاری درخواستوں کی جانچ اور نگرانی کر سکتے ہیں، وہ جو ڈسک سے پڑھتے ہیں، جو میموری کے ساتھ کام کرتے ہیں، یا اس کے برعکس، کسی قسم کا تحریری بوجھ پیدا کرتے ہیں۔
ہم سب سے زیادہ فراخدلی کی درخواستوں کا جائزہ لے سکتے ہیں۔ یہ وہ سوالات ہیں جو قطاروں کی ایک بڑی تعداد کو واپس کرتے ہیں۔ مثال کے طور پر، یہ کچھ درخواست ہو سکتی ہے جہاں وہ ایک حد مقرر کرنا بھول گئے ہوں۔ اور یہ صرف ٹیبل کے پورے مشمولات کو واپس کرتا ہے یا استفسار کردہ ٹیبلز میں استفسار کرتا ہے۔
اور آپ ان سوالات کی نگرانی بھی کر سکتے ہیں جو عارضی فائلیں یا عارضی میزیں استعمال کرتی ہیں۔

اور ہمارے پاس اب بھی پس منظر کے عمل ہیں۔ پس منظر کے عمل بنیادی طور پر چوکیاں ہیں یا انہیں چوکیاں بھی کہا جاتا ہے، یہ آٹو ویکیوم اور نقل ہیں۔
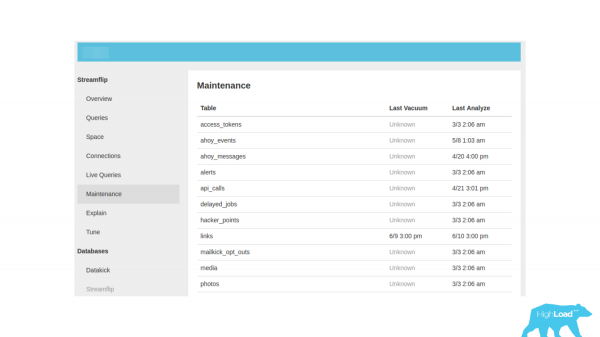
نگرانی کی ایک اور مثال۔ بائیں طرف ایک مینٹیننس ٹیب ہے، اس پر جائیں اور کچھ مفید دیکھنے کی امید کریں۔ لیکن یہاں صرف ویکیوم آپریشن اور اعداد و شمار جمع کرنے کا وقت ہے، اس سے زیادہ کچھ نہیں۔ یہ بہت ناقص معلومات ہے، اس لیے ہمیں ہمیشہ اس بارے میں معلومات کی ضرورت ہوتی ہے کہ ہمارے ڈیٹا بیس میں پس منظر کے عمل کیسے کام کرتے ہیں اور کیا ان کے کام میں کوئی دشواری ہے۔

جب ہم چوکیوں کو دیکھتے ہیں، تو ہمیں یاد رکھنا چاہیے کہ چوکیاں گندے صفحات کو شارڈ میموری ایریا سے ڈسک تک فلش کرتی ہیں، پھر ایک چیک پوائنٹ بناتی ہے۔ اور اس چیک پوائنٹ کو بحالی کے لیے جگہ کے طور پر استعمال کیا جا سکتا ہے اگر PostgreSQL کو کسی ہنگامی صورت حال میں اچانک ختم کر دیا گیا ہو۔
اس کے مطابق، تمام "گندے" صفحات کو ڈسک پر فلش کرنے کے لیے، آپ کو لکھنے کی ایک خاص مقدار کرنے کی ضرورت ہے۔ اور، ایک اصول کے طور پر، بڑی مقدار میں میموری والے سسٹمز پر، یہ بہت زیادہ ہے۔ اور اگر ہم قلیل وقفہ میں اکثر چوکیاں کرتے ہیں، تو ڈسک کی کارکردگی بہت نمایاں طور پر گر جائے گی۔ اور کلائنٹ کی درخواستیں وسائل کی کمی کا شکار ہوں گی۔ وہ وسائل کے لیے مقابلہ کریں گے اور پیداواری صلاحیت کی کمی ہوگی۔
اس کے مطابق، مخصوص فیلڈز کا استعمال کرتے ہوئے pg_stat_bgwriter کے ذریعے ہم چیک پوائنٹس کی تعداد کی نگرانی کر سکتے ہیں۔ اور اگر ہمارے پاس ایک خاص مدت (10-15-20 منٹ میں، آدھے گھنٹے میں) بہت زیادہ چوکیاں ہیں، مثال کے طور پر، 3-4-5، تو یہ پہلے سے ہی ایک مسئلہ ہو سکتا ہے۔ اور آپ کو پہلے ہی ڈیٹا بیس میں دیکھنے کی ضرورت ہے، کنفیگریشن میں دیکھو، چیک پوائنٹس کی اتنی کثرت کی وجہ کیا ہے۔ ہو سکتا ہے کہ کوئی بڑی ریکارڈنگ ہو رہی ہو۔ ہم پہلے سے ہی کام کے بوجھ کا اندازہ کر سکتے ہیں، کیونکہ ہم نے پہلے ہی کام کے بوجھ کے گراف کو شامل کیا ہے۔ ہم چیک پوائنٹ کے پیرامیٹرز کو پہلے ہی موافقت کر سکتے ہیں اور اس بات کو یقینی بنا سکتے ہیں کہ وہ استفسار کی کارکردگی کو بہت زیادہ متاثر نہیں کرتے ہیں۔

میں دوبارہ آٹو ویکیوم پر واپس آ رہا ہوں کیونکہ یہ ایک ایسی چیز ہے، جیسا کہ میں نے کہا، جو آسانی سے ڈسک اور استفسار کی کارکردگی دونوں میں اضافہ کر سکتا ہے، اس لیے آٹو ویکیوم کی مقدار کا اندازہ لگانا ہمیشہ ضروری ہے۔
ڈیٹا بیس میں آٹو ویکیوم ورکرز کی تعداد محدود ہے۔ پہلے سے طے شدہ طور پر، ان میں سے تین ہیں، لہذا اگر ہمارے پاس ہمیشہ ڈیٹا بیس میں تین کارکن کام کرتے ہیں، تو اس کا مطلب ہے کہ ہمارا آٹو ویکیوم کنفیگر نہیں ہے، ہمیں حدیں بڑھانے، آٹو ویکیوم سیٹنگز پر نظر ثانی کرنے اور کنفیگریشن میں جانے کی ضرورت ہے۔
یہ جانچنا ضروری ہے کہ ہمارے پاس کون سے ویکیوم ورکرز ہیں۔ یا تو اسے صارف سے لانچ کیا گیا تھا، DBA آیا اور دستی طور پر کسی قسم کا خلا شروع کیا، اور اس سے بوجھ پیدا ہوا۔ ہمیں کسی قسم کا مسئلہ درپیش ہے۔ یا یہ ویکیوم کی تعداد ہے جو ٹرانزیکشن کاؤنٹر کو کھولتے ہیں۔ PostgreSQL کے کچھ ورژن کے لیے یہ بہت بھاری ویکیوم ہیں۔ اور وہ آسانی سے کارکردگی میں اضافہ کر سکتے ہیں کیونکہ وہ پورے ٹیبل کو پڑھتے ہیں، اس ٹیبل کے تمام بلاکس کو اسکین کرتے ہیں۔
اور، ظاہر ہے، ویکیوم کی مدت۔ اگر ہمارے پاس دیرپا ویکیوم ہیں جو بہت لمبے عرصے تک چلتے ہیں، تو اس کا مطلب ہے کہ ہمیں دوبارہ ویکیوم کنفیگریشن پر توجہ دینے کی ضرورت ہے اور شاید اس کی سیٹنگز پر دوبارہ غور کرنا چاہیے۔ کیونکہ ایسی صورت حال پیدا ہو سکتی ہے جب ویکیوم میز پر لمبے عرصے تک کام کرتا رہے (3-4 گھنٹے)، لیکن جب ویکیوم کام کر رہا تھا، بہت زیادہ مردہ قطاریں دوبارہ میز میں جمع ہونے میں کامیاب ہو گئیں۔ اور جیسے ہی ویکیوم مکمل ہوتا ہے، اسے دوبارہ اس ٹیبل کو ویکیوم کرنے کی ضرورت ہوتی ہے۔ اور ہم ایک ایسی صورتحال پر پہنچتے ہیں - ایک نہ ختم ہونے والا خلا۔ اور اس صورت میں، ویکیوم اس کے کام سے نمٹنے نہیں کرتا، اور میزیں آہستہ آہستہ سائز میں پھولنے لگتی ہیں، اگرچہ اس میں مفید ڈیٹا کا حجم ایک ہی رہتا ہے. لہذا، طویل ویکیوم کے دوران، ہم ہمیشہ کنفیگریشن کو دیکھتے ہیں اور اسے بہتر بنانے کی کوشش کرتے ہیں، لیکن ساتھ ہی تاکہ کلائنٹ کی درخواستوں کی کارکردگی متاثر نہ ہو۔

آج کل عملی طور پر کوئی PostgreSQL انسٹالیشن نہیں ہے جس میں اسٹریمنگ کی نقل نہ ہو۔ نقل ایک ماسٹر سے نقل میں ڈیٹا منتقل کرنے کا عمل ہے۔
PostgreSQL میں نقل ایک ٹرانزیکشن لاگ کے ذریعے کی جاتی ہے۔ وزرڈ ٹرانزیکشن لاگ تیار کرتا ہے۔ ٹرانزیکشن لاگ نقل کے نیٹ ورک کنکشن پر سفر کرتا ہے، اور پھر اسے نقل پر دوبارہ تیار کیا جاتا ہے۔ یہ آسان ہے.
اس کے مطابق، pg_stat_replication ویو کو نقل کی وقفہ کی نگرانی کے لیے استعمال کیا جاتا ہے۔ لیکن اس کے ساتھ سب کچھ آسان نہیں ہے۔ ورژن 10 میں، منظر میں کئی تبدیلیاں آئی ہیں۔ سب سے پہلے، کچھ فیلڈز کا نام بدل دیا گیا ہے۔ اور کچھ فیلڈز شامل کیے گئے ہیں۔ ورژن 10 میں، فیلڈز نمودار ہوئے جو آپ کو سیکنڈوں میں نقل کے وقفے کا اندازہ لگانے کی اجازت دیتے ہیں۔ یہ بہت آرام دہ ہے۔ ورژن 10 سے پہلے، بائٹس میں نقل کے وقفے کا اندازہ لگانا ممکن تھا۔ یہ آپشن ورژن 10 میں موجود ہے، یعنی آپ اس بات کا انتخاب کر سکتے ہیں کہ آپ کے لیے کیا زیادہ آسان ہے - بائٹس میں وقفہ کا اندازہ لگائیں یا سیکنڈوں میں وقفہ کا اندازہ لگائیں۔ بہت سے لوگ دونوں کرتے ہیں۔
لیکن اس کے باوجود، نقل کے وقفے کا اندازہ کرنے کے لیے، آپ کو لین دین میں لاگ کی پوزیشن کو جاننے کی ضرورت ہے۔ اور یہ ٹرانزیکشن لاگ پوزیشن بالکل pg_stat_replication منظر میں ہیں۔ نسبتاً، ہم pg_xlog_location_diff() فنکشن کا استعمال کرتے ہوئے ٹرانزیکشن لاگ میں دو پوائنٹس لے سکتے ہیں۔ ان کے درمیان ڈیلٹا کا حساب لگائیں اور بائٹس میں نقل کا وقفہ حاصل کریں۔ یہ بہت آسان اور آسان ہے۔
ورژن 10 میں، اس فنکشن کا نام بدل کر pg_wal_lsn_diff() رکھا گیا تھا۔ عام طور پر، تمام فنکشنز، ویوز اور یوٹیلیٹیز میں جہاں لفظ "xlog" ظاہر ہوتا ہے، اسے "wal" کی قدر سے بدل دیا جاتا ہے۔ یہ خیالات اور افعال دونوں پر لاگو ہوتا ہے۔ یہ ایسی بدعت ہے۔
اس کے علاوہ، ورژن 10 میں، لائنیں شامل کی گئیں جو خاص طور پر وقفہ کو ظاہر کرتی ہیں۔ یہ رائٹ لیگ، فلش لیگ، ری پلے لیگ ہیں۔ یعنی ان چیزوں کی نگرانی ضروری ہے۔ اگر ہم دیکھتے ہیں کہ ہمارے پاس نقل تیار کرنے میں وقفہ ہے، تو ہمیں اس کی تحقیقات کرنے کی ضرورت ہے کہ یہ کیوں ظاہر ہوا، یہ کہاں سے آیا اور مسئلہ کو حل کریں۔

سسٹم میٹرکس کے ساتھ تقریباً سب کچھ ترتیب میں ہے۔ جب کوئی نگرانی شروع ہوتی ہے، تو یہ سسٹم میٹرکس سے شروع ہوتی ہے۔ یہ پروسیسرز، میموری، سویپ، نیٹ ورک اور ڈسک کا تصرف ہے۔ تاہم، بہت سے پیرامیٹرز پہلے سے طے شدہ نہیں ہیں۔
اگر سب کچھ ری سائیکلنگ کے عمل کے ساتھ ترتیب میں ہے، تو پھر ڈسک ری سائیکلنگ کے ساتھ مسائل ہیں. ایک اصول کے طور پر، نگرانی کرنے والے ڈویلپرز تھرو پٹ کے بارے میں معلومات شامل کرتے ہیں۔ یہ iops یا بائٹس میں ہو سکتا ہے۔ لیکن وہ تاخیر اور ڈسک ڈیوائسز کے استعمال کو بھول جاتے ہیں۔ یہ زیادہ اہم پیرامیٹرز ہیں جو ہمیں یہ جانچنے کی اجازت دیتے ہیں کہ ہماری ڈسکیں کتنی بھری ہوئی ہیں اور کتنی سست ہیں۔ اگر ہمارے پاس زیادہ تاخیر ہے، تو اس کا مطلب ہے کہ ڈسک کے ساتھ کچھ مسائل ہیں۔ اگر ہمارے پاس زیادہ استعمال ہے، تو اس کا مطلب ہے کہ ڈسکیں مقابلہ نہیں کر رہی ہیں۔ یہ تھرو پٹ سے بہتر خصوصیات ہیں۔
مزید یہ کہ یہ اعدادوشمار /proc فائل سسٹم سے بھی حاصل کیے جاسکتے ہیں، جیسا کہ ری سائیکلنگ پروسیسرز کے لیے کیا جاتا ہے۔ مجھے نہیں معلوم کہ یہ معلومات نگرانی میں کیوں شامل نہیں کی جاتی ہیں۔ لیکن اس کے باوجود، آپ کی نگرانی میں اس کا ہونا ضروری ہے۔
نیٹ ورک انٹرفیس پر بھی یہی لاگو ہوتا ہے۔ پیکٹ میں، بائٹس میں نیٹ ورک تھرو پٹ کے بارے میں معلومات موجود ہیں، لیکن اس کے باوجود تاخیر کے بارے میں کوئی معلومات نہیں ہے اور استعمال کے بارے میں کوئی معلومات نہیں ہے، حالانکہ یہ بھی مفید معلومات ہے۔

کسی بھی نگرانی میں خرابیاں ہوتی ہیں۔ اور اس سے کوئی فرق نہیں پڑتا ہے کہ آپ کس قسم کی نگرانی کرتے ہیں، یہ ہمیشہ کچھ معیار پر پورا نہیں اترے گا۔ لیکن اس کے باوجود، وہ ترقی کر رہے ہیں، نئی خصوصیات اور نئی چیزیں شامل کی جا رہی ہیں، لہذا کچھ منتخب کریں اور اسے مکمل کریں.
اور ختم کرنے کے لیے، آپ کو ہمیشہ اس بات کا اندازہ ہونا چاہیے کہ فراہم کردہ اعدادوشمار کا کیا مطلب ہے اور آپ انہیں مسائل کو حل کرنے کے لیے کیسے استعمال کر سکتے ہیں۔
اور چند اہم نکات:
- آپ کو ہمیشہ دستیابی کی نگرانی کرنی چاہیے اور ڈیش بورڈز رکھنے چاہئیں تاکہ آپ جلدی سے اندازہ لگا سکیں کہ ڈیٹا بیس کے ساتھ سب کچھ ٹھیک ہے۔
- آپ کو ہمیشہ یہ خیال رکھنے کی ضرورت ہوتی ہے کہ کلائنٹ آپ کے ڈیٹا بیس کے ساتھ کیا کام کر رہے ہیں تاکہ برے کلائنٹس کو ختم کیا جا سکے اور انہیں گولی مار دیں۔
- یہ جانچنا ضروری ہے کہ یہ کلائنٹس ڈیٹا کے ساتھ کیسے کام کرتے ہیں۔ آپ کو اپنے کام کے بوجھ کے بارے میں اندازہ ہونا ضروری ہے۔
- یہ جانچنا ضروری ہے کہ یہ کام کا بوجھ کیسے بنتا ہے، کن سوالات کی مدد سے۔ آپ سوالات کی جانچ کر سکتے ہیں، آپ ان کو بہتر بنا سکتے ہیں، ان کو ری ایکٹر کر سکتے ہیں، ان کے لیے انڈیکس بنا سکتے ہیں۔ یہ بہت اہم ہے.
- پس منظر کے عمل کلائنٹ کی درخواستوں پر منفی اثر ڈال سکتے ہیں، اس لیے یہ مانیٹر کرنا ضروری ہے کہ وہ بہت زیادہ وسائل استعمال نہیں کر رہے ہیں۔
- سسٹم میٹرکس آپ کو اپنے سرورز کی پیمائش اور صلاحیت بڑھانے کے منصوبے بنانے کی اجازت دیتے ہیں، اس لیے ان کا بھی پتہ لگانا اور ان کا جائزہ لینا ضروری ہے۔

اگر آپ اس موضوع میں دلچسپی رکھتے ہیں، تو آپ ان لنکس پر عمل کر سکتے ہیں۔
- یہ شماریات جمع کرنے والے کی طرف سے سرکاری دستاویز ہے۔ تمام شماریاتی آراء کی تفصیل اور تمام شعبوں کی تفصیل ہے۔ آپ انہیں پڑھ سکتے ہیں، سمجھ سکتے ہیں اور ان کا تجزیہ کر سکتے ہیں۔ اور ان کی بنیاد پر، اپنے گرافس بنائیں اور انہیں اپنی نگرانی میں شامل کریں۔
مثال کی درخواستیں:
یہ ہمارا کارپوریٹ ذخیرہ ہے اور میرا اپنا۔ وہ مثال کے سوالات پر مشتمل ہیں۔ وہاں سیریز سے سلیکٹ* سے کوئی سوالات نہیں ہیں۔ جوائنز کے ساتھ پہلے سے ہی تیار سوالات موجود ہیں، دلچسپ فنکشنز کا استعمال کرتے ہوئے جو آپ کو خام نمبروں کو پڑھنے کے قابل، آسان اقدار میں تبدیل کرنے کی اجازت دیتے ہیں، یعنی یہ بائٹس، وقت ہیں۔ آپ انہیں اٹھا سکتے ہیں، انہیں دیکھ سکتے ہیں، ان کا تجزیہ کر سکتے ہیں، انہیں اپنی نگرانی میں شامل کر سکتے ہیں، ان کی بنیاد پر اپنی نگرانی بنا سکتے ہیں۔
آپ کے سوالات
سوال: آپ نے کہا تھا کہ آپ برانڈز کی تشہیر نہیں کریں گے، لیکن میں اب بھی متجسس ہوں - آپ اپنے پروجیکٹس میں کس قسم کے ڈیش بورڈ استعمال کرتے ہیں؟
جواب: یہ مختلف ہوتا ہے۔ ایسا ہوتا ہے کہ ہم ایک گاہک کے پاس آتے ہیں اور اس کی اپنی نگرانی پہلے سے ہوتی ہے۔ اور ہم گاہک کو مشورہ دیتے ہیں کہ ان کی نگرانی میں کیا شامل کرنے کی ضرورت ہے۔ زبکس کا سب سے برا حال ہے۔ کیونکہ اس میں TopN گراف بنانے کی صلاحیت نہیں ہے۔ ہم خود استعمال کرتے ہیں۔ ، کیونکہ ہم نگرانی پر ان لڑکوں سے مشورہ کر رہے تھے۔ انہوں نے ہماری تکنیکی خصوصیات کی بنیاد پر PostgreSQL کی نگرانی کی۔ میں اپنا پالتو پراجیکٹ لکھ رہا ہوں، جو پرومیتھیس کے ذریعے ڈیٹا اکٹھا کرتا ہے اور اسے رینڈر کرتا ہے۔ . میرا کام Prometheus میں اپنا برآمد کنندہ بنانا ہے اور پھر Grafana میں سب کچھ پیش کرنا ہے۔
سوال: کیا AWR رپورٹس یا... جمع کے کوئی مشابہت ہیں؟ کیا آپ اس طرح کے بارے میں جانتے ہیں؟
جواب: جی ہاں، میں جانتا ہوں کہ AWR کیا ہے، یہ ایک اچھی چیز ہے۔ اس وقت مختلف قسم کی سائیکلیں ہیں جو تقریباً درج ذیل ماڈل کو نافذ کرتی ہیں۔ وقت کے کچھ وقفے پر، کچھ بنیادی خطوط ایک ہی PostgreSQL یا الگ اسٹوریج پر لکھے جاتے ہیں۔ آپ انہیں انٹرنیٹ پر گوگل کر سکتے ہیں، وہ وہاں موجود ہیں۔ ایسی چیز کے ڈویلپرز میں سے ایک PostgreSQL تھریڈ میں sql.ru فورم پر بیٹھا ہے۔ آپ اسے وہاں پکڑ سکتے ہیں۔ جی ہاں، ایسی چیزیں ہیں، وہ استعمال کی جا سکتی ہیں. پلس اس میں میں ایک ایسی چیز بھی لکھ رہا ہوں جو آپ کو وہی کام کرنے کی اجازت دیتا ہے۔
PS1 اگر آپ postgres_exporter استعمال کر رہے ہیں، تو آپ کون سا ڈیش بورڈ استعمال کر رہے ہیں؟ ان میں سے کئی ہیں۔ وہ پہلے ہی پرانے ہیں۔ ہوسکتا ہے کہ کمیونٹی ایک اپ ڈیٹ شدہ ٹیمپلیٹ بنائے؟
PS2 کو ہٹا دیا گیا pganalyze کیونکہ یہ ایک ملکیتی SaaS پیشکش ہے جو کارکردگی کی نگرانی اور خودکار ٹیوننگ کی تجاویز پر مرکوز ہے۔
سروے میں صرف رجسٹرڈ صارفین ہی حصہ لے سکتے ہیں۔ ، برائے مہربانی.
آپ کس سیلف ہوسٹڈ پوسٹگریس کیو ایل مانیٹرنگ (ڈیش بورڈ کے ساتھ) کو بہترین سمجھتے ہیں؟
30,0٪Zabbix + Alexey Lesovsky یا zabbix 4.4 یا libzbxpgsql + zabbix libzbxpgsql + zabbix3 سے اضافہ
0,0٪https://github.com/lesovsky/pgcenter0
0,0٪https://github.com/pg-monz/pg_monz0
20,0٪https://github.com/cybertec-postgresql/pgwatch22
20,0٪https://github.com/postgrespro/mamonsu2
0,0٪https://www.percona.com/doc/percona-monitoring-and-management/conf-postgres.html0
10,0٪pganalyze ایک ملکیتی SaaS ہے - میں اسے حذف نہیں کر سکتا
10,0٪https://github.com/powa-team/powa1
0,0٪https://github.com/darold/pgbadger0
0,0٪https://github.com/darold/pgcluu0
0,0٪https://github.com/zalando/PGObserver0
10,0٪https://github.com/spotify/postgresql-metrics1
10 صارفین نے ووٹ دیا۔ 26 صارفین غیر حاضر رہے۔
ماخذ: www.habr.com
