


ہمارے ارد گرد کی دنیا ہر قسم کی معلومات سے بھری ہوئی ہے جس پر ہمارا دماغ مسلسل عمل کرتا ہے۔ وہ یہ معلومات حسی اعضاء کے ذریعے حاصل کرتا ہے، جن میں سے ہر ایک سگنلز کے اپنے حصے کے لیے ذمہ دار ہے: آنکھیں (وژن)، زبان (ذائقہ)، ناک (بو)، جلد (ٹچ)، ویسٹیبلر اپریٹس (توازن، خلا میں پوزیشن اور احساس۔ وزن) اور کان (آواز)۔ ان تمام اعضاء سے ملنے والے سگنلز کو ملا کر ہمارا دماغ اپنے ماحول کی درست تصویر بنا سکتا ہے۔ لیکن بیرونی سگنلز کی پروسیسنگ کے تمام پہلو ہمیں معلوم نہیں ہیں۔ ان میں سے ایک راز آوازوں کے منبع کو مقامی بنانے کا طریقہ کار ہے۔
لیبارٹری آف نیورو انجینئرنگ آف سپیچ اینڈ ہیئرنگ (نیو جرسی انسٹی ٹیوٹ آف ٹیکنالوجی) کے سائنسدانوں نے آواز کی لوکلائزیشن کے اعصابی عمل کا ایک نیا ماڈل تجویز کیا ہے۔ آواز کے ادراک کے دوران دماغ میں کیا صحیح عمل ہوتا ہے، ہمارا دماغ آواز کے منبع کی پوزیشن کو کیسے سمجھتا ہے، اور یہ تحقیق سماعت کے نقائص کے خلاف جنگ میں کس طرح مدد کر سکتی ہے۔ ہم اس بارے میں ریسرچ گروپ کی رپورٹ سے سیکھتے ہیں۔ جاؤ.
تحقیق کی بنیاد
ہمارے دماغ کو ہمارے حواس سے جو معلومات ملتی ہیں وہ ایک دوسرے سے مختلف ہوتی ہیں، دونوں اس کے ماخذ کے لحاظ سے اور اس کی پروسیسنگ کے لحاظ سے۔ کچھ سگنل فوری طور پر ہمارے دماغ میں درست معلومات کے طور پر ظاہر ہوتے ہیں، جبکہ دیگر کو اضافی کمپیوٹیشنل عمل کی ضرورت ہوتی ہے۔ موٹے الفاظ میں، ہم فوری طور پر ایک لمس محسوس کرتے ہیں، لیکن جب ہم کوئی آواز سنتے ہیں، ہمیں پھر بھی یہ تلاش کرنا پڑتا ہے کہ یہ کہاں سے آتی ہے۔
افقی جہاز میں آوازوں کو مقامی بنانے کی بنیاد ہے۔ اندرونی* وقت کا فرق (ITD سے اندرونی وقت کا فرق) آواز سننے والے کے کانوں تک پہنچتی ہے۔
اندرونی بنیاد* - کانوں کے درمیان فاصلہ۔
دماغ میں ایک مخصوص علاقہ ہے (میڈیل اعلیٰ زیتون یا MSO) جو اس عمل کا ذمہ دار ہے۔ اس وقت ایم وی او میں صوتی سگنل موصول ہوتا ہے، انٹراورل ٹائم فرق نیوران کے رد عمل کی شرح میں تبدیل ہو جاتے ہیں۔ ITD کے ایک فنکشن کے طور پر MBO آؤٹ پٹ velocity curves کی شکل ہر کان کے لیے ان پٹ سگنلز کے کراس کوریلیشن فنکشن کی شکل سے مشابہت رکھتی ہے۔
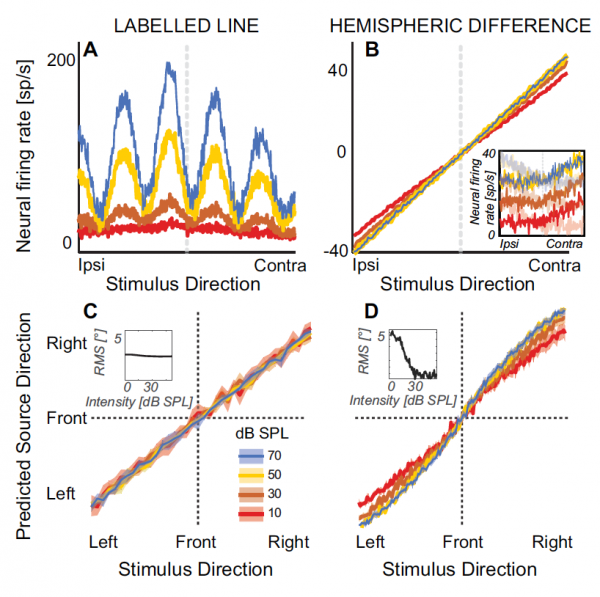
MBO میں معلومات پر کارروائی اور تشریح کیسے کی جاتی ہے یہ پوری طرح واضح نہیں ہے، یہی وجہ ہے کہ بہت سے متضاد نظریات موجود ہیں۔ صوتی لوکلائزیشن کا سب سے مشہور اور حقیقت میں کلاسیکی نظریہ جیفریس ماڈل ہے (لائیڈ اے جیفریس)۔ پر مبنی ہے۔ نشان زد لائن* ڈیٹیکٹر نیوران جو ہر کان کے اعصابی آدانوں کی بائنورل ہم آہنگی کے لیے حساس ہوتے ہیں، ہر ایک نیوران آئی ٹی ڈی کی ایک خاص مقدار کے لیے زیادہ سے زیادہ حساس ہوتا ہے۔1A).
نشان زد لائن اصول* یہ ایک مفروضہ ہے جو اس بات کی وضاحت کرتا ہے کہ کس طرح مختلف اعصاب، جن میں سے سبھی اپنے محوروں کے ساتھ تسلسل کو منتقل کرنے میں ایک جیسے جسمانی اصولوں کا استعمال کرتے ہیں، مختلف احساسات پیدا کرنے کے قابل ہیں۔ ساختی طور پر ملتے جلتے اعصاب مختلف حسی تصورات پیدا کر سکتے ہیں اگر وہ مرکزی اعصابی نظام کے منفرد نیوران سے جڑے ہوں جو مختلف طریقوں سے اسی طرح کے اعصابی اشاروں کو ڈی کوڈ کرنے کی صلاحیت رکھتے ہیں۔
تصویر #1
یہ ماڈل کمپیوٹیشنل طور پر اعصابی کوڈنگ سے ملتا جلتا ہے، جو دونوں کانوں تک پہنچنے والی آوازوں کے غیر محدود باہمی ربط پر مبنی ہے۔
ایک ایسا ماڈل بھی ہے جو تجویز کرتا ہے کہ آواز کی لوکلائزیشن کو دماغ کے مختلف نصف کرہ سے نیوران کی مخصوص آبادیوں کے ردعمل کی رفتار میں فرق کی بنیاد پر بنایا جا سکتا ہے، یعنی interhemispheric asymmetry کا ماڈل (1V).
اب تک، یہ واضح طور پر بتانا مشکل تھا کہ دونوں میں سے کون سا نظریہ (ماڈل) درست ہے، اس لیے کہ ان میں سے ہر ایک آواز کی شدت پر صوتی لوکلائزیشن کے مختلف انحصار کی پیش گوئی کرتا ہے۔
اس مطالعہ میں جسے ہم آج دیکھ رہے ہیں، محققین نے یہ سمجھنے کے لیے دونوں ماڈلز کو یکجا کرنے کا فیصلہ کیا کہ آیا آوازوں کا تصور اعصابی کوڈنگ پر مبنی ہے یا انفرادی عصبی آبادی کے ردعمل میں فرق پر۔ کئی تجربات کیے گئے جن میں 18 سے 27 سال کی عمر کے لوگوں (5 خواتین اور 7 مرد) نے حصہ لیا۔ شرکاء کی آڈیو میٹری (سماعت کی تیز رفتاری کی پیمائش) 25 اور 250 ہرٹز کے درمیان 8000 ڈی بی یا اس سے زیادہ تھی۔ تجربات میں حصہ لینے والے کو ایک ساؤنڈ پروف کمرے میں رکھا گیا تھا، جس میں خصوصی آلات رکھے گئے تھے، جنہیں اعلیٰ درستگی کے ساتھ کیلیبریٹ کیا گیا تھا۔ شرکاء کو آواز کا اشارہ سننے پر اس سمت کی نشاندہی کرنی پڑتی تھی جہاں سے یہ آیا تھا۔
تحقیق کے نتائج
انحصار کا اندازہ لگانے کے لیے پس منظر* لیبل والے نیوران کے جواب میں آواز کی شدت سے دماغی سرگرمی، بارن اللو دماغ کے لیمینر نیوکلئس میں نیوران کے رد عمل کی رفتار سے متعلق ڈیٹا استعمال کیا گیا۔
پس منظر* - جسم کے بائیں اور دائیں حصوں کی غیر متناسبیت۔
نیوران کی بعض آبادیوں کے رد عمل کی رفتار پر دماغی سرگرمی کے پس منظر کے انحصار کا اندازہ لگانے کے لیے، ریشس بندر کے دماغ کے کمتر کالیکولس کی سرگرمی سے ڈیٹا استعمال کیا گیا، جس کے بعد مختلف نصف کرہ کے نیوران کی رفتار میں فرق کا بھی حساب لگایا گیا۔ .
ڈیٹیکٹر نیورون کا نشان زدہ لائن ماڈل پیش گوئی کرتا ہے کہ جیسے جیسے آواز کی شدت کم ہوتی جائے گی، سمجھے جانے والے ماخذ کا پس منظر نرم اور بلند آوازوں کے تناسب سے ملتی جلتی قدروں میں بدل جائے گا (1S).
نصف کرہ کی ہم آہنگی ماڈل، بدلے میں، تجویز کرتا ہے کہ جیسے جیسے آواز کی شدت حد کے قریب کم ہو جاتی ہے، سمجھی جانے والی پس منظر درمیانی لکیر کی طرف منتقل ہو جائے گی (1D).
زیادہ مجموعی آواز کی شدت پر، لیٹرلائزیشن کی توقع کی جاتی ہے کہ وہ شدت کے انویریئنٹ ہوں گے (ان سیٹس 1S и 1D).
لہٰذا، اس بات کا تجزیہ کرنا کہ کس طرح آواز کی شدت آواز کی سمجھی ہوئی سمت کو متاثر کرتی ہے، ہمیں اس لمحے میں ہونے والے عمل کی نوعیت کا درست تعین کرنے کی اجازت دیتا ہے - ایک ہی عام علاقے سے نیوران یا مختلف نصف کرہ کے نیوران۔
واضح طور پر، کسی شخص کی ITD کے ساتھ امتیاز کرنے کی صلاحیت آواز کی شدت کے لحاظ سے مختلف ہو سکتی ہے۔ تاہم، سائنسدانوں کا کہنا ہے کہ آئی ٹی ڈی سے حساسیت کو جوڑنے والے سابقہ نتائج کی تشریح کرنا مشکل ہے اور آواز کی شدت کے ایک فنکشن کے طور پر صوتی ماخذ کی سمت کے بارے میں سننے والوں کے فیصلے۔ کچھ مطالعات کا کہنا ہے کہ جب آواز کی شدت حد کی حد تک پہنچ جاتی ہے، تو ماخذ کی سمجھی جانے والی پس منظر کم ہو جاتی ہے۔ دیگر مطالعات سے پتہ چلتا ہے کہ ادراک پر شدت کا کوئی اثر نہیں ہے۔
دوسرے لفظوں میں، سائنسدان "آہستگی سے" اشارہ کر رہے ہیں کہ ادب میں ITD کے درمیان تعلق، آواز کی شدت اور اس کے ماخذ کی سمت کا تعین کرنے کے حوالے سے بہت کم معلومات موجود ہیں۔ ایسے نظریات موجود ہیں جو ایک قسم کے محور کے طور پر موجود ہیں، جسے عام طور پر سائنسی برادری قبول کرتی ہے۔ اس لیے، تمام نظریات، ماڈلز اور عملی طور پر سماعت کے ادراک کے ممکنہ میکانزم کی تفصیل سے جانچ کرنے کا فیصلہ کیا گیا۔
پہلا تجربہ ایک سائیکو فزیکل تمثیل پر مبنی تھا جس نے دس عام سماعت کے شرکاء کے گروپ میں آواز کی شدت کے ایک فنکشن کے طور پر آئی ٹی ڈی پر مبنی پس منظر کے مطالعہ کی اجازت دی۔
تصویر #2
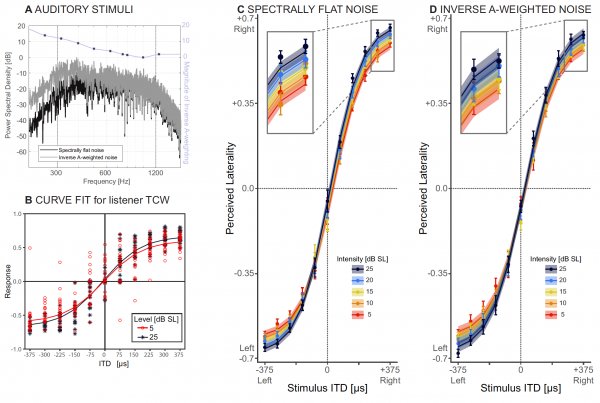
آواز کے ذرائع کو خاص طور پر زیادہ تر فریکوئنسی رینج کا احاطہ کرنے کے لیے بنایا گیا تھا جس کے اندر انسان ITD کا پتہ لگانے کے قابل ہوتے ہیں، یعنی 300 سے 1200 ہرٹج تک (2A).
ہر ٹرائل پر، سننے والے کو 375 سے 375 ms تک آئی ٹی ڈی اقدار کی ایک رینج میں، احساس کی سطح کے فنکشن کے طور پر ماپا جانے والی پس منظر کی نشاندہی کرنا پڑتی تھی۔ آواز کی شدت کے اثر کا تعین کرنے کے لیے، ایک نان لائنر مکسڈ ایفیکٹس ماڈل (NMLE) استعمال کیا گیا جس میں فکسڈ اور بے ترتیب آواز کی شدت دونوں شامل ہیں۔
شیڈول 2V ایک نمائندہ سامعین کے لیے دو آواز کی شدت پر سپیکٹرل فلیٹ شور کے ساتھ تخمینہ شدہ پس منظر کو ظاہر کرتا ہے۔ اور شیڈول 2S تمام سامعین کے خام ڈیٹا (حلقے) اور فٹ شدہ NMLE ماڈل (لائنز) دکھاتا ہے۔
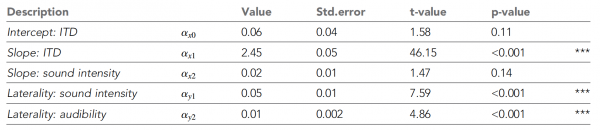
جدول نمبر 1۔
مندرجہ بالا جدول تمام NLME پیرامیٹرز کو دکھاتا ہے۔ یہ دیکھا جا سکتا ہے کہ ITD میں اضافے کے ساتھ سمجھی جانے والی پس منظر میں اضافہ ہوا، جیسا کہ سائنسدانوں کی توقع تھی۔ جیسے جیسے آواز کی شدت کم ہوتی گئی، ادراک زیادہ سے زیادہ مڈ لائن کی طرف منتقل ہوتا گیا (گراف میں انسیٹ 2C).
ان رجحانات کو NLME ماڈل کے ذریعے سپورٹ کیا گیا، جس نے ITD کے نمایاں اثرات اور پس منظر کی زیادہ سے زیادہ ڈگری پر آواز کی شدت کو ظاہر کیا، جو کہ interhemispheric فرق کے ماڈل کی حمایت کرتا ہے۔
اس کے علاوہ، خالص ٹونز کے لیے اوسط آڈیو میٹرک تھریشولڈز کا سمجھی جانے والی پس منظر پر بہت کم اثر پڑا۔ لیکن آواز کی شدت نے نفسیاتی افعال کے اشارے کو نمایاں طور پر متاثر نہیں کیا۔
دوسرے تجربے کا بنیادی مقصد یہ طے کرنا تھا کہ محرکات (آوازوں) کی طنزیہ خصوصیات کو مدنظر رکھتے ہوئے پچھلے تجربے میں حاصل کردہ نتائج کیسے بدلیں گے۔ کم آواز کی شدت پر سپیکٹرل فلیٹ شور کی جانچ کرنے کی ضرورت یہ ہے کہ سپیکٹرم کے کچھ حصے قابل سماعت نہیں ہوسکتے ہیں اور یہ آواز کی سمت کے تعین کو متاثر کر سکتا ہے۔ نتیجتاً، پہلے تجربے کے نتائج کو غلطی سے اس حقیقت کے لیے غلط قرار دیا جا سکتا ہے کہ سپیکٹرم کے قابل سماعت حصے کی چوڑائی آواز کی شدت میں کمی کے ساتھ کم ہو سکتی ہے۔
لہذا، یہ ایک اور تجربہ کرنے کا فیصلہ کیا گیا تھا، لیکن ریورس کا استعمال کرتے ہوئے ایک وزنی* شور
ایک وزنی* آواز کی سطحوں پر لاگو کیا جاتا ہے تاکہ انسانی کان کی طرف سے سمجھی جانے والی نسبتہ بلندی کو مدنظر رکھا جا سکے، کیونکہ کان کم آواز کی تعدد کے لیے کم حساس ہوتا ہے۔ A-weighting کا اطلاق ریاضی کے مطابق آکٹیو بینڈز میں درج اقدار کے جدول کو dB میں ماپی گئی آواز کے دباؤ کی سطحوں میں شامل کر کے کیا جاتا ہے۔
چارٹ پر 2D تجربے میں تمام شرکاء کا خام ڈیٹا (حلقے) اور NMLE ماڈل سے لیس ڈیٹا (لائنز) دکھاتا ہے۔
اعداد و شمار کے تجزیے سے پتہ چلتا ہے کہ جب آواز کے تمام حصے تقریباً یکساں طور پر قابل سماعت ہوتے ہیں (پہلے اور دوسرے ٹرائل میں)، محسوس شدہ پس منظر اور گراف میں ڈھلوان آواز کی شدت میں کمی کے ساتھ ITD میں کمی کے ساتھ پس منظر میں تبدیلی کی وضاحت کرتا ہے۔
اس طرح، دوسرے تجربے کے نتائج نے پہلے کے نتائج کی تصدیق کی۔ یعنی عملی طور پر یہ دکھایا گیا ہے کہ 1948 میں جیفریس نے جو ماڈل تجویز کیا تھا وہ درست نہیں ہے۔
اس سے پتہ چلتا ہے کہ آواز کی شدت میں کمی کے ساتھ ہی صوتی لوکلائزیشن خراب ہو جاتی ہے، اور جیفریس کا خیال تھا کہ آوازیں انسانوں کی طرف سے اسی طرح سمجھی جاتی ہیں اور ان پر کارروائی ہوتی ہے، چاہے ان کی شدت کچھ بھی ہو۔
مطالعہ کی باریکیوں سے مزید تفصیلی واقفیت کے لیے، میں اسے دیکھنے کی تجویز کرتا ہوں۔ .
اپسنہار
نظریاتی مفروضوں اور ان کی تصدیق کرنے والے عملی تجربات سے یہ بات سامنے آئی ہے کہ ممالیہ جانوروں میں دماغی نیوران صوتی سگنل کی سمت کے لحاظ سے مختلف شرحوں پر متحرک ہوتے ہیں۔ اس کے بعد دماغ ان رفتاروں کا موازنہ اس عمل میں شامل تمام نیورانوں کے درمیان کرتا ہے تاکہ متحرک طور پر آواز کے ماحول کا نقشہ بنایا جا سکے۔
جیفریسن کا ماڈل درحقیقت 100% غلط نہیں ہے، کیونکہ اس کا استعمال بارن اللو میں آواز کے ماخذ کی لوکلائزیشن کو مکمل طور پر بیان کرنے کے لیے کیا جا سکتا ہے۔ ہاں، گودام کے الّو کے لیے آواز کی شدت سے کوئی فرق نہیں پڑتا؛ بہر حال، وہ اس کے منبع کا تعین کریں گے۔ تاہم، یہ ماڈل ریسس بندروں کے ساتھ کام نہیں کرتا، جیسا کہ پچھلے تجربات سے ظاہر ہوا ہے۔ لہذا، یہ جیفریسن ماڈل تمام جانداروں کے لیے آوازوں کی لوکلائزیشن کو بیان نہیں کر سکتا۔
انسانی شرکاء کے ساتھ تجربات نے ایک بار پھر اس بات کی تصدیق کی ہے کہ آواز کی لوکلائزیشن مختلف جانداروں میں مختلف طریقے سے ہوتی ہے۔ بہت سے شرکاء آوازوں کی کم شدت کی وجہ سے صوتی سگنلز کے ماخذ کی پوزیشن کا صحیح طریقے سے تعین کرنے سے قاصر تھے۔
سائنس دانوں کا خیال ہے کہ ان کے کام سے کچھ مماثلتیں دکھائی دیتی ہیں کہ ہم کیسے دیکھتے ہیں اور کیسے سنتے ہیں۔ دونوں عمل دماغ کے مختلف حصوں میں نیوران کی رفتار کے ساتھ منسلک ہوتے ہیں، ساتھ ہی اس فرق کے جائزے کے ساتھ ان چیزوں کی پوزیشن کا تعین کیا جاتا ہے جو ہم خلا میں دیکھتے ہیں اور جو آواز ہم سنتے ہیں اس کے منبع کی پوزیشن دونوں کا تعین کیا جاتا ہے۔
مستقبل میں، محققین انسانی سماعت اور بصارت کے درمیان تعلق کو مزید تفصیل سے جانچنے کے لیے تجربات کا ایک سلسلہ کرنے جا رہے ہیں، جس سے ہمیں یہ بہتر طور پر سمجھنے میں مدد ملے گی کہ ہمارا دماغ کس طرح متحرک طور پر ہمارے ارد گرد کی دنیا کا نقشہ بناتا ہے۔
آپ کی توجہ کے لیے آپ کا شکریہ، متجسس رہیں اور سب کا ہفتہ اچھا گزرے! 🙂
ہمارے ساتھ رہنے کے لیے آپ کا شکریہ۔ کیا آپ کو ہمارے مضامین پسند ہیں؟ مزید دلچسپ مواد دیکھنا چاہتے ہیں؟ آرڈر دے کر یا دوستوں کو مشورہ دے کر ہمارا ساتھ دیں، , انٹری لیول سرورز کے انوکھے اینالاگ پر Habr کے صارفین کے لیے 30% رعایت، جو ہم نے آپ کے لیے ایجاد کیا تھا: (RAID1 اور RAID10 کے ساتھ دستیاب، 24 کور تک اور 40GB DDR4 تک)۔
ڈیل R730xd 2 گنا سستا؟ صرف یہاں نیدرلینڈ میں! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - $99 سے! کے بارے میں پڑھا
ماخذ: www.habr.com
